
Sadržaj
Ovaj vodič objašnjava sintaksu funkcije LINEST i pokazuje kako je koristiti za analizu linearne regresije u Excelu.
Microsoft Excel nije statistički program, ali jest imaju brojne statističke funkcije. Jedna od takvih funkcija je LINEST, koja je dizajnirana za izvođenje linearne regresijske analize i vraćanje povezane statistike. U ovom vodiču za početnike samo ćemo se malo dotaknuti teorije i temeljnih izračuna. Naš glavni fokus bit će vam pružiti formulu koja jednostavno funkcionira i može se lako prilagoditi vašim podacima.
Funkcija Excel LINEST - sintaksa i osnovna upotreba
The Funkcija LINEST izračunava statistiku za ravnu liniju koja objašnjava odnos između nezavisne varijable i jedne ili više zavisnih varijabli te vraća niz koji opisuje liniju. Funkcija koristi metodu najmanjih kvadrata kako bi pronašla ono što najbolje odgovara vašim podacima. Jednadžba za liniju je sljedeća.
Jednostavna linearna regresijska jednadžba:
y = bx + aVišestruka regresijska jednadžba:
y = b 1x 1+ b 2x 2+ … + b nx n+ aGdje je:
- y - zavisna varijabla koju pokušavate predvidjeti.
- x - nezavisna varijabla koju koristite za predviđanje y .
- a - sjecište (pokazuje gdje linija siječe Y os).
- b - nagibznačajan.
Stupnjevi slobode (df). Funkcija LINEST u Excelu vraća rezidualne stupnjeve slobode , što je ukupni df minus regresija df . Možete koristiti stupnjeve slobode da dobijete F-kritične vrijednosti u statističkoj tablici, a zatim usporedite F-kritične vrijednosti s F statistikom kako biste odredili razinu pouzdanosti za svoj model.
Regresijski zbroj kvadrata (aka objašnjeni zbroj kvadrata ili model zbroja kvadrata ). To je zbroj kvadrata razlika između predviđenih y-vrijednosti i srednje vrijednosti y, izračunat ovom formulom: =∑(ŷ - ȳ)2. Označava koliki dio varijacije u ovisnoj varijabli objašnjava vaš regresijski model.
Rezidualni zbroj kvadrata . To je zbroj kvadrata razlika između stvarnih y-vrijednosti i predviđenih y-vrijednosti. Označava koliko varijacija u ovisnoj varijabli vaš model ne objašnjava. Što je rezidualni zbroj kvadrata manji u usporedbi s ukupnim zbrojem kvadrata, to bolje vaš regresijski model odgovara vašim podacima.
5 stvari koje biste trebali znati o funkciji LINEST
Za učinkovito korištenje formula LINEST u svoje radne listove, možda biste željeli saznati nešto više o "unutarnjoj mehanici" funkcije:
- Known_y's i known_x's . U jednostavnom modelu linearne regresije sa samo jednim skupom x varijabli, poznati_y i poznati_x mogu biti rasponi bilo kojeg oblika sve dok imaju isti broj redaka i stupaca. Ako radite višestruku regresijsku analizu s više od jednog skupa neovisnih x varijabli, poznati_y mora biti vektor, tj. raspon od jednog retka ili jednog stupca.
- Postavljanje konstante na nulu . Kada je argument const TRUE ili je izostavljen, a konstanta (odsječak) se izračunava i uključuje u jednadžbu: y=bx + a. Ako je const postavljeno na FALSE, presjek se smatra jednakim 0 i izostavlja se iz regresijske jednadžbe: y=bx.
U statistici se desetljećima raspravlja o tome ima li smisla konstantu presretanja prisiliti na 0 ili ne. Mnogi praktičari vjerodostojne regresijske analize vjeruju da ako se postavljanje presjeka na nulu (const=FALSE) čini korisnim, onda je linearna regresija sama po sebi pogrešan model za skup podataka. Drugi pretpostavljaju da se konstanta može prisiliti na nulu u određenim situacijama, na primjer, u kontekstu dizajna diskontinuiteta regresije. Općenito, preporučuje se koristiti zadanu vrijednost const=TRUE ili je u većini slučajeva izostaviti.
