
Sisällysluettelo
Tässä opetusohjelmassa selitetään LINEST-funktion syntaksi ja näytetään, miten sitä käytetään lineaarisen regressioanalyysin tekemiseen Excelissä.
Microsoft Excel ei ole tilasto-ohjelma, mutta siinä on kuitenkin useita tilastollisia funktioita. Yksi tällaisista funktioista on LINEST, joka on suunniteltu lineaarisen regressioanalyysin suorittamiseen ja siihen liittyvien tilastojen palauttamiseen. Tässä aloittelijoille suunnatussa opetusohjelmassa käsittelemme vain kevyesti teoriaa ja taustalla olevia laskutoimituksia. Keskitymme lähinnä siihen, että saat kaavan, joka toimii yksinkertaisesti javoidaan helposti räätälöidä tietojasi varten.
Excelin LINEST-funktio - syntaksi ja peruskäytöt
LINEST-funktio laskee tilastoja suoralle suoralle, joka selittää riippumattoman muuttujan ja yhden tai useamman riippuvan muuttujan välisen suhteen, ja palauttaa suoraa kuvaavan matriisin. Funktio käyttää funktiota pienimmät neliöt Menetelmällä voit löytää parhaan sovitteen aineistollesi. Suoran yhtälö on seuraava.
Yksinkertainen lineaarinen regressioyhtälö:
y = bx + aMoninkertainen regressioyhtälö:
y = b 1 x 1 + b 2 x 2 + ... + b n x n + aMissä:
- y - riippuvainen muuttuja, jota yrität ennustaa.
- x - riippumaton muuttuja, jota käytät ennustamiseen y .
- a - leikkauspiste (osoittaa, missä kohdassa viiva leikkaa Y-akselin).
- b - kaltevuus (ilmaisee regressiosuoran jyrkkyyttä eli y:n muutosnopeutta x:n muuttuessa).
Perusmuodossaan LINEST-funktio palauttaa regressioyhtälön leikkauspisteen (a) ja kaltevuuden (b). Vaihtoehtoisesti se voi palauttaa myös muita regressioanalyysin tilastoja, kuten tässä esimerkissä on esitetty.
LINEST-funktion syntaksi
Excelin LINEST-funktion syntaksi on seuraava:
LINEST(tunnetut_y:t, [tunnetut_x:t], [const], [stats])Missä:
- known_y:n (vaaditaan) on riippuvaisen y -arvot regressioyhtälössä. Yleensä se on yksi sarake tai yksi rivi.
- known_x:n (valinnainen) on riippumattomien x-arvojen alue. Jos se jätetään pois, sen oletetaan olevan joukko {1,2,3,...}, joka on samankokoinen kuin joukko {1,2,3,...}. known_y:n .
- const (valinnainen) - looginen arvo, joka määrittää, miten leikkaus (vakio a ) olisi käsiteltävä:
- Jos TRUE tai jätetään pois, vakio a lasketaan normaalisti.
- Jos FALSE, vakio a pakotetaan arvoon 0 ja kaltevuus ( b kerroin) lasketaan sovittamaan y=bx.
- tilastot (valinnainen) on looginen arvo, joka määrittää, tulostetaanko lisätilastoja vai ei:
- Jos TRUE, LINEST-funktio palauttaa matriisin, jossa on muita regressiotilastoja.
- Jos FALSE tai jätetään pois, LINEST palauttaa vain leikkausvakion ja kaltevuuskerroin(t).
Huomautus: Koska LINEST palauttaa arvojen joukon, se on syötettävä joukkokaavana painamalla Ctrl + Shift + Enter-pikanäppäintä. Jos se syötetään tavallisena kaavana, vain ensimmäinen kaltevuuskerroin palautetaan.
