
Sisukord
See õpetus selgitab funktsiooni LINEST süntaksit ja näitab, kuidas seda kasutada lineaarse regressioonianalüüsi tegemiseks Excelis.
Microsoft Excel ei ole statistiline programm, kuid sellel on siiski mitmeid statistilisi funktsioone. Üks sellistest funktsioonidest on LINEST, mis on mõeldud lineaarse regressioonianalüüsi teostamiseks ja sellega seotud statistika tagastamiseks. Selles algajatele mõeldud õpetuses puudutame vaid kergelt teooriat ja selle aluseks olevaid arvutusi. Meie põhirõhk on sellel, et anda teile lihtsalt toimiv valem jasaab hõlpsasti kohandada teie andmete jaoks.
Exceli funktsioon LINEST - süntaks ja põhilised kasutusalad
Funktsioon LINEST arvutab statistilised andmed sirgjoonele, mis selgitab seost sõltumatu muutuja ja ühe või mitme sõltuva muutuja vahel, ning tagastab sirget kirjeldava massiivi. Funktsioon kasutab funktsiooni vähimad ruutud meetodiga, et leida oma andmetele parim sobivus. Joone võrrand on järgmine.
Lihtne lineaarne regressioonivõrrand:
y = bx + aMitme regressiooni võrrand:
y = b 1 x 1 + b 2 x 2 + ... + b n x n + aKus:
- y - sõltuv muutuja, mida püütakse ennustada.
- x - sõltumatu muutuja, mida kasutate prognoosimiseks y .
- a - lõikepunkt (näitab, kus joon lõikub Y-teljega).
- b - kaldenurk (näitab regressioonijoone järsust, st y muutumise kiirust, kui x muutub).
Põhivormis tagastab funktsioon LINEST regressioonivõrrandi lõikepunkti (a) ja tõusu (b). Valikuliselt võib see tagastada ka täiendavaid statistilisi andmeid regressioonianalüüsi kohta, nagu on näidatud käesolevas näites.
LINEST funktsiooni süntaks
Exceli funktsiooni LINEST süntaks on järgmine:
LINEST(tuntud_y'd, [tuntud_x'd], [const], [stats])Kus:
- known_y's (nõutav) on sõltuva y -väärtused regressioonivõrrandis. Tavaliselt on see üks veerg või üks rida.
- known_x's (valikuline) on sõltumatute x-väärtuste vahemik. Kui see jäetakse välja, eeldatakse, et see on massiivi {1,2,3,...}, mis on sama suur kui known_y's .
- const (valikuline) - loogiline väärtus, mis määrab, kuidas intercept (konstant) a ) tuleks ravida:
- Kui TRUE või jäetakse välja, siis konstant a arvutatakse normaalselt.
- Kui FALSE, siis konstant a on sunnitud olema 0 ja kalle ( b koefitsient) arvutatakse, et sobitada y=bx.
- statistika (valikuline) on loogiline väärtus, mis määrab, kas anda välja täiendavat statistikat või mitte:
- Kui funktsioon LINEST on TRUE, tagastab see massiivi täiendava regressioonistatistikaga.
- Kui FALSE või jäetakse välja, tagastab LINEST ainult lõikekonstandi ja kalde koefitsiendi(d).
Märkus. Kuna LINEST tagastab väärtuste massiivi, tuleb see sisestada massiivi valemina, vajutades klahvikombinatsiooni Ctrl + Shift + Enter. Kui see sisestatakse tavalise valemina, tagastatakse ainult esimene kalde koefitsient.
