
Tartalomjegyzék
A bemutató elmagyarázza a szórás és az átlag standard hibájának lényegét, valamint azt, hogy melyik képletet érdemes használni a szórás kiszámításához az Excelben.
A leíró statisztikában a számtani átlag (más néven átlag) és a szórás és két szorosan összefüggő fogalom. De míg az előbbit a legtöbben jól értik, az utóbbit kevesen. Ennek a bemutatónak a célja, hogy megvilágítsa, mi is valójában a szórás, és hogyan lehet kiszámítani az Excelben.
Mi a szórás?
A szórás egy olyan mérőszám, amely megmutatja, hogy az adathalmaz értékei mennyire térnek el (szóródnak) az átlagtól. Másképpen fogalmazva, a szórás megmutatja, hogy az adatai közel vannak-e az átlaghoz, vagy nagymértékben ingadoznak.
A szórás célja, hogy segítsen megérteni, hogy az átlag valóban egy "tipikus" adatot ad-e vissza. Minél közelebb van a szórás a nullához, annál kisebb az adatok variabilitása és annál megbízhatóbb az átlag. A 0-val egyenlő szórás azt jelzi, hogy az adathalmazban minden érték pontosan megegyezik az átlaggal. Minél nagyobb a szórás, annál nagyobb a szórás az adatokban.adatok és annál kevésbé pontos az átlag.
Hogy jobban megértse, hogyan működik ez, kérjük, tekintse meg az alábbi adatokat:
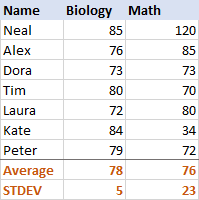
A biológia esetében a szórás 5 (egész számra kerekítve), ami azt jelenti, hogy a pontszámok többsége legfeljebb 5 pontra tér el az átlagtól. Ez jó? Nos, igen, azt jelzi, hogy a diákok biológia pontszámai meglehetősen konzisztensek.
A matematika esetében a szórás 23. Ez azt mutatja, hogy a pontszámok között óriási a szórás, ami azt jelenti, hogy egyes tanulók sokkal jobban és/vagy mások sokkal rosszabbul teljesítettek, mint az átlag.
A gyakorlatban az üzleti elemzők gyakran használják a szórást a befektetési kockázat mérőszámaként - minél nagyobb a szórás, annál nagyobb a hozamok volatilitása.
Minta szórás vs. populáció szórás
A szórással kapcsolatban gyakran hallhatja a "minta" és a "populáció" kifejezéseket, amelyek a feldolgozott adatok teljességére utalnak. A fő különbség a következő:
- Népesség tartalmazza egy adathalmaz összes elemét.
- Minta az adatok olyan részhalmaza, amely a sokaság egy vagy több elemét tartalmazza.
A kutatók és az elemzők különböző helyzetekben a minta és a sokaság szórásával dolgoznak. Például amikor egy tanár egy osztálynyi diák vizsgaeredményeit összegzi, a sokaság szórását használja. Az országos SAT átlagpontszámot kiszámító statisztikusok a minta szórását használják, mert csak a minta adatait kapják meg, nem pedig a sokaság szórását.a teljes népességből.
A szórásképlet megértése
Az adatok jellege azért számít, mert a populáció szórását és a minta szórását kissé eltérő képletekkel számítják ki:
A minta szórása | A populáció szórása |
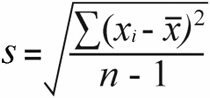 | 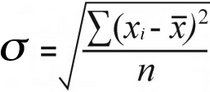 |
Hol:
- x i az adathalmaz egyes értékei
- x az összes x értékek
- n az összes x értékek az adathalmazban
Nehézséget okoz a képletek megértése? Segíthet, ha egyszerű lépésekre bontjuk őket. De előbb legyen néhány mintaadat, amin dolgozhatunk:

1. Számítsa ki az átlagot (átlagot).
Először is, meg kell találni az adathalmaz összes értékének átlagát ( x a fenti képletekben). Ha kézzel számolunk, akkor összeadjuk a számokat, majd az összeget elosztjuk a számok számával, például így:
(1+2+4+5+6+8+9)/7=5
Az Excelben az átlag kiszámításához használja az AVERAGE függvényt, pl. =AVERAGE(A2:G2)
2. Minden szám esetében vonja le az átlagot, és négyzetelje az eredményt.
Ez a szórásképletnek az a része, amely azt mondja: ( x i - x )2
Hogy szemléltesse, mi is történik valójában, tekintse meg az alábbi képeket.
