
Indholdsfortegnelse
Vejledningen forklarer essensen af standardafvigelse og standardfejl i middelværdien samt hvilken formel der er bedst at bruge til at beregne standardafvigelse i Excel.
I beskrivende statistik er det aritmetiske gennemsnit (også kaldet gennemsnittet) og standardafvigelse to nært beslægtede begreber. Men mens førstnævnte er velforstået af de fleste, er sidstnævnte kun forstået af få. Formålet med denne vejledning er at kaste lys over, hvad standardafvigelse egentlig er, og hvordan man beregner den i Excel.
Hvad er standardafvigelse?
standardafvigelse er et mål, der angiver, hvor meget værdierne i datasættet afviger (spredes) fra gennemsnittet. Med andre ord viser standardafvigelsen, om dine data ligger tæt på gennemsnittet eller om de svinger meget.
Formålet med standardafvigelsen er at hjælpe dig med at forstå, om gennemsnittet virkelig returnerer et "typisk" data. Jo tættere standardafvigelsen er på nul, jo lavere er variationen i dataene, og jo mere pålidelig er gennemsnittet. Standardafvigelsen lig med 0 angiver, at alle værdier i datasættet er nøjagtigt lig med gennemsnittet. Jo højere standardafvigelsen er, jo mere variation er der i dataene.data, og jo mindre nøjagtig middelværdien er.
For at få et bedre indtryk af, hvordan dette fungerer, kan du se på følgende data:
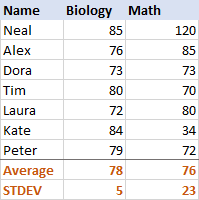
For biologi er standardafvigelsen 5 (afrundet til et helt tal), hvilket fortæller os, at de fleste resultater ikke er mere end 5 point fra gennemsnittet. Er det godt? Ja, det viser, at elevernes resultater i biologi er ret ensartede.
For matematik er standardafvigelsen 23. Det viser, at der er en enorm spredning i resultaterne, hvilket betyder, at nogle elever klarede sig meget bedre og/eller nogle langt dårligere end gennemsnittet.
I praksis anvendes standardafvigelsen ofte af virksomhedsanalytikere som et mål for investeringsrisiko - jo højere standardafvigelse, jo højere volatilitet i afkastet.
Prøvens standardafvigelse vs. befolkningens standardafvigelse
I forbindelse med standardafvigelse hører du ofte udtrykkene "stikprøve" og "population", som henviser til fuldstændigheden af de data, du arbejder med. Den væsentligste forskel er følgende:
- Befolkning omfatter alle elementer fra et datasæt.
- Eksempel er en delmængde af data, der omfatter et eller flere elementer fra populationen.
Forskere og analytikere anvender standardafvigelsen for en stikprøve og en population i forskellige situationer. Når en lærer f.eks. opsummerer eksamensresultaterne for en klasse af elever, vil han/hun anvende populationens standardafvigelse. Statistikere, der beregner den nationale gennemsnitsscore for SAT, vil anvende stikprøvens standardafvigelse, fordi de kun har data fra en stikprøve, ikkefra hele befolkningen.
Forståelse af formlen for standardafvigelse
Grunden til, at dataenes art er vigtig, er, at populationens standardafvigelse og stikprøvens standardafvigelse beregnes ved hjælp af lidt forskellige formler:
Standardafvigelse for en prøve | Befolkningens standardafvigelse |
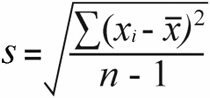 | 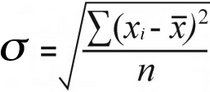 |
Hvor:
- x i er individuelle værdier i datasættet
- x er gennemsnittet af alle x værdier
- n er det samlede antal x værdier i datasættet
Hvis du har svært ved at forstå formlerne, kan det måske hjælpe at bryde dem ned i enkle trin. Men først skal vi have nogle eksempeldata at arbejde med:

1. Beregn gennemsnittet (gennemsnit)
Først finder du gennemsnittet af alle værdierne i datasættet ( x Når man regner i hånden, lægger man tallene sammen og dividerer derefter summen med antallet af tallene på denne måde:
(1+2+4+5+6+8+9)/7=5
For at finde middelværdien i Excel skal du bruge funktionen AVERAGE (gennemsnit), f.eks. =AVERAGE(A2:G2)
2. For hvert tal trækkes gennemsnittet fra og resultatet kvadreres
Dette er den del af formlen for standardafvigelse, der siger: ( x i - x )2
For at visualisere, hvad der rent faktisk foregår, kan du se på følgende billeder.