LINESTi tagastatud täiendav statistika
The statistika argumendiga TRUE antakse LINEST-funktsioonile korraldus tagastada regressioonianalüüsi jaoks järgmised statistilised andmed:
| Statistika | Kirjeldus |
| Kalde koefitsient | b väärtus y = bx + a |
| Intertseptsioonikonstant | väärtus y = bx + a |
| Kalduvuse standardviga | b koefitsiendi(de) standardviga(d). |
| Sekkumise standardviga | Konstandi standardvea väärtus a . |
| Määratluskoefitsient (R2) | Näitab, kui hästi seletab regressioonivõrrand muutujate vahelist seost. |
| Y hinnangu standardviga | Näitab regressioonianalüüsi täpsust. |
| F-statistik ehk F-vaatlusväärtus | Seda kasutatakse nullhüpoteesi F-testi tegemiseks, et teha kindlaks mudeli üldine sobivus. |
| Vabadusastmed (df) | Vabadusastmete arv. |
| Regressiooni ruutude summa | Näitab, kui suurt osa sõltuva muutuja varieeruvusest mudeliga seletatakse. |
| Ruutude jääksumma | Mõõdab sõltuva muutuja dispersiooni suurust, mida teie regressioonimudel ei seleta. |
Allpool olev kaart näitab, millises järjekorras LINEST statistika massiivi tagastab:

Kolmes viimases reas ilmuvad #N/A vead kolmandas ja järgmistes veergudes, mis ei ole andmetega täidetud. See on funktsiooni LINEST vaikimisi käitumine, kuid kui soovite veamärkusi varjata, mähkige oma LINEST-valem IFERROR-i, nagu on näidatud selles näites.
Kuidas kasutada LINESTi Excelis - valemite näited
LINEST funktsiooni kasutamine võib olla keeruline, eriti algajatele, sest lisaks valemi korrektsele koostamisele tuleb ka selle väljundit õigesti tõlgendada. Allpool on toodud mõned näited LINEST valemite kasutamisest Excelis, mis loodetavasti aitavad teoreetilisi teadmisi sisse upitada :)
Lihtne lineaarne regressioon: arvutage kaldenurk ja lõikepunkt.
Regressioonijoone lõikepunkti ja tõusu saamiseks kasutate funktsiooni LINEST selle lihtsaimal kujul: esitage sõltuvate väärtuste vahemik jaoks known_y's argumendi ja sõltumatu väärtuste vahemiku jaoks known_x's Kaks viimast argumenti võib määrata TRUE või jätta need ära.
Näiteks koos y väärtused (müüginumbrid) C2:C13 ja x väärtused (reklaamikulud) B2:B13, on meie lineaarse regressiooni valem nii lihtne kui:
=LINEST(C2:C13,B2:B13)
Selle korrektseks sisestamiseks oma töölehel valige kaks kõrvuti asetsevat lahtrit samas reas, antud näites E2:F2, sisestage valem ja vajutage Ctrl + Shift + Enter, et seda täiendada.
Valem tagastab esimeses lahtris (E2) kalde koefitsiendi ja teises lahtris (F2) lõikekonstandi:
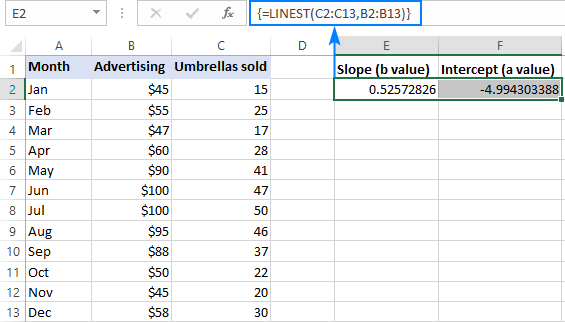
The kalle on ligikaudu 0,52 (ümardatud kahe kümnendkohani). See tähendab, et kui x suureneb 1 võrra, y suureneb 0,52 võrra.
The Y-intertseptsioon on negatiivne -4,99. See on eeldatav väärtus y kui x=0. Kui see joonistatakse graafikul, siis on see väärtus, mille juures regressioonijoon ristub y-teljega.
Sisestage ülaltoodud väärtused lihtsasse lineaarsesse regressioonivõrrandisse ja te saate järgmise valemi, et ennustada reklaami maksumuse põhjal müüginumbrit:
y = 0,52*x - 4,99
Näiteks kui kulutate 50 dollarit reklaamile, siis eeldatakse, et müüte 21 vihmavarju:
0.52*50 - 4.99 = 21.01
Kalde- ja lõikeväärtused saab ka eraldi, kasutades vastavat funktsiooni või ühendades LINEST-valemi INDEXiga:
Kalda
=SLOPE(C2:C13,B2:B13)
=INDEX(LINEST(C2:C13,B2:B13),1)
Intercept
=INTERCEPT(C2:C13,B2:B13)
=INDEX(LINEST(C2:C13,B2:B13),2)
Nagu on näidatud alloleval ekraanipildil, annavad kõik kolm valemit samu tulemusi:

Mitmekordne lineaarne regressioon: kaldenurk ja lõikepunkt
Kui teil on kaks või enam sõltumatut muutujat, sisestage need kindlasti kõrvuti asuvatesse veergudesse ja sisestage kogu see vahemik faili known_x's argument.
