
Indholdsfortegnelse
Denne vejledning forklarer syntaksen for LINEST-funktionen og viser, hvordan du bruger den til at udføre lineær regressionsanalyse i Excel.
Microsoft Excel er ikke et statistisk program, men det har dog en række statistiske funktioner. En af disse funktioner er LINEST, som er designet til at udføre lineær regressionsanalyse og returnere relaterede statistikker. I denne tutorial for begyndere vil vi kun berøre teori og underliggende beregninger lidt. Vores hovedfokus vil være på at give dig en formel, der simpelthen virker ogkan nemt tilpasses til dine data.
Excel LINEST-funktion - syntaks og grundlæggende anvendelser
LINEST-funktionen beregner statistikkerne for en lige linje, der forklarer forholdet mellem den uafhængige variabel og en eller flere afhængige variabler, og returnerer et array, der beskriver linjen. Funktionen bruger mindste kvadrater metoden til at finde den bedste tilpasning til dine data. Ligningen for linjen er som følger.
Simpel lineær regressionsligning:
y = bx + aMultipel regressionsligning:
y = b 1 x 1 + b 2 x 2 + ... + b n x n + aHvor:
- y - den afhængige variabel, som du forsøger at forudsige.
- x - den uafhængige variabel, du bruger til at forudsige y .
- a - skæringspunktet (angiver, hvor linjen skærer Y-aksen).
- b - hældningen (angiver stejlheden af regressionslinjen, dvs. ændringshastigheden for y som følge af ændringer i x).
I sin grundform returnerer LINEST-funktionen interceptet (a) og hældningen (b) for regressionsligningen. Den kan eventuelt også returnere yderligere statistikker for regressionsanalysen som vist i dette eksempel.
LINEST-funktionssyntaks
Syntaksen for Excel LINEST-funktionen er som følger:
LINEST(known_y's, [known_x's], [const], [stats])Hvor:
- known_y's (påkrævet) er en række af de afhængige y -værdierne i regressionsligningen. Normalt er det en enkelt kolonne eller en enkelt række.
- known_x's (valgfrit) er et interval af de uafhængige x-værdier. Hvis det udelades, antages det at være arrayet {1,2,3,...} af samme størrelse som known_y's .
- const (valgfri) - en logisk værdi, der bestemmer, hvordan interceptet (konstant a ) bør behandles:
- Hvis den er TRUE eller udelades, vil konstanten a beregnes normalt.
- Hvis FALSE, er konstanten a tvinges til 0, og hældningen ( b koefficient) beregnes for at passe til y=bx.
- statistik (valgfri) er en logisk værdi, der bestemmer, om der skal udgives yderligere statistikker eller ej:
- Hvis den er TRUE, returnerer LINEST-funktionen et array med yderligere regressionsstatistikker.
- Hvis LINEST er FALSK eller udelades, returnerer LINEST kun interceptkonstanten og hældningskoefficienten/koefficienterne.
Bemærk: Da LINEST returnerer et array af værdier, skal den indtastes som en arrayformel ved at trykke på genvejen Ctrl + Shift + Enter. Hvis den indtastes som en almindelig formel, returneres kun den første hældningskoefficient.
