
Სარჩევი
ეს სახელმძღვანელო განმარტავს LINEST ფუნქციის სინტაქსს და გვიჩვენებს, თუ როგორ გამოვიყენოთ იგი Excel-ში ხაზოვანი რეგრესიის ანალიზის გასაკეთებლად.
Microsoft Excel არ არის სტატისტიკური პროგრამა, თუმცა, ის ასეა. აქვს მთელი რიგი სტატისტიკური ფუნქცია. ერთ-ერთი ასეთი ფუნქციაა LINEST, რომელიც შექმნილია ხაზოვანი რეგრესიის ანალიზისა და დაკავშირებული სტატისტიკის დასაბრუნებლად. დამწყებთათვის ამ გაკვეთილში ჩვენ მხოლოდ მსუბუქად შევეხებით თეორიას და ძირითად გამოთვლებს. ჩვენი მთავარი აქცენტი გაკეთდება იმაზე, რომ მოგაწოდოთ ფორმულა, რომელიც უბრალოდ მუშაობს და ადვილად მორგებულია თქვენს მონაცემებზე.
Excel LINEST ფუნქცია - სინტაქსი და ძირითადი გამოყენება
LINEST ფუნქცია ითვლის სტატისტიკას სწორი ხაზისთვის, რომელიც ხსნის ურთიერთობას დამოუკიდებელ ცვლადსა და ერთ ან რამდენიმე დამოკიდებულ ცვლადს შორის და აბრუნებს ხაზის აღწერის მასივს. ფუნქცია იყენებს უმცირესი კვადრატების მეთოდს თქვენი მონაცემებისთვის საუკეთესო მორგების მოსაძებნად. წრფის განტოლება ასეთია.
მარტივი წრფივი რეგრესიის განტოლება:
y = bx + aმრავლობითი რეგრესიის განტოლება:
y = b 1x 1+ b 2x 2+ … + b nx n+ aსად:
- y - დამოკიდებული ცვლადი, რომლის პროგნოზირებასაც ცდილობთ.
- x - დამოუკიდებელი ცვლადი, რომელსაც იყენებთ პროგნოზირებისთვის. y .
- a - კვეთა (მიუთითებს სად კვეთს ხაზი Y ღერძს).
- b - დახრილობამნიშვნელოვანი.
თავისუფლების ხარისხი (დფ). Excel-ში LINEST ფუნქცია აბრუნებს თავისუფლების ნარჩენ ხარისხს , რაც არის სულ df გამოკლებული რეგრესია df . თქვენ შეგიძლიათ გამოიყენოთ თავისუფლების ხარისხი სტატისტიკურ ცხრილში F-კრიტიკული მნიშვნელობების მისაღებად, შემდეგ კი შეადაროთ F-კრიტიკული მნიშვნელობები F სტატისტიკას თქვენი მოდელის ნდობის დონის დასადგენად.
რეგრესიის ჯამი. კვადრატების (აგრეთვე კვადრატების ახსნილი ჯამი , ან კვადრატების ჯამის მოდელი ). ეს არის კვადრატული განსხვავებების ჯამი პროგნოზირებულ y-მნიშვნელობებსა და y-ის საშუალოს შორის, გამოითვლება ამ ფორმულით: =∑(ŷ - ȳ)2. ის მიუთითებს, თუ რამდენ ცვალებადობას ხსნის თქვენი რეგრესიის მოდელი.
კვადრატების ნარჩენი ჯამი . ეს არის კვადრატული განსხვავებების ჯამი რეალურ y-სა და პროგნოზირებულ y-მნიშვნელობებს შორის. ის მიუთითებს იმაზე, თუ რამდენ ცვალებადობას არ ხსნის თქვენი მოდელი. რაც უფრო მცირეა კვადრატების ნარჩენი ჯამი კვადრატების ჯამთან შედარებით, მით უფრო კარგად ერგება თქვენი რეგრესიის მოდელი თქვენს მონაცემებს.
