
Table of contents
本教程解释了标准差和平均数的标准误差的本质,以及在Excel中计算标准差时最好使用哪个公式。
在描述性统计中,算术平均数(也叫平均数)和标准差是两个密切相关的概念。 但是,虽然前者被大多数人所理解,但后者却很少有人理解。 本教程的目的是阐明什么是标准差以及如何在Excel中计算它。
什么是标准差?
ǞǞǞ 标准差 换句话说,标准差表明你的数据是接近平均值还是波动很大。
标准差的目的是帮助你了解平均数是否真的返回了一个 "典型 "的数据。 标准差越接近于零,数据的变异性就越低,平均数就越可靠。 标准差等于0表示数据集中的每个值都完全等于平均数。 标准差越高,数据中的变异就越多。数据,平均值就越不准确。
为了更好地了解这一点,请看以下数据。
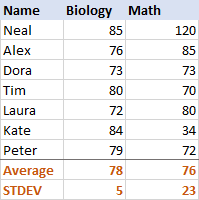
对于生物学来说,标准差是5(四舍五入为整数),这告诉我们大多数分数与平均值的差距不超过5分。 这很好吗? 嗯,是的,这表明学生的生物学分数相当稳定。
就数学而言,标准差是23,这表明分数存在巨大的离散性(spread),这意味着有些学生的表现比平均水平好得多,和/或有些学生的表现远不如平均水平。
在实践中,标准差经常被商业分析家用来衡量投资风险--标准差越高,收益的波动性就越大。
样本标准差与群体标准差的对比
关于标准差,你可能经常听到 "样本 "和 "群体 "这两个术语,它们指的是你所处理的数据的完整性。 主要区别如下。
- 人口 包括一个数据集的所有元素。
- 样品 是一个数据子集,包括人口中的一个或多个元素。
研究人员和分析人员在不同情况下对样本和群体的标准差进行操作。 例如,在总结一个班级学生的考试成绩时,教师会使用群体标准差。 统计人员在计算全国SAT平均分时,会使用样本标准差,因为他们所得到的只是样本的数据,而非从整个人口中。
了解标准差公式
数据的性质之所以重要,是因为人口标准差和样本标准差的计算公式略有不同。
样本标准偏差 | 人口标准差 |
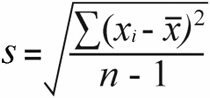 | 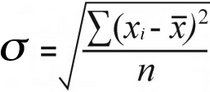 |
在哪里?
- x i 是数据集合中的单个值
- x 是所有 x 价值
- n 是总数的 x 数据集中的值
在理解公式方面有困难吗? 把它们分解成简单的步骤可能会有帮助。 但首先,让我们有一些样本数据来进行处理。

1.计算平均值(平均数)
首先,你要找到数据集中所有数值的平均值( x 当用手计算时,你将数字相加,然后用总和除以这些数字的数量,像这样。
(1+2+4+5+6+8+9)/7=5
要在Excel中找到平均值,请使用AVERAGE函数,例如:=AVERAGE(A2:G2)
2.对于每个数字,减去平均数,然后将结果平方。
这就是标准偏差公式的一部分,它说:( x i - x )2
为了直观了解实际情况,请看以下图片。
在这个例子中,平均值是5,所以我们计算每个数据点与5之间的差异。
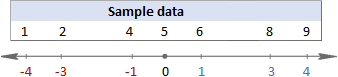
然后,你将差值平方,把它们全部变成正数。
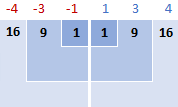
3.相加的平方差
所以,我们现在要做的是把平方差加起来,以完成公式的这一部分:Σ( x i - x )2
16 + 9 + 1 + 1 + 9 + 16 = 52
4.用总的平方差除以数值的数量
到目前为止,样本标准差和群体标准差的公式是相同的。 在这一点上,它们是不同的。
对于 样品标准差 ,你会得到 样本方差 用总的平方差异除以样本量减去1。
52 / (7-1) = 8.67
对于 人口标准差 ,你发现 差异平方的平均值 通过将总的平方差值除以他们的数量。
52 / 7 = 7.43
为什么公式中会有这种差异? 因为在样本标准差公式中,你需要纠正对样本平均数而不是真正的群体平均数的估计中的偏差。 你通过使用 n - 1 而不是 n ,这被称为贝塞尔修正。
