
INHOUDSOPGAWE
Die tutoriaal verduidelik die essensie van die standaardafwyking en standaardfout van die gemiddelde asook watter formule die beste gebruik kan word vir die berekening van standaardafwyking in Excel.
In beskrywende statistieke , die rekenkundige gemiddelde (ook genoem die gemiddelde) en standaardafwyking en is twee nou verwante konsepte. Maar terwyl eersgenoemde goed deur die meeste verstaan word, word laasgenoemde deur min verstaan. Die doel van hierdie tutoriaal is om lig te werp op wat die standaardafwyking eintlik is en hoe om dit in Excel te bereken.
Wat is standaardafwyking?
Die standaardafwyking is 'n maatstaf wat aandui hoeveel die waardes van die stel data van die gemiddelde afwyk (uitsprei). Om dit anders te stel, die standaardafwyking wys of jou data naby die gemiddelde is of baie fluktueer.
Die doel van die standaardafwyking is om jou te help verstaan of die gemiddelde werklik 'n "tipiese" data gee. Hoe nader die standaardafwyking aan nul is, hoe laer is die dataveranderlikheid en hoe meer betroubaar is die gemiddelde. Die standaardafwyking gelyk aan 0 dui aan dat elke waarde in die datastel presies gelyk is aan die gemiddelde. Hoe hoër die standaardafwyking, hoe meer variasie is daar in die data en hoe minder akkuraat is die gemiddelde.
Om 'n beter idee te kry van hoe dit werk, kyk asseblief na die volgende data:
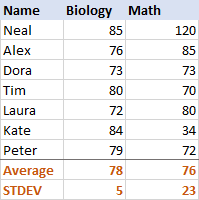
Vir Biologie, die standaardafwykingafwyking van 'n steekproef en populasie
Afhangende van die aard van jou data, gebruik een van die volgende formules:
- Om standaardafwyking te bereken gebaseer op die hele populasie , dit wil sê die volledige lys van waardes (B2:B50 in hierdie voorbeeld), gebruik die STDEV.P-funksie:
=STDEV.P(B2:B50) - Om standaardafwyking gebaseer op 'n steekproef<9 te vind> wat 'n deel, of subset, van die populasie uitmaak (B2:B10 in hierdie voorbeeld), gebruik die STDEV.S-funksie:
=STDEV.S(B2:B10)
Soos jy kan sien in die skermkiekie hieronder, gee die formules effens verskillende getalle (hoe kleiner 'n steekproef, hoe groter 'n verskil):
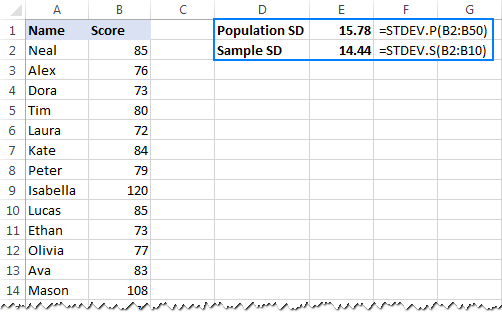
In Excel 2007 en laer, sal jy STDEVP- en STDEV-funksies gebruik plaas:
- Om populasiestandaardafwyking te kry:
=STDEVP(B2:B50) - Om steekproefstandaardafwyking te bereken:
=STDEV(B2:B10)
Berekening van standaardafwyking vir teksvoorstellings van getalle
Wanneer ons verskillende funksies bespreek het om standaardafwyking in Excel te bereken, het ons soms "teks r" genoem voorstellings van getalle" en jy sal dalk nuuskierig wees om te weet wat dit eintlik beteken.
In hierdie konteks is "teksvoorstellings van getalle" bloot getalle wat as teks geformateer is. Hoe kan sulke getalle in jou werkblaaie verskyn? Dikwels word hulle van eksterne bronne uitgevoer. Of, teruggestuur deur sogenaamde Teksfunksies wat ontwerp is om teksstringe te manipuleer, bv. TEKS, MIDDEL, REGS, LINKS,ens. Sommige van daardie funksies kan ook met getalle werk, maar hul uitvoer is altyd teks, selfs al lyk dit baie soos 'n getal.