Näiteks müüginumbritega ( y väärtused) D2:D13, reklaamikulud (üks x-väärtuste kogum) B2:B13 ja keskmine igakuine sademete hulk (teine kogum x väärtused) C2:C13, kasutate seda valemit:
=LINEST(D2:D13,B2:C13)
Kuna valem tagastab 3 väärtuse massiivi (2 kalde koefitsienti ja lõikekonstant), valime kolm kõrvuti asetsevat lahtrit samas reas, sisestame valemi ja vajutame Ctrl + Shift + Enter klahvikombinatsiooni.
Pange tähele, et mitmekordse regressiooni valem annab tagasi kalde koefitsiendid aastal vastupidine järjekord sõltumatuid muutujaid (paremalt vasakule), st b n , b n-1 , ..., b 2 , b 1 :
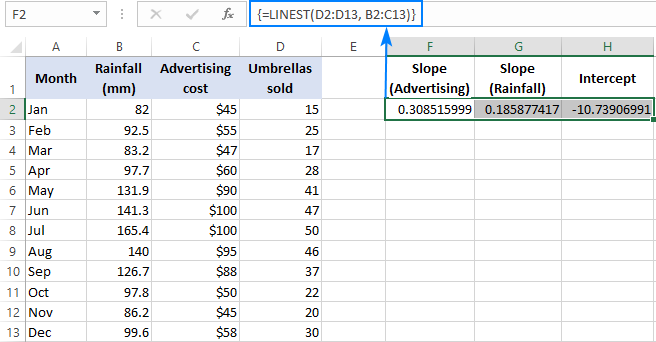
Müüginumbri prognoosimiseks sisestame LINESTi valemi abil saadud väärtused mitmikregressiooni võrrandisse:
y = 0,3*x 2 + 0.19*x 1 - 10.74
Näiteks, kui reklaamile kulub 50 dollarit ja keskmine sademete hulk on 100 mm kuus, siis eeldatakse, et te saate müüa umbes 23 vihmavarju:
0.3*50 + 0.19*100 - 10.74 = 23.26
Lihtne lineaarne regressioon: ennustada sõltuvat muutujat
Peale arvutamise a ja b regressioonivõrrandi väärtusi, saab Exceli funktsioon LINEST hinnata ka sõltuvat muutujat (y) teadaoleva sõltumatu muutuja (x) põhjal. Selleks kasutate LINESTi koos funktsiooniga SUMMA või SUMPRODUCT.
Näiteks saate järgmise kuu, näiteks oktoobri, vihmavarjude müügi arvu arvutada eelnevate kuude müügi ja oktoobri reklaamieelarve (50 dollarit) põhjal:
=SUM(LINEST(C2:C10, B2:B10)*{50,1})
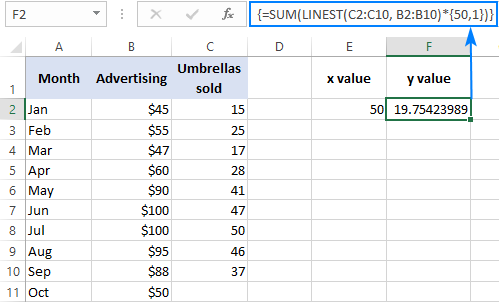
Selle asemel, et kõvakoodeerida x väärtust valemis, saate selle esitada lahtriviidetena. Sel juhul peate sisestama ka konstandi 1 mõnda lahtrisse, sest viiteid ja väärtusi ei saa massiivkonstandis segada.