LINESTin palauttamat lisätilastot
The tilastot argumentti, jonka arvoksi on asetettu TRUE, määrää LINEST-funktion palauttamaan seuraavat tilastot regressioanalyysia varten:
| Tilasto | Kuvaus |
| Kaltevuuskerroin | b arvo yhtälössä y = bx + a |
| Intercept-vakio | arvo yhtälössä y = bx + a |
| Kaltevuuden keskivirhe | b-kertoimen (kertoimien) keskivirhearvo(t). |
| Poikkeaman keskivirhe | Vakion keskivirhearvo a . |
| Määrityskerroin (R2) | Ilmaisee, kuinka hyvin regressioyhtälö selittää muuttujien välisen suhteen. |
| Y-estimaatin keskivirhe | Osoittaa regressioanalyysin tarkkuuden. |
| F-statistiikka tai F-havaittu arvo. | Sitä käytetään nollahypoteesin F-testin tekemiseen mallin yleisen sopivuuden määrittämiseksi. |
| Vapausasteet (df) | Vapausasteiden lukumäärä. |
| Regression neliösumma | Ilmaisee, kuinka suuren osan riippuvan muuttujan vaihtelusta malli selittää. |
| Jäljelle jäävä neliösumma | Mittaa sitä riippuvan muuttujan varianssin määrää, jota regressiomallisi ei selitä. |
Alla olevassa kartassa näkyy, missä järjestyksessä LINEST palauttaa tilastojen joukon:

Kolmella viimeisellä rivillä #N/A-virheet näkyvät kolmannessa ja sitä seuraavissa sarakkeissa, joita ei ole täytetty tiedoilla. Tämä on LINEST-funktion oletuskäyttäytyminen, mutta jos haluat piilottaa virhemerkinnät, kiedo LINEST-kaavasi IFERROR-merkinnäksi, kuten tässä esimerkissä näytetään.
LINESTin käyttö Excelissä - kaavaesimerkkejä
LINEST-funktio voi olla hankala käyttää, erityisesti aloittelijoille, koska sinun ei pitäisi vain rakentaa kaava oikein, vaan myös tulkita sen tulosta oikein. Alla on muutama esimerkki LINEST-kaavojen käytöstä Excelissä, jotka toivottavasti auttavat upottamaan teoreettisen tiedon sisään :)
Yksinkertainen lineaarinen regressio: laske kaltevuus ja leikkauspiste.
Saadaksesi regressiosuoran leikkauspisteen ja kaltevuuden, käytät LINEST-funktiota sen yksinkertaisimmassa muodossa: anna riippuvien arvojen vaihteluväli. known_y:n argumentti ja riippumattomien arvojen vaihteluväli parametrille known_x:n Kaksi viimeistä argumenttia voidaan asettaa arvoon TRUE tai jättää pois.
Esimerkiksi y arvot (myyntiluvut) kohdissa C2:C13 ja x-arvot (mainoskustannukset) kohdissa B2:B13, lineaarisen regression kaava on yksinkertainen:
=LINEST(C2:C13,B2:B13)
Jos haluat syöttää sen oikein laskentataulukkoon, valitse kaksi vierekkäistä solua samalta riviltä, tässä esimerkissä E2:F2, kirjoita kaava ja täydennä se painamalla Ctrl + Shift + Enter.
Kaava palauttaa kaltevuuskertoimen ensimmäiseen soluun (E2) ja leikkausvakion toiseen soluun (F2):
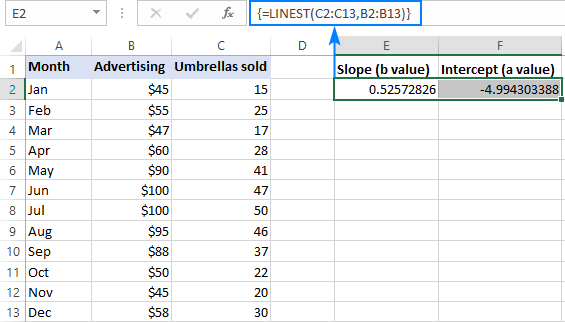
The kaltevuus on noin 0,52 (pyöristettynä kahteen desimaaliin), mikä tarkoittaa, että kun x kasvaa 1:llä, y kasvaa 0,52:lla.
The Y-suuntainen leikkauspiste on negatiivinen -4,99. Se on odotusarvo, joka on seuraava y kun x=0. Jos se esitetään kuvaajassa, se on arvo, jossa regressiosuora ylittää y-akselin.
