
Inhoudsopgave
In deze handleiding wordt de syntaxis van de LINEST-functie uitgelegd en wordt getoond hoe deze kan worden gebruikt voor lineaire regressieanalyse in Excel.
Microsoft Excel is geen statistisch programma, maar beschikt wel over een aantal statistische functies. Een van die functies is LINEST, dat is ontworpen om lineaire regressieanalyse uit te voeren en daarmee samenhangende statistieken op te leveren. In deze tutorial voor beginners zullen we slechts licht ingaan op de theorie en de onderliggende berekeningen. We zullen ons er vooral op richten u een formule aan te reiken die gewoon werkt enkan gemakkelijk worden aangepast voor uw gegevens.
Excel LINEST-functie - syntaxis en basisgebruik
De functie LINEST berekent de statistieken voor een rechte lijn die het verband tussen de onafhankelijke variabele en een of meer afhankelijke variabelen verklaart, en geeft een matrix terug die de lijn beschrijft. De functie gebruikt de kleinste kwadraten methode om de beste pasvorm voor uw gegevens te vinden. De vergelijking voor de lijn is als volgt.
Eenvoudige lineaire regressievergelijking:
y = bx + aMeervoudige regressievergelijking:
y = b 1 x 1 + b 2 x 2 + ... + b n x n + aWaar:
- y - de afhankelijke variabele die u probeert te voorspellen.
- x - de onafhankelijke variabele die u gebruikt om te voorspellen y .
- a - het snijpunt (geeft aan waar de lijn de Y-as snijdt).
- b - de helling (geeft de steilheid van de regressielijn aan, d.w.z. de mate van verandering voor y als x verandert).
In de basisvorm geeft de LINEST-functie het intercept (a) en de helling (b) voor de regressievergelijking. Optioneel kan de functie ook aanvullende statistieken voor de regressieanalyse geven, zoals in dit voorbeeld.
LINEST-functie syntaxis
De syntaxis van de Excel LINEST-functie is als volgt:
LINEST(known_y's, [known_x's], [const], [stats])Waar:
- known_y's (vereist) is een bereik van de afhankelijke y -waarden in de regressievergelijking. Gewoonlijk is het een enkele kolom of rij.
- known_x's (optioneel) is een bereik van de onafhankelijke x-waarden. Indien weggelaten, wordt aangenomen dat het de matrix {1,2,3,...} is van dezelfde grootte als known_y's .
- const (facultatief) - een logische waarde die bepaalt hoe het intercept (constante a ) moeten worden behandeld:
- Indien TRUE of weggelaten, wordt de constante a wordt normaal berekend.
- Indien FALSE, de constante a wordt gedwongen tot 0 en de helling ( b coëfficiënt) wordt berekend om te passen bij y=bx.
- stats (facultatief) is een logische waarde die bepaalt of aanvullende statistieken al dan niet moeten worden uitgevoerd:
- Indien WAAR, retourneert de LINEST-functie een matrix met aanvullende regressiestatistieken.
- Indien FALSE of weggelaten, geeft LINEST alleen de interceptconstante en hellingcoëfficiënt(en) terug.
Opmerking: Aangezien LINEST een matrix van waarden teruggeeft, moet de formule worden ingevoerd als een matrixformule door op de sneltoets Ctrl + Shift + Enter te drukken. Als de formule als een gewone formule wordt ingevoerd, wordt alleen de eerste hellingscoëfficiënt teruggegeven.
