
Ynhâldsopjefte
Dizze tutorial ferklearret de syntaksis fan 'e LINEST-funksje en lit sjen hoe't jo it brûke om lineêre regression-analyze yn Excel te dwaan.
Microsoft Excel is gjin statistysk programma, it docht lykwols hawwe in oantal statistyske funksjes. Ien fan sokke funksjes is LINEST, dat is ûntworpen om lineêre regressionanalyse út te fieren en relatearre statistiken werom te jaan. Yn dizze tutorial foar begjinners sille wy allinich licht oanreitsje op teory en ûnderlizzende berekkeningen. Us haadfokus sil wêze op it jaan fan in formule dy't gewoan wurket en kin maklik oanpast wurde foar jo gegevens.
Excel LINEST-funksje - syntaksis en basisgebrûk
De LINEST funksje berekkent de statistiken foar in rjochte line dy't ferklearret de relaasje tusken de ûnôfhinklike fariabele en ien of mear ôfhinklike fariabelen, en jout in rige beskriuwt de line. De funksje brûkt de metoade kleinste kwadraten om de bêste fit foar jo gegevens te finen. De fergeliking foar de line is as folget.
Ienfâldige lineêre regressionfergeliking:
y = bx + aMeardere regressionfergeliking:
y = b 1x 1+ b 2x 2+ … + b nx n+ aWêr:
- y - de ôfhinklike fariabele dy't jo besykje te foarsizzen.
- x - de ûnôfhinklike fariabele dy't jo brûke om te foarsizzen y .
- a - it snijpunt (jout oan wêr't de line de Y-as snijt).
- b - de hellingsignifikant.
Frijheidsgraden (df). De LINEST-funksje yn Excel jout de restgraden fan frijheid werom, dat is de totale df minus de regression df . Jo kinne de frijheidsgraden brûke om F-krityske wearden te krijen yn in statistyske tabel, en dan de F-krityske wearden fergelykje mei de F-statistyk om in betrouwensnivo foar jo model te bepalen.
Regressionsom fan kwadraten (aka de ferklearre som fan kwadraten , of modelsom fan kwadraten ). It is de som fan de kwadraten ferskillen tusken de foarseine y-wearden en it gemiddelde fan y, berekkene mei dizze formule: =∑(ŷ - ȳ)2. It jout oan hoefolle fan 'e fariaasje yn 'e ôfhinklike fariabele jo regressionmodel ferklearret.
Residuele som fan kwadraten . It is de som fan de kwadraten ferskillen tusken de werklike y-wearden en de foarseine y-wearden. It jout oan hoefolle fan 'e fariaasje yn' e ôfhinklike fariabele jo model net ferklearret. Hoe lytser de restsom fan kwadraten yn ferliking mei de totale som fan kwadraten, hoe better jo regressionmodel past by jo gegevens.
5 dingen dy't jo witte moatte oer LINEST-funksje
Om effisjint LINEST-formules te brûken yn jo wurkblêden wolle jo miskien wat mear witte oer de "ynderlike meganika" fan 'e funksje:
- Bekende_y's en bekende_x's . Yn in ienfâldich lineêr regressionmodel mei mar ien set fan x fariabelen, bekende_y's en bekende_x's kinne berik wêze fan elke foarm, salang't se itselde oantal rigen en kolommen hawwe. As jo meardere regression-analyze dogge mei mear as ien set ûnôfhinklike x -fariabelen, moatte bekende_y's in fektor wêze, dus in berik fan ien rige of ien kolom.
- De konstante op nul twinge . As it argumint const TRUE is of weilitten wurdt, wurdt de a konstante (ûnderskieding) berekkene en opnommen yn 'e fergeliking: y=bx + a. As const op FALSE ynsteld is, wurdt de ôfsnijing as gelyk oan 0 beskôge en weilitten út de regressionfergeliking: y=bx.
Yn statistyk is it al tsientallen jierren debattearre oft it sin hat om de ûnderskeppingskonstante nei 0 te twingen of net. In protte credible regression-analyze-beoefeners leauwe dat as it ynstellen fan de yntercept op nul (const = FALSE) nuttich liket te wêzen, dan is lineêre regression sels in ferkeard model foar de dataset. Oaren tinke dat de konstante kin wurde twongen ta nul yn bepaalde situaasjes, bygelyks, yn 'e kontekst fan regression diskontinuïteit ûntwerpen. Yn 't algemien is it oan te rieden om te gean mei de standert const=TRUE of yn'e measte gefallen weilitten.
