
Ynhâldsopjefte
De tutorial ferklearret de essinsje fan 'e standertdeviaasje en standertflater fan 'e gemiddelde en ek hokker formule it bêste brûkt wurde kin foar it berekkenjen fan standertdeviaasje yn Excel.
Yn beskriuwende statistyk , it rekenkundige gemiddelde (ek wol it gemiddelde neamd) en standertdeviaasje en binne twa nau besibbe begripen. Mar wylst it earste troch de measten goed begrepen wurdt, wurdt it lêste troch in pear begrepen. It doel fan dizze tutorial is wat ljocht te werpen op wat de standertdeviaasje eins is en hoe't jo dizze yn Excel berekkenje kinne.
Wat is standertdeviaasje?
De standertdeviaasje is in maat dy't oanjout hoefolle de wearden fan 'e set gegevens ôfwike (ferspraat) fan 'e gemiddelde. Om it oars te sizzen, de standertdeviaasje lit sjen oft jo gegevens ticht by it gemiddelde binne of in protte fluktuearje.
It doel fan 'e standertdeviaasje is om jo te helpen te begripen oft it gemiddelde echt in "typyske" gegevens werombringt. Hoe tichter de standertdeviaasje by nul is, hoe leger de datafariabiliteit en hoe betrouberer it gemiddelde is. De standertdeviaasje lyk oan 0 jout oan dat elke wearde yn 'e dataset krekt gelyk is oan it gemiddelde. Hoe heger de standertdeviaasje, hoe mear fariaasje der is yn de gegevens en hoe minder krekt it gemiddelde is.
Om in better idee te krijen fan hoe't dit wurket, sjoch ris nei de folgjende gegevens:
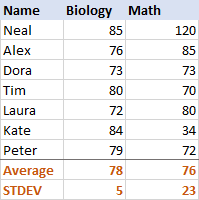
Foar Biology, de standertdeviaasjeôfwiking fan in stekproef en populaasje
Ôfhinklik fan de aard fan jo gegevens, brûk ien fan de folgjende formules:
- Om standertdeviaasje te berekkenjen basearre op de hiele populaasje , d.w.s. de folsleine list mei wearden (B2:B50 yn dit foarbyld), brûk de STDEV.P-funksje:
=STDEV.P(B2:B50) - Om standertdeviaasje te finen basearre op in sample dat in diel, of subset, fan 'e populaasje foarmet (B2:B10 yn dit foarbyld), brûk de STDEV.S-funksje:
=STDEV.S(B2:B10)
Sa't jo sjen kinne yn 'e skermôfbylding hjirûnder, de formules jouwe wat ferskillende nûmers werom (hoe lytser in stekproef, hoe grutter in ferskil):
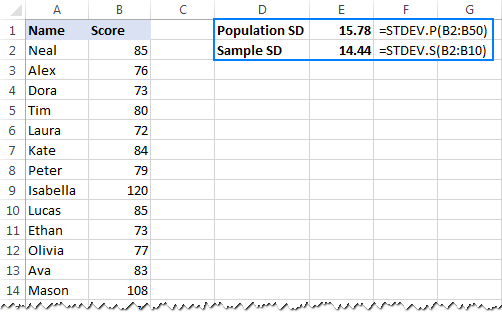
Yn Excel 2007 en leger soene jo STDEVP- en STDEV-funksjes brûke ynstee:
- Om populaasjestandertdeviaasje te krijen:
=STDEVP(B2:B50) - Om sample standertdeviaasje te berekkenjen:
=STDEV(B2:B10)
Berekkenjen fan standertdeviaasje foar tekstfoarstellings fan getallen
By it besprekken fan ferskate funksjes om standertdeviaasje yn Excel te berekkenjen, neamden wy soms "tekst r" foarstellings fan getallen" en jo binne miskien nijsgjirrich om te witten wat dat eins betsjut.