Aanvullende statistieken teruggestuurd door LINEST
De stats Het argument TRUE geeft de LINEST-functie de opdracht de volgende statistieken voor uw regressieanalyse terug te geven:
| Statistiek | Beschrijving |
| Hellingcoëfficiënt | b waarde in y = bx + a |
| Constante interceptie | een waarde in y = bx + a |
| Standaardafwijking van de helling | De standaardfoutwaarde(n) voor de b-coëfficiënt(en). |
| Standaardfout van intercept | De standaardfoutwaarde voor de constante a . |
| Determinatiecoëfficiënt (R2) | Geeft aan hoe goed de regressievergelijking het verband tussen de variabelen verklaart. |
| Standaardfout voor de Y-schatting | Toont de precisie van de regressieanalyse. |
| F-statistiek, of de F-waargenomen waarde | De F-test voor de nulhypothese wordt gebruikt om de algemene "goodness of fit" van het model te bepalen. |
| Vrijheidsgraden (df) | Het aantal vrijheidsgraden. |
| Regressie som van de kwadraten | Geeft aan hoeveel van de variatie in de afhankelijke variabele door het model wordt verklaard. |
| Resterende som van de kwadraten | Meet de hoeveelheid variantie in de afhankelijke variabele die niet wordt verklaard door uw regressiemodel. |
De onderstaande kaart toont de volgorde waarin LINEST een array van statistieken retourneert:

In de laatste drie rijen verschijnen de #N/A-fouten in de derde en volgende kolommen die niet gevuld zijn met gegevens. Dit is het standaardgedrag van de LINEST-functie, maar als u de foutmeldingen wilt verbergen, wikkel uw LINEST-formule dan in IFERROR zoals in dit voorbeeld.
Hoe LINEST gebruiken in Excel - formulevoorbeelden
De LINEST-functie kan lastig te gebruiken zijn, vooral voor beginners, omdat je niet alleen een formule correct moet opbouwen, maar ook de uitvoer ervan goed moet interpreteren. Hieronder vind je een paar voorbeelden van het gebruik van LINEST-formules in Excel die hopelijk helpen om de theoretische kennis erin te laten zinken :)
Eenvoudige lineaire regressie: bereken helling en intercept
Om het intercept en de helling van een regressielijn te verkrijgen, gebruikt u de LINEST-functie in haar eenvoudigste vorm: geef een bereik van de afhankelijke waarden voor de known_y's en een reeks onafhankelijke waarden voor de known_x's De laatste twee argumenten kunnen worden ingesteld op TRUE of worden weggelaten.
Bijvoorbeeld, met y waarden (verkoopcijfers) in C2:C13 en x-waarden (reclamekosten) in B2:B13, is onze lineaire regressieformule zo eenvoudig als:
=LINEST(C2:C13,B2:B13)
Om de formule correct in te voeren in uw werkblad, selecteert u twee aangrenzende cellen in dezelfde rij, E2:F2 in dit voorbeeld, typt u de formule, en drukt u op Ctrl + Shift + Enter om deze te voltooien.
De formule geeft de hellingcoëfficiënt in de eerste cel (E2) en de interceptconstante in de tweede cel (F2):
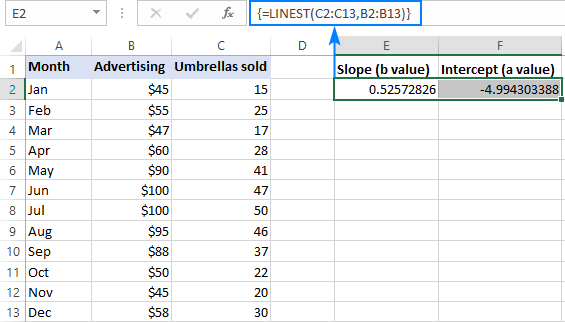
De helling is ongeveer 0,52 (afgerond op twee decimalen). Dat betekent dat wanneer x stijgt met 1, y stijgt met 0,52.
De Y-intercept is negatief -4.99. Het is de verwachte waarde van y wanneer x=0. In een grafiek is het de waarde waarbij de regressielijn de y-as kruist.
Voeg de bovenstaande waarden toe aan een eenvoudige lineaire regressievergelijking, en u krijgt de volgende formule om het verkoopcijfer te voorspellen op basis van de advertentiekosten:
y = 0,52*x - 4,99
Als u bijvoorbeeld 50 dollar uitgeeft aan reclame, wordt verwacht dat u 21 paraplu's verkoopt:
0.52*50 - 4.99 = 21.01
De waarden voor helling en intercept kunnen ook afzonderlijk worden verkregen door de overeenkomstige functie te gebruiken of door de LINEST-formule in INDEX te nesten:
Helling
=SLOPE(C2:C13,B2:B13)
=INDEX(LINEST(C2:C13,B2:B13),1)
Onderscheppen
=INTERCEPT(C2:C13,B2:B13)
=INDEX(LINEST(C2:C13,B2:B13),2)
Zoals in onderstaande schermafbeelding te zien is, leveren alle drie de formules dezelfde resultaten op:

Meervoudige lineaire regressie: helling en intercept
Als u twee of meer onafhankelijke variabelen hebt, moet u die in aangrenzende kolommen invoeren, en dat hele bereik aan de known_x's argument.
