
INHOUDSOPGAWE
Hierdie tutoriaal verduidelik die sintaksis van die LINEST-funksie en wys hoe om dit te gebruik om lineêre regressie-analise in Excel te doen.
Microsoft Excel is nie 'n statistiese program nie, maar dit doen het 'n aantal statistiese funksies. Een van sulke funksies is LINEST, wat ontwerp is om lineêre regressie-analise uit te voer en verwante statistieke terug te gee. In hierdie tutoriaal vir beginners, sal ons slegs liggies aan teorie en onderliggende berekeninge raak. Ons hooffokus sal daarop wees om vir jou 'n formule te voorsien wat eenvoudig werk en maklik vir jou data aangepas kan word.
Excel LINEST-funksie - sintaksis en basiese gebruike
Die LINEST-funksie bereken die statistieke vir 'n reguit lyn wat die verwantskap tussen die onafhanklike veranderlike en een of meer afhanklike veranderlikes verduidelik, en gee 'n skikking terug wat die lyn beskryf. Die funksie gebruik die kleinste vierkante metode om die beste passing vir jou data te vind. Die vergelyking vir die lyn is soos volg.
Eenvoudige lineêre regressievergelyking:
y = bx + aMeervoudige regressievergelyking:
y = b 1x 1+ b 2x 2+ … + b nx n+ aWaar:
- y - die afhanklike veranderlike wat jy probeer voorspel.
- x - die onafhanklike veranderlike wat jy gebruik om te voorspel y .
- a - die snypunt (dui aan waar die lyn die Y-as sny).
- b - die hellingbetekenisvol.
Grade van vryheid (df). Die LYNSTE funksie in Excel gee die residuele vryheidsgrade terug, wat die totale df minus die regressie df is. Jy kan die vryheidsgrade gebruik om F-kritiese waardes in 'n statistiese tabel te kry, en dan die F-kritiese waardes met die F-statistiek vergelyk om 'n vertrouensvlak vir jou model te bepaal.
Regressiesom van vierkante (ook bekend as die verduidelikte som van vierkante , of modelsom van vierkante ). Dit is die som van die kwadraatverskille tussen die voorspelde y-waardes en die gemiddelde van y, bereken met hierdie formule: =∑(ŷ - ȳ)2. Dit dui aan hoeveel van die variasie in die afhanklike veranderlike jou regressiemodel verduidelik.
Residuele som van vierkante . Dit is die som van die kwadraatverskille tussen die werklike y-waardes en die voorspelde y-waardes. Dit dui aan hoeveel van die variasie in die afhanklike veranderlike jou model nie verduidelik nie. Hoe kleiner die ressom van vierkante in vergelyking met die totale som van vierkante, hoe beter pas jou regressiemodel by jou data.
5 dinge wat jy moet weet oor LINEST-funksie
Om LINEST-formules doeltreffend te gebruik in jou werkblaaie, wil jy dalk 'n bietjie meer weet oor die "innerlike meganika" van die funksie:
- Bekende_y's en bekende_x's . In 'n eenvoudige lineêre regressiemodel met slegs een stel x veranderlikes, bekende_y's en bekende_x's kan reekse van enige vorm wees solank hulle dieselfde aantal rye en kolomme het. As jy meervoudige regressie-analise met meer as een stel onafhanklike x veranderlikes doen, moet bekende_y's 'n vektor wees, dit wil sê 'n reeks van een ry of een kolom.
- Forseer die konstante na nul . Wanneer die konst -argument WAAR is of weggelaat word, word die a -konstante (afsnit) bereken en ingesluit in die vergelyking: y=bx + a. As konst op ONWAAR gestel is, word die snysnit as gelyk aan 0 beskou en uit die regressievergelyking weggelaat: y=bx.
In statistieke word al dekades lank gedebatteer of dit sin maak om die afsnitkonstante na 0 te dwing of nie. Baie geloofwaardige regressie-analise-praktisyns glo dat as die stel van die snysnit op nul (const=ONWAAR) nuttig blyk te wees, lineêre regressie self 'n verkeerde model vir die datastel is. Ander veronderstel dat die konstante in sekere situasies tot nul gedwing kan word, byvoorbeeld in die konteks van regressiediskontinuïteitsontwerpe. Oor die algemeen word dit aanbeveel om te gaan met die verstek const=TRUE of in die meeste gevalle weggelaat.
