
Obsah
Tento výukový kurz vysvětluje syntaxi funkce LINEST a ukazuje, jak ji použít k provedení lineární regresní analýzy v aplikaci Excel.
Microsoft Excel není statistický program, nicméně disponuje řadou statistických funkcí. Jednou z takových funkcí je LINEST, která je určena k provádění lineární regresní analýzy a vracení souvisejících statistik. V tomto návodu pro začátečníky se teorie a základních výpočtů dotkneme jen lehce. Zaměříme se především na to, abychom vám poskytli vzorec, který jednoduše funguje alze snadno přizpůsobit vašim datům.
Funkce LINEST aplikace Excel - syntaxe a základní použití
Funkce LINEST vypočítá statistiku přímky, která vysvětluje vztah mezi nezávislou proměnnou a jednou nebo více závislými proměnnými, a vrátí pole popisující tuto přímku. nejmenší čtverce metoda pro nalezení nejlepší shody pro vaše data. Rovnice pro přímku je následující.
Jednoduchá rovnice lineární regrese:
y = bx + aRovnice vícenásobné regrese:
y = b 1 x 1 + b 2 x 2 + ... + b n x n + aKde:
- y - závislou proměnnou, kterou se snažíte předpovědět.
- x - nezávislou proměnnou, kterou používáte k předpovědi y .
- a - průsečík (označuje místo, kde přímka protíná osu Y).
- b - sklon (udává strmost regresní přímky, tj. rychlost změny y při změně x).
V základní podobě vrací funkce LINEST pro regresní rovnici intercept (a) a sklon (b). Volitelně může vrátit i další statistiky regresní analýzy, jak je uvedeno v tomto příkladu.
Syntaxe funkce LINEST
Syntaxe funkce LINEST aplikace Excel je následující:
LINEST(known_y's, [known_x's], [const], [stats])Kde:
- known_y's (povinný) je rozsah závislé hodnoty y -hodnoty v regresní rovnici. Obvykle se jedná o jeden sloupec nebo jeden řádek.
- known_x's (nepovinné) je rozsah nezávislých hodnot x. Pokud je vynechán, předpokládá se, že je to pole {1,2,3,...} stejné velikosti jako pole {1,2,3,...}. known_y's .
- const (nepovinné) - logická hodnota, která určuje, jak bude intercept (konstanta) zobrazen. a ) by měly být ošetřeny:
- Pokud je TRUE nebo je vynechána, konstanta a se počítá normálně.
- Pokud je FALSE, konstanta a je nuceně rovna 0 a sklon ( b koeficient) se vypočítá tak, aby odpovídal hodnotě y=bx.
- statistiky (nepovinné) je logická hodnota, která určuje, zda se mají vypisovat další statistiky, nebo ne:
- Je-li TRUE, funkce LINEST vrátí pole s dalšími regresními statistikami.
- Pokud je hodnota FALSE nebo je vynechána, LINEST vrátí pouze konstantu interceptu a koeficient(y) sklonu.
Poznámka: Protože LINEST vrací pole hodnot, musí být zadán jako vzorec pole stisknutím klávesové zkratky Ctrl + Shift + Enter. Pokud je zadán jako běžný vzorec, je vrácen pouze první koeficient sklonu.
