
Բովանդակություն
Այս ձեռնարկը բացատրում է LINEST ֆունկցիայի շարահյուսությունը և ցույց է տալիս, թե ինչպես օգտագործել այն Excel-ում գծային ռեգրեսիոն վերլուծություն կատարելու համար:
Microsoft Excel-ը վիճակագրական ծրագիր չէ, այնուամենայնիվ, այն ունեն մի շարք վիճակագրական գործառույթներ. Նման գործառույթներից մեկը LINEST-ն է, որը նախատեսված է գծային ռեգրեսիոն վերլուծություն կատարելու և առնչվող վիճակագրություն վերադարձնելու համար։ Սկսնակների համար նախատեսված այս ձեռնարկում մենք միայն թեթև կանդրադառնանք տեսությանը և հիմքում ընկած հաշվարկներին: Մեր հիմնական ուշադրությունը կլինի ձեզ բանաձևի տրամադրումը, որը պարզապես աշխատում է և կարող է հեշտությամբ հարմարեցվել ձեր տվյալների համար:
Excel LINEST ֆունկցիա - շարահյուսություն և հիմնական կիրառումներ
The LINEST ֆունկցիան հաշվարկում է ուղիղ գծի վիճակագրությունը, որը բացատրում է անկախ փոփոխականի և մեկ կամ մի քանի կախյալ փոփոխականների միջև կապը և վերադարձնում է գիծը նկարագրող զանգված: Ֆունկցիան օգտագործում է նվազագույն քառակուսիների մեթոդը՝ ձեր տվյալներին լավագույնս հարմարեցնելու համար: Գծի հավասարումը հետևյալն է.
Պարզ գծային ռեգրեսիոն հավասարում.
y = bx + aԲազմաթիվ ռեգրեսիոն հավասարում.
y = b 1x 1+ b 2x 2+ … + b nx n+ aՈրտեղ:
- y - կախյալ փոփոխականը, որը փորձում եք կանխատեսել:
- x - անկախ փոփոխականը, որն օգտագործում եք կանխատեսելու համար։ y .
- a - ընդհատումը (նշում է, թե որտեղ է ուղիղը հատում Y առանցքը):
- b - թեքությունընշանակալից.
Ազատության աստիճաններ (df). LINEST ֆունկցիան Excel-ում վերադարձնում է ազատության մնացորդային աստիճանը , որը ընդհանուր df հանած հետընթացը df է: Դուք կարող եք օգտագործել ազատության աստիճանները վիճակագրական աղյուսակում F-կրիտիկական արժեքներ ստանալու համար, այնուհետև համեմատել F-կրիտիկական արժեքները F վիճակագրության հետ՝ ձեր մոդելի վստահության մակարդակը որոշելու համար:
Ռեգրեսիոն գումար: քառակուսիների (նույնը` քառակուսիների բացատրված գումարը , կամ քառակուսիների մոդելային գումարը ): Այն կանխատեսված y արժեքների և y-ի միջինի քառակուսի տարբերությունների գումարն է՝ հաշվարկված այս բանաձևով՝ =∑(ŷ - ȳ)2։ Այն ցույց է տալիս, թե կախված փոփոխականի փոփոխության որքան մասն է բացատրում ձեր ռեգրեսիոն մոդելը:
Քառակուսիների մնացորդային գումարը : Դա իրական y արժեքների և կանխատեսված y արժեքների քառակուսի տարբերությունների գումարն է: Այն ցույց է տալիս, թե ձեր մոդելը կախված փոփոխականի տատանումների որքան չի բացատրում: Որքան փոքր է քառակուսիների մնացորդային գումարը՝ համեմատած քառակուսիների ընդհանուր գումարի հետ, այնքան ավելի լավ է ձեր ռեգրեսիոն մոդելը համապատասխանում ձեր տվյալներին:
5 բան, որ դուք պետք է իմանաք LINEST ֆունկցիայի մասին
LINEST բանաձևերը արդյունավետ օգտագործելու համար ձեր աշխատաթերթերը, գուցե ցանկանաք մի փոքր ավելին իմանալ ֆունկցիայի «ներքին մեխանիկայի» մասին՝
- Known_y's և known_x's : Պարզ գծային ռեգրեսիոն մոդելում՝ x փոփոխականների միայն մեկ հավաքածուով, known_y's և known_x-երը կարող են լինել ցանկացած ձևի միջակայք, քանի դեռ դրանք ունեն նույն թվով տողեր և սյունակներ: Եթե դուք կատարում եք բազմակի ռեգրեսիոն վերլուծություն մեկից ավելի անկախ x փոփոխականներով, known_y's -ը պետք է լինի վեկտոր, այսինքն՝ մեկ տողի կամ մեկ սյունակի միջակայք:
- Ստիպելով հաստատունը զրոյի : Երբ const արգումենտը ՃԻՇՏ է կամ բաց է թողնվում, a հաստատունը (հատվածը) հաշվարկվում է և ներառվում է հավասարման մեջ՝ y=bx + a: Եթե const -ը դրված է FALSE-ի, ապա կտրվածքը համարվում է հավասար 0-ի և դուրս է գրվել ռեգրեսիայի հավասարումից՝ y=bx:
Վիճակագրության մեջ տասնամյակներ շարունակ քննարկվում է, թե արդյոք իմաստ ունի՞ ստիպել ընդհատման հաստատունը 0-ի, թե՞ ոչ: Շատ վստահելի ռեգրեսիոն վերլուծողներ կարծում են, որ եթե զրոյի սահմանումը (const=FALSE) օգտակար է թվում, ապա գծային ռեգրեսիան ինքնին սխալ մոդել է տվյալների հավաքածուի համար: Մյուսները ենթադրում են, որ հաստատունը կարող է զրոյացվել որոշակի իրավիճակներում, օրինակ, ռեգրեսիոն անջրպետի նախագծման համատեքստում: Ընդհանուր առմամբ, խորհուրդ է տրվում գնալ լռելյայն const=TRUE կամ շատ դեպքերում բաց թողնված:
- Ճշգրտություն : LINEST ֆունկցիայի կողմից հաշվարկված ռեգրեսիայի հավասարման ճշգրտությունը կախված է ձեր տվյալների կետերի ցրվածությունից: Որքան գծային են տվյալները, այնքան ավելի ճշգրիտ են LINEST բանաձևի արդյունքները:
- Ավելորդ x արժեքներ : Որոշ իրավիճակներում,Մեկ կամ մի քանի անկախ x փոփոխականներ կարող են չունենալ լրացուցիչ կանխատեսող արժեք, և նման փոփոխականների հեռացումը ռեգրեսիոն մոդելից չի ազդում կանխատեսված y արժեքների ճշգրտության վրա: Այս երևույթը հայտնի է որպես «կոլայնություն»։ Excel LINEST ֆունկցիան ստուգում է համակողմանիությունը և բաց թողնում ցանկացած ավելորդ x փոփոխականներ, որոնք նա նույնացնում է մոդելից: Բաց թողնված x փոփոխականները կարող են ճանաչվել 0 գործակիցով և 0 ստանդարտ սխալի արժեքներով:
- LINEST ընդդեմ SLOPE և INTERCEPT : LINEST ֆունկցիայի հիմքում ընկած ալգորիթմը տարբերվում է SLOPE և INTERCEPT ֆունկցիաներում օգտագործվող ալգորիթմից: Հետևաբար, երբ աղբյուրի տվյալները որոշված չեն կամ համակողմանի են, այս գործառույթները կարող են տարբեր արդյունքներ տալ:
Excel LINEST ֆունկցիան չի աշխատում
Եթե ձեր LINEST բանաձևը սխալ է թույլ տալիս կամ տալիս է սխալ արդյունք: , հավանականությունը մեծ է հետևյալ պատճառներից մեկի պատճառով.
