
Spis treści
Ten tutorial wyjaśnia składnię funkcji LINEST i pokazuje, jak używać jej do wykonywania analizy regresji liniowej w programie Excel.
Microsoft Excel nie jest programem statystycznym, jednak posiada szereg funkcji statystycznych. Jedną z takich funkcji jest LINEST, która służy do przeprowadzania analizy regresji liniowej i zwracania związanych z nią statystyk. W tym poradniku dla początkujących będziemy tylko lekko dotykać teorii i podstawowych obliczeń. Skupimy się przede wszystkim na tym, aby dostarczyć Ci formułę, która po prostu działa imoże być łatwo dostosowany do Twoich danych.
Funkcja LINEST w Excelu - składnia i podstawowe zastosowania
Funkcja LINEST oblicza statystykę linii prostej wyjaśniającej związek między zmienną niezależną a jedną lub kilkoma zmiennymi zależnymi i zwraca tablicę opisującą tę linię.Funkcja korzysta z funkcji najmniejsze kwadraty Metoda ta pozwala znaleźć najlepsze dopasowanie do danych. Równanie dla linii jest następujące.
Proste równanie regresji liniowej:
y = bx + aRównanie regresji wielorakiej:
y = b 1 x 1 + b 2 x 2 + ... + b n x n + aGdzie:
- y - zmiennej zależnej, którą próbujesz przewidzieć.
- x - zmienna niezależna, którą wykorzystujesz do przewidywania y .
- a - punkt przecięcia (wskazuje miejsce przecięcia linii z osią Y).
- b - nachylenie (określa stromość linii regresji, czyli tempo zmian dla y wraz ze zmianami x).
W swojej podstawowej formie funkcja LINEST zwraca przechwyt (a) i nachylenie (b) dla równania regresji. Opcjonalnie może również zwrócić dodatkowe statystyki dla analizy regresji, jak pokazano w tym przykładzie.
Składnia funkcji LINEST
Składnia funkcji LINEST w Excelu jest następująca:
LINEST(znane_y's, [znane_x's], [const], [stats])Gdzie:
- znany_y (wymagane) jest zakresem zależnym y -wartości w równaniu regresji. Zazwyczaj jest to pojedyncza kolumna lub pojedynczy wiersz.
- znany_x (opcjonalnie) jest zakresem niezależnych wartości x. Jeżeli jest pominięty, to przyjmuje się, że jest to tablica {1,2,3,...} o takim samym rozmiarze jak znany_y .
- const (opcjonalnie) - wartość logiczna, która określa, w jaki sposób intercept (stała a ) powinny być traktowane:
- Jeśli TRUE lub pominięte, to stała a jest obliczany normalnie.
- Jeśli FALSE, to stała a jest wymuszona na 0, a nachylenie ( b współczynnik) jest obliczany dla dopasowania y=bx.
- stats (opcjonalne) jest wartością logiczną, która określa czy wyprowadzać dodatkowe statystyki czy nie:
- Jeśli TRUE, funkcja LINEST zwraca tablicę z dodatkowymi statystykami regresji.
- Jeśli FALSE lub pominięto, LINEST zwraca tylko stałą przechwytującą i współczynnik(i) nachylenia.
Uwaga. Ponieważ LINEST zwraca tablicę wartości, musi być wprowadzony jako formuła tablicowa przez naciśnięcie skrótu Ctrl + Shift + Enter. Jeśli zostanie wprowadzony jako zwykła formuła, zwracany jest tylko pierwszy współczynnik nachylenia.
