
Зміст
У цьому посібнику пояснюється синтаксис функції ЛИНЕЙН і показується, як використовувати її для проведення лінійного регресійного аналізу в Excel.
Microsoft Excel не є статистичною програмою, однак, вона має ряд статистичних функцій. Однією з таких функцій є ЛИНЕЙН, яка призначена для виконання лінійного регресійного аналізу і повернення відповідної статистики. У цьому посібнику для початківців ми лише злегка торкнемося теорії та основних розрахунків. Наша основна увага буде зосереджена на наданні вам формули, яка просто працює іможна легко налаштувати під ваші дані.
Функція ЛИНЕЙН в Excel - синтаксис та основні можливості використання
Функція ЛИНЕЙН обчислює статистику для прямої лінії, яка пояснює зв'язок між незалежною змінною і однією або декількома залежними змінними, і повертає масив, що описує цю лінію. Функція використовує найменших квадратів щоб знайти найкращу відповідність для ваших даних. Рівняння для лінії виглядає наступним чином.
Просте лінійне рівняння регресії:
y = bx + aРівняння множинної регресії:
y = b 1 x 1 + b 2 x 2 + ... + b n x n + aДе:
- y - залежна змінна, яку ви намагаєтесь передбачити.
- x - незалежна змінна, яку ви використовуєте для прогнозування y .
- a - перехват (вказує на місце перетину лінії з віссю Y).
- b - нахил (показує крутизну лінії регресії, тобто швидкість зміни у при зміні х).
У своїй базовій формі функція ЛИНЕЙНСТ повертає перехоплення (a) і нахил (b) для рівняння регресії. За бажанням, вона може також повертати додаткову статистику для регресійного аналізу, як показано в цьому прикладі.
Синтаксис функції LINEST
Синтаксис функції СРЗНАЧ наступний:
LINEST(відомі_у, [відомі_х], [const], [stats])Де:
- відомі_вам (обов'язково) - діапазон залежних y -значення в рівнянні регресії, як правило, це один стовпчик або один рядок.
- відомих_іксів (необов'язково) - діапазон незалежних значень x. Якщо не вказано, вважається, що це масив {1,2,3,...} того ж розміру, що і відомі_вам .
- const (необов'язково) - логічне значення, що визначає спосіб перехоплення (константа a ) слід лікувати:
- Якщо TRUE або пропущено, то константа a розраховується нормально.
- Якщо FALSE, то константа a прирівнюється до 0, а нахил ( b коефіцієнт) розраховується відповідно до y=bx.
- статистика (необов'язково) - логічне значення, яке визначає, виводити додаткову статистику чи ні:
- Якщо TRUE, функція LINEST повертає масив з додатковою статистикою регресії.
- Якщо FALSE або пропущено, LINEST повертає тільки константу перехоплення і коефіцієнт(и) нахилу.
Примітка. Оскільки функція LINEST повертає масив значень, її необхідно вводити як формулу масиву, натиснувши комбінацію клавіш Ctrl + Shift + Enter. Якщо вона вводиться як звичайна формула, то повертається тільки перший коефіцієнт нахилу.