Bijvoorbeeld met verkoopcijfers ( y waarden) in D2:D13, reclamekosten (een reeks x-waarden) in B2:B13 en gemiddelde maandelijkse neerslag (een andere reeks x waarden) in C2:C13, gebruik je deze formule:
=LINEST(D2:D13,B2:C13)
Omdat de formule een reeks van 3 waarden moet opleveren (2 hellingscoëfficiënten en de interceptconstante), selecteren we drie aaneengesloten cellen in dezelfde rij, voeren we de formule in en drukken we op de sneltoets Ctrl + Shift + Enter.
Merk op dat de meervoudige regressieformule de hellingscoëfficiënten in de omgekeerde volgorde van de onafhankelijke variabelen (van rechts naar links), dus b n , b n-1 , ..., b 2 , b 1 :
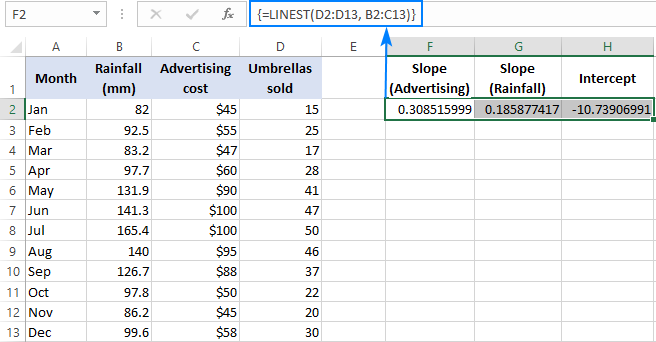
Om het verkoopcijfer te voorspellen, voegen wij de waarden die de LINEST-formule oplevert toe aan de meervoudige regressievergelijking:
y = 0,3*x 2 + 0.19*x 1 - 10.74
Bijvoorbeeld, met 50 dollar uitgegeven aan reclame en een gemiddelde maandelijkse regenval van 100 mm, zult u naar verwachting ongeveer 23 paraplu's verkopen:
0.3*50 + 0.19*100 - 10.74 = 23.26
Eenvoudige lineaire regressie: afhankelijke variabele voorspellen
Naast de berekening van de a en b waarden voor de regressievergelijking, kan de Excel LINEST-functie ook de afhankelijke variabele (y) schatten op basis van de bekende onafhankelijke variabele (x). Hiervoor gebruikt u LINEST in combinatie met de functie SUM of SUMPRODUCT.
Bijvoorbeeld, hier is hoe u het aantal paraplu verkopen voor de volgende maand, zeg oktober, op basis van de verkoop in de voorgaande maanden en oktober reclamebudget van $ 50 te berekenen:
=SUM(LINEST(C2:C10, B2:B10)*{50,1})
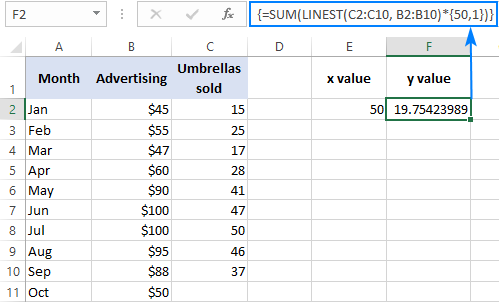
In plaats van de x In dit geval moet u de constante 1 ook in een cel invoeren, omdat u in een matrixconstante geen verwijzingen en waarden kunt mengen.
