
Innholdsfortegnelse
Denne opplæringen forklarer syntaksen til LINEST-funksjonen og viser hvordan du bruker den til å gjøre lineær regresjonsanalyse i Excel.
Microsoft Excel er ikke et statistisk program, men det gjør det har en rekke statistiske funksjoner. En av slike funksjoner er LINEST, som er designet for å utføre lineær regresjonsanalyse og returnere relatert statistikk. I denne opplæringen for nybegynnere vil vi kun berøre teori og underliggende beregninger. Vårt hovedfokus vil være å gi deg en formel som enkelt fungerer og som enkelt kan tilpasses for dine data.
Excel LINEST-funksjonen - syntaks og grunnleggende bruk
The LINEST-funksjonen beregner statistikken for en rett linje som forklarer forholdet mellom den uavhengige variabelen og en eller flere avhengige variabler, og returnerer en matrise som beskriver linjen. Funksjonen bruker minste kvadrater -metoden for å finne den beste passformen for dataene dine. Ligningen for linjen er som følger.
Enkel lineær regresjonsligning:
y = bx + aMultippel regresjonsligning:
y = b 1x 1+ b 2x 2+ … + b nx n+ aHvor:
- y - den avhengige variabelen du prøver å forutsi.
- x - den uavhengige variabelen du bruker til å forutsi y .
- a - skjæringspunktet (angir hvor linjen skjærer Y-aksen).
- b - helningenbetydelig.
Frihetsgrader (df). LINJE-funksjonen i Excel returnerer restfrihetsgradene , som er totalt df minus regresjonen df . Du kan bruke frihetsgradene til å få F-kritiske verdier i en statistisk tabell, og deretter sammenligne de F-kritiske verdiene med F-statistikken for å bestemme et konfidensnivå for modellen din.
Regresjonssum av kvadrater (aka den forklarede summen av kvadrater , eller modellsummen av kvadrater ). Det er summen av kvadrerte forskjeller mellom de predikerte y-verdiene og gjennomsnittet av y, beregnet med denne formelen: =∑(ŷ - ȳ)2. Den angir hvor mye av variasjonen i den avhengige variabelen din regresjonsmodell forklarer.
Restsum av kvadrater . Det er summen av kvadrerte forskjeller mellom de faktiske y-verdiene og de predikerte y-verdiene. Den indikerer hvor mye av variasjonen i den avhengige variabelen modellen din ikke forklarer. Jo mindre restsummen av kvadrater sammenlignet med totalsummen av kvadrater, desto bedre passer regresjonsmodellen til dataene dine.
5 ting du bør vite om LINJEST-funksjonen
For å effektivt bruke LINJEST-formler i dine regneark, kan det være lurt å vite litt mer om den "indre mekanikken" til funksjonen:
- Kjente_y's og kjente_x'er . I en enkel lineær regresjonsmodell med bare ett sett med x-variabler, kjente_y-er og kjente_x-er kan være områder av hvilken som helst form så lenge de har samme antall rader og kolonner. Hvis du gjør multippel regresjonsanalyse med mer enn ett sett med uavhengige x -variabler, må kjente_y-er være en vektor, dvs. et område på én rad eller én kolonne.
- Tvinge konstanten til null . Når const -argumentet er SANN eller utelates, beregnes a -konstanten (avskjæring) og inkluderes i ligningen: y=bx + a. Hvis konst er satt til FALSE, anses avskjæringen å være lik 0 og utelatt fra regresjonsligningen: y=bx.
I statistikken har det vært diskutert i flere tiår om det er fornuftig å tvinge avskjæringskonstanten til 0 eller ikke. Mange troverdige utøvere av regresjonsanalyse mener at hvis å sette avskjæringen til null (const=FALSE) ser ut til å være nyttig, så er lineær regresjon i seg selv en feil modell for datasettet. Andre antar at konstanten kan tvinges til null i visse situasjoner, for eksempel i sammenheng med regresjonsdiskontinuitetsdesign. Generelt anbefales det å gå med standard const=TRUE eller utelates i de fleste tilfeller.