Додаткові статистичні дані, отримані від LINEST
На сьогоднішній день, на жаль, це не так. статистика аргумент TRUE вказує функції LINEST повернути наступні статистичні дані для вашого регресійного аналізу:
| Статистика | Опис |
| Коефіцієнт нахилу | b значення в y = bx + a |
| Константа перехоплення | значення в y = bx + a |
| Стандартна похибка нахилу | Значення стандартної похибки для коефіцієнта(ів) b. |
| Стандартна похибка перехоплення | Значення стандартної похибки для константи a . |
| Коефіцієнт детермінації (R2) | Показує, наскільки добре рівняння регресії пояснює зв'язок між змінними. |
| Стандартна похибка для оцінки Y | Показує точність регресійного аналізу. |
| F-статистика, або F-спостережуване значення | Він використовується для проведення F-тесту для нульової гіпотези з метою визначення загальної адекватності моделі. |
| Ступені свободи (df) | Кількість ступенів свободи. |
| Сума квадратів регресії | Показує, яка частина варіації залежної змінної пояснюється моделлю. |
| Залишкова сума квадратів | Вимірює величину дисперсії залежної змінної, яка не пояснюється вашою регресійною моделлю. |
На наведеній нижче карті показано порядок, в якому LINEST повертає масив статистичних даних:

В останніх трьох рядках помилки #N/A з'являться в третьому і наступних стовпчиках, які не заповнені даними. Це поведінка функції ЛИНЕЙН за замовчуванням, але якщо ви хочете приховати позначення помилок, оберніть формулу ЛИНЕЙН в IFERROR, як показано в цьому прикладі.
Як використовувати LINEST в Excel - приклади формул
Функція ЛИНЕЙН може бути складною у використанні, особливо для новачків, адже потрібно не тільки правильно побудувати формулу, але й правильно інтерпретувати її результат. Нижче наведено кілька прикладів використання формул ЛИНЕЙН в Excel, які, сподіваємось, допоможуть засвоїти теоретичні знання :)
Проста лінійна регресія: розраховуємо нахил та інтервал
Для отримання перехоплення та нахилу лінії регресії використовується функція ЛИНЕЙНСТ в її найпростішому вигляді: подається діапазон залежних значень для відомі_вам та діапазон незалежних значень для аргументу відомих_іксів Останні два аргументи можуть мати значення TRUE або бути опущені.
Наприклад, з y (кількість продажів) в C2:C13 та x (витрати на рекламу) в B2:B13, наша формула лінійної регресії є дуже простою:
=LINEST(C2:C13,B2:B13)
Щоб правильно ввести її на робочому аркуші, виділіть дві сусідні комірки в одному рядку, в даному прикладі E2:F2, введіть формулу і натисніть Ctrl + Shift + Enter, щоб завершити її введення.
Формула поверне коефіцієнт нахилу в першій комірці (E2) і константу перехоплення в другій комірці (F2):
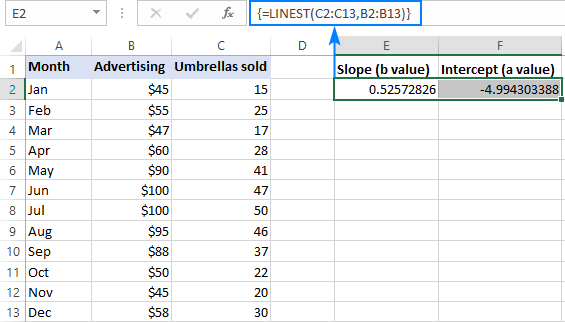
На сьогоднішній день, на жаль, це не так. нахил дорівнює приблизно 0,52 (з округленням до двох знаків після коми). Це означає, що при x збільшується на 1, y зростає на 0,52.
На сьогоднішній день, на жаль, це не так. Y-перехоплення є від'ємним -4,99. Очікуване значення y при x=0. При нанесенні на графік - це значення, при якому лінія регресії перетинає вісь y.
Підставте вищевказані значення в просте рівняння лінійної регресії, і ви отримаєте наступну формулу для прогнозування кількості продажів на основі витрат на рекламу:
y = 0,52*x - 4,99
Наприклад, якщо ви витратите 50 доларів на рекламу, то очікується, що ви продасте 21 парасольку:
0.52*50 - 4.99 = 21.01
Значення нахилу та перехоплення також можна отримати окремо, використовуючи відповідну функцію або вклавши формулу LINEST в INDEX:
Нахил
=SLOPE(C2:C13,B2:B13)
=INDEX(LINEST(C2:C13,B2:B13),1)
Перехоплення
=INTERCEPT(C2:C13,B2:B13)
=INDEX(LINEST(C2:C13,B2:B13),2)
Як показано на скріншоті нижче, всі три формули дають однакові результати:

Множинна лінійна регресія: нахил та перехоплення
Якщо у вас є дві або більше незалежних змінних, обов'язково введіть їх у сусідніх стовпчиках і введіть весь цей діапазон у поле відомих_іксів аргумент.
