
Оглавление
В этом учебном пособии объясняется синтаксис функции LINEST и показывается, как использовать ее для проведения линейного регрессионного анализа в Excel.
Microsoft Excel не является статистической программой, однако в ней есть ряд статистических функций. Одной из таких функций является LINEST, которая предназначена для проведения линейного регрессионного анализа и возврата соответствующей статистики. В этом учебнике для начинающих мы лишь слегка коснемся теории и основных расчетов. Наше основное внимание будет сосредоточено на том, чтобы предоставить вам формулу, которая просто работает.может быть легко настроена под ваши данные.
Функция ЛИНЕСТ в Excel - синтаксис и основные области применения
Функция LINEST вычисляет статистику для прямой линии, которая объясняет связь между независимой переменной и одной или несколькими зависимыми переменными, и возвращает массив, описывающий линию. Функция использует функцию наименьшие квадраты метод, чтобы найти наилучшее соответствие для ваших данных. Уравнение для линии выглядит следующим образом.
Уравнение простой линейной регрессии:
y = bx + aУравнение множественной регрессии:
y = b 1 x 1 + b 2 x 2 + ... + b n x n + aГде:
- y - зависимая переменная, которую вы пытаетесь предсказать.
- x - независимая переменная, которую вы используете для прогнозирования y .
- a - перехват (указывает, где линия пересекает ось Y).
- b - наклон (показывает крутизну линии регрессии, т.е. скорость изменения y при изменении x).
В своей основной форме функция LINEST возвращает перехват (a) и наклон (b) для уравнения регрессии. По желанию она может возвращать дополнительную статистику для регрессионного анализа, как показано в данном примере.
Синтаксис функции LINEST
Синтаксис функции Excel LINEST следующий:
LINEST(известные_y's, [известные_x's], [const], [stats])Где:
- известный (требуемый) является диапазоном зависимого y -значения в уравнении регрессии. Обычно это один столбец или одна строка.
- известные_х (необязательно) - это диапазон независимых значений x. Если он опущен, предполагается, что это массив {1,2,3,...} того же размера, что и известный .
- const (необязательно) - логическое значение, определяющее, как перехват (константа a ) должны быть обработаны:
- Если TRUE или опущено, то константа a рассчитывается нормально.
- Если FALSE, то константа a принудительно равна 0, а наклон ( b коэффициент) рассчитывается для соответствия y=bx.
- статистика (необязательно) - логическое значение, определяющее, выводить или нет дополнительную статистику:
- Если TRUE, функция LINEST возвращает массив с дополнительной статистикой регрессии.
- Если FALSE или опущено, LINEST возвращает только константу перехвата и коэффициент(ы) наклона.
Примечание. Поскольку LINEST возвращает массив значений, его необходимо ввести как формулу массива, нажав сочетание клавиш Ctrl + Shift + Enter. Если его ввести как обычную формулу, возвращается только первый коэффициент наклона.
Дополнительная статистика, возвращаемая LINEST
Сайт статистика аргумент, установленный в TRUE, дает указание функции LINEST вернуть следующие статистические данные для вашего регрессионного анализа:
| Статистика | Описание |
| Коэффициент наклона | b значение в y = bx + a |
| Константа перехвата | значение в y = bx + a |
| Стандартная ошибка наклона | Значение(я) стандартной(ых) ошибки(й) для коэффициента(ов) b. |
| Стандартная ошибка перехвата | Значение стандартной ошибки для константы a . |
| Коэффициент детерминации (R2) | Показывает, насколько хорошо уравнение регрессии объясняет взаимосвязь между переменными. |
| Стандартная ошибка для оценки Y | Показывает точность регрессионного анализа. |
| F-статистика, или F-наблюдаемое значение | Он используется для проведения F-теста для нулевой гипотезы, чтобы определить общую степень пригодности модели. |
| Степени свободы (df) | Число степеней свободы. |
| Сумма квадратов регрессии | Показывает, какая часть вариации зависимой переменной объясняется моделью. |
| Остаточная сумма квадратов | Измеряет величину дисперсии зависимой переменной, которая не объясняется вашей регрессионной моделью. |
На приведенной ниже карте показан порядок, в котором LINEST возвращает массив статистики:

В последних трех строках ошибки #N/A появятся в третьем и последующих столбцах, не заполненных данными. Это поведение функции LINEST по умолчанию, но если вы хотите скрыть обозначения ошибок, оберните вашу формулу LINEST в IFERROR, как показано в этом примере.
