
Змест
У гэтым навучальным дапаможніку тлумачыцца сінтаксіс функцыі ЛІНЕЙН і паказвае, як выкарыстоўваць яе для аналізу лінейнай рэгрэсіі ў Excel.
Але Microsoft Excel не з'яўляецца статыстычнай праграмай. маюць шэраг статыстычных функцый. Адной з такіх функцый з'яўляецца LINEST, якая прызначана для выканання лінейнага рэгрэсійнага аналізу і вяртання адпаведнай статыстыкі. У гэтым уроку для пачаткоўцаў мы толькі крыху закранем тэорыю і асноўныя разлікі. Наша асноўная ўвага будзе засяроджана на прадастаўленні вам формулы, якая проста працуе і можа быць лёгка настроена для вашых даных.
Функцыя LINEST Excel - сінтаксіс і асноўныя спосабы выкарыстання
Функцыя ЛІНІЯ вылічвае статыстыку для прамой лініі, якая тлумачыць сувязь паміж незалежнай зменнай і адной ці некалькімі залежнымі зменнымі, і вяртае масіў, які апісвае лінію. Функцыя выкарыстоўвае метад найменшых квадратаў , каб знайсці найлепшы варыянт для вашых даных. Ураўненне для лініі выглядае наступным чынам.
Ураўненне простай лінейнай рэгрэсіі:
y = bx + aУраўненне множнай рэгрэсіі:
y = b 1x 1+ b 2x 2+ … + b nx n+ aДзе:
- y - залежная зменная, якую вы спрабуеце прадказаць.
- x - незалежная зменная, якую вы выкарыстоўваеце для прагназавання y .
- a - кропка перасячэння (паказвае, дзе лінія перасякае вось Y).
- b - кут нахілузначны.
Ступені свабоды (df). Функцыя LINEST у Excel вяртае астаткавыя ступені свабоды , якія з'яўляюцца агульнай df мінус рэгрэсія df . Вы можаце выкарыстоўваць ступені свабоды, каб атрымаць F-крытычныя значэнні ў статыстычнай табліцы, а затым параўнаць F-крытычныя значэнні са статыстыкай F, каб вызначыць узровень даверу для вашай мадэлі.
Сума рэгрэсіі квадратаў (ён жа вытлумачаная сума квадратаў або мадэльная сума квадратаў ). Гэта сума квадратаў рознасці паміж прагназаванымі значэннямі y і сярэднім значэннем y, вылічаная па гэтай формуле: =∑(ŷ - ȳ)2. Ён паказвае, якую частку змены ў залежнай зменнай тлумачыць ваша рэгрэсійная мадэль.
Астаткавая сума квадратаў . Гэта сума квадратаў розніцы паміж фактычнымі значэннямі y і прагназаванымі значэннямі y. Ён паказвае, колькі варыяцый у залежнай зменнай ваша мадэль не тлумачыць. Чым менш рэшткавая сума квадратаў у параўнанні з агульнай сумай квадратаў, тым лепш ваша мадэль рэгрэсіі адпавядае вашым дадзеным.
5 рэчаў, якія вы павінны ведаць пра функцыю ЛІНЕЙН
Каб эфектыўна выкарыстоўваць формулы ЛІНЕЙН у Вашы працоўныя аркушы, вы можаце даведацца крыху больш пра "ўнутраную механіку" функцыі:
- Known_y's і known_x's . У простай мадэлі лінейнай рэгрэсіі толькі з адным наборам зменных x, вядомыя_y і вядомыя_х могуць быць дыяпазонамі любой формы, калі яны маюць аднолькавую колькасць радкоў і слупкоў. Калі вы выконваеце множны рэгрэсійны аналіз з больш чым адным наборам незалежных зменных x , вядомыя_y павінны быць вектарам, г.зн. дыяпазонам з аднаго радка або аднаго слупка.
