
目次
このチュートリアルでは、LINEST関数のシンタックスを説明し、それを使ってExcelで線形回帰分析を行う方法を紹介します。
Microsoft Excelは統計プログラムではありませんが、いくつかの統計関数を備えています。 その一つがLINESTで、これは線形回帰分析と関連する統計値を返すように設計されています。 この初心者向けチュートリアルでは、理論や基礎的な計算については軽く触れるにとどめます。 主に、簡単に機能する数式を提供することとは、お客様のデータに合わせて簡単にカスタマイズすることができます。
Excel LINEST関数 - 構文と基本的な使用方法
LINEST関数は、独立変数と1つ以上の従属変数の関係を説明する直線の統計量を計算し、その直線を記述した配列を返します。 この関数は、独立変数と1つ以上の従属変数の関係を説明する直線を記述した配列を使用します。 最小二乗 メソッドを使用して、データに最もフィットするものを探します。 直線の方程式は次のようになります。
単純な線形回帰式。
y = bx + a重回帰式。
y = b 1 x 1 + b 2 x 2 + ... + b n x n + aどこで
- y - 予測しようとする従属変数
- x - 予測に使用する独立変数 y .
- a - 切片(線がY軸と交差する場所を示す)。
- b - 傾き(回帰線の急勾配、すなわちxが変化したときのyの変化率を示す)。
LINEST関数は、基本的には回帰式の切片(a)と傾き(b)を返します。 オプションとして、この例に示すように、回帰分析の追加統計量を返すこともできます。
LINEST関数の構文
Excel LINEST関数の構文は次のとおりです。
LINEST(known_y's, [known_x's], [const], [stats])どこで
- known_yの (必須)は、依存関係の範囲 y -通常、1列または1行の値である。
- known_xの (オプション) は独立した x 値の範囲であり,省略された場合は known_yの .
- コンスト (オプション) - 切片 (定数) をどのように定義するかを決定する論理値です。 a )を処理する必要があります。
- TRUE または省略された場合、定数 a は正常に計算されます。
- FALSEの場合、定数 a は強制的に0にされ、傾き( b 係数)を計算し、y=bxに適合させる。
- スタッツ (オプション)は、追加統計情報を出力するかどうかを決定するための論理値である。
- TRUE の場合、LINEST 関数は回帰統計量を追加した配列を返します。
- FALSE または省略された場合、LINEST は切片定数とスロープ係数のみを返す。
注)LINESTは値の配列を返すので、Ctrl + Shift + Enterのショートカットキーで配列式として入力する必要があります。 通常の式として入力すると、最初の傾き係数のみが返されます。
LINESTが返す追加統計情報
があります。 スタッツ 引数を TRUE に設定すると、LINEST 関数は回帰分析のために次の統計値を返すように指示します。
| 統計データ | 商品説明 |
| スロープ係数 | y = bx + aにおけるb値 |
| インターセプト定数 | y = bx + aにおける値 |
| 傾きの標準誤差 | b係数の標準誤差の値(複数可) |