- Եթե LINEST ֆունկցիան վերադարձնում է ընդամենը մեկ թիվ (թեքության գործակից), ամենայն հավանականությամբ այն մուտքագրել եք որպես սովորական բանաձև, այլ ոչ թե զանգվածի բանաձև։ Համոզվեք, որ սեղմեք Ctrl + Shift + Enter բանաձևը ճիշտ ավարտելու համար: Երբ դուք դա անում եք, բանաձևը կցվում է {գանգուր փակագծերում}, որոնք տեսանելի են բանաձևերի տողում:
- #REF! սխալ. Առաջանում է, եթե known_x-ի և known_y-ի միջակայքերը տարբեր չափեր ունեն:
- #VALUE! սխալ. Առաջանում է, եթե known_x-ի կամ known_y-ը պարունակում է առնվազն մեկ դատարկ բջիջ, տեքստային արժեք կամ տեքստային ներկայացում մի թվի, որը Excel-ը չի ճանաչում որպես թվային արժեք: Բացի այդ, #VALUE սխալն առաջանում է, եթե const կամ stats արգումենտը չի կարող գնահատվել TRUE կամ FALSE:
Այդպես եք օգտագործում LINEST-ը Excel-ում: պարզ և բազմակի գծային ռեգրեսիոն վերլուծություն: Այս ձեռնարկում քննարկված բանաձևերին ավելի մոտիկից ծանոթանալու համար կարող եք ներբեռնել ստորև բերված մեր օրինակելի աշխատանքային գիրքը: Ես շնորհակալություն եմ հայտնում կարդալու համար և հուսով եմ, որ հաջորդ շաբաթ կտեսնենք ձեզ մեր բլոգում:
Վերբեռնեք աշխատանքային գրքույկը
Excel LINEST ֆունկցիայի օրինակներ (.xlsx ֆայլ)
(ցույց է տալիս ռեգրեսիոն գծի կտրուկությունը, այսինքն՝ y-ի փոփոխության արագությունը, երբ x-ը փոխվում է):
Իր հիմնական ձևով LINEST ֆունկցիան վերադարձնում է կտրվածքը (a) և թեքությունը (b) ռեգրեսիայի հավասարման համար։ Ընտրովի, այն կարող է նաև վերադարձնել լրացուցիչ վիճակագրություն ռեգրեսիայի վերլուծության համար, ինչպես ցույց է տրված այս օրինակում:
LINEST ֆունկցիայի շարահյուսություն
Excel LINEST ֆունկցիայի շարահյուսությունը հետևյալն է.
LINEST(known_y's , [known_x's], [const], [stats])Որտեղ.
- known_y-ները (պահանջվում է) կախված y միջակայքն է: - արժեքները ռեգրեսիայի հավասարման մեջ: Սովորաբար դա մեկ սյունակ է կամ մեկ տող:
- known_x-ը (ըստ ցանկության) անկախ x-արժեքների տիրույթ է: Եթե բաց թողնվի, ապա ենթադրվում է, որ այն նույն չափի {1,2,3,...} զանգվածն է, ինչ known_y-ի :
- const (ըստ ցանկության) - տրամաբանական արժեք, որը որոշում է, թե ինչպես պետք է վերաբերվել ընդհատմանը (հաստատուն a ).