- Прымушэнне канстанты да нуля . Калі аргумент const TRUE або апушчаны, канстанта a (перахоп) вылічваецца і ўключаецца ў раўнанне: y=bx + a. Калі const усталявана ў FALSE, адрэзак лічыцца роўным 0 і апускаецца з ураўнення рэгрэсіі: y=bx.
У статыстыцы дзесяцігоддзямі вядуцца спрэчкі аб тым, ці мае сэнс ставіць канстанту перахопу ў 0 ці не. Многія аўтарытэтныя практыкі рэгрэсійнага аналізу лічаць, што калі ўстаноўка перахопу на нуль (const=FALSE) здаецца карыснай, то лінейная рэгрэсія сама па сабе з'яўляецца няправільнай мадэллю для набору даных. Іншыя мяркуюць, што канстанта можа быць прымусова абнуленая ў пэўных сітуацыях, напрыклад, у кантэксце дызайну разрыву рэгрэсіі. Увогуле, у большасці выпадкаў рэкамендуецца выкарыстоўваць значэнне па змаўчанні const=TRUE або апускаць яго.
- Дакладнасць . Дакладнасць ураўнення рэгрэсіі, разлічанага з дапамогай функцыі LINEST, залежыць ад дысперсіі вашых кропак даных. Чым больш лінейныя даныя, тым больш дакладныя вынікі формулы LINEST.
- Залішнія значэнні x . У некаторых сітуацыях,адна або некалькі незалежных зменных x могуць не мець дадатковага прагназуючага значэння, і выдаленне такіх зменных з рэгрэсійнай мадэлі не ўплывае на дакладнасць прадказаных значэнняў y. Гэта з'ява вядома як "калінеарнасць". Функцыя Excel LINEST правярае калінеарнасць і прапускае любыя лішнія зменныя x , якія яна ідэнтыфікуе з мадэлі. Прапушчаныя зменныя x можна распазнаць па 0 каэфіцыентах і 0 стандартных значэннях памылак.
- LINEST супраць SLOPE і INTERCEPT . Базавы алгарытм функцыі LINEST адрозніваецца ад алгарытму, які выкарыстоўваецца ў функцыях SLOPE і INTERCEPT. Такім чынам, калі зыходныя даныя нявызначаныя або калінеарныя, гэтыя функцыі могуць вяртаць розныя вынікі.
Функцыя Excel LINEST не працуе
Калі ваша формула LINEST выдае памылку або дае няправільны вывад , хутчэй за ўсё, гэта з-за адной з наступных прычын:
- Калі функцыя ЛІНІЙ вяртае толькі адзін лік (каэфіцыент нахілу), хутчэй за ўсё, вы ўвялі яго як звычайную формулу, а не як формулу масіву. Абавязкова націсніце Ctrl + Shift + Enter, каб правільна завяршыць формулу. Калі вы гэта зробіце, формула будзе заключана ў {фігурныя дужкі}, якія бачныя ў радку формул.
- #REF! памылка. Адбываецца, калі дыяпазоны вядомыя_x і вядомыя_y маюць розныя памеры.
- #ЗНАЧЭННЕ! памылка. Адбываецца, калі вядомыя_х або вядомыя_y змяшчае як мінімум адну пустую ячэйку, тэкставае значэнне або тэкставае прадстаўленне ліку, якое Excel не распазнае як лікавае значэнне. Акрамя таго, памылка #VALUE узнікае, калі аргумент const або stats не можа быць ацэнены як TRUE або FALSE.
Вось як вы выкарыстоўваеце LINEST у Excel для просты і множны лінейны рэгрэсійны аналіз. Каб больш падрабязна азнаёміцца з формуламі, якія абмяркоўваюцца ў гэтым уроку, вы можаце загрузіць наш узор кнігі ніжэй. Я дзякую вам за чытанне і спадзяюся ўбачыць вас у нашым блогу на наступным тыдні!