Наприклад, з цифрами продажів ( y значень) в D2:D13, вартість реклами (один набір значень x) в B2:B13 та середньомісячна кількість опадів (інший набір значень x) в B2:B13. x значень) в С2:С13, то ви використовуєте цю формулу:
=LINEST(D2:D13,B2:C13)
Оскільки формула повинна повернути масив з 3 значень (2 коефіцієнти нахилу і константа перехоплення), виділяємо три суміжні комірки в одному рядку, вводимо формулу і натискаємо комбінацію клавіш Ctrl + Shift + Enter.
Зверніть увагу, що формула множинної регресії повертає коефіцієнти ухилу в зворотний порядок незалежних змінних (справа наліво), тобто b n , b n-1 , ..., b 2 , b 1 :
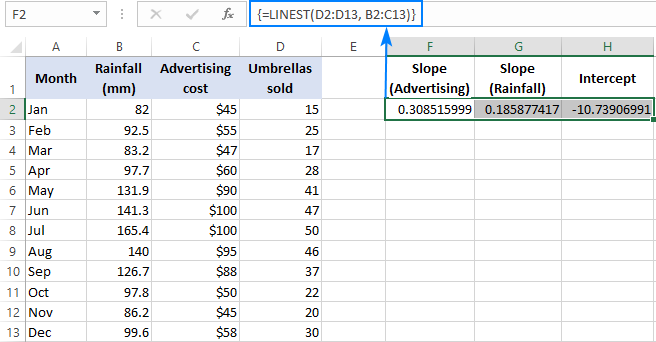
Щоб спрогнозувати кількість продажів, ми підставляємо значення, повернуті формулою ЛИНЕЙСТА, в рівняння множинної регресії:
y = 0.3*x 2 + 0.19*x 1 - 10.74
Наприклад, при витраті $50 на рекламу і середньомісячній кількості опадів 100 мм очікується, що ви продасте приблизно 23 парасольки:
0.3*50 + 0.19*100 - 10.74 = 23.26
Проста лінійна регресія: прогнозуємо залежну змінну
Крім розрахунку a і b значення для рівняння регресії, функція ЛИНЕЙНСТ Excel може також оцінити залежну змінну (у) на основі відомої незалежної змінної (х). Для цього використовується ЛИНЕЙНСТ в поєднанні з функцією СУММЕСЛИ або СУММПРОИЗВОД.
Наприклад, ось як можна розрахувати кількість продажів парасольок на наступний місяць, скажімо, жовтень, виходячи з продажів у попередні місяці та рекламного бюджету на жовтень у розмірі 50 доларів:
=SUM(LINEST(C2:C10, B2:B10)*{50,1})
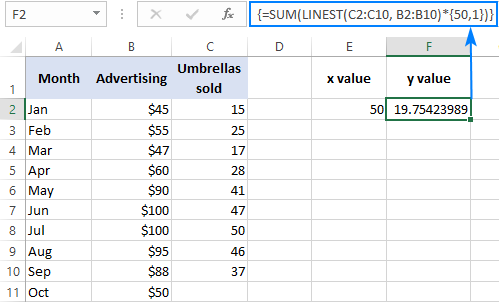
Замість того, щоб жорстко кодувати x значення у формулі, ви можете вказати його як посилання на комірку. У цьому випадку константу 1 також потрібно ввести в якусь комірку, оскільки в константі масиву не можна змішувати посилання і значення.