| 切片の標準誤差 | 定数に対する標準誤差の値 a . |
| 決定係数(R2) | 回帰式がどの程度、変数間の関係を説明できるかを示す。 |
| Yの推定値の標準誤差 | 回帰分析の精度を示す。 |
| F統計量、またはF-observed値 | 帰無仮説のF検定を行い、モデルの全体的な適合度を判断するために使用されます。 |
| 自由度(df) | 自由度の数です。 |
| 回帰自乗和 | 従属変数の変動のうち、どの程度がモデルによって説明されるかを示す。 |
| 残差二乗和 | 回帰モデルで説明されない従属変数の分散の量を測定します。 |
以下のマップは、LINESTが統計情報の配列を返す順番を示しています。

最後の3行目以降、データの入っていない列には#N/Aエラーが表示されます。 これはLINEST関数のデフォルトの動作ですが、エラー表記を隠したい場合は、この例のようにLINEST式をIFERRORでくくるようにしましょう。
ExcelでLINESTを使用する方法 - 数式の例
LINEST関数は、数式を正しく構築するだけでなく、その出力を適切に解釈する必要があるため、特に初心者の方には使いにくいかもしれません。 以下に、ExcelでLINEST式を使用するいくつかの例を示しますので、理論的な知識を身につけるのに役立つと思います:)。
単純な線形回帰:傾きと切片を計算する
回帰線の切片と傾きを求めるには、LINEST関数を最も単純な形で使用します。 known_yの の引数と独立した値の範囲を指定します。 known_xの 最後の2つの引数は、TRUEに設定するか省略することができる。
例えば y の値(売上数)とB2:B13のxの値(広告費)があれば、私たちの線形回帰式は次のように簡単になります。
=LINEST(C2:C13,B2:B13)
ワークシートに正しく入力するには、同じ行の隣接する2つのセル(この例ではE2:F2)を選択し、数式を入力し、Ctrl + Shift + Enterキーで完了させることができます。
この式では、最初のセル(E2)に傾き係数、2番目のセル(F2)に切片定数が返されます。
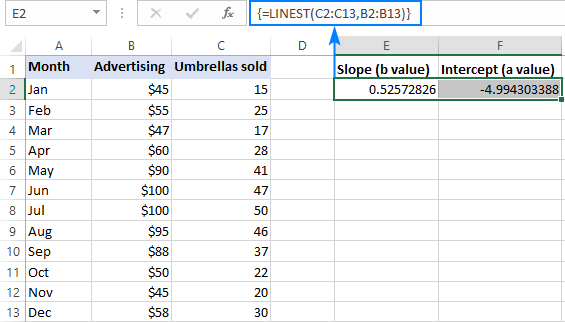
があります。 傾き は約0.52(小数点以下第3位を四捨五入)である。 これは、以下のような場合である。 x が1ずつ増加します。 y が0.52増加する。
があります。 Y切片 の期待値はマイナス-4.99である。 y グラフにプロットした場合、回帰線がy軸と交差する値です。
上記の値を単純な線形回帰式に代入すると、広告費から売上高を予測する以下の式が得られます。
y = 0.52*x - 4.99
例えば、50ドルの広告費をかけた場合、21本の傘を売ることが期待されます。
0.52*50 - 4.99 = 21.01
また、傾きと切片の値は、対応する関数を使用するか、LINEST式をINDEXに入れ込むことで別々に求めることができます。
斜面
=SLOPE(C2:C13,B2:B13)
=index(linest(c2:c13,b2:b13),1)である。
インターセプト
=切片(c2:c13,b2:b13)
=index(linest(c2:c13,b2:b13),2)である。
以下のスクリーンショットに示すように、3つの計算式はすべて同じ結果をもたらします。

