
فہرست کا خانہ
ٹیوٹوریل معیاری انحراف اور اوسط کی معیاری غلطی کے جوہر کی وضاحت کرتا ہے اور ساتھ ہی ایکسل میں معیاری انحراف کا حساب لگانے کے لیے کون سا فارمولہ استعمال کرنا بہتر ہے۔
تفصیلی اعدادوشمار میں ، ریاضی کا مطلب (جسے اوسط بھی کہا جاتا ہے) اور معیاری انحراف اور دو قریب سے متعلق تصورات ہیں۔ لیکن جب کہ پہلے کو زیادہ تر لوگ اچھی طرح سمجھتے ہیں، لیکن بعد والے کو بہت کم لوگ سمجھتے ہیں۔ اس ٹیوٹوریل کا مقصد اس بات پر کچھ روشنی ڈالنا ہے کہ معیاری انحراف دراصل کیا ہے اور اسے Excel میں کیسے شمار کیا جائے۔
معیاری انحراف کیا ہے؟
The <8 معیاری انحراف ایک ایسا پیمانہ ہے جو اس بات کی نشاندہی کرتا ہے کہ ڈیٹا کے سیٹ کی قدریں وسط سے کتنی ہٹ جاتی ہیں۔ اسے مختلف انداز میں بیان کرنے کے لیے، معیاری انحراف یہ ظاہر کرتا ہے کہ آیا آپ کا ڈیٹا اوسط کے قریب ہے یا بہت زیادہ اتار چڑھاؤ آتا ہے۔
معیاری انحراف کا مقصد آپ کو یہ سمجھنے میں مدد کرنا ہے کہ کیا مطلب واقعی ایک "عام" ڈیٹا لوٹاتا ہے۔ معیاری انحراف صفر کے جتنا قریب ہوگا، ڈیٹا کی تغیرات اتنی ہی کم ہوں گی اور وسط اتنا ہی قابل اعتماد ہوگا۔ 0 کے برابر معیاری انحراف اس بات کی نشاندہی کرتا ہے کہ ڈیٹاسیٹ میں ہر قدر اوسط کے بالکل برابر ہے۔ معیاری انحراف جتنا زیادہ ہوگا، اعداد و شمار میں اتنا ہی زیادہ تغیر ہوگا اور اوسط اتنا ہی کم درست ہوگا۔
یہ کیسے کام کرتا ہے اس کا بہتر اندازہ حاصل کرنے کے لیے، براہ کرم درج ذیل ڈیٹا پر ایک نظر ڈالیں:
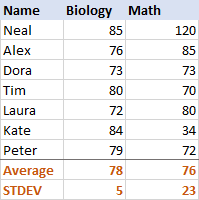
حیاتیات کے لیے، معیاری انحرافنمونے اور آبادی کا انحراف
اپنے ڈیٹا کی نوعیت پر منحصر ہے، درج ذیل فارمولوں میں سے ایک کا استعمال کریں:
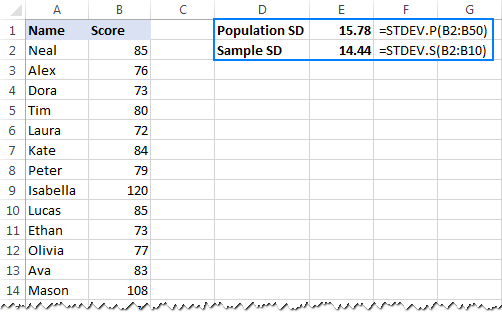
- پوری آبادی<9 کی بنیاد پر معیاری انحراف کا حساب لگانے کے لیے>، یعنی اقدار کی مکمل فہرست (اس مثال میں B2:B50)، STDEV.P فنکشن استعمال کریں:
=STDEV.P(B2:B50) - کسی نمونہ<9 کی بنیاد پر معیاری انحراف تلاش کرنے کے لیے> جو آبادی کا ایک حصہ، یا سب سیٹ بناتا ہے (اس مثال میں B2:B10)، STDEV.S فنکشن استعمال کریں:
=STDEV.S(B2:B10)
جیسا کہ آپ اس میں دیکھ سکتے ہیں۔ ذیل میں اسکرین شاٹ، فارمولے قدرے مختلف نمبر لوٹتے ہیں (جتنا چھوٹا نمونہ، اتنا ہی بڑا فرق):
ایکسل 2007 اور اس سے کم میں، آپ STDEVP اور STDEV فنکشنز استعمال کریں گے۔ اس کی بجائے:
- آبادی کا معیاری انحراف حاصل کرنے کے لیے:
=STDEVP(B2:B50) - نمونہ معیاری انحراف کا حساب لگانے کے لیے:
=STDEV(B2:B10)
نمبروں کی متنی نمائندگی کے لیے معیاری انحراف کا حساب لگانا
ایکسل میں معیاری انحراف کا حساب لگانے کے لیے مختلف فنکشنز پر بحث کرتے وقت، ہم نے بعض اوقات "ٹیکسٹ آر نمبرز کی نمائش" اور آپ یہ جاننے کے لیے متجسس ہو سکتے ہیں کہ اصل میں اس کا کیا مطلب ہے۔
اس تناظر میں، "نمبروں کی متنی نمائندگی" صرف نمبرز ہیں جنہیں متن کے طور پر فارمیٹ کیا گیا ہے۔ آپ کی ورک شیٹس میں ایسے نمبر کیسے ظاہر ہو سکتے ہیں؟ اکثر، وہ بیرونی ذرائع سے برآمد کر رہے ہیں. یا، نام نہاد ٹیکسٹ فنکشنز کے ذریعے لوٹایا گیا جو ٹیکسٹ سٹرنگز کو ہیر پھیر کرنے کے لیے ڈیزائن کیا گیا ہے، جیسے متن، درمیانی، دائیں، بائیں،وغیرہ۔ ان میں سے کچھ فنکشنز نمبرز کے ساتھ بھی کام کر سکتے ہیں، لیکن ان کا آؤٹ پٹ ہمیشہ ٹیکسٹ ہوتا ہے، چاہے وہ کسی نمبر کی طرح ہی کیوں نہ ہو۔
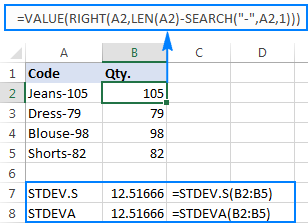
نقطے کو بہتر انداز میں بیان کرنے کے لیے، براہ کرم درج ذیل مثال پر غور کریں۔ فرض کریں کہ آپ کے پاس پروڈکٹ کوڈز کا ایک کالم ہے جیسے "Jeans-105" جہاں ہائفن کے بعد کے ہندسے مقدار کو ظاہر کرتے ہیں۔ آپ کا مقصد ہر آئٹم کی مقدار کو نکالنا ہے، اور پھر نکالے گئے نمبروں کا معیاری انحراف تلاش کرنا ہے۔
مقدار کو دوسرے کالم میں کھینچنا کوئی مسئلہ نہیں ہے:
=RIGHT(A2,LEN(A2)-SEARCH("-",A2,1))
مسئلہ یہ ہے کہ نکالے گئے نمبروں پر ایکسل معیاری انحراف فارمولہ استعمال کرنے سے یا تو #DIV/0! یا 0 جیسا کہ ذیل کے اسکرین شاٹ میں دکھایا گیا ہے:
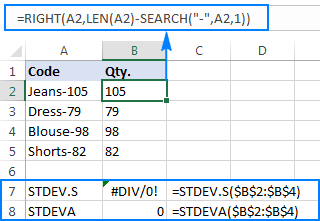
ایسے عجیب و غریب نتائج کیوں؟ جیسا کہ اوپر بتایا گیا ہے، RIGHT فنکشن کا آؤٹ پٹ ہمیشہ ٹیکسٹ سٹرنگ ہوتا ہے۔ لیکن نہ تو STDEV.S اور نہ ہی STDEVA حوالہ جات میں متن کے طور پر فارمیٹ کردہ نمبروں کو ہینڈل کر سکتے ہیں (سابقہ صرف ان کو نظر انداز کر دیتا ہے جب کہ مؤخر الذکر کو صفر کے طور پر شمار کیا جاتا ہے)۔ اس طرح کے "ٹیکسٹ نمبرز" کا معیاری انحراف حاصل کرنے کے لیے، آپ کو انہیں براہ راست دلائل کی فہرست میں فراہم کرنے کی ضرورت ہے، جو آپ کے STDEV.S یا STDEVA فارمولے میں تمام RIGHT فنکشنز کو سرایت کر کے کیا جا سکتا ہے:
=STDEV.S(RIGHT(A2,LEN(A2)-SEARCH("-",A2,1)), RIGHT(A3,LEN(A3)-SEARCH("-",A3,1)), RIGHT(A4,LEN(A4)-SEARCH("-",A4,1)), RIGHT(A5,LEN(A5)-SEARCH("-",A5,1)))
=STDEVA(RIGHT(A2,LEN(A2)-SEARCH("-",A2,1)), RIGHT(A3,LEN(A3)-SEARCH("-",A3,1)), RIGHT(A4,LEN(A4)-SEARCH("-",A4,1)), RIGHT(A5,LEN(A5)-SEARCH("-",A5,1)))
