
목차
튜토리얼은 표준편차의 본질과 평균의 표준오차를 설명하고 Excel에서 표준편차를 계산하는 데 가장 적합한 수식이 무엇인지 설명합니다.
기술통계에서 , 산술 평균(평균이라고도 함) 및 표준 편차는 밀접하게 관련된 두 가지 개념입니다. 그러나 전자는 대부분의 사람들이 잘 이해하고 있는 반면, 후자는 소수만이 이해하고 있다. 이 자습서의 목표는 표준 편차가 실제로 무엇이며 Excel에서 계산하는 방법에 대해 설명합니다.
표준 편차란 무엇입니까?
The 표준편차 는 데이터 집합의 값이 평균에서 얼마나 벗어나는지를 나타내는 척도입니다. 달리 말하면 표준 편차는 데이터가 평균에 가까운지 또는 변동이 심한지를 나타냅니다.
표준 편차의 목적은 평균이 실제로 "일반적인" 데이터를 반환하는지 이해하는 데 도움을 주는 것입니다. 표준 편차가 0에 가까울수록 데이터 변동성이 낮아지고 평균이 더 신뢰할 수 있습니다. 0과 같은 표준 편차는 데이터 세트의 모든 값이 정확히 평균과 같음을 나타냅니다. 표준 편차가 높을수록 데이터에 더 많은 변동이 있고 평균의 정확도가 떨어집니다.
이 작동 방식을 더 잘 이해하려면 다음 데이터를 살펴보세요.
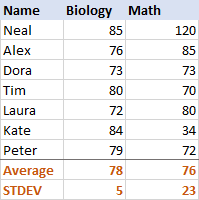
생물학의 경우 표준 편차표본 및 모집단의 편차
데이터의 특성에 따라 다음 공식 중 하나를 사용하십시오.
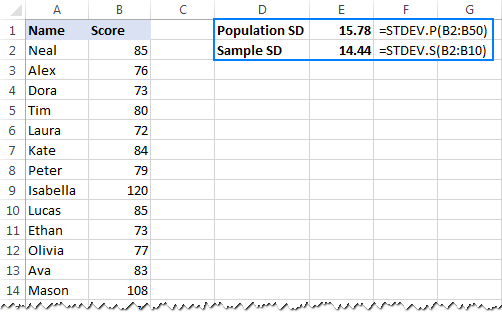
- 전체 모집단<9을 기준으로 표준 편차를 계산하려면>, 즉 값의 전체 목록(이 예에서는 B2:B50), STDEV.P 함수를 사용합니다.
=STDEV.P(B2:B50) - 샘플<9을 기반으로 표준 편차를 찾으려면> 모집단의 일부 또는 하위 집합(이 예에서는 B2:B10)을 구성하는 경우 STDEV.S 함수를 사용합니다.
=STDEV.S(B2:B10)
아래 스크린샷에서 수식은 약간 다른 숫자를 반환합니다(샘플이 작을수록 차이가 더 큼):
Excel 2007 이하에서는 STDEVP 및 STDEV 함수를 사용합니다. 대신:
- 모집단 표준 편차를 얻으려면:
=STDEVP(B2:B50) - 샘플 표준 편차를 계산하려면:
=STDEV(B2:B10)
숫자의 텍스트 표현에 대한 표준 편차 계산
Excel에서 표준 편차를 계산하는 다양한 함수를 논의할 때 "텍스트 r 숫자의 표현"이 실제로 무엇을 의미하는지 궁금할 수 있습니다.
이 문맥에서 "숫자의 텍스트 표현"은 단순히 텍스트 형식의 숫자입니다. 그러한 숫자가 워크시트에 어떻게 나타날 수 있습니까? 대부분 외부 소스에서 내보내집니다. 또는 텍스트 문자열을 조작하도록 설계된 소위 Text 함수에 의해 반환됩니다. 텍스트, 중간, 오른쪽, 왼쪽,이러한 함수 중 일부는 숫자와도 작동할 수 있지만 출력은 숫자와 매우 유사하더라도 항상 텍스트입니다.
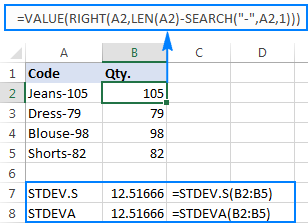
요점을 더 잘 설명하기 위해 다음 예제를 고려하십시오. 하이픈 뒤의 숫자가 수량을 나타내는 "Jeans-105"와 같은 제품 코드 열이 있다고 가정합니다. 귀하의 목표는 각 항목의 수량을 추출한 다음 추출된 숫자의 표준편차를 찾는 것입니다.