5 რამ, რაც უნდა იცოდეთ LINEST ფუნქციის შესახებ
LINEST ფორმულების ეფექტურად გამოყენებისთვის თქვენს სამუშაო ფურცლებზე, შეიძლება გინდოდეთ ცოტა მეტი იცოდეთ ფუნქციის "შინაგანი მექანიკის" შესახებ:
- Nnown_y's და known_x's . მარტივი წრფივი რეგრესიის მოდელში x ცვლადების მხოლოდ ერთი ნაკრებით, known_y's და known_x's შეიძლება იყოს ნებისმიერი ფორმის დიაპაზონი, თუ მათ აქვთ იგივე რაოდენობის რიგები და სვეტები. თუ თქვენ აკეთებთ მრავალჯერადი რეგრესიის ანალიზს დამოუკიდებელი x ცვლადების ერთზე მეტი ნაკრებით, known_y's უნდა იყოს ვექტორი, ანუ ერთი მწკრივის ან ერთი სვეტის დიაპაზონი.
- მუდმივის იძულება ნულამდე . როდესაც const არგუმენტი არის TRUE ან გამოტოვებულია, a მუდმივი (კვეთა) გამოითვლება და შედის განტოლებაში: y=bx + a. თუ const დაყენებულია FALSE-ზე, შუალედი ჩაითვლება 0-ის ტოლად და გამოტოვებულია რეგრესიის განტოლებიდან: y=bx.
სტატისტიკაში ათწლეულების მანძილზე მსჯელობდნენ იმაზე, აქვს თუ არა აზრი 0-ზე გადაკვეთის მუდმივის იძულებას, თუ არა. ბევრი სანდო რეგრესიული ანალიზის პრაქტიკოსი თვლის, რომ თუ კვეთის ნულზე დაყენება (const=FALSE) სასარგებლოა, მაშინ წრფივი რეგრესია თავისთავად არასწორი მოდელია მონაცემთა ნაკრებისთვის. სხვები ვარაუდობენ, რომ მუდმივი შეიძლება აიძულოს ნულოვანი იყოს გარკვეულ სიტუაციებში, მაგალითად, რეგრესიის შეწყვეტის დიზაინის კონტექსტში. ზოგადად, რეკომენდებულია ნაგულისხმევი const=TRUE-ით გადასვლა ან უმეტეს შემთხვევაში გამოტოვებული.
- Accuracy . LINEST ფუნქციით გამოთვლილი რეგრესიის განტოლების სიზუსტე დამოკიდებულია თქვენი მონაცემთა წერტილების დისპერსიაზე. რაც უფრო წრფივია მონაცემები, მით უფრო ზუსტი იქნება LINEST ფორმულის შედეგები.
- ზედმეტი x მნიშვნელობები . ზოგიერთ სიტუაციაში,ერთ ან მეტ დამოუკიდებელ x ცვლადს შეიძლება არ ჰქონდეს დამატებითი პროგნოზირებადი მნიშვნელობა და ასეთი ცვლადების ამოღება რეგრესიის მოდელიდან არ იმოქმედებს y პროგნოზირებული მნიშვნელობების სიზუსტეზე. ეს ფენომენი ცნობილია როგორც "კოლინარულობა". Excel LINEST ფუნქცია ამოწმებს კოლინარობას და გამოტოვებს ნებისმიერ ზედმეტ x ცვლადებს, რომლებსაც ის განსაზღვრავს მოდელიდან. გამოტოვებული x ცვლადები შეიძლება ამოიცნონ 0 კოეფიციენტით და 0 სტანდარტული შეცდომის მნიშვნელობებით.
- LINEST vs. SLOPE და INTERCEPT . LINEST ფუნქციის ძირითადი ალგორითმი განსხვავდება SLOPE და INTERCEPT ფუნქციებში გამოყენებული ალგორითმისგან. ამიტომ, როდესაც წყაროს მონაცემები განუსაზღვრელია ან თანამიმდევრული, ამ ფუნქციებმა შეიძლება დააბრუნოს სხვადასხვა შედეგები.
Excel LINEST ფუნქცია არ მუშაობს
თუ თქვენი LINEST ფორმულა გამოუშვებს შეცდომას ან გამოსცემს არასწორ გამომავალს. , დიდი ალბათობაა, რომ ეს არის ერთ-ერთი შემდეგი მიზეზის გამო:
- თუ LINEST ფუნქცია აბრუნებს მხოლოდ ერთ რიცხვს (დახრის კოეფიციენტს), დიდი ალბათობით თქვენ შეიტანეთ ის როგორც ჩვეულებრივი ფორმულა და არა მასივის ფორმულა. დარწმუნდით, რომ დააჭირეთ Ctrl + Shift + Enter ფორმულის სწორად დასასრულებლად. როდესაც ამას აკეთებთ, ფორმულა ჩასმულია {curly ფრჩხილებში}, რომლებიც ჩანს ფორმულების ზოლში.
