
Съдържание
В този урок се обяснява синтаксисът на функцията LINEST и се показва как да я използвате за извършване на линеен регресионен анализ в Excel.
Microsoft Excel не е статистическа програма, но разполага с редица статистически функции. Една от тези функции е LINEST, която е предназначена за извършване на линеен регресионен анализ и връщане на свързаните с него статистически данни. В този урок за начинаещи ще засегнем съвсем леко теорията и основните изчисления. Основният ни фокус ще бъде да ви предоставим формула, която просто работи иможе лесно да се персонализира за вашите данни.
Функция LINEST на Excel - синтаксис и основни приложения
Функцията LINEST изчислява статистиката за права линия, която обяснява връзката между независимата променлива и една или повече зависими променливи, и връща масив, описващ линията. най-малки квадрати Уравнението на линията е следното.
Уравнение на проста линейна регресия:
y = bx + aУравнение за множествена регресия:
y = b 1 x 1 + b 2 x 2 + ... + b n x n + aКъде:
- y - зависимата променлива, която се опитвате да прогнозирате.
- x - независимата променлива, която използвате, за да прогнозирате. y .
- a - пресечната точка (показва къде линията пресича оста Y).
- b - наклон (показва стръмността на регресионната линия, т.е. скоростта на изменение на y при промяна на x).
В основната си форма функцията LINEST връща интерцепцията (a) и наклона (b) за регресионното уравнение. По желание тя може да връща и допълнителни статистически данни за регресионния анализ, както е показано в този пример.
Синтаксис на функциите LINEST
Синтаксисът на функцията LINEST на Excel е следният:
LINEST(known_y's, [known_x's], [const], [stats])Къде:
- known_y's (задължително) е обхват на зависимата величина y -Обикновено това е една колона или един ред.
- known_x's (незадължително) е обхват на независимите стойности x. Ако не се посочи, се приема, че това е масивът {1,2,3,...} със същия размер като known_y's .
- const (незадължително) - логическа стойност, която определя начина, по който интерцепцията (константа) a ) трябва да се третират:
- Ако е TRUE или е пропусната, константата a се изчислява нормално.
- Ако е FALSE, константата a е принуден да бъде равен на 0, а наклонът ( b коефициент) се изчислява, за да съответства на y=bx.
- статистики (по избор) е логическа стойност, която определя дали да се извеждат допълнителни статистически данни или не:
- Ако е TRUE, функцията LINEST връща масив с допълнителни регресионни статистики.
- Ако е FALSE или е пропуснат, LINEST връща само константата на пресечната точка и коефициента(ите) на наклона.
Забележка: Тъй като LINEST връща масив от стойности, той трябва да бъде въведен като формула за масив чрез натискане на клавишната комбинация Ctrl + Shift + Enter. Ако бъде въведен като обикновена формула, се връща само първият коефициент на наклона.
Допълнителни статистически данни, връщани от LINEST
Сайтът статистики зададен като TRUE, инструктира функцията LINEST да върне следните статистически данни за вашия регресионен анализ:
| Статистика | Описание |
| Коефициент на наклона | b стойност в y = bx + a |
| Прехващаща константа | стойност в y = bx + a |
| Стандартна грешка на наклона | Стойност/и на стандартната грешка за коефициента(ите) b. |
| Стандартна грешка на интерцепцията | Стойността на стандартната грешка за константата a . |
| Коефициент на детерминация (R2) | Показва колко добре регресионното уравнение обяснява връзката между променливите. |
| Стандартна грешка за оценката на Y | Показва точността на регресионния анализ. |
| F-статистика или F-наблюдавана стойност | Той се използва за извършване на F-тест за нулевата хипотеза, за да се определи цялостната степен на пригодност на модела. |
| Степени на свобода (df) | Броят на степените на свобода. |
| Регресионна сума на квадратите | Показва каква част от вариацията на зависимата променлива се обяснява от модела. |
| Остатъчна сума на квадратите | Измерва размера на дисперсията в зависимата променлива, която не е обяснена от вашия регресионен модел. |
Картата по-долу показва реда, в който LINEST връща масив от статистически данни:

В последните три реда грешките #N/A ще се появят в третата и следващите колони, които не са попълнени с данни. Това е поведението по подразбиране на функцията LINEST, но ако искате да скриете обозначенията за грешки, обвийте формулата LINEST в IFERROR, както е показано в този пример.