- Եթե FALSE է, ապա a հաստատունը պետք է դառնա 0, իսկ թեքությունը ( b գործակից) հաշվարկվում է համապատասխանելու y=bx:
Ծանոթագրություն. Քանի որ LINEST-ը վերադարձնում է արժեքների զանգված, այն պետք է մուտքագրվի որպես զանգվածի բանաձև՝ սեղմելով Ctrl + Shift + Enter դյուրանցումը: Եթե այն մուտքագրվում է որպես կանոնավոր բանաձեւ, ապա վերադարձվում է միայն առաջին թեքության գործակիցը:
LINEST-ի կողմից վերադարձված հավելյալ վիճակագրություն
stats արգումենտը, որը սահմանված է TRUE, հրահանգում է LINEST ֆունկցիային վերադարձնել հետևյալ վիճակագրությունը ձեր ռեգրեսիոն վերլուծության համար.
| Վիճակագրություն | Նկարագրություն |
| Թեքության գործակից | b արժեքը y = bx + a |
| Ընդհատվող հաստատուն | մի արժեքը y = bx + a |
| Թեքության ստանդարտ սխալ | Ստանդարտ սխալի արժեք(ներ)ը b գործակից(ներ): |
| Ընդհատման ստանդարտ սխալ | Ստանդարտ սխալի արժեքը a հաստատունի համար: |
| Որոշման գործակից (R2) | Ցույց է տալիս, թե որքանով է ռեգրեսիոն հավասարումը բացատրում փոխհարաբերությունները փոփոխականների միջև: |
| Ստանդարտ սխալ Y գնահատման համար | Ցույց է տալիս ռեգրեսիոն վերլուծության ճշգրտությունը: |
| F վիճակագրություն կամ F-դիտարկված արժեքը | Այն օգտագործվում է F-թեստը կատարելու համար զրոյական հիպոթեզ՝ մոդելի համապատասխանության ընդհանուր լավությունը որոշելու համար: |
| F աստիճաններ eedom (df) | Ազատության աստիճանների թիվը: |
| Քառակուսիների ռեգրեսիոն գումար | Ցույց է տալիս, թե որքան է տատանումներըկախյալ փոփոխականը բացատրվում է մոդելով: |
| Քառակուսիների մնացորդային գումարը | Չափում է կախված փոփոխականի շեղումների քանակը, որը չի բացատրվում ձեր ռեգրեսիոն մոդելով: |
Ստորև բերված քարտեզը ցույց է տալիս հերթականությունը, որով LINEST-ը վերադարձնում է վիճակագրության զանգված.

Վերջին երեք տողերում՝ #N/A սխալները կհայտնվեն երրորդ և հաջորդ սյունակներում, որոնք լրացված չեն տվյալներով: Դա LINEST ֆունկցիայի լռելյայն վարքագիծն է, բայց եթե ցանկանում եք թաքցնել սխալի նշումները, ձեր LINEST բանաձևը փաթեթավորեք IFERROR-ի մեջ, ինչպես ցույց է տրված այս օրինակում:
Ինչպես օգտագործել LINEST-ը Excel-ում - բանաձևերի օրինակներ
LINEST ֆունկցիան կարող է բարդ լինել հատկապես նորեկների համար, քանի որ դուք պետք է ոչ միայն ճիշտ ձևակերպեք բանաձևը, այլև ճիշտ մեկնաբանեք դրա արդյունքը: Ստորև դուք կգտնեք Excel-ում LINEST բանաձևերի օգտագործման մի քանի օրինակներ, որոնք, հուսով ենք, կօգնեն խորացնել տեսական գիտելիքները :)
Պարզ գծային ռեգրեսիա. հաշվարկեք թեքությունը և ընդհատումը
Ընդհատումը ստանալու համար և ռեգրեսիոն գծի թեքության վրա, դուք օգտագործում եք LINEST ֆունկցիան իր ամենապարզ ձևով. տրամադրեք կախված արժեքների մի շարք known_y-ի արգումենտի համար և անկախ արժեքների միջակայք known_x-ի<2-ի համար:> փաստարկ. Վերջին երկու արգումենտները կարող են սահմանվել TRUE կամ բաց թողնել:
Օրինակ, y արժեքներով (վաճառքի համարներ) C2:C13 և x արժեքներով:(գովազդի արժեքը) B2:B13-ում, մեր գծային ռեգրեսիայի բանաձևը նույնքան պարզ է, որքան.
