
فهرست مطالب
این آموزش ماهیت انحراف استاندارد و خطای استاندارد میانگین را توضیح می دهد و همچنین اینکه کدام فرمول برای محاسبه انحراف معیار در اکسل بهتر است استفاده شود.
در آمار توصیفی ، میانگین حسابی (میانگین نیز نامیده می شود) و انحراف معیار و دو مفهوم نزدیک به هم هستند. اما در حالی که مورد اول توسط اکثر افراد به خوبی درک می شود، دومی توسط تعداد کمی درک می شود. هدف این آموزش روشن کردن انحراف استاندارد در واقع چیست و نحوه محاسبه آن در اکسل است.
انحراف معیار چیست؟
انحراف استاندارد معیاری است که نشان می دهد مقادیر مجموعه داده ها چقدر از میانگین انحراف (گسترش) دارند. به بیان دیگر، انحراف استاندارد نشان می دهد که آیا داده های شما به میانگین نزدیک است یا نوسان زیادی دارد.
هدف از انحراف استاندارد این است که به شما کمک کند بفهمید آیا میانگین واقعاً یک داده "معمولی" را برمی گرداند یا خیر. هر چه انحراف معیار به صفر نزدیکتر باشد، تنوع داده کمتر و میانگین قابل اعتمادتر است. انحراف استاندارد برابر با 0 نشان می دهد که هر مقدار در مجموعه داده دقیقا برابر با میانگین است. هرچه انحراف معیار بالاتر باشد، تنوع دادهها بیشتر است و میانگین دقت کمتری دارد.
برای درک بهتر نحوه عملکرد، لطفاً به دادههای زیر نگاهی بیندازید:
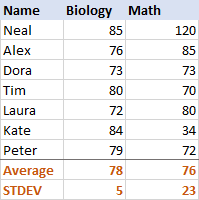
برای زیست شناسی، انحراف معیارانحراف نمونه و جامعه
بسته به ماهیت داده های خود، از یکی از فرمول های زیر استفاده کنید:
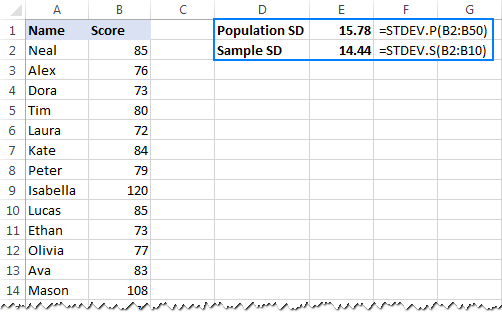
- برای محاسبه انحراف معیار بر اساس کل جمعیت ، یعنی لیست کامل مقادیر (B2:B50 در این مثال)، از تابع STDEV.P استفاده کنید:
=STDEV.P(B2:B50) - برای یافتن انحراف استاندارد بر اساس نمونه که بخشی یا زیرمجموعه ای از جمعیت را تشکیل می دهد (B2:B10 در این مثال)، از تابع STDEV.S استفاده کنید:
=STDEV.S(B2:B10)
همانطور که در قسمت مشاهده می کنید. اسکرین شات زیر، فرمول ها اعداد کمی متفاوت را نشان می دهند (هرچه نمونه کوچکتر باشد، تفاوت بزرگتر است):
در اکسل 2007 و پایین تر، از توابع STDEVP و STDEV استفاده می کنید در عوض:
- برای دریافت انحراف معیار جمعیت:
=STDEVP(B2:B50)همچنین ببینید: IF AND در اکسل: فرمول تودرتو، چند عبارت و موارد دیگر - برای محاسبه انحراف استاندارد نمونه:
=STDEV(B2:B10)
محاسبه انحراف معیار برای نمایش متن اعداد
هنگام بحث در مورد توابع مختلف برای محاسبه انحراف معیار در اکسل، گاهی اوقات به "text r" اشاره می کنیم. نمایش اعداد" و ممکن است کنجکاو باشید که بدانید واقعاً به چه معناست.
در این زمینه، "نمایش متنی اعداد" به سادگی اعدادی هستند که به صورت متن قالب بندی می شوند. چگونه چنین اعدادی می توانند در کاربرگ های شما ظاهر شوند؟ اغلب آنها از منابع خارجی صادر می شوند. یا، توسط توابع به اصطلاح Text که برای دستکاری رشته های متنی طراحی شده اند، بازگردانده می شوند، به عنوان مثال. متن، وسط، راست، چپ،برخی از این توابع می توانند با اعداد نیز کار کنند، اما خروجی آنها همیشه متن است، حتی اگر بسیار شبیه یک عدد باشد.