- Akkuraatheid . De krektens fan 'e regressionfergeliking berekkene troch de LINEST-funksje hinget ôf fan' e fersprieding fan jo gegevenspunten. Hoe lineêr de gegevens, hoe krekter de resultaten fan de LINEST-formule.
- Oerstallige x-wearden . Yn guon situaasjes,ien of mear ûnôfhinklike x fariabelen hawwe miskien gjin ekstra foarsizzende wearde, en it fuortheljen fan sokke fariabelen út it regressionmodel hat gjin ynfloed op de krektens fan 'e foarseine y-wearden. Dit ferskynsel is bekend as "kollineariteit". De Excel LINEST-funksje kontrolearret op kollineariteit en lit alle oerstallige x -fariabelen wegerje dy't it identifisearret fan it model. De weilitten x fariabelen kinne wurde werkend oan 0 koeffizienten en 0 standert flater wearden.
- LINEST vs. SLOPE en INTERCEPT . De ûnderlizzende algoritme fan 'e LINEST-funksje ferskilt fan it algoritme dat brûkt wurdt yn 'e SLOPE- en INTERCEPT-funksjes. Dêrom, as de boarne gegevens net fêststeld of collinear binne, kinne dizze funksjes ferskate resultaten weromjaan.
Excel LINEST-funksje wurket net
As jo LINEST-formule in flater smyt of in ferkearde útfier produseart , De kâns is grut dat it troch ien fan 'e folgjende redenen komt:
- As de LINEST-funksje mar ien getal (hellingkoëffisjint) jout, hawwe jo it nei alle gedachten as in reguliere formule ynfierd, net in arrayformule. Wês wis dat jo Ctrl + Shift + Enter drukke om de formule goed te foltôgjen. As jo dit dogge, wurdt de formule ynsletten yn 'e {krullende heakjes} dy't sichtber binne yn 'e formulebalke.
- #REF! fersin. Komt foar as de bekende_x's en bekende_y's berik ferskillende dimensjes hawwe.
- #VALUE! fersin. Komt foar as bekende_x's of bekende_y's befettet op syn minst ien lege sel, tekstwearde of tekstfertsjintwurdiging fan in nûmer dat Excel net herkent as in numerike wearde. Ek komt de #VALUE-flater foar as it argumint const of stats net evaluearre wurde kin op TRUE of FALSE.
Dat is hoe't jo LINEST yn Excel brûke foar in ienfâldige en meardere lineêre regression analyze. Om de formules besprutsen yn dizze tutorial tichterby te besjen, binne jo wolkom om ús foarbyldwurkboek hjirûnder te downloaden. Ik tankje jo foar it lêzen en hoopje jo nije wike op ús blog te sjen!
Oefeningswurkboek foar download
Excel LINEST-funksjefoarbylden (.xlsx-bestân)
(jout de steilheid fan 'e regressionline oan, d.w.s. de feroaringssnelheid foar y as x feroaret).
Yn syn basisfoarm jout de LINEST-funksje de ôfsnijing (a) en de helling (b) werom. foar de regression-fergeliking. Opsjoneel kin it ek ekstra statistyk weromjaan foar de regression-analyse lykas werjûn yn dit foarbyld.
LINEST-funksjesyntaksis
De syntaksis fan 'e Excel-LINEST-funksje is as folget:
LINEST(bekend_y's , [bekende_x's], [const], [statistiken])Wêr:
- bekende_y's (ferplicht) is in berik fan de ôfhinklike y -wearden yn de regression fergeliking. Meastal is it in inkele kolom of in inkele rige.
- bekende_x's (opsjoneel) is in berik fan de ûnôfhinklike x-wearden. As it weilitten wurdt, wurdt oannommen dat it de array {1,2,3,...} is fan deselde grutte as bekende_y's .
- const (opsjoneel) - in logyske wearde dy't bepaalt hoe't de ûnderskepping (konstante a ) behannele wurde moat:
- As TRUE of weilitten wurdt, wurdt de konstante a normaal berekkene.
- As FALSE, wurdt de konstante a twongen nei 0 en de helling ( b -koëffisjint) wurdt berekkene om te passen by y=bx.
