
Talaan ng nilalaman
Ipinapaliwanag ng tutorial ang kakanyahan ng standard deviation at standard error ng mean pati na rin kung aling formula ang pinakamahusay na gamitin para sa pagkalkula ng standard deviation sa Excel.
Sa descriptive statistics , ang arithmetic mean (tinatawag ding average) at standard deviation at dalawang magkaugnay na konsepto. Ngunit habang ang una ay lubos na nauunawaan ng karamihan, ang huli ay naiintindihan ng iilan. Ang layunin ng tutorial na ito ay magbigay ng kaunting liwanag sa kung ano talaga ang standard deviation at kung paano ito kalkulahin sa Excel.
Ano ang standard deviation?
Ang <8 Ang>standard deviation ay isang sukatan na nagsasaad kung gaano kalaki ang paglihis ng mga value ng set ng data (spread out) mula sa mean. Upang ilagay ito sa ibang paraan, ipinapakita ng standard deviation kung ang iyong data ay malapit sa mean o malaki ang pagbabago.
Ang layunin ng standard deviation ay tulungan kang maunawaan kung ang mean ay talagang nagbabalik ng isang "typical" na data. Kung mas malapit ang standard deviation sa zero, mas mababa ang pagkakaiba-iba ng data at mas maaasahan ang mean. Ang standard deviation na katumbas ng 0 ay nagpapahiwatig na ang bawat value sa dataset ay eksaktong katumbas ng mean. Kung mas mataas ang standard deviation, mas maraming variation ang nasa data at hindi gaanong tumpak ang mean.
Upang makakuha ng mas mahusay na ideya kung paano ito gumagana, mangyaring tingnan ang sumusunod na data:
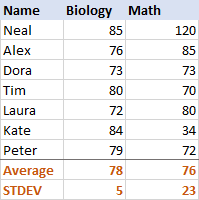
Para sa Biology, ang standard deviationdeviation ng isang sample at populasyon
Depende sa uri ng iyong data, gamitin ang isa sa mga sumusunod na formula:
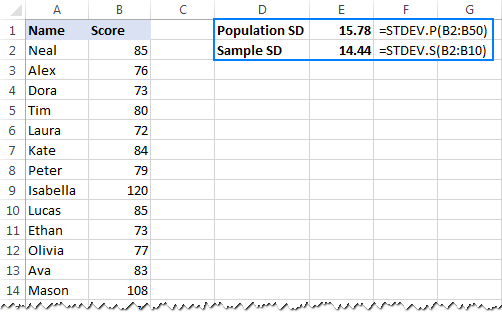
- Upang kalkulahin ang standard deviation batay sa buong populasyon , ibig sabihin, ang buong listahan ng mga value (B2:B50 sa halimbawang ito), gamitin ang STDEV.P function:
=STDEV.P(B2:B50) - Upang mahanap ang standard deviation batay sa isang sample na bumubuo ng bahagi, o subset, ng populasyon (B2:B10 sa halimbawang ito), gamitin ang STDEV.S function:
=STDEV.S(B2:B10)
Tulad ng makikita mo sa screenshot sa ibaba, ang mga formula ay nagbabalik ng bahagyang magkakaibang mga numero (mas maliit ang sample, mas malaki ang pagkakaiba):
Sa Excel 2007 at mas mababa, gagamit ka ng STDEVP at STDEV function sa halip:
- Upang makuha ang standard deviation ng populasyon:
=STDEVP(B2:B50) - Upang kalkulahin ang sample na standard deviation:
=STDEV(B2:B10)
Pagkalkula ng standard deviation para sa mga representasyon ng teksto ng mga numero
Kapag tinatalakay ang iba't ibang mga function upang kalkulahin ang standard deviation sa Excel, minsan binanggit namin ang "text r mga epresentasyon ng mga numero" at maaaring gusto mong malaman kung ano talaga ang ibig sabihin nito.
Sa kontekstong ito, ang "mga representasyon ng teksto ng mga numero" ay mga numero lamang na naka-format bilang teksto. Paano lilitaw ang mga naturang numero sa iyong worksheet? Kadalasan, na-export sila mula sa mga panlabas na mapagkukunan. O, ibinalik ng tinatawag na Text function na idinisenyo upang manipulahin ang mga string ng text, hal. TEXT, GITNA, KANAN, KALIWA,atbp. Ang ilan sa mga function na iyon ay maaari ding gumana sa mga numero, ngunit ang kanilang output ay palaging text, kahit na ito ay mukhang isang numero.