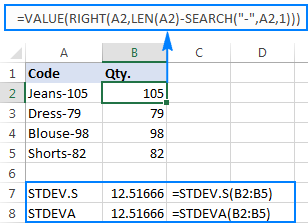
برای توضیح بهتر موضوع، لطفاً به مثال زیر توجه کنید. فرض کنید ستونی از کدهای محصول مانند "Jeans-105" دارید که اعداد بعد از خط فاصله نشان دهنده مقدار است. هدف شما این است که مقدار هر مورد را استخراج کنید و سپس انحراف استاندارد اعداد استخراج شده را بیابید.
کشاندن مقدار به ستون دیگری مشکلی نیست:
=RIGHT(A2,LEN(A2)-SEARCH("-",A2,1))
مشکل این است که استفاده از فرمول انحراف استاندارد اکسل روی اعداد استخراج شده یا #DIV/0 را برمی گرداند! یا 0 مشابه که در تصویر زیر نشان داده شده است:
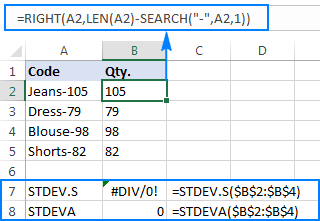
چرا چنین نتایج عجیب و غریبی وجود دارد؟ همانطور که در بالا ذکر شد، خروجی تابع RIGHT همیشه یک رشته متن است. اما نه STDEV.S و نه STDEVA نمی توانند اعداد فرمت شده به عنوان متن در مراجع را کنترل کنند (اولی به سادگی آنها را نادیده می گیرد در حالی که دومی به عنوان صفر محاسبه می شود). برای به دست آوردن انحراف استاندارد چنین "اعداد متنی"، باید آنها را مستقیماً به لیست آرگومان ها وارد کنید، که می تواند با جاسازی همه توابع RIGHT در فرمول STDEV.S یا STDEVA شما انجام شود:
=STDEV.S(RIGHT(A2,LEN(A2)-SEARCH("-",A2,1)), RIGHT(A3,LEN(A3)-SEARCH("-",A3,1)), RIGHT(A4,LEN(A4)-SEARCH("-",A4,1)), RIGHT(A5,LEN(A5)-SEARCH("-",A5,1)))
=STDEVA(RIGHT(A2,LEN(A2)-SEARCH("-",A2,1)), RIGHT(A3,LEN(A3)-SEARCH("-",A3,1)), RIGHT(A4,LEN(A4)-SEARCH("-",A4,1)), RIGHT(A5,LEN(A5)-SEARCH("-",A5,1)))
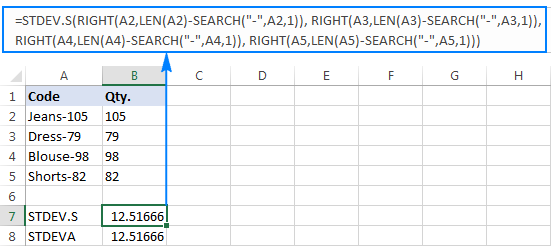
فرمول ها کمی دست و پا گیر هستند، اما ممکن است برای نمونه کوچکی راه حل موثری باشد. برای یک بزرگتر، بدون ذکر کل جمعیت، قطعاً یک گزینه نیست. در این مورد، راه حل ظریف تر، داشتن آن خواهد بودتابع VALUE «اعداد نوشتاری» را به اعدادی تبدیل میکند که هر فرمول انحراف استاندارد میتواند آنها را بفهمد (لطفاً به اعداد راست چینشده در تصویر زیر در مقابل رشتههای متنی تراز چپشده در تصویر بالا توجه کنید):
نحوه محاسبه خطای استاندارد میانگین در اکسل
در آمار، یک معیار دیگر برای تخمین تغییرپذیری داده ها وجود دارد - خطای استاندارد میانگین ، که گاهی اوقات (اگرچه، به اشتباه) به "خطای استاندارد" کوتاه می شود. انحراف استاندارد و خطای استاندارد میانگین دو مفهوم نزدیک به هم هستند، اما یکسان نیستند.
