
Obsah
Tento návod vysvetľuje syntax funkcie LINEST a ukazuje, ako ju použiť na vykonanie lineárnej regresnej analýzy v programe Excel.
Microsoft Excel nie je štatistický program, má však množstvo štatistických funkcií. Jednou z takýchto funkcií je LINEST, ktorá je určená na vykonávanie lineárnej regresnej analýzy a vrátenie súvisiacich štatistík. V tomto návode pre začiatočníkov sa budeme len zľahka dotýkať teórie a základných výpočtov. Zameriame sa hlavne na to, aby ste získali vzorec, ktorý jednoducho funguje amožno ľahko prispôsobiť vašim údajom.
Funkcia Excel LINEST - syntax a základné použitie
Funkcia LINEST vypočíta štatistiku priamky, ktorá vysvetľuje vzťah medzi nezávislou premennou a jednou alebo viacerými závislými premennými, a vráti pole opisujúce priamku. najmenšie štvorce Metóda na nájdenie najlepšieho prispôsobenia pre vaše údaje. Rovnica pre priamku je nasledovná.
Jednoduchá lineárna regresná rovnica:
y = bx + aRovnica viacnásobnej regresie:
y = b 1 x 1 + b 2 x 2 + ... + b n x n + aKde:
- y - závislej premennej, ktorú sa snažíte predpovedať.
- x - nezávislá premenná, ktorú používate na predpovedanie y .
- a - priesečník (označuje miesto, kde priamka pretína os Y).
- b - sklon (udáva strmosť regresnej priamky, t. j. rýchlosť zmeny y pri zmene x).
V základnej podobe funkcia LINEST vracia pre regresnú rovnicu intercept (a) a sklon (b). Voliteľne môže vrátiť aj ďalšie štatistiky regresnej analýzy, ako je uvedené v tomto príklade.
Syntax funkcie LINEST
Syntax funkcie Excel LINEST je nasledujúca:
LINEST(known_y's, [known_x's], [const], [stats])Kde:
- known_y's (požadované) je rozsah závislej hodnoty y -hodnoty v regresnej rovnici. Zvyčajne je to jeden stĺpec alebo jeden riadok.
- known_x's (nepovinné) je rozsah nezávislých hodnôt x. Ak sa vynechá, predpokladá sa, že je to pole {1,2,3,...} rovnakej veľkosti ako known_y's .
- const (nepovinné) - logická hodnota, ktorá určuje, ako bude intercept (konštanta) a ) by mali byť ošetrené:
- Ak je TRUE alebo je vynechaná, konštanta a sa vypočíta normálne.
- Ak je FALSE, konštanta a sa nastaví na hodnotu 0 a sklon ( b koeficient) sa vypočíta tak, aby zodpovedal y=bx.
- štatistiky (nepovinné) je logická hodnota, ktorá určuje, či sa majú vypisovať ďalšie štatistiky alebo nie:
- Ak je TRUE, funkcia LINEST vráti pole s ďalšími regresnými štatistikami.
- Ak je hodnota FALSE alebo je vynechaná, LINEST vráti iba konštantu interceptu a koeficient(y) sklonu.
Poznámka: Keďže LINEST vracia pole hodnôt, musí byť zadaný ako vzorec poľa stlačením klávesovej skratky Ctrl + Shift + Enter. Ak je zadaný ako bežný vzorec, vráti sa len prvý koeficient sklonu.