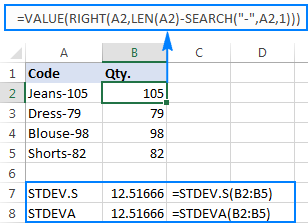
Upang mas mahusay na mailarawan ang punto, mangyaring isaalang-alang ang sumusunod na halimbawa. Ipagpalagay na mayroon kang column ng mga code ng produkto tulad ng "Jeans-105" kung saan ang mga digit pagkatapos ng gitling ay tumutukoy sa dami. Ang iyong layunin ay kunin ang dami ng bawat item, at pagkatapos ay hanapin ang karaniwang paglihis ng mga na-extract na numero.
Ang paghila ng dami sa isa pang column ay hindi problema:
=RIGHT(A2,LEN(A2)-SEARCH("-",A2,1))
Ang problema ay ang paggamit ng Excel standard deviation formula sa mga nakuhang numero ay nagbabalik ng alinman sa #DIV/0! o 0 tulad ng ipinapakita sa screenshot sa ibaba:
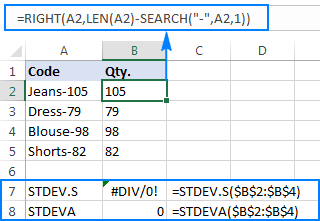
Bakit kakaiba ang mga resulta? Tulad ng nabanggit sa itaas, ang output ng RIGHT function ay palaging isang text string. Ngunit hindi maaaring pangasiwaan ng STDEV.S o STDEVA ang mga numerong naka-format bilang text sa mga sanggunian (binalewala lang ng una ang mga ito habang ang huli ay binibilang bilang mga zero). Upang makuha ang standard deviation ng naturang "text-numbers", kailangan mong direktang ibigay ang mga ito sa listahan ng mga argumento, na maaaring gawin sa pamamagitan ng pag-embed ng lahat ng RIGHT function sa iyong STDEV.S o STDEVA formula:
=STDEV.S(RIGHT(A2,LEN(A2)-SEARCH("-",A2,1)), RIGHT(A3,LEN(A3)-SEARCH("-",A3,1)), RIGHT(A4,LEN(A4)-SEARCH("-",A4,1)), RIGHT(A5,LEN(A5)-SEARCH("-",A5,1)))
=STDEVA(RIGHT(A2,LEN(A2)-SEARCH("-",A2,1)), RIGHT(A3,LEN(A3)-SEARCH("-",A3,1)), RIGHT(A4,LEN(A4)-SEARCH("-",A4,1)), RIGHT(A5,LEN(A5)-SEARCH("-",A5,1)))
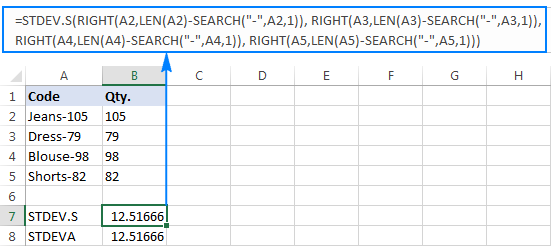
Medyo masalimuot ang mga formula, ngunit maaaring ito ay isang gumaganang solusyon para sa isang maliit na sample. Para sa isang mas malaki, hindi banggitin ang buong populasyon, ito ay tiyak na hindi isang opsyon. Sa kasong ito, ang isang mas eleganteng solusyon ay ang pagkakaroon ngAng VALUE function ay nagko-convert ng "text-numbers" sa mga numero na mauunawaan ng anumang standard deviation formula (pakipansin ang mga numerong nakahanay sa kanan sa screenshot sa ibaba kumpara sa mga string ng text na nakahanay sa kaliwa sa screenshot sa itaas):
Paano kalkulahin ang karaniwang error ng mean sa Excel
Sa mga istatistika, may isa pang sukatan para sa pagtantya ng pagkakaiba-iba sa data - karaniwang error ng mean , na kung minsan ay pinaikli (bagaman, hindi tama) sa "standard error" lamang. Ang standard deviation at standard error ng mean ay dalawang malapit na magkaugnay na konsepto, ngunit hindi pareho.