Další statistické údaje vrácené společností LINEST
Na stránkách statistiky argument nastavený na hodnotu TRUE dává funkci LINEST pokyn, aby vrátila následující statistiky pro regresní analýzu:
| Statistika | Popis |
| Koeficient sklonu | b hodnota v y = bx + a |
| Intercepční konstanta | hodnota v y = bx + a |
| Standardní chyba sklonu | Hodnota(y) standardní chyby pro koeficient(y) b. |
| Standardní chyba interceptu | Hodnota standardní chyby pro konstantu a . |
| Koeficient determinace (R2) | Ukazuje, jak dobře regresní rovnice vysvětluje vztah mezi proměnnými. |
| Standardní chyba pro odhad Y | Ukazuje přesnost regresní analýzy. |
| statistika F nebo pozorovaná hodnota F | Používá se k provedení F-testu pro nulovou hypotézu, aby se určila celková shoda modelu. |
| Stupně volnosti (df) | Počet stupňů volnosti. |
| Regresní součet čtverců | Ukazuje, jak velkou část variability závislé proměnné vysvětluje model. |
| Zbytkový součet čtverců | Měří množství rozptylu závislé proměnné, které není vysvětleno vaším regresním modelem. |
Níže uvedená mapa ukazuje pořadí, v jakém LINEST vrací pole statistik:

V posledních třech řádcích se ve třetím a následujících sloupcích, které nejsou vyplněny daty, objeví chyby #N/A. Jedná se o výchozí chování funkce LINEST, ale pokud chcete chybové poznámky skrýt, obalte vzorec LINEST do IFERROR, jak je uvedeno v tomto příkladu.
Jak používat LINEST v aplikaci Excel - příklady vzorců
Používání funkce LINEST může být zejména pro začátečníky složité, protože je třeba vzorec nejen správně sestavit, ale také správně interpretovat jeho výstup. Níže najdete několik příkladů použití vzorců LINEST v Excelu, které snad pomohou utápět teoretické znalosti :)
Jednoduchá lineární regrese: výpočet sklonu a průsečíku
Chcete-li získat průsečík a sklon regresní přímky, použijte funkci LINEST v její nejjednodušší podobě: zadejte rozsah závislých hodnot pro funkci LINEST. known_y's a rozsah nezávislých hodnot pro parametr known_x's Poslední dva argumenty mohou být nastaveny na TRUE nebo vynechány.
Například s y hodnoty (prodejní čísla) v C2:C13 a hodnoty x (náklady na reklamu) v B2:B13, je náš lineární regresní vzorec jednoduchý:
=LINEST(C2:C13,B2:B13)
Chcete-li jej správně zadat do pracovního listu, vyberte dvě sousední buňky ve stejném řádku, v tomto příkladu E2:F2, zadejte vzorec a dokončete jej stisknutím kláves Ctrl + Shift + Enter.
Vzorec vrátí koeficient sklonu v první buňce (E2) a konstantu interceptu v druhé buňce (F2):
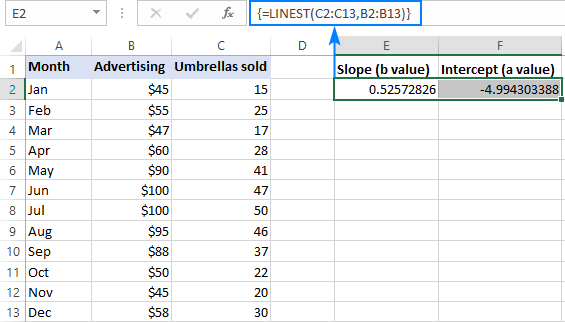
Na stránkách svah je přibližně 0,52 (zaokrouhleno na dvě desetinná místa). To znamená, že když se x se zvýší o 1, y se zvyšuje o 0,52.
Na stránkách Y-intercept je záporná -4,99. Jedná se o očekávanou hodnotu y při x=0. Pokud je vynesena do grafu, je to hodnota, při které regresní přímka protíná osu y.
Dosadíme-li výše uvedené hodnoty do jednoduché rovnice lineární regrese, získáme následující vzorec pro předpověď počtu prodejů na základě nákladů na reklamu:
y = 0,52*x - 4,99
Pokud například utratíte 50 dolarů za reklamu, očekává se, že prodáte 21 deštníků:
0.52*50 - 4.99 = 21.01
Hodnoty sklonu a průsečíku lze také získat samostatně pomocí příslušné funkce nebo vnořením vzorce LINEST do INDEXu:
Svah
=SLOPE(C2:C13,B2:B13)
=INDEX(LINEST(C2:C13,B2:B13),1)
Intercept
=INTERCEPT(C2:C13,B2:B13)
=INDEX(LINEST(C2:C13,B2:B13),2)
Jak ukazuje obrázek níže, všechny tři vzorce poskytují stejné výsledky:

Vícenásobná lineární regrese: sklon a průsečík
V případě, že máte dvě nebo více nezávislých proměnných, nezapomeňte je zadat do sousedních sloupců a celý tento rozsah zadejte do příkazu known_x's argument.
