
Sadržaj
Ovaj vodič objašnjava sintaksu funkcije LINEST i pokazuje kako je koristiti za analizu linearne regresije u Excelu.
Microsoft Excel nije statistički program, međutim, on to čini imaju niz statističkih funkcija. Jedna od takvih funkcija je LINEST, koja je dizajnirana za izvođenje analize linearne regresije i statistike vezane za povratak. U ovom tutorijalu za početnike, samo ćemo se malo dotaknuti teorije i osnovnih proračuna. Naš glavni fokus će biti na tome da vam pružimo formulu koja jednostavno radi i koja se lako može prilagoditi vašim podacima.
Excel LINEST funkcija - sintaksa i osnovne upotrebe
Funkcija LINEST izračunava statistiku za ravnu liniju koja objašnjava odnos između nezavisne varijable i jedne ili više zavisnih varijabli i vraća niz koji opisuje liniju. Funkcija koristi metodu najmanjih kvadrata kako bi pronašla najbolje za vaše podatke. Jednačina za liniju je sljedeća.
Jednostavna jednačina linearne regresije:
y = bx + aJedna višestruke regresije:
y = b 1x 1+ b 2x 2+ … + b nx n+ aGdje:
- y - zavisna varijabla koju pokušavate predvidjeti.
- x - nezavisna varijabla koju koristite za predviđanje y .
- a - presek (označava gdje prava seče Y osu).
- b - nagibznačajno.
Stepeni slobode (df). Funkcija LINEST u Excelu vraća preostalih stupnjeva slobode , što je ukupni df minus regresija df . Možete koristiti stupnjeve slobode da dobijete F-kritične vrijednosti u statističkoj tabeli, a zatim uporedite F-kritične vrijednosti sa F statistikom da odredite nivo pouzdanosti za vaš model.
Regresijski zbroj kvadrata (aka objašnjeni zbir kvadrata , ili modelski zbir kvadrata ). To je zbir kvadrata razlika između predviđenih y-vrijednosti i srednje vrijednosti y, izračunate po ovoj formuli: =∑(ŷ - ȳ)2. Pokazuje koliki dio varijacije zavisne varijable objašnjava vaš regresijski model.
Preostali zbir kvadrata . To je zbir kvadrata razlika između stvarnih y-vrijednosti i predviđenih y-vrijednosti. Pokazuje koliki dio varijacije zavisne varijable vaš model ne objašnjava. Što je manji preostali zbir kvadrata u poređenju sa ukupnim zbirom kvadrata, to bolje vaš regresijski model odgovara vašim podacima.
5 stvari koje biste trebali znati o funkciji LINEST
Da biste efikasno koristili formule LINEST u Vaši radni listovi, možda biste željeli znati nešto više o "unutrašnjoj mehanici" funkcije:
- Poznati_y i poznati_x . U jednostavnom modelu linearne regresije sa samo jednim skupom x varijabli, poznati_y i poznati_x mogu biti opsezi bilo kojeg oblika sve dok imaju isti broj redova i stupaca. Ako radite višestruku regresijsku analizu s više od jednog skupa nezavisnih x varijabli, poznati_y mora biti vektor, tj. raspon od jednog reda ili jednog stupca.
- Forsiranje konstante na nulu . Kada je argument const TRUE ili je izostavljen, konstanta a (intercept) se izračunava i uključuje u jednačinu: y=bx + a. Ako je const postavljeno na FALSE, smatra se da je presjek jednak 0 i izostavljen je iz jednadžbe regresije: y=bx.
U statistici se decenijama raspravlja da li ima smisla prisiliti konstantu presretanja na 0 ili ne. Mnogi vjerodostojni praktičari regresijske analize vjeruju da ako se postavljanje presjeka na nulu (const=FALSE) čini korisnim, onda je linearna regresija sama po sebi pogrešan model za skup podataka. Drugi pretpostavljaju da se konstanta može natjerati na nulu u određenim situacijama, na primjer, u kontekstu dizajna diskontinuiteta regresije. Općenito, preporučuje se da idete sa default const=TRUE ili izostavite u većini slučajeva.
