
Daftar Isi
Tutorial ini menjelaskan esensi dari deviasi standar dan kesalahan standar rata-rata serta rumus mana yang terbaik untuk digunakan untuk menghitung deviasi standar di Excel.
Dalam statistik deskriptif, rata-rata aritmatika (juga disebut rata-rata) dan deviasi standar dan merupakan dua konsep yang terkait erat. Tetapi sementara yang pertama dipahami dengan baik oleh sebagian besar orang, yang terakhir dipahami oleh beberapa orang. Tujuan dari tutorial ini adalah menjelaskan apa sebenarnya deviasi standar dan bagaimana menghitungnya di Excel.
Apa yang dimaksud dengan deviasi standar?
The deviasi standar adalah ukuran yang menunjukkan seberapa banyak nilai dari sekumpulan data menyimpang (menyebar) dari mean. Dengan kata lain, standar deviasi menunjukkan apakah data Anda mendekati mean atau banyak berfluktuasi.
Tujuan dari standar deviasi adalah untuk membantu Anda memahami apakah mean benar-benar mengembalikan data yang "tipikal". Semakin dekat standar deviasi ke nol, semakin rendah variabilitas data dan semakin dapat diandalkan mean. Standar deviasi yang sama dengan 0 menunjukkan bahwa setiap nilai dalam dataset sama persis dengan mean. Semakin tinggi standar deviasi, semakin banyak variasi yang ada di dalam dataset.data dan semakin tidak akurat rata-ratanya.
Untuk mendapatkan gambaran yang lebih baik mengenai cara kerjanya, silakan lihat data berikut ini:
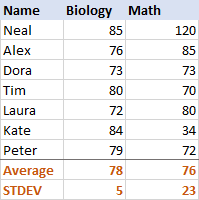
Untuk Biologi, standar deviasi adalah 5 (dibulatkan menjadi bilangan bulat), yang memberi tahu kita bahwa sebagian besar skor tidak lebih dari 5 poin dari rata-rata. Apakah itu bagus? Ya, ini menunjukkan bahwa nilai Biologi siswa cukup konsisten.
Untuk Matematika, standar deviasi adalah 23. Ini menunjukkan bahwa ada dispersi (penyebaran) yang sangat besar dalam skor, yang berarti bahwa beberapa siswa berkinerja jauh lebih baik dan / atau beberapa berkinerja jauh lebih buruk daripada rata-rata.
Dalam praktiknya, deviasi standar sering digunakan oleh para analis bisnis sebagai ukuran risiko investasi - semakin tinggi deviasi standar, semakin tinggi volatilitas imbal hasil.
Simpangan baku sampel vs Simpangan baku populasi
Sehubungan dengan deviasi standar, Anda mungkin sering mendengar istilah "sampel" dan "populasi", yang merujuk pada kelengkapan data yang Anda kerjakan. Perbedaan utamanya adalah sebagai berikut:
- Populasi mencakup semua elemen dari kumpulan data.
- Sampel adalah subset data yang mencakup satu atau lebih elemen dari populasi.
Para peneliti dan analis beroperasi pada standar deviasi sampel dan populasi dalam situasi yang berbeda. Misalnya, ketika merangkum nilai ujian dari kelas siswa, seorang guru akan menggunakan standar deviasi populasi. Ahli statistik yang menghitung skor rata-rata SAT nasional akan menggunakan standar deviasi sampel karena mereka disajikan dengan data dari sampel saja, bukandari seluruh populasi.