Habang sinusukat ng standard deviation ang pagkakaiba-iba ng set ng data mula sa mean, ang standard error ng mean (SEM) tinatantya kung gaano kalayo ang sample mean ay malamang na mula sa tunay na populasyon mean. Sinabi ng isa pang paraan - kung kumuha ka ng maraming sample mula sa parehong populasyon, ang karaniwang error ng mean ay magpapakita ng dispersion sa pagitan ng mga sample na paraan. Dahil kadalasan isang mean lang ang kinakalkula namin para sa isang set ng data, hindi ang maramihang paraan, ang karaniwang error ng mean ay tinatantya sa halip na sinusukat.
Sa matematika, ang karaniwang error ng mean ay kinakalkula gamit ang formula na ito:
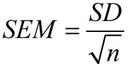
Kung saan ang SD ay ang standard deviation, at ang n ay ang sample size (ang bilang ng mga value sa sample).
Sa iyong mga Excel worksheet, maaari mong gamitin ang COUNT function upang makuha ang numerong mga value sa isang sample, ang SQRT ay kukuha ng square root ng numerong iyon, at STDEV.S upang kalkulahin ang standard deviation ng isang sample.
Pagsasama-sama ng lahat ng ito, makukuha mo ang karaniwang error ng mean formula sa Excel :
STDEV.S( range )/SQRT(COUNT( range ))Ipagpalagay na ang sample na data ay nasa B2:B10, ang aming SEM formula ay mapupunta sa mga sumusunod :
=STDEV.S(B2:B10)/SQRT(COUNT(B2:B10))
At ang resulta ay maaaring katulad nito:

Paano magdagdag ng mga standard deviation bar sa Excel
Upang biswal na magpakita ng margin ng standard deviation, maaari kang magdagdag ng mga standard deviation bar sa iyong Excel chart. Ganito:
- Gumawa ng graph sa karaniwang paraan ( Ipasok tab > Mga Chart pangkat).
- Mag-click kahit saan sa graph upang piliin ito, pagkatapos ay i-click ang button na Mga Elemento ng Chart .
- I-click ang arrow sa tabi ng Mga Error Bar , at piliin ang Standard Deviation .
Ipapasok nito ang parehong standard deviation bar para sa lahat ng data point.

Ito ay kung paano gawin ang standard deviation sa Excel. Umaasa ako na matutulungan mo ang impormasyong ito. Anyway, nagpapasalamat ako sa iyong pagbabasa at sana ay makita kita sa aming blog sa susunod na linggo.
ay 5 (binulong sa isang integer), na nagsasabi sa amin na ang karamihan ng mga marka ay hindi hihigit sa 5 puntos ang layo mula sa mean. Maganda ba yun? Well, oo, ito ay nagpapahiwatig na ang mga marka ng Biology ng mga mag-aaral ay medyo pare-pareho.Para sa Math, ang standard deviation ay 23. Ipinapakita nito na mayroong isang malaking dispersion (pagkalat) sa mga marka, ibig sabihin, ang ilang ang mga mag-aaral ay gumanap nang mas mahusay at/o ang ilan ay gumanap nang mas masahol pa kaysa sa karaniwan.
Sa pagsasagawa, ang karaniwang paglihis ay kadalasang ginagamit ng mga pagsusuri sa negosyo bilang sukatan ng panganib sa pamumuhunan - kung mas mataas ang karaniwang paglihis, mas mataas ang pagkasumpungin ng mga pagbabalik.
Sample na standard deviation vs. Population standard deviation
Kaugnay ng standard deviation, maaaring madalas mong marinig ang mga terminong "sample" at "populasyon", na tumutukoy sa pagkakumpleto ng ang data na iyong pinagtatrabahuhan. Ang pangunahing pagkakaiba ay ang mga sumusunod:
- Populasyon ay kinabibilangan ng lahat ng elemento mula sa isang set ng data.
- Sample ay isang subset ng data na kinabibilangan ng isa o higit pang elemento mula sa populasyon.
Ang mga mananaliksik at pagsusuri ay gumagana sa karaniwang paglihis ng isang sample at populasyon sa iba't ibang sitwasyon. Halimbawa, kapag nagbubuod ng mga marka ng pagsusulit ng isang klase ng mga mag-aaral, gagamitin ng guro ang pamantayang paglihis ng populasyon. Ang mga istatistika sa pagkalkula ng pambansang average na marka ng SAT ay gagamit ng sample na standard deviation dahilang mga ito ay iniharap sa data mula sa isang sample lamang, hindi mula sa buong populasyon.