=LINEST(C2:C13,B2:B13)
Այն ճիշտ մուտքագրելու համար ձեր աշխատաթերթում ընտրեք երկու հարակից բջիջներ նույն շարքում, E2: F2 այս օրինակում, մուտքագրեք բանաձևը և սեղմեք Ctrl + Shift + Enter՝ այն ավարտելու համար:
Բանաձևը կվերադարձնի թեքության գործակիցը առաջին բջիջում (E2) և ընդհատման հաստատունը երկրորդ բջիջում (F2): ):
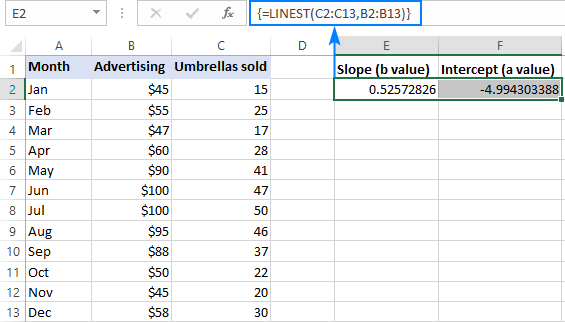
թեքությունը մոտավորապես 0,52 է (կլորացվում է երկու տասնորդական թվերի): Դա նշանակում է, որ երբ x մեծանում է 1-ով, y մեծանում է 0,52-ով:
Y-հատումը բացասական է -4,99: Դա y -ի ակնկալվող արժեքն է, երբ x=0: Եթե գծագրված է գրաֆիկի վրա, դա այն արժեքն է, որով ռեգրեսիոն գիծը հատում է y առանցքը:
Տրամադրեք վերը նշված արժեքները պարզ գծային ռեգրեսիայի հավասարմանը, և դուք կստանաք հետևյալ բանաձևը՝ վաճառքի թիվը կանխատեսելու համար: Գովազդի արժեքի հիման վրա՝
y = 0.52*x - 4.99
Օրինակ, եթե դուք 50 դոլար եք ծախսում գովազդի վրա, սպասվում է, որ կվաճառեք 21 հովանոց՝
0.52*50 - 4.99 = 21.01
Թեքության և հատման արժեքները կարելի է ստանալ նաև առանձին՝ օգտագործելով համապատասխան ֆունկցիան կամ LINEST բանաձևը INDEX-ում տեղադրելով.
Slope
=SLOPE(C2:C13,B2:B13)
=INDEX(LINEST(C2:C13,B2:B13),1)
Intercept
=INTERCEPT(C2:C13,B2:B13)
=INDEX(LINEST(C2:C13,B2:B13),2)
Ինչպես ցույց է տրված ստորև ներկայացված սքրինշոթում, բոլոր երեք բանաձևերը տալիս են նույն արդյունքները. 3>

Բազմակի գծային ռեգրեսիա. թեքություն և հատում
Եթե ունեքերկու կամ ավելի անկախ փոփոխականներ, համոզվեք, որ դրանք մուտքագրեք հարևան սյունակներում և տրամադրեք այդ ամբողջ միջակայքը known_x-ի արգումենտին:
Օրինակ, վաճառքի համարներով ( y արժեքներ) D2:D13-ում, գովազդի արժեքը (x արժեքների մեկ հավաքածու) B2:B13-ում և միջին ամսական տեղումներ ( x արժեքների մեկ այլ հավաքածու) C2:C13-ում, դուք օգտագործում եք այս բանաձևը.
