
विषयसूची
ट्यूटोरियल मानक विचलन और माध्य की मानक त्रुटि के सार के साथ-साथ एक्सेल में मानक विचलन की गणना के लिए उपयोग किए जाने वाले सूत्र के बारे में बताता है।
वर्णनात्मक आंकड़ों में , अंकगणितीय माध्य (जिसे औसत भी कहा जाता है) और मानक विचलन और दो निकट संबंधी अवधारणाएँ हैं। लेकिन जबकि पूर्व को सबसे अच्छी तरह से समझा जाता है, बाद वाले को कुछ ही समझ पाते हैं। इस ट्यूटोरियल का उद्देश्य वास्तव में मानक विचलन क्या है और एक्सेल में इसकी गणना कैसे करें, इस पर कुछ प्रकाश डाला गया है।
मानक विचलन क्या है?
मानक विचलन एक माप है जो इंगित करता है कि डेटा के सेट के मान माध्य से कितना विचलित (फैला हुआ) है। इसे दूसरे तरीके से कहें तो, मानक विचलन दिखाता है कि आपका डेटा माध्य के करीब है या बहुत अधिक उतार-चढ़ाव करता है।
मानक विचलन का उद्देश्य यह समझने में आपकी सहायता करना है कि क्या माध्य वास्तव में "ठेठ" डेटा लौटाता है। मानक विचलन शून्य के जितना करीब होता है, डेटा परिवर्तनशीलता उतनी ही कम होती है और माध्य उतना ही अधिक विश्वसनीय होता है। 0 के बराबर मानक विचलन इंगित करता है कि डेटासेट में प्रत्येक मान माध्य के बिल्कुल बराबर है। मानक विचलन जितना अधिक होता है, डेटा में उतनी ही अधिक भिन्नता होती है और माध्य उतना ही कम सटीक होता है।
यह कैसे काम करता है, इसका एक बेहतर विचार प्राप्त करने के लिए, कृपया निम्नलिखित डेटा पर एक नज़र डालें:
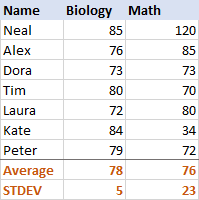
जीव विज्ञान के लिए, मानक विचलनएक नमूने और जनसंख्या का विचलन
अपने डेटा की प्रकृति के आधार पर, निम्न सूत्रों में से किसी एक का उपयोग करें:
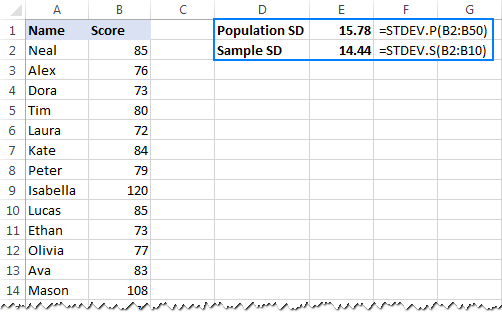
- पूरी जनसंख्या<9 के आधार पर मानक विचलन की गणना करने के लिए>, यानी मानों की पूरी सूची (इस उदाहरण में B2:B50), STDEV.P फ़ंक्शन का उपयोग करें:
=STDEV.P(B2:B50) - नमूना<9 के आधार पर मानक विचलन खोजने के लिए> जो जनसंख्या का एक भाग, या उपसमुच्चय (इस उदाहरण में B2:B10) बनाता है, STDEV.S फ़ंक्शन का उपयोग करें:
=STDEV.S(B2:B10)
जैसा कि आप इसमें देख सकते हैं नीचे दिए गए स्क्रीनशॉट में, सूत्र थोड़े अलग नंबर लौटाते हैं (नमूना जितना छोटा होगा, अंतर उतना ही बड़ा होगा):
Excel 2007 और उससे पहले के संस्करण में, आप STDEVP और STDEV फ़ंक्शन का उपयोग करेंगे इसके बजाय:
- जनसंख्या मानक विचलन प्राप्त करने के लिए:
=STDEVP(B2:B50) - नमूना मानक विचलन की गणना करने के लिए:
=STDEV(B2:B10)
संख्याओं के पाठ प्रतिनिधित्व के लिए मानक विचलन की गणना करना
एक्सेल में मानक विचलन की गणना करने के लिए विभिन्न कार्यों पर चर्चा करते समय, हमने कभी-कभी "टेक्स्ट आर" का उल्लेख किया संख्याओं का प्रतिनिधित्व" और आप यह जानने के लिए उत्सुक हो सकते हैं कि वास्तव में इसका क्या अर्थ है।
