
सामग्री तालिका
ट्युटोरियलले माध्यको मानक विचलन र मानक त्रुटिको सार र साथै एक्सेलमा मानक विचलन गणना गर्नको लागि कुन सूत्र प्रयोग गर्न उत्तम हुन्छ भनेर व्याख्या गर्दछ।
वर्णनात्मक तथ्याङ्कमा , अंकगणितीय माध्य (औसत पनि भनिन्छ) र मानक विचलन र दुई नजिकबाट सम्बन्धित अवधारणाहरू हुन्। तर पहिलेको धेरैले राम्ररी बुझेका छन्, पछिल्लालाई थोरैले बुझेका छन्। यस ट्यूटोरियलको उद्देश्यले मानक विचलन वास्तवमा के हो र यसलाई एक्सेलमा कसरी गणना गर्ने भन्ने बारे केही प्रकाश पार्नु हो।
मानक विचलन के हो?
द मानक विचलन एक मापन हो जसले डेटाको सेटको मानहरू औसतबाट कति विचलित (फैलिएको) हुन्छ भनेर संकेत गर्छ। यसलाई फरक रूपमा राख्नको लागि, मानक विचलनले तपाईंको डेटा औसतको नजिक छ वा धेरै उतार-चढाव हुन्छ भनेर देखाउँछ।
मानक विचलनको उद्देश्य भनेको अर्थले वास्तवमा "विशिष्ट" डेटा फर्काउँछ भने बुझ्न मद्दत गर्नु हो। मानक विचलन शून्यमा जति नजिक हुन्छ, डाटाको परिवर्तनशीलता कम हुन्छ र औसत उति भरपर्दो हुन्छ। ० को बराबरको मानक विचलनले डेटासेटमा भएका प्रत्येक मान औसतसँग ठ्याक्कै बराबर छ भनी संकेत गर्छ। मानक विचलन जति उच्च हुन्छ, डेटामा उति धेरै भिन्नता हुन्छ र औसत कम सटीक हुन्छ।
यसले कसरी काम गर्छ भन्ने राम्रो विचार प्राप्त गर्न, कृपया निम्न डेटा हेर्नुहोस्:
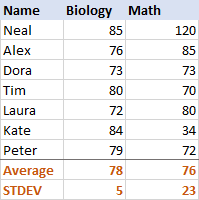
जीवविज्ञानको लागि, मानक विचलननमूना र जनसंख्याको विचलन
तपाईँको डेटाको प्रकृतिमा निर्भर गर्दै, निम्न मध्ये एउटा सूत्र प्रयोग गर्नुहोस्:
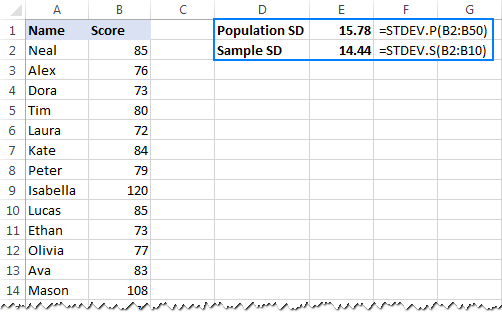
- पूरा जनसंख्या<9 मा आधारित मानक विचलन गणना गर्न>, अर्थात् मानहरूको पूर्ण सूची (यस उदाहरणमा B2:B50), STDEV.P प्रकार्य प्रयोग गर्नुहोस्:
=STDEV.P(B2:B50) - नमूना<9 मा आधारित मानक विचलन पत्ता लगाउन।> जसले जनसंख्याको एक भाग, वा उपसमूह गठन गर्दछ (यस उदाहरणमा B2:B10), STDEV.S प्रकार्य प्रयोग गर्नुहोस्:
=STDEV.S(B2:B10)
जस्तै तपाईँले देख्न सक्नुहुन्छ। तलको स्क्रिनसट, सूत्रहरूले थोरै फरक संख्याहरू फर्काउँछ (जति सानो नमूना, ठूलो भिन्नता):
एक्सेल 2007 र तल्लोमा, तपाईंले STDEVP र STDEV प्रकार्यहरू प्रयोग गर्नुहुनेछ। यसको सट्टा:
- जनसंख्या मानक विचलन प्राप्त गर्न:
=STDEVP(B2:B50) - नमूना मानक विचलन गणना गर्न:
=STDEV(B2:B10)
संख्याहरूको पाठ प्रतिनिधित्वको लागि मानक विचलन गणना गर्दै
