
Indholdsfortegnelse
Vejledningen forklarer det grundlæggende i regressionsanalyse og viser et par forskellige måder at lave lineær regression på i Excel.
Forestil dig dette: Du får en hel masse forskellige data og bliver bedt om at forudsige næste års salgstal for din virksomhed. Du har fundet dusinvis, måske endda hundredevis af faktorer, der muligvis kan påvirke tallene. Men hvordan ved du, hvilke der virkelig er vigtige? Kør en regressionsanalyse i Excel. Den vil give dig svar på dette og mange andre spørgsmål: Hvilke faktorerHvor tæt er disse faktorer forbundet med hinanden, og hvor sikre kan man være på forudsigelserne?
Regressionsanalyse i Excel - det grundlæggende
I statistisk modellering, regressionsanalyse anvendes til at estimere sammenhængen mellem to eller flere variabler:
Afhængig variabel (også kendt som kriterium variabel) er den vigtigste faktor, som du forsøger at forstå og forudsige.
Uafhængige variabler (også kendt som forklarende variabler, eller prædiktorer ) er de faktorer, der kan påvirke den afhængige variabel.
Regressionsanalyse hjælper dig med at forstå, hvordan den afhængige variabel ændrer sig, når en af de uafhængige variabler varierer, og giver dig mulighed for matematisk at afgøre, hvilken af disse variabler der virkelig har en indflydelse.
Teknisk set er en regressionsanalysemodel baseret på den summen af kvadrater Målet med en model er at opnå den mindst mulige sum af kvadrater og tegne en linje, der kommer tættest på dataene.
I statistik skelner man mellem en simpel og en multipel lineær regression. Simpel lineær regression modellerer forholdet mellem en afhængig variabel og en uafhængig variabel ved hjælp af en lineær funktion. Hvis man bruger to eller flere forklarende variabler til at forudsige den afhængige variabel, har man at gøre med multipel lineær regression Hvis den afhængige variabel er modelleret som en ikke-lineær funktion, fordi dataforholdene ikke følger en ret linje, skal du bruge ikke-lineær regression Fokus i denne vejledning vil være på en simpel lineær regression.
Lad os f.eks. tage salgstallene for paraplyer for de sidste 24 måneder og finde ud af den gennemsnitlige månedlige nedbørsmængde for samme periode. Placér disse oplysninger på et diagram, og regressionslinjen vil vise forholdet mellem den uafhængige variabel (nedbørsmængde) og den afhængige variabel (salg af paraplyer): 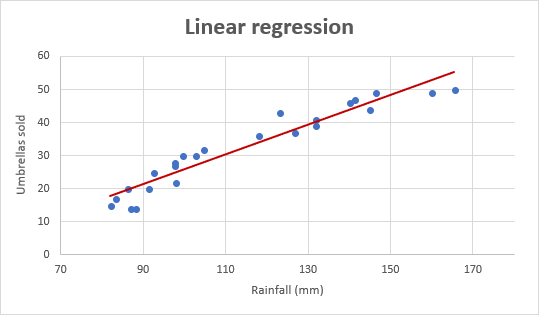
Lineær regressionsligning
Matematisk set er en lineær regression defineret ved denne ligning:
y = bx + a + εHvor:
- x er en uafhængig variabel.
- y er en afhængig variabel.
- a er den Y-intercept , som er den forventede middelværdi af y når alle x variabler er lig med 0. På en regressionsgraf er det det punkt, hvor linjen krydser Y-aksen.
- b er den hældning af en regressionslinje, som er ændringshastigheden for y som x ændringer.
- ε er den tilfældige fejltermin, som er forskellen mellem den faktiske værdi af en afhængig variabel og dens forudsagte værdi.
Den lineære regressionsligning har altid en fejltermin, fordi forudsigere i virkeligheden aldrig er helt præcise. Nogle programmer, herunder Excel, foretager dog beregningen af fejlterminen bag kulisserne. I Excel udfører du lineær regression ved hjælp af mindste kvadrater metode og søge koefficienter a og b således, at:
y = bx + aI vores eksempel har den lineære regressionsligning følgende form:
Solgte paraplyer = b * nedbør + a
Der findes en håndfuld forskellige måder at finde a og b De tre vigtigste metoder til at udføre lineær regressionsanalyse i Excel er:
- Regressionsværktøj inkluderet i Analysis ToolPak
- Spredningsdiagram med en tendenslinje
- Formel for lineær regression
Nedenfor finder du en detaljeret vejledning til hver metode.