수량을 다른 열로 가져오는 것은 문제가 되지 않습니다:
=RIGHT(A2,LEN(A2)-SEARCH("-",A2,1))
문제는 추출된 숫자에 Excel 표준 편차 공식을 사용하면 #DIV/0! 또는 아래 스크린샷에 표시된 것과 같은 0:
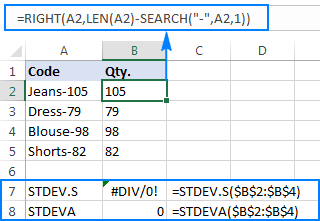
왜 이상한 결과입니까? 위에서 언급했듯이 RIGHT 함수의 출력은 항상 텍스트 문자열입니다. 그러나 STDEV.S나 STDEVA는 참조에서 텍스트로 서식이 지정된 숫자를 처리할 수 없습니다(전자는 단순히 숫자를 무시하고 후자는 0으로 계산함). 이러한 "텍스트 숫자"의 표준 편차를 얻으려면 모든 RIGHT 함수를 STDEV.S 또는 STDEVA 공식에 포함하여 수행할 수 있는 인수 목록에 직접 제공해야 합니다.
=STDEV.S(RIGHT(A2,LEN(A2)-SEARCH("-",A2,1)), RIGHT(A3,LEN(A3)-SEARCH("-",A3,1)), RIGHT(A4,LEN(A4)-SEARCH("-",A4,1)), RIGHT(A5,LEN(A5)-SEARCH("-",A5,1)))
=STDEVA(RIGHT(A2,LEN(A2)-SEARCH("-",A2,1)), RIGHT(A3,LEN(A3)-SEARCH("-",A3,1)), RIGHT(A4,LEN(A4)-SEARCH("-",A4,1)), RIGHT(A5,LEN(A5)-SEARCH("-",A5,1)))
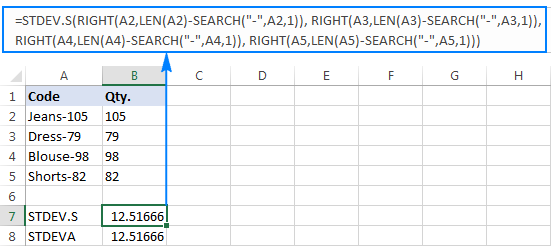
공식은 다소 번거롭지만 소규모 샘플에 대한 작업 솔루션이 될 수 있습니다. 전체 인구는 말할 것도 없고 더 큰 것의 경우에는 확실히 선택 사항이 아닙니다. 이 경우 보다 우아한 솔루션은VALUE 함수는 "텍스트 숫자"를 표준 편차 공식이 이해할 수 있는 숫자로 변환합니다(위 스크린샷의 왼쪽 정렬 텍스트 문자열과 달리 아래 스크린샷의 오른쪽 정렬 숫자에 유의하십시오).
엑셀에서 평균의 표준오차를 계산하는 방법
통계에서 데이터의 변동성을 추정하는 척도가 하나 더 있다 - 평균의 표준오차 , 때로는 "표준 오류"로 단축됩니다. 평균의 표준 편차와 표준 오차는 밀접하게 관련된 두 가지 개념이지만 동일하지는 않습니다.
표준 편차는 평균에서 데이터 세트의 변동성을 측정하는 반면, 평균의 표준 오차(SEM) 표본 평균이 실제 모집단 평균에서 얼마나 멀리 떨어져 있는지 추정합니다. 달리 말하면 동일한 모집단에서 여러 표본을 추출한 경우 평균의 표준 오차는 해당 표본 평균 간의 분산을 보여줍니다. 일반적으로 데이터 집합에 대해 여러 평균이 아닌 하나의 평균만 계산하기 때문에 평균의 표준 오차는 측정되는 것이 아니라 추정됩니다.
수학에서 평균의 표준 오차는 다음 공식으로 계산됩니다.
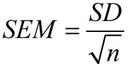
여기서 SD 는 표준 편차이고 n 는 샘플 크기(샘플의 값 수)입니다.
Excel 워크시트에서 COUNT 함수를 사용하여 숫자를 얻을 수 있습니다.SQRT는 해당 숫자의 제곱근을 취하고 STDEV.S는 샘플의 표준 편차를 계산합니다.
이 모든 것을 종합하면 Excel에서 평균 공식의 표준 오차를 얻습니다. :
STDEV.S( range )/SQRT(COUNT( range ))샘플 데이터가 B2:B10에 있다고 가정하면 SEM 공식은 다음과 같습니다. :
=STDEV.S(B2:B10)/SQRT(COUNT(B2:B10))
결과는 다음과 유사할 수 있습니다.