За допомогою x значення в E2 і константу 1 в F2, будь-яка з наведених нижче формул буде працювати безвідмовно:
Звичайна формула (вводиться натисканням клавіші Enter):
=SUMPRODUCT(LINEST(C2:C10, B2:B10)*(E2:F2))
Формула масиву (вводиться натисканням клавіш Ctrl + Shift + Enter):
=SUM(LINEST(C2:C10, B2:B10)*(E2:F2))
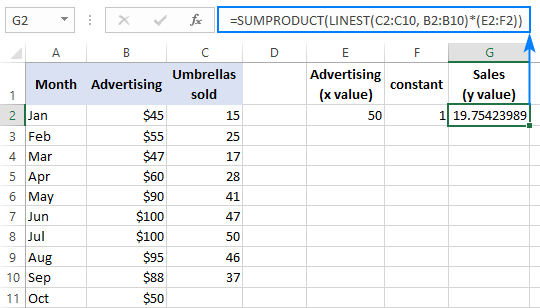
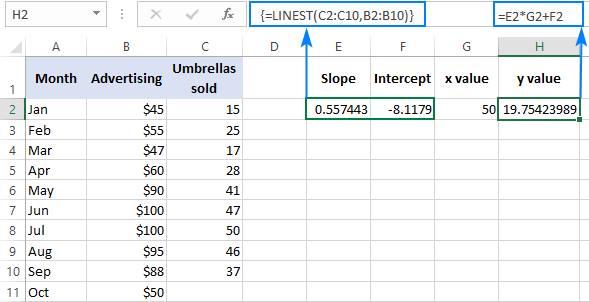
Для перевірки результату можна отримати перехоплення і нахил для тих же даних, а потім за формулою лінійної регресії розрахувати y :
=E2*G2+F2
Де E2 - нахил, G2 - ухил x значення, а F2 - перехоплення:
Множинна регресія: прогнозуємо залежну змінну
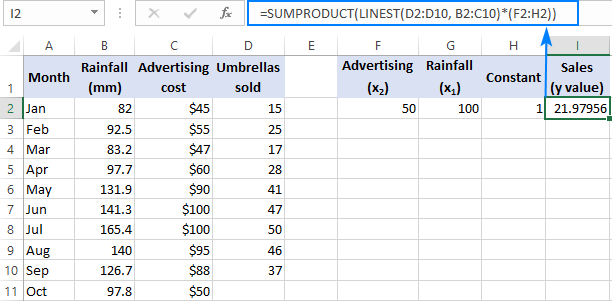
Якщо ви маєте справу з декількома предикторами, тобто з декількома різними наборами x включимо всі ці предиктори в константу масиву. Наприклад, при рекламному бюджеті $50 (x 2 ) та середньомісячною кількістю опадів 100 мм (x 1 ), формула виглядає наступним чином:
=SUM(LINEST(D2:D10, B2:C10)*{50,100,1})
де D2:D10 - відомі y а B2:C10 - два набори значень x цінності:

Просимо звернути увагу на черговість x Як зазначалося раніше, коли функція ЛИНЕЙНСТ використовується для побудови множинної регресії, вона повертає коефіцієнти нахилу справа наліво. У нашому прикладі функція ЛИНЕЙНСТ Реклама повертається спочатку коефіцієнт Кількість опадів Щоб правильно розрахувати прогнозовану кількість продажів, необхідно помножити коефіцієнти на відповідні x значення, тому ви розміщуєте елементи масиву constant у такому порядку: {50,100,1}. Останній елемент - 1, тому що останнє значення, яке повертає LINEST - це перехоплення, яке не слід змінювати, тому ви просто помножуєте його на 1.
Замість того, щоб використовувати константу масиву, ви можете ввести всі змінні х в окремі клітинки і посилатися на ці клітинки у формулі, як ми це зробили в попередньому прикладі.