Met de x waarde in E2 en de constante 1 in F2, werkt één van de onderstaande formules prima:
Reguliere formule (ingevoerd door op Enter te drukken):
=SUMPRODUCT(LINEST(C2:C10, B2:B10)*(E2:F2))
Matrixformule (ingevoerd door op Ctrl + Shift + Enter te drukken):
=SUM(LINEST(C2:C10, B2:B10)*(E2:F2))
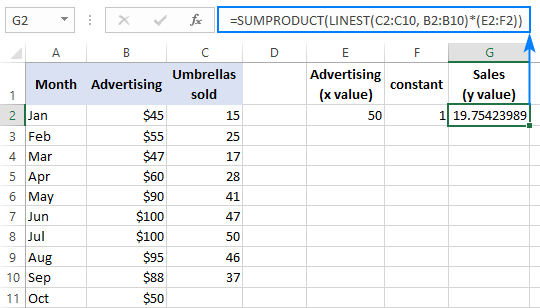
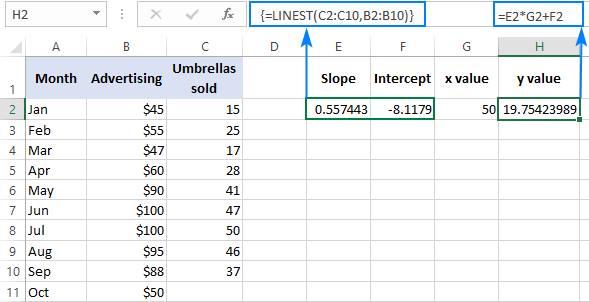
Om het resultaat te controleren, kunt u voor dezelfde gegevens het intercept en de helling bepalen, en vervolgens de lineaire regressieformule gebruiken om te berekenen y :
=E2*G2+F2
Waarbij E2 de helling is, G2 de x waarde, en F2 is het intercept:
Meervoudige regressie: afhankelijke variabele voorspellen
Als u te maken hebt met meerdere voorspellers, d.w.z. een paar verschillende sets van x waarden, al die voorspellers in de matrix constant. Bijvoorbeeld, met het reclamebudget van $50 (x 2 ) en een gemiddelde maandelijkse neerslag van 100 mm (x 1 ), gaat de formule als volgt:
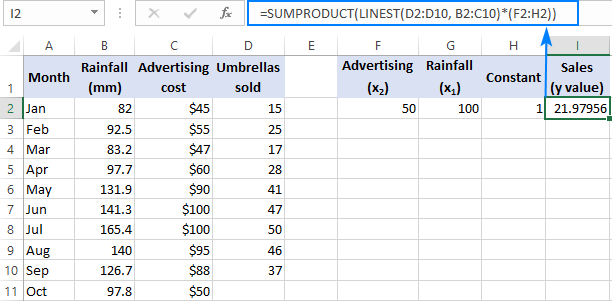
=SUM(LINEST(D2:D10, B2:C10)*{50,100,1})
Waarbij D2:D10 de bekende y waarden en B2:C10 zijn twee sets van x waarden:

Let op de volgorde van de x waarden in de matrix constant. Zoals eerder gezegd, wanneer de Excel LINEST-functie wordt gebruikt voor meervoudige regressie, geeft deze de hellingscoëfficiënten van rechts naar links terug. In ons voorbeeld is de Reclame coëfficiënt wordt eerst teruggegeven, en dan de Regenval coëfficiënt. Om het voorspelde verkoopcijfer correct te berekenen, moet u de coëfficiënten vermenigvuldigen met de overeenkomstige x waarden, dus zet je de elementen van de array constant in deze volgorde: {50,100,1}. Het laatste element is 1, want de laatste waarde die LINEST teruggeeft is de interceptie die niet veranderd mag worden, dus vermenigvuldig je die gewoon met 1.
In plaats van een matrixconstante te gebruiken, kunt u alle x-variabelen invoeren in enkele cellen, en in uw formule naar die cellen verwijzen, zoals we in het vorige voorbeeld hebben gedaan.