Om die punt beter te illustreer, oorweeg asseblief die volgende voorbeeld. Gestel jy het 'n kolom van produkkodes soos "Jeans-105" waar die syfers na 'n koppelteken die hoeveelheid aandui. Jou doel is om die hoeveelheid van elke item te onttrek, en dan die standaardafwyking van die onttrekde getalle te vind.
Om die hoeveelheid na 'n ander kolom te trek is nie 'n probleem nie:
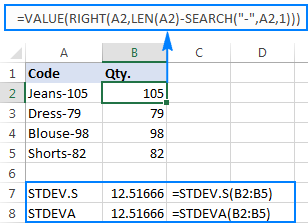
=RIGHT(A2,LEN(A2)-SEARCH("-",A2,1))
Die probleem is dat die gebruik van 'n Excel-standaardafwykingsformule op die onttrekde getalle óf #DIV/0! of 0 soos wat in die skermkiekie hieronder gewys word:
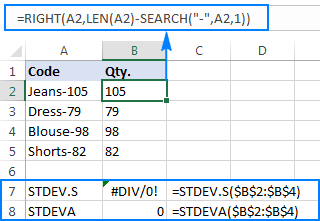
Hoekom sulke vreemde resultate? Soos hierbo genoem, is die uitvoer van die REGS-funksie altyd 'n teksstring. Maar nie STDEV.S of STDEVA kan nommers wat as teks in verwysings geformateer is, hanteer nie (eersgenoemde ignoreer hulle eenvoudig terwyl laasgenoemde as nulle tel). Om die standaardafwyking van sulke "teksnommers" te kry, moet jy hulle direk aan die lys argumente verskaf, wat gedoen kan word deur alle REGTE funksies in jou STDEV.S of STDEVA formule in te sluit:
=STDEV.S(RIGHT(A2,LEN(A2)-SEARCH("-",A2,1)), RIGHT(A3,LEN(A3)-SEARCH("-",A3,1)), RIGHT(A4,LEN(A4)-SEARCH("-",A4,1)), RIGHT(A5,LEN(A5)-SEARCH("-",A5,1)))
=STDEVA(RIGHT(A2,LEN(A2)-SEARCH("-",A2,1)), RIGHT(A3,LEN(A3)-SEARCH("-",A3,1)), RIGHT(A4,LEN(A4)-SEARCH("-",A4,1)), RIGHT(A5,LEN(A5)-SEARCH("-",A5,1)))
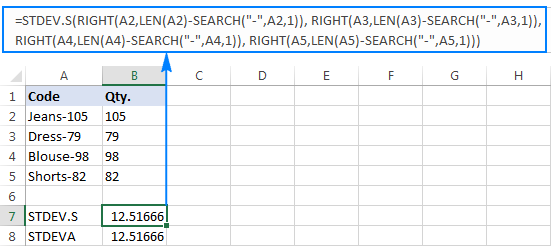
Die formules is 'n bietjie omslagtig, maar dit is dalk 'n werkende oplossing vir 'n klein steekproef. Vir 'n groter een, om nie eens te praat van die hele bevolking nie, is dit beslis nie 'n opsie nie. In hierdie geval sal 'n meer elegante oplossing wees om dieVALUE-funksie skakel "teksnommers" om na getalle wat enige standaardafwykingsformule kan verstaan (let asseblief op die regsbelynde nommers in die skermkiekie hieronder in teenstelling met die linksbelynde teksstringe op die skermkiekie hierbo):
Hoe om standaardfout van gemiddelde in Excel te bereken
In statistiek is daar nog een maatstaf om die veranderlikheid in data te skat - standaardfout van gemiddelde , wat soms (alhoewel, verkeerdelik) verkort word tot net "standaardfout". Die standaardafwyking en standaardfout van die gemiddelde is twee nou verwante konsepte, maar nie dieselfde nie.
