
目次
このチュートリアルでは、標準偏差と平均の標準誤差の本質を説明するとともに、Excelで標準偏差を計算する際にどの数式を使用するのが最適かを解説します。
記述統計学において、算術平均(平均ともいう)と標準偏差は密接に関連した概念です。 しかし、前者はよく理解されていますが、後者はほとんど理解されていません。 このチュートリアルの目的は、実際に標準偏差とは何か、そしてそれをExcelで計算する方法について明らかにすることです。
標準偏差とは何ですか?
があります。 標準偏差 つまり、標準偏差は、データが平均に近いか、変動が大きいかを示す指標です。
標準偏差の目的は、平均が本当に「典型的な」データを返しているかどうかを理解することにある。 標準偏差が0に近いほど、データのばらつきが少なく、平均の信頼性が高い。 標準偏差が0に等しければ、データセットのすべての値が平均と正確に等しいことを示す。 標準偏差が高いほど、データセットにばらつきが多くあることを示している。のデータで、平均値の精度が低いほど
この仕組みを知るために、以下のデータをご覧ください。
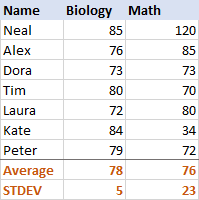
生物学の場合、標準偏差は5(整数で四捨五入)、つまり、大部分のスコアが平均から5ポイント以上離れていないことがわかります。 これは良いことですか? そうです。生徒の生物学のスコアはかなり安定していることがわかります。
数学の場合、標準偏差は23であり、平均点よりはるかに良い成績の生徒とはるかに悪い成績の生徒がいることを意味し、点数に大きなばらつきがあることを示しています。
実際には、標準偏差は投資リスクの尺度としてビジネスアナリストによく使われる。標準偏差が高いほど、リターンのボラティリティが高いことを意味する。
標本標準偏差と母集団標準偏差の比較
標準偏差に関連して、「標本」と「母集団」という言葉をよく耳にすると思いますが、これは扱うデータの完全性を指しています。 主に次のような違いがあります。
- 人口 は、データセットのすべての要素を含む。
- サンプル は、母集団から1つ以上の要素を含むデータの部分集合である。
研究者や分析者は、さまざまな場面で標本と母集団の標準偏差を使い分けます。 たとえば、あるクラスの生徒の試験の点数をまとめるとき、教師は母集団の標準偏差を使います。 全国SAT平均点を計算する統計学者は、標本からのデータのみを提示されるため標本の標準偏差を使うことになるでしょうが、母集団の標準偏差ではありません。を母集団全体から抽出する。
標準偏差の公式を理解する
データの性質が問題になるのは、母集団の標準偏差と標本の標準偏差が微妙に異なる計算式で算出されるからである。
サンプル標準偏差 | 母集団標準偏差 |
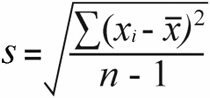 | 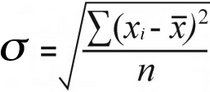 |
どこで
- x i はデータセット中の個々の値
- x は、すべての x 価値観
- n は、総数 x データセット内の値
数式を理解するのが難しい場合は、簡単なステップに分解してみるとよいでしょう。 まずは、サンプルデータを用意しましょう。

1.平均値を計算する
まず、データセット内の全値の平均を求めます( x 手計算の場合は、数字を足して、その和をその数字の数で割るというようにします。
(1+2+4+5+6+8+9)/7=5
Excelで平均値を求めるには、AVERAGE関数を使用します(例:=AVERAGE(A2:G2)
2.各数値について、平均値を引き、結果を二乗します。
これは、標準偏差の公式で言うところの、( x i - x )2
実際に何が起こっているのかをイメージするために、以下の画像をご覧ください。
この例では、平均が5なので、各データ点と5との差を計算します。
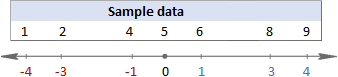
そして、その差を二乗して、すべて正の数にするのです。
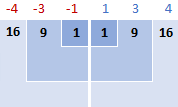
3.差の二乗を足す
数学で「まとめる」と言う場合は、Σ(シグマ)を使います。 そこで、今度は二乗した差を足して、この部分の式を完成させます:Σ( x i - x )2
16 + 9 + 1 + 1 + 9 + 16 = 52
4.二乗差の合計を値の数で割る
これまで、標本標準偏差と母標準偏差の計算式は同じでした。 この時点で、両者は異なっているのです。
については 標本標準偏差 を取得します。 標本分散 は、二乗した差の合計をサンプルサイズから1を引いた値で割ることで算出されます。
52 / (7-1) = 8.67
については 母標準偏差 を見つけることができます。 平均自乗誤差 二乗した差の合計をその数で割ることで、算出される。