Excel에서 표준 편차 막대를 추가하는 방법
표준 편차의 여백을 시각적으로 표시하려면 Excel 차트에 표준 편차 막대를 추가할 수 있습니다. 방법은 다음과 같습니다.
- 일반적인 방법으로 그래프를 만듭니다( 삽입 탭 > 차트 그룹).
- 그래프의 아무 곳이나 클릭합니다. 그래프를 선택하고 차트 요소 버튼을 클릭합니다.
- 오차 막대 옆의 화살표를 클릭하고 표준편차 를 선택합니다.
모든 데이터 포인트에 대해 동일한 표준편차 막대를 삽입합니다.

이것은 Excel에서 표준편차를 수행하는 방법입니다. 이 정보가 도움이 되기를 바랍니다. 어쨌든 읽어주셔서 감사하고 다음 주에 저희 블로그에서 뵙기를 바랍니다.
5(정수로 반올림)는 대부분의 점수가 평균에서 5점 이상 떨어져 있지 않음을 나타냅니다. 그거 좋아요? 예, 그것은 학생들의 생물 점수가 꽤 일관성이 있다는 것을 나타냅니다.수학의 경우 표준 편차는 23입니다. 이것은 점수에 엄청난 분산(확산)이 있음을 보여줍니다. 학생들은 훨씬 더 나은 성과를 보였고 일부는 평균보다 훨씬 더 낮은 성과를 냈습니다.
실제로 비즈니스 분석가는 표준 편차를 투자 위험의 척도로 자주 사용합니다. 표준 편차가 높을수록 변동성이 커집니다.
표본 표준편차 대 모집단 표준편차
표준편차와 관련하여 "표본" 및 "모집"이라는 용어를 종종 듣게 될 것입니다. 작업 중인 데이터. 주요 차이점은 다음과 같습니다.
- 인구 는 데이터 세트의 모든 요소를 포함합니다.
- 샘플 은 모집단에서 하나 이상의 요소를 포함하는 데이터입니다.
연구자와 분석가는 다양한 상황에서 표본과 모집단의 표준 편차에 대해 작업합니다. 예를 들어, 한 반 학생의 시험 점수를 요약할 때 교사는 모집단 표준 편차를 사용합니다. 국가 SAT 평균 점수를 계산하는 통계학자는 표본 표준 편차를 사용합니다.전체 모집단이 아닌 표본의 데이터만 제공됩니다.
표준 편차 공식 이해
데이터의 특성이 중요한 이유는 모집단 표준 편차와 표본이 표준 편차는 약간 다른 공식으로 계산됩니다.
샘플 표준 편차 | 모집단 표준 편차 |
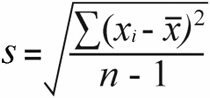 | 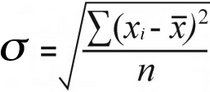 |
위치:
- x i 는 데이터 집합의 개별 값입니다.
- x 는 모든 x<2의 평균입니다> values
- n 는 데이터 세트에 있는 x 개의 총 값입니다.
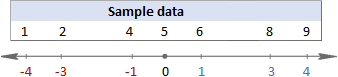
공식을 이해하는 데 어려움이 있습니까? 간단한 단계로 나누면 도움이 될 수 있습니다. 그러나 먼저 작업할 몇 가지 샘플 데이터가 있습니다.

1. 평균(average)을 계산합니다.
먼저 데이터 세트에서 모든 값의 평균을 찾습니다(위 공식에서 x ). 손으로 계산할 때는 숫자를 더한 다음 합계를 해당 숫자의 개수로 나눕니다.
(1+2+4+5+6+8+9)/7=5
Excel에서 평균을 찾으려면 AVERAGE 함수를 사용하십시오. =평균(A2:G2)
2. 각 숫자에 대해 평균을 빼고 결과를 제곱합니다.
이것은 다음과 같은 표준 편차 공식의 일부입니다. ( x i - x )2
실제 진행 상황을 시각화하려면다음 이미지.
이 예에서 평균은 5이므로 각 데이터 포인트와 5의 차이를 계산합니다.
그런 다음 제곱합니다. 차이점을 모두 양수로 바꿉니다:
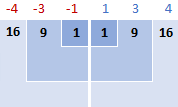
3. 제곱 차이를 합산합니다.
수학에서 "합산"을 하려면 시그마 Σ를 사용합니다. 이제 우리가 하는 일은 차의 제곱을 더하여 공식의 이 부분을 완성하는 것입니다: Σ( x i - x )2
16 + 9 + 1 + 1 + 9 + 16 = 52
4. 총 제곱 차이를 값의 개수로 나눕니다.