- Preciznost . Preciznost jednadžbe regresije koju izračunava funkcija LINEST ovisi o disperziji vaših podataka. Što su podaci linearniji, to su precizniji rezultati formule LINEST.
- Redundantne x vrijednosti . U nekim situacijama,jedna ili više nezavisnih varijabli x možda nemaju dodatnu prediktivnu vrijednost, a uklanjanje takvih varijabli iz regresijskog modela ne utiče na tačnost predviđenih y vrijednosti. Ovaj fenomen je poznat kao "kolinearnost". Excel LINEST funkcija provjerava kolinearnost i izostavlja sve redundantne x varijable koje identificira iz modela. Izostavljene varijable x mogu se prepoznati po 0 koeficijenata i 0 vrijednosti standardne greške.
- LINEST vs. SLOPE i INTERCEPT . Osnovni algoritam funkcije LINEST razlikuje se od algoritma koji se koristi u funkcijama SLOPE i INTERCEPT. Stoga, kada su izvorni podaci neodređeni ili kolinearni, ove funkcije mogu vratiti različite rezultate.
Excel funkcija LINEST ne radi
Ako vaša LINEST formula daje grešku ili daje pogrešan izlaz , velike su šanse da je to zbog jednog od sljedećih razloga:
- Ako funkcija LINEST vraća samo jedan broj (koeficijent nagiba), najvjerovatnije ste ga unijeli kao regularnu formulu, a ne formulu niza. Obavezno pritisnite Ctrl + Shift + Enter da biste pravilno dovršili formulu. Kada to uradite, formula će biti zatvorena u {kovrdžavaste zagrade} koje su vidljive u traci formule.
- #REF! greška. Pojavljuje se ako rasponi poznati_x i poznati_y imaju različite dimenzije.
- #VRIJEDNOST! greška. Javlja se ako poznati_x ili poznati_y sadrži najmanje jednu praznu ćeliju, tekstualnu vrijednost ili tekstualni prikaz broja koji Excel ne prepoznaje kao numeričku vrijednost. Također, greška #VALUE se javlja ako se argument const ili stats ne može procijeniti na TRUE ili FALSE.
Tako koristite LINEST u Excelu za jednostavna i višestruka linearna regresijska analiza. Da biste bliže pogledali formule o kojima se govori u ovom vodiču, možete preuzeti naš primjer radne sveske ispod. Zahvaljujem vam na čitanju i nadam se da se vidimo na našem blogu sljedeće sedmice!
Vježbanje za preuzimanje
Primjeri funkcija Excel LINEST (.xlsx datoteka)
(ukazuje na strminu regresijske linije, tj. stopu promjene za y kako se mijenja x).
U svom osnovnom obliku, funkcija LINEST vraća presjek (a) i nagib (b) za jednadžbu regresije. Opciono, također može vratiti dodatnu statistiku za regresijsku analizu kao što je prikazano u ovom primjeru.
Sintaksa funkcije LINEST
Sintaksa Excel funkcije LINEST je sljedeća:
LINEST(poznati_y's , [poznati_x], [const], [stats])Gdje je:
- poznati_y (obavezno) je raspon zavisnih y -vrijednosti u jednadžbi regresije. Obično je to jedna kolona ili jedan red.
- poznati_x (opciono) je raspon nezavisnih x-vrijednosti. Ako se izostavi, pretpostavlja se da je niz {1,2,3,...} iste veličine kao poznati_y .
- const (opciono) - logička vrijednost koja određuje kako se presretanje (konstanta a ) treba tretirati:
- Ako je TRUE ili izostavljeno, konstanta a se izračunava normalno.
- Ako je FALSE, konstanta a se postavlja na 0 i nagib ( b koeficijent) se izračunava tako da odgovara y=bx.
- stats (opciono) je logička vrijednost koja određuje hoće li se ispisati dodatne statistike ili ne:
- Ako je TRUE, funkcija LINEST vraća niz s dodatnom statistikom regresije.