- statistiken (opsjoneel) is in logyske wearde dy't bepaalt of ekstra statistiken wurde útjûn of net:
- As TRUE jout de LINEST-funksje in array werom mei ekstra regressionstatistiken.
- As FALSE of weilitten, jout LINEST allinnich de intercept konstante en helling weromkoëffisjint(en).
Opmerking. Sûnt LINEST jout in array fan wearden, it moat wurde ynfierd as in array formule troch te drukken op de Ctrl + Shift + Enter fluchtoets. As it as in reguliere formule ynfierd wurdt, wurdt allinich de earste hellingkoëffisjint weromjûn.
Oanfoljende statistiken weromjûn troch LINEST
It argumint stats ynsteld op TRUE jout de LINEST-funksje de opdracht om de folgjende statistiken werom te jaan foar jo regression-analyze:
| Statistyk | Beskriuwing |
| Slope koëffisjint | b wearde yn y = bx + a |
| Intercept konstante | a wearde yn y = bx + a |
| Standert flater fan helling | De standert flaterwearde(s) foar de b koëffisjint(en). |
| Standert flater fan ûnderskepping | De standert flaterwearde foar de konstante a . |
| Bepalingskoëffisjint (R2) | Jout hoe goed de regressionfergeliking de relaasje tusken de fariabelen ferklearret. |
| Standertflater foar de Y-skatting | Toant de krektens fan 'e regression-analyse. |
| F-statistyk, of de F-observearre wearde | It wurdt brûkt om de F-test te dwaan foar de nulhypoteze om de algemiene fitheid fan it model te bepalen. |
| Graden fan fr eedom (df) | It oantal frijheidsgraden. |
| Regressionsom fan kwadraten | Joint oan hoefolle fan de fariaasje yn deôfhinklike fariabele wurdt ferklearre troch it model. |
| Residuele som fan kwadraten | Mjit de hoemannichte fariânsje yn 'e ôfhinklike fariabele dy't net ferklearre wurdt troch jo regressionmodel. |
De kaart hjirûnder toant de folchoarder wêryn LINEST in array fan statistiken weromjout:

Yn de lêste trije rigen, de #N/A flaters sille ferskine yn 'e tredde en folgjende kolommen dy't net fol binne mei gegevens. It is it standertgedrach fan de LINEST-funksje, mar as jo de flaternotaasjes ferbergje wolle, wikkel dan jo LINEST-formule yn IFERROR lykas yn dit foarbyld sjen litten.
Hoe kinne jo LINEST brûke yn Excel - formulefoarbylden
De LINEST-funksje kin lestich wêze om te brûken, foaral foar begjinners, om't jo net allinich in formule korrekt moatte bouwe, mar ek de útfier dêrfan goed ynterpretearje. Hjirûnder fine jo in pear foarbylden fan it brûken fan LINEST-formules yn Excel dy't hooplik sille helpe om de teoretyske kennis yn te sinkjen :)
Ienfâldige lineêre regression: helling berekkenje en ûnderskep
Om de ûnderskepping te krijen en de helling fan in regressionline, brûke jo de LINEST-funksje yn syn ienfâldichste foarm: leverje in berik fan de ôfhinklike wearden foar it bekende_y's argumint en in berik fan de ûnôfhinklike wearden foar de bekende_x's argumint. De lêste twa arguminten kinne ynsteld wurde op TRUE of weilitten.
Bygelyks mei y -wearden (ferkeapnûmers) yn C2:C13 en x-wearden(advertinsjekosten) yn B2:B13, ús lineêre regressionformule is sa ienfâldich as:
=LINEST(C2:C13,B2:B13)
Om it korrekt yn jo wurkblêd yn te fieren, selektearje twa neistlizzende sellen yn deselde rige, E2: F2 yn dit foarbyld, typ de formule, en druk op Ctrl + Shift + Enter om it te foltôgjen.
De formule sil de hellingkoëffisjint yn 'e earste sel (E2) en de interceptkonstante yn' e twadde sel (F2) weromjaan ):
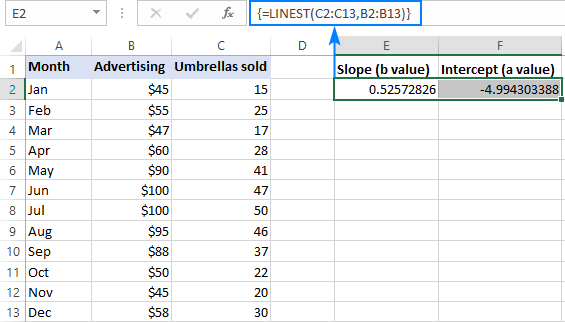
De helling is likernôch 0,52 (ôfrûn op twa desimale plakken). It betsjut dat as x ferheget mei 1, y ferheget mei 0,52.