एक्सेलमा मानक विचलन गणना गर्न विभिन्न प्रकार्यहरू छलफल गर्दा, हामीले कहिलेकाहीं "पाठ आर संख्याहरूको प्रस्तुतीकरण" र तपाइँ यसको वास्तविक अर्थ के हो भनेर जान्न उत्सुक हुन सक्नुहुन्छ।
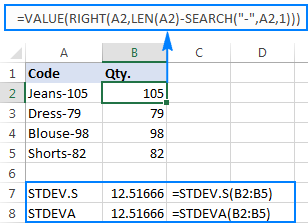
यस सन्दर्भमा, "संख्याहरूको पाठ प्रतिनिधित्वहरू" केवल पाठको रूपमा ढाँचा गरिएका संख्याहरू हुन्। तपाईंको कार्यपत्रमा यस्ता संख्याहरू कसरी देखा पर्न सक्छन्? प्रायः, तिनीहरू बाह्य स्रोतहरूबाट निर्यात गरिन्छ। वा, तथाकथित पाठ प्रकार्यहरू द्वारा फर्काइयो जुन पाठ स्ट्रिङहरू हेरफेर गर्न डिजाइन गरिएको हो, जस्तै। पाठ, मध्य, दायाँ, बायाँ,आदि। ती कार्यहरू मध्ये केही संख्याहरूसँग पनि काम गर्न सक्छन्, तर तिनीहरूको आउटपुट सधैं पाठ हो, यद्यपि यो धेरै संख्या जस्तै देखिन्छ। मानौं तपाईंसँग उत्पादन कोडहरूको स्तम्भ जस्तै "Jeans-105" छ जहाँ हाइफन पछिको अंकले मात्रालाई जनाउँछ। तपाईंको लक्ष्य प्रत्येक वस्तुको मात्रा निकाल्ने हो, र त्यसपछि निकालिएका संख्याहरूको मानक विचलन फेला पार्नुहोस्।
मात्रालाई अर्को स्तम्भमा तान्नु कुनै समस्या होइन:
=RIGHT(A2,LEN(A2)-SEARCH("-",A2,1))
समस्या यो हो कि एक्स्ट्र्याक्ट गरिएका नम्बरहरूमा एक्सेल मानक विचलन सूत्र प्रयोग गर्दा #DIV/0 फर्काउँछ! वा ० लाई तलको स्क्रिनसटमा देखाइएको जस्तै:
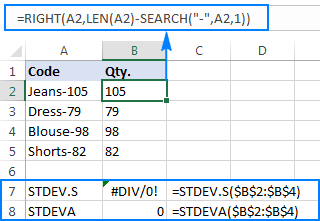
किन यस्तो अनौठो नतिजा? माथि उल्लेख गरिए अनुसार, RIGHT प्रकार्यको आउटपुट सधैं पाठ स्ट्रिङ हो। तर न त STDEV.S न STDEVA ले सन्दर्भहरूमा पाठको रूपमा ढाँचा गरिएका सङ्ख्याहरू ह्यान्डल गर्न सक्दैन (पूर्वले तिनीहरूलाई बेवास्ता गर्छ जबकि पछिल्लोले शून्यको रूपमा गणना गर्दछ)। त्यस्ता "पाठ-नम्बरहरू" को मानक विचलन प्राप्त गर्न, तपाईंले तिनीहरूलाई सिधै तर्कहरूको सूचीमा आपूर्ति गर्न आवश्यक छ, जुन तपाईंको STDEV.S वा STDEVA सूत्रमा सबै RIGHT प्रकार्यहरू इम्बेड गरेर गर्न सकिन्छ:
=STDEV.S(RIGHT(A2,LEN(A2)-SEARCH("-",A2,1)), RIGHT(A3,LEN(A3)-SEARCH("-",A3,1)), RIGHT(A4,LEN(A4)-SEARCH("-",A4,1)), RIGHT(A5,LEN(A5)-SEARCH("-",A5,1)))
=STDEVA(RIGHT(A2,LEN(A2)-SEARCH("-",A2,1)), RIGHT(A3,LEN(A3)-SEARCH("-",A3,1)), RIGHT(A4,LEN(A4)-SEARCH("-",A4,1)), RIGHT(A5,LEN(A5)-SEARCH("-",A5,1)))
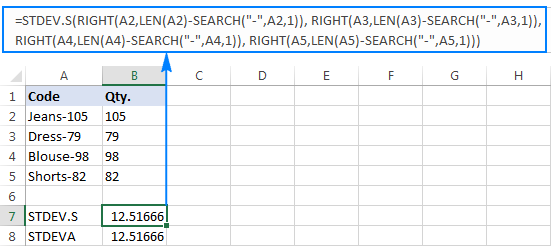