=LINEST(D2:D13,B2:C13)
Քանի որ բանաձևը պատրաստվում է վերադարձնել 3 արժեքների զանգված (2 թեքության գործակից և ընդհատման հաստատուն), մենք ընտրում ենք երեք հարակից բջիջներ նույն շարքում, մուտքագրում ենք բանաձևը և սեղմում Ctrl + Shift + Enter դյուրանցում:
Խնդրում ենք նկատի ունենալ, որ բազմակի ռեգրեսիայի բանաձևը վերադարձնում է թեքության գործակիցները անկախ փոփոխականների հակառակ կարգով (աջից ձախ), որ է b n , b n-1 , …, b 2 , բ 1 :
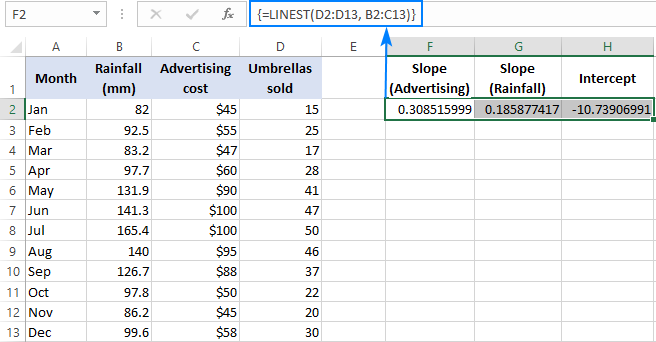
Վաճառքի թիվը կանխատեսելու համար մենք տրամադրում ենք LINEST բանաձևով վերադարձված արժեքները բազմակի ռեգրեսիայի հավասարմանը.
y = 0.3*x 2 + 0.19*x 1 - 10,74
Նախ մեծ քանակությամբ, գովազդի վրա ծախսված $50-ով և 100 մմ միջին ամսական տեղումներով, դուք կվաճառեք մոտավորապես 23 հովանոց.
0.3*50 + 0.19*100 - 10.74 = 23.26
Պարզ գծային ռեգրեսիա. կանխատեսել կախված փոփոխականը
Բացի ռեգրեսիայի հավասարման համար a և b արժեքները հաշվարկելուց, Excel LINEST ֆունկցիան կարող է նաև գնահատել կախված փոփոխականը (y)` հիմնվելով հայտնի անկախության վրա:փոփոխական (x): Դրա համար դուք օգտագործում եք LINEST-ը SUM կամ SUMPRODUCT ֆունկցիայի հետ համատեղ:
Օրինակ, ահա թե ինչպես կարող եք հաշվարկել հովանոցների վաճառքի քանակը հաջորդ ամսվա համար, ասենք հոկտեմբեր, նախորդ ամիսների վաճառքների հիման վրա և հոկտեմբեր ամսվա գովազդային բյուջեն $50 է.
=SUM(LINEST(C2:C10, B2:B10)*{50,1})
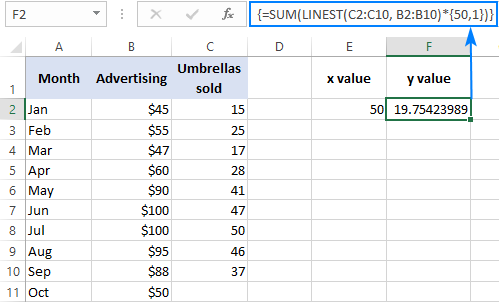
Բանաձևում x արժեքը կոշտ կոդավորելու փոխարեն, կարող եք այն տրամադրել որպես բջջային հղում. Այս դեպքում, դուք նույնպես պետք է որոշ բջիջում մուտքագրեք 1 հաստատունը, քանի որ չեք կարող հղումներն ու արժեքները խառնել զանգվածի հաստատունում:
E2-ում x արժեքով և 1 դյույմ հաստատունով: F2, ստորև բերված բանաձևերից որևէ մեկը կգործի.
