
Innholdsfortegnelse
Opplæringen forklarer essensen av standardavviket og standardfeilen til gjennomsnittet, samt hvilken formel som er best å bruke for å beregne standardavvik i Excel.
I beskrivende statistikk , det aritmetiske gjennomsnittet (også kalt gjennomsnittet) og standardavviket og er to nært beslektede begreper. Men mens det første er godt forstått av de fleste, er det få som forstår det siste. Målet med denne opplæringen er å kaste lys over hva standardavviket faktisk er og hvordan man beregner det i Excel.
Hva er standardavvik?
standardavvik er et mål som angir hvor mye verdiene til datasettet avviker (spres ut) fra gjennomsnittet. For å si det annerledes, standardavviket viser om dataene dine er nær gjennomsnittet eller svinger mye.
Hensikten med standardavviket er å hjelpe deg med å forstå om gjennomsnittet virkelig returnerer en "typisk" data. Jo nærmere standardavviket er null, jo lavere er datavariabiliteten og jo mer pålitelig er gjennomsnittet. Standardavviket lik 0 indikerer at hver verdi i datasettet er nøyaktig lik gjennomsnittet. Jo høyere standardavvik, jo mer variasjon er det i dataene og jo mindre nøyaktig er gjennomsnittet.
For å få en bedre ide om hvordan dette fungerer, vennligst ta en titt på følgende data:
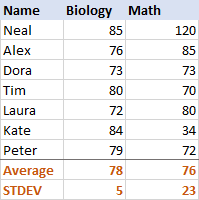
For biologi, standardavviketavvik for et utvalg og populasjon
Avhengig av arten av dataene dine, bruk en av følgende formler:
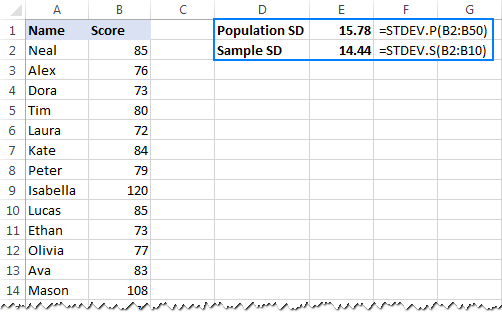
- For å beregne standardavvik basert på hele populasjonen , dvs. hele listen over verdier (B2:B50 i dette eksemplet), bruk STDEV.P-funksjonen:
=STDEV.P(B2:B50) - For å finne standardavvik basert på en prøve som utgjør en del, eller undergruppe, av populasjonen (B2:B10 i dette eksemplet), bruk STDEV.S-funksjonen:
=STDEV.S(B2:B10)
Som du kan se i skjermbilde nedenfor returnerer formlene litt forskjellige tall (jo mindre et utvalg, desto større forskjell):
I Excel 2007 og lavere vil du bruke funksjonene STDEVP og STDEV i stedet:
- For å få populasjonsstandardavvik:
=STDEVP(B2:B50) - For å beregne prøvestandardavvik:
=STDEV(B2:B10)
Beregne standardavvik for tekstrepresentasjoner av tall
Når vi diskuterer ulike funksjoner for å beregne standardavvik i Excel, nevnte vi noen ganger "tekst r representasjoner av tall", og du kan være nysgjerrig på å vite hva det faktisk betyr.
I denne sammenhengen er "tekstrepresentasjoner av tall" ganske enkelt tall formatert som tekst. Hvordan kan slike tall vises i arbeidsarkene dine? Oftest eksporteres de fra eksterne kilder. Eller, returnert av såkalte tekstfunksjoner som er designet for å manipulere tekststrenger, f.eks. TEKST, MIDTT, HØYRE, VENSTRE,osv. Noen av disse funksjonene kan også fungere med tall, men utdataene deres er alltid tekst, selv om det ser mye ut som et tall.
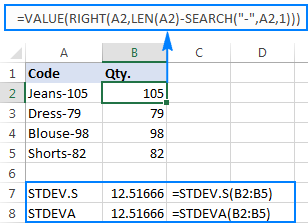
For å illustrere poenget bedre, bør du vurdere følgende eksempel. Anta at du har en kolonne med produktkoder som "Jeans-105" der sifrene etter en bindestrek angir kvantiteten. Målet ditt er å trekke ut mengden av hver vare, og deretter finne standardavviket for de utpakkede tallene.