- Akkuraatheid . Die akkuraatheid van die regressievergelyking wat deur die LINEST-funksie bereken word, hang af van die verspreiding van jou datapunte. Hoe meer lineêr die data is, hoe meer akkuraat is die resultate van die LYNSTE formule.
- Oorbodige x waardes . In sommige situasies,een of meer onafhanklike x veranderlikes het dalk geen bykomende voorspellende waarde nie, en die verwydering van sulke veranderlikes uit die regressiemodel beïnvloed nie die akkuraatheid van die voorspelde y-waardes nie. Hierdie verskynsel staan bekend as "kollineariteit". Die Excel LINEST-funksie kontroleer vir kolineariteit en laat enige oortollige x -veranderlikes wat dit uit die model identifiseer, weg. Die weggelaat x veranderlikes kan herken word deur 0 koëffisiënte en 0 standaardfoutwaardes.
- LYN vs. HELLING en ONDERSKEPPING . Die onderliggende algoritme van die LINEST-funksie verskil van die algoritme wat in die SLOPE- en INTERCEPT-funksies gebruik word. Daarom, wanneer die brondata onbepaald of kollineêr is, kan hierdie funksies verskillende resultate gee.
Excel LINEST-funksie werk nie
As jou LINEST-formule 'n fout gooi of 'n verkeerde uitvoer produseer , die kans is goed dat dit om een van die volgende redes is:
- As die LINEST-funksie net een getal (hellingkoëffisiënt) teruggee, het jy dit heel waarskynlik as 'n gewone formule ingevoer, nie 'n skikkingsformule nie. Maak seker dat u Ctrl + Shift + Enter druk om die formule korrek te voltooi. Wanneer jy dit doen, word die formule ingesluit in die {krulhakies} wat in die formulebalk sigbaar is.
- #VERW! fout. Kom voor as die bekende_x's en bekende_y's reekse verskillende dimensies het.
- #WAARDE! fout. Kom voor as bekende_x's of bekende_y's bevat ten minste een leë sel, tekswaarde of teksvoorstelling van 'n getal wat Excel nie as 'n numeriese waarde herken nie. Die #VALUE-fout kom ook voor as die konst - of statistieke -argument nie na WAAR of ONWAAR geëvalueer kan word nie.
Dit is hoe jy LINEST in Excel gebruik vir 'n eenvoudige en meervoudige lineêre regressie-analise. Om die formules wat in hierdie tutoriaal bespreek word van nader te bekyk, is u welkom om ons voorbeeldwerkboek hieronder af te laai. Ek bedank jou vir die lees en hoop om jou volgende week op ons blog te sien!
Oefen werkboek vir aflaai
Excel LINEST funksie voorbeelde (.xlsx lêer)
(dui die steilheid van die regressielyn aan, d.w.s. die tempo van verandering vir y as x verander).
In sy basiese vorm gee die LYNSTE-funksie die snypunt (a) en die helling (b) terug. vir die regressievergelyking. Opsioneel kan dit ook addisionele statistieke vir die regressie-analise terugstuur soos in hierdie voorbeeld getoon word.
LINEST funksie sintaksis
Die sintaksis van die Excel LINEST funksie is soos volg:
LINEST(bekend_y's) , [bekende_x's], [konst], [statistieke])Waar:
- bekende_y's (vereis) 'n reeks van die afhanklike y is -waardes in die regressievergelyking. Gewoonlik is dit 'n enkele kolom of 'n enkele ry.
- bekende_x's (opsioneel) is 'n reeks van die onafhanklike x-waardes. As dit weggelaat word, word aanvaar dat dit die skikking {1,2,3,...} van dieselfde grootte as bekende_y's is.
- konst (opsioneel) - 'n logiese waarde wat bepaal hoe die snypunt (konstante a ) hanteer moet word:
- Indien WAAR of weggelaat word, word die konstante a normaalweg bereken.
- Indien ONWAAR, word die konstante a na 0 gedwing en die helling ( b -koëffisiënt) word bereken om y=bx te pas.