Dodatkowe statystyki zwracane przez LINEST
Na stronie stats argument ustawiony na TRUE instruuje funkcję LINEST, aby zwróciła następujące statystyki dla twojej analizy regresji:
| Statystyka | Opis |
| Współczynnik nachylenia | b wartość w y = bx + a |
| Stała przechodnia | wartość w y = bx + a |
| Błąd standardowy nachylenia | Wartość błędu standardowego (błędów standardowych) dla współczynnika (współczynników) b. |
| Błąd standardowy punktu przecięcia | Wartość błędu standardowego dla stałej a . |
| Współczynnik determinacji (R2) | Wskazuje, jak dobrze równanie regresji wyjaśnia związek między zmiennymi. |
| Błąd standardowy dla oszacowania Y | Pokazuje precyzję analizy regresji. |
| Statystyka F, czyli wartość obserwowana F | Służy on do wykonania testu F dla hipotezy zerowej w celu określenia ogólnej dobroci dopasowania modelu. |
| Stopnie swobody (df) | Liczba stopni swobody. |
| Suma kwadratów regresji | Wskazuje, jak duża część zmienności zmiennej zależnej jest wyjaśniona przez model. |
| Pozostała suma kwadratów | Mierzy ilość wariancji w zmiennej zależnej, która nie jest wyjaśniona przez twój model regresji. |
Poniższa mapa pokazuje kolejność, w jakiej LINEST zwraca tablicę statystyk:

W trzech ostatnich wierszach błędy #N/A pojawią się w trzeciej i kolejnych kolumnach, które nie są wypełnione danymi. Jest to domyślne zachowanie funkcji LINEST, ale jeśli chciałbyś ukryć zapisy błędów, zawiń swoją formułę LINEST w IFERROR, jak pokazano w tym przykładzie.
Jak wykorzystać LINEST w Excelu - przykłady formuł
Funkcja LINEST może być podstępna w użyciu, szczególnie dla nowicjuszy, ponieważ należy nie tylko poprawnie zbudować formułę, ale również właściwie zinterpretować jej dane wyjściowe. Poniżej znajdziesz kilka przykładów użycia formuł LINEST w Excelu, które, mam nadzieję, pomogą zatopić wiedzę teoretyczną :)
Prosta regresja liniowa: obliczanie nachylenia i punktu przecięcia
Aby otrzymać punkt przecięcia i nachylenie linii regresji, używamy funkcji LINEST w jej najprostszej postaci: podajemy zakres wartości zależnych dla znany_y oraz zakres niezależnych wartości dla argumentu znany_x Ostatnie dwa argumenty mogą być ustawione na TRUE lub pominięte.
Na przykład z y wartości (liczby sprzedaży) w C2:C13 i wartości x (koszt reklamy) w B2:B13, nasz wzór regresji liniowej jest tak prosty, jak:
=LINEST(C2:C13,B2:B13)
Aby wprowadzić go poprawnie do arkusza, wybierz dwie sąsiednie komórki w tym samym wierszu, E2:F2 w tym przykładzie, wpisz formułę i naciśnij Ctrl + Shift + Enter, aby ją zakończyć.
Formuła zwróci współczynnik nachylenia w pierwszej komórce (E2) oraz stałą przechwytującą w drugiej komórce (F2):
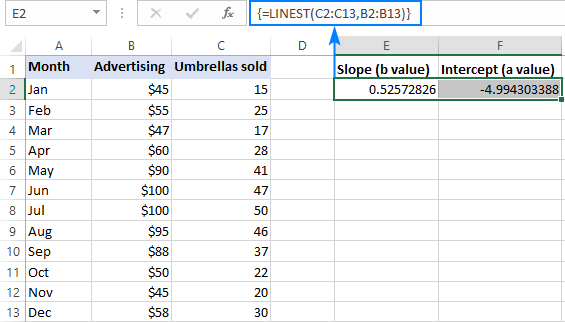
Na stronie nachylenie wynosi około 0,52 (w zaokrągleniu do dwóch miejsc po przecinku). Oznacza to, że gdy x wzrasta o 1, y wzrasta o 0,52.
Na stronie Punkt przecięcia Y jest ujemna -4,99. Jest to wartość oczekiwana y gdy x=0. W przypadku naniesienia na wykres jest to wartość, przy której linia regresji przecina oś y.
Dostarczyć powyższe wartości do prostego równania regresji liniowej, a otrzymasz następujący wzór, aby przewidzieć liczbę sprzedaży na podstawie kosztów reklamy:
y = 0,52*x - 4,99
Na przykład, jeśli wydasz 50 dolarów na reklamę, oczekuje się, że sprzedasz 21 parasoli:
0.52*50 - 4.99 = 21.01
Wartości nachylenia i przechyłu można również uzyskać oddzielnie, stosując odpowiednią funkcję lub zagnieżdżając formułę LINEST w INDEX:
Nachylenie
=SLOPE(C2:C13,B2:B13)
=INDEX(LINEST(C2:C13,B2:B13),1)
Przechwytywanie
=INTERCEPT(C2:C13,B2:B13)
=INDEX(LINEST(C2:C13,B2:B13),2)
Jak widać na poniższym zrzucie ekranu, wszystkie trzy formuły dają takie same wyniki:

Wielokrotna regresja liniowa: nachylenie i przechylenie
Jeśli masz dwie lub więcej zmiennych niezależnych, pamiętaj, aby wprowadzić je w sąsiednich kolumnach i dostarczyć cały ten zakres do znany_x argument.