Yn dit ferbân binne "tekstfoarstellings fan getallen" gewoan sifers opmakke as tekst. Hoe kinne sokke sifers ferskine yn jo wurkblêden? Meast faak, se wurde eksportearre út eksterne boarnen. Of, weromjûn troch saneamde Tekstfunksjes dy't ûntwurpen binne om tekststrings te manipulearjen, bgl. TEKST, MIDDEN, RJOCHTS, LEFT,ensfh. Guon fan dy funksjes kinne ek mei sifers wurkje, mar har útfier is altyd tekst, sels as it in protte op in nûmer liket.
Om it punt better te yllustrearjen, beskôgje asjebleaft it folgjende foarbyld. Stel dat jo in kolom fan produktkoades hawwe lykas "Jeans-105" wêr't de sifers nei in koppelteken de kwantiteit oanjaan. Jo doel is om de kwantiteit fan elk item te ekstrahearjen, en dan de standertdeviaasje fan 'e ekstrahearre nûmers te finen.
De kwantiteit nei in oare kolom lûke is gjin probleem:
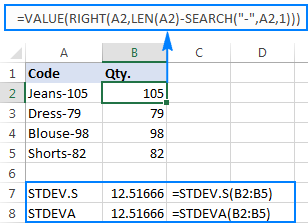
=RIGHT(A2,LEN(A2)-SEARCH("-",A2,1))
It probleem is dat it brûken fan in Excel-standertdeviaasjeformule op 'e ekstrahearre nûmers òf #DIV/0 jout! of 0 lykas werjûn yn it skermôfbylding hjirûnder:
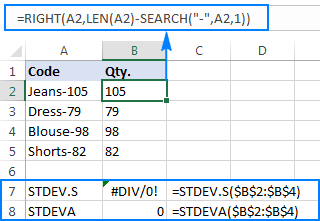
Wêrom sokke rare resultaten? Lykas hjirboppe neamd, is de útfier fan 'e RIGHT-funksje altyd in tekststring. Mar noch STDEV.S noch STDEVA kinne nûmers opmakke as tekst yn ferwizings behannelje (de earste negearret se gewoan, wylst de lêste as nullen telt). Om de standertdeviaasje fan sokke "tekstnûmers" te krijen, moatte jo se direkt yn 'e list mei arguminten leverje, wat dien wurde kin troch alle RIGHT-funksjes yn jo STDEV.S- of STDEVA-formule yn te setten:
=STDEV.S(RIGHT(A2,LEN(A2)-SEARCH("-",A2,1)), RIGHT(A3,LEN(A3)-SEARCH("-",A3,1)), RIGHT(A4,LEN(A4)-SEARCH("-",A4,1)), RIGHT(A5,LEN(A5)-SEARCH("-",A5,1)))
=STDEVA(RIGHT(A2,LEN(A2)-SEARCH("-",A2,1)), RIGHT(A3,LEN(A3)-SEARCH("-",A3,1)), RIGHT(A4,LEN(A4)-SEARCH("-",A4,1)), RIGHT(A5,LEN(A5)-SEARCH("-",A5,1)))
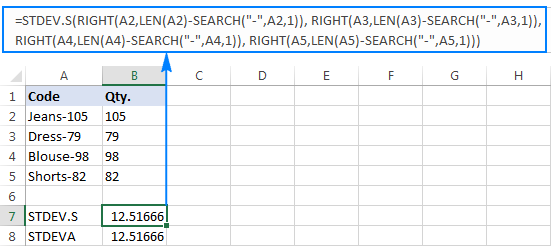
De formules binne wat omslachtich, mar dat kin in wurkjende oplossing wêze foar in lyts stekproef. Foar in gruttere, om de hiele befolking net te hawwen, is it perfoarst gjin opsje. Yn dit gefal soe in mear elegante oplossing wêze it hawwen fan deVALUE-funksje konvertearret "tekst-nûmers" nei nûmers dy't elke standertdeviaasjeformule kin begripe (sjoch asjebleaft de rjochts rjochte sifers yn 'e skermôfbylding hjirûnder yn tsjinstelling ta de lofts rjochte tekststrings op' e skermôfdruk hjirboppe):
Hoe kinne jo standertfout fan gemiddelde yn Excel berekkenje
Yn statistyk is d'r noch ien maatregel foar it skatten fan de fariabiliteit yn gegevens - standertflater fan gemiddelde , dat wurdt soms ynkoarte (hoewol, ferkeard) ta gewoan "standert flater". De standertdeviaasje en standertflater fan 'e gemiddelde binne twa nau besibbe begripen, mar net itselde.