Jos annat edellä mainitut arvot yksinkertaiseen lineaariseen regressioyhtälöön, saat seuraavan kaavan, jolla ennustetaan myyntiluku mainoskustannusten perusteella:
y = 0,52*x - 4,99
Jos esimerkiksi käytät 50 dollaria mainontaan, sinun odotetaan myyvän 21 sateenvarjoa:
0.52*50 - 4.99 = 21.01
Kaltevuus- ja leikkausarvot voidaan saada myös erikseen käyttämällä vastaavaa funktiota tai yhdistämällä LINEST-kaava INDEX-kaavaan:
Rinne
=SLOPE(C2:C13,B2:B13)
=INDEX(LINEST(C2:C13,B2:B13),1)
Intercept
=INTERCEPT(C2:C13,B2:B13)
=INDEX(LINEST(C2:C13,B2:B13),2)
Kuten alla olevasta kuvakaappauksesta näkyy, kaikki kolme kaavaa antavat samat tulokset:

Moninkertainen lineaarinen regressio: kaltevuus ja leikkauspiste
Jos sinulla on kaksi tai useampia riippumattomia muuttujia, muista syöttää ne vierekkäisiin sarakkeisiin ja anna koko alue komentoon known_x:n argumentti.
Esimerkiksi myyntinumeroiden ( y arvot) D2:D13:ssa, mainoskustannukset (yksi x-arvojen joukko) B2:B13:ssa ja keskimääräinen kuukausittainen sademäärä (toinen x-arvojen joukko) D2:D13:ssa. x arvot) C2:C13:ssa, käytetään tätä kaavaa:
=LINEST(D2:D13,B2:C13)
Koska kaava palauttaa kolmen arvon joukon (2 kaltevuuskerrointa ja leikkausvakio), valitsemme kolme vierekkäistä solua samalta riviltä, kirjoitamme kaavan ja painamme Ctrl + Shift + Enter -pikanäppäintä.
Huomaa, että moninkertaisen regression kaava palauttaa arvon kaltevuuskertoimet vuonna käänteinen järjestys riippumattomista muuttujista (oikealta vasemmalle), eli b n , b n-1 , ..., b 2 , b 1 :
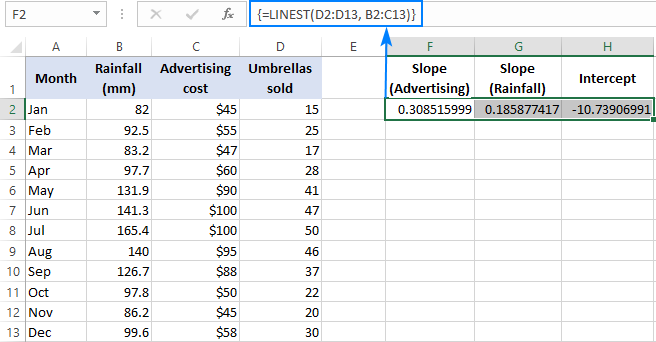
Myyntiluvun ennustamiseksi syötämme LINEST-kaavan palauttamat arvot moninkertaisen regression yhtälöön:
y = 0,3*x 2 + 0.19*x 1 - 10.74
Jos esimerkiksi mainontaan käytetään 50 dollaria ja keskimääräinen kuukausittainen sademäärä on 100 mm, sinun odotetaan myyvän noin 23 sateenvarjoa:
0.3*50 + 0.19*100 - 10.74 = 23.26
Yksinkertainen lineaarinen regressio: ennustaa riippuvainen muuttuja
Sen lisäksi, että lasketaan a ja b regressioyhtälön arvot, Excelin LINEST-toiminto voi myös arvioida riippuvaisen muuttujan (y) tunnetun riippumattoman muuttujan (x) perusteella. Tätä varten käytät LINEST-toimintoa yhdessä SUMMA- tai SUMPRODUCT-toiminnon kanssa.
Voit esimerkiksi laskea seuraavan kuukauden, vaikkapa lokakuun, sateenvarjomyynnin määrän edellisten kuukausien myynnin ja lokakuun 50 dollarin mainosbudjetin perusteella seuraavasti:
=SUM(LINEST(C2:C10, B2:B10)*{50,1})
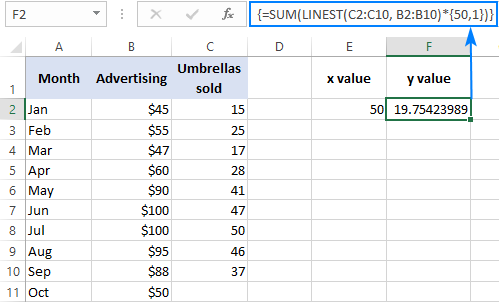
Sen sijaan, että kovakoodataan x arvo kaavassa, voit antaa sen soluviitteenä. Tässä tapauksessa sinun on syötettävä myös vakio 1 johonkin soluun, koska et voi sekoittaa viittauksia ja arvoja array-vakiossa.