Například u prodejních čísel ( y v D2:D13, náklady na reklamu (jedna sada hodnot x) v B2:B13 a průměrné měsíční srážky (další sada hodnot x) v B2:B13. x hodnoty) v C2:C13, použijete tento vzorec:
=LINEST(D2:D13,B2:C13)
Protože vzorec bude vracet pole 3 hodnot (2 koeficienty sklonu a konstantu interceptu), vybereme tři sousední buňky ve stejném řádku, zadáme vzorec a stiskneme klávesovou zkratku Ctrl + Shift + Enter.
Vezměte prosím na vědomí, že vzorec pro vícenásobnou regresi vrací hodnotu koeficienty sklonu v obrácené pořadí nezávislých proměnných (zprava doleva), tj. b n , b n-1 , ..., b 2 , b 1 :
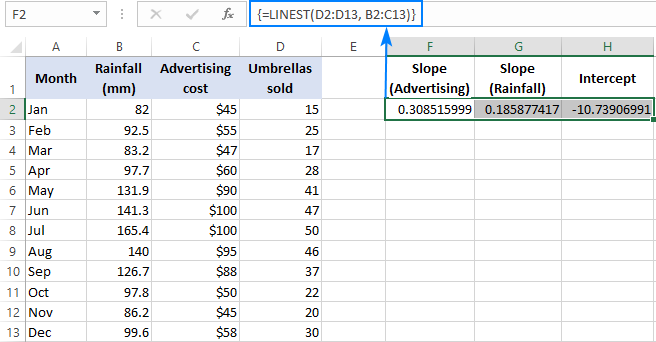
Abychom mohli předpovědět počet prodaných kusů, dosadíme do rovnice vícenásobné regrese hodnoty získané pomocí vzorce LINEST:
y = 0,3*x 2 + 0.19*x 1 - 10.74
Například při vynaložení 50 USD na reklamu a průměrných měsíčních srážkách 100 mm se očekává, že prodáte přibližně 23 deštníků:
0.3*50 + 0.19*100 - 10.74 = 23.26
Jednoduchá lineární regrese: předpověď závislé proměnné
Kromě výpočtu a a b hodnot pro regresní rovnici, může funkce Excel LINEST také odhadnout závislou proměnnou (y) na základě známé nezávislé proměnné (x). K tomu se používá LINEST v kombinaci s funkcí SUM nebo SUMPRODUCT.
Například takto můžete vypočítat počet prodejů deštníků v následujícím měsíci, například v říjnu, na základě prodejů v předchozích měsících a říjnového rozpočtu na reklamu ve výši 50 USD:
=SUM(LINEST(C2:C10, B2:B10)*{50,1})
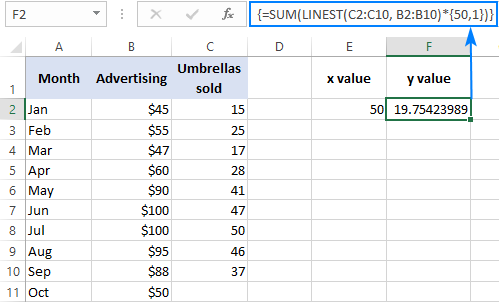
Namísto pevného kódování x hodnotu ve vzorci, můžete ji zadat jako odkaz na buňku. V tomto případě musíte do některé buňky zadat také konstantu 1, protože v konstantě pole nelze míchat odkazy a hodnoty.