در حالی که انحراف استاندارد تغییرپذیری یک مجموعه داده را از میانگین اندازه گیری می کند، خطای استاندارد میانگین (SEM) تخمین می زند که میانگین نمونه چقدر از میانگین جامعه واقعی فاصله دارد. روش دیگری گفت - اگر چندین نمونه از یک جامعه گرفته باشید، خطای استاندارد میانگین پراکندگی بین میانگینهای نمونه را نشان میدهد. از آنجایی که معمولاً ما فقط یک میانگین را برای مجموعه ای از داده ها محاسبه می کنیم، نه چند میانگین، خطای استاندارد میانگین به جای اندازه گیری تخمین زده می شود.
در ریاضیات، خطای استاندارد میانگین با این فرمول محاسبه می شود:
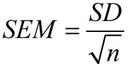
که در آن SD انحراف معیار است، و n اندازه نمونه (تعداد مقادیر در نمونه) است.
در کاربرگ های اکسل خود، می توانید از تابع COUNT برای دریافت عدد استفاده کنیداز مقادیر در یک نمونه، SQRT برای گرفتن یک جذر از آن عدد، و STDEV.S برای محاسبه انحراف استاندارد یک نمونه.
با کنار هم قرار دادن همه اینها، خطای استاندارد فرمول میانگین در اکسل را دریافت می کنید. :
STDEV.S( range )/SQRT(COUNT( range ))با فرض اینکه داده های نمونه در B2:B10 هستند، فرمول SEM ما به صورت زیر است :
=STDEV.S(B2:B10)/SQRT(COUNT(B2:B10))
و نتیجه ممکن است مشابه این باشد:

نحوه اضافه کردن نوارهای انحراف استاندارد در اکسل
برای نمایش بصری حاشیه انحراف استاندارد، می توانید نوارهای انحراف استاندارد را به نمودار اکسل خود اضافه کنید. به این صورت است:
- یک نمودار به روش معمول ایجاد کنید ( درج برگه > Charts گروه).
- روی هر جایی از نمودار را انتخاب کنید، سپس روی دکمه Chart Elements کلیک کنید.
- روی فلش کنار Error Bars کلیک کنید و Standard Deviation را انتخاب کنید.
این نوارهای انحراف استاندارد یکسان را برای همه نقاط داده درج می کند.

این نحوه انجام انحراف استاندارد در اکسل است. امیدوارم این اطلاعات برای شما مفید واقع شود. به هر حال از خواندن شما سپاسگزارم و امیدوارم هفته آینده شما را در وبلاگ خود ببینیم.
5 است (به یک عدد صحیح گرد شده)، که به ما می گوید که اکثر نمرات بیش از 5 امتیاز با میانگین فاصله ندارند. آیا این خوب است؟ خب، بله، این نشان می دهد که نمرات زیست شناسی دانش آموزان کاملاً سازگار است.برای ریاضی، انحراف معیار 23 است. این نشان می دهد که پراکندگی (گسترش) زیادی در نمرات وجود دارد، به این معنی که برخی دانشآموزان عملکرد بسیار بهتری داشتند و/یا برخی از آنها بسیار بدتر از میانگین عمل کردند.
در عمل، انحراف استاندارد اغلب توسط تحلیلگران تجاری بهعنوان معیار ریسک سرمایهگذاری استفاده میشود - هر چه انحراف استاندارد بالاتر باشد، نوسانات بیشتر است. از بازده.
انحراف استاندارد نمونه در مقابل انحراف استاندارد جمعیت
در رابطه با انحراف معیار، ممکن است اغلب اصطلاحات "نمونه" و "جمعیت" را بشنوید که به کامل بودن داده هایی که با آنها کار می کنید تفاوت اصلی به شرح زیر است:
- جمعیت شامل تمام عناصر یک مجموعه داده است.
- Sample زیر مجموعه ای از داده هایی که شامل یک یا چند عنصر از جامعه است.
محققان و تحلیلگران بر روی انحراف معیار یک نمونه و جامعه در موقعیت های مختلف عمل می کنند. به عنوان مثال، هنگام جمع بندی نمرات امتحانات یک کلاس از دانش آموزان، معلم از انحراف معیار جمعیت استفاده می کند. آماردانانی که میانگین نمره ملی SAT را محاسبه می کنند، از انحراف استاندارد نمونه استفاده می کنند زیراآنها فقط با داده های یک نمونه ارائه می شوند، نه از کل جامعه.