Terwyl die standaardafwyking die veranderlikheid van 'n datastel vanaf die gemiddelde meet, meet die standaardfout van die gemiddelde (SEM) skat hoe ver die steekproefgemiddeld waarskynlik van die ware populasiegemiddelde sal wees. Op 'n ander manier gesê - as jy veelvuldige steekproewe uit dieselfde populasie geneem het, sal die standaardfout van die gemiddelde die verspreiding tussen daardie steekproefgemiddeldes toon. Omdat ons gewoonlik net een gemiddelde vir 'n stel data bereken, nie veelvuldige gemiddeldes nie, word die standaardfout van die gemiddelde beraam eerder as gemeet.
In wiskunde word die standaardfout van gemiddelde bereken met hierdie formule:
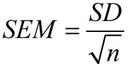
Waar SD die standaardafwyking is, en n die steekproefgrootte is (die aantal waardes in die steekproef).
In jou Excel-werkblaaie kan jy die COUNT-funksie gebruik om die nommer te kryvan waardes in 'n steekproef, SQRT om 'n vierkantswortel van daardie getal te neem, en STDEV.S om standaardafwyking van 'n steekproef te bereken.
As jy dit alles saamvoeg, kry jy die standaardfout van die gemiddelde formule in Excel :
STDEV.S( reeks )/SQRT(COUNT( reeks ))As die steekproefdata in B2:B10 is, sal ons SEM-formule soos volg verloop :
=STDEV.S(B2:B10)/SQRT(COUNT(B2:B10))
En die resultaat is dalk soortgelyk aan hierdie:

Hoe om standaardafwykingsbalkies in Excel by te voeg
Om 'n marge van die standaardafwyking visueel te vertoon, kan jy standaardafwykingsstawe by jou Excel-grafiek voeg. Dit is hoe:
- Skep 'n grafiek op die gewone manier ( Voeg in -oortjie > Charts -groep).
- Klik enige plek op die grafiek om dit te kies, klik dan op die Kaartelemente -knoppie.
- Klik op die pyltjie langs Foutstawe , en kies Standaardafwyking .
Dit sal dieselfde standaardafwykingsstawe vir alle datapunte invoeg.

Dit is hoe om standaardafwyking op Excel te doen. Ek hoop jy sal hierdie inligting nuttig vind. In elk geval, ek bedank jou vir die lees en hoop om jou volgende week op ons blog te sien.
is 5 (afgerond tot 'n heelgetal), wat vir ons sê dat die meeste tellings nie meer as 5 punte van die gemiddelde af is nie. Is dit goed? Wel, ja, dit dui aan dat die Biologie-tellings van die studente redelik konsekwent is.Vir Wiskunde is die standaardafwyking 23. Dit wys dat daar 'n groot verspreiding (verspreiding) in die tellings is, wat beteken dat sommige studente het baie beter gevaar en/of sommige het baie swakker as die gemiddelde gevaar.
In die praktyk word die standaardafwyking dikwels deur sake-ontleders gebruik as 'n maatstaf van beleggingsrisiko - hoe hoër die standaardafwyking, hoe hoër is die wisselvalligheid van die opbrengste.
Voorbeeldstandaardafwyking vs. Bevolkingstandaardafwyking
In verband met standaardafwyking hoor jy dalk dikwels die terme "steekproef" en "bevolking", wat verwys na die volledigheid van die data waarmee jy werk. Die belangrikste verskil is soos volg:
- Bevolking sluit al die elemente van 'n datastel in.
- Voorbeeld is 'n subset van data wat een of meer elemente uit die populasie insluit.