Ebben a példában az átlag 5, ezért kiszámítjuk az egyes adatpontok és az 5 közötti különbséget.
Ezután a különbségeket négyzetre állítjuk, és pozitív számokká alakítjuk őket:
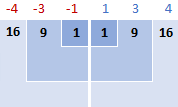
3. Adjuk össze a négyzetes különbségeket
A matematikában az "összegzés" kifejezéshez a sigma Σ-t használjuk. Tehát most azt tesszük, hogy összeadjuk a négyzetes különbségeket, hogy kiegészítsük a képletnek ezt a részét: Σ( x i - x )2
16 + 9 + 1 + 1 + 9 + 16 = 52
4. Osszuk el az összes négyzetes különbséget az értékek számával.
Eddig a minta szórás és a populáció szórás képletei azonosak voltak. Ezen a ponton különböznek.
A minta szórása , megkapod a minta szórása az összes négyzetes különbség négyzetének a minta méretével mínusz 1 osztásával:
52 / (7-1) = 8.67
A populációs szórás , megtalálja a a különbségek négyzetének átlaga az összes négyzetes különbség négyzetének a számukkal való elosztásával:
52 / 7 = 7.43
Miért van ez a különbség a képletek között? Mert a minta szórásképletében korrigálnunk kell a torzítást a minta átlagának becslésében a valódi populációs átlag helyett. Ezt pedig a következő módon tesszük. n - 1 ahelyett, hogy n , amit Bessel-korrekciónak nevezünk.
5. Vegyük ki a négyzetgyökét
Végül, ha a fenti számok négyzetgyökét vesszük, megkapjuk a szórást (az alábbi egyenletekben 2 tizedesjegyre kerekítve):
| A minta szórása | A populáció szórása |
| √ 8.67 = 2.94 | √ 7.43 = 2.73 |
A Microsoft Excelben a szórás kiszámítása ugyanígy történik, de az összes fenti számítás a színfalak mögött történik. A legfontosabb dolog a megfelelő szórásfüggvény kiválasztása, amelyről a következő részben találsz néhány támpontot.
Hogyan számítsuk ki a szórást Excelben
Összességében hat különböző függvény létezik az Excelben a szórás megkeresésére. Hogy melyiket használja, az elsősorban attól függ, hogy milyen jellegű adatokkal dolgozik - akár a teljes sokaságról, akár egy mintáról van szó.
Funkciók a minta szórás kiszámításához Excelben
A szórás kiszámításához egy minta alapján használja az alábbi képletek egyikét (mindegyik a fent leírt "n-1" módszerre épül).
Excel STDEV funkció
STDEV(number1,[number2],...) a legrégebbi Excel-funkció a minta alapján becsült szórás becslésére, és az Excel 2003-tól 2019-ig minden Excel-verzióban elérhető.
Az Excel 2007 és újabb programokban az STDEV legfeljebb 255 argumentumot fogadhat el, amelyek számok, tömbök, nevesített tartományok vagy számokat tartalmazó cellákra való hivatkozások lehetnek. Az Excel 2003-ban a függvény legfeljebb 30 argumentumot fogadhat el.
A közvetlenül az argumentumok listájában megadott számok logikai értékeit és szöveges megjelenítéseit számolni kell. A tömbökben és hivatkozásokban csak a számokat kell számolni; az üres cellákat, a TRUE és FALSE logikai értékeket, a szöveges és hibaértékeket figyelmen kívül hagyjuk.
Megjegyzés: Az Excel STDEV egy elavult funkció, amelyet az Excel újabb verzióiban csak a visszafelé kompatibilitás miatt tartanak meg. A Microsoft azonban nem tesz ígéretet a jövőbeli verziókra vonatkozóan. Ezért az Excel 2010 és újabb verziókban az STDEV.S helyett az STDEV.S használata ajánlott.
Excel STDEV.S funkció
STDEV.S(number1,[number2],...) az STDEV továbbfejlesztett változata, amelyet az Excel 2010-ben vezettek be.
Az STDEV.S függvény az STDEV-hez hasonlóan az előző szakaszban tárgyalt klasszikus minta szórásképlet alapján számítja ki egy értékkészlet minta szórását.
Excel STDEVA funkció
STDEVA(érték1, [érték2], ...) egy másik függvény egy minta szórásának kiszámítására az Excelben. A fenti kettőtől csak abban különbözik, ahogyan a logikai és szöveges értékeket kezeli:
- Minden logikai értékek számítanak, függetlenül attól, hogy tömbökben vagy hivatkozásokban szerepelnek, vagy közvetlenül az argumentumok listájába vannak beírva (a TRUE érték 1, a FALSE érték 0).