- Točnost . Točnost regresijske jednadžbe izračunate pomoću funkcije LINEST ovisi o disperziji vaših podatkovnih točaka. Što su podaci linearniji, točniji su rezultati formule LINEST.
- Suvišne x vrijednosti . U nekim situacijama,jedna ili više neovisnih x varijabli možda nemaju dodatnu prediktivnu vrijednost, a uklanjanje takvih varijabli iz regresijskog modela ne utječe na točnost predviđenih y vrijednosti. Ovaj fenomen je poznat kao "kolinearnost". Funkcija Excel LINEST provjerava kolinearnost i izostavlja sve suvišne x varijable koje identificira iz modela. Izostavljene x varijable mogu se prepoznati po 0 koeficijenata i 0 standardnih vrijednosti pogreške.
- LINEST vs. SLOPE i INTERCEPT . Temeljni algoritam funkcije LINEST razlikuje se od algoritma koji se koristi u funkcijama SLOPE i INTERCEPT. Stoga, kada su izvorni podaci neodređeni ili kolinearni, ove funkcije mogu vratiti različite rezultate.
Excel LINEST funkcija ne radi
Ako vaša LINEST formula daje pogrešku ili daje pogrešan izlaz , velika je vjerojatnost da je to zbog jednog od sljedećih razloga:
- Ako funkcija LINEST vraća samo jedan broj (koeficijent nagiba), najvjerojatnije ste ga unijeli kao običnu formulu, a ne kao formulu polja. Obavezno pritisnite Ctrl + Shift + Enter kako biste ispravno dovršili formulu. Kada to učinite, formula se zatvara u {vitičaste zagrade} koje su vidljive na traci formule.
- #REF! greška. Pojavljuje se ako rasponi poznati_x i poznati_y imaju različite dimenzije.
- #VRIJEDNOST! greška. Javlja se ako poznati_x ili poznati_y sadrži najmanje jednu praznu ćeliju, tekstualnu vrijednost ili tekstualni prikaz broja koji Excel ne prepoznaje kao numeričku vrijednost. Također, pogreška #VALUE pojavljuje se ako se argument const ili stats ne može procijeniti na TRUE ili FALSE.
Tako koristite LINEST u Excelu za jednostavna i višestruka linearna regresijska analiza. Da biste pobliže pogledali formule o kojima se govori u ovom vodiču, slobodno možete preuzeti naš primjer radne knjige u nastavku. Zahvaljujem vam na čitanju i nadam se da se vidimo na našem blogu sljedeći tjedan!
Radna bilježnica za vježbe za preuzimanje
Primjeri funkcija Excel LINEST (.xlsx datoteka)
(pokazuje strmost regresijske linije, tj. stopu promjene za y kako se x mijenja).
U svom osnovnom obliku, funkcija LINEST vraća odsjek (a) i nagib (b) za regresijsku jednadžbu. Po izboru, također može vratiti dodatne statistike za regresijsku analizu kao što je prikazano u ovom primjeru.
Sintaksa funkcije LINEST
Sintaksa funkcije LINEST programa Excel je sljedeća:
LINEST(poznati_y's , [poznati_x], [konst], [statistika])Gdje je:
- poznati_y (obavezno) raspon ovisnog y -vrijednosti u regresijskoj jednadžbi. Obično je to jedan stupac ili jedan redak.
- poznati_x (neobavezno) je raspon nezavisnih x-vrijednosti. Ako se izostavi, pretpostavlja se da je niz {1,2,3,...} iste veličine kao poznati_y .
- const (neobavezno) - logička vrijednost koja određuje kako se presretanje (konstanta a ) treba tretirati:
- Ako je TRUE ili izostavljeno, konstanta a izračunava se normalno.
- Ako je FALSE, konstanta a postavlja se na 0, a nagib ( b koeficijent) se izračunava tako da odgovara y=bx.