Å trekke antallet til en annen kolonne er ikke noe problem:
=RIGHT(A2,LEN(A2)-SEARCH("-",A2,1))
Problemet er at bruk av en Excel-standardavviksformel på de ekstraherte tallene returnerer enten #DIV/0! eller 0 som vist i skjermbildet nedenfor:
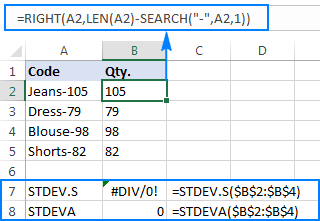
Hvorfor så rare resultater? Som nevnt ovenfor er utdataene til RIGHT-funksjonen alltid en tekststreng. Men verken STDEV.S eller STDEVA kan håndtere tall formatert som tekst i referanser (førstnevnte ignorerer dem ganske enkelt mens sistnevnte teller som null). For å få standardavviket til slike "tekstnumre", må du oppgi dem direkte til listen over argumenter, noe som kan gjøres ved å bygge inn alle HØYRE funksjoner i STDEV.S- eller STDEVA-formelen:
=STDEV.S(RIGHT(A2,LEN(A2)-SEARCH("-",A2,1)), RIGHT(A3,LEN(A3)-SEARCH("-",A3,1)), RIGHT(A4,LEN(A4)-SEARCH("-",A4,1)), RIGHT(A5,LEN(A5)-SEARCH("-",A5,1)))
=STDEVA(RIGHT(A2,LEN(A2)-SEARCH("-",A2,1)), RIGHT(A3,LEN(A3)-SEARCH("-",A3,1)), RIGHT(A4,LEN(A4)-SEARCH("-",A4,1)), RIGHT(A5,LEN(A5)-SEARCH("-",A5,1)))
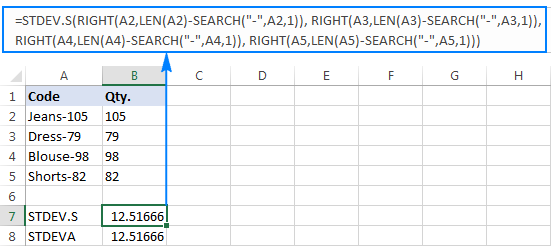
Formlene er litt tungvinte, men det kan være en fungerende løsning for et lite utvalg. For en større, for ikke å snakke om hele befolkningen, er det definitivt ikke et alternativ. I dette tilfellet ville en mer elegant løsning være å haVERDI-funksjonen konverterer "teksttall" til tall som enhver standardavviksformel kan forstå (vær oppmerksom på de høyrejusterte tallene i skjermbildet nedenfor i motsetning til de venstrejusterte tekststrengene på skjermbildet ovenfor):
Hvordan beregne standardfeil for gjennomsnitt i Excel
I statistikk er det enda et mål for å estimere variabiliteten i data - standardfeil for gjennomsnitt , som noen ganger er forkortet (men feil) til bare "standardfeil". Standardavviket og standardfeilen til gjennomsnittet er to nært beslektede konsepter, men ikke det samme.
Mens standardavviket måler variabiliteten til et datasett fra gjennomsnittet, er standardfeilen til gjennomsnittet (SEM) estimerer hvor langt utvalgets gjennomsnitt sannsynligvis vil være fra det sanne populasjonsgjennomsnittet. Sagt på en annen måte - hvis du tok flere prøver fra samme populasjon, ville standardfeilen til gjennomsnittet vise spredningen mellom disse prøvemidlene. Fordi vi vanligvis beregner bare ett gjennomsnitt for et sett med data, ikke flere gjennomsnitt, blir standardfeilen til gjennomsnittet estimert i stedet for målt.
I matematikk beregnes standardfeilen for gjennomsnittet med denne formelen:
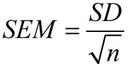
Hvor SD er standardavviket, og n er prøvestørrelsen (antall verdier i prøven).
I Excel-regnearkene dine kan du bruke COUNT-funksjonen for å få talletav verdier i en prøve, SQRT for å ta kvadratroten av det tallet, og STDEV.S for å beregne standardavviket for en prøve.