重回帰:傾きと切片
独立変数が2つ以上ある場合は、必ず隣の列に入力し、その範囲全体を known_xの の議論になります。
例えば、販売数で( y D2:D13の広告費(x値の1セット)、B2:B13の月平均降水量(x値のもう1セット)。 x の値)をC2:C13で計算すると、この式になります。
=LINEST(D2:D13,B2:C13)
数式は3つの値(2つの傾き係数と切片定数)の配列を返すつもりなので、同じ行の連続した3つのセルを選択し、数式を入力してCtrl + Shift + Enterのショートカットを押します。
を重回帰式で返すことに注意してください。 傾斜係数 において 逆順 の独立変数(右から左へ)、すなわち、b n , b n-1 , ..., b 2 , b 1 :
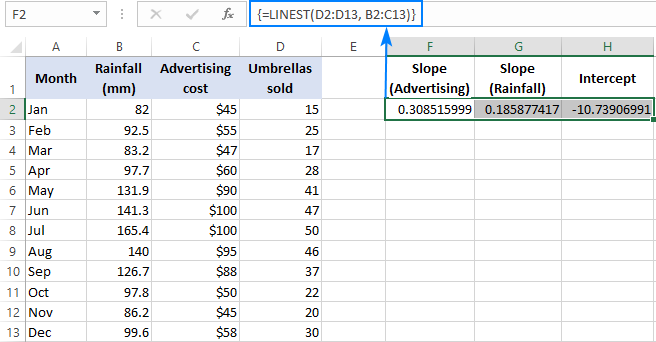
販売数を予測するために、LINEST式で返された値を重回帰式に供給する。
y = 0.3*x 2 + 0.19*x 1 - 10.74
例えば、広告費50ドル、月平均降水量100mmの場合、約23本の傘が売れると予想されます。
0.3*50 + 0.19*100 - 10.74 = 23.26
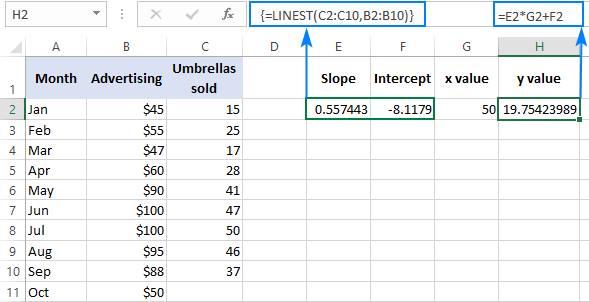
単純な線形回帰:従属変数を予測する
計算とは別に a と b Excel の LINEST 関数は、既知の独立変数 (x) に基づいて従属変数 (y) を推定することもできます。 この場合、LINEST を SUM または SUMPRODUCT 関数と組み合わせて使用します。
例えば、前の月の売上と10月の広告予算50ドルから、次の月、例えば10月の傘の売上枚数を計算する方法は次のとおりです。
=SUM(LINEST(C2:C10, B2:B10)*{50,1})
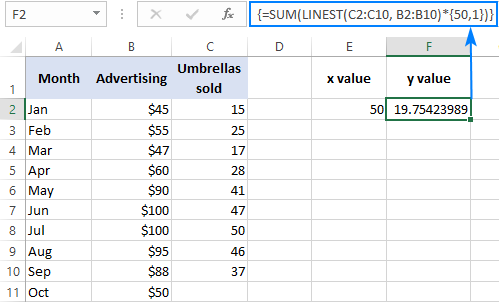
をハードコードする代わりに x この場合、配列定数には参照と値を混在させることができないので、1定数もどこかのセルに入力する必要があります。
とともに x を E2 に、定数 1 を F2 に指定すれば、以下の計算式のいずれかを用いて計算することができます。
正規の数式(Enterキーで入力)。
=sumproduct(linest(c2:c10,b2:b10)*(e2:f2))
配列式(Ctrl + Shift + Enterキーで入力)。
=sum(linest(c2:c10, b2:b10)*(e2:f2))
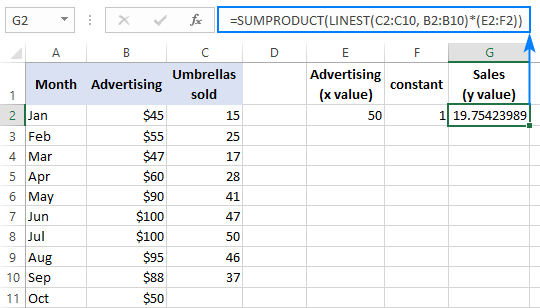
この結果を確認するには、同じデータの切片と傾きを求め、線形回帰式を用いて y :
=E2*G2+F2
ここで、E2 は傾き、G2 は x 値、F2 は切片である。
重回帰:被説明変数の予測
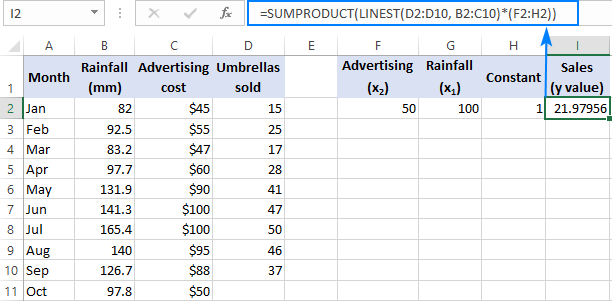
複数の予測因子、つまり、いくつかの異なるセットを扱う場合 x の値がある場合、それらの予測変数はすべて配列の定数に含める。 例えば、広告予算が50ドルの場合(x 2 )、月平均降水量100mm(x 1 ) の場合、次のような式になる。
=SUM(LINEST(D2:D10, B2:C10)*{50,100,1})