5.取平方根
最后,取上述数字的平方根,你将得到你的标准差(在下面的方程式中,四舍五入到小数点后2位)。
| 样本标准偏差 | 人口标准差 |
| √ 8.67 = 2.94 | √ 7.43 = 2.73 |
在Microsoft Excel中,标准差的计算方法相同,但上述所有计算都是在幕后进行的。 对你来说,关键是要选择一个合适的标准差函数,关于这一点,下面的章节会给你一些线索。
如何在Excel中计算标准差
总的来说,在Excel中有六种不同的函数来寻找标准差。 使用哪一种主要取决于你所处理的数据的性质--是整个人口还是一个样本。
在Excel中计算样本标准偏差的函数
要计算基于样本的标准差,请使用以下公式之一(所有这些公式都是基于上述的 "n-1 "方法)。
Excel STDEV函数
STDEV(number1,[number2],...) 是最古老的Excel函数,用于估计基于样本的标准差,它在Excel 2003至2019年的所有版本中都可用。
在Excel 2007及以后的版本中,STDEV最多可以接受255个参数,这些参数可以用数字、数组、命名的范围或包含数字的单元格的引用来表示。 在Excel 2003中,该函数最多只能接受30个参数。
在参数列表中直接提供的数字的逻辑值和文本表示被计算。 在数组和引用中,只有数字被计算;空单元、TRUE和FALSE的逻辑值、文本和错误值被忽略。
注意:Excel STDEV是一个过时的函数,保留在较新的Excel版本中只是为了向后兼容。 然而,微软对未来的版本没有任何承诺。 因此,在Excel 2010及以后的版本中,建议使用STDEV.S而不是STDEV。
Excel STDEV.S函数
STDEV.S(number1,[number2],...) 是STDEV的改进版,在Excel 2010中引入。
与STDEV一样,STDEV.S函数根据上一节讨论的经典样本标准差公式,计算一组数值的样本标准差。
Excel STDEVA函数
STDEVA(value1, [value2], ...) 是另一个在Excel中计算样本标准差的函数。 它与上述两个函数的不同之处仅在于它处理逻辑值和文本值的方式。
- 全部 逻辑值 都被计算在内,无论它们是包含在数组或引用中,还是直接输入到参数列表中(TRUE评估为1,FALSE评估为0)。
- 文本值 在数组或引用参数中的数字被计算为0,包括空字符串("")、数字的文本表示和任何其他文本。 在参数列表中直接提供的数字的文本表示被计算为它们所代表的数字(这里有一个公式例子)。
- 空的单元格会被忽略。
注意:为了使样本标准差公式正常工作,提供的参数必须至少包含两个数值,否则会返回#DIV/0!错误。
在Excel中计算人口标准差的函数
如果你处理的是整个人口,请使用以下函数之一在Excel中做标准差。 这些函数是基于 "n "方法的。
Excel STDEVP函数
STDEVP(number1,[number2],...) 是Excel的旧函数,用于查找人口的标准偏差。
在Excel 2010、2013、2016和2019的新版本中,它被改进后的STDEV.P函数所取代,但为了向后兼容仍被保留。
Excel STDEV.P函数
STDEV.P(number1,[number2],...) 是STDEVP函数的现代版本,提供了更高的精度。 它在Excel 2010及以后的版本中可用。
就像它们的样本标准差一样,在数组或引用参数中,STDEVP和STDEV.P函数只计算数字。 在参数列表中,它们也计算逻辑值和数字的文本表示法。
Excel STDEVPA函数
STDEVPA(value1, [value2], ...) 计算一个群体的标准差,包括文本和逻辑值。 对于非数字值,STDEVPA的工作原理与STDEVA函数完全相同。
注意:无论你使用哪种Excel标准偏差公式,如果一个或多个参数包含一个由其他函数返回的错误值或不能解释为数字的文本,它将返回一个错误。
使用哪个Excel标准差函数?