Как да използвате LINEST в Excel - примери за формули
Функцията LINEST може да се окаже трудна за използване, особено за начинаещите, тъй като трябва не само да построите правилно формулата, но и да интерпретирате правилно резултата от нея. По-долу ще намерите няколко примера за използване на LINEST формули в Excel, които, надяваме се, ще ви помогнат да потънете в теоретичните знания :)
Проста линейна регресия: изчисляване на наклона и пресечната точка
За да получите пресечната точка и наклона на регресионна линия, използвайте функцията LINEST в нейната най-проста форма: задайте диапазон от зависими стойности за known_y's и диапазон от независими стойности за аргумента known_x's Последните два аргумента могат да бъдат зададени на TRUE или пропуснати.
Например, с y стойности (брой продажби) в C2:C13 и стойности x (разходи за реклама) в B2:B13, нашата формула за линейна регресия е проста:
=LINEST(C2:C13,B2:B13)
За да я въведете правилно в работния си лист, изберете две съседни клетки в един и същи ред, E2:F2 в този пример, въведете формулата и натиснете Ctrl + Shift + Enter, за да я завършите.
Формулата ще върне коефициента на наклона в първата клетка (E2) и константата на пресичането във втората клетка (F2):
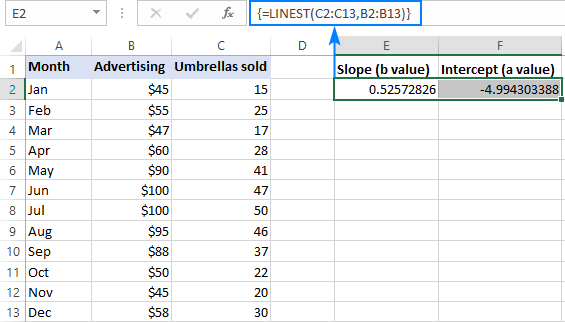
Сайтът наклон е приблизително 0,52 (закръглено до втория знак след десетичната запетая). Това означава, че когато x се увеличава с 1, y се увеличава с 0,52.
Сайтът Y-интерцепция е отрицателна -4,99. Това е очакваната стойност на y Когато x=0, това е стойността, при която регресионната линия пресича оста y. Ако се изобрази на графика, това е стойността, при която регресионната линия пресича оста y.
Поставете горните стойности в уравнението за проста линейна регресия и ще получите следната формула за прогнозиране на броя на продажбите въз основа на разходите за реклама:
y = 0,52*x - 4,99
Например, ако похарчите 50 долара за реклама, се очаква да продадете 21 чадъра:
0.52*50 - 4.99 = 21.01
Стойностите на наклона и пресечната точка могат да се получат и поотделно чрез използване на съответната функция или чрез влагане на формулата LINEST в INDEX:
Наклон
=SLOPE(C2:C13,B2:B13)
=INDEX(LINEST(C2:C13,B2:B13),1)
Прихващане
=ИНТЕРЦЕПЦИЯ(C2:C13,B2:B13)
=INDEX(LINEST(C2:C13,B2:B13),2)
Както е показано на снимката на екрана по-долу, и трите формули дават едни и същи резултати:

Множествена линейна регресия: наклон и прекъсване
В случай че имате две или повече независими променливи, не забравяйте да ги въведете в съседни колони и да предоставите целия диапазон на known_x's аргумент.
Например, с номера на продажбите ( y D2:D13, разходите за реклама (един набор от стойности x) в B2:B13 и средните месечни валежи (друг набор от стойности x) в x стойности) в C2:C13, използвайте тази формула:
=LINEST(D2:D13,B2:C13)
Тъй като формулата ще върне масив от 3 стойности (2 коефициента на наклона и константата на прекъсването), избираме три съседни клетки в един и същи ред, въвеждаме формулата и натискаме клавишната комбинация Ctrl + Shift + Enter.