- statistieke (opsioneel) is 'n logiese waarde wat bepaal of bykomende statistieke uitgevoer moet word of nie:
- Indien WAAR, gee die LYNSTE funksie 'n skikking met bykomende regressiestatistieke terug.
- Indien ONWAAR of weggelaat word, gee LYN slegs die snypuntkonstante en helling terugkoëffisiënt(e).
Let wel. Aangesien LINEST 'n reeks waardes terugstuur, moet dit as 'n skikkingsformule ingevoer word deur die Ctrl + Shift + Enter-kortpad te druk. As dit as 'n gewone formule ingevoer word, word slegs die eerste hellingkoëffisiënt teruggestuur.
Bykomende statistieke teruggestuur deur LINEST
Die stats -argument wat op TRUE gestel is, gee die LINEST-funksie opdrag om die volgende statistieke vir jou regressie-analise terug te gee:
| Statistiek | Beskrywing |
| Huinskoëffisiënt | b waarde in y = bx + a |
| Afsnitkonstante | a waarde in y = bx + a |
| Standaardfout van helling | Die standaardfoutwaarde(s) vir die b koëffisiënt(e). |
| Standaardfout van afsnit | Die standaardfoutwaarde vir die konstante a . |
| Bepalingskoëffisiënt (R2) | Dui aan hoe goed die regressievergelyking die verwantskap tussen die veranderlikes verduidelik. |
| Standaardfout vir die Y-skatting | Toon die akkuraatheid van die regressie-analise. |
| F-statistiek, of die F-waargenome waarde | Dit word gebruik om die F-toets vir die nulhipotese om die algehele goedheid van passing van die model te bepaal. |
| Grade van fr eedom (df) | Die aantal grade van vryheid. |
| Regressiesom van vierkante | Dui aan hoeveel van die variasie in dieafhanklike veranderlike word deur die model verduidelik. |
| Residuele som van vierkante | Meet die hoeveelheid variansie in die afhanklike veranderlike wat nie deur jou regressiemodel verduidelik word nie. |
Die kaart hieronder toon die volgorde waarin LINEST 'n verskeidenheid statistieke terugstuur:

In die laaste drie rye, die #Nvt foute sal in die derde en daaropvolgende kolomme verskyn wat nie met data gevul is nie. Dit is die verstekgedrag van die LINEST-funksie, maar as jy die foutnotasies wil wegsteek, draai jou LINEST-formule in IFERROR soos in hierdie voorbeeld getoon.
Hoe om LINEST in Excel te gebruik - formulevoorbeelde
Die LINEST-funksie kan moeilik wees om te gebruik, veral vir beginners, omdat jy nie net 'n formule korrek moet bou nie, maar ook die uitvoer daarvan behoorlik moet interpreteer. Hieronder vind u 'n paar voorbeelde van die gebruik van LYN-formules in Excel wat hopelik sal help om die teoretiese kennis in te sink :)
Eenvoudige lineêre regressie: bereken helling en snypunt
Om die snypunt te kry en die helling van 'n regressielyn, gebruik jy die LINEST-funksie in sy eenvoudigste vorm: verskaf 'n reeks van die afhanklike waardes vir die bekende_y se -argument en 'n reeks van die onafhanklike waardes vir die bekende_x's argument. Die laaste twee argumente kan op WAAR gestel word of weggelaat word.
Byvoorbeeld, met y -waardes (verkoopgetalle) in C2:C13- en x-waardes(advertensiekoste) in B2:B13, ons lineêre regressieformule is so eenvoudig soos:
=LINEST(C2:C13,B2:B13)
Om dit korrek in jou werkblad in te voer, kies twee aangrensende selle in dieselfde ry, E2: F2 in hierdie voorbeeld, tik die formule en druk Ctrl + Shift + Enter om dit te voltooi.
Die formule sal die hellingkoëffisiënt in die eerste sel (E2) en die snypuntkonstante in die tweede sel (F2) terugstuur ):
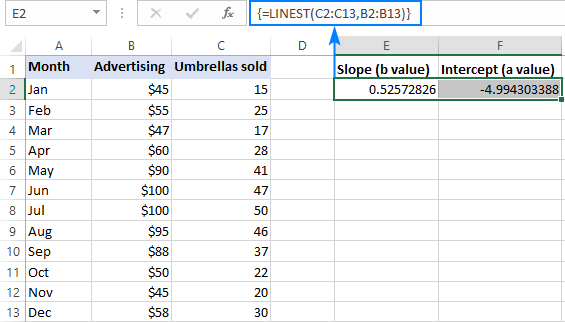
Die helling is ongeveer 0.52 (afgerond tot twee desimale plekke). Dit beteken dat wanneer x met 1 toeneem, y met 0,52 toeneem.