Pag-unawa sa standard deviation formula
Ang dahilan kung bakit mahalaga ang kalikasan ng data ay dahil ang populasyon na standard deviation at sample ang karaniwang paglihis ay kinakalkula gamit ang bahagyang magkakaibang mga formula:
Sample na karaniwang paglihis | Populasyon na karaniwang paglihis |
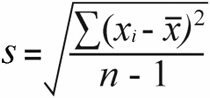 | 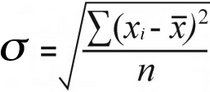 |
Saan:
- <8 Ang> x i ay mga indibidwal na value sa set ng data
- x ang ibig sabihin ng lahat ng x values
- n ay ang kabuuang bilang ng x value sa set ng data
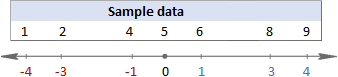
Nahihirapan sa pag-unawa sa mga formula? Maaaring makatulong ang paghahati-hati sa mga ito sa mga simpleng hakbang. Ngunit una, magkaroon tayo ng ilang sample na data na gagawin:

1. Kalkulahin ang mean (average)
Una, makikita mo ang mean ng lahat ng value sa set ng data ( x sa mga formula sa itaas). Kapag nagkalkula gamit ang kamay, idaragdag mo ang mga numero at pagkatapos ay hatiin ang kabuuan sa bilang ng mga numerong iyon, tulad nito:
(1+2+4+5+6+8+9)/7=5
Upang maghanap ng mean sa Excel, gamitin ang AVERAGE function, hal. =AVERAGE(A2:G2)
2. Para sa bawat numero, ibawas ang mean at parisukat ang resulta
Ito ang bahagi ng standard deviation formula na nagsasabing: ( x i - x )2
Upang makita kung ano ang aktwal na nangyayari, mangyaring tingnanang mga sumusunod na larawan.
Sa halimbawang ito, ang mean ay 5, kaya kinakalkula namin ang pagkakaiba sa pagitan ng bawat data point at 5.
Pagkatapos, ikaw ay parisukat ang mga pagkakaiba, ginagawa silang lahat sa positibong numero:
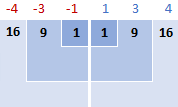
3. Magdagdag ng mga squared differences
Upang sabihin ang "sum things up" sa matematika, gumamit ka ng sigma Σ. Kaya, ang ginagawa natin ngayon ay pagdaragdag ng mga squared differences para makumpleto ang bahaging ito ng formula: Σ( x i - x )2
16 + 9 + 1 + 1 + 9 + 16 = 52
4. Hatiin ang kabuuang squared differences sa bilang ng mga value
Sa ngayon, ang sample na standard deviation at population standard deviation formula ay magkapareho. Sa puntong ito, magkaiba ang mga ito.
Para sa sample standard deviation , makukuha mo ang sample variance sa pamamagitan ng paghahati sa kabuuang squared differences sa sample size na minus 1:
52 / (7-1) = 8.67
Para sa karaniwang deviation ng populasyon , makikita mo ang mean ng mga squared differences sa pamamagitan ng paghahati sa kabuuan mga squared differences ayon sa kanilang bilang:
52 / 7 = 7.43
Bakit ganito ang pagkakaiba sa mga formula? Dahil sa sample na standard deviation formula, kailangan mong iwasto ang bias sa estimation ng sample mean sa halip na ang tunay na population mean. At gagawin mo ito sa pamamagitan ng paggamit ng n - 1 sa halip na n , na tinatawag na pagwawasto ni Bessel.
5. Kunin ang square root
Sa wakas, kunin ang square root ng nasa itaasmga numero, at makukuha mo ang iyong karaniwang paglihis (sa mga equation sa ibaba, na bilugan sa 2 decimal na lugar):
| Sample na standard deviation | Populasyon na standard deviation |
| √ 8.67 = 2.94 | √ 7.43 = 2.73 |
Sa Microsoft Excel, ang standard deviation ay kinukuwenta sa sa parehong paraan, ngunit ang lahat ng mga kalkulasyon sa itaas ay ginagawa sa likod ng eksena. Ang pangunahing bagay para sa iyo ay ang pumili ng tamang standard deviation function, kung saan ang sumusunod na seksyon ay magbibigay sa iyo ng ilang mga pahiwatig.