Memahami rumus deviasi standar
Alasan mengapa sifat data penting adalah karena deviasi standar populasi dan deviasi standar sampel dihitung dengan rumus yang sedikit berbeda:
Simpangan baku sampel | Deviasi standar populasi |
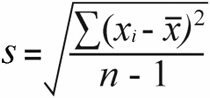 | 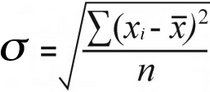 |
Di mana:
- x i adalah nilai individual dalam kumpulan data
- x adalah rata-rata dari semua x nilai
- n adalah jumlah total x nilai dalam kumpulan data
Mengalami kesulitan dalam memahami rumus-rumus tersebut? Memecahnya menjadi langkah-langkah sederhana mungkin bisa membantu. Tapi pertama-tama, mari kita memiliki beberapa contoh data untuk dikerjakan:

1. Hitung mean (rata-rata)
Pertama, Anda menemukan mean dari semua nilai dalam kumpulan data ( x Ketika menghitung dengan tangan, Anda menjumlahkan angka-angka dan kemudian membagi jumlah tersebut dengan hitungan angka-angka tersebut, seperti ini:
(1+2+4+5+6+8+9)/7=5
Untuk mencari mean di Excel, gunakan fungsi AVERAGE, misalnya =AVERAGE(A2:G2)
2. Untuk setiap angka, kurangi rata-rata dan kuadratkan hasilnya
Ini adalah bagian dari rumus deviasi standar yang mengatakan: ( x i - x )2
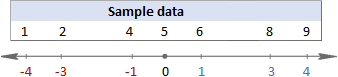
Untuk memvisualisasikan apa yang sesungguhnya terjadi, silakan lihat gambar berikut ini.
Dalam contoh ini, mean adalah 5, jadi kita menghitung perbedaan antara setiap titik data dan 5.
Kemudian, Anda menguadratkan selisihnya, mengubah semuanya menjadi angka positif:
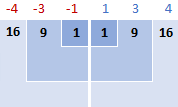
3. Menjumlahkan perbedaan kuadrat
Untuk mengatakan "menjumlahkan segala sesuatu" dalam matematika, Anda menggunakan sigma Σ. Jadi, apa yang kita lakukan sekarang adalah menjumlahkan selisih kuadrat untuk menyelesaikan bagian rumus ini: Σ( x i - x )2
16 + 9 + 1 + 1 + 9 + 16 = 52
4. Bagi total perbedaan kuadrat dengan jumlah nilai
Sejauh ini, rumus deviasi standar sampel dan deviasi standar populasi identik. Pada titik ini, keduanya berbeda.
Untuk deviasi standar sampel , Anda mendapatkan varians sampel dengan membagi total perbedaan kuadrat dengan ukuran sampel dikurangi 1:
52 / (7-1) = 8.67
Untuk deviasi standar populasi , Anda menemukan rata-rata perbedaan kuadrat dengan membagi total perbedaan kuadrat dengan jumlah mereka:
52 / 7 = 7.43
Mengapa ada perbedaan dalam rumus ini? Karena dalam rumus deviasi standar sampel, Anda perlu mengoreksi bias dalam estimasi rata-rata sampel, bukan rata-rata populasi yang sebenarnya. Dan Anda melakukan ini dengan menggunakan n - 1 bukannya n yang disebut koreksi Bessel.
5. Ambil akar kuadrat
Terakhir, ambil akar kuadrat dari angka-angka di atas, dan Anda akan mendapatkan deviasi standar (dalam persamaan di bawah ini, dibulatkan ke 2 tempat desimal):
| Simpangan baku sampel | Deviasi standar populasi |
| √ 8.67 = 2.94 | √ 7.43 = 2.73 |
Di Microsoft Excel, deviasi standar dihitung dengan cara yang sama, tetapi semua perhitungan di atas dilakukan di belakang layar. Hal utama bagi Anda adalah memilih fungsi deviasi standar yang tepat, yang mana bagian berikut ini akan memberi Anda beberapa petunjuk.
Cara menghitung deviasi standar di Excel
Secara keseluruhan, ada enam fungsi berbeda untuk menemukan deviasi standar di Excel. Yang mana yang digunakan terutama bergantung pada sifat data yang Anda kerjakan - apakah itu seluruh populasi atau sampel.
Fungsi untuk menghitung deviasi standar sampel di Excel
Untuk menghitung deviasi standar berdasarkan sampel, gunakan salah satu rumus berikut ini (semuanya didasarkan pada metode "n-1" yang dijelaskan di atas).