Die Y-afsnit is negatief -4,99. Dit is die verwagte waarde van y wanneer x=0. As dit op 'n grafiek geplot word, is dit die waarde waarteen die regressielyn die y-as kruis.
Gee bogenoemde waardes aan 'n eenvoudige lineêre regressievergelyking, en jy sal die volgende formule kry om die verkoopsgetal te voorspel gebaseer op die advertensiekoste:
y = 0.52*x - 4.99
As jy byvoorbeeld $50 aan advertensies spandeer, word daar van jou verwag om 21 sambrele te verkoop:
0.52*50 - 4.99 = 21.01
Die helling- en snypuntwaardes kan ook afsonderlik verkry word deur die ooreenstemmende funksie te gebruik of deur die LYNSTE formule in INDEX:
Slope
=SLOPE(C2:C13,B2:B13)
=INDEX(LINEST(C2:C13,B2:B13),1)
Onderskep
=INTERCEPT(C2:C13,B2:B13)
=INDEX(LINEST(C2:C13,B2:B13),2)
Soos in die skermkiekie hieronder getoon, lewer al drie formules dieselfde resultate:

Meervoudige lineêre regressie: helling en snypunt
In geval jy hettwee of meer onafhanklike veranderlikes, maak seker dat jy hulle in aangrensende kolomme invoer, en verskaf daardie hele reeks aan die bekende_x se -argument.
Byvoorbeeld, met verkoopsnommers ( y waardes) in D2:D13, advertensiekoste (een stel x waardes) in B2:B13 en gemiddelde maandelikse reënval (nog 'n stel x waardes) in C2:C13, gebruik jy hierdie formule:
=LINEST(D2:D13,B2:C13)
Aangesien formule 'n skikking van 3 waardes (2 hellingkoëffisiënte en die afsnitkonstante) gaan terugstuur), kies ons drie aangrensende selle in dieselfde ry, voer die formule in en druk die Ctrl + Shift + Enter-kortpad.
Neem asseblief kennis dat die meervoudige regressieformule die hellingkoëffisiënte in die omgekeerde volgorde van die onafhanklike veranderlikes (van regs na links), wat is b n , b n-1 , …, b 2 , b 1 :
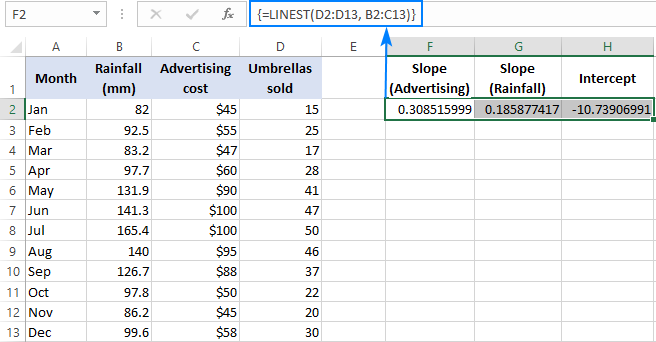
Om die verkoopsnommer te voorspel, verskaf ons die waardes wat deur die LYNSTE formule teruggestuur word na die meervoudige regressievergelyking:
y = 0.3*x 2 + 0.19*x 1 - 10,74
Bv ruim, met $50 bestee aan advertensies en 'n gemiddelde maandelikse reënval van 100 mm, word daar van jou verwag om ongeveer 23 sambrele te verkoop:
0.3*50 + 0.19*100 - 10.74 = 23.26
Eenvoudige lineêre regressie: voorspel afhanklike veranderlike
Behalwe om die a en b waardes vir die regressievergelyking te bereken, kan die Excel LINEST-funksie ook die afhanklike veranderlike (y) skat gebaseer op die bekende onafhanklikeveranderlike (x). Hiervoor gebruik jy LINEST in kombinasie met die SOM- of SUMPRODUCT-funksie.