- Ako je FALSE ili izostavljen, LINEST vraća samo konstantu presjeka i nagibkoeficijent(i).
Napomena. Budući da LINEST vraća niz vrijednosti, mora se unijeti kao formula niza pritiskom na prečicu Ctrl + Shift + Enter. Ako se unese kao redovna formula, vraća se samo prvi koeficijent nagiba.
Dodatne statistike koje vraća LINEST
Argument stats postavljen na TRUE daje instrukcije funkciji LINEST da vrati sljedeće statistike za vašu regresijsku analizu:
| Statistika | Opis |
| Koeficijent nagiba | b vrijednost u y = bx + a |
| Konstanta presjeka | a vrijednost u y = bx + a |
| Standardna greška nagiba | Standardna vrijednost(e) greške za b koeficijent(i). |
| Standardna greška presjeka | Standardna vrijednost greške za konstantu a . |
| Koeficijent determinacije (R2) | Označava koliko dobro jednačina regresije objašnjava odnos između varijabli. |
| Standardna greška za Y procjenu | Pokazuje preciznost regresione analize. |
| F statistika, ili F-uočena vrijednost | Koristi se za izvođenje F-testa za nulta hipoteza za određivanje ukupne dobrote uklapanja modela. |
| Stepeni fr eedom (df) | Broj stupnjeva slobode. |
| Regresijski zbir kvadrata | Označava koliki je dio varijacije uZavisna varijabla je objašnjena modelom. |
| Preostali zbir kvadrata | Mjeri količinu varijanse zavisne varijable koja nije objašnjena vašim regresijskim modelom. |
Mapa ispod pokazuje redoslijed kojim LINEST vraća niz statistika:

U posljednja tri reda, #N/A greške će se pojaviti u trećoj i sljedećim kolonama koje nisu popunjene podacima. To je zadano ponašanje funkcije LINEST, ali ako želite sakriti oznake greške, umotajte svoju LINEST formulu u IFERROR kao što je prikazano u ovom primjeru.
Kako koristiti LINEST u Excelu - primjeri formule
Funkcija LINEST može biti teška za korištenje, posebno za početnike, jer ne samo da biste trebali ispravno izgraditi formulu, već i pravilno interpretirati njen izlaz. Ispod ćete pronaći nekoliko primjera korištenja LINEST formula u Excel-u koji će, nadamo se, pomoći da se potopi teoretsko znanje u :)
Jednostavna linearna regresija: izračunajte nagib i presjek
Da biste dobili presjek i nagib linije regresije, koristite funkciju LINEST u njenom najjednostavnijem obliku: navedite raspon zavisnih vrijednosti za poznati_y argument i raspon nezavisnih vrijednosti za poznati_x argument. Posljednja dva argumenta mogu se postaviti na TRUE ili izostaviti.
Na primjer, sa y vrijednostima (prodajnim brojevima) u C2:C13 i x vrijednostima(troškovi oglašavanja) u B2:B13, naša formula linearne regresije je jednostavna kao:
=LINEST(C2:C13,B2:B13)
Da biste je ispravno unijeli u radni list, odaberite dvije susjedne ćelije u istom redu, E2: F2 u ovom primjeru, upišite formulu i pritisnite Ctrl + Shift + Enter da je dovršite.
Formula će vratiti koeficijent nagiba u prvoj ćeliji (E2) i konstantu presjeka u drugoj ćeliji (F2 ):
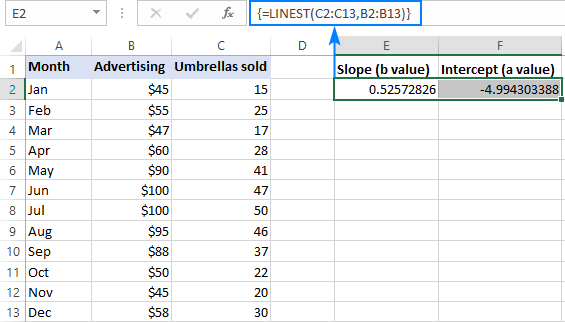
Nagib nagib je približno 0,52 (zaokruženo na dvije decimale). To znači da kada se x poveća za 1, y raste za 0,52.
