
Innehållsförteckning
Den här handledningen förklarar syntaxen för LINEST-funktionen och visar hur du använder den för att göra linjära regressionsanalyser i Excel.
Microsoft Excel är inte ett statistikprogram, men det har ett antal statistiska funktioner. En av dessa funktioner är LINEST, som är utformad för att utföra linjära regressionsanalyser och återge relaterad statistik. I den här handledningen för nybörjare kommer vi endast att beröra teorin och de underliggande beräkningarna. Vårt huvudfokus kommer att vara att ge dig en formel som helt enkelt fungerar ochkan enkelt anpassas till dina uppgifter.
Excel LINEST-funktionen - syntax och grundläggande användningsområden
Funktionen LINEST beräknar statistiken för en rak linje som förklarar förhållandet mellan den oberoende variabeln och en eller flera beroende variabler, och returnerar en matris som beskriver linjen. minsta kvadrat. Metoden för att hitta den bästa anpassningen för dina data. Ekvationen för linjen är följande.
Enkel linjär regressionsekvation:
y = bx + aEkvation för multipel regression:
y = b 1 x 1 + b 2 x 2 + ... + b n x n + aVar:
- y - den beroende variabel som du försöker förutsäga.
- x - den oberoende variabel som du använder för att förutsäga y .
- a - skärningspunkten (anger var linjen skär Y-axeln).
- b - lutningen (anger regressionslinjens branthet, dvs. hur snabbt y förändras när x förändras).
I sin grundform returnerar LINEST-funktionen interceptet (a) och lutningen (b) för regressionsekvationen. Som ett alternativ kan den också returnera ytterligare statistik för regressionsanalysen, vilket visas i det här exemplet.
Syntax för LINEST-funktioner
Syntaxen för Excel LINEST-funktionen är följande:
LINEST(known_y's, [known_x's], [const], [stats])Var:
- known_y's (krävs) är ett intervall för den beroende y -värden i regressionsekvationen. Vanligtvis är det en enda kolumn eller en enda rad.
- known_x's (valfritt) är ett intervall för de oberoende x-värdena. Om det utelämnas antas det vara matrisen {1,2,3,...} av samma storlek som known_y's .
- const (valfritt) - ett logiskt värde som bestämmer hur interceptet (konstant a ) bör behandlas:
- Om TRUE eller om den utelämnas, kommer konstanten a beräknas på normalt sätt.
- Om FALSE, är konstanten a tvingas till 0 och lutningen ( b koefficient) beräknas för att passa y=bx.
- statistik (valfritt) är ett logiskt värde som bestämmer om ytterligare statistik ska skickas ut eller inte:
- Om den är TRUE returnerar LINEST-funktionen en matris med ytterligare regressionsstatistik.
- Om FALSE eller utelämnas returnerar LINEST endast interceptkonstanten och lutningskoefficienten/koefficienterna.
Eftersom LINEST returnerar en matris av värden måste den skrivas in som en matrisformel genom att trycka på genvägen Ctrl + Shift + Enter. Om den skrivs in som en vanlig formel returneras endast den första lutningskoefficienten.
Ytterligare statistik som returneras av LINEST
statistik argumentet är satt till TRUE, vilket innebär att LINEST-funktionen ska ge följande statistik för din regressionsanalys:
| Statistik | Beskrivning |
| Koefficient för lutning | b värdet i y = bx + a |
| Interceptkonstant | ett värde i y = bx + a |
| Standardfel för lutningen | Standardfelvärde(n) för b-koefficienten(erna). |
| Standardfel för interceptet | Standardfelvärdet för konstanten a . |
| Bestämningskoefficient (R2) | Anger hur väl regressionsekvationen förklarar sambandet mellan variablerna. |
| Standardfel för Y-skattningen | Visar regressionsanalysens precision. |
| F-statistik, eller F-värdet för observerat värde. | Den används för att göra F-testet för nollhypotesen för att fastställa modellens övergripande passform. |
| Frihetsgrader (df) | Antalet frihetsgrader. |
| Regression summa av kvadrater | Anger hur stor del av variationen i den beroende variabeln som förklaras av modellen. |
| Resterande summa av kvadrater | Mäter den mängd varians i den beroende variabeln som inte förklaras av regressionsmodellen. |
Kartan nedan visar i vilken ordning LINEST returnerar en matris med statistik:

I de tre sista raderna kommer #N/A-felen att visas i den tredje och följande kolumner som inte är fyllda med data. Det är standardbeteendet för LINEST-funktionen, men om du vill dölja felnoteringarna kan du linda in LINEST-formeln i IFERROR som i det här exemplet.