सूत्रहरू थोरै बोझिलो छन्, तर त्यो सानो नमूनाको लागि काम गर्ने समाधान हुन सक्छ। ठूलोको लागि, सम्पूर्ण जनसंख्या उल्लेख नगर्नु, यो निश्चित रूपमा विकल्प होइन। यस अवस्थामा, थप सुरुचिपूर्ण समाधान हुनेछVALUE प्रकार्यले "टेक्स्ट-नम्बरहरू" लाई कुनै पनि मानक विचलन सूत्रले बुझ्न सक्ने सङ्ख्याहरूमा रूपान्तरण गर्नुहोस् (कृपया माथिको स्क्रिनसटमा बायाँ-पङ्क्तिबद्ध पाठ स्ट्रिङको विपरीत तलको स्क्रिनसटमा दायाँ-पङ्क्तिबद्ध संख्याहरूलाई ध्यान दिनुहोस्):
एक्सेलमा माध्यको मानक त्रुटि कसरी गणना गर्ने
अंकमा, डेटामा परिवर्तनशीलता अनुमान गर्नको लागि त्यहाँ एउटा थप उपाय छ - माध्यको मानक त्रुटि , जुन कहिलेकाहीँ छोटो हुन्छ (यद्यपि, गलत रूपमा) केवल "मानक त्रुटि" मा। माध्यको मानक विचलन र मानक त्रुटि दुई घनिष्ठ सम्बन्धित अवधारणाहरू हुन्, तर एउटै होइनन्।
मानक विचलनले माध्यबाट डेटा सेटको परिवर्तनशीलता मापन गर्दा, माध्यको मानक त्रुटि (SEM) नमूना मतलब वास्तविक जनसङ्ख्याको अर्थबाट कति टाढा हुन सक्ने अनुमान गर्दछ। अर्को तरिकाले भन्यो - यदि तपाईले एउटै जनसंख्याबाट धेरै नमूनाहरू लिनुभयो भने, माध्यको मानक त्रुटिले ती नमूना माध्यमहरू बीचको फैलावट देखाउनेछ। किनभने सामान्यतया हामी डेटाको सेटको लागि केवल एक माध्य गणना गर्छौं, धेरै माध्यमहरू होइन, मापनको सट्टा माध्यको मानक त्रुटि अनुमान गरिन्छ।
गणितमा, माध्यको मानक त्रुटि यस सूत्रबाट गणना गरिन्छ:
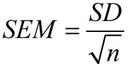
जहाँ SD मानक विचलन हो, र n नमूना आकार हो (नमूनामा मानहरूको संख्या)।
तपाईँको एक्सेल कार्यपत्रहरूमा, तपाईले नम्बर प्राप्त गर्न COUNT प्रकार्य प्रयोग गर्न सक्नुहुन्छनमूनामा मानहरूको, त्यो संख्याको वर्गमूल लिनको लागि SQRT, र नमूनाको मानक विचलन गणना गर्न STDEV.S।
यी सबैलाई एकसाथ राख्दा, तपाईंले Excel मा औसत सूत्रको मानक त्रुटि पाउनुहुनेछ। :
STDEV.S( range )/SQRT(COUNT( range ))नमूना डाटा B2:B10 मा छ भनी मान्दै, हाम्रो SEM सूत्र निम्नानुसार हुनेछ :
=STDEV.S(B2:B10)/SQRT(COUNT(B2:B10))
र नतिजा यससँग मिल्दोजुल्दो हुन सक्छ:
40>
एक्सेलमा मानक विचलन बारहरू कसरी थप्ने
मानक विचलनको मार्जिन दृश्यात्मक रूपमा प्रदर्शन गर्न, तपाइँ आफ्नो एक्सेल चार्टमा मानक विचलन बारहरू थप्न सक्नुहुन्छ। यहाँ कसरी छ:
- सामान्य तरिकामा ग्राफ सिर्जना गर्नुहोस् ( Insert ट्याब > चार्टहरू समूह)।