Fungsi STDEV Excel
STDEV(nomor1,[nomor2],...) adalah fungsi Excel tertua untuk memperkirakan deviasi standar berdasarkan sampel, dan tersedia di semua versi Excel 2003 hingga 2019.
Di Excel 2007 dan yang lebih baru, STDEV dapat menerima hingga 255 argumen yang dapat diwakili oleh angka, larik, rentang bernama, atau referensi ke sel yang berisi angka. Di Excel 2003, fungsi tersebut hanya dapat menerima hingga 30 argumen.
Nilai logika dan representasi teks dari angka yang diberikan secara langsung dalam daftar argumen dihitung. Dalam array dan referensi, hanya angka yang dihitung; sel kosong, nilai logika TRUE dan FALSE, teks dan nilai kesalahan diabaikan.
Catatan. Excel STDEV adalah fungsi yang sudah ketinggalan zaman, yang disimpan di versi Excel yang lebih baru hanya untuk kompatibilitas ke belakang. Namun, Microsoft tidak menjanjikan versi yang akan datang. Jadi, di Excel 2010 dan yang lebih baru, disarankan untuk menggunakan STDEV.S daripada STDEV.
Fungsi Excel STDEV.S
STDEV.S(nomor1,[nomor2],...) adalah versi STDEV yang ditingkatkan, diperkenalkan di Excel 2010.
Seperti STDEV, fungsi STDEV.S menghitung deviasi standar sampel dari sekumpulan nilai berdasarkan rumus deviasi standar sampel klasik yang dibahas di bagian sebelumnya.
Fungsi Excel STDEVA
STDEVA(nilai1, [nilai2], ...) adalah fungsi lain untuk menghitung deviasi standar sampel di Excel. Ini berbeda dari dua di atas hanya dalam cara menangani nilai logika dan teks:
- Semua nilai logis dihitung, apakah mereka terkandung dalam array atau referensi, atau diketik langsung ke dalam daftar argumen (TRUE dievaluasi sebagai 1, FALSE dievaluasi sebagai 0).
- Nilai-nilai teks di dalam array atau argumen referensi dihitung sebagai 0, termasuk string kosong (""), representasi teks angka, dan teks lainnya. Representasi teks angka yang diberikan secara langsung dalam daftar argumen dihitung sebagai angka yang diwakilinya (berikut contoh rumusnya).
- Sel-sel kosong diabaikan.
Catatan. Agar rumus deviasi standar sampel berfungsi dengan benar, argumen yang diberikan harus berisi setidaknya dua nilai numerik, jika tidak, kesalahan #DIV/0! dikembalikan.
Fungsi untuk menghitung deviasi standar populasi di Excel
Jika Anda berurusan dengan seluruh populasi, gunakan salah satu fungsi berikut untuk melakukan deviasi standar di Excel. Fungsi-fungsi ini didasarkan pada metode "n".
Fungsi STDEVP Excel
STDEVP(nomor1,[nomor2],...) adalah fungsi Excel lama untuk menemukan deviasi standar populasi.
Di versi baru Excel 2010, 2013, 2016 dan 2019, ini diganti dengan fungsi STDEV.P yang ditingkatkan, tetapi masih disimpan untuk kompatibilitas ke belakang.
Fungsi Excel STDEV.P
STDEV.P(nomor1,[nomor2],...) adalah versi modern dari fungsi STDEVP yang memberikan akurasi yang lebih baik. Ini tersedia di Excel 2010 dan versi yang lebih baru.
Seperti rekan-rekan deviasi standar sampel mereka, di dalam array atau argumen referensi, fungsi STDEVP dan STDEV.P hanya menghitung angka. Dalam daftar argumen, mereka juga menghitung nilai logika dan representasi teks dari angka.
Fungsi Excel STDEVPA
STDEVPA(nilai1, [nilai2], ...) menghitung deviasi standar dari sebuah populasi, termasuk teks dan nilai logika. Berkenaan dengan nilai non-numerik, STDEVPA bekerja persis seperti fungsi STDEVA.