Ďalšie štatistické údaje vrátené spoločnosťou LINEST
Stránka štatistiky argument nastavený na TRUE prikazuje funkcii LINEST, aby vrátila nasledujúce štatistiky pre vašu regresnú analýzu:
| Štatistika | Popis |
| Koeficient sklonu | b hodnota v y = bx + a |
| Konštanta interceptu | hodnota v y = bx + a |
| Štandardná chyba sklonu | Hodnota(-y) štandardnej chyby pre koeficient(-y) b. |
| Štandardná chyba interceptu | Hodnota štandardnej chyby pre konštantu a . |
| Koeficient determinácie (R2) | Ukazuje, ako dobre regresná rovnica vysvetľuje vzťah medzi premennými. |
| Štandardná chyba pre odhad Y | Zobrazuje presnosť regresnej analýzy. |
| F-štatistika alebo pozorovaná hodnota F | Používa sa na vykonanie F-testu pre nulovú hypotézu na určenie celkovej vhodnosti modelu. |
| Stupne voľnosti (df) | Počet stupňov voľnosti. |
| Regresný súčet štvorcov | Udáva, akú časť variability závislej premennej vysvetľuje model. |
| Zvyškový súčet štvorcov | Meria množstvo rozptylu závislej premennej, ktoré nie je vysvetlené vaším regresným modelom. |
Nasledujúca mapa zobrazuje poradie, v akom LINEST vracia pole štatistík:

V posledných troch riadkoch sa v treťom a ďalších stĺpcoch, ktoré nie sú vyplnené údajmi, zobrazia chyby #N/A. Je to predvolené správanie funkcie LINEST, ale ak chcete skryť chybové zápisy, zabaľte vzorec LINEST do IFERROR, ako je uvedené v tomto príklade.
Ako používať LINEST v programe Excel - príklady vzorcov
Používanie funkcie LINEST môže byť najmä pre začiatočníkov zložité, pretože by ste mali vzorec nielen správne zostaviť, ale aj správne interpretovať jeho výstup. Nižšie nájdete niekoľko príkladov použitia vzorcov LINEST v Exceli, ktoré vám, dúfajme, pomôžu utápať teoretické vedomosti :)
Jednoduchá lineárna regresia: výpočet sklonu a interceptu
Ak chcete získať priesečník a sklon regresnej priamky, použite funkciu LINEST v jej najjednoduchšej forme: zadajte rozsah závislých hodnôt pre known_y's a rozsah nezávislých hodnôt pre known_x's Posledné dva argumenty môžu byť nastavené na TRUE alebo vynechané.
Napríklad s y hodnoty (predajné čísla) v C2:C13 a hodnoty x (náklady na reklamu) v B2:B13, náš lineárny regresný vzorec je jednoduchý:
=LINEST(C2:C13,B2:B13)
Ak ho chcete správne zadať do pracovného hárka, vyberte dve susedné bunky v tom istom riadku, v tomto príklade E2:F2, zadajte vzorec a stlačte klávesovú skratku Ctrl + Shift + Enter, aby ste ho dokončili.
Vzorec vráti koeficient sklonu v prvej bunke (E2) a konštantu intercepcie v druhej bunke (F2):
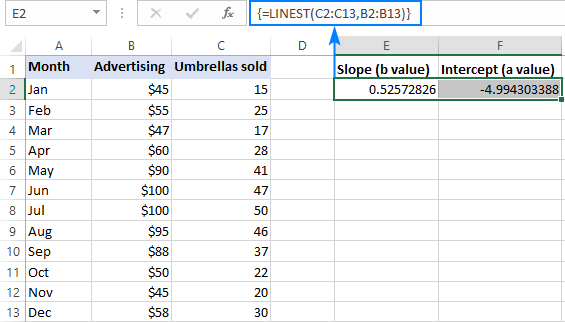
Stránka sklon je približne 0,52 (zaokrúhlené na dve desatinné miesta). x sa zvýši o 1, y sa zvyšuje o 0,52.
Stránka Y-intercept je záporná -4,99. Je to očakávaná hodnota y ak je x=0. Ak sa znázorní na grafe, je to hodnota, pri ktorej regresná priamka pretína os y.
Dosadením uvedených hodnôt do jednoduchej rovnice lineárnej regresie získate nasledujúci vzorec na predpovedanie počtu predajov na základe nákladov na reklamu:
y = 0,52*x - 4,99
Ak napríklad miniete 50 USD na reklamu, očakáva sa, že predáte 21 dáždnikov:
0.52*50 - 4.99 = 21.01
Hodnoty sklonu a interceptu možno získať aj samostatne pomocou príslušnej funkcie alebo vnorením vzorca LINEST do INDEXU:
Svah
=SLOPE(C2:C13,B2:B13)
=INDEX(LINEST(C2:C13,B2:B13),1)
Intercept
=INTERCEPT(C2:C13,B2:B13)
=INDEX(LINEST(C2:C13,B2:B13),2)
Ako je znázornené na obrázku nižšie, všetky tri vzorce poskytujú rovnaké výsledky:

Viacnásobná lineárna regresia: sklon a priesečník
V prípade, že máte dve alebo viac nezávislých premenných, nezabudnite ich zadať do susedných stĺpcov a celý tento rozsah dodajte do known_x's argument.