- मा जहाँ पनि क्लिक गर्नुहोस्। यसलाई चयन गर्न ग्राफ, त्यसपछि चार्ट तत्वहरू बटनमा क्लिक गर्नुहोस्।
- त्रुटि पट्टीहरू छेउमा रहेको तीरमा क्लिक गर्नुहोस्, र मानक विचलन छान्नुहोस्।
यसले सबै डेटा बिन्दुहरूको लागि समान मानक विचलन पट्टीहरू सम्मिलित गर्नेछ।
43>
यसले Excel मा मानक विचलन गर्ने तरिका हो। मलाई आशा छ कि तपाईंले यो जानकारी उपयोगी पाउनुहुनेछ। जे भए पनि, म पढ्नको लागि धन्यवाद र अर्को हप्ता हाम्रो ब्लगमा भेट्ने आशा गर्दछु।
5 (एक पूर्णांकमा राउन्ड गरिएको) हो, जसले हामीलाई बताउँछ कि अधिकांश स्कोरहरू औसतबाट 5 अंक भन्दा बढी टाढा छैनन्। त्यो राम्रो छ? ठीक छ, हो, यसले विद्यार्थीहरूको जीवविज्ञान स्कोरहरू एकदमै एकरूप छन् भनी संकेत गर्छ।गणितको लागि, मानक विचलन 23 हो। यसले स्कोरहरूमा ठूलो फैलावट (स्प्रेड) रहेको देखाउँछ, जसको अर्थ केही विद्यार्थीहरूले धेरै राम्रो प्रदर्शन गरे र/वा कतिपयले औसत भन्दा धेरै खराब प्रदर्शन गरे।
अभ्यासमा, मानक विचलनलाई प्रायः व्यापार विश्लेषकहरूले लगानी जोखिमको मापनको रूपमा प्रयोग गर्छन् - मानक विचलन जति उच्च हुन्छ, अस्थिरता त्यति नै उच्च हुन्छ। प्रतिफलको।
नमूना मानक विचलन बनाम जनसंख्या मानक विचलन
मानक विचलनको सम्बन्धमा, तपाईले प्रायः "नमूना" र "जनसंख्या" शब्दहरू सुन्न सक्नुहुन्छ, जसले को पूर्णतालाई जनाउँछ। तपाईले काम गरिरहनुभएको डाटा। मुख्य भिन्नता निम्नानुसार छ:
- जनसंख्या डेटा सेटका सबै तत्वहरू समावेश गर्दछ।
- नमूना को एक उपसेट हो जनसंख्याबाट एक वा बढी तत्वहरू समावेश गर्ने डेटा।
अनुसन्धानकर्ताहरू र विश्लेषकहरूले विभिन्न परिस्थितिहरूमा नमूना र जनसंख्याको मानक विचलनमा काम गर्छन्। उदाहरणका लागि, विद्यार्थीहरूको कक्षाको परीक्षा स्कोरहरू सारांश गर्दा, शिक्षकले जनसंख्या मानक विचलन प्रयोग गर्नेछ। राष्ट्रिय SAT औसत स्कोर गणना गर्ने तथ्याङ्कविद्हरूले नमूना मानक विचलन प्रयोग गर्नेछन्तिनीहरू एक नमूनाबाट मात्र डेटा प्रस्तुत गरिन्छ, सम्पूर्ण जनसंख्याबाट होइन।
मानक विचलन सूत्र बुझ्दै
डेटाको प्रकृति महत्त्वपूर्ण छ किनभने जनसंख्या मानक विचलन र नमूना मानक विचलनलाई थोरै फरक सूत्रहरूसँग गणना गरिन्छ:
नमूना मानक विचलन | जनसंख्या मानक विचलन |
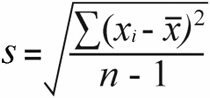 | 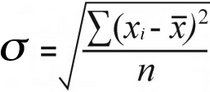 |
कहाँ:
- <8 x i डेटाको सेटमा व्यक्तिगत मानहरू हुन्
- x सबैको औसत हो x मानहरू