Как использовать LINEST в Excel - примеры формул
Функция ЛИНЭСТ может быть сложной в использовании, особенно для новичков, потому что нужно не только правильно построить формулу, но и правильно интерпретировать ее результат. Ниже вы найдете несколько примеров использования формул ЛИНЭСТ в Excel, которые, надеюсь, помогут погрузиться в теоретические знания :)
Простая линейная регрессия: вычислить наклон и перехват
Чтобы получить интерцепт и наклон линии регрессии, вы используете функцию ЛИНЕЙН в ее простейшей форме: задайте диапазон зависимых значений для параметра известный аргумент и диапазон независимых значений для известные_х Последние два аргумента могут быть установлены в TRUE или опущены.
Например, с y значения (количество продаж) в C2:C13 и значения x (стоимость рекламы) в B2:B13, наша формула линейной регрессии проста:
=LINEST(C2:C13,B2:B13)
Чтобы правильно ввести ее в рабочий лист, выделите две соседние ячейки в одной строке, E2:F2 в данном примере, введите формулу и нажмите Ctrl + Shift + Enter для ее завершения.
Формула вернет коэффициент наклона в первую ячейку (E2) и константу перехвата во вторую ячейку (F2):
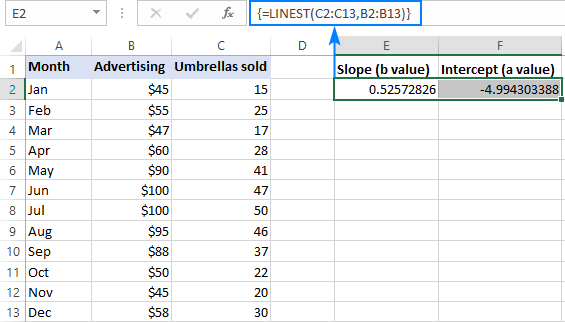
Сайт наклон составляет приблизительно 0,52 (округлено до двух знаков после запятой). Это означает, что когда x увеличивается на 1, y увеличивается на 0,52.
Сайт Y-интерцепт отрицательное -4.99. Это ожидаемое значение y когда x=0. Если построить график, то это значение, при котором линия регрессии пересекает ось y.
Подставьте приведенные выше значения в простое уравнение линейной регрессии, и вы получите следующую формулу для прогнозирования количества продаж в зависимости от стоимости рекламы:
y = 0,52*x - 4,99
Например, если вы потратите 50 долларов на рекламу, то ожидается, что вы продадите 21 зонтик:
0.52*50 - 4.99 = 21.01
Значения наклона и перехвата можно также получить отдельно, используя соответствующую функцию или вложив формулу LINEST в INDEX:
Склон
=SLOPE(C2:C13,B2:B13)
=INDEX(LINEST(C2:C13,B2:B13),1)
Перехват
=INTERCEPT(C2:C13,B2:B13)
=INDEX(LINEST(C2:C13,B2:B13),2)
Как показано на скриншоте ниже, все три формулы дают одинаковые результаты:

Множественная линейная регрессия: наклон и перехват
Если у вас есть две или более независимых переменных, обязательно введите их в соседние столбцы и передайте весь этот диапазон в файл известные_х аргумент.
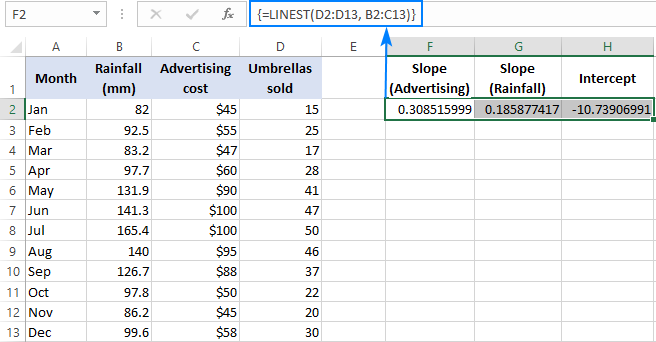
Например, с номерами продаж ( y D2:D13, стоимость рекламы (один набор значений x) в B2:B13 и среднемесячное количество осадков (другой набор значений x) в D2:D13. x значения) в C2:C13, вы используете эту формулу:
=LINEST(D2:D13,B2:C13)
Поскольку формула будет возвращать массив из 3 значений (2 коэффициента наклона и константа перехвата), выделим три смежные ячейки в одной строке, введем формулу и нажмем комбинацию клавиш Ctrl + Shift + Enter.
