
Innehållsförteckning
I handledningen förklaras vad standardavvikelsen och medelvärdesfelet innebär och vilken formel som är bäst att använda för att beräkna standardavvikelsen i Excel.
I deskriptiv statistik är det aritmetiska medelvärdet (även kallat genomsnittet) och standardavvikelsen två närbesläktade begrepp. Men medan det förstnämnda begreppet är välkänt av de flesta, är det sistnämnda begreppet begripligt för få. Syftet med den här handledningen är att belysa vad standardavvikelsen egentligen är och hur man beräknar den i Excel.
Vad är standardavvikelse?
standardavvikelse är ett mått som anger hur mycket värdena i en uppsättning data avviker (sprider sig) från medelvärdet. Med andra ord visar standardavvikelsen om dina data ligger nära medelvärdet eller om de fluktuerar mycket.
Syftet med standardavvikelsen är att hjälpa dig att förstå om medelvärdet verkligen ger en "typisk" data. Ju närmare noll standardavvikelsen ligger, desto mindre är variationen i data och desto mer tillförlitlig är medelvärdet. En standardavvikelse som är lika med 0 innebär att varje värde i datasetet är exakt lika med medelvärdet. Ju högre standardavvikelsen är, desto mer variation finns det i data.data och ju mindre exakt medelvärdet är.
För att få en bättre uppfattning om hur detta fungerar kan du ta en titt på följande data:
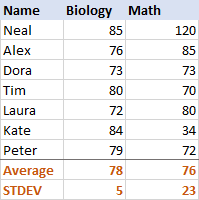
För biologi är standardavvikelsen 5 (avrundat till ett heltal), vilket innebär att majoriteten av resultaten inte avviker mer än 5 poäng från medelvärdet. Är det bra? Ja, det visar att elevernas resultat i biologi är ganska jämna.
För matematik är standardavvikelsen 23. Det visar att det finns en stor spridning i resultaten, vilket innebär att vissa elever presterade mycket bättre och/eller andra mycket sämre än genomsnittet.
I praktiken används standardavvikelsen ofta av affärsanalytiker som ett mått på investeringsrisk - ju högre standardavvikelse, desto högre volatilitet i avkastningen.
Provets standardavvikelse jämfört med populationens standardavvikelse
När det gäller standardavvikelse kan du ofta höra begreppen "urval" och "population", som syftar på fullständigheten hos de data du arbetar med. Den viktigaste skillnaden är följande:
- Befolkning innehåller alla element från en datamängd.
- Exempel är en delmängd av data som innehåller ett eller flera element från populationen.
Forskare och analytiker använder sig av standardavvikelsen för ett urval och en population i olika situationer. När en lärare till exempel sammanfattar en klass av elevers provresultat använder han eller hon populationens standardavvikelse. Statistiker som beräknar det nationella genomsnittsresultatet för SAT skulle använda sig av urvalets standardavvikelse eftersom de endast har uppgifter från ett urval, inte frånfrån hela befolkningen.
Förstå formeln för standardavvikelse
Anledningen till att det spelar roll vilken typ av data som används är att populationens standardavvikelse och urvalets standardavvikelse beräknas med lite olika formler:
Standardavvikelse för provet | Populationens standardavvikelse |
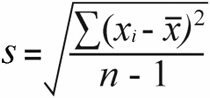 | 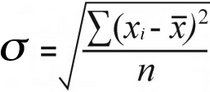 |
Var:
- x i är enskilda värden i datamängden
- x är medelvärdet av alla x värden
- n är det totala antalet x värden i datamängden
Om du har svårt att förstå formlerna kan det hjälpa att dela upp dem i enkla steg. Men först ska vi ha några exempeluppgifter att arbeta med:

1. Beräkna medelvärdet (genomsnittet).
Först hittar du medelvärdet av alla värden i datamängden ( x När du räknar för hand adderar du siffrorna och dividerar sedan summan med antalet av dessa siffror, på följande sätt:
(1+2+4+5+6+8+9)/7=5
För att hitta medelvärdet i Excel använder du funktionen AVERAGE, t.ex. =AVERAGE(A2:G2).