Kun x arvo E2:ssa ja vakio 1 F2:ssa, jompikumpi alla olevista kaavoista toimii:
Tavallinen kaava (syötetään painamalla Enter ):
=SUMPRODUCT(LINEST(C2:C10, B2:B10)*(E2:F2))
Array-kaava (syötetään painamalla Ctrl + Shift + Enter ):
=SUM(LINEST(C2:C10, B2:B10)*(E2:F2))
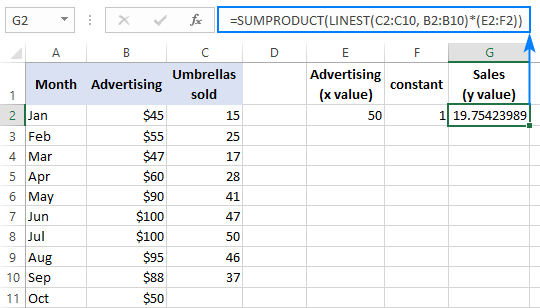
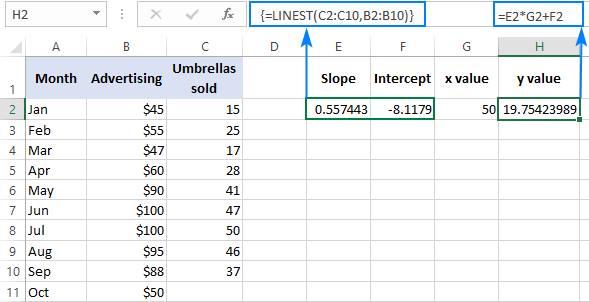
Voit tarkistaa tuloksen saamalla samasta datasta leikkauspisteen ja kaltevuuden ja laskemalla sen jälkeen lineaarisen regression kaavalla seuraavat luvut y :
=E2*G2+F2
Jossa E2 on kaltevuus, G2 on kaltevuus, G2 on x arvo ja F2 on leikkauspiste:
Moninkertainen regressio: ennustaa riippuvainen muuttuja
Jos kyseessä on useita ennustajia, eli muutama eri joukko erilaisia x arvot, sisällytä kaikki nämä ennustajat vakiojoukkoon. Esimerkiksi, kun mainosbudjetti on 50 dollaria (x 2 ) ja keskimääräinen kuukausittainen sademäärä on 100 mm (x 1 ), kaava on seuraava:
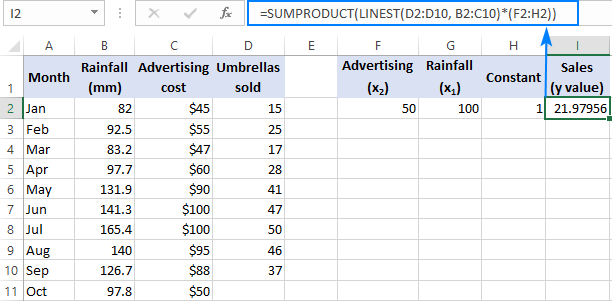
=SUM(LINEST(D2:D10, B2:C10)*{50,100,1})
Jossa D2:D10 ovat tunnetut y arvot ja B2:C10 ovat kaksi sarjaa x arvot:

Kiinnitä huomiota järjestykseen x Kuten aiemmin todettiin, kun Excelin LINEST-funktiota käytetään moninkertaisen regression tekemiseen, se palauttaa kaltevuuskerroinarvot oikealta vasemmalle. Esimerkissä Mainonta kerroin palautetaan ensin, ja sitten palautetaan kerroin Sademäärä Jotta ennustettu myyntiluku voidaan laskea oikein, kertoimet on kerrottava vastaavalla kertoimella. x arvot, joten asetat vakiojoukon elementit tässä järjestyksessä: {50,100,1}. Viimeinen elementti on 1, koska LINESTin palauttama viimeinen arvo on leikkausarvo, jota ei saa muuttaa, joten se yksinkertaisesti kerrotaan 1:llä.
Joukkovakion käytön sijaan voit syöttää kaikki x-muuttujat joihinkin soluihin ja viitata näihin soluihin kaavassa, kuten edellisessä esimerkissä.