- statistika (neobavezno) je logička vrijednost koja određuje treba li ispisati dodatne statistike ili ne:
- Ako je TRUE, funkcija LINEST vraća niz s dodatnom regresijskom statistikom.
- Ako je FALSE ili izostavljen, LINEST vraća samo konstantu presjeka i nagibkoeficijent(i).
Napomena. Budući da LINEST vraća niz vrijednosti, mora se unijeti kao formula polja pritiskom na prečac Ctrl + Shift + Enter. Ako se unese kao redovita formula, vraća se samo prvi koeficijent nagiba.
Dodatna statistika koju vraća LINEST
Argument statistika postavljen na TRUE nalaže funkciji LINEST da vrati sljedeće statistike za vašu regresijsku analizu:
| Statistika | Opis |
| Koeficijent nagiba | b vrijednost u y = bx + a |
| Konstanta presjeka | vrijednost u y = bx + a |
| Standardna pogreška nagiba | Vrijednost(e) standardne pogreške za b koeficijent(i). |
| Standardna pogreška presjeka | Standardna pogreška vrijednosti za konstantu a . |
| Koeficijent determinacije (R2) | Pokazuje koliko dobro regresijska jednadžba objašnjava odnos među varijablama. |
| Standardna pogreška za procjenu Y | Pokazuje preciznost regresijske analize. |
| F statistika ili F-opažena vrijednost | Koristi se za izvođenje F-testa za nulta hipoteza za određivanje ukupne dobrote prilagodbe modela. |
| Stupnjevi fr eedom (df) | Broj stupnjeva slobode. |
| Regresijski zbroj kvadrata | Pokazuje koliko je varijacija uzavisna varijabla je objašnjena modelom. |
| Rezidualni zbroj kvadrata | Mjeri količinu varijance u zavisnoj varijabli koja nije objašnjena vašim regresijskim modelom. |
Mapa u nastavku prikazuje redoslijed kojim LINEST vraća niz statistika:

U zadnja tri retka, Pogreške #N/A pojavit će se u trećem i sljedećim stupcima koji nisu ispunjeni podacima. To je zadano ponašanje funkcije LINEST, ali ako želite sakriti oznake pogreške, zamotajte svoju formulu LINEST u IFERROR kao što je prikazano u ovom primjeru.
Kako koristiti LINEST u Excelu - primjeri formula
Funkcija LINEST može biti teška za korištenje, posebno za početnike, jer ne samo da biste trebali ispravno izgraditi formulu, već i pravilno interpretirati njezin izlaz. U nastavku ćete pronaći nekoliko primjera korištenja LINEST formula u Excelu koji će vam, nadamo se, pomoći da utopite teoretsko znanje :)
Jednostavna linearna regresija: izračunajte nagib i presjek
Da biste dobili presjek i nagib regresijske linije, koristite funkciju LINEST u njenom najjednostavnijem obliku: navedite raspon zavisnih vrijednosti za argument poznati_y i raspon nezavisnih vrijednosti za poznate_x argument. Posljednja dva argumenta mogu se postaviti na TRUE ili izostaviti.
Na primjer, s y vrijednostima (prodajni brojevi) u C2:C13 i x vrijednostima(trošak oglašavanja) u B2:B13, naša formula linearne regresije je jednostavna kao:
=LINEST(C2:C13,B2:B13)
Da biste je ispravno unijeli u svoj radni list, odaberite dvije susjedne ćelije u istom retku, E2: F2 u ovom primjeru upišite formulu i pritisnite Ctrl + Shift + Enter da biste je dovršili.
Formula će vratiti koeficijent nagiba u prvoj ćeliji (E2) i konstantu presjeka u drugoj ćeliji (F2 ):
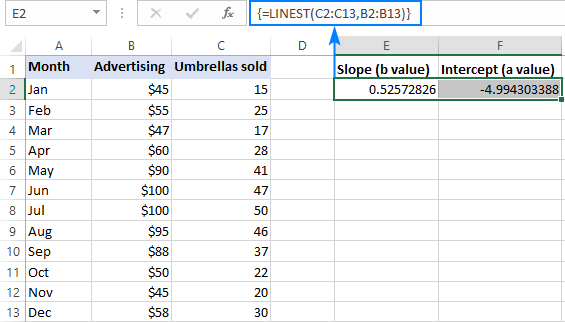
Nagib je približno 0,52 (zaokruženo na dvije decimale). To znači da kada x poraste za 1, y poraste za 0,52.