지금까지 표본 표준 편차와 모집단 표준 편차 공식은 동일했습니다. 이 시점에서 그들은 다릅니다.
표본 표준 편차 의 경우 총 제곱 차이를 표본 크기에서 1을 뺀 값으로 나누어 표본 분산 을 얻습니다.
52 / (7-1) = 8.67
모집단 표준편차 의 경우 총계를 나누어 차이 제곱 평균 을 찾습니다. 카운트별 차이 제곱:
52 / 7 = 7.43
수식에서 왜 이러한 차이가 발생합니까? 표본 표준 편차 공식에서 실제 모집단 평균 대신 표본 평균 추정의 치우침을 수정해야 하기 때문입니다. 그리고 n 대신 n - 1 를 사용하여 이를 베셀 보정이라고 합니다.
5. 제곱근을 취하십시오.
마지막으로 위의 제곱근을 취하십시오.숫자를 입력하면 표준 편차를 얻을 수 있습니다(아래 방정식에서 소수점 둘째 자리로 반올림):
| 표본 표준 편차 | 인구 표준 편차 |
| √ 8.67 = 2.94 | √ 7.43 = 2.73 |
Microsoft Excel에서 표준 편차는 같은 방식이지만 위의 모든 계산은 장면 뒤에서 수행됩니다. 중요한 것은 적절한 표준편차 함수를 선택하는 것입니다. 다음 섹션에서 몇 가지 단서를 제공할 것입니다.
Excel에서 표준편차를 계산하는 방법
전체적으로 6가지가 있습니다. Excel에서 표준 편차를 찾는 함수. 어떤 것을 사용할지는 주로 작업 중인 데이터의 특성(전체 모집단인지 샘플인지)에 따라 다릅니다.
Excel에서 샘플 표준 편차를 계산하는 함수
표준을 계산하려면 샘플을 기준으로 한 편차는 다음 공식 중 하나를 사용합니다(모두 위에서 설명한 "n-1" 방법을 기반으로 함).
Excel STDEV 함수
STDEV(number1,[number2],…) 은 가장 오래된 Excel입니다. 샘플을 기반으로 표준 편차를 추정하는 함수이며 Excel 2003~2019의 모든 버전에서 사용할 수 있습니다.
Excel 2007 이상에서 STDEV는 숫자, 배열로 나타낼 수 있는 최대 255개의 인수를 허용할 수 있습니다. , 명명된 범위 또는 숫자가 포함된 셀에 대한 참조. Excel 2003에서 이 함수는 최대30개의 인수.
인수 목록에 직접 제공된 숫자의 논리 값 및 텍스트 표현이 계산됩니다. 배열과 참조에서는 숫자만 계산됩니다. 빈 셀, TRUE 및 FALSE의 논리 값, 텍스트 및 오류 값은 무시됩니다.
참고. Excel STDEV는 이전 버전과의 호환성을 위해서만 최신 버전의 Excel에서 유지되는 오래된 함수입니다. 그러나 Microsoft는 향후 버전에 대해 약속하지 않습니다. 따라서 엑셀 2010 이상에서는 STDEV 대신 STDEV.S를 사용하는 것을 권장한다.
엑셀 STDEV.S 함수
STDEV.S(number1,[number2],…) 은 엑셀 2010에서 도입된 STDEV의 개선된 버전이다.
STDEV와 마찬가지로 STDEV.S 함수는 이전 섹션에서 설명한 고전적인 샘플 표준 편차 공식을 기반으로 일련의 값에 대한 샘플 표준 편차를 계산합니다.
Excel STDEVA 함수
STDEVA(value1, [value2], …) 는 Excel에서 샘플의 표준 편차를 계산하는 또 다른 함수입니다. 논리 값과 텍스트 값을 처리하는 방식에서만 위의 두 값과 다릅니다.
- 모든 논리 값 은 배열 또는 참조 내에 포함되어 있거나 직접 입력되었는지 여부에 관계없이 계산됩니다. 인수 목록에 넣습니다(TRUE는 1로 평가되고 FALSE는 0으로 평가됨). 배열 또는 참조 인수 내의
- 텍스트 값 은 빈 문자열(""), 텍스트를 포함하여 0으로 계산됩니다. 숫자 및 기타 텍스트의 표현. 의 텍스트 표현인수 목록에 직접 제공된 숫자는 해당 숫자가 나타내는 숫자로 계산됩니다(수식 예는 다음과 같습니다).
- 빈 셀은 무시됩니다.