Практычны сшытак для спампоўкі
Прыклады функцый Excel LINEST (файл .xlsx)
(паказвае крутасць лініі рэгрэсіі, г.зн. хуткасць змены для y пры змене x).
У сваёй асноўнай форме функцыя ЛІНІЙ вяртае адрэзак (a) і нахіл (b) для ўраўнення рэгрэсіі. Пры жаданні ён таксама можа вяртаць дадатковую статыстыку для рэгрэсійнага аналізу, як паказана ў гэтым прыкладзе.
Сінтаксіс функцыі ЛІНЕЙН
Сінтаксіс функцыі ЛІНЕЙН у Excel наступны:
ЛІНЕЙН(вядомыя_y's , [вядомыя_x], [const], [статыстыка])Дзе:
- вядомыя_y (абавязкова) - дыяпазон залежнага y -значэнні ў раўнанні рэгрэсіі. Звычайна гэта адзін слупок або адзін радок.
- вядомыя_х (неабавязкова) - гэта дыяпазон незалежных значэнняў х. Калі апусціць, мяркуецца, што гэта масіў {1,2,3,...} таго ж памеру, што і вядомыя_y .
- const (неабавязкова) - лагічнае значэнне, якое вызначае, як трэба разглядаць перахоп (канстанта a ):
- Калі TRUE або апушчана, канстанта a вылічваецца нармальна.
- Калі FALSE, канстанта a задаецца роўнай 0, а нахіл (каэфіцыент b ) разлічваецца, каб адпавядаць y=bx.
- статыстыка (неабавязкова) - гэта лагічнае значэнне, якое вызначае, выводзіць дадатковую статыстыку ці не:
- Калі TRUE, функцыя LINEST вяртае масіў з дадатковай статыстыкай рэгрэсіі.
- Калі FALSE або апушчана, LINEST вяртае толькі канстанту перасячэння і нахілкаэфіцыент(ы).
Заўвага. Паколькі LINEST вяртае масіў значэнняў, яго трэба ўвесці як формулу масіва, націснуўшы спалучэнне клавіш Ctrl + Shift + Enter. Калі ён уводзіцца як звычайная формула, вяртаецца толькі першы каэфіцыент нахілу.
Дадатковая статыстыка, якую вяртае LINEST
Аргумент stats , усталяваны ў TRUE, загадвае функцыі LINEST вярнуць наступную статыстыку для вашага рэгрэсійнага аналізу:
| Статыстыка | Апісанне |
| Каэфіцыент нахілу | b значэнне ў y = bx + a |
| Канстанта перахопу | значэнне ў y = bx + a |
| Стандартная памылка нахілу | Значэнне(я) стандартнай памылкі для каэфіцыент(ы) b. |
| Стандартная памылка перахопу | Значэнне стандартнай памылкі для канстанты a . |
| Каэфіцыент дэтэрмінацыі (R2) | Паказвае, наколькі добра ўраўненне рэгрэсіі тлумачыць сувязь паміж зменнымі. |
| Стандартная памылка для ацэнкі Y | Паказвае дакладнасць рэгрэсійнага аналізу. |
| F-статыстыка, або F-назіранае значэнне | Яно выкарыстоўваецца для выканання F-тэсту для нулявая гіпотэза для вызначэння агульнай адпаведнасці мадэлі. |
| Ступені fr eedom (df) | Колькасць ступеняў свабоды. |
| Сума квадратаў рэгрэсіі | Паказвае, колькі варыяцый узалежная зменная тлумачыцца мадэллю. |
| Астаткавая сума квадратаў | Вымярае велічыню дысперсіі залежнай зменнай, якая не тлумачыцца вашай мадэллю рэгрэсіі. |
Карта ніжэй паказвае парадак, у якім LINEST вяртае масіў статыстыкі:

У апошніх трох радках, Памылкі #N/A з'явяцца ў трэцім і наступных слупках, якія не запоўнены дадзенымі. Гэта паводзіны функцыі ЛІНЕЙН па змаўчанні, але калі вы жадаеце схаваць абазначэнні памылак, абгарніце сваю формулу ЛІНЕЙН у IFERROR, як паказана ў гэтым прыкладзе.