Hur man använder LINEST i Excel - exempel på formler
LINEST-funktionen kan vara svår att använda, särskilt för nybörjare, eftersom du inte bara ska bygga upp en formel på rätt sätt, utan också tolka resultatet korrekt. Nedan hittar du några exempel på hur du använder LINEST-formler i Excel som förhoppningsvis hjälper dig att få in den teoretiska kunskapen :)
Enkel linjär regression: beräkna lutning och intercept
För att få fram interceptet och lutningen för en regressionslinje använder du LINEST-funktionen i dess enklaste form: ange ett intervall av beroende värden för known_y's argumentet och ett intervall av oberoende värden för known_x's De två sista argumenten kan sättas till TRUE eller utelämnas.
Till exempel, med y värden (försäljningssiffror) i C2:C13 och x-värden (reklamkostnader) i B2:B13 är vår formel för linjär regression så enkel som:
=LINEST(C2:C13,B2:B13)
För att skriva in den korrekt i arbetsbladet markerar du två intilliggande celler i samma rad, E2:F2 i det här exemplet, skriver formeln och trycker på Ctrl + Shift + Enter för att slutföra den.
Formeln returnerar lutningskoefficienten i den första cellen (E2) och interceptkonstanten i den andra cellen (F2):
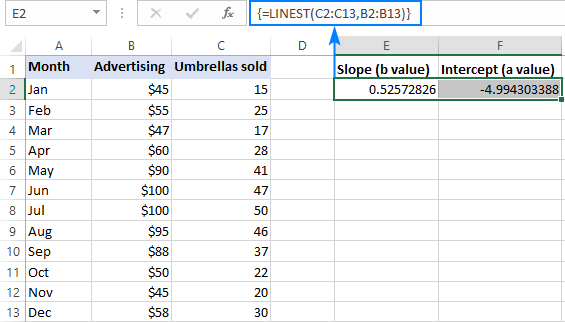
lutning är ungefär 0,52 (avrundat till två decimaler). Det innebär att när x ökar med 1, y ökar med 0,52.
Y-intercept är negativt -4,99. Det är det förväntade värdet av y när x=0. Om det visas i en graf är det det värde vid vilket regressionslinjen korsar y-axeln.
Om du använder ovanstående värden i en enkel linjär regressionsekvation får du följande formel för att förutsäga försäljningssiffrorna baserat på reklamkostnaden:
y = 0,52*x - 4,99
Om du till exempel lägger 50 dollar på reklam förväntas du sälja 21 paraplyer:
0.52*50 - 4.99 = 21.01
Värdena för lutning och intercept kan också erhållas separat genom att använda motsvarande funktion eller genom att hägna in LINEST-formeln i INDEX:
Lutning
=SLOPE(C2:C13,B2:B13)
=INDEX(LINEST(C2:C13,B2:B13),1)
Intercept
=INTERCEPT(C2:C13,B2:B13)
=INDEX(LINEST(C2:C13,B2:B13),2)
Som framgår av skärmbilden nedan ger alla tre formlerna samma resultat:

Multipel linjär regression: lutning och intercept
Om du har två eller flera oberoende variabler, se till att du anger dem i intilliggande kolumner, och förse hela området med hela intervallet till known_x's argument.
Till exempel med försäljningsnummer ( y värden) i D2:D13, reklamkostnad (en uppsättning x-värden) i B2:B13 och genomsnittlig månadsregn (en annan uppsättning x-värden) i B2:B13 och genomsnittlig månadsregn (en annan uppsättning x-värden) i B2:B13. x värden) i C2:C13 använder du denna formel:
=LINEST(D2:D13,B2:C13)
Eftersom formeln ska ge en matris med tre värden (två lutningskoefficienter och interceptkonstanten) väljer vi tre sammanhängande celler i samma rad, skriver in formeln och trycker på genvägen Ctrl + Shift + Enter.