Sett alt dette sammen, får du standardfeilen til gjennomsnittsformelen i Excel. :
STDEV.S( område )/SQRT(COUNT( område ))Forutsatt at eksempeldataene er i B2:B10, vil SEM-formelen vår se ut som følger :
=STDEV.S(B2:B10)/SQRT(COUNT(B2:B10))
Og resultatet kan være likt dette:

Hvordan legge til standardavvikslinjer i Excel
For visuelt å vise en margin av standardavviket, kan du legge til standardavvikslinjer i Excel-diagrammet. Slik gjør du det:
- Lag en graf på vanlig måte ( Sett inn -kategorien > Diagram -gruppen).
- Klikk hvor som helst på grafen for å velge den, og klikk deretter Kartelementer -knappen.
- Klikk på pilen ved siden av Feillinjer , og velg Standardavvik .
Dette vil sette inn de samme standardavvikslinjene for alle datapunkter.

Slik gjør man standardavvik i Excel. Jeg håper du vil finne denne informasjonen nyttig. Uansett, jeg takker for at du leser og håper å se deg på bloggen vår neste uke.
er 5 (avrundet til et heltall), som forteller oss at flertallet av poengsummene ikke er mer enn 5 poeng unna gjennomsnittet. Er det bra? Vel, ja, det indikerer at biologiskårene til elevene er ganske konsistente.For matematikk er standardavviket 23. Det viser at det er en enorm spredning (spredning) i skårene, noe som betyr at noen studenter presterte mye bedre og/eller noen langt dårligere enn gjennomsnittet.
I praksis blir standardavviket ofte brukt av forretningsanalytikere som et mål på investeringsrisiko – jo høyere standardavvik, jo høyere volatilitet av avkastningen.
Utvalgsstandardavvik vs. populasjonsstandardavvik
I forhold til standardavvik kan du ofte høre begrepene "utvalg" og "populasjon", som refererer til fullstendigheten av dataene du jobber med. Hovedforskjellen er som følger:
- Befolkning inkluderer alle elementene fra et datasett.
- Sample er en delmengde av data som inkluderer ett eller flere elementer fra populasjonen.
Forskere og analytikere opererer på standardavviket til et utvalg og en populasjon i ulike situasjoner. For eksempel, når en lærer oppsummerer eksamensresultatene til en klasse med elever, vil en lærer bruke standardavviket for populasjonen. Statistikere som beregner den nasjonale SAT-gjennomsnittsskåren vil bruke et utvalg standardavvik fordide presenteres kun med data fra et utvalg, ikke fra hele populasjonen.
Forstå standardavviksformelen
Grunnen til at dataene er viktige er fordi populasjonens standardavvik og utvalg standardavvik beregnes med litt forskjellige formler:
Eksempel på standardavvik | Befolkningsstandardavvik |
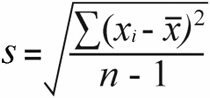 | 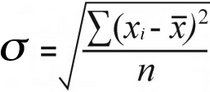 |
Hvor:
- x i er individuelle verdier i settet med data
- x er gjennomsnittet av alle x verdier
- n er det totale antallet x verdier i datasettet
Har du problemer med å forstå formlene? Å dele dem ned i enkle trinn kan hjelpe. Men først, la oss ha noen eksempeldata å jobbe med:

1. Regn ut gjennomsnittet (gjennomsnitt)
Først finner du gjennomsnittet av alle verdiene i datasettet ( x i formlene ovenfor). Når du regner for hånd, legger du sammen tallene og deler deretter summen på antallet av disse tallene, slik:
(1+2+4+5+6+8+9)/7=5
For å finne gjennomsnitt i Excel, bruk AVERAGE-funksjonen, f.eks. =GJENNOMSNITT(A2:G2)
2. For hvert tall, trekk gjennomsnittet og kvadrat resultatet
Dette er delen av standardavviksformelen som sier: ( x i - x )2
For å visualisere hva som faktisk skjer, vennligst ta en titt påfølgende bilder.
I dette eksempelet er gjennomsnittet 5, så vi beregner forskjellen mellom hvert datapunkt og 5.