Yderligere statistikker, der returneres af LINEST
statistik argumentet sat til TRUE giver LINEST-funktionen besked om at returnere følgende statistikker for din regressionsanalyse:
| Statistik | Beskrivelse |
| Hældningskoefficient | b-værdien i y = bx + a |
| Interceptkonstant | en værdi i y = bx + a |
| Standardfejl for hældning | Standardfejlværdien(-værdierne) for b-koefficienten(erne). |
| Standardfejl for intercept | Standardfejlværdien for konstanten a . |
| Bestemmelseskoefficient (R2) | Angiver, hvor godt regressionsligningen forklarer sammenhængen mellem variablerne. |
| Standardfejl for Y-estimatet | Viser regressionsanalysens præcision. |
| F-statistik eller den F-observerede værdi | Den bruges til at udføre F-testen for nulhypotesen for at bestemme modellens generelle tilpasningsevne. |
| Frihedsgrader (df) | Antallet af frihedsgrader. |
| Regressionssummen af kvadrater | Angiver, hvor stor en del af variationen i den afhængige variabel der forklares af modellen. |
| Resterende sum af kvadrater | Måler den mængde varians i den afhængige variabel, som ikke forklares af din regressionsmodel. |
Nedenstående kort viser den rækkefølge, hvori LINEST returnerer et array af statistikker:

I de sidste tre rækker vises #N/A-fejlene i den tredje og de efterfølgende kolonner, som ikke er fyldt med data. Det er standardadfærden for LINEST-funktionen, men hvis du vil skjule fejlnoteringerne, skal du indpakke din LINEST-formel i IFERROR som vist i dette eksempel.
Sådan bruger du LINEST i Excel - eksempler på formler
LINEST-funktionen kan være vanskelig at bruge, især for nybegyndere, fordi du ikke blot skal opbygge en formel korrekt, men også fortolke dens output korrekt. Nedenfor finder du et par eksempler på brug af LINEST-formler i Excel, som forhåbentlig vil hjælpe dig med at få den teoretiske viden ind :)
Simpel lineær regression: beregn hældning og intercept
For at få interceptet og hældningen af en regressionslinje bruger du LINEST-funktionen i sin enkleste form: angiv et interval af de afhængige værdier for den known_y's argumentet og et interval af de uafhængige værdier for den kendte_x's De sidste to argumenter kan sættes til TRUE eller udelades.
For eksempel med y værdier (salgstal) i C2:C13 og x-værdier (reklameomkostninger) i B2:B13, er vores lineære regressionsformel så enkel som:
=LINEST(C2:C13,B2:B13)
For at indtaste den korrekt i dit regneark skal du vælge to tilstødende celler i samme række, E2:F2 i dette eksempel, skrive formlen og trykke på Ctrl + Shift + Enter for at fuldføre den.
Formlen returnerer hældningskoefficienten i den første celle (E2) og interceptkonstanten i den anden celle (F2):
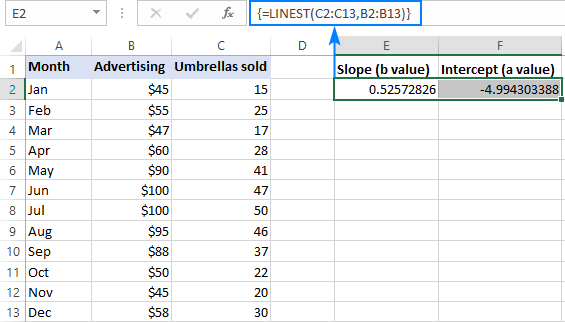
hældning er ca. 0,52 (afrundet til to decimaler). Det betyder, at når x øges med 1, y stiger med 0,52.
Y-intercept er negativ -4,99. Det er den forventede værdi af y når x=0. Hvis den er vist på en graf, er det den værdi, hvor regressionslinjen krydser y-aksen.
Hvis du indsætter ovenstående værdier i en simpel lineær regressionsligning, får du følgende formel til at forudsige salgstallet baseret på reklameomkostningerne:
y = 0,52*x - 4,99
Hvis du f.eks. bruger 50 USD på reklame, forventes det, at du sælger 21 paraplyer:
0.52*50 - 4.99 = 21.01
Værdierne for hældning og skæringspunkt kan også fås separat ved at bruge den tilsvarende funktion eller ved at indlejre LINEST-formlen i INDEX:
Hældning
=SLOPE(C2:C13,B2:B13)
=INDEX(LINEST(C2:C13,B2:B13),1)
Aflytning
=INTERCEPT(C2:C13,B2:B13)
=INDEX(LINEST(C2:C13,B2:B13),2)
Som vist i skærmbilledet nedenfor giver alle tre formler de samme resultater:

Multipel lineær regression: hældning og intercept
Hvis du har to eller flere uafhængige variabler, skal du sørge for at indtaste dem i tilstødende kolonner og levere hele dette område til kendte_x's argument.