S x v položce E2 a konstantu 1 v položce F2, bude fungovat jeden z následujících vzorců:
Pravidelný vzorec (zadává se stisknutím klávesy Enter ):
=SOUČIN(LINEST(C2:C10, B2:B10)*(E2:F2))
Vzorec pole (zadává se stisknutím kláves Ctrl + Shift + Enter ):
=SOUČET(LINEST(C2:C10, B2:B10)*(E2:F2))
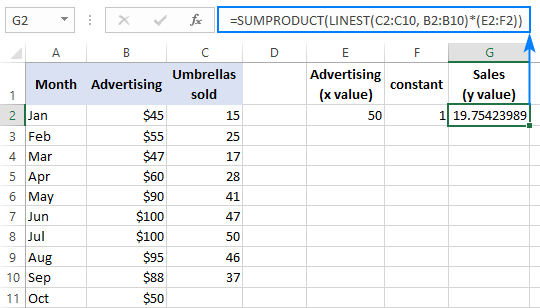
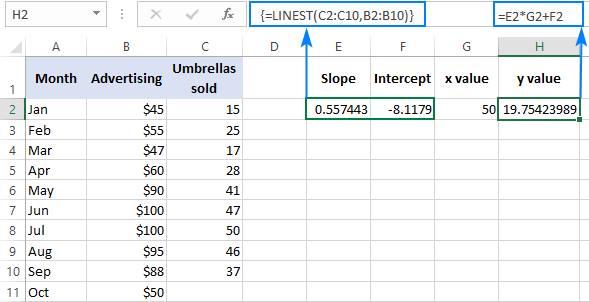
Chcete-li si výsledek ověřit, můžete pro stejná data získat průsečík a sklon a poté pomocí vzorce pro lineární regresi vypočítat y :
=E2*G2+F2
Kde E2 je sklon, G2 je sklon. x a F2 je intercepce:
Vícenásobná regrese: předpověď závislé proměnné
V případě, že máte co do činění s několika prediktory, tj. několika různými sadami prediktorů. x zahrňte všechny tyto prediktory do konstanty pole. Například při rozpočtu na reklamu ve výši 50 USD (x 2 ) a průměrný měsíční úhrn srážek 100 mm (x 1 ), vzorec je následující:
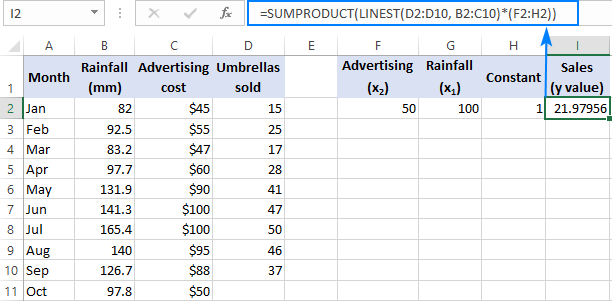
=SUM(LINEST(D2:D10, B2:C10)*{50,100,1})
Kde D2:D10 jsou známé y a B2:C10 jsou dvě sady hodnot. x hodnoty:

Věnujte prosím pozornost pořadí x Jak již bylo uvedeno dříve, když se funkce LINEST v Excelu používá k vícenásobné regresi, vrací koeficienty sklonu zprava doleva. V našem příkladu je to Reklama je nejprve vrácen koeficient a poté je vrácen koeficient Srážky Abyste správně vypočítali předpokládané číslo prodeje, musíte koeficienty vynásobit odpovídajícím koeficientem. x hodnot, takže prvky konstantního pole seřazujete v tomto pořadí: {50,100,1}. Poslední prvek je 1, protože poslední hodnota vrácená příkazem LINEST je intercepce, která se nemá měnit, takže ji jednoduše vynásobíte 1.
Místo použití konstanty pole můžete zadat všechny proměnné x do některých buněk a odkazovat na ně ve vzorci, jako jsme to udělali v předchozím příkladu.