درک فرمول انحراف معیار
دلیل ماهیت داده ها این است که انحراف استاندارد جامعه و نمونه انحراف معیار با فرمول های کمی متفاوت محاسبه می شود:
انحراف استاندارد نمونه | انحراف استاندارد جمعیت |
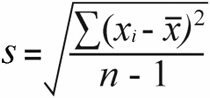 | 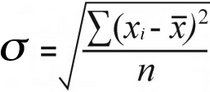 |
کجا:
- x i مقادیر فردی در مجموعه داده ها هستند
- x میانگین همه x<2 است> مقادیر
- n تعداد کل مقادیر x در مجموعه داده است
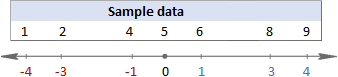
در درک فرمول ها مشکل دارید؟ شکستن آنها به مراحل ساده ممکن است کمک کند. اما ابتدا، اجازه دهید چند داده نمونه برای کار روی آن داشته باشیم:

1. میانگین (میانگین) را محاسبه کنید
ابتدا، میانگین تمام مقادیر موجود در مجموعه داده را پیدا می کنید ( x در فرمول های بالا). هنگام محاسبه با دست، اعداد را جمع می کنید و سپس مجموع را بر تعداد آن اعداد تقسیم می کنید، به این صورت:
(1+2+4+5+6+8+9)/7=5
برای یافتن میانگین در اکسل، از تابع AVERAGE استفاده کنید، به عنوان مثال. =AVERAGE(A2:G2)
2. برای هر عدد، میانگین را کم کنید و نتیجه را مربع کنید
این بخشی از فرمول انحراف معیار است که می گوید: ( x i - x )2
برای تجسم آنچه واقعاً در حال وقوع است، لطفاً نگاهی به آن بیندازیدتصاویر زیر.
در این مثال، میانگین 5 است، بنابراین ما تفاوت بین هر نقطه داده و 5 را محاسبه می کنیم.
سپس، شما مربع می شوید. تفاوت ها، تبدیل همه آنها به اعداد مثبت:
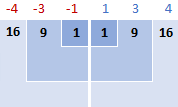
3. مجذور تفاوت ها را جمع کنید
برای گفتن "مجموع چیزها" در ریاضیات، از سیگما Σ استفاده می کنید. بنابراین، کاری که اکنون انجام میدهیم این است که مجذور تفاوتها را برای تکمیل این بخش از فرمول جمع میکنیم: Σ( x i - x)2
16 + 9 + 1 + 1 + 9 + 16 = 52
4. مجذور کل اختلافات را بر تعداد مقادیر تقسیم کنید
تاکنون فرمول انحراف معیار نمونه و انحراف معیار جمعیت یکسان بوده است. در این مرحله، آنها متفاوت هستند.
برای انحراف استاندارد نمونه ، شما واریانس نمونه را با تقسیم مجذور مجذور اختلافات کل بر حجم نمونه منهای 1 بدست می آورید:
52 / (7-1) = 8.67
برای انحراف استاندارد جمعیت ، میانگین تفاوتهای مجذور را با تقسیم کل پیدا میکنید. مجذور تفاوت ها بر اساس تعداد آنها:
52 / 7 = 7.43
چرا این تفاوت در فرمول ها وجود دارد؟ زیرا در فرمول انحراف معیار نمونه، باید به جای میانگین جامعه واقعی، سوگیری را در تخمین میانگین نمونه اصلاح کنید. و شما این کار را با استفاده از n - 1 به جای n انجام می دهید که به آن تصحیح بسل می گویند.
5. جذر را بگیرید
در نهایت جذر موارد بالا را بگیریداعداد، و انحراف معیار خود را دریافت خواهید کرد (در معادلات زیر، گرد شده به 2 رقم اعشار):
| انحراف استاندارد نمونه | انحراف استاندارد جمعیت |
| √ 8.67 = 2.94 | √ 7.43 = 2.73 |
در Microsoft Excel، انحراف استاندارد در به همین ترتیب، اما تمام محاسبات فوق در پشت صحنه انجام می شود. نکته کلیدی برای شما این است که یک تابع انحراف استاندارد مناسب را انتخاب کنید، که در بخش زیر سرنخ هایی در مورد آن به شما ارائه خواهد شد.