For eksempel med salgstal ( y værdier) i D2:D13, reklameomkostninger (et sæt x-værdier) i B2:B13 og gennemsnitlig månedlig nedbør (et andet sæt x-værdier) i B2:B13 og gennemsnitlig månedlig nedbør (et andet sæt x værdier) i C2:C13, bruger du denne formel:
=LINEST(D2:D13,B2:C13)
Da formlen skal returnere et array med 3 værdier (2 hældningskoefficienter og interceptkonstanten), vælger vi tre sammenhængende celler i samme række, indtaster formlen og trykker på genvejen Ctrl + Shift + Enter.
Bemærk venligst, at formlen for multipel regression returnerer den hældningskoefficienter i den omvendt rækkefølge af de uafhængige variabler (fra højre til venstre), dvs. b n , b n-1 , ..., b 2 , b 1 :
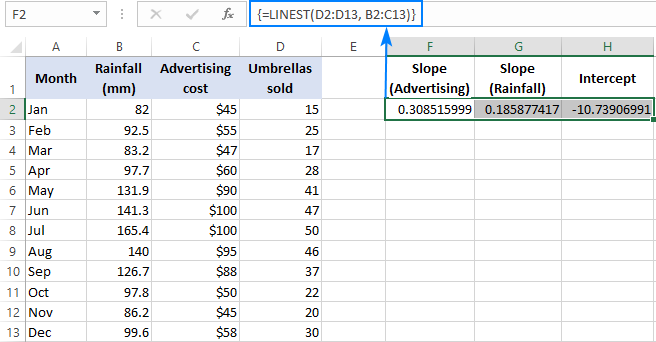
For at forudsige salgstallet leverer vi de værdier, som LINEST-formlen returnerer, til den multiple regressionsligning:
y = 0,3*x 2 + 0.19*x 1 - 10.74
Hvis du f.eks. bruger 50 USD på reklame og en gennemsnitlig månedlig nedbørsmængde på 100 mm, forventes det, at du vil sælge ca. 23 paraplyer:
0.3*50 + 0.19*100 - 10.74 = 23.26
Simpel lineær regression: forudsige den afhængige variabel
Ud over at beregne den a og b værdier til regressionsligningen, kan Excel-funktionen LINEST også estimere den afhængige variabel (y) baseret på den kendte uafhængige variabel (x). Til dette formål bruger du LINEST i kombination med funktionen SUM eller SUMPRODUCT.
Sådan kan du f.eks. beregne antallet af paraplysalg for den næste måned, f.eks. oktober, baseret på salget i de foregående måneder og oktober måneds reklamebudget på 50 $:
=SUM(LINEST(C2:C10, B2:B10)*{50,1})
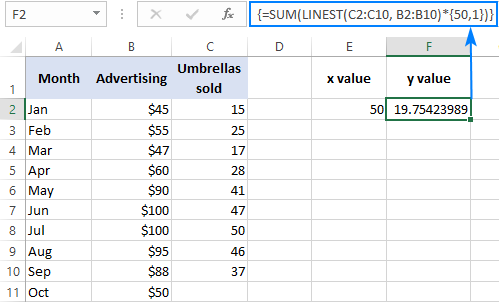
I stedet for at hardcode den x I dette tilfælde skal du også indtaste 1-konstanten i en celle, fordi du ikke kan blande referencer og værdier i en arraykonstant.