52 / 7 = 7.43
なぜこのような違いがあるかというと、標本標準偏差の式では、真の母平均ではなく標本平均の推定値の偏りを補正する必要があるからです。 そして、そのために n - 1 代わりに n であり、ベッセル補正と呼ばれるものである。
5.平方根をとる
最後に、上記の数値の平方根をとれば、標準偏差が求まります(以下の式では、小数点以下2桁を四捨五入しています)。
| サンプル標準偏差 | 母集団標準偏差 |
| √ 8.67 = 2.94 | √ 7.43 = 2.73 |
Microsoft Excelでは、標準偏差は同じように計算されますが、上記の計算はすべて裏で行われています。 重要なのは、適切な標準偏差関数を選ぶことですが、これについては次のセクションがヒントになるでしょう。
Excelで標準偏差を計算する方法
Excelで標準偏差を求める関数は全部で6種類ありますが、どれを使うかは、主に扱うデータの性質(母集団全体かサンプルか)によります。
Excelで標本標準偏差を計算する関数
標本に基づく標準偏差を計算するには、次のいずれかの公式を使用します(いずれも前述の「n-1」法に基づくものです)。
エクセルSTDEV関数
STDEV(番号1,[番号2],...) は、標本に基づいて標準偏差を推定する最も古いExcel関数で、Excel 2003から2019のすべてのバージョンで利用可能です。
Excel 2007以降では、STDEVは数値、配列、名前付き範囲、数値を含むセルへの参照で表される最大255個の引数を受け取ることができます。 Excel 2003では、関数は最大30個の引数しか受け取ることができません。
引数リストで直接与えられた数値の論理値とテキスト表現がカウントされる。 配列と参照では、数値のみがカウントされ、空のセル、TRUEとFALSEの論理値、テキストとエラー値は無視される。
注意:ExcelのSTDEVは古い関数で、後方互換性のために新しいバージョンでも残されています。 しかし、Microsoftは将来のバージョンに関して約束しません。 そのため、Excel 2010以降では、STDEVの代わりにSTDEV.Sを使用することが推奨されます。
エクセルSTDEV.S関数
STDEV.S(番号1,[番号2],...) は、Excel 2010で導入されたSTDEVの改良版です。
STDEVと同様に、STDEV.S関数は、前節で説明した古典的な標本標準偏差の公式に基づいて、一連の値の標本標準偏差を計算します。
エクセルSTDEVA関数
STDEVA(値1, [値2], ...) は、Excel で標本の標準偏差を計算するもう一つの関数です。 上の二つと違うのは、論理値とテキスト値の扱い方だけです。
- すべて 論理値 は,配列や参照に含まれているか,あるいは引数のリストに直接入力されているかにかかわらず,カウントされます(TRUEは1,FALSEは0と評価されます)。
- テキスト値 配列や参照引数内の数値は、空文字列("")、数値のテキスト表現、その他のテキストを含めて0としてカウントされます。 引数のリストで直接与えられた数値のテキスト表現は、それが表す数値としてカウントされます(以下は式の例です)。
- 空白のセルは無視されます。
注意:標本標準偏差の計算式が正しく動作するためには、与えられた引数に少なくとも2つの数値が含まれていなければなりません。そうでない場合は、#DIV/0!
Excelで母集団の標準偏差を計算するための関数
母集団全体を扱う場合は、以下のいずれかの関数を使用して、Excel で標準偏差を計算します。 これらの関数は、「n」メソッドに基づいています。
エクセルSTDEVP関数
STDEVP(番号1,[番号2],...) は、母集団の標準偏差を求めるための古いExcel関数です。
Excel 2010、2013、2016、2019の新バージョンでは、改良されたSTDEV.P関数に置き換えられますが、後方互換性のためにまだ残されています。
エクセルSTDEV.P関数
STDEV.P(番号1,[番号2],...) は、STDEVP関数の精度を向上させた現代版です。 Excel2010以降のバージョンで利用可能です。
STDEVPとSTDEV.P関数は、標本標準偏差と同様に、配列や参照引数内では数値のみをカウントします。 引数リストでは、論理値や数値のテキスト表現もカウントします。
エクセルSTDEVPA関数
STDEVPA(値1, [値2], ...) STDEVPAは、テキストや論理値を含む母集団の標準偏差を計算します。 数値以外の値については、STDEVA関数と全く同じように動作します。
注意:どのExcel標準偏差の計算式を使っても、1つ以上の引数に他の関数が返したエラー値や数値として解釈できないテキストが含まれていると、エラーが返されます。
Excelの標準偏差の関数はどれを使えばいいのか?