Observera att formeln för multipel regression returnerar lutningskoefficienter. i den omvänd ordning av de oberoende variablerna (från höger till vänster), dvs. b n , b n-1 , ..., b 2 , b 1 :
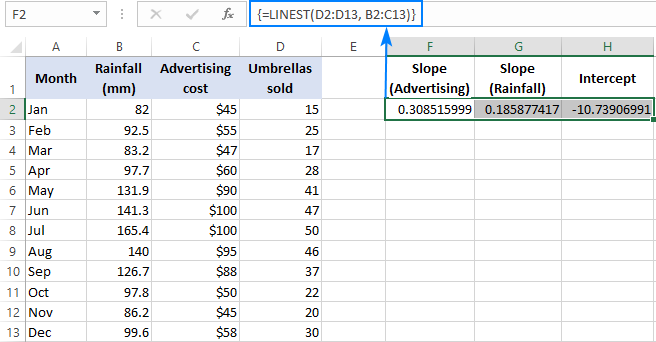
För att förutsäga försäljningssiffrorna förser vi multipelregressionsekvationen med de värden som LINEST-formeln ger oss:
y = 0,3*x 2 + 0.19*x 1 - 10.74
Om du till exempel spenderar 50 dollar på annonsering och om den genomsnittliga nederbörden per månad är 100 mm, förväntas du sälja cirka 23 paraplyer:
0.3*50 + 0.19*100 - 10.74 = 23.26
Enkel linjär regression: förutsäga den beroende variabeln
Förutom att beräkna a och b Om du vill använda Excel-funktionen LINEST för att beräkna regressionsekvationen kan du också uppskatta den beroende variabeln (y) utifrån den kända oberoende variabeln (x). För detta använder du LINEST i kombination med funktionerna SUM eller SUMPRODUCT.
Så här kan du till exempel beräkna antalet paraplyförsäljningar för nästa månad, låt oss säga oktober, baserat på försäljningen under de föregående månaderna och oktober månads reklambudget på 50 dollar:
=SUM(LINEST(C2:C10, B2:B10)*{50,1})
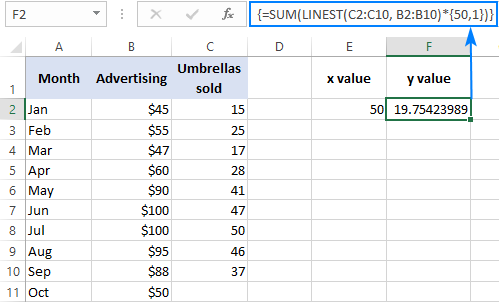
Istället för att hårdkoda x I det här fallet måste du också ange konstanten 1 i en cell eftersom du inte kan blanda referenser och värden i en arraykonstant.
Med hjälp av x värdet i E2 och konstanten 1 i F2, fungerar någon av nedanstående formler utmärkt:
Ordinarie formel (skrivs in genom att trycka på Enter ):
=SUMPRODUKT(LINEST(C2:C10, B2:B10)*(E2:F2))
Array-formel (skrivs in genom att trycka på Ctrl + Shift + Enter ):
=SUMMA(LINEST(C2:C10, B2:B10)*(E2:F2))
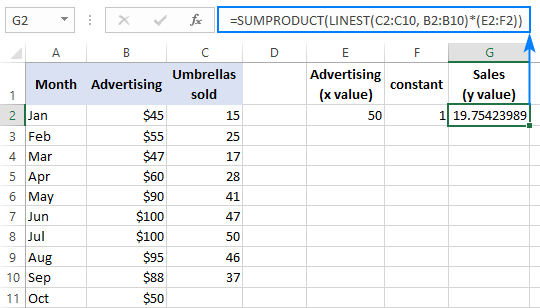
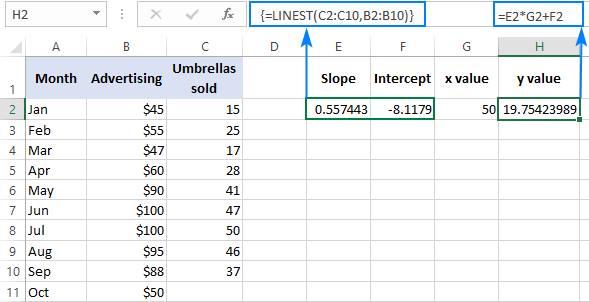
För att verifiera resultatet kan du ta fram interceptet och lutningen för samma data och sedan använda formeln för linjär regression för att beräkna y :
=E2*G2+F2
Där E2 är lutningen, G2 är x värde och F2 är interceptet:
Multipel regression: förutsäga den beroende variabeln
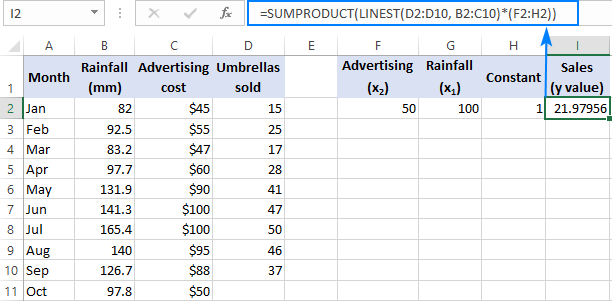
Om du har att göra med flera prediktorer, dvs. några olika uppsättningar av x värden, inkludera alla dessa prediktorer i arrayen konstant. Till exempel, med en reklambudget på 50 dollar (x 2 ) och en genomsnittlig månadsnederbörd på 100 mm (x 1 ), så lyder formeln som följer:
=SUM(LINEST(D2:D10, B2:C10)*{50,100,1})
Där D2:D10 är de kända y värden och B2:C10 är två uppsättningar av x värden:

Var uppmärksam på ordningsföljden av x värden i arrayen konstant. Som tidigare påpekats, när Excel LINEST-funktionen används för att göra multipel regression, returnerar den lutningskoefficienterna från höger till vänster. I vårt exempel är det Reklam koefficienten returneras först, och därefter återges koefficienten Nederbörd För att beräkna det förutspådda försäljningstalet korrekt måste du multiplicera koefficienterna med motsvarande x Värden, så du placerar elementen i arraykonstanten i denna ordning: {50,100,1}. Det sista elementet är 1, eftersom det sista värdet som LINEST returnerar är det intercept som inte ska ändras, så du multiplicerar det helt enkelt med 1.