- #REF! შეცდომა. ჩნდება, თუ known_x-ის და known_y-ის დიაპაზონებს განსხვავებული ზომები აქვთ.
- #VALUE! შეცდომა. ჩნდება, თუ known_x-ის ან known_y's შეიცავს მინიმუმ ერთ ცარიელ უჯრედს, ტექსტურ მნიშვნელობას ან ტექსტის წარმოდგენას იმ რიცხვისა, რომელსაც Excel არ ცნობს ციფრულ მნიშვნელობად. ასევე, #VALUE შეცდომა ჩნდება, თუ const ან stats არგუმენტი არ შეიძლება შეფასდეს TRUE ან FALSE.
ასე იყენებთ LINEST-ს Excel-ში მარტივი და მრავალჯერადი წრფივი რეგრესიის ანალიზი. ამ სახელმძღვანელოში განხილული ფორმულების უფრო დეტალურად დასათვალიერებლად, შეგიძლიათ ჩამოტვირთოთ ჩვენი სამუშაო წიგნის ნიმუში ქვემოთ. მადლობას გიხდით, რომ წაიკითხეთ და იმედი მაქვს, რომ მომავალ კვირას გნახავთ ჩვენს ბლოგზე!
ივარჯიშეთ სამუშაო წიგნი ჩამოსატვირთად
Excel LINEST ფუნქციის მაგალითები (ფაილი .xlsx)
(მიუთითებს რეგრესიის ხაზის ციცაბოობას, ე.ი. y-ის ცვლილების სიხშირეს, როგორც x იცვლება).
მის ძირითად ფორმაში, LINEST ფუნქცია აბრუნებს კვეთას (a) და დახრილობას (b) რეგრესიის განტოლებისთვის. სურვილისამებრ, მას ასევე შეუძლია დააბრუნოს დამატებითი სტატისტიკა რეგრესიის ანალიზისთვის, როგორც ეს ნაჩვენებია ამ მაგალითში.
LINEST ფუნქციის სინტაქსი
Excel LINEST ფუნქციის სინტაქსი ასეთია:
LINEST(known_y's , [known_x's], [const], [stats])სად:
- known_y's (აუცილებელია) არის დამოკიდებული y დიაპაზონი -მნიშვნელობები რეგრესიის განტოლებაში. ჩვეულებრივ, ეს არის ერთი სვეტი ან ერთი მწკრივი.
- known_x's (სურვილისამებრ) არის დამოუკიდებელი x-მნიშვნელობების დიაპაზონი. თუ გამოტოვებულია, ვარაუდობენ, რომ არის მასივი {1,2,3,...} იგივე ზომის, როგორც known_y's .
- const (სურვილისამებრ) - ლოგიკური მნიშვნელობა, რომელიც განსაზღვრავს, თუ როგორ უნდა განიხილებოდეს კვეთა (მუდმივი a ):
- თუ TRUE ან გამოტოვებულია, მუდმივი a გამოითვლება ნორმალურად.
- თუ FALSE, მუდმივი a აიძულება 0-მდე და დახრილობა ( b კოეფიციენტი) გამოითვლება რათა მოერგოს y=bx.
- stats (სურვილისამებრ) არის ლოგიკური მნიშვნელობა, რომელიც განსაზღვრავს დამატებითი სტატისტიკის გამოტანა თუ არა:
- თუ TRUE, LINEST ფუნქცია აბრუნებს მასივს დამატებითი რეგრესიის სტატისტიკით.
- FALSE ან გამოტოვებული, LINEST აბრუნებს მხოლოდ კვეთის მუდმივობას და დახრილობასკოეფიციენტ(ებ)ი.
შენიშვნა. ვინაიდან LINEST აბრუნებს მნიშვნელობების მასივს, ის უნდა იყოს შეყვანილი, როგორც მასივის ფორმულა Ctrl + Shift + Enter მალსახმობის დაჭერით. თუ ის შეყვანილია როგორც ჩვეულებრივი ფორმულა, ბრუნდება მხოლოდ პირველი დახრილობის კოეფიციენტი.