Կանոնավոր բանաձև (մուտքագրվում է Enter սեղմելով):
=SUMPRODUCT(LINEST(C2:C10, B2:B10)*(E2:F2))
Զանգվածի բանաձև (մուտքագրվում է Ctrl + Shift + սեղմելով: Մուտքագրեք):
=SUM(LINEST(C2:C10, B2:B10)*(E2:F2))
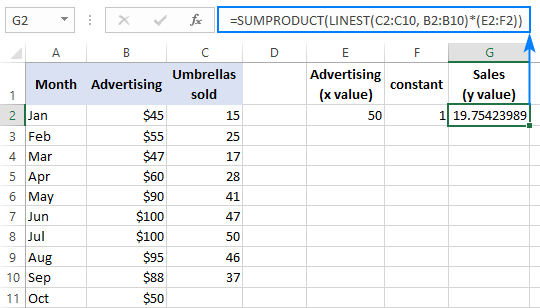
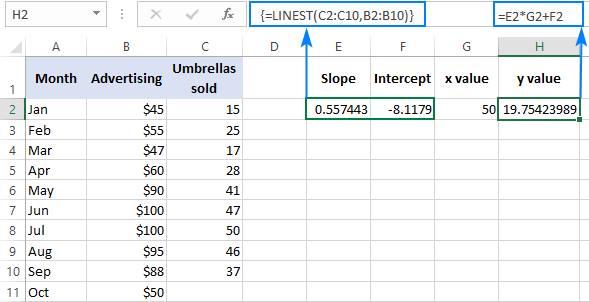
Արդյունքը ստուգելու համար կարող եք ստանալ նույն տվյալների կտրումը և թեքությունը, այնուհետև օգտագործել գծային ռեգրեսիայի բանաձևը հաշվարկեք y :
=E2*G2+F2
Որտեղ E2-ը թեքությունն է, G2-ը x արժեքն է, իսկ F2-ը հատումն է՝
Բազմակի ռեգրեսիա. կանխատեսել կախված փոփոխականը
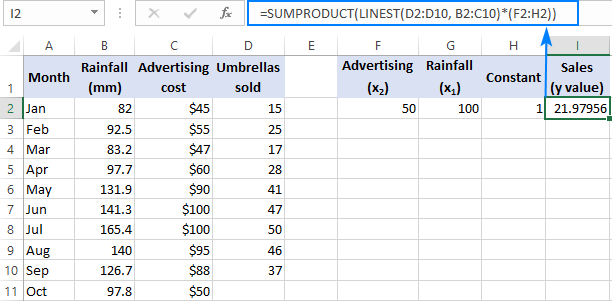
Այն դեպքում, երբ գործ ունեք մի քանի կանխատեսիչների, այսինքն x արժեքների մի քանի տարբեր խմբերի հետ, ներառեք բոլորը կանխատեսիչներ զանգվածի հաստատունում: Օրինակ՝ $50 (x 2 ) գովազդի բյուջեով և 100 մմ միջին ամսական տեղումներով (x 1 ), բանաձևը հետևյալն է.Հետևում է.
=SUM(LINEST(D2:D10, B2:C10)*{50,100,1})
Որտեղ D2:D10-ը հայտնի y արժեքներն են, իսկ B2:C10-ը x արժեքների երկու հավաքածու են.