Catatan. Apapun rumus deviasi standar Excel yang Anda gunakan, itu akan mengembalikan kesalahan jika satu atau lebih argumen berisi nilai kesalahan yang dikembalikan oleh fungsi atau teks lain yang tidak dapat diartikan sebagai angka.
Fungsi deviasi standar Excel mana yang digunakan?
Berbagai fungsi deviasi standar di Excel pasti dapat menyebabkan kekacauan, terutama bagi pengguna yang tidak berpengalaman. Untuk memilih rumus deviasi standar yang benar untuk tugas tertentu, jawab saja 3 pertanyaan berikut:
- Apakah Anda menghitung deviasi standar sampel atau populasi?
- Versi Excel apa yang Anda gunakan?
- Apakah kumpulan data Anda hanya mencakup angka atau nilai logika dan teks juga?
Untuk menghitung deviasi standar berdasarkan numerik sampel , gunakan fungsi STDEV.S di Excel 2010 dan yang lebih baru; STDEV di Excel 2007 dan sebelumnya.
Untuk menemukan deviasi standar dari populasi , gunakan fungsi STDEV.P di Excel 2010 dan yang lebih baru; STDEVP di Excel 2007 dan sebelumnya.
Jika Anda ingin logis atau teks Meskipun saya tidak dapat memikirkan skenario apa pun di mana kedua fungsi tersebut dapat berguna dengan sendirinya, mereka mungkin berguna dalam rumus yang lebih besar, di mana satu atau lebih argumen dikembalikan oleh fungsi lain sebagai nilai logis atau representasi teks dari angka.
Untuk membantu Anda memutuskan fungsi deviasi standar Excel mana yang paling cocok untuk kebutuhan Anda, harap tinjau tabel berikut yang merangkum informasi yang telah Anda pelajari.
| STDEV | STDEV.S | STDEVP | STDEV.P | STDEVA | STDEVPA | |
| Versi Excel | 2003 - 2019 | 2010 - 2019 | 2003 - 2019 | 2010 - 2019 | 2003 - 2019 | 2003 - 2019 |
| Sampel | ✓ | ✓ | ✓ | |||
| Populasi | ✓ | ✓ | ✓ | |||
| Nilai logis dalam larik atau referensi | Diabaikan | Dievaluasi (BENAR=1, SALAH=0) | ||||
| Teks dalam larik atau referensi | Diabaikan | Dievaluasi sebagai nol | ||||
| Nilai logika dan "teks-angka" dalam daftar argumen | Dievaluasi (BENAR=1, SALAH=0) | |||||
| Sel-sel kosong | Diabaikan | |||||
Contoh rumus deviasi standar Excel
Setelah Anda memilih fungsi yang sesuai dengan tipe data Anda, seharusnya tidak ada kesulitan dalam menulis rumus - sintaksnya sangat polos dan transparan sehingga tidak menyisakan ruang untuk kesalahan :) Contoh-contoh berikut menunjukkan beberapa rumus deviasi standar Excel dalam tindakan.