Моля, обърнете внимание, че формулата за множествена регресия връща коефициенти на наклона в обратен ред на независимите променливи (отдясно наляво), т.е. b n , b n-1 , ..., b 2 , b 1 :
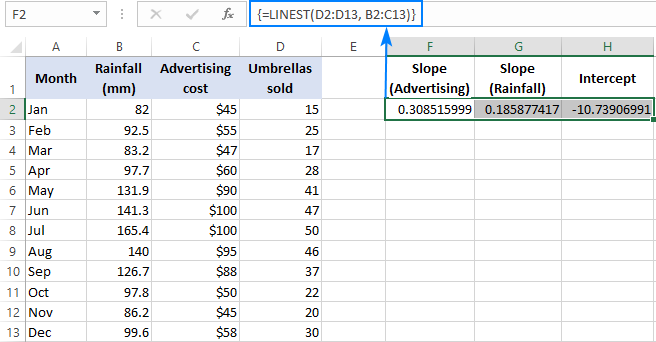
За да прогнозираме броя на продажбите, въвеждаме стойностите, получени от формулата LINEST, в уравнението за множествена регресия:
y = 0,3*x 2 + 0.19*x 1 - 10.74
Например при 50 долара, похарчени за реклама, и средни месечни валежи от 100 мм се очаква да продадете приблизително 23 чадъра:
0.3*50 + 0.19*100 - 10.74 = 23.26
Проста линейна регресия: прогнозиране на зависимата променлива
Освен изчисляването на a и b стойности за уравнението на регресията, функцията LINEST на Excel може също така да оцени зависимата променлива (y) въз основа на известната независима променлива (x). За тази цел използвате LINEST в комбинация с функцията SUM или SUMPRODUCT.
Например, ето как можете да изчислите броя на продажбите на чадъри за следващия месец, да речем октомври, въз основа на продажбите през предходните месеци и бюджета за реклама за октомври от 50 USD:
=SUM(LINEST(C2:C10, B2:B10)*{50,1})
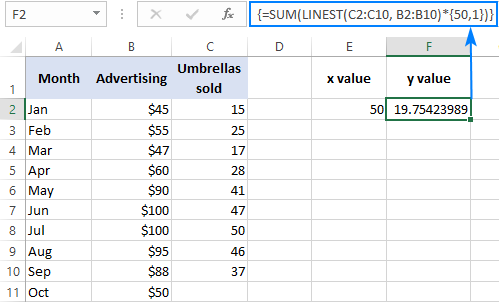
Вместо да кодирате твърдо x В този случай трябва да въведете и константата 1 в някоя клетка, тъй като не можете да смесвате референции и стойности в константа на масив.
С x стойност в E2 и константата 1 в F2, всяка от следните формули ще работи добре:
Обикновена формула (въвежда се с натискане на Enter ):
=SUMPRODUCT(LINEST(C2:C10, B2:B10)*(E2:F2))
Формула за масив (въвежда се с натискане на Ctrl + Shift + Enter ):
=SUM(LINEST(C2:C10, B2:B10)*(E2:F2))
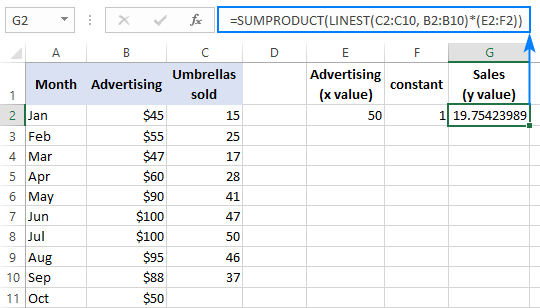
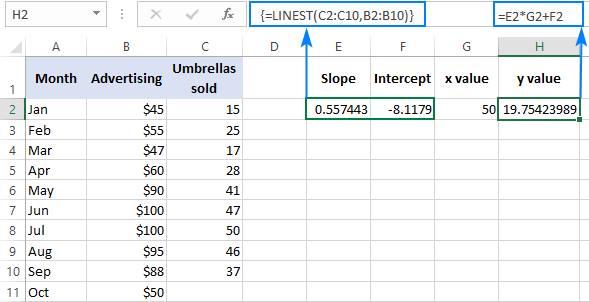
За да проверите резултата, можете да получите пресечната точка и наклона за същите данни и след това да използвате формулата за линейна регресия, за да изчислите y :
=E2*G2+F2
Където E2 е наклонът, G2 е x а F2 е пресечната точка:
Множествена регресия: прогнозиране на зависимата променлива
В случай че имате работа с няколко предиктора, т.е. няколко различни набора от x включва всички тези предиктори в масива като константа. Например, при бюджет за реклама от 50 USD (x 2 ) и средномесечни валежи от 100 mm (x 1 ), формулата е следната:
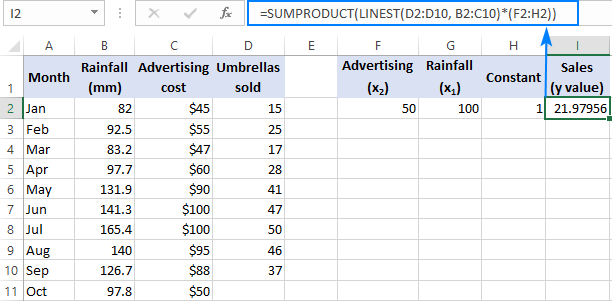
=SUM(LINEST(D2:D10, B2:C10)*{50,100,1})
Където D2:D10 са известните y и B2:C10 са два набора от x стойности:

Обърнете внимание на реда на x Както бе посочено по-рано, когато функцията LINEST на Excel се използва за множествена регресия, тя връща коефициентите на наклона отдясно наляво. В нашия пример Реклама първо се връща коефициентът, а след това Дъждове За да изчислите правилно прогнозирания брой продажби, трябва да умножите коефициентите по съответния x Затова поставяте елементите на константния масив в този ред: {50,100,1}. Последният елемент е 1, тъй като последната стойност, върната от LINEST, е прихващането, което не трябва да се променя, затова просто я умножавате по 1.