Wylst de standertdeviaasje de fariabiliteit fan in gegevensset fan 'e gemiddelde mjit, is de standertfout fan 'e gemiddelde (SEM) skatte hoe fier it stekproefgemiddelde wierskynlik is fan it wiere populaasjegemiddelde. Sei in oare manier - as jo namen meardere samples út deselde befolking, soe de standert flater fan it gemiddelde sjen litte de fersprieding tusken dy stekproef betsjut. Om't wy gewoanlik mar ien gemiddelde berekkenje foar in set gegevens, net meardere middels, wurdt de standertfout fan it gemiddelde rûsd ynstee fan mjitten.
Yn de wiskunde wurdt de standertfout fan gemiddelde berekkene mei dizze formule:
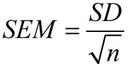
Wêr't SD de standertdeviaasje is, en n de stekproefgrutte is (it oantal wearden yn 'e stekproef).
Yn jo Excel-wurkblêden kinne jo de funksje COUNT brûke om it nûmer te krijenfan wearden yn in stekproef, SQRT om in fjouwerkantswoartel fan dat getal te nimmen, en STDEV.S om standertdeviaasje fan in stekproef te berekkenjen.
As jo dit alles byinoar sette, krije jo de standertflater fan 'e gemiddelde formule yn Excel :
STDEV.S( berik )/SQRT(COUNT( berik ))Aannommen dat de foarbyldgegevens yn B2:B10 binne, soe ús SEM-formule as folgjend gean :
=STDEV.S(B2:B10)/SQRT(COUNT(B2:B10))
En it resultaat kin fergelykber wêze mei dit:

Hoe kinne jo standertdeviaasjebalken tafoegje yn Excel
Om visueel in marzje fan 'e standertdeviaasje wer te jaan, kinne jo standertdeviaasjebalken tafoegje oan jo Excel-diagram. Hjir is hoe:
- Meitsje in grafyk op 'e gewoane manier ( Ynfoegje tab > Charts groep).
- Klik oeral op de grafyk om it te selektearjen, klik dan op de knop Chart Elements .
- Klik op de pylk neist Flaterbalken , en kies Standertôfwiking .
Dit sil deselde standertdeviaasjebalken ynfoegje foar alle gegevenspunten.

Dit is hoe't jo standertdeviaasje dwaan op Excel. Ik hoopje dat jo dizze ynformaasje nuttich fine. Hoe dan ek, ik tankje jo foar it lêzen en hoopje jo nije wike op ús blog te sjen.
is 5 (ôfrûn op in hiel getal), dat fertelt ús dat de mearderheid fan skoares binne net mear as 5 punten fuort fan it gemiddelde. Is dat goed? No ja, it jout oan dat de Biology-skoares fan de learlingen aardich konsekwint binne.Foar Wiskunde is de standertdeviaasje 23. It docht bliken dat der in grutte fersprieding (fersprieding) is yn de skoares, wat betsjut dat guon studinten prestearren folle better en/of guon prestearren folle minder as it gemiddelde.
Yn 'e praktyk wurdt de standertdeviaasje faak brûkt troch saaklike analysten as mjitte fan ynvestearringsrisiko - hoe heger de standertdeviaasje, hoe heger de volatiliteit fan de rendeminten.
Sample standertdeviaasje tsjin populaasje standertdeviaasje
Yn relaasje mei standertdeviaasje kinne jo faaks de termen "sample" en "population" hearre, dy't ferwize nei de folsleinens fan de gegevens wêrmei jo wurkje. It wichtichste ferskil is as folget:
- Befolking befettet alle eleminten út in gegevensset.
- Sample is in subset fan gegevens dy't ien of mear eleminten út 'e populaasje befetsje.