De Y-ôfslach is negatyf -4,99. It is de ferwachte wearde fan y as x=0. As it op in grafyk útset is, is it de wearde wêrop de regressionline de y-as krúst.
Lear de boppesteande wearden oan in ienfâldige lineêre regressionfergeliking, en jo krije de folgjende formule om it ferkeapnûmer te foarsizzen basearre op de reklamekosten:
y = 0.52*x - 4.99
As jo bygelyks $50 oan reklame besteegje, wurdt jo ferwachte dat jo 21 paraplu's ferkeapje:
0.52*50 - 4.99 = 21.01
De hellings- en ûnderskeppingswearden kinne ek apart krigen wurde troch de oerienkommende funksje te brûken of troch de LINEST-formule te nesteljen yn INDEX:
Slope
=SLOPE(C2:C13,B2:B13)
=INDEX(LINEST(C2:C13,B2:B13),1)
Intercept
=INTERCEPT(C2:C13,B2:B13)
=INDEX(LINEST(C2:C13,B2:B13),2)
Lykas werjûn yn it skermôfbylding hjirûnder, jouwe alle trije formules deselde resultaten:

Meardere lineêre regression: helling en ûnderskepping
In gefal jo hawwetwa of mear ûnôfhinklike fariabelen, wês wis dat jo se ynfiere yn neistlizzende kolommen, en leverje dat hiele berik oan it bekende_x's argumint.
Bygelyks mei ferkeapnûmers ( y wearden) yn D2:D13, advertinsjekosten (ien set fan x-wearden) yn B2:B13 en gemiddelde moanlikse delslach (in oare set fan x -wearden) yn C2:C13, jo brûke dizze formule:
=LINEST(D2:D13,B2:C13)
Om't formule in array fan 3 wearden sil werombringe (2 hellingkoëffisjinten en de ûnderskeppingskonstante), selektearje wy trije oanienkommende sellen yn deselde rige, fier de formule yn en drukke op de Ctrl + Shift + Enter fluchtoets.
Tink derom dat de formule foar meardere regression de hellingkoëffisiënten weromjout yn 'e omkearde folchoarder fan 'e ûnôfhinklike fariabelen (fan rjochts nei lofts), dat is b n , b n-1 , …, b 2 , b 1 :
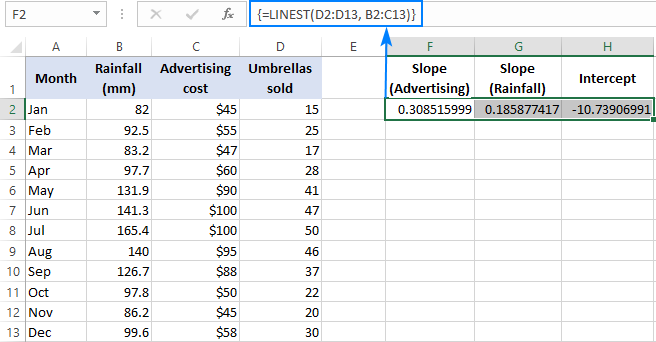
Om it ferkeapnûmer te foarsizzen, leverje wy de wearden weromjûn troch de LINEST-formule oan de fergeliking foar meardere regression:
y = 0.3*x 2 + 0.19*x 1 - 10.74
Bgl genôch, mei $ 50 bestege oan reklame en in gemiddelde moanlikse delslach fan 100 mm, wurdt ferwachte dat jo sawat 23 paraplu's ferkeapje:
0.3*50 + 0.19*100 - 10.74 = 23.26
Ienfâldige lineêre regression: foarsizze ôfhinklike fariabele
Njonken it berekkenjen fan de a - en b -wearden foar de regression-fergeliking, kin de Excel LINEST-funksje ek de ôfhinklike fariabele (y) skatte op basis fan de bekende ûnôfhinklikefariabele (x). Hjirfoar brûke jo LINEST yn kombinaasje mei de SUM- of SUMPRODUCT-funksje.