Tavallinen kaava:
=SUMPRODUCT(LINEST(D2:D10, B2:C10)*(F2:H2))
Array-kaava:
=SUM(LINEST(D2:D10, B2:C10)*(F2:H2))
Jossa F2 ja G2 ovat x arvot ja H2 on 1:
LINEST-kaava: lisää regressiotilastoja
Kuten ehkä muistat, saadaksesi lisää tilastoja regressioanalyysiisi, laitat LINEST-funktion viimeiseen argumenttiin TRUE. Sovellettuna esimerkkiaineistoihimme kaava saa seuraavan muodon:
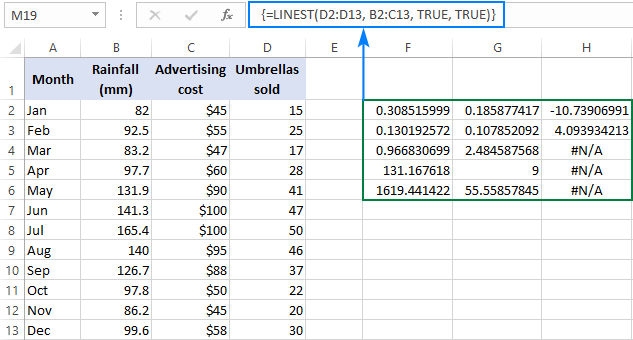
=LINEST(D2:D13, B2:C13, TRUE, TRUE)
Koska meillä on kaksi riippumatonta muuttujaa sarakkeissa B ja C, valitsemme rajan, joka koostuu kolmesta rivistä (kaksi x-arvoa + leikkauspiste) ja viidestä sarakkeesta, kirjoitamme yllä olevan kaavan, painamme Ctrl + Shift + Enter , ja saamme tämän tuloksen:
Pääset eroon #N/A-virheistä, kun LINEST liitetään IFERRORiin seuraavasti:
=IFERROR(LINEST(D2:D13, B2:C13, TRUE, TRUE), "")
Alla olevassa kuvakaappauksessa näkyy tulos ja selitetään, mitä kukin numero tarkoittaa:

Kaltevuuskerroin ja Y-välileikkaus selitettiin edellisissä esimerkeissä, joten tarkastellaan nopeasti muita tilastoja.
Määrityskerroin (R2). R2:n arvo on tulos, joka saadaan jakamalla regression neliösumma kokonaisneliösummalla. Se kertoo, kuinka moni y arvot selittyvät x Se voi olla mikä tahansa luku välillä 0-1, eli 0-100 %. Tässä esimerkissä R2 on noin 0,97, mikä tarkoittaa, että 97 % riippuvaisista muuttujista (sateenvarjojen myynti) selittyy riippumattomilla muuttujilla (mainonta + keskimääräinen kuukausittainen sademäärä), mikä on erinomainen sovitus!
Vakiovirheet Yleensä nämä arvot osoittavat regressioanalyysin tarkkuuden. Mitä pienemmät luvut ovat, sitä varmempi voit olla regressiomallista.
F-statistiikka F-tilastoa käytetään nollahypoteesin tukemiseen tai hylkäämiseen. On suositeltavaa käyttää F-tilastoa yhdessä P-arvon kanssa, kun päätetään, ovatko kokonaistulokset merkitseviä.
Vapausasteet (df). Excelin LINEST-funktio palauttaa tuloksen, joka on jäännösvapausasteet , joka on yhteensä df miinus regression df Voit käyttää vapausasteita saadaksesi F-kriittiset arvot tilastollisessa taulukossa ja verrata F-kriittisiä arvoja F-statistiikkaan määrittääksesi mallisi luottamustason.
Regression neliösumma (eli selitetty neliösumma , tai mallin neliösumma ). Se on ennustettujen y-arvojen ja y:n keskiarvon neliöerojen summa, joka lasketaan seuraavalla kaavalla: =∑(ŷ - ȳ)2. Se osoittaa, kuinka suuren osan riippuvan muuttujan vaihtelusta regressiomallisi selittää.
Jäljelle jäävä neliösumma Se on todellisten y-arvojen ja ennustettujen y-arvojen neliöerojen summa. Se osoittaa, kuinka suurta osaa riippuvan muuttujan vaihtelusta malli ei selitä. Mitä pienempi jäännösneliösumma on verrattuna kokonaisneliösummaan, sitä paremmin regressiomalli sopii aineistoon.