LINEST-ის მიერ დაბრუნებული დამატებითი სტატისტიკა
არგუმენტი stats დაყენებულია TRUE-ზე, ავალებს LINEST ფუნქციას დააბრუნოს შემდეგი სტატისტიკა თქვენი რეგრესიის ანალიზისთვის:
| სტატისტიკა | აღწერა |
| დახრის კოეფიციენტი | b მნიშვნელობა y = bx + a |
| გადაკვეთის მუდმივი | მნიშვნელობა y = bx + a |
| დახრის სტანდარტული შეცდომა | სტანდარტული შეცდომის მნიშვნელობა(ებ)ისთვის b კოეფიციენტ(ებ)ი. |
| ჩაჭრის სტანდარტული შეცდომა | სტანდარტული შეცდომის მნიშვნელობა a მუდმივისთვის. |
| დეტერმინაციის კოეფიციენტი (R2) | მიუთითებს რამდენად კარგად ხსნის რეგრესიის განტოლება ცვლადებს შორის ურთიერთობას. |
| სტანდარტული შეცდომა Y შეფასებისთვის | გვიჩვენებს რეგრესიის ანალიზის სიზუსტეს. |
| F სტატისტიკა, ან F-დაკვირვებული მნიშვნელობა | იგი გამოიყენება F-ტესტის გასაკეთებლად ნულოვანი ჰიპოთეზა მოდელის მორგების საერთო სიკეთის დასადგენად. |
| ფრის ხარისხები eedom (df) | თავისუფლების გრადუსების რაოდენობა. |
| კვადრატების რეგრესიული ჯამი | მიუთითებს რამდენ ცვალებადობას შეიცავსდამოკიდებული ცვლადი აიხსნება მოდელით. |
| კვადრატების ნარჩენი ჯამი | ზომავს დამოკიდებულ ცვლადში დისპერსიის რაოდენობას, რომელიც არ არის ახსნილი თქვენი რეგრესიის მოდელით. |
ქვემოთ მოცემულ რუკაზე ნაჩვენებია თანმიმდევრობა, რომლითაც LINEST აბრუნებს სტატისტიკის მასივს:

ბოლო სამ რიგში, #N/A შეცდომები გამოჩნდება მესამე და მომდევნო სვეტებში, რომლებიც არ არის შევსებული მონაცემებით. ეს არის LINEST ფუნქციის ნაგულისხმევი ქცევა, მაგრამ თუ გსურთ შეცდომის აღნიშვნების დამალვა, გადაიტანეთ თქვენი LINEST ფორმულა IFERROR-ში, როგორც ეს ნაჩვენებია ამ მაგალითში.
როგორ გამოვიყენოთ LINEST Excel-ში - ფორმულის მაგალითები
LINEST ფუნქციის გამოყენება შეიძლება რთული იყოს, განსაკუთრებით დამწყებთათვის, რადგან თქვენ არა მხოლოდ უნდა ააწყოთ ფორმულა სწორად, არამედ სწორად ინტერპრეტაციაც გააკეთოთ მისი გამომავალი. ქვემოთ ნახავთ LINEST ფორმულების გამოყენების რამდენიმე მაგალითს Excel-ში, რომლებიც, იმედია, დაგეხმარებათ თეორიული ცოდნის ჩაძირვაში :)
მარტივი წრფივი რეგრესია: გამოთვალეთ დახრილობა და კვეთა
გადაკვეთის მისაღებად და რეგრესიის ხაზის ფერდობზე, თქვენ იყენებთ LINEST ფუნქციას მისი უმარტივესი ფორმით: მიაწოდეთ დამოკიდებული მნიშვნელობების დიაპაზონი known_y-ის არგუმენტისთვის და დამოუკიდებელი მნიშვნელობების დიაპაზონი known_x-ისთვის არგუმენტი. ბოლო ორი არგუმენტი შეიძლება დაყენდეს TRUE-ზე ან გამოტოვდეს.