Y-presjek je negativan -4,99. To je očekivana vrijednost y kada je x=0. Ako je nacrtana na grafikonu, to je vrijednost pri kojoj linija regresije prelazi y-osu.
Unesite gornje vrijednosti u jednostavnu jednadžbu linearne regresije i dobit ćete sljedeću formulu za predviđanje broja prodaje na osnovu troškova oglašavanja:
y = 0.52*x - 4.99
Na primjer, ako potrošite 50 USD na oglašavanje, očekuje se da ćete prodati 21 suncobran:
0.52*50 - 4.99 = 21.01
Vrijednosti nagiba i presjeka se također mogu dobiti odvojeno korištenjem odgovarajuće funkcije ili ugniježđenjem formule LINEST u INDEX:
Slope
=SLOPE(C2:C13,B2:B13)
=INDEX(LINEST(C2:C13,B2:B13),1)
Presret
=INTERCEPT(C2:C13,B2:B13)
=INDEX(LINEST(C2:C13,B2:B13),2)
Kao što je prikazano na slici ispod, sve tri formule daju iste rezultate:

Višestruka linearna regresija: nagib i presek
U slučaju da imatedvije ili više nezavisnih varijabli, obavezno ih unesite u susjedne stupce i dostavite cijeli raspon argumentu poznati_x .
Na primjer, s brojevima prodaje ( y vrijednosti) u D2:D13, troškovi oglašavanja (jedan skup x vrijednosti) u B2:B13 i prosječna mjesečna količina padavina (drugi skup vrijednosti x ) u C2:C13, koristite ovu formulu:
=LINEST(D2:D13,B2:C13)
Kako će formula vratiti niz od 3 vrijednosti (2 koeficijenta nagiba i konstanta presjeka), odabiremo tri susjedne ćelije u istom redu, unesemo formulu i pritisnemo Ctrl + Shift + Enter prečica.
Imajte na umu da formula višestruke regresije vraća koeficijente nagiba u obrnutim redoslijedom nezavisnih varijabli (s desna na lijevo), da je b n , b n-1 , …, b 2 , b 1 :
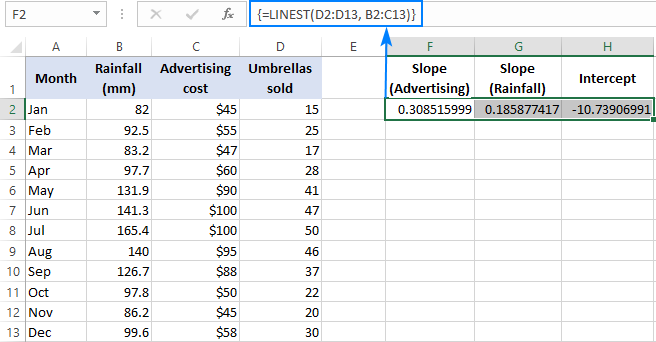
Da bismo predvidjeli broj prodaje, unosimo vrijednosti koje vraća formula LINEST u jednadžbu višestruke regresije:
y = 0,3*x 2 + 0,19*x 1 - 10,74
npr dovoljno, sa 50 dolara potrošenim na oglašavanje i prosječnom mjesečnom količinom padavina od 100 mm, očekuje se da ćete prodati otprilike 23 kišobrana:
0.3*50 + 0.19*100 - 10.74 = 23.26
Jednostavna linearna regresija: predvidite zavisnu varijablu
Osim izračunavanja a i b vrijednosti za jednadžbu regresije, Excel LINEST funkcija također može procijeniti zavisnu varijablu (y) na osnovu poznatih nezavisnihvarijabla (x). Za ovo koristite LINEST u kombinaciji sa funkcijom SUM ili SUMPRODUCT.