Як выкарыстоўваць ЛІНЕЙН у Excel - прыклады формул
Выкарыстоўваць функцыю LINEST можа быць складана, асабліва для пачаткоўцаў, таму што вы павінны не толькі правільна пабудаваць формулу, але і правільна інтэрпрэтаваць яе вывад. Ніжэй вы знойдзеце некалькі прыкладаў выкарыстання формул LINEST у Excel, якія, мы спадзяемся, дапамогуць паглыбіць тэарэтычныя веды :)
Простая лінейная рэгрэсія: вылічыць нахіл і адрэзак
Каб атрымаць адрэзак і нахіл лініі рэгрэсіі, вы выкарыстоўваеце функцыю ЛІНІЙ у найпростай форме: увядзіце дыяпазон залежных значэнняў для аргумента вядомыя_y і дыяпазон незалежных значэнняў для вядомыя_х аргумент. Апошнія два аргументы могуць быць усталяваны ў TRUE або апушчаны.
Напрыклад, са значэннямі y (колькасці продажаў) у C2:C13 і значэннямі x(кошт рэкламы) у B2:B13 наша формула лінейнай рэгрэсіі такая ж простая, як:
=LINEST(C2:C13,B2:B13)
Каб правільна ўвесці яе ў працоўны аркуш, вылучыце дзве суседнія ячэйкі ў адным радку E2: F2 у гэтым прыкладзе, увядзіце формулу і націсніце Ctrl + Shift + Enter, каб завяршыць яе.
Формула верне каэфіцыент нахілу ў першай ячэйцы (E2) і канстанту перахопу ў другой ячэйцы (F2). ):
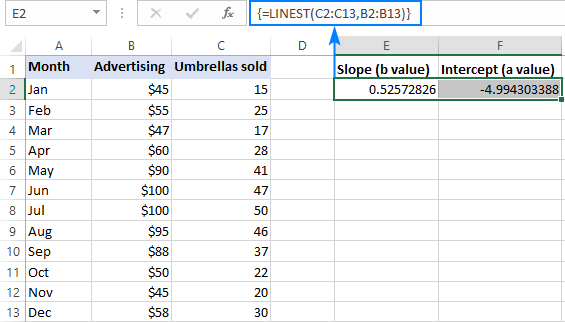
Нахіл складае прыблізна 0,52 (акруглена да двух знакаў пасля коскі). Гэта азначае, што калі x павялічваецца на 1, y павялічваецца на 0,52.
Перасячэнне Y адмоўнае -4,99. Гэта чаканае значэнне y , калі x=0. Калі нанесці на графік, гэта значэнне, пры якім лінія рэгрэсіі перасякае вось у.
Унясіце вышэйзгаданыя значэнні ў простае ўраўненне лінейнай рэгрэсіі, і вы атрымаеце наступную формулу для прагназавання колькасці продажаў на аснове кошту рэкламы:
y = 0.52*x - 4.99
Напрыклад, калі вы выдаткуеце 50 долараў на рэкламу, чакаецца, што вы прадасце 21 парасон:
0.52*50 - 4.99 = 21.01
Значэнні нахілу і перасячэння можна таксама атрымаць асобна з дапамогай адпаведнай функцыі або шляхам укладання формулы LINEST у INDEX:
Slope
=SLOPE(C2:C13,B2:B13)
=INDEX(LINEST(C2:C13,B2:B13),1)
Перахоп
=INTERCEPT(C2:C13,B2:B13)
=INDEX(LINEST(C2:C13,B2:B13),2)
Як паказана на скрыншоце ніжэй, усе тры формулы даюць аднолькавыя вынікі:

Множная лінейная рэгрэсія: нахіл і перасячэнне
У выпадку, калі ў вас ёсцьдзвюх або больш незалежных зменных, не забудзьцеся ўвесці іх у суседнія слупкі і перадаць увесь гэты дыяпазон аргументу вядомы_x .