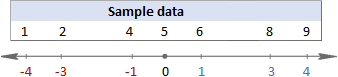
Deretter kvadrerer du forskjellene, gjør dem alle til positive tall:
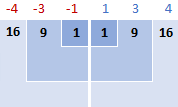
3. Legg sammen kvadratiske forskjeller
For å si «oppsummere ting» i matematikk bruker du sigma Σ. Så det vi gjør nå er å legge sammen de kvadratiske forskjellene for å fullføre denne delen av formelen: Σ( x i - x )2
16 + 9 + 1 + 1 + 9 + 16 = 52
4. Del de totale kvadrerte forskjellene med antall verdier
Så langt har utvalgets standardavvik og populasjonsstandardavviksformlene vært identiske. På dette tidspunktet er de forskjellige.
For utvalgsstandardavviket får du utvalgsvariansen ved å dele de totale kvadrerte forskjellene med prøvestørrelsen minus 1:
52 / (7-1) = 8,67
For populasjonsstandardavviket finner du middelverdien av kvadrerte forskjeller ved å dele totalen kvadreres forskjeller etter antall:
52 / 7 = 7,43
Hvorfor denne forskjellen i formlene? Fordi i utvalgets standardavviksformel må du korrigere skjevheten i estimeringen av et utvalgsgjennomsnitt i stedet for det sanne populasjonsgjennomsnittet. Og dette gjør du ved å bruke n - 1 i stedet for n , som kalles Bessels korreksjon.
5. Ta kvadratroten
Til slutt tar du kvadratroten av ovenståendetall, og du vil få standardavviket ditt (i ligningene nedenfor, avrundet til 2 desimaler):
| Eksempel på standardavvik | Befolkningsstandardavvik |
| √ 8,67 = 2,94 | √ 7,43 = 2,73 |
I Microsoft Excel beregnes standardavviket i samme måte, men alle beregningene ovenfor utføres bak scenen. Nøkkelen for deg er å velge en riktig standardavviksfunksjon, som den følgende delen vil gi deg noen ledetråder om.
Hvordan beregne standardavvik i Excel
Samlet sett er det seks forskjellige funksjoner for å finne standardavvik i Excel. Hvilken du skal bruke avhenger først og fremst av arten av dataene du jobber med - om det er hele populasjonen eller et utvalg.
Funksjoner for å beregne prøvestandardavvik i Excel
For å beregne standard avvik basert på en prøve, bruk en av følgende formler (alle er basert på "n-1"-metoden beskrevet ovenfor).
Excel STDEV-funksjon
STDEV(number1,[number2],…) er den eldste Excel-funksjonen funksjon for å estimere standardavvik basert på en prøve, og den er tilgjengelig i alle versjoner av Excel 2003 til 2019.
I Excel 2007 og nyere kan STDEV akseptere opptil 255 argumenter som kan representeres av tall, matriser , navngitte områder eller referanser til celler som inneholder tall. I Excel 2003 kan funksjonen bare akseptere opptil30 argumenter.
Logiske verdier og tekstrepresentasjoner av tall som er oppgitt direkte i listen over argumenter, telles. I matriser og referanser telles kun tall; tomme celler, logiske verdier av TRUE og FALSE, tekst- og feilverdier ignoreres.
Merk. Excel STDEV er en utdatert funksjon, som bare beholdes i de nyere versjonene av Excel for bakoverkompatibilitet. Microsoft gir imidlertid ingen løfter angående fremtidige versjoner. Så i Excel 2010 og nyere anbefales det å bruke STDEV.S i stedet for STDEV.
Excel STDEV.S-funksjonen
STDEV.S(number1,[number2],…) er en forbedret versjon av STDEV, introdusert i Excel 2010.
I likhet med STDEV, beregner STDEV.S-funksjonen prøvestandardavviket for et sett med verdier basert på den klassiske prøvestandardavviksformelen diskutert i forrige avsnitt.
Excel STDEVA-funksjonen
STDEVA(value1, [value2], …) er en annen funksjon for å beregne standardavvik for en prøve i Excel. Den skiller seg fra de to ovennevnte bare i måten den håndterer logiske verdier og tekstverdier på:
- Alle logiske verdier telles, enten de er inneholdt i matriser eller referanser, eller skrevet direkte inn i listen over argumenter (TRUE evalueres som 1, FALSE evalueres som 0).
- Tekstverdier i matriser eller referanseargumenter telles som 0, inkludert tomme strenger (""), tekst representasjoner av tall og annen tekst. Tekstrepresentasjoner avtall som er oppgitt direkte i listen over argumenter, telles som tallene de representerer (her er et formeleksempel).
- Tomme celler ignoreres.