Běžný vzorec:
=SOUČIN(LINEST(D2:D10, B2:C10)*(F2:H2))
Vzorec pole:
=SOUČET(LINEST(D2:D10, B2:C10)*(F2:H2))
Kde F2 a G2 jsou x a H2 je 1:
Vzorec LINEST: další regresní statistiky
Jak si možná pamatujete, chcete-li získat další statistické údaje pro regresní analýzu, vložíte do posledního argumentu funkce LINEST hodnotu TRUE. Při aplikaci na naše vzorová data má vzorec následující tvar:
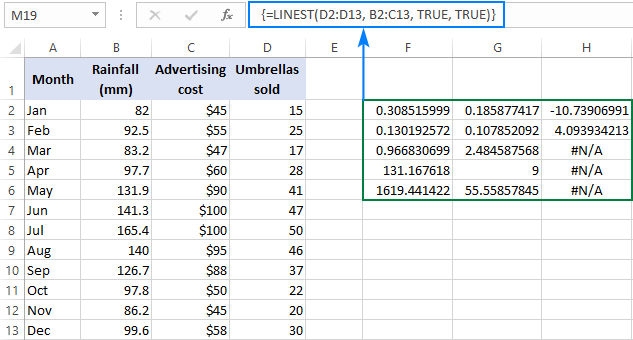
=LINEST(D2:D13, B2:C13, TRUE, TRUE)
Protože máme 2 nezávislé proměnné ve sloupcích B a C, vybereme hněv sestávající ze 3 řádků (dvě hodnoty x + intercepce) a 5 sloupců, zadáme výše uvedený vzorec, stiskneme Ctrl + Shift + Enter , a dostaneme tento výsledek:
Chcete-li se zbavit chyb #N/A, můžete LINEST vnořit do IFERROR takto:
=IFERROR(LINEST(D2:D13, B2:C13, TRUE, TRUE), "")
Níže uvedený obrázek ukazuje výsledek a vysvětluje, co jednotlivá čísla znamenají:

V předchozích příkladech byly vysvětleny koeficienty sklonu a průsečík Y, proto se v krátkosti podívejme na ostatní statistiky.
Koeficient determinace (R2). Hodnota R2 je výsledkem dělení součtu čtverců regrese celkovým součtem čtverců. Říká vám, kolik y jsou vysvětleny x V tomto příkladu je R2 přibližně 0,97, což znamená, že 97 % našich závislých proměnných (prodej deštníků) je vysvětleno nezávislými proměnnými (reklama + průměrné měsíční srážky), což je vynikající shoda!
Standardní chyby . Obecně tyto hodnoty ukazují přesnost regresní analýzy. Čím menší jsou tato čísla, tím jistější si můžete být svým regresním modelem.
F statistika . k potvrzení nebo zamítnutí nulové hypotézy použijete statistiku F. Při rozhodování o tom, zda jsou celkové výsledky významné, se doporučuje použít statistiku F v kombinaci s hodnotou P.
Stupně volnosti (df). Funkce LINEST v Excelu vrací hodnotu zbytkové stupně volnosti , což je celkový df mínus regresní df Stupně volnosti můžete použít k získání F-kritických hodnot ve statistické tabulce a poté porovnat F-kritické hodnoty se statistikou F a určit hladinu spolehlivosti pro váš model.
Regresní součet čtverců (aka vysvětlený součet čtverců , nebo modelový součet čtverců ) Je to součet čtvercových rozdílů mezi předpovídanými hodnotami y a střední hodnotou y, vypočtený podle tohoto vzorce: =∑(ŷ - ȳ)2. Udává, jak velkou část variability závislé proměnné váš regresní model vysvětluje.
Zbytkový součet čtverců Je to součet čtvercových rozdílů mezi skutečnými hodnotami y a předpovídanými hodnotami y. Udává, jak velkou část variability závislé proměnné váš model nevysvětluje. Čím menší je reziduální součet čtverců ve srovnání s celkovým součtem čtverců, tím lépe váš regresní model odpovídá vašim datům.