მაგალითად, y მნიშვნელობებით (გაყიდვის ნომრები) C2:C13 და x მნიშვნელობებში(რეკლამის ღირებულება) B2:B13-ში, ჩვენი წრფივი რეგრესიის ფორმულა ისეთივე მარტივია, როგორც:
=LINEST(C2:C13,B2:B13)
თქვენს სამუშაო ფურცელში სწორად შესაყვანად, აირჩიეთ ორი მიმდებარე უჯრედი იმავე მწკრივში, E2: F2 ამ მაგალითში, ჩაწერეთ ფორმულა და დააჭირეთ Ctrl + Shift + Enter მის დასასრულებლად.
ფორმულა დააბრუნებს დახრის კოეფიციენტს პირველ უჯრედში (E2) და კვეთის მუდმივას მეორე უჯრედში (F2). ):
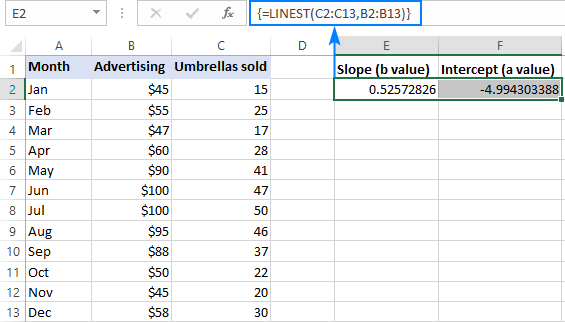
დახრილობა არის დაახლოებით 0,52 (დამრგვალებულია ორ ათწილადამდე). ეს ნიშნავს, რომ როდესაც x იზრდება 1-ით, y იზრდება 0,52-ით.
Y-კვეთა არის უარყოფითი -4,99. ეს არის y მოსალოდნელი მნიშვნელობა, როდესაც x=0. თუ გრაფიკზე გამოსახულია, ეს არის მნიშვნელობა, რომლის დროსაც რეგრესიის ხაზი კვეთს y-ღერძს.
მიიტანეთ ზემოთ ჩამოთვლილი მნიშვნელობები მარტივი წრფივი რეგრესიის განტოლებაში და მიიღებთ შემდეგ ფორმულას გაყიდვების რიცხვის პროგნოზირებისთვის. სარეკლამო ღირებულების მიხედვით:
y = 0.52*x - 4.99
მაგალითად, თუ დახარჯავთ $50 რეკლამაში, თქვენ უნდა გაყიდოთ 21 ქოლგა:
0.52*50 - 4.99 = 21.01
დახრილობისა და კვეთის მნიშვნელობების მიღება ასევე შესაძლებელია ცალ-ცალკე შესაბამისი ფუნქციის გამოყენებით ან LINEST ფორმულის INDEX-ში ჩასმით:
Slope
=SLOPE(C2:C13,B2:B13)
=INDEX(LINEST(C2:C13,B2:B13),1)
Intercept
=INTERCEPT(C2:C13,B2:B13)
=INDEX(LINEST(C2:C13,B2:B13),2)
როგორც ნაჩვენებია ქვემოთ მოცემულ ეკრანის სურათზე, სამივე ფორმულა იძლევა ერთსა და იმავე შედეგს:

მრავალჯერადი წრფივი რეგრესია: დახრილობა და კვეთა
თუ გაქვთორი ან მეტი დამოუკიდებელი ცვლადი, აუცილებლად შეიყვანეთ ისინი მიმდებარე სვეტებში და მიაწოდეთ მთელი დიაპაზონი known_x-ის არგუმენტს.
მაგალითად, გაყიდვების ნომრებით ( y მნიშვნელობები) D2:D13-ში, რეკლამის ღირებულება (x მნიშვნელობების ერთი ნაკრები) B2:B13-ში და საშუალო თვიური ნალექი ( x მნიშვნელობების სხვა ნაკრები) C2:C13-ში, თქვენ იყენებთ ამ ფორმულას:
=LINEST(D2:D13,B2:C13)
რადგან ფორმულა აპირებს დააბრუნოს 3 მნიშვნელობის მასივი (2 დახრილობის კოეფიციენტი და კვეთის მუდმივი), ჩვენ ვირჩევთ სამ მიმდებარე უჯრედს იმავე რიგში, შევიყვანთ ფორმულას და დააჭირეთ Ctrl + Shift + Enter მალსახმობი.