Excel中的各种标准差函数肯定会造成混乱,尤其是对没有经验的用户来说。 要为某项任务选择正确的标准差公式,只需回答以下3个问题。
- 你会计算样本或群体的标准差吗?
- 你用的是什么Excel版本?
- 你的数据集是否只包括数字或逻辑值和文本?
要计算基于数字的标准偏差 样本 ,在Excel 2010及以后版本中使用STDEV.S函数;在Excel 2007及以前版本中使用STDEV。
要找到一个人的标准偏差 人口 ,在Excel 2010及以后版本中使用STDEV.P函数;在Excel 2007及以前版本中使用STDEVP。
如果你想 合理 或 文本 虽然我想不出这两个函数在什么情况下可以单独使用,但它们在更大的公式中可能会派上用场,其中一个或多个参数被其他函数作为逻辑值或数字的文本表示形式返回。
为了帮助你决定哪一个Excel标准差函数最适合你的需要,请查看下表,该表总结了你已经学到的信息。
| STDEV | STDEV.S | ǞǞǞ | STDEV.P | ǞǞǞ | STDEVPA | |
| Excel版本 | 2003 - 2019 | 2010 - 2019 | 2003 - 2019 | 2010 - 2019 | 2003 - 2019 | 2003 - 2019 |
| 样品 | ||||||
| 人口 | ||||||
| 数组或引用中的逻辑值 | 被忽视的 | 已评估 (true=1, false=0) | ||||
| 数组或引用中的文本 | 被忽视的 | 被评估为零 | ||||
| 参数列表中的逻辑值和 "文本-数字"。 | 已评估 (true=1, false=0) | |||||
| 空的细胞 | 被忽视的 | |||||
Excel标准偏差公式实例
一旦你选择了与你的数据类型相对应的函数,在编写公式时应该没有什么困难--语法是如此的简单和透明,以至于没有错误的余地:)下面的例子展示了几个Excel标准偏差公式的操作。
计算样本和群体的标准差
根据你的数据的性质,使用以下公式之一。
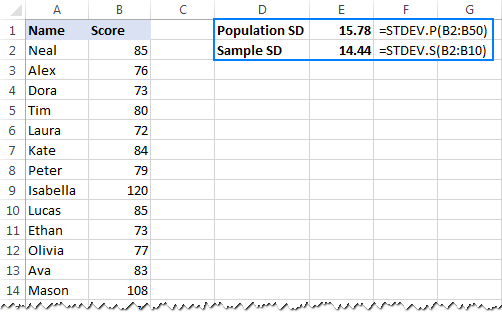
- 为了计算基于全部的标准偏差 人口 ,即完整的数值列表(本例中为B2:B50),使用STDEV.P函数。
=stdev.p(b2:b50) - 要想在标准差的基础上找到标准差 样本 构成人口的一部分或子集(本例中为B2:B10),使用STDEV.S函数。
=stdev.s(b2:b10)
正如你在下面的截图中看到的,这些公式返回的数字略有不同(样本越小,差异越大)。
在Excel 2007和更低版本中,你会使用STDEVP和STDEV函数来代替。
- 为了得到人口标准差。
=stdevp(b2:b50) - 要计算样本标准偏差。
=STDEV(B2:B10)
计算数字的文本表示法的标准偏差
在讨论Excel中计算标准差的不同函数时,我们有时会提到 "数字的文本表示法",你可能很想知道这到底是什么意思。
在这种情况下,"数字的文本表示 "仅仅是指格式化为文本的数字。 这种数字如何出现在你的工作表中? 最常见的是,它们从外部来源导出。 或者,由所谓的文本函数返回,这些函数旨在处理文本字符串,例如TEXT、MID、RIGHT、LEFT等。 其中一些函数也可以处理数字,但其输出总是文本,甚至如果它看起来很像一个数字。
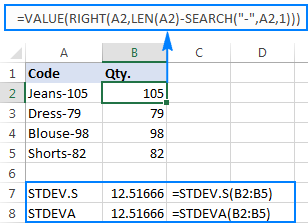
为了更好地说明这一点,请考虑下面的例子。 假设你有一列产品代码,如 "Jeans-105",其中连字符后的数字表示数量。 你的目标是提取每个项目的数量,然后找到提取的数字的标准偏差。
把数量拉到另一列并不是问题。