Med den x værdi i E2 og konstanten 1 i F2, vil en af nedenstående formler fungere fint:
Almindelig formel (indtastes ved at trykke på Enter ):
=SUMPRODUKT(LINEST(C2:C10, B2:B10)*(E2:F2))
Array-formel (indtastes ved at trykke på Ctrl + Shift + Enter ):
=SUM(LINEST(C2:C10, B2:B10)*(E2:F2))
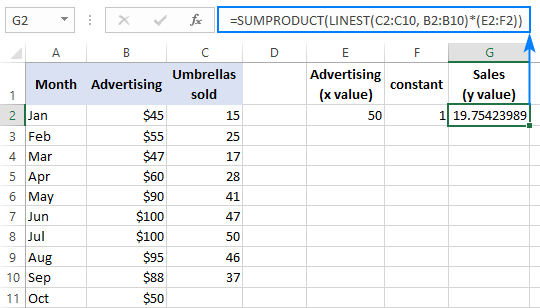
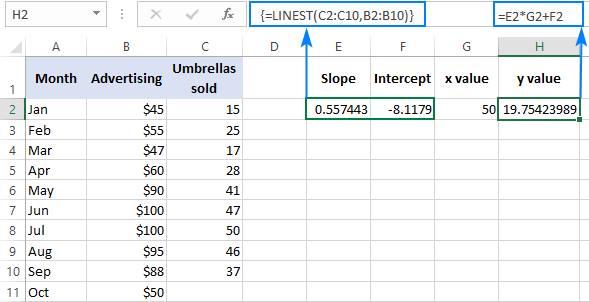
For at verificere resultatet kan du få interceptet og hældningen for de samme data og derefter bruge den lineære regressionsformel til at beregne y :
=E2*G2+F2
Hvor E2 er hældningen, G2 er x værdi, og F2 er interceptet:
Multipel regression: forudsige afhængig variabel
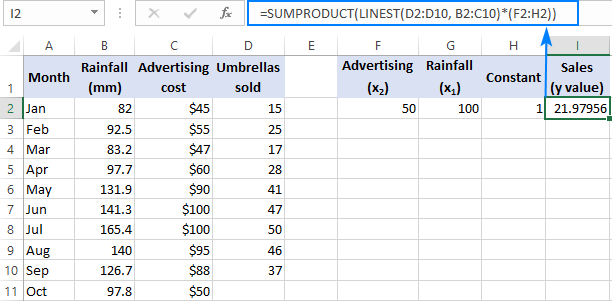
Hvis du har at gøre med flere prædiktorer, dvs. et par forskellige sæt af x værdier, skal du medtage alle disse prædiktorer i arrayet konstant. For eksempel, med et reklamebudget på 50 $ (x 2 ) og en gennemsnitlig månedlig nedbørsmængde på 100 mm (x 1 ), lyder formlen som følger:
=SUM(LINEST(D2:D10, B2:C10)*{50,100,1})
Hvor D2:D10 er de kendte y værdier og B2:C10 er to sæt af x værdier:

Vær opmærksom på rækkefølgen af de x værdier i arrayet konstant. Som tidligere påpeget returnerer Excel LINEST-funktionen, når den bruges til multipel regression, hældningskoefficienterne fra højre til venstre. I vores eksempel er det Reklame koefficienten returneres først, og derefter returneres Nedbør For at beregne det forudsagte salgstal korrekt skal du gange koefficienterne med den tilsvarende x værdier, så du sætter elementerne i arraykonstanten i denne rækkefølge: {50,100,1}. Det sidste element er 1, fordi den sidste værdi, der returneres af LINEST, er den intercept, der ikke skal ændres, så du ganger den blot med 1.
I stedet for at bruge en arraykonstant kan du indtaste alle x-variablerne i nogle celler og henvise til disse celler i din formel, som vi gjorde i det foregående eksempel.