Вместо да използвате константа на масив, можете да въведете всички променливи x в някои клетки и да направите препратка към тези клетки във формулата си, както направихме в предишния пример.
Обикновена формула:
=SUMPRODUCT(LINEST(D2:D10, B2:C10)*(F2:H2))
Формула на масива:
=SUM(LINEST(D2:D10, B2:C10)*(F2:H2))
Където F2 и G2 са x и H2 е 1:
Формула LINEST: допълнителна регресионна статистика
Както може би си спомняте, за да получите повече статистически данни за регресионния си анализ, поставяте TRUE в последния аргумент на функцията LINEST. Приложена към нашите примерни данни, формулата придобива следната форма:
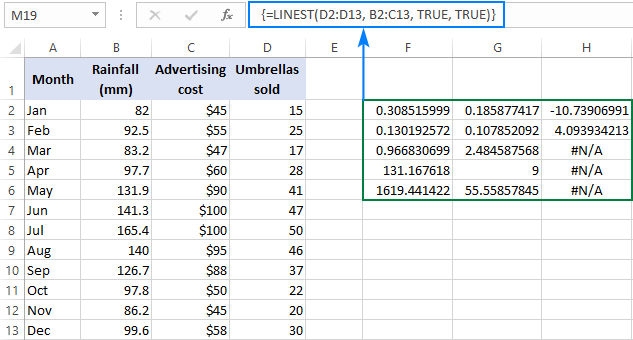
=LINEST(D2:D13, B2:C13, TRUE, TRUE)
Тъй като имаме 2 независими променливи в колони B и C, избираме гнездо, състоящо се от 3 реда (две стойности x + интерцепция) и 5 колони, въвеждаме горната формула, натискаме Ctrl + Shift + Enter , и получаваме този резултат:
За да се отървете от грешките #N/A, можете да вложите LINEST в IFERROR по следния начин:
=IFERROR(LINEST(D2:D13, B2:C13, TRUE, TRUE), "")
Снимката на екрана по-долу показва резултата и обяснява какво означава всяко число:

В предишните примери бяха обяснени коефициентите на наклона и пресечната точка Y, затова нека разгледаме набързо другите статистически данни.
Коефициент на детерминация (R2). стойността на R2 е резултат от разделянето на сумата на квадратите на регресията на общата сума на квадратите. тя ви показва колко y се обясняват с x В този пример R2 е приблизително 0,97, което означава, че 97% от нашите зависими променливи (продажби на чадъри) се обясняват от независимите променливи (реклама + средномесечни валежи), което е отлично съответствие!
Стандартни грешки . Като цяло тези стойности показват точността на регресионния анализ. Колкото по-малки са числата, толкова по-сигурни можете да бъдете за вашия регресионен модел.
Статистика F Използвате статистиката F, за да потвърдите или отхвърлите нулевата хипотеза. Препоръчва се статистиката F да се използва в комбинация със стойността P, когато се решава дали общите резултати са значими.
Степени на свобода (df). Функцията LINEST в Excel връща остатъчни степени на свобода , което е общо df минус регресия df Можете да използвате степените на свобода, за да получите F-критичните стойности в статистическа таблица, и след това да сравните F-критичните стойности с F-статистиката, за да определите доверително ниво за вашия модел.