Sådan laver du lineær regression i Excel med Analysis ToolPak
Dette eksempel viser, hvordan du kan køre regression i Excel ved hjælp af et særligt værktøj, der er inkluderet i tilføjelsesprogrammet Analysis ToolPak.
Aktiver tilføjelsesprogrammet Analysis ToolPak
Analysis ToolPak er tilgængelig i alle versioner af Excel 365 til 2003, men er ikke aktiveret som standard. Du skal derfor slå det til manuelt. Sådan gør du:
- I Excel skal du klikke på Fil > Indstillinger .
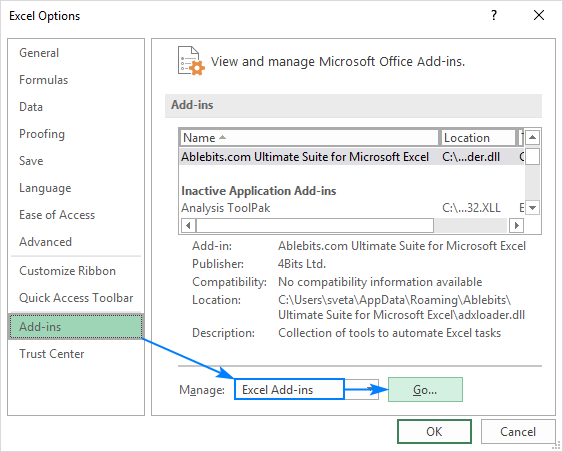
- I den Excel-muligheder dialogboksen, skal du vælge Tilføjelser på venstre sidepanel, skal du sørge for, at Excel-tilføjelser er valgt i den Administrer feltet, og klik på Gå .
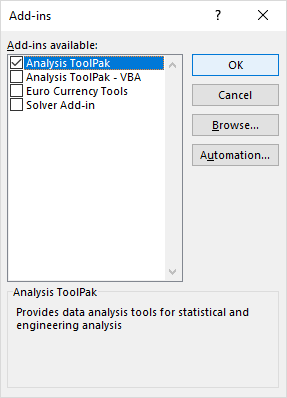
- I den Tilføjelser dialogboksen, afkrydse Analyseværktøjspakke , og klik på OK :
Dette vil tilføje den Analyse af data værktøjer til den Data fanen i Excel-båndet.
Kør regressionsanalyse
I dette eksempel vil vi lave en simpel lineær regression i Excel. Vi har en liste over den gennemsnitlige månedlige nedbør i de sidste 24 måneder i kolonne B, som er vores uafhængige variabel (prædiktor), og antallet af solgte paraplyer i kolonne C, som er den afhængige variabel. Der er naturligvis mange andre faktorer, der kan påvirke salget, men i øjeblikket fokuserer vi kun på disse to variabler: 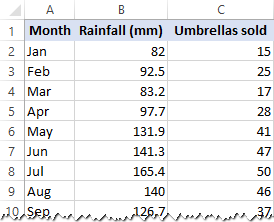
Når Analysis Toolpak er aktiveret, skal du udføre disse trin for at udføre regressionsanalyse i Excel:
- På den Data under fanen, i fanen Analyse gruppe, skal du klikke på Analyse af data knap.
- Vælg Regression og klik på OK .
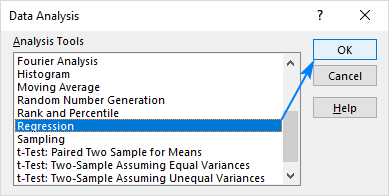
- I den Regression skal du konfigurere følgende indstillinger:
- Vælg den Input Y-område , som er din afhængige variabel I vores tilfælde er det paraplysalg (C1:C25).
- Vælg den Indgang X Område , dvs. din uafhængig variabel I dette eksempel er det den gennemsnitlige månedlige nedbørsmængde (B1:B25).
Hvis du opretter en multipel regressionsmodel, skal du vælge to eller flere tilstødende kolonner med forskellige uafhængige variabler.
- Kontroller den Etiketter boks hvis der er overskrifter øverst i dine X- og Y-områder.