I dette eksempel er middelværdien 5, så vi beregner forskellen mellem hvert datapunkt og 5.
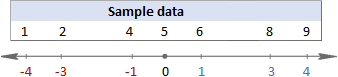
Derefter kvadrerer du forskellene, så de alle bliver til positive tal:
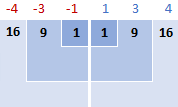
3. Læg de kvadrerede forskelle sammen
Når man siger "opsummering" i matematik, bruger man sigma Σ. Så det, vi gør nu, er at lægge de kvadrerede forskelle sammen for at fuldføre denne del af formlen: Σ( x i - x )2
16 + 9 + 1 + 1 + 9 + 16 = 52
4. Divider de samlede kvadrerede forskelle med antallet af værdier
Hidtil har formlerne for stikprøvens standardafvigelse og populationens standardafvigelse været identiske. På dette tidspunkt er de forskellige.
For den stikprøvens standardafvigelse , får du den stikprøvevarians ved at dividere de samlede kvadrerede forskelle med stikprøvens størrelse minus 1:
52 / (7-1) = 8.67
For den populationens standardafvigelse , finder du den middelværdi af kvadrerede forskelle ved at dividere de samlede kvadrerede forskelle med deres antal:
52 / 7 = 7.43
Hvorfor denne forskel i formlerne? Fordi man i formlen for standarddeviation i stikprøven skal korrigere for skævheden i estimatet af en stikprøvens gennemsnit i stedet for det sande befolkningsmiddel. Og det gør man ved at bruge n - 1 i stedet for n , som kaldes Bessel-korrektion.
5. Tag kvadratroden
Til sidst skal du tage kvadratroden af ovenstående tal, og du får din standardafvigelse (i nedenstående ligninger afrundet til 2 decimaler):
| Standardafvigelse for en prøve | Befolkningens standardafvigelse |
| √ 8.67 = 2.94 | √ 7.43 = 2.73 |
I Microsoft Excel beregnes standardafvigelsen på samme måde, men alle ovenstående beregninger udføres bag scenen. Det vigtigste for dig er at vælge en passende standardafvigelsesfunktion, som du får nogle fingerpeg om i det følgende afsnit.
Hvordan man beregner standardafvigelse i Excel
Der er i alt seks forskellige funktioner til at finde standardafvigelsen i Excel. Hvilken funktion du skal bruge, afhænger primært af arten af de data, du arbejder med - om det er hele populationen eller en stikprøve.
Funktioner til beregning af standardafvigelse for stikprøver i Excel
For at beregne standardafvigelsen baseret på en stikprøve skal du bruge en af følgende formler (alle er baseret på "n-1"-metoden beskrevet ovenfor).
Excel STDEV-funktion
STDEV(nummer1,[nummer2],...) er den ældste Excel-funktion til at estimere standardafvigelse baseret på en stikprøve, og den er tilgængelig i alle versioner af Excel 2003 til 2019.
I Excel 2007 og senere kan STDEV acceptere op til 255 argumenter, der kan repræsenteres af tal, arrays, navngivne intervaller eller referencer til celler, der indeholder tal. I Excel 2003 kan funktionen kun acceptere op til 30 argumenter.
Logiske værdier og tekstrepræsentationer af tal, der angives direkte i listen over argumenter, tælles med. I arrays og referencer tælles kun tal; tomme celler, logiske værdier som TRUE og FALSE, tekst- og fejlværdier ignoreres.
Bemærk: Excel STDEV er en forældet funktion, som kun er bevaret i de nyere versioner af Excel af hensyn til bagudkompatibilitet. Microsoft lover dog ikke noget med hensyn til fremtidige versioner. I Excel 2010 og senere anbefales det derfor at bruge STDEV.S i stedet for STDEV.
Excel STDEV.S-funktionen
STDEV.S(nummer1,[nummer2],...) er en forbedret version af STDEV, der blev introduceret i Excel 2010.
Ligesom STDEV beregner funktionen STDEV.S stikprøve-standardafvigelsen for et sæt værdier baseret på den klassiske formel for stikprøve-standardafvigelse, som blev diskuteret i det foregående afsnit.