Undersikers en analysts operearje op 'e standertdeviaasje fan in stekproef en populaasje yn ferskate situaasjes. Bygelyks, by it gearfetten fan de eksamenskoares fan in klasse studinten, sil in learaar de populaasjestandertôfwiking brûke. Statisticians berekkenjen fan de nasjonale SAT gemiddelde skoare soe brûke in stekproef standertdeviaasje omdatse wurde presintearre mei de gegevens fan allinich in stekproef, net fan 'e hiele populaasje.
De standertdeviaasjeformule begripe
De reden dat de aard fan 'e gegevens fan belang is, is om't de populaasje standertdeviaasje en stekproef standertdeviaasje wurde berekkene mei wat ferskillende formules:
Sample standertdeviaasje | Befolkingstandertdeviaasje |
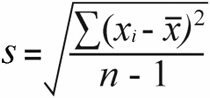 | 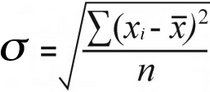 |
Wêr:
- x i binne yndividuele wearden yn de set gegevens
- x is it gemiddelde fan alle x wearden
- n is it totale oantal x -wearden yn de gegevensset
Swierrichheden hawwe mei it begripen fan de formules? It opbrekken fan se yn ienfâldige stappen kin helpe. Mar lit ús earst wat foarbyldgegevens hawwe om oan te wurkjen:

1. Berekkenje it gemiddelde (gemiddelde)
Earst fine jo it gemiddelde fan alle wearden yn 'e dataset ( x yn 'e formules hjirboppe). By it berekkenjen mei de hân, telle jo de nûmers op en diele dan de som troch it oantal fan dy nûmers, sa as dit:
(1+2+4+5+6+8+9)/7=5
Om betsjutting te finen yn Excel, brûk de AVERAGE-funksje, bgl. =AVERAGE(A2:G2)
2. Foar elk getal, subtrahearje it gemiddelde en kwadraat it resultaat
Dit is it diel fan 'e standertdeviaasjeformule dat seit: ( x i - x )2
Om te sjen wat der eins bart, sjoch asjebleaft neide folgjende ôfbyldings.
Yn dit foarbyld is it gemiddelde 5, dus berekkenje wy it ferskil tusken elk gegevenspunt en 5.
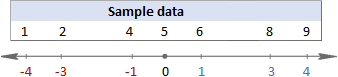
Dan, jo kwadraat de ferskillen, wêrtroch't se allegear positive sifers meitsje:
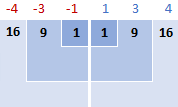
3. Foegje fjouwerkante ferskillen op
Om "dingen op te tellen" yn wiskunde te sizzen, brûke jo sigma Σ. Dat, wat wy no dogge, is de kwadraatferskillen optelle om dit diel fan 'e formule te foltôgjen: Σ( x i - x )2
16 + 9 + 1 + 1 + 9 + 16 = 52
4. Diel de totale kwadraatferskillen troch it oantal wearden
Oant no binne de formules foar standertdeviaasje en populaasjestandertdeviaasje identyk west. Op dit punt binne se oars.
Foar de sample standertdeviaasje krije jo de sample fariânsje troch de totale kwadraatferskillen te dielen troch de stekproefgrutte min 1:
52 / (7-1) = 8.67
Foar de befolking standertdeviaasje fine jo it gemiddelde fan kwadraatferskillen troch it totaal te dielen kwadraatferskillen troch har oantal:
52 / 7 = 7,43
Wêrom dit ferskil yn 'e formules? Om't yn 'e formule fan' e standertdeviaasje fan 'e stekproef, jo moatte korrigearje de bias yn' e skatting fan in stekproef gemiddelde ynstee fan de wiere befolking gemiddelde. En dat dogge jo troch n - 1 te brûken yn stee fan n , wat de korreksje fan Bessel hjit.
5. Nim de fjouwerkantswoartel
Nim as lêste de fjouwerkantswoartel fan it boppesteandenûmers, en jo sille jo standertdeviaasje krije (yn 'e ûndersteande fergelikingen, ôfrûn op 2 desimale plakken):
| Sample standertdeviaasje | Befolkingstandertdeviaasje |
| √ 8.67 = 2.94 | √ 7.43 = 2.73 |
Yn Microsoft Excel wurdt standertdeviaasje berekkene yn de deselde wize, mar al de boppesteande berekkeningen wurde útfierd efter it toaniel. It wichtichste ding foar jo is om in goede standertdeviaasjefunksje te kiezen, dêr't de folgjende paragraaf jo wat oanwizings oer sil jaan.