- Vælg din foretrukne Mulighed for udgang, et nyt regneark i vores tilfælde.
- Du kan eventuelt vælge den Restprodukter for at få forskellen mellem den forudsagte og den faktiske værdi.
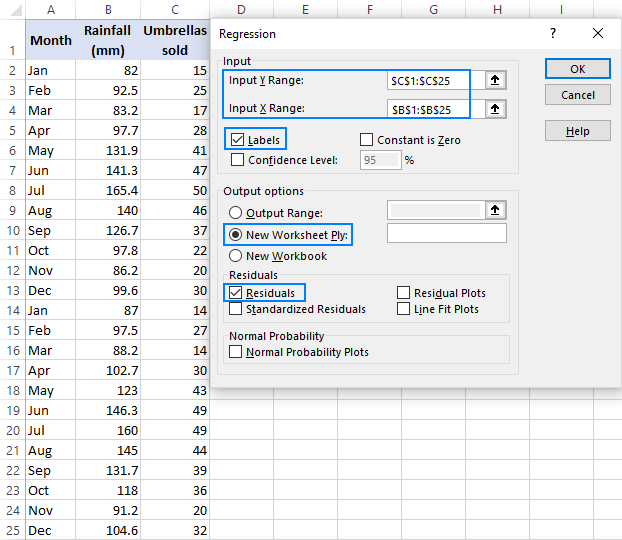
- Klik på OK og se det regressionsanalyseoutput, der er oprettet af Excel.
Fortolke resultatet af regressionsanalysen
Som du lige har set, er det nemt at udføre regression i Excel, fordi alle beregninger udføres automatisk. Fortolkningen af resultaterne er lidt vanskeligere, fordi du skal vide, hvad der ligger bag hvert tal. Nedenfor finder du en opdeling af de fire hoveddele af regressionsanalysens output.
Output af regressionsanalysen: Resume af output
Denne del fortæller dig, hvor godt den beregnede lineære regressionsligning passer til dine kildedata. 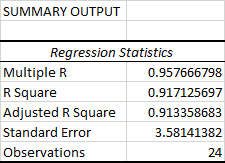
Her er, hvad de enkelte oplysninger betyder:
Flere R . Det er den C orrelationskoefficient der måler styrken af en lineær sammenhæng mellem to variabler. Korrelationskoefficienten kan have en værdi mellem -1 og 1, og dens absolutte værdi angiver styrken af sammenhængen. Jo større den absolutte værdi er, desto stærkere er sammenhængen:
- 1 betyder et stærkt positivt forhold
- -1 betyder en stærk negativ sammenhæng
- 0 betyder ingen forbindelse overhovedet
R-kvadrat . Det er den Bestemmelseskoefficient , som bruges som en indikator for tilpasningsgraden. Den viser, hvor mange punkter der ligger på regressionslinjen. R2-værdien beregnes ud fra den samlede sum af kvadrater, mere præcist er det summen af de originale datas kvadrerede afvigelser fra middelværdien.
I vores eksempel er R2 0,91 (afrundet til 2 cifre), hvilket er godt. Det betyder, at 91 % af vores værdier passer til regressionsanalysemodellen. Med andre ord forklares 91 % af de afhængige variabler (y-værdier) af de uafhængige variabler (x-værdier). Generelt anses en R Squared på 95 % eller mere for at være en god tilpasning.
Justeret R-kvadrat . Det er den R kvadrat justeret for antallet af uafhængige variabler i modellen. Du skal bruge denne værdi i stedet for R kvadrat til multipel regressionsanalyse.
Standardfejl Det er et andet mål for god tilpasningsevne, der viser præcisionen af din regressionsanalyse - jo mindre tallet er, jo mere sikker kan du være på din regressionsligning. Mens R2 repræsenterer den procentdel af de afhængige variablers varians, der forklares af modellen, er standardfejl et absolut mål, der viser den gennemsnitlige afstand, som datapunkterne ligger fra regressionsligningen.linje.
Bemærkninger Det er simpelthen antallet af observationer i din model.
Resultat af regressionsanalyse: ANOVA
Den anden del af outputtet er variansanalyse (ANOVA): 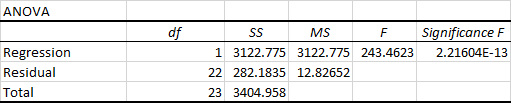
Den opdeler summen af kvadrater i individuelle komponenter, der giver oplysninger om variabilitetsniveauet i din regressionsmodel:
- df er antallet af frihedsgrader i forbindelse med varianskilderne.