Na primjer, evo kako možete izračunati broj krovnih prodaja za sljedeći mjesec, recimo oktobar, na osnovu prodaje u prethodnim mjesecima i Oktobarski budžet za oglašavanje od 50 USD:
=SUM(LINEST(C2:C10, B2:B10)*{50,1})
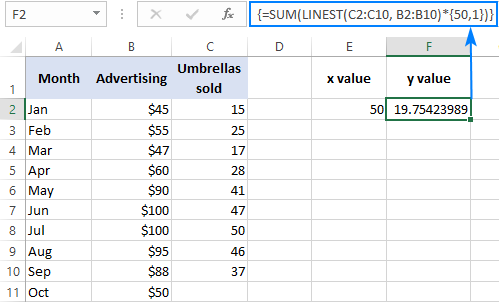
Umjesto da čvrsto kodirate vrijednost x u formuli, možete je dati kao referenca ćelije. U ovom slučaju, morate unijeti konstantu 1 iu neku ćeliju jer ne možete miješati reference i vrijednosti u konstanti niza.
Sa x vrijednošću u E2 i konstantom 1 u F2, bilo koja od sljedećih formula će raditi kao poslastica:
Obična formula (unesena pritiskom na Enter ):
=SUMPRODUCT(LINEST(C2:C10, B2:B10)*(E2:F2))
Formula niza (unesena pritiskom na Ctrl + Shift + Unesite ):
=SUM(LINEST(C2:C10, B2:B10)*(E2:F2))
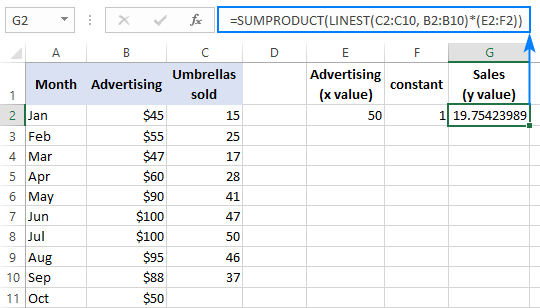
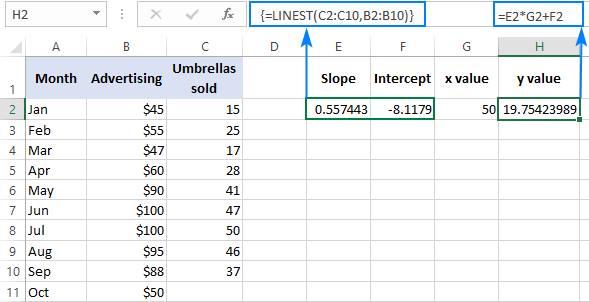
Da biste potvrdili rezultat, možete dobiti presjek i nagib za iste podatke, a zatim koristiti formulu linearne regresije da izračunaj y :
=E2*G2+F2
Gdje je E2 nagib, G2 je x vrijednost, a F2 je presjek:
Višestruka regresija: predvidi zavisnu varijablu
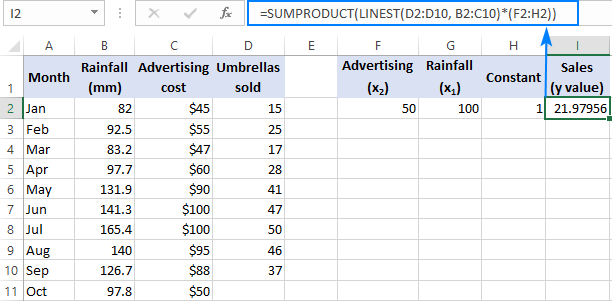
U slučaju da imate posla s nekoliko prediktora, tj. nekoliko različitih skupova x vrijednosti, uključite sve one prediktori u konstanti niza. Na primjer, sa budžetom za oglašavanje od 50 USD (x 2 ) i prosječnom mjesečnom količinom padavina od 100 mm (x 1 ), formula izgleda kaoslijedi:
=SUM(LINEST(D2:D10, B2:C10)*{50,100,1})
Gdje su D2:D10 poznate y vrijednosti, a B2:C10 su dva skupa x vrijednosti:

Obratite pažnju na redoslijed vrijednosti x u konstanti niza. Kao što je ranije istaknuto, kada se funkcija Excel LINEST koristi za višestruku regresiju, ona vraća koeficijente nagiba s desna na lijevo. U našem primjeru, prvo se vraća koeficijent Advertising , a zatim koeficijent Rainfall . Da biste ispravno izračunali predviđeni broj prodaje, morate pomnožiti koeficijente sa odgovarajućim vrijednostima x , tako da elemente konstante niza postavite ovim redoslijedom: {50,100,1}. Zadnji element je 1, jer je posljednja vrijednost koju vraća LINEST presretak koji ne treba mijenjati, tako da ga jednostavno pomnožite sa 1.