Almindelig formel:
=SUMPRODUKT(LINEST(D2:D10, B2:C10)*(F2:H2))
Array-formel:
=SUM(LINEST(D2:D10, B2:C10)*(F2:H2))
Hvor F2 og G2 er de x værdier og H2 er 1:
LINEST-formlen: yderligere regressionsstatistik
Som du måske husker, skal du for at få flere statistikker til din regressionsanalyse indsætte TRUE i det sidste argument i LINEST-funktionen. Anvendt på vores eksempeldata får formlen følgende formular:
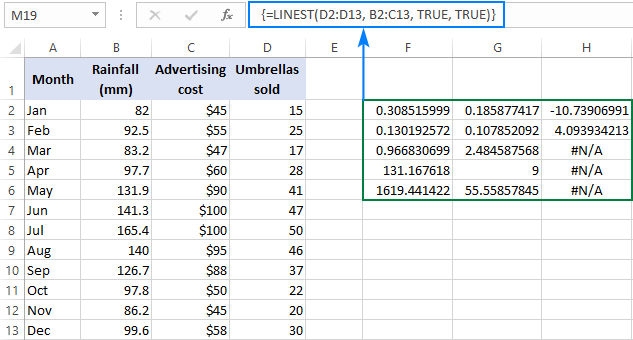
=LINEST(D2:D13, B2:C13, TRUE, TRUE)
Da vi har 2 uafhængige variabler i kolonne B og C, vælger vi en rage bestående af 3 rækker (to x-værdier + intercept) og 5 kolonner, indtaster ovenstående formel, trykker på Ctrl + Shift + Enter , og får dette resultat:
For at slippe af med #N/A-fejlene kan du indlejre LINEST i IFERROR på følgende måde:
=IFERROR(LINEST(D2:D13, B2:C13, TRUE, TRUE), "")
Skærmbilledet nedenfor viser resultatet og forklarer, hvad hvert tal betyder:

Hældningskoefficienterne og Y-interceptet blev forklaret i de foregående eksempler, så lad os se lidt på de andre statistikker.
Bestemmelseskoefficient (R2). Værdien R2 er resultatet af at dividere regressionens sum af kvadrater med den samlede sum af kvadrater. Den fortæller dig, hvor mange y værdier forklares ved x Det kan være et tal fra 0 til 1, dvs. fra 0 % til 100 %. I dette eksempel er R2 ca. 0,97, hvilket betyder, at 97 % af vores afhængige variabler (salg af paraplyer) forklares af de uafhængige variabler (reklame + gennemsnitlig månedlig nedbør), hvilket er en fremragende tilpasning!
Standardfejl Generelt viser disse værdier regressionsanalysens præcision. Jo mindre tallene er, jo mere sikker kan du være på din regressionsmodel.
F-statistik Du bruger F-statistikken til at støtte eller forkaste nulhypotesen. Det anbefales at bruge F-statistikken sammen med P-værdien, når du skal afgøre, om de samlede resultater er signifikante.
Frihedsgrader (df). LINEST-funktionen i Excel returnerer resterende frihedsgrader , som er den df i alt minus den regression df Du kan bruge frihedsgraderne til at få F-kritiske værdier i en statistisk tabel og derefter sammenligne de F-kritiske værdier med F-statistikken for at bestemme et konfidensniveau for din model.
Regressionssummen af kvadrater (også kendt som den forklaret summen af kvadrater , eller model summen af kvadrater Det er summen af de kvadrerede forskelle mellem de forudsagte y-værdier og middelværdien af y, beregnet med denne formel: =∑(ŷ - ȳ)2. Det angiver, hvor stor en del af variationen i den afhængige variabel, som din regressionsmodel forklarer.
Resterende sum af kvadrater Det er summen af de kvadrerede forskelle mellem de faktiske y-værdier og de forudsagte y-værdier. Den angiver, hvor stor en del af variationen i den afhængige variabel din model ikke forklarer. Jo mindre residual summen af kvadrater er i forhold til den samlede sum af kvadrater, jo bedre passer din regressionsmodel til dine data.