इस संदर्भ में, "संख्याओं का पाठ प्रतिनिधित्व" केवल पाठ के रूप में स्वरूपित संख्याएँ हैं। आपकी वर्कशीट में ऐसी संख्याएँ कैसे दिखाई दे सकती हैं? ज्यादातर, उन्हें बाहरी स्रोतों से निर्यात किया जाता है। या, तथाकथित टेक्स्ट फ़ंक्शंस द्वारा लौटाया जाता है जो टेक्स्ट स्ट्रिंग्स में हेरफेर करने के लिए डिज़ाइन किए गए हैं, उदा। पाठ, मध्य, दाएँ, बाएँ,आदि। उन कार्यों में से कुछ संख्या के साथ भी काम कर सकते हैं, लेकिन उनका आउटपुट हमेशा पाठ होता है, भले ही वह एक संख्या की तरह दिखता हो।
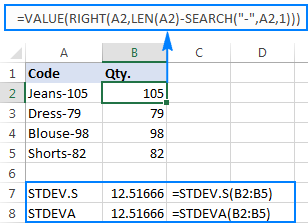
बिंदु को बेहतर ढंग से समझाने के लिए, कृपया निम्नलिखित उदाहरण पर विचार करें। मान लें कि आपके पास "Jeans-105" जैसे उत्पाद कोड का एक कॉलम है, जहां हाइफ़न के बाद के अंक मात्रा को दर्शाते हैं। आपका लक्ष्य प्रत्येक आइटम की मात्रा निकालना है, और फिर निकाली गई संख्याओं का मानक विचलन ज्ञात करना है।
मात्रा को दूसरे कॉलम में खींचना कोई समस्या नहीं है:
=RIGHT(A2,LEN(A2)-SEARCH("-",A2,1))
समस्या यह है कि निकाले गए नंबरों पर एक्सेल मानक विचलन सूत्र का उपयोग करने से या तो #DIV/0! या 0 जैसे नीचे स्क्रीनशॉट में दिखाया गया है:
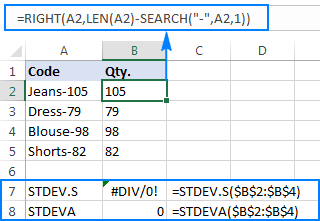
इतने अजीब परिणाम क्यों? जैसा ऊपर बताया गया है, राइट फ़ंक्शन का आउटपुट हमेशा एक टेक्स्ट स्ट्रिंग होता है। लेकिन न तो STDEV.S और न ही STDEVA संदर्भों में पाठ के रूप में स्वरूपित संख्याओं को संभाल सकते हैं (पूर्व केवल उन्हें अनदेखा करते हैं जबकि बाद वाले को शून्य के रूप में गिना जाता है)। ऐसे "पाठ-संख्याओं" का मानक विचलन प्राप्त करने के लिए, आपको उन्हें सीधे तर्कों की सूची में आपूर्ति करने की आवश्यकता है, जो आपके STDEV.S या STDEVA सूत्र में सभी राइट फ़ंक्शन एम्बेड करके किया जा सकता है:
=STDEV.S(RIGHT(A2,LEN(A2)-SEARCH("-",A2,1)), RIGHT(A3,LEN(A3)-SEARCH("-",A3,1)), RIGHT(A4,LEN(A4)-SEARCH("-",A4,1)), RIGHT(A5,LEN(A5)-SEARCH("-",A5,1)))
=STDEVA(RIGHT(A2,LEN(A2)-SEARCH("-",A2,1)), RIGHT(A3,LEN(A3)-SEARCH("-",A3,1)), RIGHT(A4,LEN(A4)-SEARCH("-",A4,1)), RIGHT(A5,LEN(A5)-SEARCH("-",A5,1)))
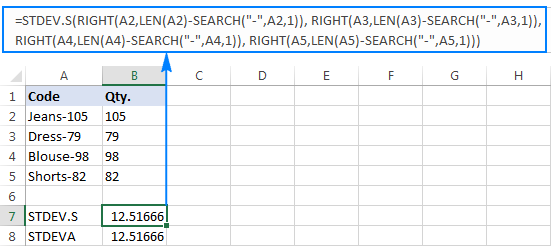
सूत्र थोड़े बोझिल हैं, लेकिन यह एक छोटे से नमूने के लिए एक कार्यशील समाधान हो सकता है। एक बड़े के लिए, पूरी आबादी का उल्लेख नहीं करना निश्चित रूप से एक विकल्प नहीं है। इस मामले में, एक अधिक सुरुचिपूर्ण समाधान होगाVALUE फ़ंक्शन "पाठ-संख्याओं" को उन संख्याओं में रूपांतरित करता है जिन्हें कोई भी मानक विचलन सूत्र समझ सकता है (कृपया नीचे दिए गए स्क्रीनशॉट में दाएं-संरेखित संख्याओं पर ध्यान दें जैसा कि ऊपर दिए गए स्क्रीनशॉट पर बाईं-संरेखित पाठ स्ट्रिंग्स के विपरीत है):
Excel में माध्य की मानक त्रुटि की गणना कैसे करें