- Nøyaktighet . Nøyaktigheten til regresjonsligningen beregnet av LINJE-funksjonen avhenger av spredningen av datapunktene dine. Jo mer lineære dataene er, desto mer nøyaktige blir resultatene av LINEST-formelen.
- Redundante x-verdier . I noen situasjoner,én eller flere uavhengige x -variabler har kanskje ingen ekstra prediktiv verdi, og fjerning av slike variabler fra regresjonsmodellen påvirker ikke nøyaktigheten til de predikerte y-verdiene. Dette fenomenet er kjent som "kollinearitet". Excel LINEST-funksjonen sjekker for kollinearitet og utelater eventuelle redundante x -variabler som den identifiserer fra modellen. De utelatte x -variablene kan gjenkjennes av 0 koeffisienter og 0 standard feilverdier.
- LINEST vs. SLOPE og INTERCEPT . Den underliggende algoritmen til LINEST-funksjonen skiller seg fra algoritmen som brukes i SLOPE- og INTERCEPT-funksjonene. Derfor, når kildedataene er ubestemte eller kollineære, kan disse funksjonene returnere forskjellige resultater.
Excel LINEST-funksjonen fungerer ikke
Hvis LINEST-formelen gir en feil eller gir feil utdata , er sjansen stor for at det er på grunn av en av følgende årsaker:
- Hvis LINJE-funksjonen returnerer bare ett tall (hellingskoeffisient), har du mest sannsynlig angitt det som en vanlig formel, ikke en matriseformel. Sørg for å trykke Ctrl + Shift + Enter for å fullføre formelen riktig. Når du gjør dette, blir formelen omsluttet av {krøllete parenteser} som er synlige i formellinjen.
- #REF! feil. Oppstår hvis kjente_x-er og kjente_y-er -områdene har forskjellige dimensjoner.
- #VERDI! feil. Oppstår hvis kjente_x'er eller kjente_y-er inneholder minst én tom celle, tekstverdi eller tekstrepresentasjon av et tall som Excel ikke gjenkjenner som en numerisk verdi. Dessuten oppstår #VALUE-feilen hvis argumentet const eller stats ikke kan evalueres til TRUE eller FALSE.
Det er slik du bruker LINJEST i Excel for en enkel og multippel lineær regresjonsanalyse. For å se nærmere på formlene som er diskutert i denne opplæringen, er du velkommen til å laste ned vår eksempelarbeidsbok nedenfor. Jeg takker for at du leste og håper å se deg på bloggen vår neste uke!
Øvningsarbeidsbok for nedlasting
Excel LINEST-funksjonseksempler (.xlsx-fil)
(indikerer brattheten til regresjonslinjen, dvs. endringshastigheten for y når x endres).
I sin grunnleggende form returnerer LINJE-funksjonen skjæringspunktet (a) og helningen (b) for regresjonsligningen. Alternativt kan den også returnere tilleggsstatistikk for regresjonsanalysen som vist i dette eksemplet.
LINJEST-funksjonens syntaks
Syntaksen til Excel-LINJEST-funksjonen er som følger:
LINJEST(kjent_y's) , [known_x's], [const], [stats])Hvor:
- known_y's (obligatorisk) er et område av den avhengige y -verdier i regresjonsligningen. Vanligvis er det en enkelt kolonne eller en enkelt rad.
- kjente_x'er (valgfritt) er et område av de uavhengige x-verdiene. Hvis utelatt, antas det å være matrisen {1,2,3,...} av samme størrelse som kjente_y-er .
- konst (valgfritt) - en logisk verdi som bestemmer hvordan skjæringspunktet (konstant a ) skal behandles:
- Hvis TRUE eller utelatt, beregnes konstanten a normalt.
- Hvis FALSE, tvinges konstanten a til 0 og helningen ( b koeffisienten) beregnes for å passe til y=bx.