- n डेटा सेटमा x मानहरूको कुल संख्या हो
सूत्रहरू बुझ्न कठिनाइ भइरहेको छ? तिनीहरूलाई सरल चरणहरूमा विभाजन गर्न मद्दत गर्न सक्छ। तर पहिले, हामीसँग काम गर्नको लागि केहि नमूना डेटा दिनुहोस्:

पहिले, तपाईंले डेटा सेटमा ( x माथिको सूत्रहरूमा) मा सबै मानहरूको माध्य फेला पार्नुहुनेछ। हातले गणना गर्दा, तपाईंले संख्याहरू थप्नुहोस् र त्यसपछि ती संख्याहरूको गणनाद्वारा योगफललाई विभाजन गर्नुहोस्, जस्तै:
(1+2+4+5+6+8+9)/7=5
Excel मा मतलब पत्ता लगाउन, AVERAGE प्रकार्य प्रयोग गर्नुहोस्, उदाहरणका लागि। =AVERAGE(A2:G2)
2। प्रत्येक संख्याको लागि, औसत घटाउनुहोस् र नतिजालाई वर्ग गर्नुहोस्
यो मानक विचलन सूत्रको भाग हो जसले भन्छ: ( x i - x )2
वास्तवमा के भइरहेको छ भनी कल्पना गर्न, कृपया हेर्नुहोस्निम्न छविहरू।
यस उदाहरणमा, औसत 5 हो, त्यसैले हामी प्रत्येक डेटा बिन्दु र 5 बीचको भिन्नता गणना गर्छौं।
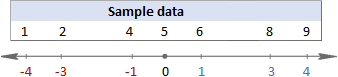
त्यसपछि, तपाईंले वर्ग भिन्नताहरू, ती सबैलाई सकारात्मक संख्यामा परिणत गर्दै:
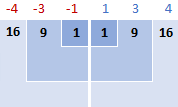
3। वर्गीय भिन्नताहरू थप्नुहोस्
गणितमा "योग चीजहरू" भन्नको लागि, तपाइँ सिग्मा Σ प्रयोग गर्नुहुन्छ। त्यसोभए, अब हामी के गर्छौं सूत्रको यो भाग पूरा गर्न वर्गीय भिन्नताहरू जोड्नु हो: Σ( x i - x )2
16 + 9 + १ + १ + ९ + १६ = ५२
४। कुल वर्गीय भिन्नताहरूलाई मानहरूको गणनाद्वारा विभाजित गर्नुहोस्
अहिलेसम्म, नमूना मानक विचलन र जनसंख्या मानक विचलन सूत्रहरू समान छन्। यस बिन्दुमा, तिनीहरू फरक छन्।
नमूना मानक विचलन को लागी, तपाईले नमूना भिन्नता कुल वर्ग भिन्नतालाई नमूना आकार माइनस १ द्वारा विभाजित गरेर प्राप्त गर्नुहुन्छ:
52 / (7-1) = 8.67
जनसंख्या मानक विचलन को लागि, तपाईंले कुल विभाजन गरेर वर्गीय भिन्नताहरूको अर्थ फेला पार्नुहुनेछ। तिनीहरूको गणना अनुसार वर्ग भिन्नताहरू:
52 / 7 = 7.43
सूत्रहरूमा यो भिन्नता किन? किनभने नमूना मानक विचलन सूत्रमा, तपाईंले वास्तविक जनसङ्ख्याको अर्थको सट्टा नमूना अर्थको अनुमानमा पूर्वाग्रहलाई सच्याउन आवश्यक छ। र तपाईले यो n - 1 को सट्टा n प्रयोग गरेर गर्नुहुन्छ, जसलाई बेसेलको सुधार भनिन्छ।
5। वर्गमूल लिनुहोस्
अन्तमा, माथिको वर्गमूल लिनुहोस्संख्याहरू, र तपाईंले आफ्नो मानक विचलन प्राप्त गर्नुहुनेछ (तलको समीकरणहरूमा, 2 दशमलव स्थानहरूमा राउन्ड गरिएको):