Обратите внимание, что формула множественной регрессии возвращает значение коэффициенты наклона в обратный порядок независимых переменных (справа налево), то есть b n , b n-1 , ..., b 2 , b 1 :
Чтобы спрогнозировать количество продаж, мы подставляем значения, полученные по формуле LINEST, в уравнение множественной регрессии:
y = 0.3*x 2 + 0.19*x 1 - 10.74
Например, при затратах на рекламу в размере $50 и среднемесячном количестве осадков в 100 мм, ожидается, что вы продадите примерно 23 зонта:
0.3*50 + 0.19*100 - 10.74 = 23.26
Простая линейная регрессия: предсказать зависимую переменную
Помимо расчета a и b значения для уравнения регрессии, функция Excel ЛИНЭСТ может также оценить зависимую переменную (y) на основе известной независимой переменной (x). Для этого используется ЛИНЭСТ в сочетании с функцией SUM или SUMPRODUCT.
Например, вот как вы можете рассчитать количество продаж зонтов на следующий месяц, скажем, октябрь, на основе продаж в предыдущие месяцы и рекламного бюджета на октябрь в размере 50 долларов:
=SUM(LINEST(C2:C10, B2:B10)*{50,1})
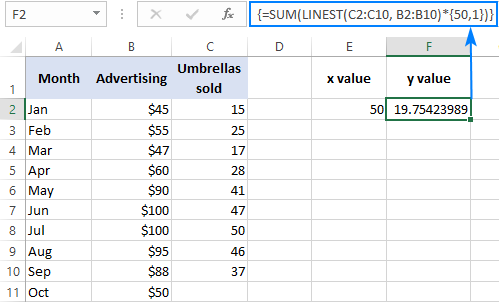
Вместо жесткого кодирования x значение в формуле, вы можете предоставить его как ссылку на ячейку. В этом случае вам нужно ввести константу 1 в какую-то ячейку, потому что вы не можете смешивать ссылки и значения в константе массива.
С x значение в E2 и константу 1 в F2, то любая из приведенных ниже формул будет работать на ура:
Обычная формула (вводится нажатием клавиши Enter ):
= СУММАРНЫЙ ПРОДУКТ(LINEST(C2:C10, B2:B10)*(E2:F2))
Формула массива (вводится нажатием клавиш Ctrl + Shift + Enter ):
=SUM(LINEST(C2:C10, B2:B10)*(E2:F2))
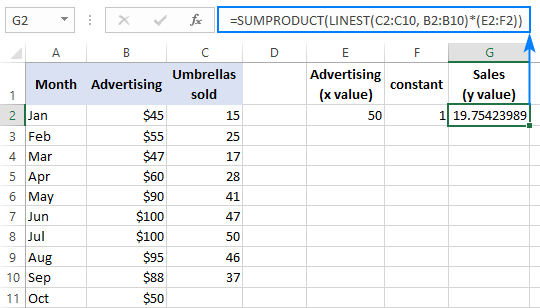
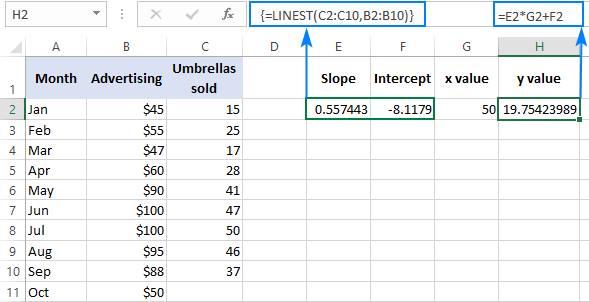
Чтобы проверить результат, вы можете получить перехват и наклон для тех же данных, а затем использовать формулу линейной регрессии для расчета y :
=E2*G2+F2
Где E2 - наклон, G2 - x значение, а F2 - перехват:
Множественная регрессия: прогнозирование зависимой переменной
В случае, если вы имеете дело с несколькими предикторами, т.е. с несколькими различными наборами x значения, включите все эти предикторы в массив констант. Например, при рекламном бюджете в 50 долларов (x 2 ) и среднемесячное количество осадков 100 мм (x 1 ), формула выглядит следующим образом:
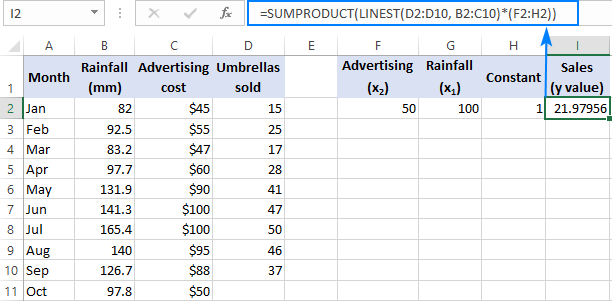
=SUM(LINEST(D2:D10, B2:C10)*{50,100,1})
Где D2:D10 - известные y значения, а B2:C10 - два набора x значения:

Пожалуйста, обратите внимание на порядок x значения в массиве constant. Как указывалось ранее, когда функция Excel ЛИНЭСТ используется для множественной регрессии, она возвращает коэффициенты наклона справа налево. В нашем примере, функция Реклама сначала возвращается коэффициент, а затем Осадки коэффициент. Чтобы правильно рассчитать прогнозируемое число продаж, необходимо умножить коэффициенты на соответствующие x значения, поэтому вы размещаете элементы константы массива в таком порядке: {50,100,1}. Последний элемент - 1, потому что последнее значение, возвращаемое LINEST, - это перехват, который не должен быть изменен, поэтому вы просто умножаете его на 1.