Hoe kinne jo standertdeviaasje berekkenje yn Excel
Oeral binne der seis ferskillende funksjes om standertdeviaasje te finen yn Excel. Hokker te brûken hinget foaral ôf fan 'e aard fan' e gegevens wêrmei't jo wurkje - oft it no de hiele populaasje is as in stekproef.
Funksjes foar it berekkenjen fan de standertdeviaasje fan 'e sample yn Excel
Om standert te berekkenjen ôfwiking basearre op in stekproef, brûk ien fan de folgjende formules (allegear binne basearre op de "n-1" metoade hjirboppe beskreaun).
Excel STDEV-funksje
STDEV(number1,[number2],…) is de âldste Excel funksje om standertdeviaasje te skatten basearre op in stekproef, en it is beskikber yn alle ferzjes fan Excel 2003 oant 2019.
Yn Excel 2007 en letter kin STDEV oant 255 arguminten akseptearje dy't kinne wurde fertsjintwurdige troch nûmers, arrays , neamde berik of ferwizings nei sellen mei nûmers. Yn Excel 2003 kin de funksje allinich akseptearje oant30 arguminten.
Logyske wearden en tekstfoarstellings fan nûmers dy't direkt yn 'e list mei arguminten oanjûn binne, wurde teld. Yn arrays en referinsjes wurde allinnich nûmers teld; lege sellen, logyske wearden fan TRUE en FALSE, tekst- en flaterwearden wurde negearre.
Opmerking. Excel STDEV is in ferâldere funksje, dy't bewarre wurdt yn 'e nijere ferzjes fan Excel allinich foar efterkompatibiliteit. Microsoft makket lykwols gjin beloften oangeande de takomstige ferzjes. Dus, yn Excel 2010 en letter, is it oan te rieden om STDEV.S te brûken ynstee fan STDEV.
Excel STDEV.S-funksje
STDEV.S(number1,[number2],…) is in ferbettere ferzje fan STDEV, yntrodusearre yn Excel 2010.
Lykas STDEV, berekkenet de STDEV.S-funksje de standertdeviaasje fan in set wearden op basis fan de klassike standertdeviaasjeformule foar foarbylden dy't besprutsen is yn 'e foarige paragraaf.
Excel STDEVA-funksje
STDEVA(value1, [value2], …) is in oare funksje foar it berekkenjen fan standertdeviaasje fan in stekproef yn Excel. It ferskilt fan de boppesteande twa allinich yn 'e manier wêrop it omgiet logyske en tekstwearden:
- Alle logyske wearden wurde teld, of se binne befette yn arrays of ferwizings, of direkt typearre yn de list mei arguminten (TRUE evaluearret as 1, FALSE evaluearret as 0).
- Tekstwearden binnen arrays of referinsjearguminten wurde teld as 0, ynklusyf lege stringen (""), tekst foarstellings fan nûmers, en elke oare tekst. Tekstfoarstellings fannûmers dy't direkt yn 'e list mei arguminten oanbean wurde, wurde teld as de nûmers dy't se fertsjintwurdigje (hjir is in formulefoarbyld).
- Lege sellen wurde negearre.
Opmerking. Foar in foarbyld fan standertdeviaasjeformule om goed te wurkjen, moatte de levere arguminten op syn minst twa numerike wearden befetsje, oars de #DIV/0! flater wurdt weromjûn.
Funksjes foar it berekkenjen fan populaasjestandertdeviaasje yn Excel
As jo te krijen hawwe mei de hiele populaasje, brûk dan ien fan de folgjende funksjes om standertdeviaasje yn Excel te dwaan. Dizze funksjes binne basearre op de "n" metoade.
Excel STDEVP-funksje
STDEVP(number1,[number2],…) is de âlde Excel-funksje om standertdeviaasje fan in populaasje te finen.