Напрыклад, з лічбамі продажаў ( y значэнні) у D2:D13, кошт рэкламы (адзін набор значэнняў x) у B2:B13 і сярэднямесячная колькасць ападкаў (іншы набор значэнняў x ) у C2:C13, вы выкарыстоўваеце наступную формулу:
=LINEST(D2:D13,B2:C13)
Паколькі формула будзе вяртаць масіў з 3 значэнняў (2 каэфіцыентаў нахілу і канстанта перасячэння), мы выбіраем тры сумежныя ячэйкі ў адным радку, уводзім формулу і націскаем Ctrl + Спалучэнне клавіш Shift + Enter.
Звярніце ўвагу, што формула множнай рэгрэсіі вяртае каэфіцыенты нахілу ў адваротным парадку незалежных зменных (справа налева), што гэта b n , b n-1 , …, b 2 , b 1 :
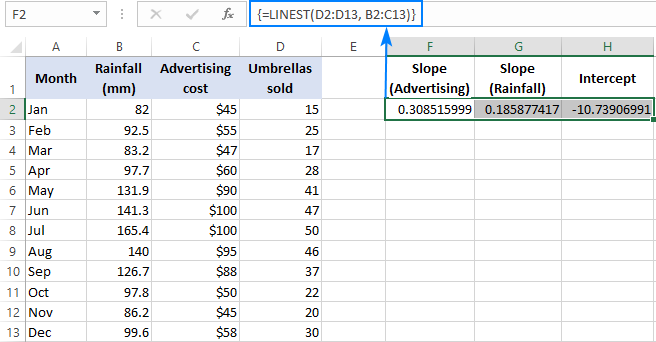
Каб прагназаваць колькасць продажаў, мы даем значэнні, якія вяртае формула ЛІНІЙНЫ, ва ўраўненне множнай рэгрэсіі:
y = 0,3*x 2 + 0,19*x 1 - 10,74
Напр дастаткова, з $50, выдаткаванымі на рэкламу і сярэднямесячнай колькасцю ападкаў 100 мм, чакаецца, што вы прадасце прыкладна 23 парасоны:
0.3*50 + 0.19*100 - 10.74 = 23.26
Простая лінейная рэгрэсія: прадказаць залежную зменную
Акрамя вылічэння значэнняў a і b для ўраўнення рэгрэсіі, функцыя ЛІНІЙНЫ ў Excel можа таксама ацаніць залежную зменную (y) на аснове вядомай незалежнайзменная (x). Для гэтага вы выкарыстоўваеце LINEST у спалучэнні з функцыяй SUM або SUMPRODUCT.
Напрыклад, вось як можна вылічыць колькасць продажаў парасонаў за наступны месяц, скажам, у кастрычніку, на аснове продажаў за папярэднія месяцы і Кастрычніцкі рэкламны бюджэт у 50 долараў:
=SUM(LINEST(C2:C10, B2:B10)*{50,1})
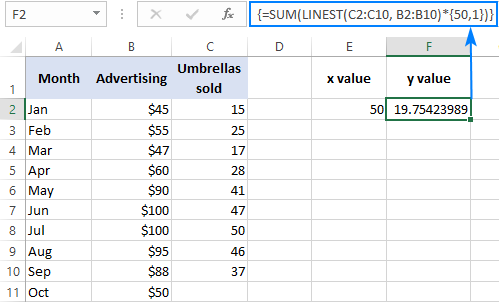
Замест жорсткага кадзіравання значэння x у формуле, вы можаце падаць яго як спасылка на клетку. У гэтым выпадку вам таксама трэба ўвесці канстанту 1 у нейкую ячэйку, таму што вы не можаце змешваць спасылкі і значэнні ў канстанце масіва.