Вместо того чтобы использовать константу массива, вы можете ввести все переменные x в некоторые ячейки и ссылаться на эти ячейки в вашей формуле, как мы делали в предыдущем примере.
Обычная формула:
= СУММАРНЫЙ ПРОДУКТ(LINEST(D2:D10, B2:C10)*(F2:H2))
Формула массива:
=SUM(LINEST(D2:D10, B2:C10)*(F2:H2))
Где F2 и G2 - это x значения, а H2 - 1:
Формула LINEST: дополнительная статистика регрессии
Как вы помните, чтобы получить больше статистики для регрессионного анализа, в последнем аргументе функции LINEST ставится TRUE. В применении к данным нашей выборки формула принимает следующий вид:
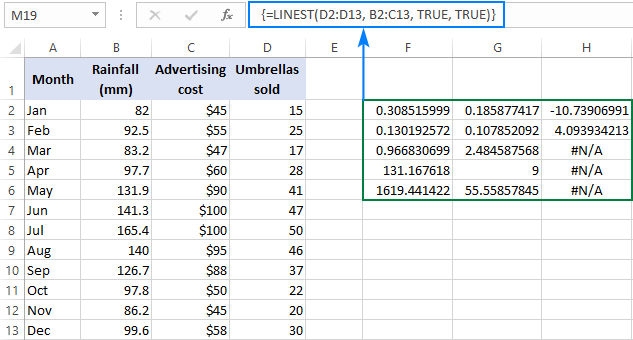
=LINEST(D2:D13, B2:C13, TRUE, TRUE)
Поскольку у нас есть 2 независимые переменные в столбцах B и C, мы выбираем ярость, состоящую из 3 строк (два значения x + перехват) и 5 столбцов, вводим приведенную выше формулу, нажимаем Ctrl + Shift + Enter , и получаем такой результат:
Чтобы избавиться от ошибок #N/A, вы можете вложить LINEST в IFERROR следующим образом:
=IFERROR(LINEST(D2:D13, B2:C13, TRUE, TRUE), "")
На скриншоте ниже показан результат и объяснено, что означает каждое число:

Коэффициенты наклона и Y-интерцепт были объяснены в предыдущих примерах, поэтому давайте вкратце рассмотрим другие статистические данные.
Коэффициент детерминации (R2). Значение R2 - это результат деления суммы квадратов регрессии на общую сумму квадратов. Оно показывает, сколько y значения объясняются x переменных. Это может быть любое число от 0 до 1, то есть от 0% до 100%. В данном примере R2 составляет приблизительно 0,97, что означает, что 97% наших зависимых переменных (продажи зонтов) объясняются независимыми переменными (реклама + среднемесячное количество осадков), что является отличным подходом!
Стандартные ошибки В целом, эти значения показывают точность регрессионного анализа. Чем меньше эти числа, тем больше уверенности в регрессионной модели.
F-статистика Рекомендуется использовать статистику F в сочетании со значением P при решении вопроса о том, являются ли общие результаты значимыми.