- statistikk (valgfritt) er en logisk verdi som bestemmer om tilleggsstatistikk skal sendes ut eller ikke:
- Hvis TRUE, returnerer LINJEST-funksjonen en matrise med ytterligere regresjonsstatistikk.
- Hvis FALSE eller utelatt, returnerer LINEST bare skjæringskonstanten og helningenkoeffisient(er).
Merk. Siden LINEST returnerer en matrise med verdier, må den angis som en matriseformel ved å trykke Ctrl + Shift + Enter-snarveien. Hvis den legges inn som en vanlig formel, returneres kun den første stigningskoeffisienten.
Ytterligere statistikk returnert av LINEST
Argumentet stats satt til TRUE instruerer LINEST-funksjonen om å returnere følgende statistikk for regresjonsanalysen:
| Statistikk | Beskrivelse |
| Helningskoeffisient | b verdi i y = bx + a |
| Skjæringskonstant | a verdi i y = bx + a |
| Standardfeil for helning | Standardfeilverdien(e) for b koeffisient(er). |
| Standard avskjæringsfeil | Standardfeilverdien for konstanten a . |
| Determinasjonskoeffisient (R2) | Angir hvor godt regresjonsligningen forklarer forholdet mellom variablene. |
| Standardfeil for Y-estimat | Viser presisjonen til regresjonsanalysen. |
| F-statistikk, eller den F-observerte verdien | Den brukes til å gjøre F-testen for nullhypotese for å bestemme den generelle godheten til modellen. |
| Grader av fr eedom (df) | Antall frihetsgrader. |
| Regresjonssum av kvadrater | Angir hvor mye av variasjonen iavhengig variabel forklares av modellen. |
| Restsum av kvadrater | Måler mengden av varians i den avhengige variabelen som ikke er forklart av regresjonsmodellen din. |
Kartet nedenfor viser rekkefølgen som LINEST returnerer en matrise med statistikk:

I de tre siste radene, #N/A-feil vil vises i den tredje og påfølgende kolonnene som ikke er fylt med data. Det er standardoppførselen til LINJEST-funksjonen, men hvis du ønsker å skjule feilnotasjonene, pakk inn LINJEST-formelen i IFERROR som vist i dette eksemplet.
Hvordan bruke LINJEST i Excel - formeleksempler
LINEST-funksjonen kan være vanskelig å bruke, spesielt for nybegynnere, fordi du ikke bare bør bygge en formel riktig, men også tolke utdataene riktig. Nedenfor finner du noen eksempler på bruk av LINEST formler i Excel som forhåpentligvis vil bidra til å senke den teoretiske kunnskapen inn :)
Enkel lineær regresjon: beregn helning og skjæring
For å få skjæringspunktet og stigningstallet til en regresjonslinje, bruker du LINJE-funksjonen i sin enkleste form: oppgi et område av de avhengige verdiene for kjent_y's -argumentet og et område av de uavhengige verdiene for kjente_x-ene argument. De to siste argumentene kan settes til TRUE eller utelates.
For eksempel med y -verdier (salgstall) i C2:C13- og x-verdier(annonseringskostnad) i B2:B13, vår lineære regresjonsformel er så enkel som:
=LINEST(C2:C13,B2:B13)
For å legge den inn riktig i regnearket, velg to tilstøtende celler i samme rad, E2: F2 i dette eksemplet, skriv inn formelen, og trykk Ctrl + Shift + Enter for å fullføre den.
Formelen vil returnere helningskoeffisienten i den første cellen (E2) og skjæringskonstanten i den andre cellen (F2) ):
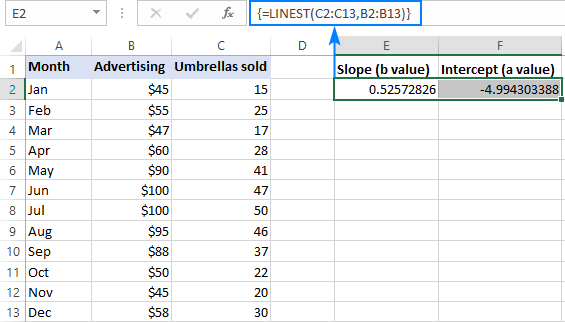
hellingen er omtrent 0,52 (avrundet til to desimaler). Det betyr at når x øker med 1, øker y med 0,52.