Регресионна сума на квадратите (известен още като обяснена сума на квадратите , или сума на квадратите на модела ). това е сумата от квадратните разлики между предсказаните стойности на y и средната стойност на y, изчислена по тази формула: =∑(ŷ - ȳ)2. тя показва каква част от вариацията на зависимата променлива обяснява вашият регресионен модел.
Остатъчна сума на квадратите Това е сумата от квадратичните разлики между действителните стойности y и предсказаните стойности y. Тя показва каква част от вариацията на зависимата променлива не се обяснява от вашия модел. Колкото по-малка е остатъчната сума на квадратите в сравнение с общата сума на квадратите, толкова по-добре регресионният ви модел отговаря на данните.
5 неща, които трябва да знаете за функцията LINEST
За да използвате ефективно формулите LINEST в работните си листове, може да искате да научите малко повече за "вътрешната механика" на функцията:
- Known_y's и known_x's В прост линеен регресионен модел само с един набор от променливи x, known_y's и known_x's могат да бъдат диапазони с произволна форма, стига да имат еднакъв брой редове и колони. Ако правите множествен регресионен анализ с повече от един набор от независими x променливи, known_y's трябва да бъде вектор, т.е. обхват от един ред или една колона.
- Принуждаване на константата към нула . Когато const е TRUE или е пропуснат, аргументът a се изчислява константата (интерцепция) и се включва в уравнението: y=bx + a. Ако const се задава FALSE, се счита, че интерцепцията е равна на 0 и се изпуска от уравнението на регресията: y=bx.
В статистиката в продължение на десетилетия се спори дали има смисъл да се принуждава константата на интерцепцията да бъде равна на 0 или не. Много надеждни специалисти по регресионен анализ смятат, че ако задаването на интерцепцията на нула (const=FALSE) се окаже полезно, то самата линейна регресия е грешен модел за набора от данни. Други предполагат, че константата може да бъде принудена да бъде равна на нула в определени ситуации, например,Като цяло се препоръчва в повечето случаи да се използва стандартното const=TRUE или да се пропусне.
- Точност . точността на регресионното уравнение, изчислено с функцията LINEST, зависи от дисперсията на вашите точки с данни. колкото по-линейни са данните, толкова по-точни са резултатите от формулата LINEST.
- Излишни стойности x В някои ситуации един или повече независими x Променливите може да нямат допълнителна прогностична стойност и отстраняването на такива променливи от регресионния модел да не се отрази на точността на прогнозираните стойности y. Това явление е известно като "колинеарност". Функцията LINEST на Excel проверява за колинеарност и пропуска всички излишни променливи. x променливи, които идентифицира от модела. Пропуснатите x променливите могат да бъдат разпознати по 0 коефициента и 0 стойности на стандартната грешка.
- LINEST срещу SLOPE и INTERCEPT Алгоритъмът, залегнал в основата на функцията LINEST, се различава от алгоритъма, използван във функциите SLOPE и INTERCEPT. Поради това, когато изходните данни са неопределени или колинеарни, тези функции могат да върнат различни резултати.
Функцията LINEST на Excel не работи
Ако вашата формула LINEST хвърля грешка или дава грешен резултат, има вероятност това да се дължи на една от следните причини:
- Ако функцията LINEST връща само едно число (коефициент на наклона), най-вероятно сте я въвели като обикновена формула, а не като формула на масив. Не забравяйте да натиснете Ctrl + Shift + Enter, за да завършите правилно формулата. Когато направите това, формулата се затваря в {къдрави скоби}, които се виждат в лентата с формули.
- #REF! грешка. Възниква, ако known_x's и known_y's диапазоните имат различни размери.
- #VALUE! грешка. Настъпва, ако known_x's или known_y's съдържа поне една празна клетка, текстова стойност или текстово представяне на число, което Excel не разпознава като числова стойност. Също така грешката #VALUE възниква, ако const или статистики аргументът не може да бъде оценен като TRUE или FALSE.
Ето как се използва LINEST в Excel за прост и множествен линеен регресионен анализ. За да разгледате по-отблизо формулите, разгледани в този урок, можете да изтеглите нашата примерна работна книга по-долу. Благодаря ви, че прочетохте, и се надявам да се видим в нашия блог следващата седмица!
Практическа работна тетрадка за изтегляне
Примери за функции на Excel LINEST (.xlsx файл)