Navorsers en ontleders werk op die standaardafwyking van 'n steekproef en populasie in verskillende situasies. Byvoorbeeld, wanneer 'n onderwyser die eksamentellings van 'n klas studente opsom, sal 'n onderwyser die populasiestandaardafwyking gebruik. Statistici wat die nasionale SAT gemiddelde telling bereken sal 'n steekproef standaardafwyking gebruik omdathulle word slegs met die data van 'n steekproef aangebied, nie van die hele populasie nie.
Begrip van die standaardafwykingsformule
Die rede waarom die aard van die data belangrik is, is omdat die populasiestandaardafwyking en steekproef standaardafwyking word met effens verskillende formules bereken:
Voorbeeld standaardafwyking | Bevolkingstandaardafwyking |
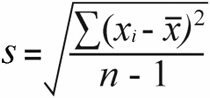 | 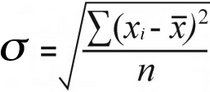 |
Waar:
- x i is individuele waardes in die stel data
- x is die gemiddelde van alle x waardes
- n is die totale aantal x waardes in die datastel
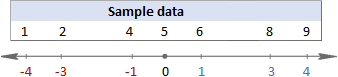
Het jy probleme om die formules te verstaan? Dit kan help om hulle in eenvoudige stappe op te deel. Maar eers, laat ons 'n paar voorbeelddata hê om aan te werk:

1. Bereken die gemiddelde (gemiddeld)
Eers vind jy die gemiddelde van alle waardes in die datastel ( x in die formules hierbo). Wanneer jy met die hand bereken, tel jy die getalle bymekaar en deel dan die som deur die getal van daardie getalle, soos volg:
(1+2+4+5+6+8+9)/7=5
Om gemiddelde in Excel te vind, gebruik die AVERAGE-funksie, bv. =GEmiddeld(A2:G2)
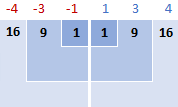
2. Vir elke getal, trek die gemiddelde af en kwadraat die resultaat
Dit is die deel van die standaardafwykingsformule wat sê: ( x i - x )2
Om te visualiseer wat werklik aangaan, kyk asseblief nadie volgende beelde.
In hierdie voorbeeld is die gemiddelde 5, so ons bereken die verskil tussen elke datapunt en 5.
Dan vier jy die verskille, en verander hulle almal in positiewe getalle:
3. Tel kwadraatverskille by
Om "som dinge op" in wiskunde te sê, gebruik jy sigma Σ. Dus, wat ons nou doen, is om die kwadraatverskille by te tel om hierdie deel van die formule te voltooi: Σ( x i - x )2
16 + 9 + 1 + 1 + 9 + 16 = 52
4. Verdeel die totale kwadraatverskille deur die telling van waardes
Tot dusver was die steekproefstandaardafwyking en populasiestandaardafwykingsformules identies. Op hierdie stadium is hulle anders.
Vir die steekproefstandaardafwyking kry jy die steekproefafwyking deur die totale kwadraatverskille deur die steekproefgrootte minus 1 te deel:
52 / (7-1) = 8.67
Vir die bevolkingstandaardafwyking vind jy die gemiddelde van kwadraatverskille deur die totaal te deel kwadraat verskille volgens hul telling:
52 / 7 = 7.43
Waarom hierdie verskil in die formules? Want in die steekproefstandaardafwykingsformule moet jy die vooroordeel in die skatting van 'n steekproefgemiddeld in plaas van die ware populasiegemiddeld regstel. En jy doen dit deur n - 1 te gebruik in plaas van n , wat Bessel se regstelling genoem word.
5. Neem die vierkantswortel
Ten slotte, neem die vierkantswortel van bogenoemdegetalle, en jy sal jou standaardafwyking kry (in die onderstaande vergelykings, afgerond tot 2 desimale plekke):
| Voorbeeld standaardafwyking | Bevolkingstandaardafwyking |
| √ 8.67 = 2.94 | √ 7.43 = 2.73 |
In Microsoft Excel word standaardafwyking bereken in die dieselfde manier, maar al die bogenoemde berekeninge word agter die toneel uitgevoer. Die belangrikste ding vir jou is om 'n behoorlike standaardafwyking funksie te kies, waaroor die volgende afdeling vir jou 'n paar leidrade sal gee.