Napríklad pri predajných číslach ( y (jeden súbor hodnôt x) v D2:D13, náklady na reklamu (jeden súbor hodnôt x) v B2:B13 a priemerné mesačné zrážky (ďalší súbor hodnôt x) v B2:B13. x hodnoty) v C2:C13, použite tento vzorec:
=LINEST(D2:D13,B2:C13)
Keďže vzorec vráti pole 3 hodnôt (2 koeficienty sklonu a konštantu intercepcie), vyberieme tri susediace bunky v tom istom riadku, zadáme vzorec a stlačíme klávesovú skratku Ctrl + Shift + Enter.
Upozorňujeme, že vzorec viacnásobnej regresie vracia koeficienty sklonu v opačné poradie nezávislých premenných (sprava doľava), t. j. b n , b n-1 , ..., b 2 , b 1 :
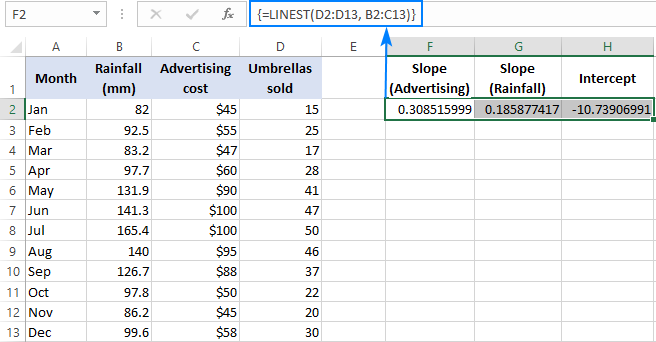
Ak chceme predpovedať počet predajov, do rovnice viacnásobnej regresie dosadíme hodnoty získané vzorcom LINEST:
y = 0,3*x 2 + 0.19*x 1 - 10.74
Napríklad pri výdavkoch 50 USD na reklamu a priemerných mesačných zrážkach 100 mm sa očakáva, že predáte približne 23 dáždnikov:
0.3*50 + 0.19*100 - 10.74 = 23.26
Jednoduchá lineárna regresia: predpovedanie závislej premennej
Okrem výpočtu a a b hodnôt pre regresnú rovnicu, funkcia Excel LINEST dokáže odhadnúť aj závislú premennú (y) na základe známej nezávislej premennej (x). Na tento účel použijete LINEST v kombinácii s funkciou SUM alebo SUMPRODUCT.
Napríklad takto môžete vypočítať počet predajov dáždnikov v nasledujúcom mesiaci, napríklad v októbri, na základe predajov v predchádzajúcich mesiacoch a októbrového rozpočtu na reklamu vo výške 50 USD:
=SUM(LINEST(C2:C10, B2:B10)*{50,1})
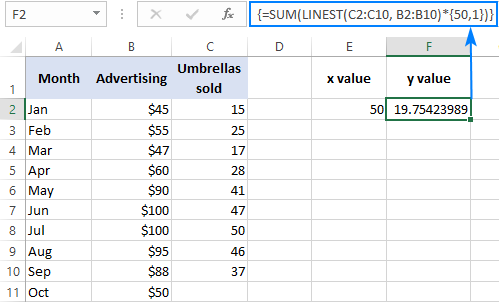
Namiesto pevného kódovania x hodnotu vo vzorci, môžete ju uviesť ako odkaz na bunku. V tomto prípade musíte v niektorej bunke zadať aj konštantu 1, pretože v konštantnom poli nemôžete miešať odkazy a hodnoty.