ここで、D2:D10は既知の y の値、B2:C10は2つのセットです。 x の値です。

の順番にご注意ください。 x の値を定数として返します。 先ほども指摘したように、ExcelのLINEST関数で重回帰を行う場合、右から左に向かって傾きの係数を返します。 この例では 広告宣伝 係数が最初に返され、その後 雨量 予測販売数を正しく計算するためには、係数を掛け合わせる必要があります。 x LINESTが返す最後の値は変更してはいけない切片なので、単純に1倍しています。
配列定数を使う代わりに、前の例でやったように、いくつかのセルにすべてのx変数を入力し、それらのセルを数式で参照することができます。
レギュラー・フォーミュラ。
=sumproduct(linest(d2:d10,b2:c10)*(f2:h2))とする。
アレイ式。
=sum(linest(d2:d10, b2:c10)*(f2:h2))である。
ここで、F2 と G2 は x の値で、H2が1である。
LINEST式:回帰統計量の追加
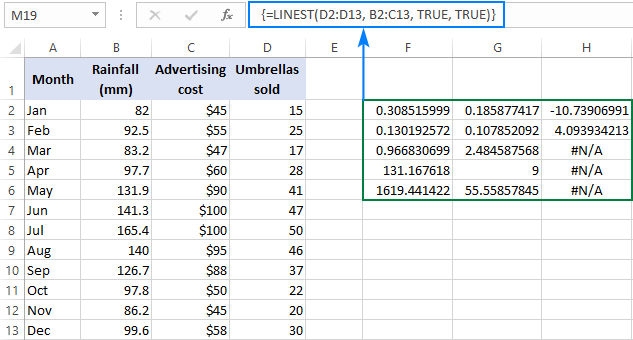
ご記憶の方も多いと思いますが、回帰分析でより多くの統計量を得るために、LINEST関数の最後の引数にTRUEを入れます。 今回のサンプルデータに適用すると、以下のような形の式になります。
=linest(d2:d13, b2:c13, true, true)
B列とC列に2つの独立変数があるので、3行(2つのx値+切片)と5列からなる憤怒を選択し、上記の式を入力し、Ctrl + Shift + Enter を押して、この結果を得ます。
N/Aエラーをなくすには、次のようにLINESTをIFERRORにネストすればよい。
=iferror(linest(d2:d13, b2:c13, true, true), "")
下のスクリーンショットはその結果を示すもので、それぞれの数値が何を意味するのかを説明しています。

傾きの係数とY切片は前の例で説明しましたので、他の統計量について簡単に見てみましょう。
決定係数 (R2 は、回帰の二乗和を全二乗和で割った値であり、回帰の二乗和が何乗に相当するかを示している。 y の値は、以下のように説明されます。 x この例では、R2 は約 0.97 であり、従属変数(傘の売り上げ)の 97% が独立変数(広告 + 月平均雨量)で説明できることを意味し、素晴らしい適合性です。
標準誤差 一般に、これらの値は回帰分析の精度を示しており、数値が小さいほど、回帰モデルについてより確実であることを示しています。
F統計量 帰無仮説を支持または棄却するために F 統計量を使用します。 全体の結果が有意であるかどうかを判断する際には、F 統計量と P 値を組み合わせて使用することが推奨されます。
自由度 (df)を返すExcelのLINEST関数。 残留自由度 である。 全DF を差し引くと 回帰df 自由度を用いて統計表でF臨界値を求め、F臨界値をF統計量と比較してモデルの信頼度を決定することができます。
回帰自乗和 (を使用することができます。 説明済み二乗和 または モデル二乗和 これは,予測されたy値とyの平均の間の2乗差の合計で,この式で計算される: =∑(ŷ - ↪Ll_233)2. これは,回帰モデルが従属変数の変動のどれぐらいを説明するかを示す.