Merk. For at en eksempelformel for standardavvik skal fungere riktig, må de oppgitte argumentene inneholde minst to numeriske verdier, ellers må #DIV/0! feil returneres.
Funksjoner for å beregne populasjonsstandardavvik i Excel
Hvis du har med hele populasjonen å gjøre, bruk en av følgende funksjoner for å gjøre standardavvik i Excel. Disse funksjonene er basert på "n"-metoden.
Excel STDEVP-funksjon
STDEVP(number1,[number2],…) er den gamle Excel-funksjonen for å finne standardavvik for en populasjon.
I de nye versjonene av Excel 2010, 2013, 2016 og 2019, er den erstattet med den forbedrede STDEV.P-funksjonen, men beholdes fortsatt for bakoverkompatibilitet.
Excel STDEV.P-funksjonen
STDEV.P(number1,[number2],…) er den moderne versjon av STDEVP-funksjonen som gir en forbedret nøyaktighet. Den er tilgjengelig i Excel 2010 og senere versjoner.
Akkurat som standardavvikseksempler, innenfor matriser eller referanseargumenter, teller STDEVP- og STDEV.P-funksjonene kun tall. I listen over argumenter teller de også logiske verdier og tekstrepresentasjoner av tall.
Excel STDEVPA-funksjon
STDEVPA(value1, [value2], …) beregner standardavviket for en populasjon, inkludert tekst og logiske verdier. Med hensyn til ikke-numeriskeverdier, fungerer STDEVPA akkurat som STDEVA-funksjonen gjør.
Merk. Uansett hvilken Excel-standardavviksformel du bruker, vil den returnere en feil hvis ett eller flere argumenter inneholder en feilverdi returnert av en annen funksjon eller tekst som ikke kan tolkes som et tall.
Hvilken Excel-standardavviksfunksjon skal brukes?
En rekke standardavviksfunksjoner i Excel kan definitivt forårsake rot, spesielt for uerfarne brukere. For å velge riktig standardavviksformel for en bestemt oppgave, svarer du bare på følgende 3 spørsmål:
- Regner du standardavviket for et utvalg eller en populasjon?
- Hvilken Excel-versjon bruker du bruk?
- Inneholder datasettet ditt bare tall eller logiske verdier og tekst også?
For å beregne standardavvik basert på et numerisk utvalg , bruk STDEV.S-funksjon i Excel 2010 og nyere; STDEV i Excel 2007 og tidligere.
For å finne standardavvik for en populasjon , bruk STDEV.P-funksjonen i Excel 2010 og nyere; STDEVP i Excel 2007 og tidligere.
Hvis du vil at logiske - eller tekst -verdier skal inkluderes i beregningen, bruk enten STDEVA (sample standardavvik) eller STDEVPA ( populasjonsstandardavvik). Selv om jeg ikke kan komme på noe scenario der en av funksjonene kan være nyttige alene, kan de være nyttige i større formler, der ett eller flere argumenter returneres avandre funksjoner som logiske verdier eller tekstrepresentasjoner av tall.
For å hjelpe deg med å avgjøre hvilken av Excel-standardavviksfunksjonene som passer best for dine behov, vennligst se følgende tabell som oppsummerer informasjonen du allerede har lært.
| STDEV | STDEV.S | STDEV | STDEV.P | STDEVA | STDEVPA | |
| Excel-versjon | 2003 - 2019 | 2010 - 2019 | 2003 - 2019 | 2010 - 2019 | 2003 - 2019 | 2003 - 2019 |
| Eksempel | ✓ | ✓ | ✓ | |||
| Befolkning | ✓ | ✓ | ✓ | |||
| Logiske verdier i matriser eller referanser | Ignorert | Evaluert (TRUE=1, FALSE=0) | ||||
| Tekst i matriser eller referanser | Ignorert | Evaluert som null | ||||
| Logiske verdier og "tekstnumre" i listen over argumenter | Evaluert (TRUE) =1, FALSE=0) | |||||
| Tomme celler | <3 4>Ignorert||||||
Eksempler på Excel-standardavviksformel
Når du har valgt funksjonen som tilsvarer datatypen din, skal det ikke være noen problemer med å skrive formel - syntaksen er så enkel og gjennomsiktig at den ikke gir rom for feil :) De følgende eksemplene viser et par Excel-standardavviksformler i aksjon.
Beregner standard.