Са значэннем x у E2 і канстантай 1 у F2, любая з прыведзеных ніжэй формул будзе добра працаваць:
Звычайная формула (уводзіцца націскам Enter ):
=SUMPRODUCT(LINEST(C2:C10, B2:B10)*(E2:F2))
Формула масіву (уводзіцца націскам Ctrl + Shift + Калі ласка, увядзіце ):
=SUM(LINEST(C2:C10, B2:B10)*(E2:F2))
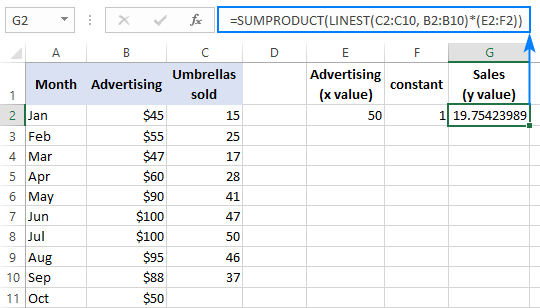
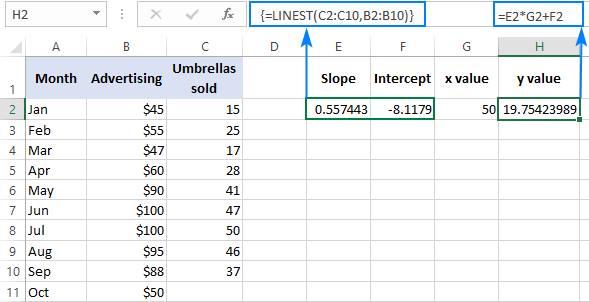
Каб праверыць вынік, вы можаце атрымаць адрэзак і нахіл для тых жа даных, а затым выкарыстоўваць формулу лінейнай рэгрэсіі, каб вылічыць y :
=E2*G2+F2
Дзе E2 - нахіл, G2 - значэнне x , а F2 - гэта адрэзак:
Множная рэгрэсія: прадказаць залежную зменную
Калі вы маеце справу з некалькімі прадказальнікамі, г. зн. некалькімі рознымі наборамі значэнняў x , уключыце ўсе гэтыя прадказальнікі ў канстанце масіва. Напрыклад, пры рэкламным бюджэце ў 50 долараў (x 2 ) і сярэднямесячнай колькасці ападкаў 100 мм (x 1 ) формула выглядае так:наступным чынам:
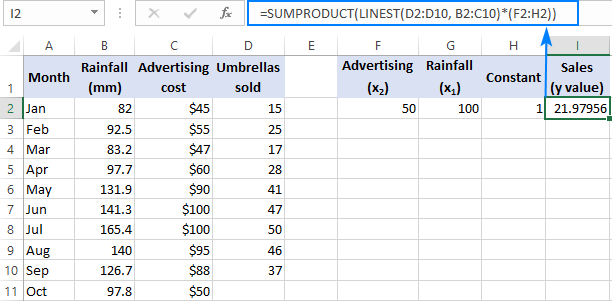
=SUM(LINEST(D2:D10, B2:C10)*{50,100,1})
Дзе D2:D10 вядомыя значэнні y і B2:C10 два наборы значэнняў x :

Калі ласка, звярніце ўвагу на парадак значэнняў x у канстанце масіва. Як адзначалася раней, калі функцыя LINEST Excel выкарыстоўваецца для множнай рэгрэсіі, яна вяртае каэфіцыенты нахілу справа налева. У нашым прыкладзе спачатку вяртаецца каэфіцыент Рэклама , а затым каэфіцыент Ападкаў . Каб правільна вылічыць прагназаваную лічбу продажаў, вам трэба памножыць каэфіцыенты на адпаведныя значэнні x , таму вы размяшчаеце элементы канстанты масіва ў наступным парадку: {50,100,1}. Апошні элемент роўны 1, таму што апошняе значэнне, якое вяртаецца ЛІНІЙНЫМ, з'яўляецца перахопам, які не павінен быць зменены, таму вы проста памнажаеце яго на 1.