Koos x väärtus E2-s ja konstant 1 F2-s, töötab ükskõik milline allpool esitatud valemitest:
Tavaline valem (sisestatakse vajutades Enter ):
=SUMPRODUCT(LINEST(C2:C10, B2:B10)*(E2:F2))
Array valem (sisestatakse vajutades Ctrl + Shift + Enter ):
=SUM(LINEST(C2:C10, B2:B10)*(E2:F2))
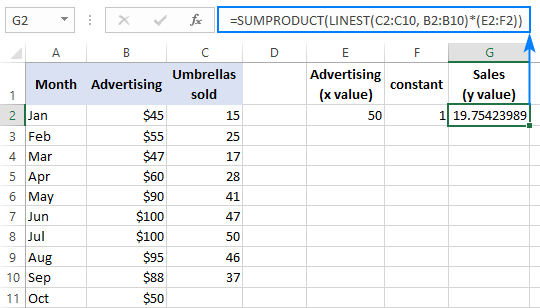
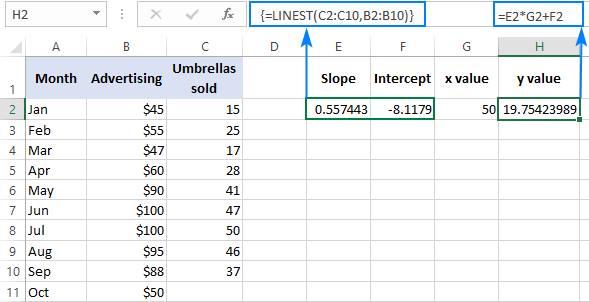
Tulemuse kontrollimiseks võite saada samade andmete jaoks lõikepunkti ja tõusu ning seejärel kasutada lineaarse regressiooni valemit, et arvutada y :
=E2*G2+F2
Kus E2 on kalle, G2 on x väärtus ja F2 on lõikepunkt:
Mitmekordne regressioon: ennustada sõltuvat muutujat
Juhul, kui tegemist on mitme ennustajaga, st mitme erineva komplekti x väärtused, lisada kõik need ennustajad massiivi konstant. Näiteks, kui reklaami eelarve on 50 dollarit (x 2 ) ja kuu keskmine sademete hulk 100 mm (x 1 ), valem on järgmine:
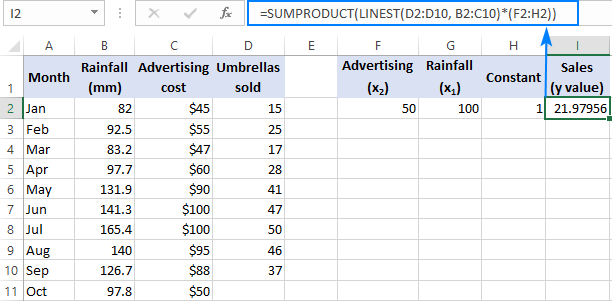
=SUM(LINEST(D2:D10, B2:C10)*{50,100,1})
Kus D2:D10 on teadaolevad y väärtused ja B2:C10 on kaks komplekti x väärtused:

Palun pöörake tähelepanu järjekorrale x väärtused massiivi konstant. Nagu varem märgitud, kui Exceli LINEST funktsiooni kasutatakse mitmekordse regressiooni tegemiseks, siis tagastab see kalde koefitsiendid paremalt vasakule. Meie näites on Reklaam koefitsient tagastatakse esimesena ja seejärel tagastatakse Vihmasadu koefitsient. Et prognoositud müüginumbrit õigesti arvutada, tuleb koefitsiendid korrutada vastava x väärtused, seega paned massiivi konstandi elemendid sellises järjekorras: {50,100,1}. Viimane element on 1, sest viimane LINESTi poolt tagastatud väärtus on intercept, mida ei tohiks muuta, seega korrutad selle lihtsalt 1ga.
Selle asemel, et kasutada massiivi konstanti, võite sisestada kõik x-muutujad mõnda lahtrisse ja viidata nendele lahtritele oma valemis, nagu me tegime eelmises näites.