Hier is bygelyks hoe't jo it oantal parapluferkeapen foar de kommende moanne, sis oktober, kinne berekkenje op basis fan ferkeap yn 'e foargeande moannen en It reklamebudzjet fan oktober fan $ 50:
=SUM(LINEST(C2:C10, B2:B10)*{50,1})
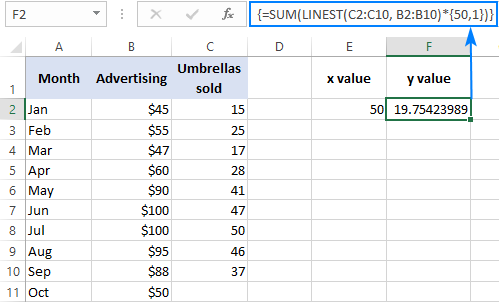
Ynstee fan hardkodearjen fan de x -wearde yn 'e formule, kinne jo it leverje as in sel ferwizing. Yn dit gefal moatte jo de konstante 1 yn guon sel ek ynfiere, om't jo referinsjes en wearden net kinne mingje yn in arraykonstante.
Mei de x -wearde yn E2 en de konstante 1 yn F2, ien fan 'e ûndersteande formules sil in traktaasje wurkje:
Reguliere formule (ynfierd troch op Enter te drukken):
=SUMPRODUCT(LINEST(C2:C10, B2:B10)*(E2:F2))
Arrayformule (ynfierd troch te drukken op Ctrl + Shift + Enter ):
=SUM(LINEST(C2:C10, B2:B10)*(E2:F2))
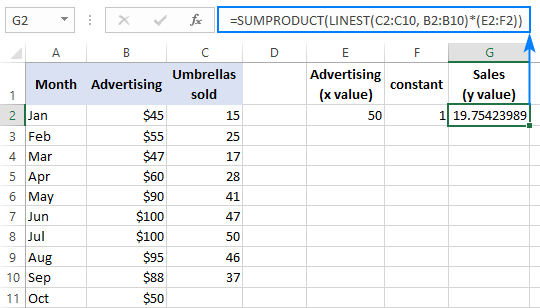
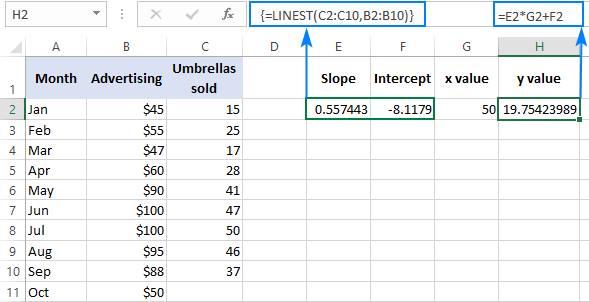
Om it resultaat te ferifiearjen, kinne jo de yntercept en helling krije foar deselde gegevens, en brûk dan de lineêre regressionformule om berekkenje y :
=E2*G2+F2
Dêr't E2 de helling is, G2 de x -wearde is, en F2 it ôfsûndering is:
Meardere regression: foarsizze ôfhinklike fariabele
As jo te krijen hawwe mei ferskate foarsizzers, dus in pear ferskillende sets fan x -wearden, befetsje al dy foarsizzers yn 'e array konstante. Bygelyks, mei it reklamebudzjet fan $ 50 (x 2 ) en in gemiddelde moanlikse delslach fan 100 mm (x 1 ), giet de formule asfolget:
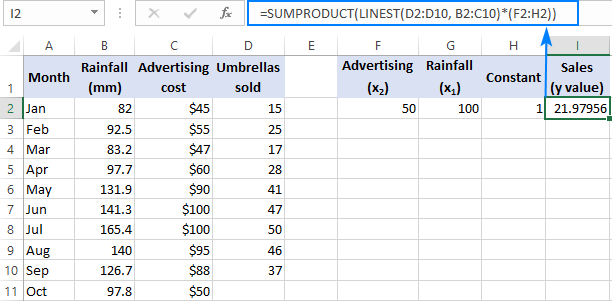
=SUM(LINEST(D2:D10, B2:C10)*{50,100,1})
Dêr't D2:D10 de bekende y -wearden binne en B2:C10 twa sets fan x -wearden binne:

Let op de folchoarder fan de x -wearden yn de arraykonstante. Lykas earder oanjûn, as de Excel LINEST-funksje wurdt brûkt om meardere regression te dwaan, jout it de hellingkoëffisjinten werom fan rjochts nei lofts. Yn ús foarbyld wurdt de Reklame -koëffisjint earst weromjûn, en dan de Reinfall -koëffisjint. Om it foarseine ferkeapnûmer goed te berekkenjen, moatte jo de koeffizienten fermannichfâldigje mei de oerienkommende x -wearden, sadat jo de eleminten fan 'e arraykonstante yn dizze folchoarder sette: {50,100,1}. It lêste elemint is 1, om't de lêste wearde weromjûn troch LINEST de ûnderskepping is dy't net feroare wurde moat, dus jo fermannichfâldigje it gewoan mei 1.