Степени свободы (df). Функция ЛИНЕСТ в Excel возвращает значение остаточные степени свободы , который является общий df минус регрессионный df Вы можете использовать степени свободы для получения F-критических значений в статистической таблице, а затем сравнить F-критические значения со статистикой F для определения уровня доверия для вашей модели.
Сумма квадратов регрессии (он же объясненная сумма квадратов , или сумма квадратов модели ). Это сумма квадратов разницы между предсказанными значениями y и средним значением y, рассчитываемая по формуле: =∑(ŷ - ȳ)2. Она показывает, какую часть вариации зависимой переменной объясняет ваша регрессионная модель.
Остаточная сумма квадратов Это сумма квадратов разницы между фактическими значениями y и предсказанными значениями y. Она показывает, какую часть вариации зависимой переменной ваша модель не объясняет. Чем меньше остаточная сумма квадратов по сравнению с общей суммой квадратов, тем лучше ваша регрессионная модель соответствует данным.
5 вещей, которые вы должны знать о функции LINEST
Чтобы эффективно использовать формулы LINEST в своих рабочих листах, вы можете узнать немного больше о "внутренней механике" функции:
- Known_y's и известные_х В простой линейной регрессионной модели с одним набором переменных x, известный и известные_х могут быть диапазонами любой формы, если только они имеют одинаковое количество строк и столбцов. Если вы проводите множественный регрессионный анализ с более чем одним набором независимых x переменные, известный должен быть вектором, т.е. диапазоном из одной строки или одного столбца.
- Принуждение константы к нулю . Когда const аргумент равен TRUE или опущен, то a вычисляется константа (перехват) и включается в уравнение: y=bx + a. Если const имеет значение FALSE, перехват считается равным 0 и исключается из уравнения регрессии: y=bx.
В статистике уже несколько десятилетий ведутся споры о том, имеет ли смысл приводить константу перехвата к 0 или нет. Многие авторитетные специалисты по регрессионному анализу считают, что если приведение перехвата к нулю (const=FALSE) оказывается полезным, то линейная регрессия сама по себе является неверной моделью для данного набора данных. Другие полагают, что константу можно приводить к нулю в определенных ситуациях, например,В целом, в большинстве случаев рекомендуется использовать const=TRUE или опустить.
- Точность Точность уравнения регрессии, рассчитанного функцией LINEST, зависит от дисперсии точек ваших данных. Чем линейнее данные, тем точнее результаты формулы LINEST.
- Избыточные значения x В некоторых ситуациях один или несколько независимых x переменные могут не иметь дополнительной предсказательной ценности, и удаление таких переменных из регрессионной модели не влияет на точность предсказанных значений y. Это явление известно как "коллинеарность". Функция Excel ЛИНЕСТ проверяет коллинеарность и исключает все лишние переменные. x переменные, которые он идентифицирует из модели. Опущенные x переменных можно узнать по 0 коэффициентам и 0 значениям стандартной ошибки.
- ЛИНЕСТ против СЛОПА и ИНТЕРСЕПТА Алгоритм, лежащий в основе функции LINEST, отличается от алгоритма, используемого в функциях SLOPE и INTERCEPT. Поэтому, когда исходные данные не определены или коллинеарны, эти функции могут давать разные результаты.
Функция ЛИНЕСТ в Excel не работает
Если ваша формула LINEST выдает ошибку или выдает неправильный результат, скорее всего, это происходит по одной из следующих причин:
- Если функция LINEST возвращает только одно число (коэффициент наклона), скорее всего, вы ввели ее как обычную формулу, а не как формулу массива. Обязательно нажмите Ctrl + Shift + Enter, чтобы правильно завершить формулу. Когда вы это сделаете, формула будет заключена в {курчавые скобки}, которые видны в строке формул.
- Ошибка #REF! Возникает, если известные_х и известный диапазоны имеют разные размеры.
- #VALUE! ошибка. Возникает, если известные_х или известный содержит хотя бы одну пустую ячейку, текстовое значение или текстовое представление числа, которое Excel не распознает как числовое значение. Также ошибка #VALUE возникает, если в поле const или статистика аргумент не может быть оценен как TRUE или FALSE.
Вот как можно использовать LINEST в Excel для простого и множественного линейного регрессионного анализа. Для более детального изучения формул, рассмотренных в этом руководстве, вы можете скачать наш образец рабочей книги ниже. Я благодарю вас за чтение и надеюсь увидеть вас в нашем блоге на следующей неделе!
Рабочая тетрадь для тренировок для скачивания
Примеры функций Excel LINEST (файл.xlsx)