Menghitung deviasi standar sampel dan populasi
Tergantung pada sifat data Anda, gunakan salah satu rumus berikut ini:
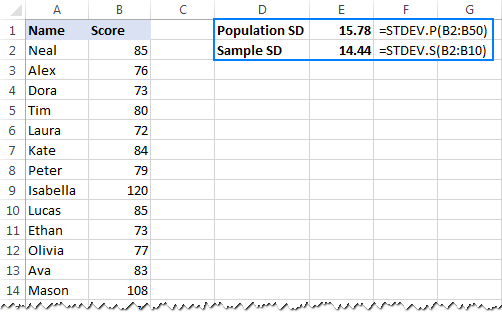
- Untuk menghitung deviasi standar berdasarkan seluruh populasi yaitu daftar lengkap nilai (B2:B50 dalam contoh ini), gunakan fungsi STDEV.P:
=STDEV.P(B2:B50) - Untuk menemukan deviasi standar berdasarkan sampel yang merupakan bagian, atau subset, dari populasi (B2: B10 dalam contoh ini), gunakan fungsi STDEV.S:
=STDEV.S(B2:B10)
Seperti yang bisa Anda lihat pada tangkapan layar di bawah ini, rumus-rumus tersebut menghasilkan angka yang sedikit berbeda (semakin kecil sampel, semakin besar perbedaannya):
Di Excel 2007 dan yang lebih rendah, Anda akan menggunakan fungsi STDEVP dan STDEV sebagai gantinya:
- Untuk mendapatkan deviasi standar populasi:
=STDEVP(B2:B50) - Untuk menghitung deviasi standar sampel:
=STDEV(B2:B10)
Menghitung deviasi standar untuk representasi teks angka
Saat membahas berbagai fungsi untuk menghitung deviasi standar di Excel, kami terkadang menyebutkan "representasi teks angka" dan Anda mungkin penasaran untuk mengetahui apa sebenarnya artinya.
Dalam konteks ini, "representasi teks angka" hanyalah angka yang diformat sebagai teks. Bagaimana angka-angka seperti itu bisa muncul di lembar kerja Anda? Paling sering, angka-angka tersebut diekspor dari sumber eksternal. Atau, dikembalikan oleh apa yang disebut fungsi Teks yang dirancang untuk memanipulasi string teks, misalnya TEXT, MID, RIGHT, LEFT, dll. Beberapa fungsi tersebut dapat bekerja dengan angka juga, tetapi outputnya selalu berupa teks, bahkanjika terlihat seperti angka.
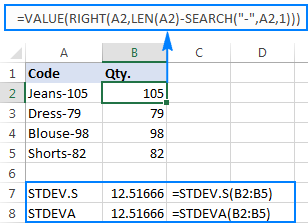
Untuk mengilustrasikan poinnya dengan lebih baik, pertimbangkan contoh berikut ini. Misalkan Anda memiliki kolom kode produk seperti "Jeans-105" di mana digit setelah tanda hubung menunjukkan kuantitas. Tujuan Anda adalah mengekstrak kuantitas setiap item, dan kemudian menemukan deviasi standar dari angka yang diekstrak.
Menarik kuantitas ke kolom lain tidak menjadi masalah:
=RIGHT(A2,LEN(A2)-SEARCH("-",A2,1))
Masalahnya adalah menggunakan rumus deviasi standar Excel pada angka yang diekstraksi mengembalikan #DIV/0! atau 0 seperti yang ditunjukkan pada gambar di bawah:
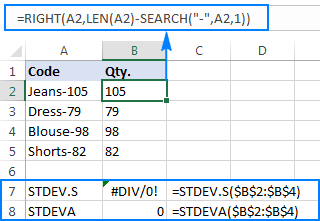
Mengapa hasil yang aneh seperti itu? Seperti disebutkan di atas, output dari fungsi RIGHT selalu berupa string teks. Tetapi baik STDEV.S maupun STDEVA tidak dapat menangani angka yang diformat sebagai teks dalam referensi (yang pertama mengabaikannya begitu saja sementara yang terakhir dihitung sebagai nol). Untuk mendapatkan standar deviasi dari "teks-angka" seperti itu, Anda perlu menyediakannya langsung ke daftar argumen, yang dapat dilakukan dengan menyematkan semuaRIGHT ke dalam rumus STDEV.S atau STDEVA Anda:
=STDEV.S(RIGHT(A2,LEN(A2)-SEARCH("-",A2,1)), RIGHT(A3,LEN(A3)-SEARCH("-",A3,1)), RIGHT(A4,LEN(A4)-SEARCH("-",A4,1)), RIGHT(A5,LEN(A5)-SEARCH("-",A5,1)))