Խնդրում ենք ուշադրություն դարձնել զանգվածի հաստատունում x արժեքների հերթականությանը: Ինչպես նշվեց ավելի վաղ, երբ Excel LINEST ֆունկցիան օգտագործվում է բազմակի ռեգրեսիա կատարելու համար, այն վերադարձնում է թեքության գործակիցները աջից ձախ: Մեր օրինակում սկզբում վերադարձվում է Գովազդի գործակիցը, իսկ հետո Անձրևի գործակիցը։ Վաճառքի կանխատեսված թիվը ճիշտ հաշվարկելու համար անհրաժեշտ է գործակիցները բազմապատկել համապատասխան x արժեքներով, այնպես որ զանգվածի հաստատունի տարրերը տեղադրեք հետևյալ հաջորդականությամբ՝ {50,100,1}։ Վերջին տարրը 1-ն է, քանի որ LINEST-ի վերադարձած վերջին արժեքն այն հատվածն է, որը չպետք է փոխվի, այնպես որ դուք պարզապես այն բազմապատկեք 1-ով:
Զանգվածի հաստատուն օգտագործելու փոխարեն կարող եք մուտքագրել բոլոր x փոփոխականները: որոշ բջիջներում և հղում կատարել ձեր բանաձևի այդ բջիջներին, ինչպես մենք արեցինք նախորդ օրինակում:
Կանոնավոր բանաձև՝
=SUMPRODUCT(LINEST(D2:D10, B2:C10)*(F2:H2))
Զանգվածի բանաձև՝
=SUM(LINEST(D2:D10, B2:C10)*(F2:H2))
Որտեղ F2-ը և G2-ը x արժեքներն են, իսկ H2-ը՝ 1:
LINEST բանաձև. լրացուցիչ ռեգրեսիայի վիճակագրություն
Ինչպես հիշում եք, ձեր ռեգրեսիոն վերլուծության համար ավելի շատ վիճակագրություն ստանալու համար LINEST ֆունկցիայի վերջին արգումենտում դնում եք TRUE: Կիրառելով մեր ընտրանքային տվյալներին՝ բանաձևը ստանում է հետևյալ ձևը.
=LINEST(D2:D13, B2:C13, TRUE, TRUE)
Քանի որ մենք ունենք 2 անկախB և C սյունակների փոփոխականները, մենք ընտրում ենք կատաղություն, որը բաղկացած է 3 տողից (երկու x արժեք + ընդհատում) և 5 սյունակ, մուտքագրում ենք վերը նշված բանաձևը, սեղմում ենք Ctrl + Shift + Enter և ստանում ենք այս արդյունքը.
<. 33>
#N/A սխալներից ազատվելու համար դուք կարող եք LINEST-ը տեղադրել IFERROR-ում այսպես.
=IFERROR(LINEST(D2:D13, B2:C13, TRUE, TRUE), "")
Սքրինշոթը ցույց է տալիս արդյունքը և բացատրում, թե ինչն է Յուրաքանչյուր թիվ նշանակում է՝

Թեքության գործակիցները և Y-հատումը բացատրվել են նախորդ օրինակներում, ուստի եկեք արագ նայենք մյուս վիճակագրությանը:
Որոշման գործակից (R2): R2-ի արժեքը քառակուսիների ռեգրեսիոն գումարը քառակուսիների ընդհանուր գումարի վրա բաժանելու արդյունք է։ Այն ցույց է տալիս, թե քանի y արժեքներ են բացատրվում x փոփոխականներով: Դա կարող է լինել ցանկացած թիվ 0-ից 1, այսինքն՝ 0%-ից 100%: Այս օրինակում R2-ը մոտավորապես 0,97 է, ինչը նշանակում է, որ մեր կախյալ փոփոխականների 97%-ը (հովանոցների վաճառք) բացատրվում են անկախ փոփոխականներով (գովազդ + միջին ամսական տեղումներ), ինչը հիանալի տեղավորվում է:
Ստանդարտ սխալներ : Ընդհանուր առմամբ, այս արժեքները ցույց են տալիս ռեգրեսիոն վերլուծության ճշգրտությունը: Որքան փոքր են թվերը, այնքան ավելի վստահ կարող եք լինել ձեր ռեգրեսիայի մոդելի վերաբերյալ:
F վիճակագրություն : Դուք օգտագործում եք F վիճակագրությունը՝ զրոյական վարկածը հաստատելու կամ մերժելու համար: Խորհուրդ է տրվում օգտագործել F վիճակագրությունը P արժեքի հետ համատեղ, երբ որոշում կայացվի, թե արդյոք ընդհանուր արդյունքները կան