2. För varje tal, subtrahera medelvärdet och kvadrera resultatet.
Detta är den del av formeln för standardavvikelse som lyder: ( x i - x )2
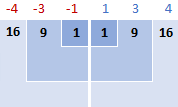
För att visualisera vad som faktiskt händer kan du titta på följande bilder.
I det här exemplet är medelvärdet 5, så vi beräknar skillnaden mellan varje datapunkt och 5.
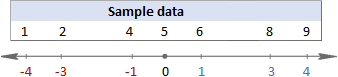
Sedan kvadrerar du skillnaderna och omvandlar dem alla till positiva tal:
3. Addera kvadrerade skillnader.
För att säga "summera saker och ting" i matematik använder man sigma Σ. Så vad vi gör nu är att addera de kvadrerade skillnaderna för att komplettera denna del av formeln: Σ( x i - x )2
16 + 9 + 1 + 1 + 9 + 16 = 52
4. Dividera de totala kvadratiska skillnaderna med antalet värden.
Hittills har formlerna för urvalets standardavvikelse och populationens standardavvikelse varit identiska, men nu är de olika.
För standardavvikelse för provet , får du varians i stickprovet. genom att dividera de totala skillnaderna i kvadrat med urvalsstorleken minus 1:
52 / (7-1) = 8.67
För populationens standardavvikelse , hittar du den medelvärde av kvadrerade skillnader genom att dividera de totala skillnaderna i kvadrat med deras antal:
52 / 7 = 7.43
Varför denna skillnad i formlerna? För att du i formeln för standardavvikelse för stickprov måste korrigera bias i uppskattningen av ett stickprovs medelvärde istället för det sanna populationsmedelvärdet. Och det gör du genom att använda n - 1 i stället för n , vilket kallas Bessels korrigering.
5. Ta kvadratroten
Slutligen tar du kvadratroten av ovanstående tal och får din standardavvikelse (i ekvationerna nedan avrundat till två decimaler):
| Standardavvikelse för provet | Populationens standardavvikelse |
| √ 8.67 = 2.94 | √ 7.43 = 2.73 |
I Microsoft Excel beräknas standardavvikelsen på samma sätt, men alla ovanstående beräkningar utförs bakom scenen. Det viktigaste för dig är att välja en lämplig standardavvikelsefunktion, vilket följande avsnitt kommer att ge dig några ledtrådar om.
Hur man beräknar standardavvikelse i Excel
Det finns totalt sex olika funktioner för att hitta standardavvikelsen i Excel. Vilken funktion du ska använda beror främst på vilken typ av data du arbetar med - om det är hela populationen eller ett urval.
Funktioner för att beräkna standardavvikelse i Excel
För att beräkna standardavvikelsen baserat på ett urval använder du en av följande formler (alla är baserade på "n-1"-metoden som beskrivs ovan).
Excel STDEV-funktionen
STDEV(nummer1,[nummer2],...) är den äldsta Excel-funktionen för att beräkna standardavvikelsen baserat på ett urval, och den finns tillgänglig i alla versioner av Excel 2003 till 2019.
I Excel 2007 och senare kan STDEV ta emot upp till 255 argument som kan representeras av siffror, matriser, namngivna intervall eller referenser till celler som innehåller siffror. I Excel 2003 kan funktionen bara ta emot upp till 30 argument.
Logiska värden och textrepresentationer av tal som anges direkt i argumentlistan räknas. I matriser och referenser räknas endast tal; tomma celler, logiska värden av TRUE och FALSE, text- och felvärden ignoreras.
Obs. Excel STDEV är en föråldrad funktion, som behålls i de nyare versionerna av Excel endast för att vara bakåtkompatibel. Microsoft lovar dock inget om framtida versioner. I Excel 2010 och senare rekommenderas att du använder STDEV.S i stället för STDEV.
Excel-funktionen STDEV.S
STDEV.S(nummer1,[nummer2],...) är en förbättrad version av STDEV som introducerades i Excel 2010.
Precis som STDEV beräknar funktionen STDEV.S urvalets standardavvikelse för en uppsättning värden baserat på den klassiska formeln för urvalets standardavvikelse som diskuterades i föregående avsnitt.