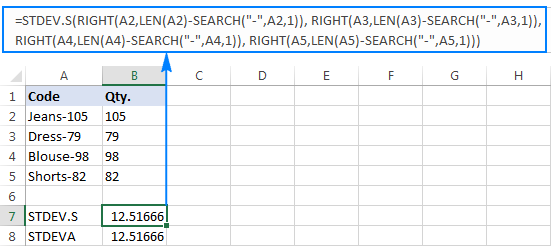
فارمولے قدرے بوجھل ہیں، لیکن یہ ایک چھوٹے نمونے کے لیے کام کرنے والا حل ہوسکتا ہے۔ ایک بڑے کے لیے، پوری آبادی کا ذکر نہ کرنا، یہ یقینی طور پر کوئی آپشن نہیں ہے۔ اس صورت میں، ایک زیادہ خوبصورت حل ہو جائے گاVALUE فنکشن "ٹیکسٹ نمبرز" کو ان نمبروں میں تبدیل کرتا ہے جسے کوئی بھی معیاری انحراف فارمولہ سمجھ سکتا ہے (براہ کرم نیچے دیے گئے اسکرین شاٹ میں دائیں سیدھ والے نمبرز کو نوٹ کریں جیسا کہ اوپر اسکرین شاٹ پر بائیں طرف سے منسلک ٹیکسٹ سٹرنگز کے برعکس ہے):
ایکسل میں اوسط کی معیاری غلطی کا حساب کیسے لگائیں
اعداد و شمار میں، ڈیٹا میں تغیر کا اندازہ لگانے کے لیے ایک اور پیمانہ ہے - اوسط کی معیاری خرابی ، جسے بعض اوقات مختصر کر دیا جاتا ہے (اگرچہ، غلط طریقے سے) صرف "معیاری غلطی"۔ معیاری انحراف اور اوسط کی معیاری خرابی دو قریب سے متعلق تصورات ہیں، لیکن ایک جیسے نہیں ہیں۔
جبکہ معیاری انحراف وسط سے سیٹ کردہ ڈیٹا کی تغیر کو ماپتا ہے، وسط کی معیاری خرابی (SEM) اندازہ لگاتا ہے کہ نمونہ کا مطلب حقیقی آبادی کے اوسط سے کتنا دور ہے۔ دوسرے طریقے سے کہا - اگر آپ ایک ہی آبادی سے متعدد نمونے لیتے ہیں، تو اوسط کی معیاری غلطی ان نمونوں کے ذرائع کے درمیان پھیلاؤ کو ظاہر کرے گی۔ چونکہ عام طور پر ہم اعداد و شمار کے سیٹ کے لیے صرف ایک مطلب کا حساب لگاتے ہیں، متعدد ذرائع کا نہیں، اس لیے اوسط کی معیاری غلطی کا اندازہ ناپا جانے کے بجائے لگایا جاتا ہے۔
ریاضی میں، اوسط کی معیاری غلطی کا حساب اس فارمولے سے کیا جاتا ہے:
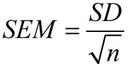
جہاں SD معیاری انحراف ہے، اور n نمونہ کا سائز ہے (نمونہ میں اقدار کی تعداد)۔
آپ کی ایکسل ورک شیٹس میں، آپ نمبر حاصل کرنے کے لیے COUNT فنکشن استعمال کر سکتے ہیں۔نمونے میں قدروں کا، اس نمبر کا مربع جڑ لینے کے لیے SQRT، اور نمونے کے معیاری انحراف کا حساب لگانے کے لیے STDEV.S۔
ان سب کو ایک ساتھ رکھنے سے، آپ کو ایکسل میں اوسط فارمولے کی معیاری خرابی ملتی ہے۔ :
STDEV.S( range )/SQRT(COUNT( range ))یہ فرض کرتے ہوئے کہ نمونہ ڈیٹا B2:B10 میں ہے، ہمارا SEM فارمولہ مندرجہ ذیل ہوگا۔ :
=STDEV.S(B2:B10)/SQRT(COUNT(B2:B10))
اور نتیجہ اس سے ملتا جلتا ہو سکتا ہے:
40>
ایکسل میں معیاری انحراف بارز کیسے شامل کریں
معیاری انحراف کے مارجن کو بصری طور پر ظاہر کرنے کے لیے، آپ اپنے ایکسل چارٹ میں معیاری ڈیوی ایشن بارز شامل کر سکتے ہیں۔ یہاں طریقہ ہے:
- معمول کے طریقے سے ایک گراف بنائیں ( داخل کریں ٹیب > چارٹس گروپ)۔
- پر کہیں بھی کلک کریں۔ اسے منتخب کرنے کے لیے گراف پر کلک کریں، پھر چارٹ عناصر بٹن پر کلک کریں۔
- خرابی بارز کے آگے تیر پر کلک کریں، اور معیاری انحراف کو منتخب کریں۔
یہ تمام ڈیٹا پوائنٹس کے لیے یکساں معیاری انحراف بار داخل کرے گا۔
43>
ایکسل پر معیاری انحراف کرنے کا طریقہ یہ ہے۔ مجھے امید ہے کہ آپ کو یہ معلومات کارآمد ثابت ہوں گی۔ بہرحال، میں پڑھنے کے لیے آپ کا شکریہ ادا کرتا ہوں اور امید کرتا ہوں کہ آپ کو اگلے ہفتے ہمارے بلاگ پر ملوں گا۔
5 ہے (انٹیجر پر گول)، جو ہمیں بتاتا ہے کہ اسکور کی اکثریت اوسط سے 5 پوائنٹس سے زیادہ دور نہیں ہے۔ کیا یہ اچھا ہے؟ ٹھیک ہے، ہاں، یہ اس بات کی نشاندہی کرتا ہے کہ طالب علموں کے حیاتیات کے اسکور کافی حد تک مطابقت رکھتے ہیں۔ریاضی کے لیے، معیاری انحراف 23 ہے۔ یہ ظاہر کرتا ہے کہ اسکورز میں بہت بڑا پھیلاؤ (پھیلاؤ) ہے، یعنی کچھ طلباء نے بہت بہتر کارکردگی کا مظاہرہ کیا اور/یا کچھ نے اوسط سے کہیں زیادہ خراب کارکردگی کا مظاہرہ کیا۔
عملی طور پر، معیاری انحراف کو اکثر کاروباری تجزیہ کار سرمایہ کاری کے خطرے کی پیمائش کے طور پر استعمال کرتے ہیں - معیاری انحراف جتنا زیادہ ہوگا، اتار چڑھاؤ اتنا ہی زیادہ ہوگا۔ واپسیوں کا۔
نمونہ معیاری انحراف بمقابلہ آبادی معیاری انحراف
معیاری انحراف کے سلسلے میں، آپ اکثر "نمونہ" اور "آبادی" کی اصطلاحات سن سکتے ہیں، جو کہ مکمل ہونے کا حوالہ دیتے ہیں۔ ڈیٹا جس کے ساتھ آپ کام کر رہے ہیں۔ بنیادی فرق مندرجہ ذیل ہے:
- آبادی میں ڈیٹا سیٹ کے تمام عناصر شامل ہیں۔
- Sample کا سب سیٹ ہے۔ ڈیٹا جس میں آبادی کے ایک یا زیادہ عناصر شامل ہوتے ہیں۔
محققین اور تجزیہ کار مختلف حالات میں نمونے اور آبادی کے معیاری انحراف پر کام کرتے ہیں۔ مثال کے طور پر، طلباء کی کلاس کے امتحانی اسکور کا خلاصہ کرتے وقت، ایک استاد آبادی کے معیاری انحراف کا استعمال کرے گا۔ قومی SAT اوسط سکور کا حساب لگانے والے شماریات نمونہ معیاری انحراف کا استعمال کریں گے کیونکہوہ صرف ایک نمونے کے اعداد و شمار کے ساتھ پیش کیے جاتے ہیں، نہ کہ پوری آبادی سے۔
معیاری انحراف کے فارمولے کو سمجھنا
ڈیٹا کی نوعیت اہم ہونے کی وجہ یہ ہے کہ آبادی کا معیاری انحراف اور نمونہ معیاری انحراف کا حساب قدرے مختلف فارمولوں کے ساتھ کیا جاتا ہے:
نمونہ معیاری انحراف | آبادی معیاری انحراف | <21 |||||