Y-skjæringspunktet er negativt -4,99. Det er den forventede verdien av y når x=0. Hvis det er plottet på en graf, er det verdien som regresjonslinjen krysser y-aksen med.
Legg inn verdiene ovenfor til en enkel lineær regresjonsligning, og du vil få følgende formel for å forutsi salgsnummeret basert på annonseringskostnaden:
y = 0.52*x - 4.99
Hvis du for eksempel bruker $50 på annonsering, forventes det at du selger 21 paraplyer:
0.52*50 - 4.99 = 21.01
Helnings- og avskjæringsverdiene kan også oppnås separat ved å bruke den tilsvarende funksjonen eller ved å neste LINEST-formelen inn i INDEX:
Slope
=SLOPE(C2:C13,B2:B13)
=INDEX(LINEST(C2:C13,B2:B13),1)
Intercept
=INTERCEPT(C2:C13,B2:B13)
=INDEX(LINEST(C2:C13,B2:B13),2)
Som vist på skjermbildet nedenfor, gir alle tre formlene de samme resultatene:

Multippel lineær regresjon: helning og avskjæring
Hvis du harto eller flere uavhengige variabler, sørg for å legge dem inn i tilstøtende kolonner, og oppgi hele området til kjent_xs -argumentet.
For eksempel med salgstall ( y verdier) i D2:D13, annonseringskostnad (ett sett med x-verdier) i B2:B13 og gjennomsnittlig månedlig nedbør (et annet sett med x -verdier) i C2:C13, bruker du denne formelen:
=LINEST(D2:D13,B2:C13)
Da formelen skal returnere en matrise med 3 verdier (2 helningskoeffisienter og skjæringskonstanten), velger vi tre sammenhengende celler i samme rad, skriver inn formelen og trykker Ctrl + Skift + Enter-snarvei.
Vær oppmerksom på at den multiple regresjonsformelen returnerer helningskoeffisientene i omvendt rekkefølge av de uavhengige variablene (fra høyre til venstre), som er b<10n , b n-1 , …, b 2 , b 1 :
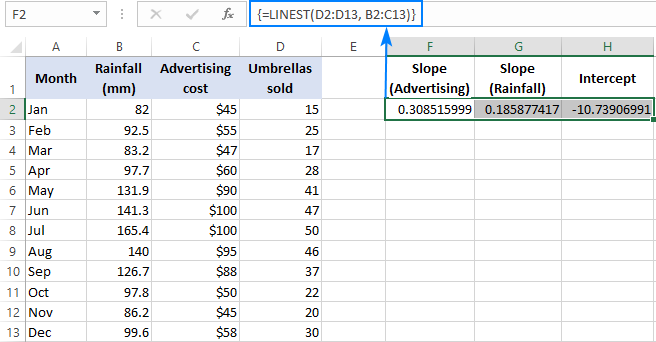
For å forutsi salgsnummeret, leverer vi verdiene returnert av LINJEST-formelen til multiple regresjonsligningen:
y = 0,3*x 2 + 0,19*x 1 - 10,74
F.eks rikelig, med $50 brukt på annonsering og en gjennomsnittlig månedlig nedbør på 100 mm, forventes du å selge omtrent 23 paraplyer:
0.3*50 + 0.19*100 - 10.74 = 23.26
Enkel lineær regresjon: forutsi avhengig variabel
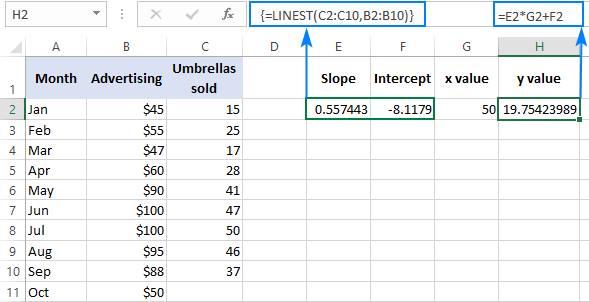
Bortsett fra å beregne a - og b -verdiene for regresjonsligningen, kan Excel LINEST-funksjonen også estimere den avhengige variabelen (y) basert på den kjente uavhengigevariabel (x). Til dette bruker du LINEST i kombinasjon med SUM- eller SUMPRODUKT-funksjonen.