=STDEVA(RIGHT(A2,LEN(A2)-SEARCH("-",A2,1)), RIGHT(A3,LEN(A3)-SEARCH("-",A3,1)), RIGHT(A4,LEN(A4)-SEARCH("-",A4,1)), RIGHT(A5,LEN(A5)-SEARCH("-",A5,1)))
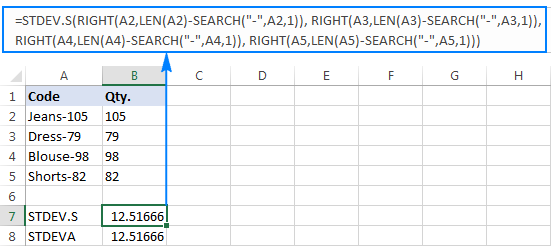
Rumusnya agak rumit, tetapi itu mungkin solusi yang berfungsi untuk sampel kecil. Untuk sampel yang lebih besar, belum lagi seluruh populasi, itu jelas bukan pilihan. Dalam hal ini, solusi yang lebih elegan adalah memiliki fungsi VALUE yang mengubah "angka-teks" menjadi angka yang dapat dimengerti oleh rumus deviasi standar apa pun (harap perhatikan angka rata kanan di tangkapan layardi bawah ini sebagai lawan dari string teks rata kiri pada tangkapan layar di atas):
Bagaimana cara menghitung kesalahan standar mean di Excel
Dalam statistika, ada satu ukuran lagi untuk memperkirakan variabilitas dalam data - kesalahan standar rata-rata yang kadang-kadang disingkat (meskipun, secara tidak benar) menjadi hanya "kesalahan standar". Deviasi standar dan kesalahan standar rata-rata adalah dua konsep yang terkait erat, tetapi tidak sama.
Sementara deviasi standar mengukur variabilitas kumpulan data dari mean, kesalahan standar mean (SEM) memperkirakan seberapa jauh rata-rata sampel kemungkinan berasal dari rata-rata populasi yang sebenarnya. Dengan kata lain - jika Anda mengambil beberapa sampel dari populasi yang sama, kesalahan standar mean akan menunjukkan dispersi antara rata-rata sampel tersebut. Karena biasanya kita menghitung hanya satumean untuk sekumpulan data, bukan beberapa mean, kesalahan standar mean diperkirakan daripada diukur.
Dalam matematika, kesalahan standar rata-rata dihitung dengan rumus ini:
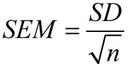
Di mana SD adalah deviasi standar, dan n adalah ukuran sampel (jumlah nilai dalam sampel).
Di lembar kerja Excel Anda, Anda dapat menggunakan fungsi COUNT untuk mendapatkan jumlah nilai dalam sampel, SQRT untuk mengambil akar kuadrat dari angka itu, dan STDEV.S untuk menghitung deviasi standar sampel.
Menyatukan semua ini, Anda mendapatkan kesalahan standar dari rumus mean di Excel:
STDEV.S( rentang )/SQRT(COUNT( rentang ))Dengan asumsi data sampel berada di B2:B10, rumus SEM kita akan berjalan sebagai berikut:
=STDEV.S(B2:B10)/SQRT(COUNT(B2:B10))
Dan hasilnya mungkin mirip dengan ini:

Bagaimana cara menambahkan bilah deviasi standar di Excel
Untuk menampilkan margin deviasi standar secara visual, Anda dapat menambahkan batang deviasi standar ke bagan Excel Anda. Begini caranya:
- Buat grafik dengan cara biasa ( Sisipkan tab> Grafik kelompok).
- Klik di mana saja pada grafik untuk memilihnya, kemudian klik tombol Elemen Bagan tombol.
- Klik tanda panah di samping Bilah Kesalahan , dan pilih Deviasi Standar .
Ini akan menyisipkan batang deviasi standar yang sama untuk semua titik data.

Ini adalah cara melakukan deviasi standar di Excel. Saya harap Anda akan menemukan informasi ini bermanfaat. Bagaimanapun, saya berterima kasih telah membaca dan berharap dapat melihat Anda di blog kami minggu depan.