- Szöveges értékek a tömbökön vagy referenciaargumentumokon belül 0-nak számítanak, beleértve az üres karakterláncokat (""), a számok szöveges megjelenítését és minden más szöveget. A közvetlenül az argumentumok listájában megadott számok szöveges megjelenítését az általuk képviselt számoknak kell tekinteni (itt egy képletpélda).
- Az üres cellákat figyelmen kívül hagyjuk.
Megjegyzés: Ahhoz, hogy a minta szórásképlete helyesen működjön, a megadott argumentumoknak legalább két numerikus értéket kell tartalmazniuk, különben a #DIV/0! hiba érkezik vissza.
Funkciók a populáció szórásának kiszámításához Excelben
Ha a teljes sokasággal foglalkozik, használja az alábbi függvények valamelyikét a standard eltérés Excelben történő elvégzéséhez. Ezek a függvények az "n" módszerre épülnek.
Excel STDEVP funkció
STDEVP(number1,[number2],...) a régi Excel-funkció a populáció szórásának meghatározására.
Az Excel 2010, 2013, 2016 és 2019 új verzióiban ezt a funkciót a továbbfejlesztett STDEV.P függvény váltja fel, de a visszafelé kompatibilitás érdekében továbbra is megmarad.
Excel STDEV.P funkció
STDEV.P(number1,[number2],...) az STDEVP függvény modern változata, amely jobb pontosságot biztosít. Az Excel 2010 és újabb verziókban érhető el.
Mint a minta szórásának megfelelői, az STDEVP és az STDEV.P függvények a tömbökön vagy a referenciaargumentumokon belül csak számokat számolnak. Az argumentumok listájában logikai értékeket és a számok szöveges ábrázolásait is számolják.
Excel STDEVPA funkció
STDEVPA(érték1, [érték2], ...) kiszámítja egy sokaság szórását, beleértve a szöveges és logikai értékeket is. A nem numerikus értékek tekintetében az STDEVPA pontosan úgy működik, mint az STDEVA függvény.
Megjegyzés: Bármelyik Excel standard eltérés képletet is használja, hibát ad vissza, ha egy vagy több argumentum egy másik függvény által visszaadott hibaértéket vagy számként nem értelmezhető szöveget tartalmaz.
Melyik Excel standard eltérés funkciót kell használni?
Az Excelben található sokféle szórásfüggvény határozottan zűrzavart okozhat, különösen a tapasztalatlan felhasználók számára. Ahhoz, hogy kiválassza a megfelelő szórásképletet egy adott feladathoz, csak válaszoljon a következő 3 kérdésre:
- A minta vagy a sokaság szórását számítja ki?
- Milyen Excel verziót használ?
- Az adatkészlete csak számokat vagy logikai értékeket és szöveget is tartalmaz?
A szórás kiszámítása numerikus érték alapján minta , használja az STDEV.S függvényt az Excel 2010 és újabb programokban; az STDEV függvényt az Excel 2007 és korábbi programokban.
A standard eltérés megtalálása lakosság , használja az STDEV.P függvényt az Excel 2010 és újabb programokban; az STDEVP függvényt az Excel 2007 és korábbi programokban.
Ha azt akarod, hogy logikai vagy szöveg a számításba bevonni kívánt értékeket, használja az STDEVA (minta szórás) vagy az STDEVPA (populáció szórás) függvényt. Bár nem tudok olyan forgatókönyvet elképzelni, amelyben bármelyik függvény önmagában hasznos lehet, jól jöhetnek nagyobb képletekben, ahol egy vagy több argumentumot más függvények logikai értékként vagy számok szöveges ábrázolásaként adnak vissza.
Annak eldöntéséhez, hogy az Excel standard eltérés funkciói közül melyik felel meg leginkább az Ön igényeinek, tekintse át az alábbi táblázatot, amely összefoglalja a már megtanult információkat.