Normale formule:
=SUMPRODUCT(LINEST(D2:D10, B2:C10)*(F2:H2))
Matrixformule:
=SUM(LINEST(D2:D10, B2:C10)*(F2:H2))
Waarbij F2 en G2 de x waarden en H2 is 1:
LINEST-formule: aanvullende regressiestatistieken
Zoals u zich wellicht herinnert, zet u TRUE in het laatste argument van de LINEST-functie om meer statistieken voor uw regressieanalyse te verkrijgen. Toegepast op onze voorbeeldgegevens krijgt de formule de volgende vorm:
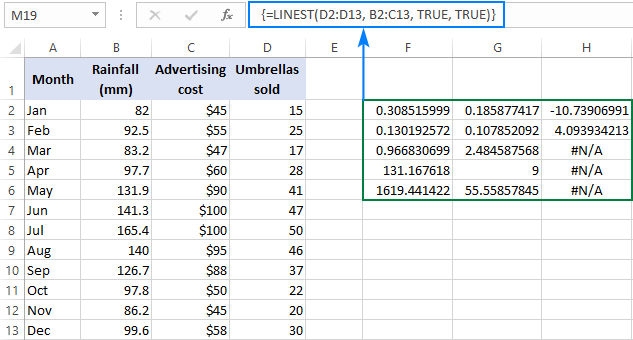
=LINEST(D2:D13, B2:C13, TRUE, TRUE)
Aangezien wij 2 onafhankelijke variabelen hebben in de kolommen B en C, selecteren wij een rage bestaande uit 3 rijen (twee x-waarden + intercept) en 5 kolommen, voeren de bovenstaande formule in, drukken op Ctrl + Shift + Enter , en krijgen dit resultaat:
Om van de #N/A-fouten af te komen, kunt u LINEST als volgt in IFERROR nestelen:
=IFERROR(LINEST(D2:D13, B2:C13, TRUE, TRUE), "")
De schermafbeelding hieronder toont het resultaat en legt uit wat elk getal betekent:

De hellingscoëfficiënten en het Y-intercept zijn uitgelegd in de vorige voorbeelden, dus laten we even kijken naar de andere statistieken.
Bepalingscoëfficiënt (De waarde van R2 is het resultaat van het delen van de som van de kwadraten van de regressie door de totale som van de kwadraten. Het vertelt je hoeveel y waarden worden verklaard door x In dit voorbeeld is R2 ongeveer 0,97, wat betekent dat 97% van onze afhankelijke variabelen (parapluverkoop) wordt verklaard door de onafhankelijke variabelen (reclame + gemiddelde maandelijkse regenval), wat een uitstekende fit is!
Standaardfouten In het algemeen tonen deze waarden de precisie van de regressieanalyse. Hoe kleiner de getallen, hoe zekerder u kunt zijn van uw regressiemodel.
F-statistiek U gebruikt de F-statistiek om de nulhypothese te ondersteunen of te verwerpen. Het verdient aanbeveling de F-statistiek te gebruiken in combinatie met de P-waarde om te bepalen of de totale resultaten significant zijn.
Vrijheidsgraden (df). De LINEST functie in Excel geeft de resterende vrijheidsgraden die de totaal df minus de regressie df U kunt de vrijheidsgraden gebruiken om F-kritische waarden te krijgen in een statistische tabel, en dan de F-kritische waarden vergelijken met de F-statistiek om een betrouwbaarheidsniveau voor uw model te bepalen.
Regressie som van de kwadraten (aka de verklaarde som van de kwadraten of model som van de kwadraten Het is de som van de gekwadrateerde verschillen tussen de voorspelde y-waarden en het gemiddelde van y, berekend met deze formule: =∑(ŷ - ȳ)2. Het geeft aan hoeveel van de variatie in de afhankelijke variabele uw regressiemodel verklaart.
Resterende som van de kwadraten Het is de som van de gekwadrateerde verschillen tussen de werkelijke y-waarden en de voorspelde y-waarden. Het geeft aan hoeveel van de variatie in de afhankelijke variabele uw model niet verklaart. Hoe kleiner de residuele som van de kwadraten in vergelijking met de totale som van de kwadraten, hoe beter uw regressiemodel bij uw gegevens past.