5 věcí, které byste měli vědět o funkci LINEST
Chcete-li v pracovních listech efektivně používat vzorce LINEST, možná budete chtít vědět něco více o "vnitřní mechanice" funkce:
- Known_y's a known_x's V jednoduchém lineárním regresním modelu s pouze jednou sadou proměnných x, known_y's a known_x's mohou být rozsahy libovolného tvaru, pokud mají stejný počet řádků a sloupců. Pokud provádíte vícenásobnou regresní analýzu s více než jednou sadou nezávislých dat. x proměnné, known_y's musí být vektor, tj. rozsah jednoho řádku nebo jednoho sloupce.
- Vynucení konstanty na nulu . Když const je TRUE nebo je vynechána, je argument a se vypočítá konstanta (intercepce) a zahrne se do rovnice: y=bx + a. Pokud const je nastavena na FALSE, intercept se považuje za rovný 0 a z regresní rovnice se vynechá: y=bx.
Ve statistice se již po desetiletí diskutuje o tom, zda má smysl vynucovat konstantu interceptu na 0, či nikoliv. Mnoho důvěryhodných odborníků na regresní analýzu se domnívá, že pokud se nastavení interceptu na nulu (const=FALSE) jeví jako užitečné, pak je lineární regrese sama o sobě špatným modelem pro daný soubor dat. Jiní předpokládají, že konstantu lze v určitých situacích vynucovat na nulu, např,Obecně se ve většině případů doporučuje použít výchozí hodnotu const=TRUE nebo ji vynechat.
- Přesnost . přesnost regresní rovnice vypočtené funkcí LINEST závisí na rozptylu vašich datových bodů. Čím lineárnější jsou data, tím přesnější jsou výsledky vzorce LINEST.
- Zbytečné hodnoty x V některých situacích může jeden nebo více nezávislých x proměnné nemusí mít žádnou dodatečnou vypovídací hodnotu a jejich odstranění z regresního modelu nemá vliv na přesnost předpovídaných hodnot y. Tento jev je znám jako "kolinearita". Funkce LINEST v Excelu kontroluje kolinearitu a vynechává všechny nadbytečné proměnné. x proměnné, které identifikuje z modelu. Vynechané proměnné x proměnné lze rozpoznat podle 0 koeficientů a 0 hodnot standardní chyby.
- LINEST vs. SLOPE a INTERCEPT . základní algoritmus funkce LINEST se liší od algoritmu použitého ve funkcích SLOPE a INTERCEPT. Proto v případě, že zdrojová data jsou neurčitá nebo kolineární, mohou tyto funkce vracet odlišné výsledky.
Nefunkčnost funkce LINEST aplikace Excel
Pokud váš vzorec LINEST vyhodí chybu nebo vyprodukuje nesprávný výstup, je pravděpodobné, že je to z jednoho z následujících důvodů:
- Pokud funkce LINEST vrací pouze jedno číslo (koeficient sklonu), s největší pravděpodobností jste ji zadali jako běžný vzorec, nikoli jako vzorec pole. Nezapomeňte stisknout klávesy Ctrl + Shift + Enter, abyste vzorec správně dokončili. Když to uděláte, vzorec se uzavře do {vlnitých závorek}, které jsou viditelné na panelu vzorců.
- #REF! chyba. Vyskytne se, pokud je known_x's a known_y's rozsahy mají různé rozměry.
- #VALUE! chyba. Nastane, pokud known_x's nebo known_y's obsahuje alespoň jednu prázdnou buňku, textovou hodnotu nebo textovou reprezentaci čísla, které Excel nerozpozná jako číselnou hodnotu. K chybě #VALUE dojde také v případě, že se v poli const nebo statistiky argument nelze vyhodnotit jako TRUE nebo FALSE.
Takto se v Excelu používá LINEST pro jednoduchou a vícenásobnou lineární regresní analýzu. Chcete-li se blíže seznámit se vzorci probíranými v tomto tutoriálu, můžete si stáhnout náš ukázkový sešit níže. Děkuji vám za přečtení a doufám, že se uvidíme na našem blogu příští týden!
Cvičebnice ke stažení
Příklady funkcí Excel LINEST (.xlsx soubor)