Звичайна формула:
=SUMPRODUCT(LINEST(D2:D10, B2:C10)*(F2:H2))
Формула масиву:
=SUM(LINEST(D2:D10, B2:C10)*(F2:H2))
Де F2 та G2 - це x і Н2 дорівнює 1:
Формула LINEST: додаткова регресійна статистика
Як ви пам'ятаєте, щоб отримати більше статистичних даних для регресійного аналізу, в останньому аргументі функції ЛИНЕЙНСТ потрібно вказати значення ІСТИНА. Застосовуючи до наших вибіркових даних, формула набуває наступного вигляду:
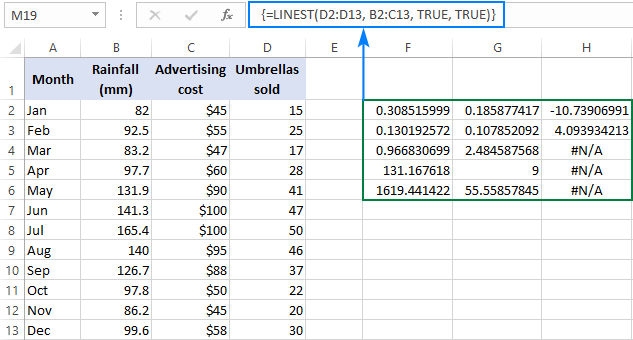
=LINEST(D2:D13, B2:C13, TRUE, TRUE)
Оскільки ми маємо 2 незалежні змінні в стовпчиках B і C, ми вибираємо гнів, що складається з 3 рядків (два значення x + перехоплення) і 5 стовпчиків, вводимо наведену вище формулу, натискаємо Ctrl + Shift + Enter, і отримуємо такий результат:
Щоб позбутися помилок #N/A, можна вкласти LINEST в IFERROR ось так:
=IFERROR(LINEST(D2:D13, B2:C13, TRUE, TRUE), "")
Скріншот нижче демонструє результат і пояснює, що означає кожна цифра:

Коефіцієнти нахилу та Y-інтервал були пояснені в попередніх прикладах, тому давайте коротко розглянемо інші статистичні дані.
Коефіцієнт детермінації (Значення R2 - це результат ділення суми квадратів регресії на загальну суму квадратів. Воно показує, на скільки y значення пояснюються x Це може бути будь-яке число від 0 до 1, тобто від 0% до 100%. У цьому прикладі R2 становить приблизно 0,97, що означає, що 97% наших залежних змінних (продажі парасольок) пояснюються незалежними змінними (реклама + середньомісячна кількість опадів), що є відмінною відповідністю!
Стандартні похибки Як правило, ці значення показують точність регресійного аналізу. Чим менші числа, тим більше ви можете бути впевнені у вашій регресійній моделі.
F-статистика Ви використовуєте F-статистику для підтвердження або відхилення нульової гіпотези. Рекомендується використовувати F-статистику в поєднанні з P-значенням при вирішенні питання про те, чи є загальні результати значущими.
Ступені свободи (df). функція ЛИНЕЙН в Excel повертає функцію залишкові ступені свободи який є загальний df за вирахуванням регресія df Ви можете використовувати ступені свободи для отримання F-критичних значень у статистичній таблиці, а потім порівняти F-критичні значення з F-статистикою для визначення рівня довіри до вашої моделі.
Сума квадратів регресії (також відома як пояснена сума квадратів або модель суми квадратів Це сума квадратів різниць між прогнозованими значеннями у та середнім значенням у, розрахована за такою формулою: =∑(ŷ - ȳ)2. Вона показує, яку частину варіації залежної змінної пояснює ваша регресійна модель.
Залишкова сума квадратів Це сума квадратів різниць між фактичними та прогнозованими значеннями y. Вона показує, яку частину варіації залежної змінної ваша модель не пояснює. Чим менша залишкова сума квадратів порівняно із загальною сумою квадратів, тим краще ваша регресійна модель відповідає вашим даним.