S x hodnotu v E2 a konštantu 1 v F2, bude fungovať ktorýkoľvek z nasledujúcich vzorcov:
Pravidelný vzorec (zadáva sa stlačením klávesu Enter ):
=SUMPRODUKT(LINEST(C2:C10, B2:B10)*(E2:F2))
Vzorec poľa (zadáva sa stlačením klávesovej skratky Ctrl + Shift + Enter ):
=SUM(LINEST(C2:C10, B2:B10)*(E2:F2))
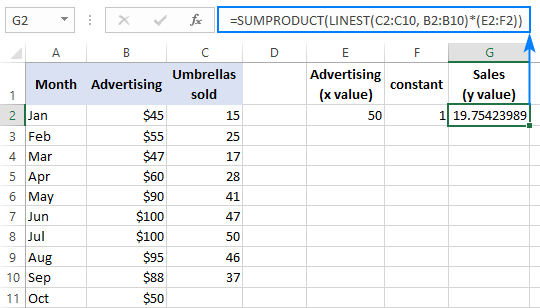
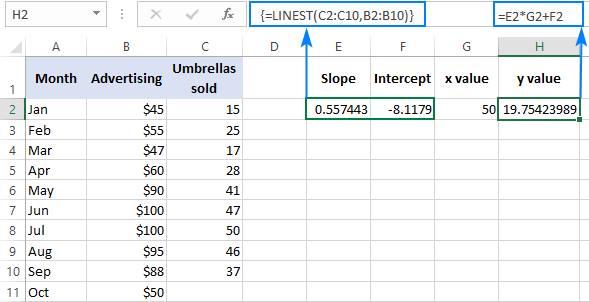
Na overenie výsledku môžete pre tie isté údaje získať intercept a sklon a potom použiť vzorec lineárnej regresie na výpočet y :
=E2*G2+F2
Kde E2 je sklon, G2 je x a F2 je intercept:
Viacnásobná regresia: predpovedanie závislej premennej
V prípade, že sa zaoberáte viacerými prediktormi, t. j. niekoľkými rôznymi súbormi x zahrňte všetky tieto prediktory do konštantného poľa. Napríklad pri rozpočte na reklamu vo výške 50 USD (x 2 ) a priemerný mesačný úhrn zrážok 100 mm (x 1 ), vzorec je nasledovný:
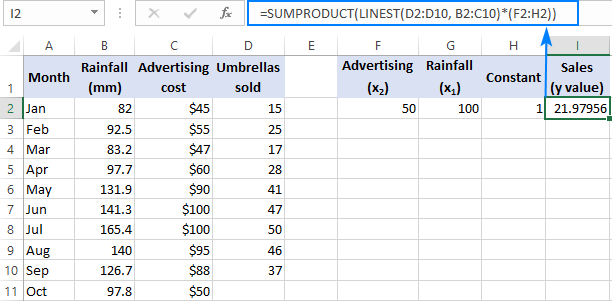
=SUM(LINEST(D2:D10, B2:C10)*{50,100,1})
Kde D2:D10 sú známe y a B2:C10 sú dva súbory x hodnoty:

Venujte pozornosť poradiu x Ako už bolo uvedené, keď sa funkcia LINEST v programe Excel používa na viacnásobnú regresiu, vracia koeficienty sklonu sprava doľava. V našom príklade Reklama sa najprv vráti koeficient a potom Zrážky Aby ste správne vypočítali predpokladané číslo predaja, musíte koeficienty vynásobiť príslušným x hodnôt, takže prvky konštantného poľa umiestnite v tomto poradí: {50,100,1}. Posledný prvok je 1, pretože posledná hodnota vrátená programom LINEST je intercept, ktorý by sa nemal meniť, takže ho jednoducho vynásobíte 1.
Namiesto použitia konštanty poľa môžete do niektorých buniek zadať všetky premenné x a odkazovať na tieto bunky vo vzorci, ako sme to urobili v predchádzajúcom príklade.