5 ting, du bør vide om LINEST-funktionen
Hvis du vil bruge LINEST-formler effektivt i dine regneark, skal du måske vide lidt mere om funktionens "indre mekanik":
- Known_y's og known_x's . i en simpel lineær regressionsmodel med kun ét sæt x-variabler, known_y's og known_x's kan være intervaller af enhver form, så længe de har det samme antal rækker og kolonner. Hvis du foretager en multipel regressionsanalyse med mere end ét sæt uafhængige x variabler, known_y's skal være en vektor, dvs. et område med én række eller én kolonne.
- Tvinge konstanten til nul . Når den const argumentet er TRUE eller udelades, vil a konstant (intercept) beregnes og indgår i ligningen: y=bx + a. Hvis const er sat til FALSE, anses interceptet for at være lig 0 og udelades fra regressionsligningen: y=bx.
Inden for statistik har det i årtier været diskuteret, om det giver mening at tvinge interceptkonstanten til 0 eller ej. Mange troværdige regressionsanalysefolk mener, at hvis det synes nyttigt at sætte interceptet til nul (const=FALSE), så er lineær regression i sig selv en forkert model for datasættet. Andre mener, at konstanten kan tvinges til nul i visse situationer, f.eks,Generelt anbefales det at vælge standard const=TRUE eller udelades i de fleste tilfælde.
- Nøjagtighed Nøjagtigheden af den regressionsligning, der beregnes med LINEST-funktionen, afhænger af spredningen af dine datapunkter. Jo mere lineære dataene er, jo mere nøjagtige er resultaterne af LINEST-formlen.
- Redundante x-værdier . I visse situationer kan en eller flere uafhængige x variabler har måske ingen yderligere prædiktiv værdi, og hvis sådanne variabler fjernes fra regressionsmodellen, påvirker det ikke nøjagtigheden af de forudsagte y-værdier. Dette fænomen er kendt som "kollinearitet". Excel-funktionen LINEST kontrollerer kollinearitet og udelader alle overflødige x variabler, som den identificerer fra modellen. De udeladte x variabler kan genkendes ved 0 koefficienter og 0 standardfejlværdier.
- LINJEST vs. SLOPE og INTERCEPT Den underliggende algoritme for LINEST-funktionen adskiller sig fra den algoritme, der anvendes i SLOPE- og INTERCEPT-funktionerne. Når kildedataene er ubestemte eller kollineære, kan disse funktioner derfor give forskellige resultater.
Excel LINEST-funktionen fungerer ikke
Hvis din LINEST-formel giver en fejl eller et forkert output, er der stor sandsynlighed for, at det skyldes en af følgende årsager:
- Hvis LINEST-funktionen kun returnerer ét tal (hældningskoefficient), har du sandsynligvis indtastet den som en almindelig formel og ikke som en array-formel. Sørg for at trykke på Ctrl + Shift + Enter for at fuldføre formlen korrekt. Når du gør dette, bliver formlen omsluttet af {krøllede parenteser}, der er synlige i formellinjen.
- #REF! fejl. Opstår, hvis known_x's og known_y's områder har forskellige dimensioner.
- #VALUE! fejl. Opstår, hvis known_x's eller known_y's indeholder mindst én tom celle, en tekstværdi eller en tekstrepræsentation af et tal, som Excel ikke genkender som en numerisk værdi. Fejlen #VALUE opstår også, hvis const eller statistik argumentet kan ikke evalueres til TRUE eller FALSE.
Sådan bruger du LINEST i Excel til en simpel og multipel lineær regressionsanalyse. Hvis du vil se nærmere på de formler, der er beskrevet i denne vejledning, er du velkommen til at downloade vores prøvearbejdsbog nedenfor. Tak for læsningen og håber at se dig på vores blog i næste uge!
Arbejdsbog til download
Eksempler på Excel LINEST-funktioner (.xlsx-fil)