Hoe om standaardafwyking in Excel te bereken
Algeheel is daar ses verskillende funksies om standaardafwyking in Excel te vind. Watter een om te gebruik hang hoofsaaklik af van die aard van die data waarmee jy werk - of dit die hele populasie of 'n steekproef is.
Funksies om steekproefstandaardafwyking in Excel te bereken
Om standaard te bereken afwyking gebaseer op 'n steekproef, gebruik een van die volgende formules (almal van hulle is gebaseer op die "n-1" metode hierbo beskryf).
Excel STDEV funksie
STDEV(number1,[number2],…) is die oudste Excel funksie om standaardafwyking te skat gebaseer op 'n steekproef, en dit is beskikbaar in alle weergawes van Excel 2003 tot 2019.
In Excel 2007 en later kan STDEV tot 255 argumente aanvaar wat deur getalle, skikkings voorgestel kan word , benoemde reekse of verwysings na selle wat nommers bevat. In Excel 2003 kan die funksie slegs aanvaar tot30 argumente.
Logiese waardes en teksvoorstellings van getalle wat direk in die lys argumente verskaf word, word getel. In skikkings en verwysings word slegs getalle getel; leë selle, logiese waardes van WAAR en ONWAAR, teks- en foutwaardes word geïgnoreer.
Let wel. Excel STDEV is 'n verouderde funksie wat slegs in die nuwer weergawes van Excel gehou word vir terugwaartse versoenbaarheid. Microsoft maak egter geen beloftes oor die toekomstige weergawes nie. Dus, in Excel 2010 en later, word dit aanbeveel om STDEV.S in plaas van STDEV te gebruik.
Excel STDEV.S-funksie
STDEV.S(number1,[number2],…) is 'n verbeterde weergawe van STDEV, bekendgestel in Excel 2010.
Soos STDEV, bereken die STDEV.S-funksie die steekproefstandaardafwyking van 'n stel waardes gebaseer op die klassieke steekproefstandaardafwykingsformule wat in die vorige afdeling bespreek is.
Excel STDEVA-funksie
STDEVA(value1, [value2], …) is 'n ander funksie om standaardafwyking van 'n steekproef in Excel te bereken. Dit verskil slegs van die bogenoemde twee in die manier waarop dit logiese en tekswaardes hanteer:
- Alle logiese waardes word getel, of hulle binne skikkings of verwysings vervat is, of direk getik word in die lys argumente (WAAR evalueer as 1, ONWAAR evalueer as 0).
- Tekswaardes binne skikkings of verwysingsargumente word as 0 getel, insluitend leë stringe (""), teks voorstellings van getalle en enige ander teks. Teksvoorstellings vangetalle wat direk in die lys argumente verskaf word, word getel as die getalle wat hulle verteenwoordig (hier is 'n formulevoorbeeld).
- Leë selle word geïgnoreer.
Let wel. Vir 'n voorbeeldstandaardafwykingformule om korrek te werk, moet die verskafde argumente ten minste twee numeriese waardes bevat, anders die #DIV/0! fout word teruggestuur.
Funksies om populasiestandaardafwyking in Excel te bereken
As jy met die hele populasie te doen het, gebruik een van die volgende funksie om standaardafwyking in Excel te doen. Hierdie funksies is gebaseer op die "n" metode.
Excel STDEVP-funksie
STDEVP(number1,[number2],…) is die ou Excel-funksie om standaardafwyking van 'n populasie te vind.
In die nuwe weergawes van Excel 2010, 2013, 2016 en 2019, word dit vervang met die verbeterde STDEV.P-funksie, maar word steeds gehou vir terugwaartse versoenbaarheid.