आँकड़ों में, डेटा में परिवर्तनशीलता का अनुमान लगाने के लिए एक और उपाय है - माध्य की मानक त्रुटि , जिसे कभी-कभी छोटा कर दिया जाता है (हालांकि, गलत तरीके से) केवल "मानक त्रुटि" के रूप में। माध्य का मानक विचलन और मानक त्रुटि दो निकट संबंधी अवधारणाएँ हैं, लेकिन समान नहीं हैं।
जबकि मानक विचलन माध्य से सेट किए गए डेटा की परिवर्तनशीलता को मापता है, माध्य की मानक त्रुटि (SEM) अनुमान लगाता है कि नमूना माध्य वास्तविक जनसंख्या माध्य से कितनी दूर होने की संभावना है। दूसरे तरीके से कहा - यदि आपने एक ही जनसंख्या से कई नमूने लिए, तो माध्य की मानक त्रुटि उन नमूना माध्यों के बीच फैलाव को दर्शाएगी। क्योंकि आमतौर पर हम डेटा के एक सेट के लिए केवल एक माध्य की गणना करते हैं, न कि कई माध्यमों की, माध्य की मानक त्रुटि को मापने के बजाय अनुमानित किया जाता है।
गणित में, माध्य की मानक त्रुटि की गणना इस सूत्र से की जाती है:
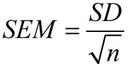
जहां SD मानक विचलन है, और n नमूना आकार है (नमूने में मानों की संख्या)।
आपके एक्सेल वर्कशीट में, आप नंबर प्राप्त करने के लिए COUNT फ़ंक्शन का उपयोग कर सकते हैंएक नमूने में मानों की संख्या, उस संख्या का एक वर्गमूल लेने के लिए SQRT, और एक नमूने के मानक विचलन की गणना करने के लिए STDEV.S।
इन सभी को एक साथ रखकर, आपको एक्सेल में माध्य सूत्र की मानक त्रुटि मिलती है। :
STDEV.S( रेंज )/SQRT(COUNT( रेंज ))यह मानते हुए कि नमूना डेटा B2:B10 में है, हमारा SEM फॉर्मूला इस प्रकार होगा :
=STDEV.S(B2:B10)/SQRT(COUNT(B2:B10))
और परिणाम इसके समान हो सकता है:

एक्सेल में मानक विचलन बार कैसे जोड़ें
मानक विचलन के मार्जिन को विज़ुअल रूप से प्रदर्शित करने के लिए, आप अपने एक्सेल चार्ट में मानक विचलन बार जोड़ सकते हैं। यहां बताया गया है कि कैसे:
- सामान्य तरीके से एक ग्राफ़ बनाएं ( सम्मिलित करें टैब > चार्ट समूह)।
- यहां कहीं भी क्लिक करें इसे चुनने के लिए ग्राफ़ चुनें, फिर चार्ट एलीमेंट्स बटन पर क्लिक करें।
- एरर बार्स के बगल में स्थित तीर पर क्लिक करें, और मानक विचलन चुनें।
यह सभी डेटा बिंदुओं के लिए समान मानक विचलन बार सम्मिलित करेगा।

एक्सेल पर मानक विचलन करने का तरीका यह है। मुझे उम्मीद है कि आपको यह जानकारी मददगार लगी होगी। वैसे भी, मैं आपको पढ़ने के लिए धन्यवाद देता हूं और अगले सप्ताह आपको हमारे ब्लॉग पर देखने की उम्मीद करता हूं।
5 है (एक पूर्णांक के लिए गोल), जो हमें बताता है कि अधिकांश स्कोर माध्य से 5 अंक से अधिक दूर नहीं हैं। क्या वह अच्छा है? ठीक है, हाँ, यह इंगित करता है कि छात्रों के जीव विज्ञान के अंक काफी सुसंगत हैं।गणित के लिए, मानक विचलन 23 है। यह दर्शाता है कि अंकों में एक बड़ा फैलाव (फैलाव) है, जिसका अर्थ है कि कुछ छात्रों ने बहुत बेहतर प्रदर्शन किया और/या कुछ ने औसत से कहीं अधिक खराब प्रदर्शन किया।