Na przykład, przy numerach sprzedaży ( y w D2:D13, koszt reklamy (jeden zestaw wartości x) w B2:B13 oraz średni miesięczny opad deszczu (kolejny zestaw wartości x wartości) w C2:C13, korzystasz z tego wzoru:
=LINEST(D2:D13,B2:C13)
Ponieważ formuła ma zwrócić tablicę 3 wartości (2 współczynniki nachylenia i stała przechwytująca), zaznaczamy trzy sąsiadujące ze sobą komórki w tym samym wierszu, wpisujemy formułę i naciskamy skrót Ctrl + Shift + Enter.
Należy pamiętać, że formuła regresji wielorakiej zwraca współczynniki nachylenia w odwrotna kolejność zmiennych niezależnych (od prawej do lewej), czyli b n , b n-1 , ..., b 2 , b 1 :
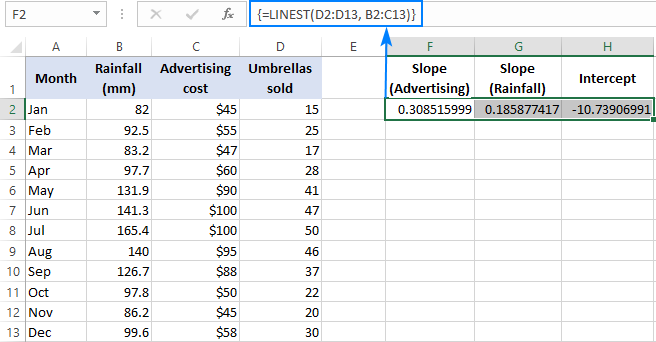
Aby przewidzieć liczbę sprzedaży, do równania regresji wielorakiej dostarczamy wartości zwrócone przez formułę LINEST:
y = 0,3*x 2 + 0.19*x 1 - 10.74
Na przykład, przy 50$ wydanych na reklamę i średniej miesięcznej ilości opadów 100 mm, oczekuje się, że sprzedasz około 23 parasole:
0.3*50 + 0.19*100 - 10.74 = 23.26
Prosta regresja liniowa: przewidywanie zmiennej zależnej
Poza obliczaniem a oraz b wartości dla równania regresji, funkcja Excel LINEST może również oszacować zmienną zależną (y) na podstawie znanej zmiennej niezależnej (x). W tym celu używasz LINEST w połączeniu z funkcją SUM lub SUMPRODUCT.
Na przykład, oto jak można obliczyć liczbę sprzedaży parasoli dla następnego miesiąca, powiedzmy października, na podstawie sprzedaży w poprzednich miesiącach i października budżet reklamowy 50 dolarów:
=SUM(LINEST(C2:C10, B2:B10)*{50,1})
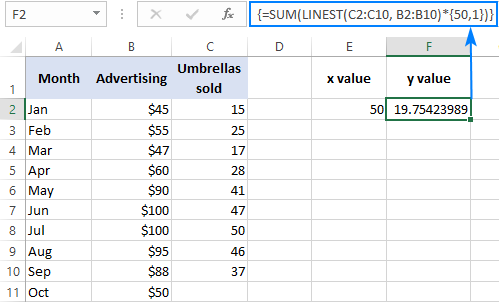
Zamiast twardego kodowania x wartość w formule, możesz podać ją jako odniesienie do komórki. W tym przypadku musisz wprowadzić stałą 1 również w jakiejś komórce, ponieważ nie możesz mieszać referencji i wartości w stałej tablicowej.