| STDEV | STDEV.S | STDEVP | STDEV.P | STDEVA | STDEVPA | |
| Excel verzió | 2003 - 2019 | 2010 - 2019 | 2003 - 2019 | 2010 - 2019 | 2003 - 2019 | 2003 - 2019 |
| Minta | ✓ | ✓ | ✓ | |||
| Népesség | ✓ | ✓ | ✓ | |||
| Logikai értékek tömbökben vagy hivatkozásokban | Figyelmen kívül hagyta | Értékelt (TRUE=1, FALSE=0) | ||||
| Szöveg tömbökben vagy hivatkozásokban | Figyelmen kívül hagyta | Nulla értékűként értékelve | ||||
| Logikai értékek és "szöveges számok" az argumentumok listájában | Értékelt (TRUE=1, FALSE=0) | |||||
| Üres cellák | Figyelmen kívül hagyta | |||||
Excel szórásképlet példák
Miután kiválasztotta az adattípusnak megfelelő függvényt, nem okozhat nehézséget a képlet megírása - a szintaxis annyira egyszerű és átlátható, hogy nem hagy teret a hibáknak :) A következő példák néhány Excel standard eltérés képletet mutatnak be működés közben.
A minta és a sokaság szórásának kiszámítása
Az adatok jellegétől függően használja az alábbi képletek egyikét:
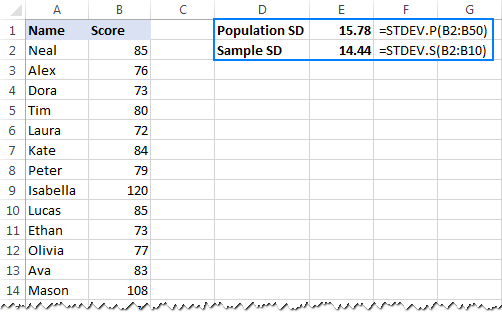
- A szórás kiszámításához a teljes lakosság , azaz az értékek teljes listáját (ebben a példában B2:B50), használja az STDEV.P függvényt:
=STDEV.P(B2:B50) - A szórás megállapítása egy minta amely a sokaság egy részét vagy részhalmazát alkotja (ebben a példában B2:B10), használja az STDEV.S függvényt:
=STDEV.S(B2:B10)
Amint az alábbi képernyőképen látható, a képletek kissé eltérő számokat adnak vissza (minél kisebb a minta, annál nagyobb a különbség):
Az Excel 2007 és alacsonyabb verziókban ehelyett az STDEVP és STDEV függvényeket használja:
- A populáció szórásának kiszámításához:
=STDEVP(B2:B50) - A minta szórásának kiszámítása:
=STDEV(B2:B10)
A számok szöveges ábrázolásának szórásszámítása
Amikor az Excelben a standard eltérés kiszámítására szolgáló különböző funkciókat tárgyaltuk, néha említettük a "számok szöveges ábrázolását", és talán kíváncsi vagy, hogy ez mit is jelent valójában.
Ebben az összefüggésben a "számok szöveges ábrázolása" egyszerűen szövegként formázott számokat jelent. Hogyan jelenhetnek meg ilyen számok a munkalapokon? Leggyakrabban külső forrásokból exportálják őket. Vagy olyan úgynevezett szövegfüggvények adják vissza, amelyek szöveges karakterláncok kezelésére szolgálnak, pl. TEXT, MID, RIGHT, LEFT stb. Néhány ilyen függvény számokkal is tud dolgozni, de a kimenetük mindig szöveg, még haha nagyon hasonlít egy számra.
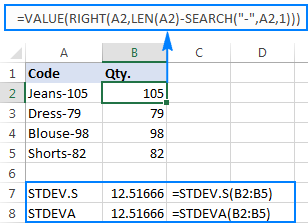
Hogy jobban szemléltesse a lényeget, kérjük, tekintse át a következő példát. Tegyük fel, hogy van egy olyan termékkódokat tartalmazó oszlop, mint például a "Jeans-105", ahol a kötőjel utáni számjegyek a mennyiséget jelölik. A célja az, hogy kivonja az egyes tételek mennyiségét, majd megtalálja a kivont számok szórását.