Tavaline valem:
=SUMPRODUCT(LINEST(D2:D10, B2:C10)*(F2:H2))
Array valem:
=SUM(LINEST(D2:D10, B2:C10)*(F2:H2))
Kus F2 ja G2 on x väärtused ja H2 on 1:
LINEST valem: täiendav regressioonistatistika
Nagu te ehk mäletate, et saada regressioonianalüüsi jaoks rohkem statistikat, panete funktsiooni LINEST viimasesse argumenti TRUE. Meie näidisandmetele rakendatuna võtab valem järgmise kuju:
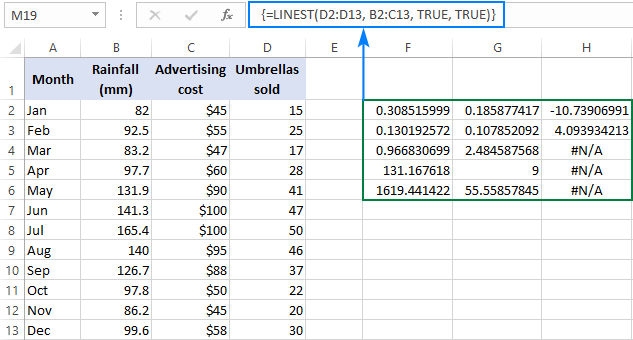
=LINEST(D2:D13, B2:C13, TRUE, TRUE)
Kuna meil on 2 sõltumatut muutujat veergudes B ja C, valime 3 reast (kaks x-väärtust + intercept) ja 5 veerust koosneva rahe, sisestame ülaltoodud valemi, vajutame Ctrl + Shift + Enter ja saame selle tulemuse:
Et vabaneda #N/A vigadest, võite LINEST-i IFERROR-i sisse pesitseda järgmiselt:
=IFERROR(LINEST(D2:D13, B2:C13, TRUE, TRUE), "")
Allpool olev ekraanipilt näitab tulemust ja selgitab, mida iga number tähendab:

Kalde koefitsiente ja Y-intertseptsiooni selgitati eelmistes näidetes, nii et vaatame lühidalt teisi statistilisi näitajaid.
Määratluskoefitsient (R2). R2 väärtus on regressiooni ruutude summa jagamise tulemus kogu ruutude summaga. See näitab, kui palju y väärtused on seletatavad x See võib olla mis tahes arv vahemikus 0-1, st 0% kuni 100%. Selles näites on R2 ligikaudu 0,97, mis tähendab, et 97% meie sõltuvatest muutujatest (vihmavarjude müük) on seletatav sõltumatute muutujatega (reklaam + keskmine kuine sademete hulk), mis on suurepärane sobivus!
Standardvead Üldiselt näitavad need väärtused regressioonianalüüsi täpsust. Mida väiksemad on need arvud, seda kindlamalt saab regressioonimudelit hinnata.
F-statistika . Te kasutate F-statistikat nullhüpoteesi toetamiseks või tagasilükkamiseks. Soovitatav on kasutada F-statistikat koos P-väärtusega, kui otsustate, kas üldised tulemused on olulised.
Vabadusastmed (df). Exceli funktsioon LINEST tagastab jääkvabaduskraadid , mis on kokku df miinus regressioon df Võite kasutada vabadusastmeid, et saada F-kriitilised väärtused statistilises tabelis ja seejärel võrrelda F-kriitilisi väärtusi F-statistikaga, et määrata oma mudeli usaldusnivoo.
Regressiooni ruutude summa (ehk siis seletatud ruutude summa , või mudeli ruutude summa ). See on prognoositud y-väärtuste ja y keskväärtuse ruuterinevuste summa, mis arvutatakse järgmise valemiga: =∑(ŷ - ȳ)2. See näitab, kui suurt osa sõltuva muutuja varieerumisest teie regressioonimudel seletab.
Ruutude jääksumma See on tegelike y-väärtuste ja prognoositud y-väärtuste vaheliste erinevuste ruutude summa. See näitab, kui suurt osa sõltuva muutuja varieerumisest teie mudel ei seleta. Mida väiksem on jääkruutude summa võrreldes ruutude kogusummaga, seda paremini sobib teie regressioonimudel teie andmetega.