Y-odsječak je negativnih -4,99. To je očekivana vrijednost y kada je x=0. Ako se iscrta na grafikonu, to je vrijednost pri kojoj regresijska linija siječe y-os.
Unesite gornje vrijednosti u jednostavnu linearnu regresijsku jednadžbu i dobit ćete sljedeću formulu za predviđanje broja prodaje na temelju troškova oglašavanja:
y = 0.52*x - 4.99
Na primjer, ako potrošite 50 USD na oglašavanje, očekuje se da ćete prodati 21 kišobran:
0.52*50 - 4.99 = 21.01
Vrijednosti nagiba i presjeka također se mogu dobiti zasebno korištenjem odgovarajuće funkcije ili ugniježđivanjem formule LINEST u INDEX:
Nagib
=SLOPE(C2:C13,B2:B13)
=INDEX(LINEST(C2:C13,B2:B13),1)
Presretanje
=INTERCEPT(C2:C13,B2:B13)
=INDEX(LINEST(C2:C13,B2:B13),2)
Kao što je prikazano na slici ispod, sve tri formule daju iste rezultate:

Višestruka linearna regresija: nagib i presjek
U slučaju da imatedvije ili više neovisnih varijabli, svakako ih unesite u susjedne stupce i dostavite taj cijeli raspon argumentu poznati_x .
Na primjer, s brojevima prodaje ( y vrijednosti) u D2:D13, trošak oglašavanja (jedan skup x vrijednosti) u B2:B13 i prosječna mjesečna količina padalina (drugi skup x vrijednosti) u C2:C13, koristite ovu formulu:
=LINEST(D2:D13,B2:C13)
Budući da će formula vratiti niz od 3 vrijednosti (2 koeficijenta nagiba i konstanta presjeka), odabiremo tri uzastopne ćelije u istom retku, upisujemo formulu i pritisnemo Ctrl + Prečac Shift + Enter.
Imajte na umu da formula višestruke regresije vraća koeficijente nagiba obrnutim redoslijedom nezavisnih varijabli (s desna na lijevo), tj. je b n , b n-1 , …, b 2 , b 1 :
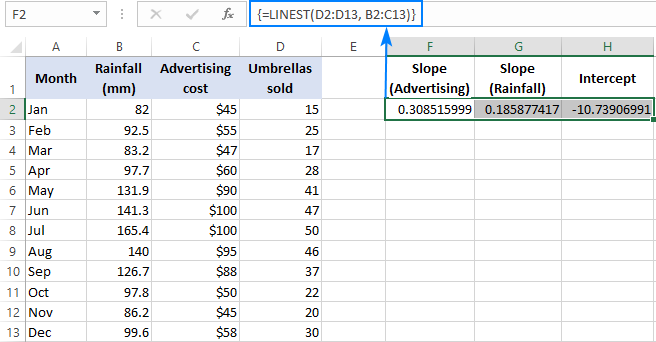
Da bismo predvidjeli broj prodaje, dostavljamo vrijednosti koje vraća formula LINEST u jednadžbu višestruke regresije:
y = 0,3*x 2 + 0,19*x 1 - 10,74
Na pr dovoljno, s 50 USD potrošenih na oglašavanje i prosječnom mjesečnom količinom padalina od 100 mm, očekuje se da ćete prodati približno 23 kišobrana:
0.3*50 + 0.19*100 - 10.74 = 23.26
Jednostavna linearna regresija: predvidite zavisnu varijablu
Osim izračuna vrijednosti a i b za regresijsku jednadžbu, funkcija Excel LINEST također može procijeniti zavisnu varijablu (y) na temelju poznate neovisnevarijabla (x). Za ovo koristite LINEST u kombinaciji s funkcijom SUM ili SUMPRODUCT.