Istället för att använda en arraykonstant kan du ange alla x-variabler i vissa celler och hänvisa till dessa celler i formeln, som vi gjorde i det föregående exemplet.
Normal formel:
=SUMPRODUKT(LINEST(D2:D10, B2:C10)*(F2:H2))
Formel för arrayer:
=SUMMA(LINEST(D2:D10, B2:C10)*(F2:H2))
Där F2 och G2 är x värden och H2 är 1:
LINEST-formeln: ytterligare regressionsstatistik
Som du kanske minns, för att få mer statistik för din regressionsanalys, sätter du TRUE i det sista argumentet i LINEST-funktionen. Tillämpad på våra provdata får formeln följande form:
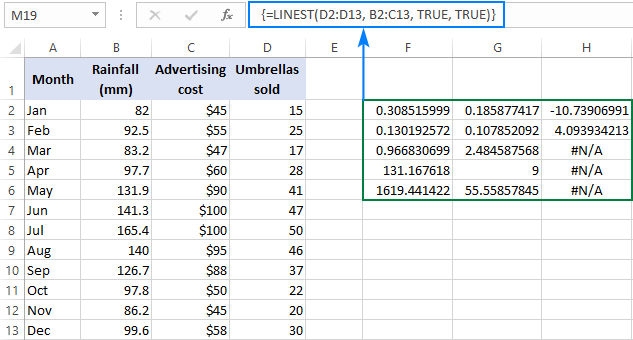
=LINEST(D2:D13, B2:C13, TRUE, TRUE)
Eftersom vi har två oberoende variabler i kolumnerna B och C väljer vi en rage som består av tre rader (två x-värden + intercept) och fem kolumner, skriver in ovanstående formel, trycker på Ctrl + Shift + Enter och får detta resultat:
För att bli av med #N/A-felen kan du bädda in LINEST i IFERROR på följande sätt:
=IFERROR(LINEST(D2:D13, B2:C13, TRUE, TRUE), "")
Skärmbilden nedan visar resultatet och förklarar vad varje siffra betyder:

Hällningskoefficienterna och Y-interceptet förklarades i de tidigare exemplen, så låt oss ta en snabb titt på den övriga statistiken.
Bestämningskoefficient (R2). Värdet R2 är resultatet av att regressionens kvadratsumma divideras med den totala kvadratsumman. Det anger hur många y värden förklaras av följande x Det kan vara ett tal mellan 0 och 1, dvs. 0 % till 100 %. I det här exemplet är R2 ungefär 0,97, vilket innebär att 97 % av våra beroende variabler (paraplyförsäljning) förklaras av de oberoende variablerna (reklam + genomsnittlig månatlig nederbörd), vilket är en utmärkt anpassning!
Standardfel I allmänhet visar dessa värden regressionsanalysens precision. Ju mindre siffrorna är, desto säkrare kan du vara på din regressionsmodell.
F-statistik Du använder F-statistiken för att stödja eller förkasta nollhypotesen. Det rekommenderas att använda F-statistiken i kombination med P-värdet när du beslutar om de övergripande resultaten är signifikanta.
Frihetsgrader (df). LINEST-funktionen i Excel returnerar Resterande frihetsgrader. , som är den total df minus den regression df Du kan använda frihetsgraderna för att få fram F-kritiska värden i en statistisk tabell och sedan jämföra de F-kritiska värdena med F-statistiken för att fastställa en konfidensnivå för din modell.