გთხოვთ, გაითვალისწინოთ, რომ მრავალჯერადი რეგრესიის ფორმულა აბრუნებს დახრის კოეფიციენტებს დამოუკიდებელი ცვლადების საპირისპირო მიმდევრობით (მარჯვნიდან მარცხნივ), რომ არის b n , b n-1 , …, b 2 , b 1 :
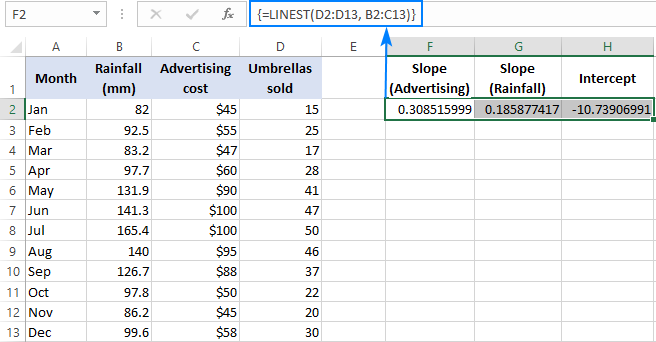
გაყიდვების ნომრის პროგნოზირებისთვის, ჩვენ ვაწვდით LINEST ფორმულით დაბრუნებულ მნიშვნელობებს მრავალჯერადი რეგრესიის განტოლებას:
y = 0.3*x 2 + 0.19*x 1 - 10.74
მაგ დიდი რაოდენობით, რეკლამაზე დახარჯული $50 და საშუალო თვიური ნალექით 100 მმ, მოსალოდნელია გაყიდოთ დაახლოებით 23 ქოლგა:
0.3*50 + 0.19*100 - 10.74 = 23.26
მარტივი წრფივი რეგრესია: პროგნოზირება დამოკიდებული ცვლადი
გარდა რეგრესიის განტოლებისთვის a და b მნიშვნელობების გაანგარიშებისა, Excel LINEST ფუნქციას ასევე შეუძლია შეაფასოს დამოკიდებული ცვლადი (y) ცნობილი დამოუკიდებელის საფუძველზე.ცვლადი (x). ამისთვის იყენებთ LINEST-ს SUM ან SUMPRODUCT ფუნქციასთან ერთად.
მაგალითად, აი, როგორ შეგიძლიათ გამოთვალოთ ქოლგის გაყიდვების რაოდენობა მომდევნო თვისთვის, ვთქვათ ოქტომბერში, წინა თვეების გაყიდვებზე დაყრდნობით და ოქტომბრის სარეკლამო ბიუჯეტი $50:
=SUM(LINEST(C2:C10, B2:B10)*{50,1})
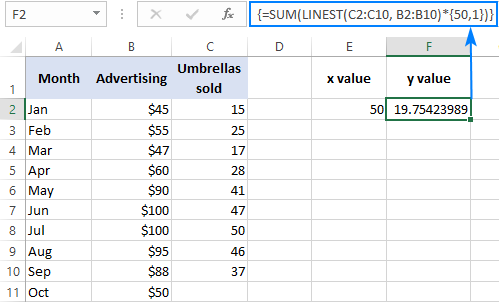
ფორმულაში x მნიშვნელობის მყარი კოდირების ნაცვლად, შეგიძლიათ მიაწოდოთ ის როგორც უჯრედის მითითება. ამ შემთხვევაში, თქვენ ასევე უნდა შეიყვანოთ 1 მუდმივი ზოგიერთ უჯრედში, რადგან თქვენ არ შეგიძლიათ აურიოთ მითითებები და მნიშვნელობები მასივის მუდმივში.