व्यावहारिक रूप से, व्यापार विश्लेषणकर्ताओं द्वारा मानक विचलन का उपयोग अक्सर निवेश जोखिम के एक उपाय के रूप में किया जाता है - मानक विचलन जितना अधिक होगा, अस्थिरता उतनी ही अधिक होगी रिटर्न का।
नमूना मानक विचलन बनाम जनसंख्या मानक विचलन
मानक विचलन के संबंध में, आप अक्सर "नमूना" और "जनसंख्या" शब्द सुन सकते हैं, जो की पूर्णता का संदर्भ देते हैं आप जिस डेटा के साथ काम कर रहे हैं। मुख्य अंतर इस प्रकार है:
- जनसंख्या में डेटा सेट के सभी तत्व शामिल हैं।
- नमूना इसका एक उपसमूह है डेटा जिसमें जनसंख्या से एक या अधिक तत्व शामिल होते हैं।
शोधकर्ता और विश्लेषणकर्ता विभिन्न स्थितियों में एक नमूने और जनसंख्या के मानक विचलन पर काम करते हैं। उदाहरण के लिए, छात्रों की एक कक्षा के परीक्षा अंकों का सारांश करते समय, एक शिक्षक जनसंख्या मानक विचलन का उपयोग करेगा। राष्ट्रीय एसएटी औसत स्कोर की गणना करने वाले सांख्यिकीविद नमूना मानक विचलन का उपयोग करेंगे क्योंकिउन्हें केवल एक नमूने के डेटा के साथ प्रस्तुत किया जाता है, पूरी आबादी से नहीं।
मानक विचलन सूत्र को समझना
डेटा की प्रकृति मायने रखती है क्योंकि जनसंख्या मानक विचलन और नमूना मानक विचलन की गणना थोड़े भिन्न सूत्रों के साथ की जाती है:
नमूना मानक विचलन | जनसंख्या मानक विचलन | <21
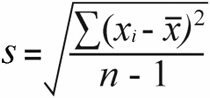 | 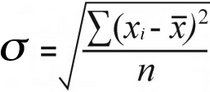 |
कहाँ:
- <8 x i डेटा के सेट में अलग-अलग मान हैं
- x सभी x<2 का माध्य है> मान
- n डेटा सेट में x मानों की कुल संख्या है
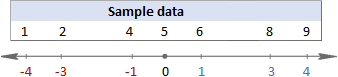
सूत्रों को समझने में कठिनाई हो रही है? उन्हें सरल चरणों में तोड़ने से मदद मिल सकती है। लेकिन पहले, हमारे पास काम करने के लिए कुछ नमूना डेटा हैं:

1. माध्य (औसत) की गणना करें
सबसे पहले, आप डेटा सेट में सभी मानों का माध्य पाते हैं ( x उपरोक्त सूत्रों में)। हाथ से गणना करते समय, आप संख्याओं को जोड़ते हैं और फिर योग को उन संख्याओं की गिनती से विभाजित करते हैं, इस तरह:
(1+2+4+5+6+8+9)/7=5
Excel में माध्य खोजने के लिए, AVERAGE फ़ंक्शन का उपयोग करें, उदा. =औसत(A2:G2)
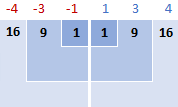
2. प्रत्येक संख्या के लिए, माध्य घटाएँ और परिणाम का वर्ग करें
यह मानक विचलन सूत्र का वह भाग है जो कहता है: ( x i - x )2 <3
वास्तव में क्या चल रहा है, यह देखने के लिए कृपया इसे देखेंनिम्नलिखित चित्र।
इस उदाहरण में, माध्य 5 है, इसलिए हम प्रत्येक डेटा बिंदु और 5 के बीच अंतर की गणना करते हैं।
फिर, आप वर्ग करते हैं अंतर, उन सभी को धनात्मक संख्याओं में बदलना:
3. वर्गित अंतर जोड़ें
गणित में "सम थिंग्स अप" कहने के लिए, आप सिग्मा Σ का उपयोग करते हैं। इसलिए, अब हम सूत्र के इस भाग को पूरा करने के लिए वर्गित अंतरों को जोड़ते हैं: Σ( x i - x )2
16 + 9 + 1 + 1 + 9 + 16 = 52
4. मानों की गणना से कुल वर्ग अंतर को विभाजित करें