エクセルには様々な標準偏差の関数があり、特に経験の浅いユーザーにとっては混乱の元となります。 特定のタスクに適した標準偏差の計算式を選ぶには、次の3つの質問に答えるだけでよいのです。
- 標本や母集団の標準偏差を計算するのですか?
- お使いのExcelのバージョンは?
- データセットには数値だけなのか、論理値やテキストも含まれているのか?
数値に基づき標準偏差を計算する場合 試料 は、Excel 2010 以降では STDEV.S 関数を、Excel 2007 以前では STDEV を使用します。
の標準偏差を求めるには 人口 Excel 2010 以降では STDEV.P 関数を使用し、Excel 2007 以前では STDEVP を使用します。
もし、あなたが 論理的 または テキスト どちらの関数もそれ自体で役に立つシナリオは思いつきませんが、より大きな数式で、1つ以上の引数が他の関数から論理値や数値のテキスト表現として返される場合に便利でしょう。
Excel の標準偏差関数のうち、どの関数が最適かを判断するために、すでに学習した情報をまとめた次の表を確認してください。
| STDEV | STDEV.S | エスティデブピー | STDEV.P | STDEVA | STDEVPA | |
| エクセル版 | 2003 - 2019 | 2010 - 2019 | 2003 - 2019 | 2010 - 2019 | 2003 - 2019 | 2003 - 2019 |
| サンプル | ✓ | ✓ | ✓ | |||
| 人口 | ✓ | ✓ | ✓ | |||
| 配列または参照における論理値 | 無視される | 評価済み (真=1、偽=0) | ||||
| 配列または参照の中のテキスト | 無視される | ゼロとして評価される | ||||
| 引数リストにおける論理値と "text-numbers "について | 評価済み (真=1、偽=0) | |||||
| 空っぽのセル | 無視される | |||||
Excelの標準偏差の計算式の例
一度、データ型に対応する関数を選択すれば、数式を書くのに苦労することはないでしょう。
標本と母集団の標準偏差を計算する
データの性質に応じて、以下の計算式のいずれかを使用してください。
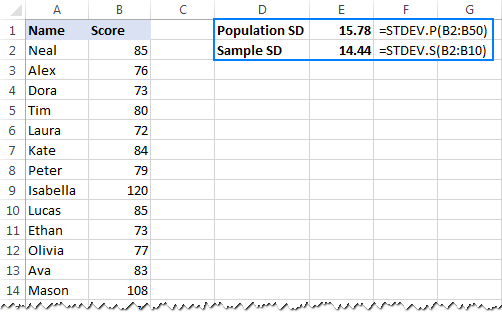
- 全体から標準偏差を算出する場合 人口 つまり、値の完全なリスト(この例ではB2:B50)には、STDEV.P関数を使用します。
=stdev.p(b2:b50) - をもとに標準偏差を求めること。 試料 母集団の一部(この例ではB2:B10)を構成する、STDEV.S関数を使用します。
=stdev.s(b2:b10)
下のスクリーンショットにあるように、計算式はわずかに異なる数値を返します(サンプルが小さいほど、その差は大きくなります)。
Excel 2007以下では、代わりにSTDEVP関数とSTDEV関数を使用することになります。
- 母集団の標準偏差を求めるには
=stdevp(b2:b50) - 標本標準偏差を算出する。
=STDEV(B2:B10)です。
数値のテキスト表現に対する標準偏差の計算
Excelで標準偏差を計算するためのさまざまな関数について説明する際に、「数値のテキスト表現」について触れることがありますが、実際にどういう意味なのか興味があるのではないでしょうか。
ここでいう「数値のテキスト表現」とは、単にテキストとしてフォーマットされた数値のことです。 このような数値は、どのようにしてワークシートに現れるのでしょうか。 多くの場合、外部ソースからエクスポートされます。 あるいは、テキスト文字列を操作するために設計されたいわゆるテキスト関数、例えばTEXT、 MID、 RIGHT、 LEFTなどが返します。 これらの関数の中には、数値も扱えるものがありますが、その出力は常にテキストであり、たとえそれがは、数字によく似ている場合。
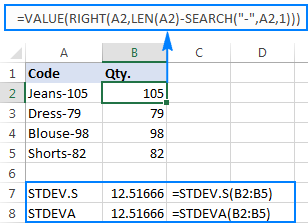
例えば、"Jeans-105 "のように、ハイフン以降の数字が数量を表す商品コードの列があったとする。 目標は、各商品の数量を抽出し、抽出した数値の標準偏差を求めることである。
数量を別の列に引っ張るのは問題ない。
=right(a2,len(a2)-search("-",a2,1)))