Замест выкарыстання канстанты масіва вы можаце ўвесці ўсе зменныя x у некаторых ячэйках і спасылайцеся на гэтыя ячэйкі ў сваёй формуле, як мы рабілі ў папярэднім прыкладзе.
Звычайная формула:
=SUMPRODUCT(LINEST(D2:D10, B2:C10)*(F2:H2))
Формула масіву:
=SUM(LINEST(D2:D10, B2:C10)*(F2:H2))
Дзе F2 і G2 — значэнні x , а H2 — 1:
Формула LINEST: дадатковая статыстыка рэгрэсіі
Як вы, магчыма, памятаеце, каб атрымаць больш статыстычных дадзеных для вашага рэгрэсійнага аналізу, вы ставіце TRUE у апошні аргумент функцыі LINEST. У дачыненні да нашых выбарачных дадзеных формула прымае наступную форму:
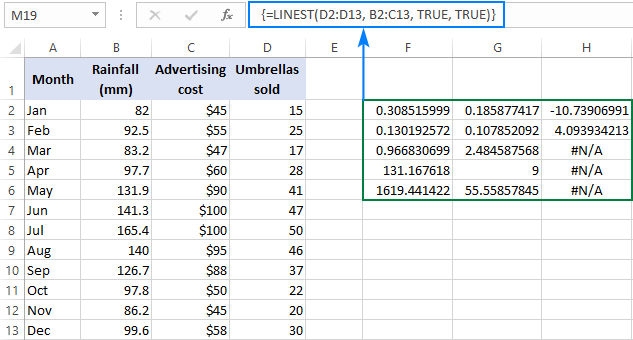
=LINEST(D2:D13, B2:C13, TRUE, TRUE)
Паколькі ў нас ёсць 2 незалежныязменныя ў слупках B і C, мы выбіраем лютасць, якая складаецца з 3 радкоў (два значэнні x + перахоп) і 5 слупкоў, уводзім прыведзеную вышэй формулу, націскаем Ctrl + Shift + Enter і атрымліваем наступны вынік:
Каб пазбавіцца ад памылак #N/A, вы можаце ўкласці LINEST у IFERROR так:
=IFERROR(LINEST(D2:D13, B2:C13, TRUE, TRUE), "")
Скрыншот ніжэй дэманструе вынік і тлумачыць, што кожны лік азначае:

Каэфіцыенты нахілу і Y-перасячэнне былі растлумачаны ў папярэдніх прыкладах, таму давайце хутка паглядзім на іншыя статыстычныя дадзеныя.
Каэфіцыент дэтэрмінацыі (R2). Значэнне R2 з'яўляецца вынікам дзялення сумы квадратаў рэгрэсіі на агульную суму квадратаў. Ён паказвае, колькі значэнняў y тлумачацца зменнымі x . Гэта можа быць любое лік ад 0 да 1, гэта значыць ад 0% да 100%. У гэтым прыкладзе R2 складае прыблізна 0,97, што азначае, што 97% нашых залежных зменных (парасонавыя продажы) тлумачацца незалежнымі зменнымі (рэклама + сярэднямесячная колькасць ападкаў), што выдатна адпавядае!
Стандартныя памылкі . Як правіла, гэтыя значэнні паказваюць дакладнасць рэгрэсійнага аналізу. Чым меншыя лічбы, тым больш упэўнены вы ў сваёй мадэлі рэгрэсіі.
F статыстыка . Вы выкарыстоўваеце статыстыку F, каб падтрымаць або адхіліць нулявую гіпотэзу. Рэкамендуецца выкарыстоўваць статыстыку F у спалучэнні са значэннем P пры вызначэнні агульных вынікаў