Yn de nije ferzjes fan Excel 2010, 2013, 2016 en 2019, wurdt it ferfongen troch de ferbettere STDEV.P-funksje, mar wurdt noch altyd bewarre foar efterkompatibiliteit.
Excel STDEV.P-funksje
STDEV.P(number1,[number2],…) is de moderne ferzje fan de STDEVP-funksje dy't in ferbettere krektens leveret. It is beskikber yn Excel 2010 en letter ferzjes.
Lykas harren foarbyld standertdeviaasje tsjinhingers, binnen arrays of referinsje arguminten, de STDEVP en STDEV.P funksjes telle allinnich sifers. Yn de list mei arguminten telle se ek logyske wearden en tekstfoarstellings fan sifers.
Excel STDEVPA-funksje
STDEVPA(value1, [value2], …) berekkent standertdeviaasje fan in populaasje, ynklusyf tekst en logyske wearden. Oangeande net-numerikewearden, STDEVPA wurket krekt lykas de STDEVA funksje docht.
Opmerking. Hokker Excel standertdeviaasjeformule jo ek brûke, it sil in flater weromjaan as ien of mear arguminten in flaterwearde befetsje dy't weromjûn wurdt troch in oare funksje of tekst dy't net as in getal ynterpretearre wurde kin.
Hokker Excel-standertdeviaasjefunksje te brûken?
In ferskaat oan standertdeviaasjefunksjes yn Excel kin perfoarst in puinhoop feroarsaakje, foaral foar sûnder ûnderfining brûkers. Om de juste standertdeviaasjeformule foar in bepaalde taak te kiezen, beantwurdzje gewoan de folgjende 3 fragen:
- Berekkenje jo standertdeviaasje fan in stekproef of populaasje?
- Hokker Excel-ferzje dogge jo brûke?
- Befettet jo gegevensset ek allinnich nûmers of logyske wearden en tekst?
Om standertdeviaasje te berekkenjen basearre op in numerike sample , brûk de STDEV.S funksje yn Excel 2010 en letter; STDEV yn Excel 2007 en earder.
Om standertdeviaasje fan in befolking te finen, brûk de STDEV.P-funksje yn Excel 2010 en letter; STDEVP yn Excel 2007 en earder.
As jo wolle dat logyske of tekst wearden opnommen wurde yn 'e berekkening, brûk dan STDEVA (sample standertdeviaasje) of STDEVPA ( populaasje standertdeviaasje). Hoewol ik gjin senario kin betinke wêryn beide funksjes op harsels nuttich wêze kinne, kinne se fan pas komme yn gruttere formules, wêrby't ien of mear arguminten weromjûn wurde trochoare funksjes as logyske wearden of tekstfoarstellings fan sifers.
Om jo te helpen beslute hokker fan 'e Excel-standertôfwikingsfunksjes it bêste by jo behoeften past, kontrolearje asjebleaft de folgjende tabel dy't de ynformaasje gearfettet dy't jo al leard hawwe.
| STDEV | STDEV.S | STDEVP | STDEV.P | STDEVA | STDEVPA | |
| Excel ferzje | 2003 - 2019 | 2010 - 2019 | 2003 - 2019 | 2010 - 2019 | 2003 - 2019 | 2003 - 2019 |
| Sample | ✓ | ✓ | ✓ | |||
| Befolking | ✓ | ✓ | ✓ | |||
| Logyske wearden yn arrays of referinsjes | Negearre | Evaluearre (TRUE=1, FALSE=0) | ||||
| Tekst yn arrays of referinsjes | Negearre | Evaluearre as nul | ||||
| Logyske wearden en "tekstnûmers" yn 'e list mei arguminten | Evaluearre (TRUE =1, FALSE=0) | |||||
| Lege sellen | <3 4>Negearre||||||
Excel standertdeviaasjeformulefoarbylden
As jo ienris de funksje keazen hawwe dy't oerienkomt mei jo gegevenstype, soene d'r gjin swierrichheden wêze moatte by it skriuwen fan de formule - de syntaksis is sa sljocht en trochsichtich dat it gjin romte lit foar flaters :) De folgjende foarbylden litte in pear Excel-standertôfwikingsformules yn aksje sjen.
Standert berekkenjen