Paano kalkulahin ang standard deviation sa Excel
Sa pangkalahatan, mayroong anim na magkakaibang function upang mahanap ang standard deviation sa Excel. Alin ang gagamitin ay pangunahing nakadepende sa likas na katangian ng data na pinagtatrabahuhan mo - ito man ay ang buong populasyon o isang sample.
Mga function upang kalkulahin ang sample na standard deviation sa Excel
Upang kalkulahin ang standard paglihis batay sa isang sample, gumamit ng isa sa mga sumusunod na formula (lahat ng mga ito ay batay sa "n-1" na pamamaraan na inilarawan sa itaas).
Excel STDEV function
STDEV(number1,[number2],…) ay ang pinakalumang Excel function upang matantya ang standard deviation batay sa isang sample, at available ito sa lahat ng bersyon ng Excel 2003 hanggang 2019.
Sa Excel 2007 at mas bago, maaaring tumanggap ang STDEV ng hanggang 255 na argumento na maaaring katawanin ng mga numero, array , pinangalanang mga hanay o mga sanggunian sa mga cell na naglalaman ng mga numero. Sa Excel 2003, ang function ay maaari lamang tumanggap ng hanggang sa30 argumento.
Ang mga lohikal na halaga at representasyon ng teksto ng mga numerong direktang ibinigay sa listahan ng mga argumento ay binibilang. Sa mga arrays at reference, mga numero lamang ang binibilang; walang laman na mga cell, lohikal na halaga ng TRUE at FALSE, text at error na mga halaga ay binabalewala.
Tandaan. Ang Excel STDEV ay isang lumang function, na pinananatili sa mga mas bagong bersyon ng Excel para sa backward compatibility lamang. Gayunpaman, walang pangako ang Microsoft tungkol sa mga hinaharap na bersyon. Kaya, sa Excel 2010 at mas bago, inirerekomendang gamitin ang STDEV.S sa halip na STDEV.
Excel STDEV.S function
STDEV.S(number1,[number2],…) ay isang pinahusay na bersyon ng STDEV, na ipinakilala sa Excel 2010.
Tulad ng STDEV, kinakalkula ng STDEV.S function ang sample na standard deviation ng isang set ng mga value batay sa classic na sample na standard deviation formula na tinalakay sa nakaraang seksyon.
Excel STDEVA function
Ang STDEVA(value1, [value2], …) ay isa pang function upang kalkulahin ang standard deviation ng isang sample sa Excel. Naiiba ito sa dalawang nasa itaas lamang sa paraan ng paghawak nito sa mga lohikal at text na halaga:
- Lahat ng lohikal na halaga ay binibilang, kung ang mga ito ay nasa loob ng mga array o reference, o direktang nai-type sa listahan ng mga argumento (TRUE sinusuri bilang 1, FALSE sinusuri bilang 0).
- Ang mga text value sa loob ng mga array o reference na argumento ay binibilang bilang 0, kasama ang mga walang laman na string (""), text representasyon ng mga numero, at anumang iba pang teksto. Mga representasyon ng teksto ngang mga numerong direktang ibinigay sa listahan ng mga argumento ay binibilang bilang mga numerong kinakatawan ng mga ito (narito ang isang halimbawa ng formula).
- Ang mga walang laman na cell ay binabalewala.
Tandaan. Para gumana nang tama ang sample na standard deviation formula, ang mga ibinigay na argumento ay dapat maglaman ng hindi bababa sa dalawang numeric na halaga, kung hindi man ay ang #DIV/0! ibinalik ang error.
Mga function para kalkulahin ang standard deviation ng populasyon sa Excel
Kung tinatalakay mo ang buong populasyon, gamitin ang isa sa sumusunod na function para gawin ang standard deviation sa Excel. Ang mga function na ito ay batay sa "n" na paraan.
Excel STDEVP function
STDEVP(number1,[number2],…) ay ang lumang Excel function upang mahanap ang standard deviation ng isang populasyon.