残差二乗和 これは、実際のY値と予測されたY値の差の2乗の合計です。 これは、モデルが従属変数の変動のどれだけを説明していないかを示します。 残差平方和が全体の平方和と比較して小さいほど、回帰モデルがデータによく適合していることを示しています。
LINEST機能について知っておくべき5つのこと
ワークシートでLINEST式を効率的に使用するには、関数の「内部構造」についてもう少し知っておくとよいでしょう。
- Known_y's と known_xの x変数が1組だけの単純な線形回帰モデルでは、このようになります。 known_yの と known_xの は,行と列の数が同じであれば,どのような形でもよい。 複数の独立な x の変数を使用します。 known_yの は,ベクトル,すなわち1行または1列の範囲でなければならない。
- 定数を強制的にゼロにする .その時 コンスト 引数が TRUE であるか、または省略された場合は a の場合、定数(切片)が計算され、方程式:y=bx + a に含まれます。 コンスト をFALSEに設定すると、切片は0とみなされ、回帰式:y=bxから省略される。
統計学では、切片定数を強制的に0にすることに意味があるかどうか、何十年も議論されてきました。 多くの信頼できる回帰分析の専門家は、もし切片を0にする(const=FALSE)ことが有効だと思われたら、線形回帰自体がデータセットに対して誤ったモデルであると考えています。 また、例えば特定の状況下では定数は強制的に0にできるとする人もいます。一般的には、ほとんどの場合、デフォルトのconst=TRUEまたは省略することをお勧めします。
- 精度 LINEST関数で計算される回帰式の精度は、データポイントの分散に依存します。 データが直線的であればあるほど、LINEST式の結果はより正確なものになります。
- 冗長なx値 状況によっては、1つまたは複数の独立した x この現象は「共線性」と呼ばれ、Excel の LINEST 関数は共線性をチェックし、冗長な変数を省くことができます。 x モデルから特定した変数が省略されている。 x は、係数 0、標準誤差 0 で認識することができる。
- LINESTとSLOPE、INTERCEPTの比較 LINEST関数は、SLOPE関数やINTERCEPT関数とはアルゴリズムが異なるため、元データが未確定または共線的な場合、異なる結果を返すことがあります。
Excel LINEST関数が動作しない
LINEST の数式でエラーが発生したり、間違った出力が出る場合は、次のいずれかの原因が考えられます。
- LINEST関数が1つの数値(勾配係数)だけを返す場合、配列式ではなく通常の数式として入力した可能性が高いです。 Ctrl + Shift + Enterキーを押して数式を正しく入力してください。 このとき、数式は数式バーに表示されている{カーリーブラケット}で囲まれます。
- #REF! エラー。 known_xの と known_yの は、異なる次元のものです。
- #VALUE! エラーです。 known_xの または known_yの は、Excelが数値として認識しない空白セル、テキスト値、数値のテキスト表現が少なくとも1つ含まれています。 また、#VALUEエラーが発生するのは コンスト または スタッツ 引数は TRUE または FALSE に評価できない。
以上、ExcelでLINESTを使用して単回帰分析および重回帰分析を行う方法でした。 このチュートリアルで説明した数式をより詳しく見るには、以下のサンプルワークブックをダウンロードしてください。 読んでいただきありがとうございました。
練習用ワークブック(ダウンロード
Excel LINEST 関数例 (.xlsx ファイル)