Byvoorbeeld, hier is hoe jy die aantal sambreelverkope vir die volgende maand, byvoorbeeld Oktober, kan bereken op grond van verkope in die vorige maande en Oktober se advertensiebegroting van $50:
=SUM(LINEST(C2:C10, B2:B10)*{50,1})
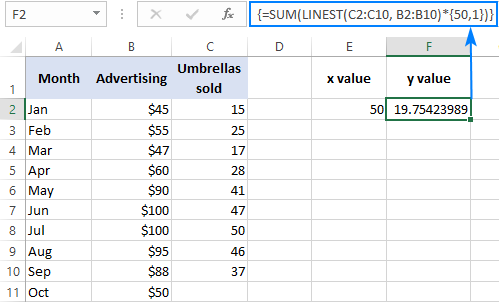
In plaas daarvan om die x -waarde in die formule te hardkodeer, kan jy dit as 'n selverwysing. In hierdie geval moet jy ook die 1-konstante in die een of ander sel invoer, want jy kan nie verwysings en waardes in 'n skikkingkonstante meng nie.
Met die x -waarde in E2 en die konstante 1 in F2, enige van die onderstaande formules sal 'n lekkerny werk:
Gereelde formule (ingevoer deur Enter te druk):
=SUMPRODUCT(LINEST(C2:C10, B2:B10)*(E2:F2))
Skikkingsformule (ingevoer deur Ctrl + Shift + te druk Tik ):
=SUM(LINEST(C2:C10, B2:B10)*(E2:F2))
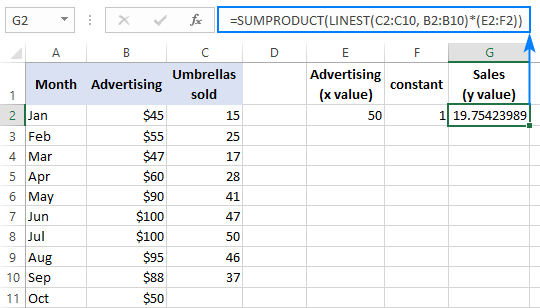
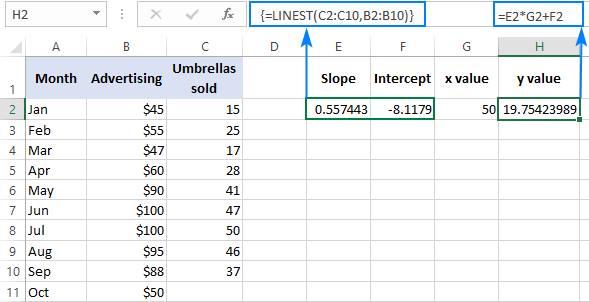
Om die resultaat te verifieer, kan jy die snypunt en helling vir dieselfde data kry, en dan die lineêre regressieformule gebruik om bereken y :
=E2*G2+F2
Waar E2 die helling is, G2 die x waarde is, en F2 die snysnit is:
Meervoudige regressie: voorspel afhanklike veranderlike
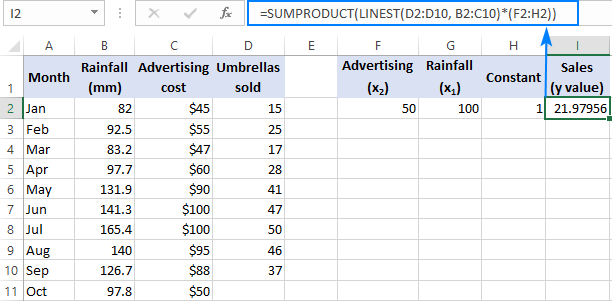
In die geval dat jy met verskeie voorspellers te doen het, dit wil sê 'n paar verskillende stelle x -waardes, sluit al die voorspellers in die skikking konstante. Byvoorbeeld, met die advertensiebegroting van $50 (x 2 ) en 'n gemiddelde maandelikse reënval van 100 mm (x 1 ), gaan die formule soos volgvolg:
=SUM(LINEST(D2:D10, B2:C10)*{50,100,1})
Waar D2:D10 die bekende y -waardes is en B2:C10 twee stelle x -waardes is:

Gee asseblief aandag aan die volgorde van die x -waardes in die skikkingkonstante. Soos vroeër uitgewys, wanneer die Excel LINEST-funksie gebruik word om meervoudige regressie te doen, gee dit die hellingkoëffisiënte van regs na links terug. In ons voorbeeld word die Reklame -koëffisiënt eerste teruggestuur, en dan die Reënval -koëffisiënt. Om die voorspelde verkoopsnommer korrek te bereken, moet jy die koëffisiënte vermenigvuldig met die ooreenstemmende x waardes, sodat jy die elemente van die skikkingskonstante in hierdie volgorde plaas: {50,100,1}. Die laaste element is 1, want die laaste waarde wat deur LYNST teruggestuur word, is die snysnit wat nie verander moet word nie, so jy vermenigvuldig dit eenvoudig met 1.