Sa mga bagong bersyon ng Excel 2010, 2013, 2016 at 2019, ito ay pinalitan ng pinahusay na STDEV.P function, ngunit pinananatili pa rin para sa backward compatibility.
Excel STDEV.P function
STDEV.P(number1,[number2],…) ay ang modernong bersyon ng STDEVP function na nagbibigay ng pinahusay na katumpakan. Available ito sa mga bersyon ng Excel 2010 at mas bago.
Tulad ng kanilang mga sample na standard deviation counterparts, sa loob ng mga arrays o reference na argumento, ang mga function ng STDEVP at STDEV.P ay nagbibilang lamang ng mga numero. Sa listahan ng mga argumento, binibilang din nila ang mga logical value at representasyon ng text ng mga numero.
Kinakalkula ng Excel STDEVPA function
STDEVPA(value1, [value2], …) ang standard deviation ng isang populasyon, kabilang ang text at logical values. Tungkol sa non-numericvalue, gumagana ang STDEVPA tulad ng ginagawa ng STDEVA function.
Tandaan. Alinmang Excel standard deviation formula ang gamitin mo, ito ay magbabalik ng error kung ang isa o higit pang mga argument ay naglalaman ng error value na ibinalik ng isa pang function o text na hindi mabibigyang kahulugan bilang isang numero.
Aling Excel standard deviation function ang gagamitin?
Ang iba't ibang standard deviation function sa Excel ay tiyak na maaaring magdulot ng gulo, lalo na sa mga hindi karanasang user. Para piliin ang tamang standard deviation formula para sa isang partikular na gawain, sagutin lang ang sumusunod na 3 tanong:
- Kinakalkula mo ba ang standard deviation ng isang sample o populasyon?
- Anong bersyon ng Excel ang gagawin mo gamitin?
- Ang iyong data set ba ay nagsasama lamang ng mga numero o lohikal na halaga at text din?
Upang kalkulahin ang standard deviation batay sa isang numeric sample , gamitin ang STDEV.S function sa Excel 2010 at mas bago; STDEV sa Excel 2007 at mas maaga.
Upang mahanap ang standard deviation ng isang populasyon , gamitin ang STDEV.P function sa Excel 2010 at mas bago; STDEVP sa Excel 2007 at mas maaga.
Kung gusto mong maisama ang mga value ng logical o text sa pagkalkula, gamitin ang alinman sa STDEVA (sample standard deviation) o STDEVPA ( pamantayang paglihis ng populasyon). Bagama't wala akong maisip na senaryo kung saan maaaring maging kapaki-pakinabang ang alinmang function sa sarili nito, maaaring magamit ang mga ito sa mas malalaking formula, kung saan ang isa o higit pang mga argumento ay ibinalik ngiba pang mga function bilang mga lohikal na halaga o representasyon ng teksto ng mga numero.
Upang matulungan kang magpasya kung alin sa mga Excel standard deviation function ang pinakaangkop para sa iyong mga pangangailangan, pakisuri ang sumusunod na talahanayan na nagbubuod sa impormasyong natutunan mo na.
| STDEV | STDEV.S | STDEVP | STDEV.P | STDEVA | STDEVPA | |
| Bersyon ng Excel | 2003 - 2019 | 2010 - 2019 | 2003 - 2019 | 2010 - 2019 | 2003 - 2019 | 2003 - 2019 |
| Sample | ✓ | ✓ | ✓ | |||
| Populasyon | ✓ | ✓ | ✓ | |||
| Mga lohikal na halaga sa mga array o mga sanggunian | Hindi pinansin | Nasusuri (TRUE=1, FALSE=0) | ||||
| Text sa mga array o reference | Hindi pinansin | Nasusuri bilang zero | ||||
| Mga lohikal na halaga at "text-numbers" sa listahan ng mga argumento | Nasuri (TRUE =1, FALSE=0) | |||||
| Mga walang laman na cell | <3 4>Balewalain||||||
Mga halimbawa ng excel standard deviation formula
Kapag napili mo na ang function na tumutugma sa uri ng iyong data, hindi dapat magkaroon ng kahirapan sa pagsulat ng formula - ang syntax ay napakalinaw at malinaw na hindi nag-iiwan ng puwang para sa mga error :) Ang mga sumusunod na halimbawa ay nagpapakita ng isang pares ng Excel standard deviation formula na gumagana.
Pagkalkula ng pamantayan