Excel STDEVA-funktionen
STDEVA(värde1, [värde2], ...) är en annan funktion för att beräkna standardavvikelsen för ett urval i Excel. Den skiljer sig från de två ovan nämnda funktionerna endast i fråga om hur den hanterar logiska värden och textvärden:
- Alla logiska värden räknas, oavsett om de ingår i matriser eller referenser eller om de skrivs in direkt i listan med argument (TRUE värderas som 1, FALSE värderas som 0).
- Textvärden inom arrayer eller referensargument räknas som 0, inklusive tomma strängar (""), textrepresentationer av tal och all annan text. Textrepresentationer av tal som anges direkt i listan med argument räknas som de tal de representerar (här är ett exempel på en formel).
- Tomma celler ignoreras.
Observera: För att en formel för standardavvikelse ska fungera korrekt måste de medföljande argumenten innehålla minst två numeriska värden, annars returneras felet #DIV/0!
Funktioner för att beräkna populationens standardavvikelse i Excel
Om du har att göra med hela populationen kan du använda någon av följande funktioner för att beräkna standardavvikelsen i Excel. Dessa funktioner bygger på n-metoden.
Excel STDEVP-funktionen
STDEVP(nummer1,[nummer2],...) är den gamla Excel-funktionen för att hitta standardavvikelsen för en population.
I de nya versionerna av Excel 2010, 2013, 2016 och 2019 har den ersatts av den förbättrade STDEV.P-funktionen, men den behålls fortfarande för bakåtkompatibilitet.
Excel-funktionen STDEV.P
STDEV.P(nummer1,[nummer2],...) är en modern version av STDEVP-funktionen som ger en förbättrad noggrannhet. Den finns i Excel 2010 och senare versioner.
Precis som deras motsvarigheter till standardavvikelse för provtagning, räknar funktionerna STDEVP och STDEV.P endast tal i matriser eller referensargument. I listan över argument räknar de även logiska värden och textrepresentationer av tal.
Excel STDEVPA-funktionen
STDEVPA(värde1, [värde2], ...) beräknar standardavvikelsen för en population, inklusive text och logiska värden. När det gäller icke-numeriska värden fungerar STDEVPA precis som STDEVA-funktionen.
Observera: Oavsett vilken Excel-formel för standardavvikelse du använder, returnerar den ett fel om ett eller flera argument innehåller ett felvärde som returnerats av en annan funktion eller text som inte kan tolkas som ett tal.
Vilken Excel-funktion för standardavvikelse ska jag använda?
En mängd olika standardavvikelsefunktioner i Excel kan definitivt ställa till det, särskilt för oerfarna användare. För att välja rätt standardavvikelseformel för en viss uppgift är det bara att svara på följande tre frågor:
- Beräknar du standardavvikelsen för ett urval eller en population?
- Vilken Excel-version använder du?
- Innehåller din datamängd endast siffror eller logiska värden och även text?
Om du vill beräkna standardavvikelse baserat på en numerisk exempel Använd funktionen STDEV.S i Excel 2010 och senare; STDEV i Excel 2007 och tidigare.
För att hitta standardavvikelsen för en Befolkning Använd funktionen STDEV.P i Excel 2010 och senare; STDEVP i Excel 2007 och tidigare.
Om du vill logisk eller . text värden som ska ingå i beräkningen, använd antingen STDEVA (standardavvikelse för stickprov) eller STDEVPA (standardavvikelse för population). Jag kan inte komma på något scenario där någon av funktionerna kan vara användbara på egen hand, men de kan vara användbara i större formler där ett eller flera argument returneras av andra funktioner som logiska värden eller textrepresentationer av tal.
För att hjälpa dig att avgöra vilken av Excels standardavvikelsefunktioner som är bäst lämpad för dina behov kan du läsa följande tabell som sammanfattar den information du redan har lärt dig.
| STDEV | STDEV.S | STDEVP | STDEV.P | STDEVA | STDEVPA | |
| Excel-version | 2003 - 2019 | 2010 - 2019 | 2003 - 2019 | 2010 - 2019 | 2003 - 2019 | 2003 - 2019 |
| Exempel | ✓ | ✓ | ✓ | |||
| Befolkning | ✓ | ✓ | ✓ | |||
| Logiska värden i matriser eller referenser | Ignorerad | Utvärderad (SANT=1, FALSKT=0) | ||||
| Text i matriser eller referenser | Ignorerad | Utvärderas som noll | ||||
| Logiska värden och "text-nummer" i listan över argument | Utvärderad (SANT=1, FALSKT=0) | |||||
| Tomma celler | Ignorerad | |||||
Exempel på Excel-formeln för standardavvikelse
När du väl har valt den funktion som motsvarar din datatyp bör det inte vara några svårigheter att skriva formeln - syntaxen är så enkel och transparent att den inte lämnar något utrymme för fel :) Följande exempel visar ett par Excel-formler för standardavvikelse i praktiken.