Slik kan du for eksempel beregne antall paraplysalg for neste måned, for eksempel oktober, basert på salg i de foregående månedene og Oktobers annonseringsbudsjett på $50:
=SUM(LINEST(C2:C10, B2:B10)*{50,1})
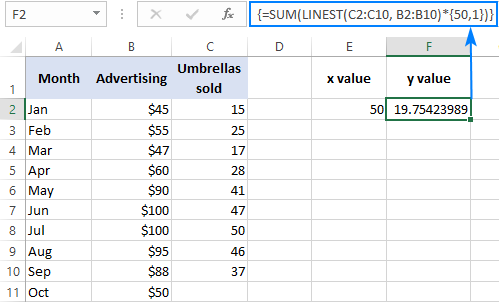
I stedet for å hardkode x -verdien i formelen, kan du angi den som en cellereferanse. I dette tilfellet må du også legge inn 1-konstanten i en celle fordi du ikke kan blande referanser og verdier i en matrisekonstant.
Med x -verdien i E2 og konstanten 1 i F2, en av formlene nedenfor vil fungere som en godbit:
Vanlig formel (skrives inn ved å trykke Enter):
=SUMPRODUCT(LINEST(C2:C10, B2:B10)*(E2:F2))
Arrayformel (skrives inn ved å trykke Ctrl + Shift + Enter ):
=SUM(LINEST(C2:C10, B2:B10)*(E2:F2))
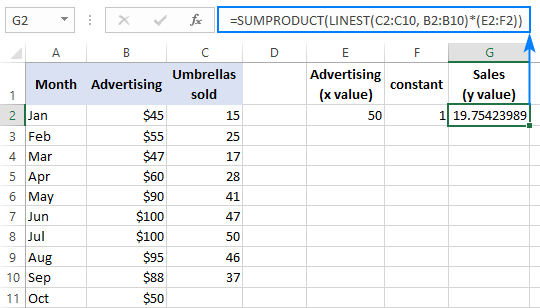
For å bekrefte resultatet kan du få skjæringspunktet og helningen for de samme dataene, og deretter bruke den lineære regresjonsformelen til å beregne y :
=E2*G2+F2
Hvor E2 er stigningen, G2 er x -verdien, og F2 er skjæringspunktet:
Multippel regresjon: forutsi avhengig variabel
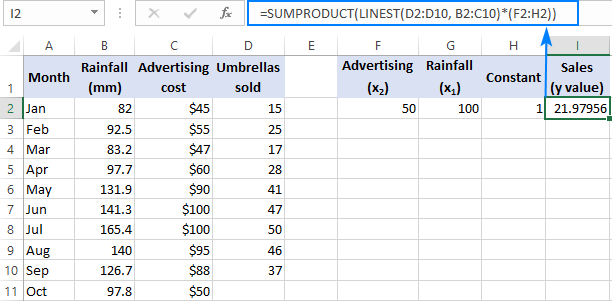
Hvis du har å gjøre med flere prediktorer, det vil si noen få forskjellige sett med x -verdier, inkluderer alle disse prediktorer i matrisekonstanten. For eksempel, med et annonseringsbudsjett på $50 (x 2 ) og en gjennomsnittlig månedlig nedbør på 100 mm (x 1 ), går formelen somfølger:
=SUM(LINEST(D2:D10, B2:C10)*{50,100,1})
Hvor D2:D10 er de kjente y -verdiene og B2:C10 er to sett med x -verdier:

Vær oppmerksom på rekkefølgen av x -verdiene i matrisekonstanten. Som påpekt tidligere, når Excel LINEST-funksjonen brukes til å gjøre multippel regresjon, returnerer den helningskoeffisientene fra høyre til venstre. I vårt eksempel returneres Reklame -koeffisienten først, og deretter Regnfall -koeffisienten. For å beregne det anslåtte salgstallet riktig, må du multiplisere koeffisientene med de tilsvarende x -verdiene, slik at du setter elementene i matrisekonstanten i denne rekkefølgen: {50,100,1}. Det siste elementet er 1, fordi den siste verdien returnert av LINEST er skjæringspunktet som ikke skal endres, så du multipliserer det med 1.