Regression summa av kvadrater (även kallad förklarad summa av kvadrater , eller modellens summa av kvadrater ). Det är summan av de kvadrerade skillnaderna mellan de förutspådda y-värdena och medelvärdet för y, beräknat med denna formel: =∑(ŷ - ȳ)2. Det anger hur stor del av variationen i den beroende variabeln som din regressionsmodell förklarar.
Resterande summa av kvadrater Det är summan av de kvadrerade skillnaderna mellan de faktiska y-värdena och de förutspådda y-värdena. Det visar hur stor del av variationen i den beroende variabeln som modellen inte förklarar. Ju mindre residualkvadratsumman är jämfört med den totala kvadratiska summan, desto bättre stämmer regressionsmodellen överens med data.
5 saker du bör veta om LINEST-funktionen
För att effektivt kunna använda LINEST-formler i dina kalkylblad kan du vilja veta lite mer om funktionens "inre mekanik":
- Known_y's och known_x's I en enkel linjär regressionsmodell med endast en uppsättning x-variabler, known_y's och known_x's kan vara intervall av vilken form som helst så länge de har samma antal rader och kolumner. Om du gör en multipel regressionsanalys med mer än en uppsättning oberoende x variabler, known_y's måste vara en vektor, dvs. ett intervall med en rad eller en kolumn.
- Att tvinga konstanten till noll . När const är TRUE eller utelämnas, kommer a konstant (intercept) beräknas och inkluderas i ekvationen: y=bx + a. Om const sätts till FALSE, anses interceptet vara lika med 0 och utelämnas från regressionsekvationen: y=bx.
Inom statistiken har man i årtionden diskuterat huruvida det är meningsfullt att tvinga interceptkonstanten till 0 eller inte. Många trovärdiga regressionsanalytiker anser att om det verkar vara användbart att sätta interceptet till noll (const=FALSE) så är linjär regression i sig en felaktig modell för datamängden. Andra antar att konstanten kan tvingas till noll i vissa situationer, till exempel,I allmänhet rekommenderas att man i de flesta fall använder standardvärdet const=TRUE eller utelämnar det.
- Noggrannhet Noggrannheten hos den regressionsekvation som beräknas med LINEST-funktionen beror på spridningen av dina datapunkter. Ju mer linjära data, desto mer exakta resultat får du med LINEST-formeln.
- Redundanta x-värden . I vissa situationer kan en eller flera oberoende x variabler kan inte ha något ytterligare prediktivt värde, och att ta bort sådana variabler från regressionsmodellen påverkar inte noggrannheten hos de förutspådda y-värdena. Detta fenomen kallas "kollinearitet". Excel-funktionen LINEST kontrollerar om kollinearitet föreligger och utelämnar alla överflödiga variabler. x variabler som identifieras i modellen. De utelämnade variablerna x Variabler kan identifieras med 0 koefficienter och 0 standardfelvärden.
- LINEST vs. SLOPE och INTERCEPT Den underliggande algoritmen för LINEST-funktionen skiljer sig från den algoritm som används i SLOPE- och INTERCEPT-funktionerna. När källdata är obestämda eller kollinjära kan dessa funktioner därför ge olika resultat.
Excel LINEST-funktionen fungerar inte
Om din LINEST-formel ger upphov till ett fel eller producerar fel resultat är det troligt att det beror på någon av följande orsaker:
- Om LINEST-funktionen bara returnerar ett tal (lutningskoefficienten) har du troligen angett den som en vanlig formel, inte som en matrisformel. Tryck Ctrl + Shift + Enter för att slutföra formeln korrekt. När du gör detta omsluts formeln av {krusade parenteser} som syns i formellfältet.
- #REF! fel. Uppstår om known_x's och known_y's har olika dimensioner.
- #VALUE! fel. Uppstår om known_x's eller . known_y's innehåller minst en tom cell, ett textvärde eller en textrepresentation av ett tal som Excel inte känner igen som ett numeriskt värde. Felet #VALUE uppstår också om const eller . statistik argumentet kan inte utvärderas till TRUE eller FALSE.
Så här använder du LINEST i Excel för en enkel och multipel linjär regressionsanalys. Om du vill titta närmare på de formler som diskuteras i den här handledningen är du välkommen att ladda ner vår arbetsbok nedan. Tack för att du läste och hoppas att vi ses på vår blogg nästa vecka!
Arbetsbok för övning för nedladdning
Exempel på Excel LINEST-funktioner (.xlsx-fil)