Beräkning av standardavvikelsen för ett urval och en population
Beroende på hur dina uppgifter ser ut kan du använda en av följande formler:
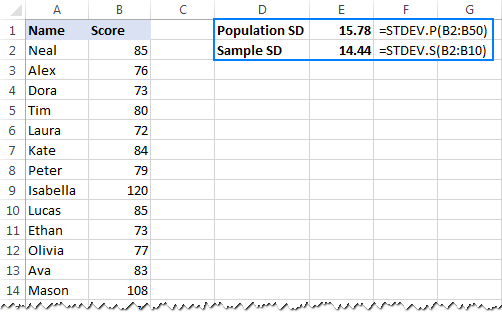
- För att beräkna standardavvikelsen baserat på hela Befolkning , dvs. hela listan med värden (B2:B50 i det här exemplet), använder du funktionen STDEV.P:
=STDEV.P(B2:B50) - Att hitta standardavvikelsen utifrån en exempel som utgör en del av populationen (B2:B10 i detta exempel), använd funktionen STDEV.S:
=STDEV.S(B2:B10)
Som du kan se i skärmdumpen nedan ger formlerna något olika siffror (ju mindre urvalet är, desto större är skillnaden):
I Excel 2007 och senare använder du istället funktionerna STDEVP och STDEV:
- För att få fram populationens standardavvikelse:
=STDEVP(B2:B50) - För att beräkna urvalets standardavvikelse:
=STDEV(B2:B10)
Beräkning av standardavvikelse för textrepresentationer av tal.
När vi diskuterade olika funktioner för att beräkna standardavvikelse i Excel nämnde vi ibland "textrepresentationer av tal" och du kanske är nyfiken på vad det egentligen betyder.
I det här sammanhanget är "textrepresentationer av tal" helt enkelt tal formaterade som text. Hur kan sådana tal dyka upp i dina kalkylblad? Oftast exporteras de från externa källor eller returneras av så kallade textfunktioner som är utformade för att manipulera textsträngar, t.ex. TEXT, MID, RIGHT, LEFT, etc. Vissa av dessa funktioner kan också arbeta med tal, men deras resultat är alltid text, även omom det ser ut som ett nummer.
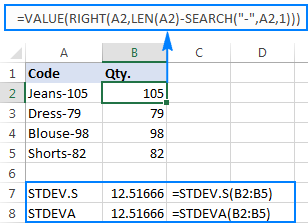
För att bättre illustrera detta kan du ta följande exempel: Anta att du har en kolumn med produktkoder som "Jeans-105" där siffrorna efter bindestrecket anger kvantiteten. Ditt mål är att ta fram kvantiteten för varje artikel och sedan hitta standardavvikelsen för de framtagna siffrorna.