=right(a2,len(a2)-search("-",a2,1))
问题是,在提取的数字上使用Excel标准偏差公式,要么返回#DIV/0!要么返回0,如下面的截图所示。
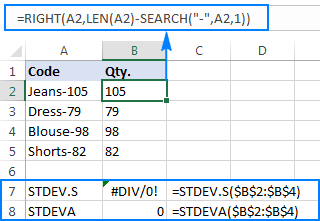
为什么会有这样奇怪的结果呢? 如上所述,RIGHT函数的输出总是一个文本字符串。 但是STDEV.S和STDEVA都不能处理引用中的文本格式的数字(前者简单地忽略它们,而后者则算作零)。 为了得到这种 "文本数字 "的标准偏差,你需要直接向参数列表提供它们,这可以通过嵌入所有的在你的STDEV.S或STDEVA公式中加入RIGHT函数。
=stdev.s(right(a2,len(a2)-search("-",a2,1)), right(a3,len(a3)-search("-",a3,1)), right(a4,len(a4)-search("-",a4,1)) , right(a5,len(a5)-search("-",a5,1) )
=stdeva(right(a2,len(a2)-search("-",a2,1)), right(a3,len(a3)-search("-",a3,1)), right(a4,len(a4)-search("-",a4,1)) , right(a5,len(a5)-search("-",a5,1) )
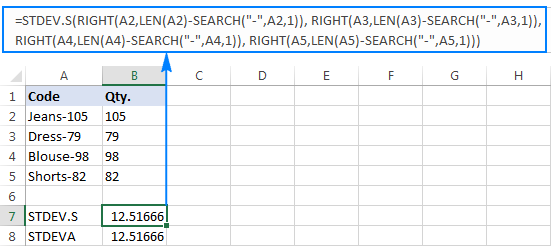
这些公式有点麻烦,但对于小样本来说,这可能是一个可行的解决方案。 对于更大的样本,更不用说整个人口,这绝对不是一个选项。 在这种情况下,一个更优雅的解决方案是让VALUE函数将 "文本数字 "转换成任何标准偏差公式都能理解的数字(请注意截图中右对齐的数字而不是上面截图中的左对齐的文本字符串)。
如何在Excel中计算均值的标准误差
在统计学中,还有一种估计数据变异性的措施-- 平均值的标准误差 标准差和均值的标准误差是两个密切相关的概念,但不是同一个概念。
标准差衡量的是数据集与平均值的差异性,而平均数标准误差(SEM)估计的是样本平均值与真实的群体平均值之间可能存在的距离。 换一种说法--如果你从同一群体中抽取多个样本,平均数标准误差将显示这些样本平均值之间的分散度。 因为通常我们只计算一个一组数据的平均数,而不是多个平均数,平均数的标准误差是估计而不是测量的。
在数学上,平均数的标准误差是用这个公式计算的。
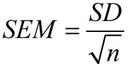
在哪里? ǞǞǞ 是标准差,和 n 是样本大小(样本中的数值数量)。
在Excel工作表中,你可以使用COUNT函数来获取样本中的数值,使用SQRT来获取该数值的平方根,使用STDEV.S来计算样本的标准偏差。
把所有这些放在一起,你就得到了Excel中的平均数公式的标准误差。
STDEV.S( 范围 )/SQRT(COUNT( 范围 ))假设样本数据在B2:B10中,我们的SEM公式将如下。
=stdev.s(b2:b10)/sqrt(count(b2:b10))
而结果可能与此类似。

如何在Excel中添加标准偏差条
为了直观地显示标准差的幅度,你可以在Excel图表中添加标准差条。 下面是方法。
- 以通常的方式创建一个图形( 插入 标签> 图表 组)。
- 点击图形上的任何地方来选择它,然后点击 图表元素 按钮。
- 点击旁边的箭头 误差条 ,并挑选 标准偏差 .
这将为所有数据点插入相同的标准偏差条。

这就是如何在Excel上做标准差。 我希望你会发现这些信息对你有帮助。 无论如何,我感谢你的阅读,希望下周在我们的博客上见到你。