| नमूना मानक विचलन | जनसंख्या मानक विचलन |
| √ 8.67 = 2.94 | √ 7.43 = 2.73 |
Microsoft Excel मा, मानक विचलन गणना गरिन्छ त्यसै गरी, तर माथिका सबै गणनाहरू दृश्य पछाडि प्रदर्शन गरिन्छ। तपाईको लागि मुख्य कुरा भनेको उचित मानक विचलन प्रकार्य छनोट गर्नु हो, जसको बारेमा निम्न खण्डले तपाईलाई केही संकेत दिनेछ।
एक्सेलमा मानक विचलन कसरी गणना गर्ने
समग्रमा, त्यहाँ छवटा फरक छन्। Excel मा मानक विचलन फेला पार्न कार्यहरू। कुन प्रयोग गर्ने मुख्य रूपमा तपाईले काम गरिरहनुभएको डेटाको प्रकृतिमा निर्भर गर्दछ - चाहे यो सम्पूर्ण जनसंख्या होस् वा नमूना हो।
Excel मा नमूना मानक विचलन गणना गर्न कार्यहरू
मानक गणना गर्न नमूनामा आधारित विचलन, निम्न मध्ये एउटा सूत्र प्रयोग गर्नुहोस् (ती सबै माथि वर्णन गरिएको "n-1" विधिमा आधारित छन्)।
Excel STDEV प्रकार्य
STDEV(number1,[number2],…) सबैभन्दा पुरानो Excel हो। नमूनामा आधारित मानक विचलन अनुमान गर्ने प्रकार्य, र यो एक्सेल २००३ देखि २०१९ को सबै संस्करणहरूमा उपलब्ध छ।
एक्सेल २००७ र पछि, STDEV ले २५५ सम्म तर्कहरू स्वीकार गर्न सक्छ जुन संख्याहरू, एरेहरूद्वारा प्रतिनिधित्व गर्न सकिन्छ। , नामित दायराहरू वा संख्याहरू भएका कक्षहरूको सन्दर्भ। एक्सेल 2003 मा, प्रकार्यले मात्र स्वीकार गर्न सक्छ30 तर्कहरू।
तर्कको सूचीमा सिधै आपूर्ति गरिएका संख्याहरूको तार्किक मान र पाठ प्रतिनिधित्वहरू गणना गरिन्छ। एरे र सन्दर्भहरूमा, संख्याहरू मात्र गणना गरिन्छ; खाली कक्षहरू, TRUE र FALSE को तार्किक मानहरू, पाठ र त्रुटि मानहरूलाई बेवास्ता गरिन्छ।
नोट। Excel STDEV एक पुरानो प्रकार्य हो, जुन एक्सेलको नयाँ संस्करणहरूमा ब्याकवर्ड अनुकूलताको लागि मात्र राखिएको छ। यद्यपि, माइक्रोसफ्टले भविष्यका संस्करणहरूको बारेमा कुनै वाचा गर्दैन। त्यसैले, Excel 2010 र पछि, STDEV को सट्टा STDEV.S प्रयोग गर्न सिफारिस गरिन्छ।
Excel STDEV.S प्रकार्य
STDEV.S(number1,[number2],…) STDEV को सुधारिएको संस्करण हो, Excel 2010 मा प्रस्तुत गरिएको छ।
STDEV जस्तै, STDEV.S प्रकार्यले अघिल्लो खण्डमा छलफल गरिएको क्लासिक नमूना मानक विचलन सूत्रमा आधारित मानहरूको सेटको नमूना मानक विचलन गणना गर्दछ।
Excel STDEVA प्रकार्य
STDEVA(value1, [value2], …) Excel मा नमूनाको मानक विचलन गणना गर्न अर्को प्रकार्य हो। यो केवल तार्किक र पाठ मानहरू ह्यान्डल गर्ने तरिकामा माथिको दुई भन्दा फरक छ:
- सबै तार्किक मानहरू गनिन्छन्, चाहे तिनीहरू arrays वा सन्दर्भहरूमा समावेश छन्, वा सीधा टाइप गरिएका छन्। तर्कहरूको सूचीमा (TRUE ले 1 को रूपमा मूल्याङ्कन गर्दछ, FALSE ले 0 को रूपमा मूल्याङ्कन गर्दछ)।
- पाठ मानहरू arrays भित्र वा सन्दर्भ तर्कहरू 0 को रूपमा गणना गरिन्छ, खाली स्ट्रिङहरू (""), पाठ सहित संख्याहरूको प्रतिनिधित्व, र कुनै अन्य पाठ। को पाठ प्रतिनिधित्वतर्कहरूको सूचीमा सिधै आपूर्ति गरिएका संख्याहरूलाई तिनीहरूले प्रतिनिधित्व गर्ने संख्याहरूको रूपमा गणना गरिन्छ (यहाँ एउटा सूत्र उदाहरण छ)।
- खाली कक्षहरूलाई बेवास्ता गरिएको छ।
नोट। नमूना मानक विचलन सूत्र सही रूपमा काम गर्नको लागि, आपूर्ति गरिएका तर्कहरूमा कम्तिमा दुई संख्यात्मक मानहरू हुनुपर्छ, अन्यथा #DIV/0! त्रुटि फर्काइएको छ।
Excel मा जनसंख्या मानक विचलन गणना गर्न कार्यहरू
यदि तपाइँ सम्पूर्ण जनसंख्यासँग व्यवहार गर्दै हुनुहुन्छ भने, Excel मा मानक विचलन गर्न निम्न मध्ये एउटा प्रकार्य प्रयोग गर्नुहोस्। यी प्रकार्यहरू "n" विधिमा आधारित छन्।
Excel STDEVP प्रकार्य
STDEVP(number1,[number2],…) पुरानो एक्सेल प्रकार्य हो जुन जनसंख्याको मानक विचलन फेला पार्न सकिन्छ।
नयाँ संस्करणहरूमा Excel 2010, 2013, 2016 र 2019 को, यसलाई सुधारिएको STDEV.P प्रकार्यले प्रतिस्थापन गरिएको छ, तर अझै पनि पछाडि अनुकूलताको लागि राखिएको छ।
Excel STDEV.P प्रकार्य
STDEV.P(number1,[number2],…) आधुनिक छ STDEVP प्रकार्यको संस्करण जसले सुधारिएको शुद्धता प्रदान गर्दछ। यो Excel 2010 र पछिका संस्करणहरूमा उपलब्ध छ।
तिनीहरूको नमूना मानक विचलन समकक्षहरू जस्तै, arrays वा सन्दर्भ तर्कहरू भित्र, STDEVP र STDEV.P प्रकार्यहरूले संख्या मात्र गणना गर्दछ। तर्कहरूको सूचीमा, तिनीहरूले संख्याहरूको तार्किक मानहरू र पाठ प्रतिनिधित्वहरू पनि गणना गर्छन्।
Excel STDEVPA प्रकार्य
STDEVPA(value1, [value2], …) ले पाठ र तार्किक मानहरू सहित जनसंख्याको मानक विचलन गणना गर्दछ। गैर-संख्यात्मक सम्बन्धमामानहरू, STDEVPA ले STDEVA प्रकार्यले जस्तै काम गर्छ।
नोट। तपाईंले जुनसुकै Excel मानक विचलन सूत्र प्रयोग गर्नुभयो भने, यदि एक वा बढी तर्कहरूले अर्को प्रकार्य वा पाठद्वारा फर्काइएको त्रुटि मान समावेश गर्दछ जुन संख्याको रूपमा व्याख्या गर्न सकिँदैन।
कुन एक्सेल मानक विचलन प्रकार्य प्रयोग गर्ने?