I stedet for å bruke en matrisekonstant, kan du legge inn alle x-variablene i noen celler, og referer til disse cellene i formelen din som vi gjorde i forrige eksempel.
Vanlig formel:
=SUMPRODUCT(LINEST(D2:D10, B2:C10)*(F2:H2))
Matriseformel:
=SUM(LINEST(D2:D10, B2:C10)*(F2:H2))
Hvor F2 og G2 er x -verdiene og H2 er 1:
LINEST formel: tilleggsregresjonsstatistikk
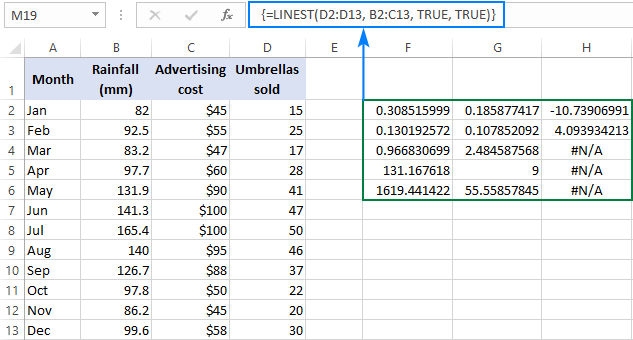
Som du kanskje husker, for å få mer statistikk for regresjonsanalysen, setter du TRUE i det siste argumentet til LINJEST-funksjonen. Brukt på prøvedataene våre, har formelen følgende form:
=LINEST(D2:D13, B2:C13, TRUE, TRUE)
Siden vi har 2 uavhengigevariabler i kolonne B og C, velger vi et raseri bestående av 3 rader (to x verdier + avskjæring) og 5 kolonner, skriv inn formelen ovenfor, trykk Ctrl + Shift + Enter , og få dette resultatet:
For å bli kvitt #N/A-feilene kan du legge LINEST inn i IFERROR slik:
=IFERROR(LINEST(D2:D13, B2:C13, TRUE, TRUE), "")
Skjermbildet nedenfor viser resultatet og forklarer hva hvert tall betyr:

Helningskoeffisienten og Y-skjæringspunktet ble forklart i de forrige eksemplene, så la oss ta en rask titt på den andre statistikken.
bestemmelseskoeffisient (R2). Verdien av R2 er resultatet av å dele regresjonssummen av kvadrater med totalsummen av kvadrater. Den forteller deg hvor mange y -verdier som er forklart av x -variabler. Det kan være et hvilket som helst tall fra 0 til 1, det vil si 0 % til 100 %. I dette eksemplet er R2 omtrent 0,97, noe som betyr at 97 % av våre avhengige variabler (paraplysalg) er forklart av de uavhengige variablene (reklame + gjennomsnittlig månedlig nedbør), som passer utmerket!
Standardfeil . Generelt viser disse verdiene presisjonen til regresjonsanalysen. Jo mindre tallene er, jo sikrere kan du være på regresjonsmodellen din.
F-statistikk . Du bruker F-statistikken for å støtte eller forkaste nullhypotesen. Det anbefales å bruke F-statistikken i kombinasjon med P-verdien når du avgjør om de samlede resultatene er det