5 asja, mida peaksite teadma LINEST funktsiooni kohta
Selleks, et kasutada LINESTi valemeid oma töölehtedel tõhusalt, peaksite teadma veidi rohkem funktsiooni "sisemehaanikast":
- Known_y's ja known_x's Lihtsa lineaarse regressioonimudeli puhul, kus on ainult üks x-muutujate kogum, known_y's ja known_x's võivad olla mis tahes kujuga vahemikud, kui neil on sama arv ridu ja veerge. Kui teete mitme regressioonianalüüsi rohkem kui ühe sõltumatu komplektiga. x muutujad, known_y's peab olema vektor, st ühe rea või ühe veeru vahemik.
- Konstandi nullini sundimine Kui const argument on TRUE või jäetakse välja, siis on funktsiooni a konstant (intercept) arvutatakse ja lisatakse võrrandisse: y=bx + a. Kui const on FALSE, loetakse intercept võrdseks 0-ga ja jäetakse regressioonivõrrandist välja: y=bx.
Statistikas on aastakümneid vaieldud selle üle, kas on mõttekas sundida intertseptikonstant nulli või mitte. Paljud usaldusväärsed regressioonianalüüsi praktikud usuvad, et kui intertseptikonstantsi nullile seadmine (const=FALSE) tundub olevat kasulik, siis on lineaarne regressioon ise vale mudel andmestiku jaoks. Teised arvavad, et konstanti võib teatud olukordades näiteks nullile sundida,Üldiselt on soovitatav kasutada vaikimisi const=TRUE või jätta see enamikul juhtudel välja.
- Täpsus LINEST-funktsiooni abil arvutatud regressioonivõrrandi täpsus sõltub teie andmepunktide hajuvusest. Mida lineaarsemad on andmed, seda täpsemad on LINEST-valemi tulemused.
- Üleliigsed x-väärtused Mõnes olukorras on üks või mitu sõltumatut x muutujatel ei pruugi olla täiendavat ennustusväärtust ja selliste muutujate eemaldamine regressioonimudelist ei mõjuta ennustatavate y väärtuste täpsust. Seda nähtust nimetatakse "kollineaarsuseks". Exceli funktsioon LINEST kontrollib kollineaarsust ja jätab välja kõik üleliigsed x muutujad, mis ta mudelist tuvastab. Väljajäetud x muutujaid saab ära tunda 0 koefitsiendi ja 0 standardvea väärtuse järgi.
- LINEST vs. SLOPE ja INTERCEPT Funktsiooni LINEST aluseks olev algoritm erineb funktsioonides SLOPE ja INTERCEPT kasutatavast algoritmist. Seetõttu võivad need funktsioonid anda erinevaid tulemusi, kui lähteandmed on määramata või kollineaarsed.
Exceli LINEST funktsioon ei tööta
Kui teie LINESTi valem viskab vea või annab vale tulemuse, on tõenäoline, et see on tingitud ühest järgmistest põhjustest:
- Kui funktsioon LINEST tagastab ainult ühe arvu (kalde koefitsiendi), siis olete tõenäoliselt sisestanud selle tavalise valemina, mitte massiivi valemina. Vajutage kindlasti Ctrl + Shift + Enter, et valemit õigesti täita. Kui te seda teete, siis valemit ümbritsevad {sõõrdsulgudes}, mis on nähtav valemiribal.
- #REF! viga. Tekib, kui known_x's ja known_y's vahemikud on erineva suurusega.
- #VALUE! viga. Tekib, kui known_x's või known_y's sisaldab vähemalt ühte tühja lahtrit, tekstiväärtust või numbri tekstilist esitust, mida Excel ei tunnista numbrilise väärtusena. Samuti tekib #VALUE viga, kui const või statistika argumenti ei saa hinnata TRUE või FALSE.
Nii kasutate LINESTi Excelis lihtsa ja mitmekordse lineaarse regressioonianalüüsi tegemiseks. Et lähemalt tutvuda selles õpetuses käsitletud valemitega, olete oodatud alljärgnevalt meie näidistöövihiku allalaadimiseks. Tänan teid lugemise eest ja loodan, et näeme teid järgmisel nädalal meie blogis!
Praktiline töövihik allalaadimiseks
Exceli LINEST-funktsiooni näited (.xlsx fail)