Bežný vzorec:
=SUMPRODUKT(LINEST(D2:D10, B2:C10)*(F2:H2))
Vzorec poľa:
=SUM(LINEST(D2:D10, B2:C10)*(F2:H2))
Kde F2 a G2 sú x a H2 je 1:
Vzorec LINEST: ďalšie regresné štatistiky
Ako si možno pamätáte, ak chcete získať viac štatistických údajov pre regresnú analýzu, do posledného argumentu funkcie LINEST vložíte TRUE. Po aplikácii na naše vzorové údaje má vzorec nasledujúci tvar:
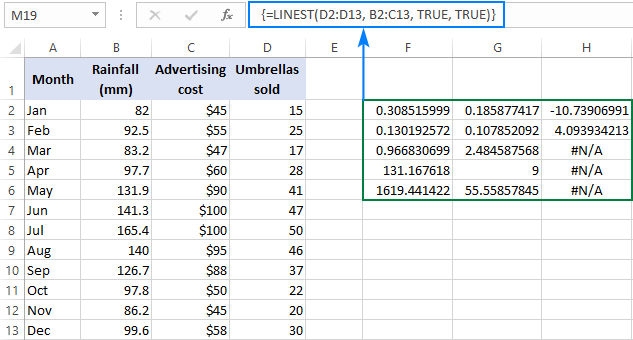
=LINEST(D2:D13, B2:C13, TRUE, TRUE)
Keďže máme 2 nezávislé premenné v stĺpcoch B a C, vyberieme hnev pozostávajúci z 3 riadkov (dve hodnoty x + intercept) a 5 stĺpcov, zadáme vyššie uvedený vzorec, stlačíme Ctrl + Shift + Enter , a dostaneme tento výsledok:
Ak sa chcete zbaviť chýb #N/A, môžete LINEST vložiť do IFERROR takto:
=IFERROR(LINEST(D2:D13, B2:C13, TRUE, TRUE), "")
Na nasledujúcom obrázku je znázornený výsledok a vysvetlené, čo jednotlivé čísla znamenajú:

Koeficienty sklonu a Y-interceptu boli vysvetlené v predchádzajúcich príkladoch, preto sa v krátkosti pozrime na ostatné štatistiky.
Koeficient determinácie (R2). hodnota R2 je výsledkom delenia súčtu štvorcov regresie celkovým súčtom štvorcov. hovorí o tom, koľko y hodnoty vysvetľujú x V tomto príklade je R2 približne 0,97, čo znamená, že 97 % našich závislých premenných (predaj dáždnikov) je vysvetlených nezávislými premennými (reklama + priemerné mesačné zrážky), čo je vynikajúca zhoda!
Štandardné chyby . vo všeobecnosti tieto hodnoty ukazujú presnosť regresnej analýzy. čím sú tieto čísla menšie, tým si môžete byť istejší svojím regresným modelom.
F štatistika . na potvrdenie alebo zamietnutie nulovej hypotézy použijete štatistiku F. Pri rozhodovaní, či sú celkové výsledky významné, sa odporúča použiť štatistiku F v kombinácii s hodnotou P.
Stupne voľnosti (df). Funkcia LINEST v programe Excel vracia zvyškové stupne voľnosti , čo je celkový df mínus regresné df Stupne voľnosti môžete použiť na získanie F-kritických hodnôt v štatistickej tabuľke a potom porovnať F-kritické hodnoty so štatistikou F na určenie úrovne spoľahlivosti pre váš model.
Regresný súčet štvorcov (alias vysvetlený súčet štvorcov , alebo modelový súčet štvorcov ) Je to súčet štvorcových rozdielov medzi predpovedanými hodnotami y a strednou hodnotou y, vypočítaný podľa tohto vzorca: =∑(ŷ - ȳ)2. Udáva, akú časť variability závislej premennej vysvetľuje váš regresný model.
Zvyškový súčet štvorcov Je to súčet štvorcových rozdielov medzi skutočnými hodnotami y a predpovedanými hodnotami y. Udáva, akú časť variability závislej premennej váš model nevysvetľuje. Čím menší je reziduálny súčet štvorcov v porovnaní s celkovým súčtom štvorcov, tým lepšie váš regresný model zodpovedá vašim údajom.