A mennyiség áthúzása egy másik oszlopba nem jelent problémát:
=RIGHT(A2,LEN(A2)-SEARCH("-",A2,1))
A probléma az, hogy az Excel standard eltérés képletének használata a kivont számokon #DIV/0! vagy 0 értéket ad vissza, ahogy az alábbi képernyőképen látható:
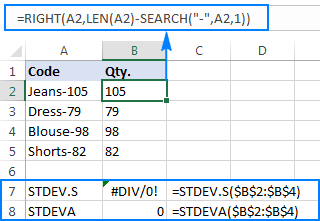
Miért ilyen furcsa eredmények? Mint fentebb említettük, a RIGHT függvény kimenete mindig egy szöveges karakterlánc. De sem az STDEV.S, sem az STDEVA nem tudja kezelni a szövegként formázott számokat a hivatkozásokban (az előbbi egyszerűen figyelmen kívül hagyja őket, míg az utóbbi nullának számít). Ahhoz, hogy az ilyen "szöveges számok" szórását megkapjuk, közvetlenül az argumentumok listájába kell beírni őket, ami az összesRIGHT függvényeket az STDEV.S vagy STDEVA képletbe:
=STDEV.S(RIGHT(A2,LEN(A2)-SEARCH("-",A2,1)), RIGHT(A3,LEN(A3)-SEARCH("-",A3,1)), RIGHT(A4,LEN(A4)-SEARCH("-",A4,1)), RIGHT(A5,LEN(A5)-SEARCH("-",A5,1))))
=STDEVA(RIGHT(A2,LEN(A2)-SEARCH("-",A2,1)), RIGHT(A3,LEN(A3)-SEARCH("-",A3,1)), RIGHT(A4,LEN(A4)-SEARCH("-",A4,1)), RIGHT(A5,LEN(A5)-SEARCH("-",A5,1))))
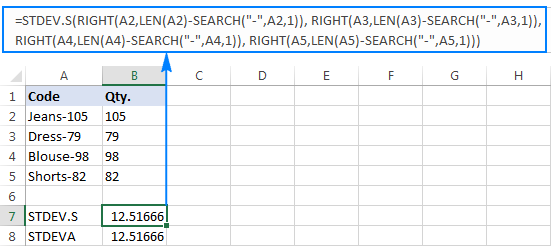
A képletek kissé nehézkesek, de ez egy kis minta esetében működőképes megoldás lehet. Egy nagyobb minta esetében, nem is beszélve a teljes populációról, ez biztosan nem opció. Ebben az esetben elegánsabb megoldás lenne, ha a VALUE függvény a "szöveges számokat" olyan számokká alakítaná, amelyeket bármelyik szórásképlet megért (kérjük, vegye figyelembe a jobbra igazított számokat a képernyőképen).szemben a fenti képernyőképen látható balra igazított szöveges karakterláncokkal):
Hogyan számítsuk ki az átlag standard hibáját az Excelben
A statisztikában van még egy mérőszám az adatok változékonyságának becslésére - az átlag standard hibája A szórás és az átlag standard hibája két, egymással szorosan összefüggő fogalom, de nem ugyanaz.
Míg a szórás az adathalmaz átlagtól való eltérését méri, addig az átlag szórása (SEM) azt becsüli meg, hogy a minta átlaga milyen messze van a populáció valódi átlagától. Másképpen fogalmazva - ha több mintát vennénk ugyanabból a populációból, az átlag szórása megmutatná a szórást a minta átlagai között. Mivel általában csak egy mintát számolunk ki.egy adathalmaz átlaga, nem pedig többszörös átlag, az átlag standard hibáját inkább becsüljük, mint mérjük.
A matematikában az átlag standard hibáját ezzel a képlettel számítják ki:
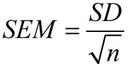
Hol SD a szórás, és n a minta mérete (a mintában szereplő értékek száma).
Az Excel munkalapjain a COUNT függvényt használhatja a mintában lévő értékek számának megadására, az SQRT függvényt a szám négyzetgyökének kiszámítására, az STDEV.S függvényt pedig a minta szórásának kiszámítására.
Ha mindezt összevetjük, megkapjuk az Excelben az átlag standard hibája képletet:
STDEV.S( tartomány )/SQRT(COUNT( tartomány ))Feltételezve, hogy a minta adatai B2:B10-ben vannak, a SEM képletünk a következőképpen néz ki:
=STDEV.S(B2:B10)/SQRT(COUNT(B2:B10))
Az eredmény pedig ehhez hasonló lehet:

Hogyan adjunk hozzá standard eltérés sávokat az Excelben
A szórástartomány vizuális megjelenítéséhez az Excel-diagramhoz hozzáadhat szórási sávokat. Íme, hogyan:
- Hozzon létre egy grafikont a szokásos módon ( Beillesztés tab> Diagramok csoport).
- Kattintson bárhol a grafikonon a kijelöléshez, majd kattintson a Diagram elemek gomb.
- Kattintson a nyílra a Hibasávok , és válasszuk ki Standard eltérés .
Ez minden adatponthoz ugyanazt a szórássávot illeszti be.

Így kell a standard eltérést Excelben elvégezni. Remélem, hasznosnak találod majd ezeket az információkat. Mindenesetre köszönöm, hogy elolvastad, és remélem, jövő héten találkozunk a blogon.