نحوه محاسبه انحراف معیار در اکسل
به طور کلی، شش عدد مختلف وجود دارد. توابع برای یافتن انحراف استاندارد در اکسل. اینکه کدام یک از آنها استفاده شود در درجه اول به ماهیت داده هایی که با آنها کار می کنید بستگی دارد - خواه کل جامعه باشد یا یک نمونه.
توابع محاسبه انحراف استاندارد نمونه در Excel
برای محاسبه استاندارد انحراف بر اساس یک نمونه، از یکی از فرمول های زیر استفاده کنید (همه آنها بر اساس روش "n-1" توصیف شده در بالا هستند).
Excel STDEV تابع
STDEV(number1,[number2],…) قدیمی ترین Excel است. تابعی برای تخمین انحراف استاندارد بر اساس یک نمونه است، و در تمام نسخههای اکسل 2003 تا 2019 موجود است.
در اکسل 2007 به بعد، STDEV میتواند حداکثر 255 آرگومان را بپذیرد که میتواند با اعداد، آرایهها نمایش داده شود. ، محدوده های نامگذاری شده یا ارجاع به سلولهای حاوی اعداد. در اکسل 2003، تابع فقط می تواند تا30 آرگومان.
مقادیر منطقی و نمایش متنی اعداد ارائه شده مستقیماً در فهرست آرگومان ها شمارش می شوند. در آرایه ها و مراجع، فقط اعداد شمارش می شوند. سلول های خالی، مقادیر منطقی TRUE و FALSE، متن و مقادیر خطا نادیده گرفته می شوند.
توجه داشته باشید. Excel STDEV یک تابع منسوخ شده است که در نسخه های جدیدتر اکسل فقط برای سازگاری با گذشته نگهداری می شود. با این حال، مایکروسافت هیچ قولی در مورد نسخه های آینده نمی دهد. بنابراین، در اکسل 2010 به بعد، توصیه می شود به جای STDEV از STDEV.S استفاده کنید.
عملکرد Excel STDEV.S
STDEV.S(number1,[number2],…) نسخه بهبود یافته STDEV است که در اکسل 2010 معرفی شده است.
مانند STDEV، تابع STDEV.S انحراف استاندارد نمونه مجموعه ای از مقادیر را بر اساس فرمول نمونه کلاسیک انحراف استاندارد که در بخش قبل مورد بحث قرار گرفت محاسبه می کند.
عملکرد اکسل STDEVA
STDEVA(value1, [value2], …) تابع دیگری برای محاسبه انحراف استاندارد یک نمونه در اکسل است. تفاوت آن با دو مورد بالا فقط در نحوه مدیریت مقادیر منطقی و متنی است:
- همه مقادیر منطقی شمارش میشوند، خواه در آرایهها یا مراجع موجود باشند یا مستقیماً تایپ شوند. در لیست آرگومان ها (TRUE به عنوان 1 ارزیابی می شود، FALSE به عنوان 0 ارزیابی می شود).
- مقادیر متن در آرایه ها یا آرگومان های مرجع به عنوان 0 شمارش می شود، از جمله رشته های خالی ("")، متن نمایش اعداد و هر متن دیگری. نمایش های متنی ازاعدادی که مستقیماً در لیست آرگومان ها ارائه می شوند به عنوان اعدادی که نشان می دهند شمرده می شوند (در اینجا یک مثال فرمول است).
- سلول های خالی نادیده گرفته می شوند.
توجه داشته باشید. برای اینکه یک نمونه فرمول انحراف استاندارد به درستی کار کند، آرگومان های ارائه شده باید حداقل دارای دو مقدار عددی باشند، در غیر این صورت #DIV/0! خطا برگردانده شده است.
توابع برای محاسبه انحراف استاندارد جمعیت در اکسل
اگر با کل جمعیت سروکار دارید، از یکی از تابع های زیر برای انجام انحراف معیار در اکسل استفاده کنید. این توابع بر اساس روش "n" هستند.
عملکرد Excel STDEVP
STDEVP(number1,[number2],…) تابع اکسل قدیمی برای یافتن انحراف استاندارد جمعیت است.
در نسخه های جدید در اکسل 2010، 2013، 2016 و 2019، با تابع STDEV.P بهبودیافته جایگزین شده است، اما همچنان برای سازگاری با عقب نگه داشته شده است.