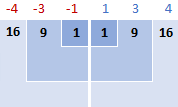
| نمونہ معیاری انحراف | آبادی کا معیاری انحراف |
| √ 8.67 = 2.94 | √ 7.43 = 2.73 |
مائیکروسافٹ ایکسل میں، معیاری انحراف کی گنتی اسی طرح، لیکن اوپر کے تمام حسابات پردے کے پیچھے کیے جاتے ہیں۔ آپ کے لیے اہم چیز ایک مناسب معیاری انحراف کا انتخاب کرنا ہے، جس کے بارے میں درج ذیل سیکشن آپ کو کچھ اشارے فراہم کرے گا۔
ایکسل میں معیاری انحراف کا حساب کیسے لگایا جائے
مجموعی طور پر، چھ مختلف ہیں ایکسل میں معیاری انحراف تلاش کرنے کے افعال۔ کون سا استعمال کرنا ہے اس کا انحصار بنیادی طور پر اس ڈیٹا کی نوعیت پر ہے جس کے ساتھ آپ کام کر رہے ہیں - چاہے وہ پوری آبادی ہو یا نمونہ۔
ایکسل میں نمونے کے معیاری انحراف کا حساب لگانے کے فنکشنز
معیاری کا حساب لگانا نمونے کی بنیاد پر انحراف، درج ذیل فارمولوں میں سے ایک استعمال کریں (یہ سب اوپر بیان کردہ "n-1" طریقہ پر مبنی ہیں)۔
Excel STDEV فنکشن
STDEV(number1,[number2],…) قدیم ترین Excel ہے۔ نمونے کی بنیاد پر معیاری انحراف کا تخمینہ لگانے کے لیے فنکشن، اور یہ Excel 2003 سے 2019 کے تمام ورژنز میں دستیاب ہے۔
ایکسل 2007 اور بعد میں، STDEV 255 تک دلائل قبول کر سکتا ہے جن کی نمائندگی نمبرز، صفوں سے کی جا سکتی ہے۔ , نام کی حدود یا نمبروں پر مشتمل سیلز کے حوالے۔ ایکسل 2003 میں، فنکشن صرف تک ہی قبول کر سکتا ہے۔30 دلائل۔
دلائل کی فہرست میں براہ راست فراہم کردہ نمبروں کی منطقی اقدار اور متن کی نمائندگی کو شمار کیا جاتا ہے۔ صفوں اور حوالوں میں، صرف اعداد شمار کیے جاتے ہیں۔ خالی خلیات، درست اور غلط کی منطقی اقدار، متن اور غلطی کی اقدار کو نظر انداز کر دیا جاتا ہے۔
نوٹ۔ Excel STDEV ایک پرانا فنکشن ہے، جسے Excel کے نئے ورژنز میں صرف پسماندہ مطابقت کے لیے رکھا گیا ہے۔ تاہم، مائیکروسافٹ مستقبل کے ورژن کے حوالے سے کوئی وعدہ نہیں کرتا ہے۔ لہذا، Excel 2010 اور بعد میں، STDEV کے بجائے STDEV.S استعمال کرنے کی سفارش کی جاتی ہے۔
Excel STDEV.S فنکشن
STDEV.S(number1,[number2],…) STDEV کا ایک بہتر ورژن ہے، جسے Excel 2010 میں متعارف کرایا گیا ہے۔
STDEV کی طرح، STDEV.S فنکشن پچھلے سیکشن میں زیر بحث کلاسک نمونہ معیاری انحراف فارمولے کی بنیاد پر اقدار کے سیٹ کے نمونے کے معیاری انحراف کا حساب لگاتا ہے۔
Excel STDEVA فنکشن
STDEVA(value1, [value2], …) ایکسل میں نمونے کے معیاری انحراف کا حساب لگانے کے لیے ایک اور فنکشن ہے۔ یہ مندرجہ بالا دونوں سے صرف اس طریقے سے مختلف ہے جس طرح یہ منطقی اور متنی اقدار کو ہینڈل کرتا ہے:
- تمام منطقی اقدار کو شمار کیا جاتا ہے، چاہے وہ صفوں یا حوالہ جات کے اندر موجود ہوں، یا براہ راست ٹائپ کی گئی ہوں۔ دلائل کی فہرست میں (TRUE کا اندازہ 1 کے طور پر ہوتا ہے، FALSE کا اندازہ 0 کے طور پر ہوتا ہے)۔
- متن کی قدریں صفوں کے اندر یا حوالہ کے دلائل کو 0 کے طور پر شمار کیا جاتا ہے، بشمول خالی تار ("")، متن اعداد کی نمائندگی، اور کوئی دوسرا متن۔ کے متن کی نمائندگیدلائل کی فہرست میں براہ راست فراہم کردہ نمبروں کو ان نمبروں کے طور پر شمار کیا جاتا ہے جن کی وہ نمائندگی کرتے ہیں (یہاں ایک فارمولہ کی مثال ہے)۔
- خالی خلیوں کو نظر انداز کر دیا جاتا ہے۔
نوٹ۔ نمونے کے معیاری انحراف کے فارمولے کے درست طریقے سے کام کرنے کے لیے، فراہم کردہ دلائل میں کم از کم دو عددی قدریں ہونی چاہئیں، بصورت دیگر #DIV/0! غلطی واپس آ گئی ہے۔
ایکسل میں آبادی کے معیاری انحراف کا حساب لگانے کے فنکشنز
اگر آپ پوری آبادی کے ساتھ کام کر رہے ہیں تو، Excel میں معیاری انحراف کرنے کے لیے درج ذیل فنکشن میں سے ایک کا استعمال کریں۔ یہ فنکشنز "n" طریقہ پر مبنی ہیں۔
Excel STDEVP فنکشن
STDEVP(number1,[number2],…) آبادی کے معیاری انحراف کو تلاش کرنے کے لیے ایکسل پرانا فنکشن ہے۔
نئے ورژنز میں Excel 2010, 2013, 2016 اور 2019 میں، اسے بہتر STDEV.P فنکشن سے تبدیل کر دیا گیا ہے، لیکن پھر بھی پسماندہ مطابقت کے لیے رکھا گیا ہے۔
Excel STDEV.P فنکشن
STDEV.P(number1,[number2],…) جدید ہے STDEVP فنکشن کا ورژن جو ایک بہتر درستگی فراہم کرتا ہے۔ یہ Excel 2010 اور بعد کے ورژنز میں دستیاب ہے۔
ان کے نمونے کے معیاری انحراف کے ہم منصبوں کی طرح، صفوں یا حوالہ جات کے اندر، STDEVP اور STDEV.P فنکشنز صرف اعداد شمار کرتے ہیں۔ دلائل کی فہرست میں، وہ منطقی اقدار اور اعداد کی متنی نمائندگی کو بھی شمار کرتے ہیں۔
Excel STDEVPA فنکشن
STDEVPA(value1, [value2], …) متن اور منطقی اقدار سمیت آبادی کے معیاری انحراف کا حساب لگاتا ہے۔ غیر عددی کے حوالے سےاقدار، STDEVPA بالکل اسی طرح کام کرتا ہے جیسے STDEVA فنکشن کرتا ہے۔
نوٹ۔ آپ جو بھی Excel معیاری انحراف کا فارمولہ استعمال کرتے ہیں، یہ ایک خرابی لوٹائے گا اگر ایک یا زیادہ آرگیومنٹ میں کسی دوسرے فنکشن یا ٹیکسٹ کے ذریعے لوٹائی گئی خامی ویلیو ہو جس کو نمبر کے طور پر نہیں سمجھا جا سکتا۔
کس Excel معیاری انحراف کا فنکشن استعمال کرنا ہے؟