5 vecí, ktoré by ste mali vedieť o funkcii LINEST
Ak chcete efektívne používať vzorce LINEST vo svojich pracovných listoch, možno budete chcieť vedieť trochu viac o "vnútornej mechanike" funkcie:
- Known_y's a known_x's V jednoduchom lineárnom regresnom modeli len s jednou sadou premenných x, known_y's a known_x's môžu byť rozsahy ľubovoľného tvaru, ak majú rovnaký počet riadkov a stĺpcov. Ak robíte viacnásobnú regresnú analýzu s viac ako jednou sadou nezávislých x premenné, known_y's musí byť vektor, t. j. rozsah jedného riadku alebo jedného stĺpca.
- Vynútenie konštanty na nulu . Keď sa const je TRUE alebo je vynechaný, je a konštanta (intercept) sa vypočíta a zahrnie do rovnice: y=bx + a. Ak const je nastavená na FALSE, intercept sa považuje za rovný 0 a z regresnej rovnice sa vynechá: y=bx.
V štatistike sa už desaťročia diskutuje o tom, či má zmysel vynútiť konštantu interceptu na hodnotu 0 alebo nie. Mnohí dôveryhodní odborníci na regresnú analýzu sa domnievajú, že ak sa nastavenie interceptu na nulu (const=FALSE) javí ako užitočné, potom samotná lineárna regresia je nesprávnym modelom pre súbor údajov. Iní predpokladajú, že konštantu možno v určitých situáciách vynútiť na nulu, napr,Vo všeobecnosti sa odporúča vo väčšine prípadov použiť predvolenú hodnotu const=TRUE alebo ju vynechať.
- Presnosť . presnosť regresnej rovnice vypočítanej funkciou LINEST závisí od rozptylu vašich dátových bodov. Čím sú údaje lineárnejšie, tým sú výsledky vzorca LINEST presnejšie.
- Zbytočné hodnoty x V niektorých situáciách sa jeden alebo viac nezávislých x premenné nemusia mať žiadnu dodatočnú výpovednú hodnotu a odstránenie takýchto premenných z regresného modelu neovplyvní presnosť predpovedaných hodnôt y. Tento jav je známy ako "kolinearita". Funkcia Excel LINEST kontroluje kolinearitu a vynecháva všetky nadbytočné x premenné, ktoré identifikuje z modelu. Vynechané premenné x premenné možno rozpoznať podľa 0 koeficientov a 0 hodnôt štandardnej chyby.
- LINEST vs. SLOPE a INTERCEPT . základný algoritmus funkcie LINEST sa líši od algoritmu použitého vo funkciách SLOPE a INTERCEPT. preto, ak sú zdrojové údaje neurčité alebo kolineárne, môžu tieto funkcie vrátiť odlišné výsledky.
Nefunguje funkcia Excel LINEST
Ak váš vzorec LINEST vyhodí chybu alebo vytvorí nesprávny výstup, je pravdepodobné, že je to z jedného z nasledujúcich dôvodov:
- Ak funkcia LINEST vráti len jedno číslo (koeficient sklonu), s najväčšou pravdepodobnosťou ste ju zadali ako bežný vzorec, nie ako vzorec poľa. Nezabudnite stlačiť klávesovú skratku Ctrl + Shift + Enter, aby ste vzorec správne dokončili. Keď to urobíte, vzorec sa uzavrie do {vlnitých zátvoriek}, ktoré sú viditeľné na paneli vzorcov.
- #REF! chyba. Nastane, ak known_x's a known_y's rozsahy majú rôzne rozmery.
- #VALUE! chyba. Nastane, ak known_x's alebo known_y's obsahuje aspoň jednu prázdnu bunku, textovú hodnotu alebo textovú reprezentáciu čísla, ktoré Excel nerozpozná ako číselnú hodnotu. const alebo štatistiky argument nemôže byť vyhodnotený ako TRUE alebo FALSE.
Takto sa používa LINEST v programe Excel na jednoduchú a viacnásobnú lineárnu regresnú analýzu. Ak sa chcete bližšie zoznámiť so vzorcami, o ktorých sa hovorí v tomto návode, môžete si stiahnuť náš vzorový zošit nižšie. Ďakujem vám za prečítanie a dúfam, že sa uvidíme na našom blogu budúci týždeň!
Cvičebnica na stiahnutie
Príklady funkcií Excel LINEST (.xlsx súbor)