Excel STDEV.P-funksie
STDEV.P(number1,[number2],…) is die moderne weergawe van die STDEVP-funksie wat 'n verbeterde akkuraatheid bied. Dit is beskikbaar in Excel 2010 en later weergawes.
Soos hul voorbeeld standaardafwyking eweknieë, binne skikkings of verwysingsargumente, tel die STDEVP en STDEV.P funksies slegs getalle. In die lys argumente tel hulle ook logiese waardes en teksvoorstellings van getalle.
Excel STDEVPA-funksie
STDEVPA(value1, [value2], …) bereken standaardafwyking van 'n populasie, insluitend teks en logiese waardes. Met betrekking tot nie-numeriesewaardes, STDEVPA werk presies soos die STDEVA funksie doen.
Let wel. Watter Excel-standaardafwykingsformule ook al jy gebruik, dit sal 'n fout terugstuur as een of meer argumente 'n foutwaarde bevat wat deur 'n ander funksie of teks teruggestuur word wat nie as 'n getal geïnterpreteer kan word nie.
Watter Excel-standaardafwykingfunksie om te gebruik?
'n Verskeidenheid standaardafwykingsfunksies in Excel kan beslis 'n gemors veroorsaak, veral vir onervare gebruikers. Om die korrekte standaardafwykingformule vir 'n spesifieke taak te kies, beantwoord net die volgende 3 vrae:
- Bereken jy standaardafwyking van 'n steekproef of populasie?
- Watter Excel-weergawe het jy gebruik?
- Sluit jou datastel net syfers of logiese waardes en teks ook in?
Om standaardafwyking gebaseer op 'n numeriese steekproef te bereken, gebruik die STDEV.S-funksie in Excel 2010 en later; STDEV in Excel 2007 en vroeër.
Om standaardafwyking van 'n populasie te vind, gebruik die STDEV.P-funksie in Excel 2010 en later; STDEVP in Excel 2007 en vroeër.
As jy wil hê dat logiese of teks waardes by die berekening ingesluit moet word, gebruik óf STDEVA (voorbeeld standaardafwyking) óf STDEVPA ( bevolking standaardafwyking). Alhoewel ek nie aan enige scenario kan dink waarin enige funksie op sy eie nuttig kan wees nie, kan hulle handig te pas kom in groter formules, waar een of meer argumente teruggestuur word deurander funksies as logiese waardes of teksvoorstellings van getalle.
Om jou te help besluit watter van die Excel-standaardafwykingsfunksies die beste by jou behoeftes pas, hersien asseblief die volgende tabel wat die inligting wat jy reeds geleer het, opsom.
| STDEV | STDEV.S | STDEV | STDEV.P | STDEVA | STDEVPA | |
| Excel-weergawe | 2003 - 2019 | 2010 - 2019 | 2003 - 2019 | 2010 - 2019 | 2003 - 2019 | 2003 - 2019 |
| Voorbeeld | ✓ | ✓ | ✓ | |||
| Bevolking | ✓ | ✓ | ✓ | |||
| Logiese waardes in skikkings of verwysings | Ignoreer | Geëvalueer (WAAR=1, ONWAAR=0) | ||||
| Teks in skikkings of verwysings | Ignoreer | Geëvalueer as nul | ||||
| Logiese waardes en "teksnommers" in die lys argumente | Geëvalueer (WAAR) =1, ONWAAR=0) | |||||
| Leë selle | <3 4>Ignoreer||||||
Excel standaardafwyking formule voorbeelde
Sodra jy die funksie gekies het wat ooreenstem met jou datatipe, behoort daar geen probleme te wees om die formule - die sintaksis is so eenvoudig en deursigtig dat dit geen ruimte vir foute laat nie :) Die volgende voorbeelde demonstreer 'n paar Excel-standaardafwykingsformules in aksie.
Bereken standaard.