In plaas daarvan om 'n skikkingkonstante te gebruik, kan jy al die x veranderlikes invoer in sommige selle, en verwys na daardie selle in jou formule soos ons in die vorige voorbeeld gedoen het.
Gereelde formule:
=SUMPRODUCT(LINEST(D2:D10, B2:C10)*(F2:H2))
Skikkingsformule:
=SUM(LINEST(D2:D10, B2:C10)*(F2:H2))
Waar F2 en G2 die x -waardes is en H2 1 is:
LYNSTE formule: addisionele regressiestatistieke
Soos jy dalk onthou, om meer statistieke vir jou regressie-analise te kry, plaas jy WAAR in die laaste argument van die LYNSTE funksie. Toegepas op ons voorbeelddata, neem die formule die volgende vorm aan:
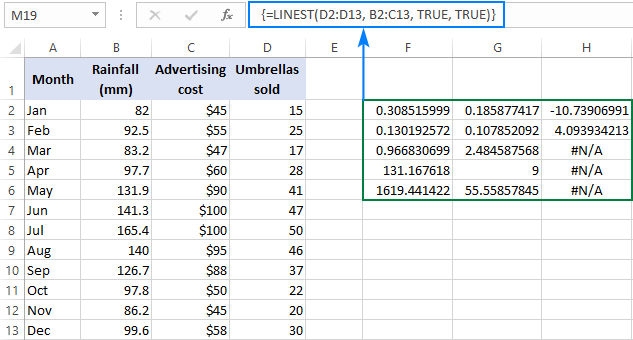
=LINEST(D2:D13, B2:C13, TRUE, TRUE)
Aangesien ons 2 onafhanklike hetveranderlikes in kolomme B en C, kies ons 'n woede wat bestaan uit 3 rye (twee x waardes + sny) en 5 kolomme, voer die formule hierbo in, druk Ctrl + Shift + Enter , en kry hierdie resultaat:
Om van die #N/A-foute ontslae te raak, kan jy LINEST in IFERROR soos volg nes:
=IFERROR(LINEST(D2:D13, B2:C13, TRUE, TRUE), "")
Die skermkiekie hieronder demonstreer die resultaat en verduidelik wat elke getal beteken:

Die hellingkoëffisiënte en die Y-afsnit is in die vorige voorbeelde verduidelik, so kom ons kyk vinnig na die ander statistieke.
Bepalingskoëffisiënt (R2). Die waarde van R2 is die resultaat van die deling van die regressiesom van vierkante deur die totale som van vierkante. Dit vertel jou hoeveel y waardes deur x veranderlikes verduidelik word. Dit kan enige getal van 0 tot 1 wees, dit is 0% tot 100%. In hierdie voorbeeld is R2 ongeveer 0.97, wat beteken dat 97% van ons afhanklike veranderlikes (sambreelverkope) verklaar word deur die onafhanklike veranderlikes (advertensies + gemiddelde maandelikse reënval), wat 'n uitstekende passing is!
Standaardfoute . Oor die algemeen toon hierdie waardes die akkuraatheid van die regressie-analise aan. Hoe kleiner die getalle, hoe sekerder kan jy wees oor jou regressiemodel.
F-statistiek . Jy gebruik die F-statistiek om die nulhipotese te ondersteun of te verwerp. Dit word aanbeveel om die F-statistiek in kombinasie met die P-waarde te gebruik wanneer jy besluit of die algehele resultate is