Excel मा विभिन्न मानक विचलन कार्यहरूले निश्चित रूपमा गडबडी निम्त्याउन सक्छ, विशेष गरी अनुभवहीन प्रयोगकर्ताहरूलाई। एक विशेष कार्यको लागि सही मानक विचलन सूत्र छनोट गर्न, केवल निम्न 3 प्रश्नहरूको जवाफ दिनुहोस्:
- के तपाइँ नमूना वा जनसंख्याको मानक विचलन गणना गर्नुहुन्छ?
- तपाईले कुन एक्सेल संस्करण गर्नुहुन्छ? प्रयोग गर्नुहोस्?
- तपाईँको डेटा सेटले संख्याहरू वा तार्किक मानहरू र पाठ पनि समावेश गर्दछ?
संख्यात्मक नमूना मा आधारित मानक विचलन गणना गर्न, प्रयोग गर्नुहोस्। STDEV.S प्रकार्य Excel 2010 र पछि; STDEV Excel 2007 र पहिलेको।
जनसंख्या को मानक विचलन पत्ता लगाउन, Excel 2010 र पछिको STDEV.P प्रकार्य प्रयोग गर्नुहोस्; STDEVP Excel 2007 र पहिलेको।
यदि तपाईं गणनामा तार्किक वा टेक्स्ट मानहरू समावेश गर्न चाहनुहुन्छ भने, STDEVA (नमूना मानक विचलन) वा STDEVPA ( जनसंख्या मानक विचलन)। यद्यपि म कुनै पनि परिदृश्यको बारेमा सोच्न सक्दिन जसमा कुनै पनि प्रकार्य आफैंमा उपयोगी हुन सक्छ, तिनीहरू ठूला सूत्रहरूमा काममा आउन सक्छन्, जहाँ एक वा बढी तर्कहरू द्वारा फर्काइन्छ।अन्य कार्यहरू तार्किक मानहरू वा संख्याहरूको पाठ प्रतिनिधित्वको रूपमा।
तपाईँको आवश्यकताहरूको लागि कुन Excel मानक विचलन प्रकार्यहरू सबैभन्दा उपयुक्त छ भनेर निर्णय गर्न मद्दतको लागि, कृपया निम्न तालिका समीक्षा गर्नुहोस् जुन तपाईंले पहिले नै सिकेका जानकारीको सारांश दिन्छ।
| STDEV | STDEV.S | STDEVP | STDEV.P | STDEVA | STDEVPA | |
| Excel संस्करण | 2003 - 2019 | 2010 - 2019 | 2003 - 2019 | 2010 - 2019 | 2003 - 2019 | 2003 - 2019 |
| नमूना | ✓ | ✓ | ✓ | |||
| जनसंख्या | ✓ | ✓ | ✓ | |||
| array मा तार्किक मानहरू वा सन्दर्भहरू | उपेक्षित | मूल्याङ्कन गरिएको (TRUE=1, FALSE=0) | ||||
| एरे वा सन्दर्भहरूमा पाठ | बेवास्ता गरियो | शून्यको रूपमा मूल्याङ्कन गरियो | ||||
| तार्किक मानहरू र तर्कहरूको सूचीमा "पाठ-संख्याहरू" | मूल्याङ्कन गरिएको (TRUE =1, FALSE=0) | |||||
| खाली कक्षहरू | <3 4>बेवास्ता गरियो||||||
Excel मानक विचलन सूत्र उदाहरणहरू
एकपटक तपाईंले आफ्नो डेटा प्रकारसँग मेल खाने प्रकार्य रोज्नुभएपछि, त्यहाँ लेख्न कुनै कठिनाइ हुनु हुँदैन। सूत्र - वाक्यविन्यास यति सादा र पारदर्शी छ कि यसले त्रुटिहरूको लागि कुनै ठाउँ छोड्दैन :) निम्न उदाहरणहरूले कार्यमा Excel मानक विचलन सूत्रहरूको एक जोडी प्रदर्शन गर्दछ।
मानक गणना गर्दै