ایکسل میں مختلف قسم کے معیاری انحراف کے افعال یقینی طور پر خرابی کا باعث بن سکتے ہیں، خاص طور پر غیر تجربہ کار صارفین کے لیے۔ کسی خاص کام کے لیے درست معیاری انحراف کا فارمولہ منتخب کرنے کے لیے، صرف درج ذیل 3 سوالوں کے جواب دیں:
- کیا آپ کسی نمونے یا آبادی کے معیاری انحراف کا حساب لگاتے ہیں؟
- آپ کون سا ایکسل ورژن کرتے ہیں؟ استعمال کریں؟
- کیا آپ کے ڈیٹا سیٹ میں صرف اعداد یا منطقی اقدار اور متن بھی شامل ہے؟
عددی نمونہ کی بنیاد پر معیاری انحراف کا حساب لگانے کے لیے، استعمال کریں ایکسل 2010 اور بعد میں STDEV.S فنکشن؛ ایکسل 2007 اور اس سے پہلے میں STDEV۔
کسی آبادی کا معیاری انحراف تلاش کرنے کے لیے، ایکسل 2010 اور بعد میں STDEV.P فنکشن استعمال کریں۔ ایکسل 2007 اور اس سے پہلے میں STDEVP۔
اگر آپ چاہتے ہیں کہ حساب میں منطقی یا text اقدار کو شامل کیا جائے تو STDEVA (نمونہ معیاری انحراف) یا STDEVPA ( آبادی کے معیاری انحراف)۔ اگرچہ میں کسی ایسے منظر نامے کے بارے میں نہیں سوچ سکتا جس میں کوئی بھی فنکشن خود کارآمد ہو، وہ بڑے فارمولوں میں کام آسکتے ہیں، جہاں ایک یا زیادہ دلائل واپس کیے جاتے ہیں۔دوسرے فنکشنز بطور منطقی اقدار یا نمبروں کی متنی نمائندگی۔
آپ کو یہ فیصلہ کرنے میں مدد کرنے کے لیے کہ کون سے ایکسل معیاری انحراف فنکشن آپ کی ضروریات کے لیے موزوں ہے، براہ کرم درج ذیل جدول کا جائزہ لیں جو آپ پہلے ہی سیکھی ہوئی معلومات کا خلاصہ کرتا ہے۔
| STDEV | STDEV.S | STDEVP | STDEV.P | STDEVA | STDEVPA | |
| Excel ورژن | 2003 - 2019 | 2010 - 2019 | 2003 - 2019 | 2010 - 2019 | 2003 - 2019 | 2003 - 2019 |
| نمونہ | ✓ | ✓ | ✓ | |||
| آبادی | ✓ | ✓ | ✓ | |||
| آری میں منطقی اقدار یا حوالہ جات | نظر انداز کیے گئے | تشخیص کردہ (TRUE=1, FALSE=0) | ||||
| arrays یا references میں متن | نظر انداز کیا گیا | صفر کے طور پر تشخیص کیا گیا | ||||
| دلائل کی فہرست میں منطقی اقدار اور "ٹیکسٹ نمبرز" | تجزیہ شدہ (TRUE =1، FALSE=0) | |||||
| خالی سیل | <3 4>نظرانداز کیا گیا||||||
Excel معیاری انحراف کے فارمولے کی مثالیں
ایک بار جب آپ اس فنکشن کا انتخاب کر لیتے ہیں جو آپ کے ڈیٹا کی قسم سے مطابقت رکھتا ہے، تو اسے لکھنے میں کوئی دشواری نہیں ہونی چاہیے۔ فارمولہ - نحو اتنا سادہ اور شفاف ہے کہ اس میں غلطیوں کی کوئی گنجائش نہیں ہے :) درج ذیل مثالیں ایکسل معیاری انحراف کے چند فارمولوں کو عملی شکل میں ظاہر کرتی ہیں۔
معیار کا حساب لگانا