x მნიშვნელობით E2-ში და მუდმივი 1 in-ით. F2, ქვემოთ ჩამოთვლილი ფორმულებიდან რომელიმე იმუშავებს:
ჩვეულებრივი ფორმულა (შეყვანილია Enter-ზე დაჭერით):
=SUMPRODUCT(LINEST(C2:C10, B2:B10)*(E2:F2))
მასივის ფორმულა (შეყვანილია Ctrl + Shift + დაჭერით შეიყვანეთ ):
=SUM(LINEST(C2:C10, B2:B10)*(E2:F2))
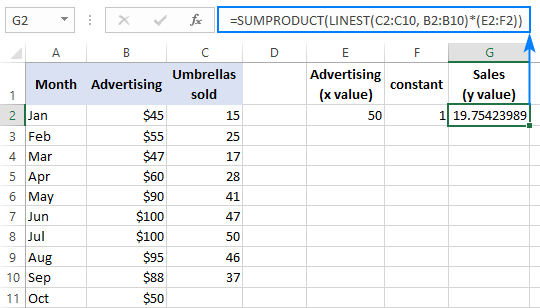
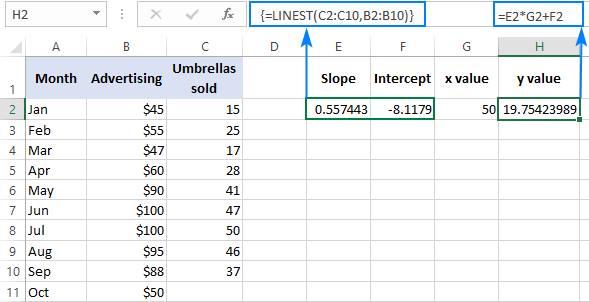
შედეგის გადასამოწმებლად, შეგიძლიათ მიიღოთ კვეთა და დახრილობა იმავე მონაცემებისთვის, შემდეგ კი გამოიყენოთ ხაზოვანი რეგრესიის ფორმულა. გამოთვალეთ y :
=E2*G2+F2
სადაც E2 არის დახრილობა, G2 არის x მნიშვნელობა და F2 არის კვეთა:
მრავალჯერადი რეგრესია: იწინასწარმეტყველეთ დამოკიდებული ცვლადი
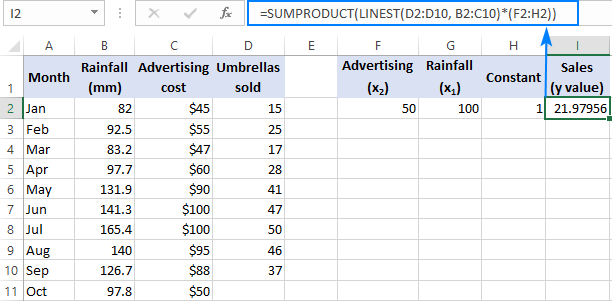
თუ საქმე გაქვთ რამდენიმე პროგნოზირთან, ანუ x მნიშვნელობების რამდენიმე სხვადასხვა კომპლექტთან, ჩართეთ ყველა ეს პროგნოზები მასივის მუდმივში. მაგალითად, სარეკლამო ბიუჯეტით $50 (x 2 ) და საშუალო თვიური ნალექით 100 მმ (x 1 ), ფორმულა ასე გამოიყურება.შემდეგნაირად:
=SUM(LINEST(D2:D10, B2:C10)*{50,100,1})
სადაც D2:D10 არის ცნობილი y მნიშვნელობები და B2:C10 არის x მნიშვნელობების ორი ნაკრები:

გთხოვთ, ყურადღება მიაქციოთ x მნიშვნელობების თანმიმდევრობას მასივის მუდმივში. როგორც უკვე აღვნიშნეთ, როდესაც Excel LINEST ფუნქცია გამოიყენება მრავალჯერადი რეგრესიის გასაკეთებლად, ის აბრუნებს დახრილობის კოეფიციენტებს მარჯვნიდან მარცხნივ. ჩვენს მაგალითში ჯერ დაბრუნდა რეკლამის კოეფიციენტი, შემდეგ კი ნალექის კოეფიციენტი. პროგნოზირებული გაყიდვების რიცხვის სწორად გამოსათვლელად, თქვენ უნდა გაამრავლოთ კოეფიციენტები შესაბამის x მნიშვნელობებზე, ამიტომ მასივის მუდმივი ელემენტები ამ თანმიმდევრობით დააყენეთ: {50,100,1}. ბოლო ელემენტი არის 1, რადგან LINEST-ის მიერ დაბრუნებული ბოლო მნიშვნელობა არის შუალედი, რომელიც არ უნდა შეიცვალოს, ასე რომ თქვენ უბრალოდ ამრავლებთ მას 1-ზე.