अब तक, नमूना मानक विचलन और जनसंख्या मानक विचलन सूत्र समान रहे हैं। इस बिंदु पर, वे भिन्न हैं।
नमूना मानक विचलन के लिए, आपको नमूना प्रसरण प्राप्त होता है, जो कुल वर्ग अंतर को नमूना आकार माइनस 1 से विभाजित करके प्राप्त होता है:
52 / (7-1) = 8.67
जनसंख्या मानक विचलन के लिए, आप कुल को विभाजित करके स्क्वायर अंतर का माध्य पाते हैं अंतर को उनकी गिनती से वर्गित करें:
52 / 7 = 7.43
सूत्रों में यह अंतर क्यों? क्योंकि नमूना मानक विचलन सूत्र में, आपको सही जनसंख्या माध्य के बजाय नमूना माध्य के अनुमान में पूर्वाग्रह को सही करने की आवश्यकता है। और ऐसा आप n के स्थान पर n - 1 का उपयोग करके करते हैं, जिसे बेसेल का सुधार कहते हैं।
5। वर्गमूल लें
अंत में, उपरोक्त का वर्गमूल लेंसंख्याएँ, और आप अपना मानक विचलन प्राप्त करेंगे (नीचे दिए गए समीकरणों में, 2 दशमलव स्थानों तक गोल):
| नमूना मानक विचलन | जनसंख्या मानक विचलन |
| √ 8.67 = 2.94 | √ 7.43 = 2.73 |
माइक्रोसॉफ्ट एक्सेल में मानक विचलन की गणना की जाती है उसी तरह, लेकिन उपरोक्त सभी गणनाएँ दृश्य के पीछे की जाती हैं। आपके लिए महत्वपूर्ण बात यह है कि एक उचित मानक विचलन फ़ंक्शन चुनें, जिसके बारे में निम्नलिखित अनुभाग आपको कुछ सुराग देगा।
एक्सेल में मानक विचलन की गणना कैसे करें
कुल मिलाकर, छह अलग-अलग हैं एक्सेल में मानक विचलन खोजने के लिए कार्य करता है। किसका उपयोग करना है यह मुख्य रूप से उस डेटा की प्रकृति पर निर्भर करता है जिसके साथ आप काम कर रहे हैं - चाहे वह पूरी आबादी हो या एक नमूना।
एक्सेल में नमूना मानक विचलन की गणना करने के लिए कार्य
मानक की गणना करने के लिए एक नमूने के आधार पर विचलन, निम्न सूत्रों में से एक का उपयोग करें (ये सभी ऊपर वर्णित "n-1" विधि पर आधारित हैं)।
एक्सेल STDEV फ़ंक्शन
STDEV(number1,[number2],…) सबसे पुराना एक्सेल है नमूना के आधार पर मानक विचलन का अनुमान लगाने के लिए कार्य करता है, और यह एक्सेल 2003 से 2019 के सभी संस्करणों में उपलब्ध है। , नामित श्रेणियां या संख्या वाले कक्षों के संदर्भ। Excel 2003 में, फ़ंक्शन केवल तक ही स्वीकार कर सकता है30 तर्क।
तर्कों की सूची में सीधे आपूर्ति की गई संख्याओं के तार्किक मान और पाठ प्रतिनिधित्व गिने जाते हैं। सरणियों और संदर्भों में, केवल संख्याओं की गणना की जाती है; खाली कक्ष, TRUE और FALSE के तार्किक मान, पाठ और त्रुटि मान पर ध्यान नहीं दिया जाता है।
नोट। एक्सेल एसटीडीईवी एक पुराना कार्य है, जिसे केवल पिछड़े संगतता के लिए एक्सेल के नए संस्करणों में रखा गया है। हालाँकि, Microsoft भविष्य के संस्करणों के बारे में कोई वादा नहीं करता है। इसलिए, Excel 2010 और बाद में, STDEV के बजाय STDEV.S का उपयोग करने की अनुशंसा की जाती है।
Excel STDEV.S फ़ंक्शन
STDEV.S(number1,[number2],…) , STDEV का एक उन्नत संस्करण है, जिसे Excel 2010 में पेश किया गया था।