5 asiaa, jotka sinun tulisi tietää LINEST-toiminnosta
Jos haluat käyttää LINEST-kaavoja tehokkaasti työarkissasi, sinun on ehkä hyvä tietää hieman enemmän funktion "sisäisestä mekaniikasta":
- Known_y:n ja known_x:n . yksinkertaisessa lineaarisessa regressiomallissa, jossa on vain yksi x-muuttujien joukko, known_y:n ja known_x:n voivat olla minkä tahansa muotoisia alueita, kunhan niissä on sama määrä rivejä ja sarakkeita. Jos teet moninkertaisen regressioanalyysin useammalla kuin yhdellä sarjalla riippumattomia x muuttujat, known_y:n on oltava vektori eli yhden rivin tai yhden sarakkeen alue.
- Vakion pakottaminen nollaan . Kun const argumentti on TRUE tai se jätetään pois, argumentti a vakio (leikkaus) lasketaan ja sisällytetään yhtälöön: y=bx + a. Mikäli const on FALSE, leikkauspisteen katsotaan olevan 0 ja se jätetään pois regressioyhtälöstä: y=bx.
Tilastotieteessä on vuosikymmeniä kiistelty siitä, onko järkevää pakottaa leikkausvakio nollaan vai ei. Monet uskottavat regressioanalyysin harjoittajat ovat sitä mieltä, että jos leikkausvakion asettaminen nollaan (const=FALSE) vaikuttaa hyödylliseltä, lineaarinen regressio itsessään on väärä malli aineistolle. Toiset taas olettavat, että vakio voidaan pakottaa nollaan tietyissä tilanteissa, esim,Yleensä on suositeltavaa käyttää oletusarvoa const=TRUE tai jättää se useimmissa tapauksissa pois.
- Tarkkuus LINEST-toiminnolla lasketun regressioyhtälön tarkkuus riippuu datapisteiden hajonnasta. Mitä lineaarisempi data on, sitä tarkempia ovat LINEST-kaavan tulokset.
- Ylimääräiset x-arvot Joissakin tilanteissa yksi tai useampi riippumaton x muuttujilla ei välttämättä ole mitään ylimääräistä ennustearvoa, eikä tällaisten muuttujien poistaminen regressiomallista vaikuta ennustettujen y-arvojen tarkkuuteen. Tätä ilmiötä kutsutaan "kollineaarisuudeksi". Excelin LINEST-toiminto tarkistaa kollineaarisuuden ja jättää pois kaikki tarpeettomat y-arvot. x muuttujat, jotka se tunnistaa mallista. Pois jätetyt x muuttujat voidaan tunnistaa 0 kertoimesta ja 0 keskivirhearvosta.
- LINEST vs. SLOPE ja INTERCEPT LINEST-funktion algoritmi eroaa SLOPE- ja INTERCEPT-funktioissa käytetystä algoritmista, minkä vuoksi nämä funktiot voivat antaa erilaisia tuloksia, kun lähtötiedot ovat määrittelemättömiä tai kolineaarisia.
Excel LINEST -toiminto ei toimi
Jos LINEST-kaavasi heittää virheen tai tuottaa väärän tuloksen, se johtuu todennäköisesti jostain seuraavista syistä:
- Jos LINEST-funktio palauttaa vain yhden luvun (kaltevuuskerroin), olet todennäköisesti syöttänyt sen tavallisena kaavana, etkä matriisikaavana. Muista painaa Ctrl + Shift + Enter, jotta kaava tulee oikein valmiiksi. Kun teet näin, kaava suljetaan {sulkeisiin}, jotka näkyvät kaavapalkissa.
- #REF! -virhe. Tapahtuu, jos... known_x:n ja known_y:n vaihteluväleillä on erilaiset mitat.
- #VALUE! virhe. Tapahtuu, jos known_x:n tai known_y:n sisältää vähintään yhden tyhjän solun, tekstiarvon tai sellaisen numeron tekstimuotoisen esityksen, jota Excel ei tunnista numeeriseksi arvoksi. Lisäksi #VALUE-virhe tapahtuu, jos kenttässä const tai tilastot argumenttia ei voida arvioida TRUEksi tai FALSEksi.
Näin käytät LINESTiä Excelissä yksinkertaiseen ja moninkertaiseen lineaariseen regressioanalyysiin. Jos haluat tutustua tarkemmin tässä ohjeessa käsiteltyihin kaavoihin, voit ladata alla olevan esimerkkityökirjan. Kiitos lukemisesta ja toivottavasti tapaamme blogissamme ensi viikolla!
Käytännön työkirja ladattavissa
Excel LINEST -funktioiden esimerkkejä (.xlsx-tiedosto)