Z x w E2 i stałą 1 w F2, każdy z poniższych wzorów będzie działał jak należy:
Formuła zwykła (wprowadzana przez naciśnięcie klawisza Enter ):
=SUMPRODUCT(LINEST(C2:C10, B2:B10)*(E2:F2))
Formuła tablicowa (wprowadzana przez naciśnięcie klawiszy Ctrl + Shift + Enter ):
=SUMA(LINEST(C2:C10, B2:B10)*(E2:F2))
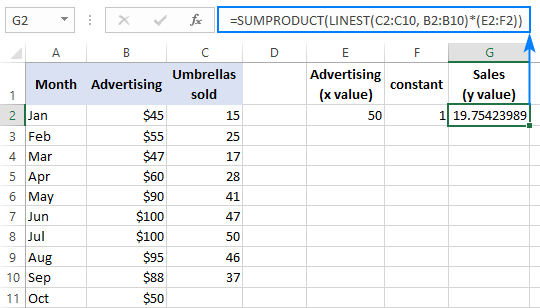
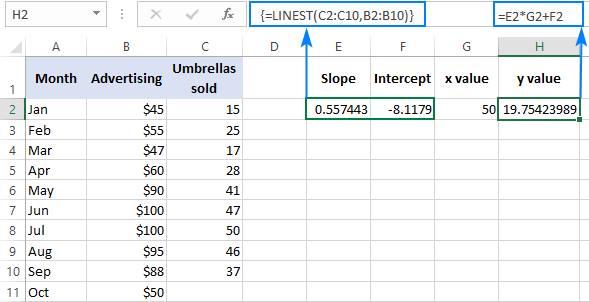
Aby sprawdzić wynik, można uzyskać przechwyt i nachylenie dla tych samych danych, a następnie użyć formuły regresji liniowej do obliczenia y :
=E2*G2+F2
Gdzie E2 jest nachyleniem, G2 jest x wartość, a F2 to intercept:
Regresja wielokrotna: przewidywanie zmiennej zależnej
W przypadku, gdy mamy do czynienia z kilkoma predyktorami, tj. kilkoma różnymi zestawami x wartości, włącz wszystkie te predyktory do tablicy constant. Na przykład, przy budżecie reklamowym 50$ (x 2 ) oraz średnia miesięczna suma opadów 100 mm (x 1 ), formuła przebiega następująco:
=SUM(LINEST(D2:D10, B2:C10)*{50,100,1})
Gdzie D2:D10 są znanymi y wartości, a B2:C10 to dwa zestawy x wartości:

Proszę zwrócić uwagę na kolejność x wartości w tablicy constant. Jak już wcześniej wspomniano, gdy funkcja LINEST programu Excel jest używana do regresji wielokrotnej, zwraca ona współczynniki nachylenia od prawej do lewej strony. W naszym przykładzie Reklama najpierw zwracany jest współczynnik, a następnie Opady deszczu Aby prawidłowo obliczyć przewidywaną liczbę sprzedaży, należy pomnożyć współczynniki przez odpowiednie x wartości, więc umieszczasz elementy stałej tablicy w takiej kolejności: {50,100,1}. Ostatnim elementem jest 1, ponieważ ostatnia wartość zwrócona przez LINEST jest przechwytem, który nie powinien być zmieniany, więc po prostu mnożysz ją przez 1.
Zamiast używać stałej tablicowej, możesz wprowadzić wszystkie zmienne x do niektórych komórek i odwołać się do tych komórek w swojej formule, tak jak zrobiliśmy to w poprzednim przykładzie.