Umjesto korištenja konstante niza, možete unijeti sve varijable x u nekim ćelijama i referencirajte te ćelije u vašoj formuli kao što smo radili u prethodnom primjeru.
Obična formula:
=SUMPRODUCT(LINEST(D2:D10, B2:C10)*(F2:H2))
Formula niza:
=SUM(LINEST(D2:D10, B2:C10)*(F2:H2))
Gdje su F2 i G2 vrijednosti x , a H2 je 1:
LINEST formula: dodatna statistika regresije
Kao što se možda sjećate, da biste dobili više statistike za vašu regresijsku analizu, stavite TRUE u posljednji argument funkcije LINEST. Primijenjena na naše uzorke podataka, formula poprima sljedeći oblik:
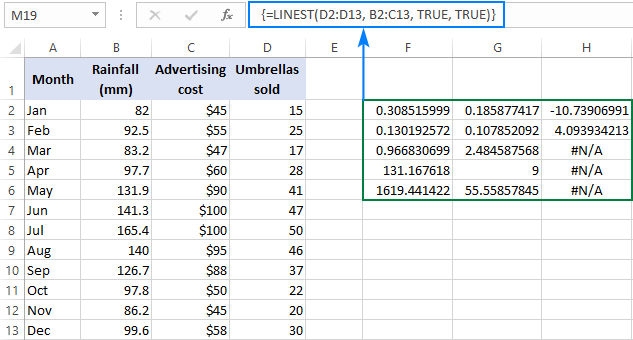
=LINEST(D2:D13, B2:C13, TRUE, TRUE)
Pošto imamo 2 nezavisnavarijable u kolonama B i C, odabiremo bijes koji se sastoji od 3 reda (dvije x vrijednosti + presretanje) i 5 kolona, unesemo gornju formulu, pritisnemo Ctrl + Shift + Enter i dobijemo ovaj rezultat:
Da biste se riješili #N/A grešaka, možete ugnijezditi LINEST u IFERROR na sljedeći način:
=IFERROR(LINEST(D2:D13, B2:C13, TRUE, TRUE), "")
Snimak ekrana ispod pokazuje rezultat i objašnjava šta svaki broj znači:

Koeficijenti nagiba i Y-presjek objašnjeni su u prethodnim primjerima, pa pogledajmo na brzinu ostale statistike.
Koeficijent determinacije (R2). Vrijednost R2 je rezultat dijeljenja regresijskog zbira kvadrata sa ukupnim zbrojem kvadrata. Govori vam koliko y vrijednosti je objašnjeno varijablama x . Može biti bilo koji broj od 0 do 1, odnosno od 0% do 100%. U ovom primjeru, R2 je otprilike 0,97, što znači da je 97% naših zavisnih varijabli (kišobran prodaje) objašnjeno nezavisnim varijablama (reklama + prosječna mjesečna količina padavina), što je odlično!
Standardne greške . Generalno, ove vrijednosti pokazuju preciznost regresione analize. Što su brojevi manji, to možete biti sigurniji u svoj regresijski model.
F statistika . Koristite F statistiku da podržite ili odbacite nultu hipotezu. Preporučljivo je koristiti F statistiku u kombinaciji sa P vrijednošću kada se odlučuje da li su ukupni rezultati