Excel STDEVA-funktion
STDEVA(value1, [value2], ...) er en anden funktion til at beregne standardafvigelsen for en prøve i Excel. Den adskiller sig kun fra de to ovenstående funktioner ved den måde, den håndterer logiske værdier og tekstværdier på:
- Alle logiske værdier tælles med, uanset om de er indeholdt i arrays eller referencer eller er skrevet direkte i listen over argumenter (TRUE evalueres som 1, FALSE evalueres som 0).
- Tekstværdier i arrays eller referenceargumenter tælles som 0, herunder tomme strenge (""), tekstrepræsentationer af tal og anden tekst. Tekstrepræsentationer af tal, der angives direkte i listen over argumenter, tælles som de tal, de repræsenterer (her er et eksempel på en formel).
- Tomme celler ignoreres.
Bemærk: For at en formel for standardafvigelse i en prøve kan fungere korrekt, skal de medfølgende argumenter indeholde mindst to numeriske værdier, ellers returneres fejlen #DIV/0!
Funktioner til beregning af populationens standardafvigelse i Excel
Hvis du har med hele populationen at gøre, skal du bruge en af følgende funktioner til at beregne standardafvigelse i Excel. Disse funktioner er baseret på "n"-metoden.
Excel STDEVP-funktion
STDEVP(nummer1,[nummer2],...) er den gamle Excel-funktion til at finde standardafvigelsen for en population.
I de nye versioner af Excel 2010, 2013, 2016 og 2019 er den erstattet af den forbedrede STDEV.P-funktion, men den er stadig bevaret af hensyn til bagudkompatibilitet.
Excel STDEV.P-funktionen
STDEV.P(nummer1,[nummer2],...) er den moderne version af STDEVP-funktionen, der giver en forbedret nøjagtighed. Den er tilgængelig i Excel 2010 og nyere versioner.
Ligesom deres modstykker til standardafvigelse af stikprøveværdier tæller STDEVP- og STDEV.P-funktionerne kun tal i arrays eller referenceargumenter. I listen over argumenter tæller de også logiske værdier og tekstrepræsentationer af tal.
Excel STDEVPA-funktion
STDEVPA(value1, [value2], ...) beregner standardafvigelsen for en population, herunder tekst og logiske værdier. Med hensyn til ikke-numeriske værdier fungerer STDEVPA nøjagtigt som STDEVA-funktionen.
Bemærk. Uanset hvilken Excel-formel for standardafvigelse du bruger, returnerer den en fejl, hvis et eller flere argumenter indeholder en fejlværdi, der returneres af en anden funktion eller tekst, som ikke kan fortolkes som et tal.
Hvilken Excel standardafvigelsesfunktion skal jeg bruge?
En række forskellige standardafvigelsesfunktioner i Excel kan helt sikkert skabe rod, især for uerfarne brugere. For at vælge den korrekte standardafvigelsesformel til en bestemt opgave skal du blot besvare følgende 3 spørgsmål:
- Beregner du standardafvigelsen for en prøve eller en population?
- Hvilken Excel-version bruger du?
- Indeholder dit datasæt kun tal eller også logiske værdier og tekst?
Sådan beregnes standardafvigelse baseret på en numerisk prøve , bruge funktionen STDEV.S i Excel 2010 og senere; STDEV i Excel 2007 og tidligere.
Sådan finder du standardafvigelsen for en befolkning , bruge funktionen STDEV.P i Excel 2010 og senere; STDEVP i Excel 2007 og tidligere.
Hvis du ønsker logisk eller tekst værdier, der skal indgå i beregningen, skal du bruge enten STDEVA (standarddeviation for en stikprøve) eller STDEVPA (standarddeviation for en population). Jeg kan ikke komme i tanke om noget scenarie, hvor nogen af funktionerne kan være nyttige alene, men de kan være nyttige i større formler, hvor et eller flere argumenter returneres af andre funktioner som logiske værdier eller tekstrepræsentationer af tal.
For at hjælpe dig med at beslutte, hvilken af Excel's standardafvigelsesfunktioner der er bedst egnet til dine behov, skal du gennemgå følgende tabel, som opsummerer de oplysninger, du allerede har lært.
| STDEV | STDEV.S | STDEVP | STDEV.P | STDEVA | STDEVPA | |
| Excel-version | 2003 - 2019 | 2010 - 2019 | 2003 - 2019 | 2010 - 2019 | 2003 - 2019 | 2003 - 2019 |
| Eksempel | ✓ | ✓ | ✓ | |||
| Befolkning | ✓ | ✓ | ✓ | |||
| Logiske værdier i arrays eller referencer | Ignoreret | Vurderet (SAND=1, FALSK=0) | ||||
| Tekst i arrays eller referencer | Ignoreret | Vurderet som nul | ||||
| Logiske værdier og "tekst-numre" i listen over argumenter | Vurderet (SAND=1, FALSK=0) | |||||
| Tomme celler | Ignoreret | |||||
Excel-formel for standardafvigelse eksempler
Når du har valgt den funktion, der svarer til din datatype, bør det ikke være nogen problemer at skrive formlen - syntaksen er så enkel og gennemskuelig, at der ikke er plads til fejl :) De følgende eksempler viser et par Excel-formler for standardafvigelse i praksis.