Regularna formuła:
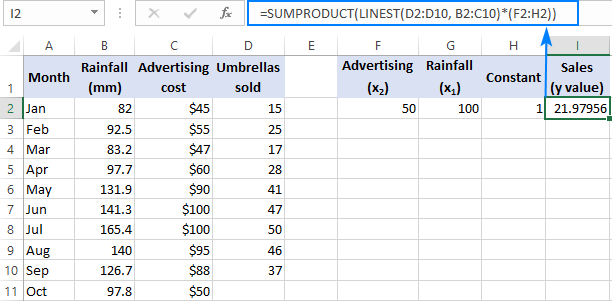
=SUMPRODUCT(LINEST(D2:D10, B2:C10)*(F2:H2))
Formuła matrycy:
=SUM(LINEST(D2:D10, B2:C10)*(F2:H2))
Gdzie F2 i G2 są x wartości, a H2 wynosi 1:
Wzór LINEST: dodatkowe statystyki regresji
Jak zapewne pamiętasz, aby uzyskać więcej statystyk do analizy regresji, w ostatnim argumencie funkcji LINEST umieszczasz TRUE. Zastosowana do naszych przykładowych danych formuła przyjmuje następujący kształt:
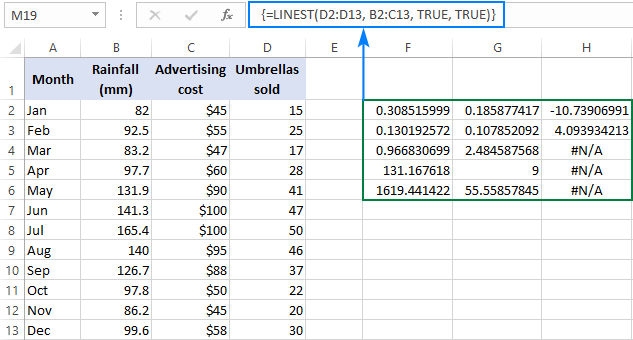
=LINEST(D2:D13, B2:C13, TRUE, TRUE)
Ponieważ w kolumnach B i C mamy 2 zmienne niezależne, wybieramy wściekłość składającą się z 3 wierszy (dwie wartości x + intercept) i 5 kolumn, wpisujemy powyższą formułę, naciskamy Ctrl + Shift + Enter , i otrzymujemy taki wynik:
Aby pozbyć się błędów #N/A, możesz zagnieździć LINEST w IFERROR w ten sposób:
=IFERROR(LINEST(D2:D13, B2:C13, TRUE, TRUE), "")
Poniższy zrzut ekranu demonstruje wynik i wyjaśnia, co oznacza każda liczba:

Współczynniki nachylenia i punkt przecięcia Y zostały wyjaśnione w poprzednich przykładach, więc przyjrzyjmy się szybko innym statystykom.
Współczynnik determinacji (R2).Wartość R2 jest wynikiem dzielenia sumy kwadratów regresji przez całkowitą sumę kwadratów.Mówi, ile y są wyjaśnione przez x zmiennych. Może to być dowolna liczba od 0 do 1, czyli od 0% do 100%. W tym przykładzie R2 wynosi około 0,97, co oznacza, że 97% naszych zmiennych zależnych (sprzedaż parasoli) jest wyjaśnione przez zmienne niezależne (reklama + średnie miesięczne opady), co jest doskonałym dopasowaniem!
Błędy standardowe Generalnie wartości te pokazują precyzję analizy regresji. Im mniejsze są te liczby, tym bardziej można być pewnym swojego modelu regresji.
Statystyka F . używasz statystyki F do poparcia lub odrzucenia hipotezy zerowej. zaleca się używanie statystyki F w połączeniu z wartością P przy podejmowaniu decyzji, czy ogólne wyniki są znaczące.
Stopnie swobody (df). Funkcja LINEST w Excelu zwraca pozostałe stopnie swobody , czyli całkowite df minus regresja df Możesz użyć stopni swobody, aby uzyskać wartości krytyczne F w tabeli statystycznej, a następnie porównać wartości krytyczne F ze statystyką F, aby określić poziom ufności dla twojego modelu.
Suma kwadratów regresji (aka. wyjaśniona suma kwadratów lub suma kwadratów modelu Jest to suma różnic kwadratowych między przewidywanymi wartościami y a średnią wartością y, obliczona za pomocą tego wzoru: =∑(ŷ - ȳ)2. Wskazuje, jak dużą część zmienności zmiennej zależnej wyjaśnia twój model regresji.
Pozostała suma kwadratów Jest to suma kwadratów różnic między rzeczywistymi wartościami y i przewidywanymi wartościami y. Wskazuje ona, jak dużej części zmienności zmiennej zależnej twój model nie wyjaśnia. Im mniejsza jest resztkowa suma kwadratów w porównaniu z całkowitą sumą kwadratów, tym lepiej twój model regresji pasuje do twoich danych.