STDEV की तरह, STDEV.S फ़ंक्शन पिछले अनुभाग में चर्चित क्लासिक नमूना मानक विचलन सूत्र के आधार पर मूल्यों के एक सेट के नमूना मानक विचलन की गणना करता है।
Excel STDEVA फ़ंक्शन
STDEVA(value1, [value2], …) एक्सेल में एक नमूने के मानक विचलन की गणना करने के लिए एक और कार्य है। यह उपरोक्त दोनों से केवल उस तरीके से भिन्न है जिस तरह से यह तार्किक और पाठ मानों को संभालता है:
- सभी तार्किक मान गिने जाते हैं, चाहे वे सरणियों या संदर्भों में समाहित हों, या सीधे टाइप किए गए हों तर्कों की सूची में (TRUE 1 के रूप में मूल्यांकन करता है, FALSE 0 के रूप में मूल्यांकन करता है)।
- पाठ मान सरणियों या संदर्भ तर्कों के भीतर 0 के रूप में गिने जाते हैं, जिसमें खाली स्ट्रिंग्स (""), टेक्स्ट शामिल हैं संख्याओं का प्रतिनिधित्व, और कोई अन्य पाठ। पाठ का प्रतिनिधित्वतर्कों की सूची में सीधे प्रदान की गई संख्याओं की गणना उन संख्याओं के रूप में की जाती है जिनका वे प्रतिनिधित्व करते हैं (यहां एक सूत्र उदाहरण है)।
- खाली कक्षों को अनदेखा किया जाता है।
नोट एक नमूना मानक विचलन सूत्र के सही ढंग से काम करने के लिए, दिए गए तर्कों में कम से कम दो संख्यात्मक मान होने चाहिए, अन्यथा #DIV/0! त्रुटि वापस आ गई है।
एक्सेल में जनसंख्या मानक विचलन की गणना करने के लिए कार्य
यदि आप पूरी आबादी के साथ काम कर रहे हैं, तो एक्सेल में मानक विचलन करने के लिए निम्न में से किसी एक फ़ंक्शन का उपयोग करें। ये कार्य "एन" विधि पर आधारित हैं।
एक्सेल एसटीडीईवीपी फंक्शन
STDEVP(number1,[number2],…) आबादी के मानक विचलन को खोजने के लिए पुराना एक्सेल कार्य है।
नए संस्करणों में एक्सेल 2010, 2013, 2016 और 2019 में, इसे बेहतर STDEV.P फ़ंक्शन के साथ बदल दिया गया है, लेकिन अभी भी पिछड़े संगतता के लिए रखा गया है।
एक्सेल STDEV.P फ़ंक्शन
STDEV.P(number1,[number2],…) आधुनिक है STDEVP फ़ंक्शन का संस्करण जो एक बेहतर सटीकता प्रदान करता है। यह Excel 2010 और बाद के संस्करणों में उपलब्ध है।
उनके नमूना मानक विचलन समकक्षों की तरह, सरणियों या संदर्भ तर्कों के भीतर, STDEVP और STDEV.P फ़ंक्शन केवल संख्याओं की गणना करते हैं। तर्कों की सूची में, वे संख्याओं के तार्किक मानों और पाठ निरूपणों की भी गणना करते हैं।
Excel STDEVPA फ़ंक्शन
STDEVPA(value1, [value2], …) पाठ और तार्किक मानों सहित जनसंख्या के मानक विचलन की गणना करता है। गैर-संख्यात्मक के संबंध मेंमान, STDEVPA ठीक उसी तरह काम करता है जैसे STDEVA फ़ंक्शन करता है।
ध्यान दें। आप जो भी एक्सेल मानक विचलन सूत्र का उपयोग करते हैं, यह एक त्रुटि लौटाएगा यदि एक या अधिक तर्कों में किसी अन्य फ़ंक्शन या पाठ द्वारा लौटाए गए त्रुटि मान होते हैं जिसे एक संख्या के रूप में नहीं समझा जा सकता है।
किस एक्सेल मानक विचलन फ़ंक्शन का उपयोग करना है?