Beregning af standardafvigelse for en prøve og en population
Afhængigt af dataenes art kan du bruge en af følgende formler:
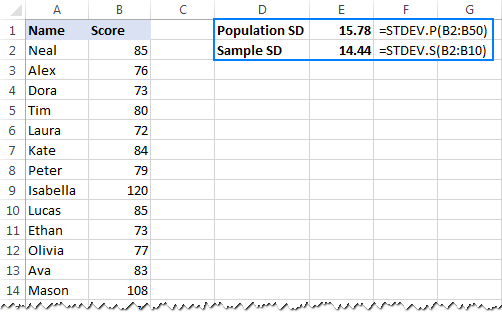
- For at beregne standardafvigelsen på grundlag af hele befolkning , dvs. den fulde liste over værdier (B2:B50 i dette eksempel), skal du bruge funktionen STDEV.P:
=STDEV.P(B2:B50) - Sådan finder du standardafvigelsen baseret på en prøve der udgør en del eller en delmængde af populationen (B2:B10 i dette eksempel), skal du bruge funktionen STDEV.S:
=STDEV.S(B2:B10)
Som du kan se på skærmbilledet nedenfor, giver formlerne lidt forskellige tal (jo mindre en prøve, jo større forskel):
I Excel 2007 og nyere versioner skal du i stedet bruge STDEVP- og STDEV-funktionerne:
- For at få populationens standardafvigelse:
=STDEVP(B2:B50) - For at beregne stikprøvens standardafvigelse:
=STDEV(B2:B10)
Beregning af standardafvigelse for tekstrepræsentationer af tal
Når vi diskuterede forskellige funktioner til beregning af standardafvigelse i Excel, nævnte vi nogle gange "tekstrepræsentationer af tal", og du er måske nysgerrig efter at vide, hvad det egentlig betyder.
I denne sammenhæng er "tekstrepræsentationer af tal" simpelthen tal formateret som tekst. Hvordan kan sådanne tal dukke op i dine regneark? Oftest eksporteres de fra eksterne kilder. Eller de returneres af såkaldte tekstfunktioner, der er designet til at manipulere tekststrenge, f.eks. TEXT, MID, RIGHT, LEFT osv. Nogle af disse funktioner kan også arbejde med tal, men deres output er altid tekst, selv omhvis det ligner et tal meget.
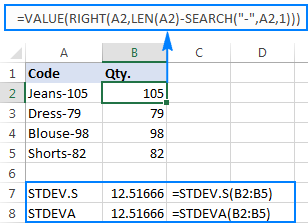
For at illustrere det bedre kan du se på følgende eksempel: Antag, at du har en kolonne med produktkoder som "Jeans-105", hvor cifrene efter en bindestreg angiver mængden. Dit mål er at udtrække mængden af hver vare og derefter finde standardafvigelsen for de udtrækkede tal.