5 речей, які варто знати про функцію LINEST
Щоб ефективно використовувати формули LINEST у своїх робочих аркушах, можливо, ви захочете дізнатися трохи більше про "внутрішню механіку" функції:
- Відомі і відомих_іксів У простій лінійній регресійній моделі з одним набором змінних х, відомі_вам і відомих_іксів можуть бути діапазонами будь-якої форми, якщо вони мають однакову кількість рядків і стовпців. Якщо ви проводите множинний регресійний аналіз з більш ніж одним набором незалежних x змінні, відомі_вам має бути вектором, тобто діапазоном з одного рядка або одного стовпця.
- Приведення константи до нуля Коли в Україні з'явився const аргумент має значення ІСТИНА або пропущений, то a обчислюється константа (перехоплення), яка входить в рівняння: y=bx + a. Якщо const встановлюється в значення FALSE, перехоплення вважається рівним 0 і не включається в рівняння регресії: y=bx.
У статистиці десятиліттями точаться суперечки про те, чи має сенс примушувати константу перехоплення дорівнювати 0 чи ні. Багато авторитетних практиків регресійного аналізу вважають, що якщо встановлення перехоплення на нуль (const=FALSE) виявляється корисним, то сама лінійна регресія є неправильною моделлю для набору даних. Інші вважають, що константу можна примусити дорівнювати нулю в певних ситуаціях, наприклад, в деяких ситуаціях,в контексті розривних моделей регресії. Загалом, рекомендується використовувати значення за замовчуванням const=TRUE або опускати його в більшості випадків.
- Точність Точність рівняння регресії, розрахованого функцією ЛИНЕЙНСТ, залежить від дисперсії ваших точок даних. Чим більш лінійні дані, тим точніші результати формули ЛИНЕЙНСТ.
- Надлишкові значення x У деяких ситуаціях один або декілька незалежних x змінні можуть не мати додаткової прогностичної цінності, і видалення таких змінних з регресійної моделі не впливає на точність прогнозованих значень у. Це явище називається "колінеарність". Функція ЛИНЕЙНСТ Excel перевіряє наявність колінеарності і видаляє зайві змінні. x змінні, які вона ідентифікує з моделі. Пропущені x змінні можуть бути розпізнані за 0 коефіцієнтами та 0 значеннями стандартної похибки.
- LINEST проти SLOPE та INTERCEPT Алгоритм, що лежить в основі функції ЛИНЕЙНСТ, відрізняється від алгоритму, що використовується у функціях СЛОЙ і ИНТЕРСЕПТ. Тому, коли вихідні дані є невизначеними або колінеарними, ці функції можуть повертати різні результати.
Не працює функція Excel LINEST
Якщо ваша формула LINEST видає помилку або виводить неправильний результат, швидше за все, це пов'язано з однією з наступних причин:
- Якщо функція ЛИНЕЙН повертає лише одне число (коефіцієнт нахилу), швидше за все, ви ввели її як звичайну формулу, а не формулу масиву. Обов'язково натисніть Ctrl + Shift + Enter, щоб правильно заповнити формулу. При цьому формула буде укладена в {фігурні дужки}, які видно в рядку формул.
- Помилка #REF!. Виникає, якщо відомих_іксів і відомі_вам діапазони мають різні габарити.
- Помилка #VALUE! Виникає, якщо відомих_іксів або відомі_вам містить хоча б одну порожню комірку, текстове значення або текстове представлення числа, яке Excel не розпізнає як числове значення. Також помилка #VALUE виникає, якщо const або статистика аргумент не може бути оцінений як ІСТИНА або ХИБНІСТЬ.
Ось як можна використовувати LINEST в Excel для простого і множинного лінійного регресійного аналізу. Щоб ближче познайомитися з формулами, розглянутими в цьому уроці, ви можете завантажити наш зразок робочого зошита нижче. Дякую за прочитання і сподіваюся побачити вас на нашому блозі наступного тижня!
Практичний посібник для завантаження
Приклади функцій Excel LINEST (файл .xlsx)