5 rzeczy, które powinieneś wiedzieć o funkcji LINEST
Aby efektywnie wykorzystać formuły LINEST w swoich arkuszach, warto wiedzieć nieco więcej o "wewnętrznej mechanice" funkcji:
- Znany_y oraz znany_x . W prostym modelu regresji liniowej z tylko jednym zestawem zmiennych x, znany_y oraz znany_x mogą być zakresami o dowolnym kształcie, o ile mają tę samą liczbę wierszy i kolumn. Jeśli przeprowadzasz analizę regresji wielokrotnej z więcej niż jednym zestawem niezależnych x zmienne, znany_y musi być wektorem, czyli zakresem jednego wiersza lub jednej kolumny.
- Wymuszenie stałej na zero . When the const argument jest TRUE lub jest pominięty, to a stałą (intercept) oblicza się i włącza do równania: y=bx + a. Jeśli const jest ustawiona na FALSE, przyjmuje się, że punkt przecięcia jest równy 0 i pomija się go w równaniu regresji: y=bx.
W statystyce od dziesięcioleci dyskutuje się, czy ma sens wymuszanie stałej przechwytującej na 0, czy nie. Wielu wiarygodnych praktyków analizy regresji uważa, że jeśli ustawienie przechwytu na zero (const=FALSE) wydaje się być użyteczne, to sama regresja liniowa jest złym modelem dla zbioru danych. Inni przypuszczają, że stała może być wymuszona na zero w pewnych sytuacjach, np,w kontekście projektów nieciągłości regresji. Ogólnie rzecz biorąc, w większości przypadków zalecane jest użycie domyślnego const=TRUE lub pominięcie go.
- Dokładność Dokładność równania regresji obliczonego za pomocą funkcji LINEST zależy od rozproszenia punktów danych. Im bardziej liniowe dane, tym dokładniejsze wyniki formuły LINEST.
- Nadmiarowe wartości x W niektórych sytuacjach jeden lub więcej niezależnych x zmienne mogą nie mieć dodatkowej wartości predykcyjnej, a usunięcie takich zmiennych z modelu regresji nie wpływa na dokładność przewidywanych wartości y. Zjawisko to znane jest jako "współliniowość". Funkcja LINEST programu Excel sprawdza współliniowość i pomija wszelkie zbędne x zmiennych, które identyfikuje z modelu. Pominięte x zmienne można rozpoznać po 0 współczynnikach i 0 wartościach błędów standardowych.
- LINIA a STOPIEŃ i PRZESTRZEŃ Algorytm leżący u podstaw funkcji LINEST różni się od algorytmu stosowanego w funkcjach SLOPE i INTERCEPT, dlatego gdy dane źródłowe są nieokreślone lub współliniowe, funkcje te mogą zwracać różne wyniki.
Funkcja LINEST w programie Excel nie działa
Jeśli twoja formuła LINEST rzuca błąd lub produkuje złe wyjście, są szanse, że jest to spowodowane jednym z następujących powodów:
- Jeśli funkcja LINEST zwraca tylko jedną liczbę (współczynnik nachylenia), najprawdopodobniej wpisałeś ją jako zwykłą formułę, a nie formułę tablicową. Pamiętaj, aby nacisnąć Ctrl + Shift + Enter, aby poprawnie zakończyć formułę. Kiedy to zrobisz, formuła zostanie zamknięta w nawiasach klamrowych {curly bracket}, które są widoczne na pasku formuły.
- Błąd #REF! Występuje, jeśli znany_x oraz znany_y zakresy mają różne wymiary.
- #Błąd! Występuje, jeśli znany_x lub znany_y zawiera co najmniej jedną pustą komórkę, wartość tekstową lub tekstową reprezentację liczby, której Excel nie rozpoznaje jako wartości liczbowej. Ponadto błąd #VALUE występuje, jeżeli const lub stats argument nie może zostać oceniony na TRUE lub FALSE.
W ten sposób używasz LINEST w Excelu do analizy prostej i wielokrotnej regresji liniowej. Aby przyjrzeć się bliżej formułom omawianym w tym tutorialu, zapraszamy do pobrania naszego przykładowego skoroszytu poniżej. Dziękuję za lekturę i mam nadzieję, że zobaczymy się na naszym blogu w przyszłym tygodniu!
Zeszyt ćwiczeń do pobrania
Przykłady funkcji Excel LINEST (plik .xlsx)