Excel STDEV.P تابع
STDEV.P(number1,[number2],…) مدرن است نسخه ای از تابع STDEVP که دقت بهبود یافته ای را ارائه می دهد. این در اکسل 2010 و نسخههای بعدی موجود است.
مانند نمونههای مشابه انحراف استاندارد، در آرایهها یا آرگومانهای مرجع، توابع STDEVP و STDEV.P فقط اعداد را میشمارند. در لیست آرگومانها، آنها مقادیر منطقی و نمایشهای متنی اعداد را نیز شمارش میکنند.
عملکرد اکسل STDEVPA
STDEVPA(value1, [value2], …) انحراف استاندارد یک جمعیت را محاسبه میکند، از جمله متن و مقادیر منطقی. با توجه به غیر عددیمقادیر، STDEVPA دقیقاً مانند تابع STDEVA کار می کند.
توجه داشته باشید. از هر فرمول انحراف استاندارد اکسل که استفاده می کنید، اگر یک یا چند آرگومان حاوی مقدار خطای بازگشتی توسط تابع یا متن دیگری باشد که نمی تواند به عنوان عدد تفسیر شود، یک خطا برمی گرداند.
از کدام تابع انحراف استاندارد اکسل استفاده شود؟
انواع توابع انحراف استاندارد در اکسل قطعاً می تواند باعث آشفتگی، به خصوص برای کاربران بی تجربه شود. برای انتخاب فرمول انحراف معیار صحیح برای یک کار خاص، کافی است به 3 سوال زیر پاسخ دهید:
- آیا انحراف معیار یک نمونه یا جامعه را محاسبه می کنید؟
- چه نسخه اکسل را دارید؟ استفاده کنید؟
- آیا مجموعه داده های شما فقط شامل اعداد یا مقادیر منطقی و متن نیز می شود؟
برای محاسبه انحراف معیار بر اساس عددی نمونه ، از تابع STDEV.S در اکسل 2010 به بعد. STDEV در اکسل 2007 و قبل از آن.
برای یافتن انحراف استاندارد یک جمعیت ، از تابع STDEV.P در اکسل 2010 و جدیدتر استفاده کنید. STDEVP در اکسل 2007 و قبل از آن.
اگر می خواهید مقادیر منطقی یا متن در محاسبه لحاظ شود، از STDEVA (انحراف استاندارد نمونه) یا STDEVPA ( انحراف معیار جمعیت). در حالی که من نمی توانم سناریویی را که در آن هر یک از تابع ها به تنهایی مفید باشد فکر کنم، ممکن است در فرمول های بزرگتر مفید باشند، جایی که یک یا چند آرگومان توسطتوابع دیگر به عنوان مقادیر منطقی یا نمایش متنی اعداد.
برای کمک به تصمیم گیری در مورد اینکه کدام یک از توابع انحراف استاندارد اکسل برای نیازهای شما مناسب تر است، لطفاً جدول زیر را که خلاصه اطلاعاتی را که قبلاً آموخته اید مرور کنید.
| STDEV | STDEV.S | STDEVP | STDEV.P | STDEVA | STDEVPA | |
| نسخه اکسل | 2003 - 2019 | 2010 - 2019 | 2003 - 2019 | 2010 - 2019 | 2003 - 2019 | 2003 - 2019 |
| نمونه | ✓ | ✓ | ✓ | |||
| جمعیت | ✓ | ✓ | ✓ | |||
| مقادیر منطقی در آرایه ها یا مراجع | نادیده گرفته شد | ارزیابی شده (TRUE=1, FALSE=0) | ||||
| متن در آرایه ها یا مراجع | نادیده گرفته شد | به عنوان صفر ارزیابی شد | ||||
| مقادیر منطقی و "اعداد متن" در لیست آرگومانها | ارزیابی شده (درست =1، FALSE=0) | |||||
| سلولهای خالی | <3 4> نادیده گرفته شد||||||
نمونه های فرمول انحراف استاندارد اکسل
پس از انتخاب تابعی که با نوع داده شما مطابقت دارد، نباید مشکلی در نوشتن فرمول - نحو آنقدر ساده و شفاف است که جایی برای خطا باقی نمی گذارد :) مثال های زیر چند فرمول انحراف استاندارد اکسل را در عمل نشان می دهند.
محاسبه استاندارد