Det är inget problem att flytta kvantiteten till en annan kolumn:
=RIGHT(A2,LEN(A2)-SEARCH("-",A2,1))
Problemet är att om man använder en Excel-formel för standardavvikelse på de extraherade siffrorna får man antingen #DIV/0! eller 0, vilket visas i skärmdumpen nedan:
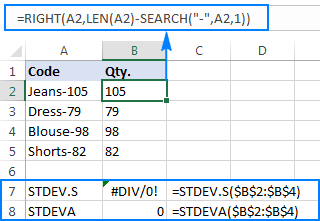
Varför så konstiga resultat? Som nämnts ovan är resultatet av RIGHT-funktionen alltid en textsträng. Men varken STDEV.S eller STDEVA kan hantera tal som är formaterade som text i referenser (den förstnämnda ignorerar dem helt enkelt medan den sistnämnda räknar dem som nollor). För att få fram standardavvikelsen för sådana "text-tal" måste du ange dem direkt i listan med argument, vilket kan göras genom att bädda in allaRIGHT-funktioner i din STDEV.S- eller STDEVA-formel:
=STDEV.S(HÖGER(A2,LEN(A2)-SEARCH("-",A2,1)), HÖGER(A3,LEN(A3)-SEARCH("-",A3,1)), HÖGER(A4,LEN(A4)-SEARCH("-",A4,1)), HÖGER(A5,LEN(A5)-SEARCH("-",A5,1)))
=STDEVA(RIGHT(A2,LEN(A2)-SEARCH("-",A2,1)), RIGHT(A3,LEN(A3)-SEARCH("-",A3,1)), RIGHT(A4,LEN(A4)-SEARCH("-",A4,1)), RIGHT(A5,LEN(A5)-SEARCH("-",A5,1)))
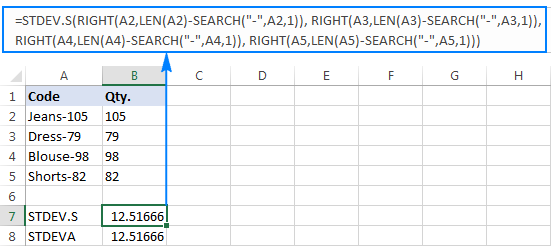
Formlerna är lite besvärliga, men det kan vara en fungerande lösning för ett litet urval. För ett större urval, för att inte tala om hela populationen, är det definitivt inte ett alternativ. I det här fallet skulle en mer elegant lösning vara att låta VALUE-funktionen konvertera "textsiffror" till siffror som alla standardavvikelseformler kan förstå (lägg märke till de högerinriktade siffrorna i skärmdumpen).nedan i motsats till de vänsterjusterade textsträngarna i skärmdumpen ovan):
Hur man beräknar standardfelet för medelvärdet i Excel
Inom statistiken finns det ytterligare ett mått för att uppskatta variabiliteten i data - standardfel för medelvärdet Standardavvikelsen och medelvärdets standardfel är två närbesläktade begrepp, men inte samma sak.
Medan standardavvikelsen mäter variabiliteten i en datamängd från medelvärdet, uppskattar medelvärdets standardavvikelse (SEM) hur långt det är troligt att provets medelvärde ligger från det verkliga populationsmedlet. Om man säger det på ett annat sätt - om man tar flera prover från samma population, skulle medelvärdets standardavvikelse visa spridningen mellan dessa provmedelvärden. Eftersom vi vanligtvis beräknar bara enmedelvärde för en uppsättning data, inte flera medelvärden, och medelvärdets standardfel uppskattas snarare än mäts.
Inom matematiken beräknas medelvärdets standardavvikelse med denna formel:
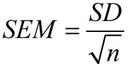
Var SD är standardavvikelsen, och n är urvalets storlek (antalet värden i urvalet).
I dina Excel-arbetsblad kan du använda funktionen COUNT för att få fram antalet värden i ett prov, SQRT för att ta en kvadratrot av detta antal och STDEV.S för att beräkna standardavvikelsen för ett prov.
Genom att sätta ihop allt detta får du formeln för medelvärdesfelet i Excel:
STDEV.S( sortiment )/SQRT(COUNT( sortiment ))Om vi antar att provdata finns i B2:B10, skulle vår SEM-formel se ut på följande sätt:
=STDEV.S(B2:B10)/SQRT(COUNT(B2:B10))
Resultatet kan se ut ungefär så här:

Hur man lägger till standardavvikelsebalkar i Excel
För att visuellt visa en marginal för standardavvikelsen kan du lägga till staplar för standardavvikelse i ditt Excel-diagram. Så här gör du:
- Skapa en graf på vanligt sätt ( Infoga flik> Diagram grupp).
- Klicka någonstans på grafen för att markera den och klicka sedan på Diagramelement knapp.
- Klicka på pilen bredvid Felmarginaler , och välj Standardavvikelse .
Detta kommer att ge samma standardavvikelse för alla datapunkter.

Så här gör man standardavvikelse i Excel. Jag hoppas att du kommer att tycka att den här informationen är användbar. Jag tackar i alla fall för att du läste och hoppas att vi ses på vår blogg nästa vecka.