참고. 샘플 표준 편차 공식이 올바르게 작동하려면 제공된 인수에 두 개 이상의 숫자 값이 포함되어야 합니다. 그렇지 않으면 #DIV/0! 오류가 반환됩니다.
Excel에서 모집단 표준편차를 계산하는 함수
전체 모집단을 처리하는 경우 다음 함수 중 하나를 사용하여 Excel에서 표준편차를 계산합니다. 이러한 기능은 "n" 방법을 기반으로 합니다.
Excel STDEVP 기능
STDEVP(number1,[number2],…) 는 모집단의 표준 편차를 찾는 이전 Excel 기능입니다.
새 버전에서 엑셀 2010, 2013, 2016, 2019 버전에서는 개선된 STDEV.P 함수로 대체되었으나 이전 버전과의 호환성을 위해 여전히 유지됩니다.
엑셀 STDEV.P 함수
STDEV.P(number1,[number2],…) 은 최신 향상된 정확도를 제공하는 STDEVP 기능의 버전입니다. Excel 2010 이상 버전에서 사용할 수 있습니다.
배열 또는 참조 인수 내에서 샘플 표준 편차와 마찬가지로 STDEVP 및 STDEV.P 함수는 숫자만 계산합니다. 인수 목록에서 논리 값과 숫자의 텍스트 표현도 계산합니다.
Excel STDEVPA 함수
STDEVPA(value1, [value2], …) 은 텍스트 및 논리 값을 포함하여 모집단의 표준 편차를 계산합니다. 숫자가 아닌 경우STDEVPA는 STDEVA 함수와 똑같이 작동합니다.
참고. 어떤 Excel 표준편차 수식을 사용하든 하나 이상의 인수에 숫자로 해석할 수 없는 다른 함수 또는 텍스트에서 반환된 오류 값이 포함되어 있으면 오류가 반환됩니다.
사용할 Excel 표준편차 함수는 무엇입니까?
Excel의 다양한 표준편차 함수는 특히 경험이 없는 사용자에게 혼란을 야기할 수 있습니다. 특정 작업에 대한 올바른 표준 편차 공식을 선택하려면 다음 3가지 질문에 답하십시오.
- 샘플 또는 모집단의 표준 편차를 계산합니까?
- 어떤 Excel 버전을 사용합니까? 사용하시겠습니까?
- 데이터 세트에 숫자만 포함되어 있습니까, 아니면 논리 값과 텍스트도 포함되어 있습니까?
숫자 샘플 을 기반으로 표준 편차를 계산하려면 다음을 사용하십시오. Excel 2010 이상의 STDEV.S 기능; Excel 2007 및 이전 버전의 STDEV.
모집단 의 표준 편차를 찾으려면 Excel 2010 이상에서 STDEV.P 함수를 사용하십시오. Excel 2007 및 이전 버전의 STDEVP.
계산에 논리 또는 텍스트 값을 포함하려면 STDEVA(표본 표준 편차) 또는 STDEVPA( 모집단 표준 편차). 함수가 그 자체로 유용할 수 있는 시나리오를 생각할 수는 없지만 하나 이상의 인수가 반환되는 더 큰 수식에서는 유용할 수 있습니다.논리 값 또는 숫자의 텍스트 표현과 같은 기타 기능.
필요에 가장 적합한 Excel 표준 편차 기능을 결정하는 데 도움이 되도록 이미 학습한 정보를 요약한 다음 표를 검토하십시오.
| STDEV | STDEV.S | STDEVP | STDEV.P | STDEVA | STDEVPA | |
| 엑셀버전 | 2003 - 2019 | 2010 - 2019 | 2003 - 2019 | 2010 - 2019 | 2003 - 2019 | 2003 - 2019 |
| 샘플 | ✓ | ✓ | ✓ | |||
| 인구 | ✓ | ✓ | ✓ | |||
| 배열의 논리 값 또는 참조 | 무시됨 | 평가됨 (TRUE=1, FALSE=0) | ||||
| 배열 또는 참조의 텍스트 | 무시됨 | 0으로 평가됨 | ||||
| 논리 값 및 인수 목록의 "텍스트 숫자" | 평가됨 (TRUE =1, FALSE=0) | |||||
| 빈 셀 | <3 4>무시||||||
Excel 표준편차 수식 예제
데이터 유형에 해당하는 함수를 선택하면 작성에 어려움이 없을 것입니다. 수식 - 구문이 너무 단순하고 투명하여 오류의 여지가 없습니다 :) 다음 예는 작동 중인 몇 가지 Excel 표준 편차 수식을 보여줍니다.
표준 계산