5 dingen die u moet weten over de LINEST-functie
Om LINEST-formules efficiënt te gebruiken in uw werkbladen, wilt u misschien iets meer weten over de "innerlijke werking" van de functie:
- Known_y's en known_x's In een eenvoudig lineair regressiemodel met slechts één reeks x-variabelen, known_y's en known_x's kunnen reeksen van elke vorm zijn, zolang ze maar hetzelfde aantal rijen en kolommen hebben. Als u een meervoudige regressieanalyse uitvoert met meer dan één reeks onafhankelijke x variabelen, known_y's moet een vector zijn, d.w.z. een bereik van één rij of één kolom.
- De constante op nul zetten Wanneer de const argument TRUE is of is weggelaten, de a constante (intercept) wordt berekend en opgenomen in de vergelijking: y=bx + a. Indien const is ingesteld op FALSE, wordt het intercept geacht gelijk te zijn aan 0 en weggelaten uit de regressievergelijking: y=bx.
In de statistiek wordt al tientallen jaren gedebatteerd over de vraag of het zinvol is de interceptconstante op 0 te zetten of niet. Veel geloofwaardige beoefenaars van regressieanalyse zijn van mening dat als het op nul zetten van de interceptie (const=FALSE) nuttig blijkt te zijn, de lineaire regressie zelf een verkeerd model is voor de gegevensverzameling. Anderen veronderstellen dat de constante in bepaalde situaties op nul kan worden gezet,in de context van regressie discontinuïteit ontwerpen. In het algemeen wordt aanbevolen om in de meeste gevallen de standaard const=TRUE of weggelaten.
- Nauwkeurigheid De nauwkeurigheid van de door de LINEST-functie berekende regressievergelijking hangt af van de spreiding van uw datapunten. Hoe lineairder de gegevens, hoe nauwkeuriger de resultaten van de LINEST-formule.
- Overbodige x-waarden In sommige situaties kunnen een of meer onafhankelijke x Het is mogelijk dat variabelen geen extra voorspellende waarde hebben, en het verwijderen van dergelijke variabelen uit het regressiemodel heeft geen invloed op de nauwkeurigheid van de voorspelde y-waarden. Dit verschijnsel staat bekend als "collineariteit". De LINEST-functie van Excel controleert op collineariteit en laat overbodige variabelen weg. x variabelen die het uit het model haalt. De weggelaten x variabelen zijn te herkennen aan 0 coëfficiënten en 0 standaardfoutwaarden.
- LIJNEN vs. HELLING en INTERCEPT Het onderliggende algoritme van de LINEST-functie verschilt van het algoritme van de SLOPE- en INTERCEPT-functies. Wanneer de brongegevens onbepaald of collineair zijn, kunnen deze functies derhalve verschillende resultaten opleveren.
Excel LINEST functie werkt niet
Als uw LINEST-formule een foutmelding geeft of een verkeerde uitvoer produceert, is de kans groot dat dit komt door een van de volgende redenen:
- Indien de LINEST-functie slechts één getal (hellingscoëfficiënt) oplevert, hebt u deze waarschijnlijk ingevoerd als een gewone formule en niet als een matrixformule. Zorg ervoor dat u op Ctrl + Shift + Enter drukt om de formule correct in te vullen. Wanneer u dit doet, wordt de formule ingesloten in de {kroeshaken} die zichtbaar zijn in de formulebalk.
- #REF! fout. Komt voor als de known_x's en known_y's reeksen hebben verschillende afmetingen.
- #VALUE! fout. Komt voor als known_x's of known_y's ten minste één lege cel, tekstwaarde of tekstrepresentatie van een getal bevat dat Excel niet herkent als een numerieke waarde. Ook treedt de #VALUE foutmelding op indien de const of stats argument kan niet worden geëvalueerd op TRUE of FALSE.
Dat is hoe u LINEST in Excel gebruikt voor een eenvoudige en meervoudige lineaire regressieanalyse. Om de formules die in deze tutorial worden besproken nader te bekijken, kunt u hieronder onze voorbeeldwerkmap downloaden. Ik dank u voor het lezen en hoop u volgende week op onze blog te zien!
Praktijk werkboek om te downloaden
Excel LINEST functievoorbeelden (.xlsx bestand)