問題は、抽出した数値にExcelの標準偏差の計算式を使うと、以下のスクリーンショットに示すように、#DIV/0!または0が返されることです。
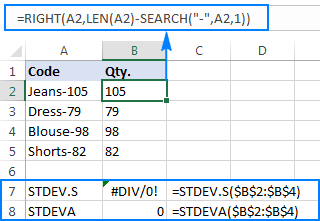
なぜこのような奇妙な結果になるのでしょうか? 前述のように、RIGHT関数の出力は常にテキスト文字列です。 しかし、STDEV.SもSTDEVAもテキストとしてフォーマットされた数値を参照で扱うことができません(前者は単に無視し、後者はゼロとしてカウントします)。 このような「テキスト数値」の標準偏差を取得するには、引数のリストに直接それらを与える必要がありますが、これは、すべてのRIGHT関数をSTDEV.SまたはSTDEVA式に組み込んでください。
=stdev.s(right(a2,len(a2)-search("-",a2,1)), right(a3,len(a3)-search("-",a3,1)), right(a4,len(a4)-search("-",a4,1)),right(a5,len(a5)-search("-",a5,1))))
=stdeva(right(a2,len(a2)-search("-",a2,1)), right(a3,len(a3)-search("-",a3,1)), right(a4,len(a4)-search("-",a4,1)), right(a5,len(a5)-search("-",a5,1))))
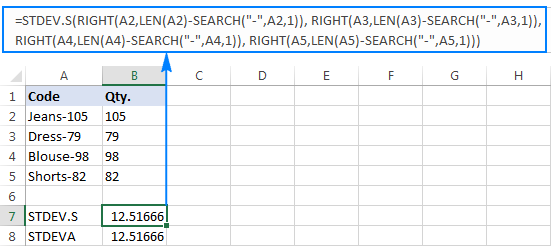
計算式は少し面倒ですが、小さなサンプルでは有効な解決策かもしれません。 大きなサンプル、ましてや母集団全体では、間違いなく選択肢にはなりません。 この場合、VALUE関数で「テキスト数字」を標準偏差の計算式が理解できる数字に変換することで、よりエレガントな解決策となるでしょう(スクリーンショットの右寄せの数字にご注目ください)。上のスクリーンショットでは文字列が左寄せになっていますが、下のスクリーンショットでは左寄せになっています)。
Excelで平均の標準誤差を計算する方法
統計学では、データのばらつきを推定するための尺度がもう一つある--。 平均の標準誤差 標準偏差と平均の標準誤差は密接に関連した概念ですが、同じではありません。
標準偏差がデータセットの平均からのばらつきを測定するのに対し、平均の標準誤差(SEM)は標本平均が真の母平均からどの程度離れているかを推定します。 別の言い方をすれば、同じ母集団から複数の標本を取った場合、平均の標準誤差はそれらの標本平均間の分散を示します。 通常は1つだけ計算するため、標本平均の標準誤差は1つだけです。平均の標準誤差は測定されるのではなく、推定されます。
数学では、平均の標準誤差はこの式で計算される。
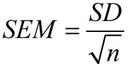
どこ 標準偏差 は標準偏差であり n はサンプルサイズ(サンプルに含まれる値の数)です。
Excelのワークシートでは、COUNT関数でサンプルの値数を、SQRTでその値の平方根を、STDEV.Sでサンプルの標準偏差を計算することができます。
これらをまとめると、Excelの「平均の標準誤差」の式になります。
STDEV.S( レンジ )/SQRT(COUNT()値) レンジ ))サンプルデータがB2:B10であるとすると、SEMの計算式は次のようになります。
=stdev.s(b2:b10)/sqrt(count(b2:b10))
そして、結果はこれに近いかもしれません。

Excelで標準偏差の棒グラフを追加する方法
標準偏差の余裕を視覚的に表示するには、Excelのグラフに標準偏差の棒を追加します。 その方法は次のとおりです。
- 通常の方法でグラフを作成する( インサート tab> チャート のグループ)。
- グラフ上の任意の場所をクリックして選択し、その上で チャートの要素 ボタンをクリックします。
- の横の矢印をクリックします。 エラーバー を選びます。 標準偏差 .
これにより、すべてのデータポイントに同じ標準偏差のバーが挿入されます。

以上、エクセルで標準偏差を行う方法でした。 この情報がお役に立てれば幸いです。 とにかく、お読みいただきありがとうございました!来週のブログでお会いしましょう。