एक्सेल में विभिन्न प्रकार के मानक विचलन कार्य निश्चित रूप से गड़बड़ कर सकते हैं, विशेष रूप से अनुभवहीन उपयोगकर्ताओं के लिए। किसी विशेष कार्य के लिए सही मानक विचलन सूत्र चुनने के लिए, बस निम्नलिखित 3 प्रश्नों का उत्तर दें:
- क्या आप किसी नमूने या जनसंख्या के मानक विचलन की गणना करते हैं?
- आप एक्सेल का कौन सा संस्करण इस्तेमाल करते हैं उपयोग करें?
- क्या आपके डेटा सेट में केवल संख्याएं या तार्किक मान और पाठ भी शामिल हैं?
एक संख्यात्मक नमूना के आधार पर मानक विचलन की गणना करने के लिए, का उपयोग करें STDEV.S एक्सेल 2010 और बाद में कार्य करता है; Excel 2007 और इससे पहले के संस्करण में STDEV।
आबादी का मानक विचलन खोजने के लिए, Excel 2010 और बाद के संस्करण में STDEV.P फ़ंक्शन का उपयोग करें; एक्सेल 2007 और पहले के संस्करण में एसटीडीईवीपी।
यदि आप तार्किक या टेक्स्ट मूल्यों को गणना में शामिल करना चाहते हैं, तो या तो एसटीडीईवीए (नमूना मानक विचलन) या एसटीडीईवीपीए ( जनसंख्या मानक विचलन)। जबकि मैं किसी भी परिदृश्य के बारे में नहीं सोच सकता जिसमें कोई भी कार्य अपने आप उपयोगी हो सकता है, वे बड़े सूत्रों में काम में आ सकते हैं, जहाँ एक या अधिक तर्क दिए जाते हैंतार्किक मानों या संख्याओं के पाठ प्रतिनिधित्व के रूप में अन्य कार्य।
यह तय करने में आपकी सहायता के लिए कि एक्सेल मानक विचलन कार्यों में से कौन सा आपकी आवश्यकताओं के लिए सबसे उपयुक्त है, कृपया निम्नलिखित तालिका की समीक्षा करें जो आपके द्वारा पहले से सीखी गई जानकारी को सारांशित करती है।
| STDEV | STDEV.S | STDEVP | STDEV.P | STDEVA | STDEVPA | |
| एक्सेल संस्करण | 2003 - 2019 | 2010 - 2019 | 2003 - 2019 | 2010 - 2019 | 2003 - 2019 | 2003 - 2019 |
| नमूना | ✓ | ✓ | ✓ | |||
| आबादी | ✓ | ✓ | ✓ | |||
| सरणियों में तार्किक मान या संदर्भ | उपेक्षित | मूल्यांकन किया गया (TRUE=1, FALSE=0) | ||||
| सारणी या संदर्भ में पाठ | अनदेखा किया गया | शून्य के रूप में मूल्यांकन किया गया | ||||
| तर्कों की सूची में तार्किक मान और "पाठ-संख्या" | मूल्यांकन किया गया (TRUE =1, FALSE=0) | |||||
| खाली सेल | <3 4>अनदेखा किया गया||||||
Excel मानक विचलन सूत्र के उदाहरण
एक बार जब आप अपने डेटा प्रकार के अनुरूप फ़ंक्शन चुन लेते हैं, तो लिखने में कोई कठिनाई नहीं होनी चाहिए फार्मूला - सिंटैक्स इतना सादा और पारदर्शी है कि यह त्रुटियों के लिए कोई जगह नहीं छोड़ता :) निम्नलिखित उदाहरण कुछ एक्सेल मानक विचलन सूत्रों को क्रियान्वित करते हुए प्रदर्शित करते हैं।
मानक की गणना करना