Ynstee fan in arraykonstante te brûken, kinne jo alle x-fariabelen ynfiere yn guon sellen, en ferwize dy sellen yn jo formule lykas wy diene yn it foarige foarbyld.
Reguliere formule:
=SUMPRODUCT(LINEST(D2:D10, B2:C10)*(F2:H2))
Arrayformule:
=SUM(LINEST(D2:D10, B2:C10)*(F2:H2))
Wêr't F2 en G2 de x -wearden binne en H2 1 is:
LINEST-formule: ekstra regressionstatistiken
Sa't jo miskien ûnthâlde, om mear statistiken te krijen foar jo regression-analyse, sette jo TRUE yn it lêste argumint fan 'e LINEST-funksje. Tapast op ús stekproefgegevens nimt de formule de folgjende foarm oan:
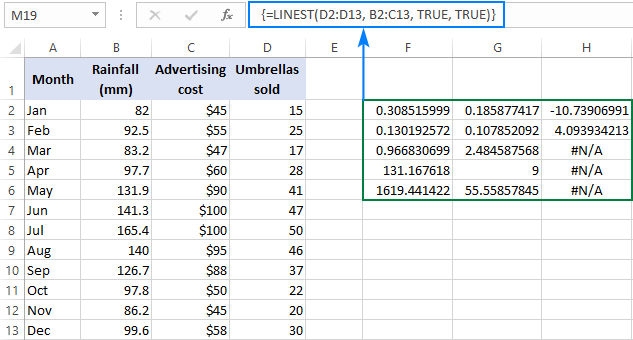
=LINEST(D2:D13, B2:C13, TRUE, TRUE)
Om't wy 2 ûnôfhinklik hawwefariabelen yn kolommen B en C, selektearje wy in rage besteande út 3 rigen (twa x wearden + ûnderskepping) en 5 kolommen, fier de boppesteande formule yn, druk op Ctrl + Shift + Enter , en krije dit resultaat:
Om de #N/A flaters kwyt te reitsjen, kinne jo LINEST yn IFERROR nêstje sa:
=IFERROR(LINEST(D2:D13, B2:C13, TRUE, TRUE), "")
De skermôfbylding hjirûnder toant it resultaat en ferklearret wat elk getal betsjut:

De hellingkoëffisjinten en de Y-ôfsnijing binne útlein yn 'e foargeande foarbylden, dus litte wy de oare statistiken efkes sjen.
Bepalingskoëffisjint (R2). De wearde fan R2 is it resultaat fan it dielen fan de regressionsom fan kwadraten troch de totale som fan kwadraten. It fertelt jo hoefolle y wearden wurde ferklearre troch x fariabelen. It kin elk nûmer wêze fan 0 oant 1, dat is 0% oant 100%. Yn dit foarbyld is R2 sawat 0,97, wat betsjuttet dat 97% fan ús ôfhinklike fariabelen (parapluferkeap) wurde ferklearre troch de ûnôfhinklike fariabelen (reklame + gemiddelde moanlikse delslach), wat in poerbêste fit is!
Standert flaters . Yn 't algemien litte dizze wearden de krektens fan' e regressionanalyse sjen. Hoe lytser de sifers, hoe wissiger jo kinne wêze oer jo regressionmodel.
F statistic . Jo brûke de F-statistyk om de nulhypoteze te stypjen of te fersmiten. It is oan te rieden om de F-statistyk te brûken yn kombinaasje mei de P-wearde by it besluten as de totale resultaten binne