მაივის მუდმივის გამოყენების ნაცვლად, შეგიძლიათ შეიყვანოთ ყველა x ცვლადი. ზოგიერთ უჯრედში და მიუთითეთ ეს უჯრედები თქვენს ფორმულაში, როგორც ეს გავაკეთეთ წინა მაგალითში.
რეგულარული ფორმულა:
=SUMPRODUCT(LINEST(D2:D10, B2:C10)*(F2:H2))
მასივის ფორმულა:
=SUM(LINEST(D2:D10, B2:C10)*(F2:H2))
სადაც F2 და G2 არის x მნიშვნელობები და H2 არის 1:
LINEST ფორმულა: დამატებითი რეგრესიის სტატისტიკა
როგორც გახსოვთ, თქვენი რეგრესიის ანალიზისთვის მეტი სტატისტიკის მისაღებად, LINEST ფუნქციის ბოლო არგუმენტში ჩასვით TRUE. ჩვენი ნიმუშის მონაცემებზე გამოყენებული, ფორმულა იღებს შემდეგ ფორმას:
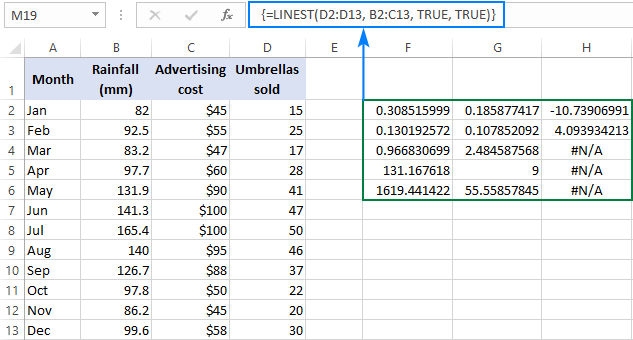
=LINEST(D2:D13, B2:C13, TRUE, TRUE)
როგორც გვაქვს 2 დამოუკიდებელიცვლადებს B და C სვეტებში, ვირჩევთ გაბრაზებას, რომელიც შედგება 3 მწკრივისაგან (ორი x მნიშვნელობა + კვეთა) და 5 სვეტი, შევიყვანთ ზემოთ მოცემულ ფორმულას, დააჭირეთ Ctrl + Shift + Enter და მივიღებთ ამ შედეგს:
#N/A შეცდომებისგან თავის დასაღწევად შეგიძლიათ LINEST ჩასვათ IFERROR-ში ასე:
=IFERROR(LINEST(D2:D13, B2:C13, TRUE, TRUE), "")
ქვემოთ სკრინშოტი აჩვენებს შედეგს და განმარტავს რა თითოეული რიცხვი ნიშნავს:

დახრის კოეფიციენტები და Y-კვეთა ახსნილი იყო წინა მაგალითებში, ასე რომ, მოდით გადავხედოთ სხვა სტატისტიკას.
განსაზღვრების კოეფიციენტი (R2). R2-ის მნიშვნელობა არის კვადრატების რეგრესიული ჯამის კვადრატების ჯამზე გაყოფის შედეგი. ის გეუბნებათ რამდენი y მნიშვნელობა აიხსნება x ცვლადით. ეს შეიძლება იყოს ნებისმიერი რიცხვი 0-დან 1-მდე, ანუ 0%-დან 100%-მდე. ამ მაგალითში, R2 არის დაახლოებით 0.97, რაც ნიშნავს, რომ ჩვენი დამოკიდებული ცვლადების 97% (ქოლგის გაყიდვები) აიხსნება დამოუკიდებელი ცვლადებით (რეკლამა + საშუალო თვიური ნალექი), რაც შესანიშნავად შეესაბამება!
სტანდარტული შეცდომები . ზოგადად, ეს მნიშვნელობები აჩვენებს რეგრესიის ანალიზის სიზუსტეს. რაც უფრო მცირეა რიცხვები, მით უფრო დარწმუნებული იქნებით თქვენი რეგრესიის მოდელში.
F სტატისტიკა . თქვენ იყენებთ F სტატისტიკას ნულოვანი ჰიპოთეზის მხარდასაჭერად ან უარყოფისთვის. რეკომენდებულია F სტატისტიკის გამოყენება P მნიშვნელობასთან ერთად, როდესაც გადაწყვეტთ, არის თუ არა საერთო შედეგები