Na primjer, evo kako možete izračunati broj rasprodaja kišobrana za sljedeći mjesec, recimo listopad, na temelju prodaje u prethodnim mjesecima i Proračun za oglašavanje u listopadu od 50 USD:
=SUM(LINEST(C2:C10, B2:B10)*{50,1})
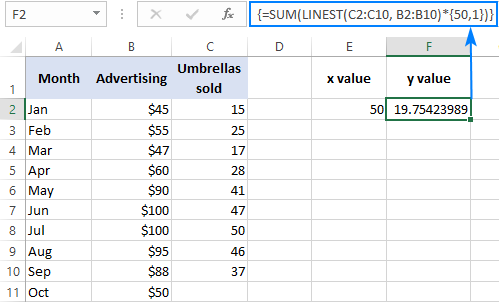
Umjesto tvrdog kodiranja vrijednosti x u formuli, možete je dati kao referenca ćelije. U ovom slučaju morate unijeti i konstantu 1 u neku ćeliju jer ne možete miješati reference i vrijednosti u konstanti polja.
S vrijednošću x u E2 i konstantom 1 u F2, bilo koja od donjih formula će biti dobra:
Regularna formula (unesena pritiskom na Enter ):
=SUMPRODUCT(LINEST(C2:C10, B2:B10)*(E2:F2))
Formula niza (unesena pritiskom na Ctrl + Shift + Unesite ):
=SUM(LINEST(C2:C10, B2:B10)*(E2:F2))
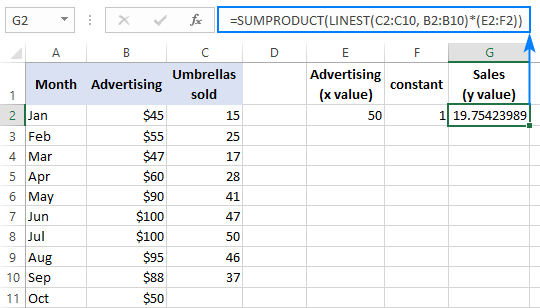
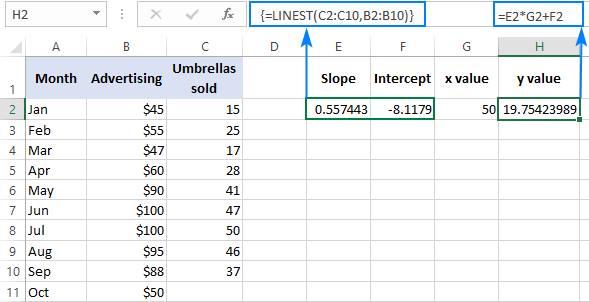
Da biste provjerili rezultat, možete dobiti presjek i nagib za iste podatke, a zatim upotrijebiti formulu linearne regresije za izračunaj y :
=E2*G2+F2
Gdje je E2 nagib, G2 vrijednost x , a F2 presjek:
Višestruka regresija: predvidite zavisnu varijablu
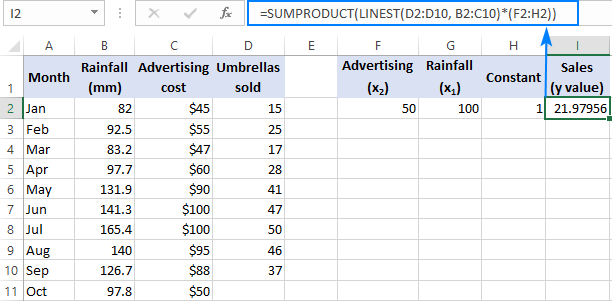
U slučaju da imate posla s nekoliko prediktora, tj. nekoliko različitih skupova x vrijednosti, uključite sve one prediktori u konstanti niza. Na primjer, s proračunom za oglašavanje od 50 USD (x 2 ) i prosječnom mjesečnom količinom padalina od 100 mm (x 1 ), formula ide ovakoslijedi:
=SUM(LINEST(D2:D10, B2:C10)*{50,100,1})
Gdje su D2:D10 poznate vrijednosti y i B2:C10 dva skupa vrijednosti x :

Molimo obratite pozornost na redoslijed vrijednosti x u konstanti polja. Kao što je ranije istaknuto, kada se funkcija Excel LINEST koristi za višestruku regresiju, vraća koeficijente nagiba s desna na lijevo. U našem primjeru prvo se vraća koeficijent Oglašavanje , a zatim koeficijent Kuša . Da biste točno izračunali predviđeni broj prodaje, trebate pomnožiti koeficijente s odgovarajućim x vrijednostima, tako da elemente konstante polja stavite ovim redoslijedom: {50,100,1}. Posljednji element je 1, jer je zadnja vrijednost koju vraća LINEST presretanje koje se ne bi trebalo mijenjati, tako da ga jednostavno pomnožite s 1.