Det er ikke noget problem at trække mængden til en anden kolonne:
=RIGHT(A2,LEN(A2)-SEARCH("-",A2,1))
Problemet er, at hvis man bruger en Excel-formel for standardafvigelse på de udtrukne tal, får man enten #DIV/0! eller 0 tilbage, som vist i skærmbilledet nedenfor:
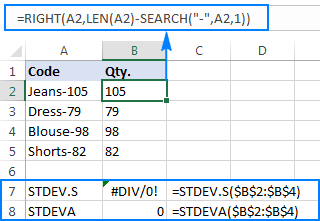
Hvorfor så mærkelige resultater? Som nævnt ovenfor er resultatet af RIGHT-funktionen altid en tekststreng. Men hverken STDEV.S eller STDEVA kan håndtere tal formateret som tekst i referencer (førstnævnte ignorerer dem simpelthen, mens sidstnævnte tæller dem som nuller). For at få standardafvigelsen af sådanne "tekst-tal" skal du angive dem direkte i listen over argumenter, hvilket kan gøres ved at indlejre alleRIGHT-funktioner i din STDEV.S- eller STDEVA-formel:
=STDEV.S(HØJRE(A2,LEN(A2)-SØGNING("-",A2,1)), HØJRE(A3,LEN(A3)-SØGNING("-",A3,1)), HØJRE(A4,LEN(A4)-SØGNING("-",A4,1)), HØJRE(A5,LEN(A5)-SØGNING("-",A5,1)))
=STDEVA(RIGHT(A2,LEN(A2)-SEARCH("-",A2,1)), RIGHT(A3,LEN(A3)-SEARCH("-",A3,1)), RIGHT(A4,LEN(A4)-SEARCH("-",A4,1)), RIGHT(A5,LEN(A5)-SEARCH("-",A5,1)))
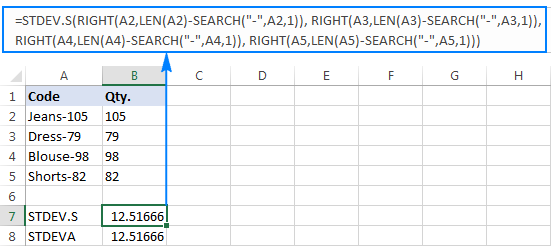
Formlerne er lidt besværlige, men det kan være en løsning, der kan fungere for en lille stikprøve. For en større stikprøve, for ikke at tale om hele populationen, er det bestemt ikke en mulighed. I dette tilfælde ville en mere elegant løsning være at lade VALUE-funktionen konvertere "teksttal" til tal, som enhver standardafvigelsesformel kan forstå (bemærk venligst de højrejusterede tal i skærmbilledetnedenfor i modsætning til de venstrejusterede tekststrenge på skærmbilledet ovenfor):
Sådan beregnes standardfejl af middelværdien i Excel
I statistik er der endnu et mål til at estimere variabiliteten i data - standardfejl i forhold til gennemsnittet , som nogle gange forkortes (om end fejlagtigt) til blot "standardfejl". Standardafvigelse og middelværdifald er to nært beslægtede begreber, men ikke det samme.
Mens standardafvigelsen måler variabiliteten i et datasæt i forhold til gennemsnittet, vurderer middelværdighedens standardfejl (SEM), hvor langt stikprøvens gennemsnit sandsynligvis ligger fra den sande befolkningsgennemsnit. Sagt på en anden måde - hvis du tog flere stikprøver fra den samme population, ville middelværdighedens standardfejl vise spredningen mellem disse stikprøvers gennemsnit. Da vi normalt kun beregner enmiddelværdi for et datasæt, ikke flere middelværdier, og standardfejlen for middelværdien estimeres snarere end måles.
I matematik beregnes standardfejlen for middelværdien ved hjælp af denne formel:
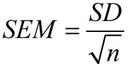
Hvor SD er standardafvigelsen, og n er stikprøvens størrelse (antallet af værdier i stikprøven).
I dine Excel-regneark kan du bruge funktionen COUNT til at få antallet af værdier i en prøve, SQRT til at tage kvadratroden af dette antal og STDEV.S til at beregne standardafvigelsen for en prøve.
Ved at sætte alt dette sammen får du formlen for middelværdiens standardfejl i Excel:
STDEV.S( rækkevidde )/SQRT(COUNT( rækkevidde ))Hvis vi antager, at stikprøvedataene er i B2:B10, vil vores SEM-formel se ud som følger:
=STDEV.S(B2:B10)/SQRT(COUNT(B2:B10))
Og resultatet kunne ligne dette:

Sådan tilføjer du standardafvigelsesbjælker i Excel
Hvis du vil vise en margen for standardafvigelsen visuelt, kan du tilføje standardafvigelsesbjælker til dit Excel-diagram. Sådan gør du:
- Opret en graf på den sædvanlige måde ( Indsæt faneblad> Diagrammer gruppe).
- Klik et vilkårligt sted på grafen for at vælge den, og klik derefter på Diagramelementer knap.
- Klik på pilen ud for Fejlstænger , og vælg Standardafvigelse .
Dette vil indsætte de samme standardafvigelsesbjælker for alle datapunkter.

Dette er hvordan man laver standardafvigelse i Excel. Jeg håber, at du vil finde disse oplysninger nyttige. Jeg takker for din læsning og håber at se dig på vores blog i næste uge.