Umjesto korištenja konstante polja, možete unijeti sve x varijable u nekim ćelijama i referencirajte te ćelije u svojoj formuli kao što smo učinili u prethodnom primjeru.
Regularna formula:
=SUMPRODUCT(LINEST(D2:D10, B2:C10)*(F2:H2))
Formula niza:
=SUM(LINEST(D2:D10, B2:C10)*(F2:H2))
Gdje su F2 i G2 vrijednosti x , a H2 je 1:
LINEST formula: dodatna regresijska statistika
Kao što se možda sjećate, da biste dobili više statistike za svoju regresijsku analizu, stavite TRUE u zadnji argument funkcije LINEST. Primijenjena na naše ogledne podatke, formula ima sljedeći oblik:
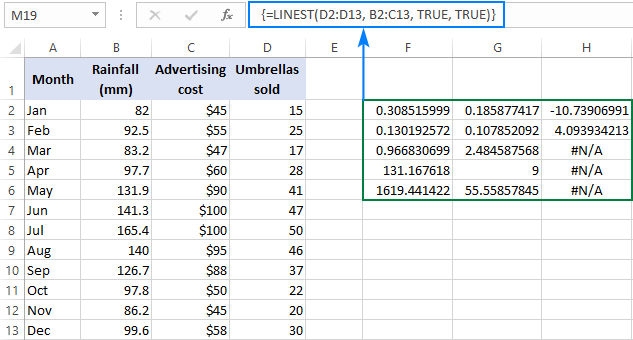
=LINEST(D2:D13, B2:C13, TRUE, TRUE)
Budući da imamo 2 neovisnavarijable u stupcima B i C, odabiremo bijes koji se sastoji od 3 retka (dvije vrijednosti x + presjekač) i 5 stupaca, unesite gornju formulu, pritisnite Ctrl + Shift + Enter i dobit ćete ovaj rezultat:
Da biste se riješili pogrešaka #N/A, možete ugnijezditi LINEST u IFERROR ovako:
=IFERROR(LINEST(D2:D13, B2:C13, TRUE, TRUE), "")
Snimka zaslona u nastavku pokazuje rezultat i objašnjava što svaki broj znači:

Koeficijenti nagiba i Y-odsječak objašnjeni su u prethodnim primjerima, pa pogledajmo na brzinu ostale statistike.
Koeficijent determinacije (R2). Vrijednost R2 rezultat je dijeljenja regresijskog zbroja kvadrata s ukupnim zbrojem kvadrata. Govori vam koliko je y vrijednosti objašnjeno x varijablama. To može biti bilo koji broj od 0 do 1, odnosno 0% do 100%. U ovom primjeru, R2 je približno 0,97, što znači da je 97% naših zavisnih varijabli (kišobran prodaja) objašnjeno nezavisnim varijablama (oglašavanje + prosječna mjesečna količina padalina), što je izvrsno uklapanje!
Standardne pogreške . Općenito, ove vrijednosti pokazuju preciznost regresijske analize. Što su brojevi manji, to možete biti sigurniji u svoj regresijski model.
F statistika . Koristite F statistiku za potporu ili odbacivanje nulte hipoteze. Preporuča se koristiti F statistiku u kombinaciji s P vrijednošću kada se odlučuje jesu li ukupni rezultati