- SS er summen af kvadrater. Jo mindre rest-SS er i forhold til det samlede SS, jo bedre passer din model til dataene.
- MS er kvadratmidlet.
- F er F-statistikken eller F-testen for nulhypotesen. Den bruges til at teste modellens generelle signifikans.
- Betydning F er P-værdien af F.
ANOVA-delen bruges sjældent til en simpel lineær regressionsanalyse i Excel, men du bør helt sikkert kigge nærmere på den sidste komponent. Betydning F værdien giver en idé om, hvor pålidelige (statistisk signifikante) dine resultater er. Hvis Signifikans F er mindre end 0,05 (5 %), er din model OK. Hvis den er større end 0,05, er det nok bedre at vælge en anden uafhængig variabel.
Output af regressionsanalysen: koefficienter
Dette afsnit indeholder specifikke oplysninger om de enkelte dele af din analyse: 
Den mest nyttige komponent i dette afsnit er Koefficienter Det giver dig mulighed for at opbygge en lineær regressionsligning i Excel:
y = bx + aFor vores datasæt, hvor y er antallet af solgte paraplyer, og x er den gennemsnitlige månedlige nedbørsmængde, lyder vores lineære regressionsformel således:
Y = nedbørskoefficient * x + Intercept
Udstyret med a- og b-værdier afrundet til tre decimaler bliver det til:
Y=0,45*x-19,074
Hvis den gennemsnitlige månedlige nedbørsmængde f.eks. er 82 mm, vil paraplysalget være ca. 17,8 mm:
0.45*82-19.074=17.8
På samme måde kan du finde ud af, hvor mange paraplyer der vil blive solgt med en hvilken som helst anden månedlig nedbørsmængde (x-variabel), du angiver.
Output af regressionsanalysen: residualer
Hvis man sammenligner det anslåede og det faktiske antal solgte paraplyer svarende til den månedlige nedbørsmængde på 82 mm, vil man se, at disse tal er lidt forskellige:
- Anslået: 17,8 (beregnet ovenfor)
- Faktisk: 15 (række 2 i kildedataene)
Hvorfor er der forskel? Fordi uafhængige variabler aldrig er perfekte forudsigere af de afhængige variabler. Og residualerne kan hjælpe dig med at forstå, hvor langt de faktiske værdier er fra de forudsagte værdier: 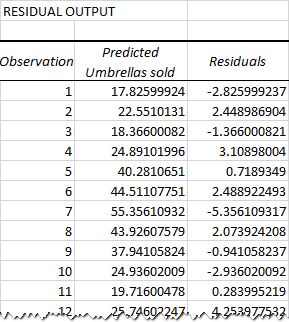
For det første datapunkt (nedbør på 82 mm) er restværdien ca. -2,8. Så vi lægger dette tal til den forudsagte værdi og får den faktiske værdi: 17,8 - 2,8 = 15.
Hvordan man laver en lineær regressionsgraf i Excel
Hvis du hurtigt skal visualisere forholdet mellem de to variabler, kan du tegne et lineært regressionsdiagram. Det er meget nemt! Sådan gør du:
- Vælg de to kolonner med dine data, herunder overskrifter.
- På den Indsat under fanen, i fanen Chats gruppe, skal du klikke på Spredningsdiagram ikonet, og vælg ikonet Spredning miniaturebillede (det første):
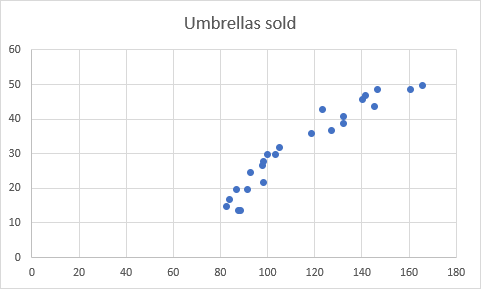
Dette vil indsætte et spredningsdiagram i dit regneark, som vil ligne dette:
- Nu skal vi tegne regressionslinjen for de mindste kvadraters regression. For at få det gjort skal du højreklikke på et punkt og vælge Tilføj Trendline... fra kontekstmenuen.
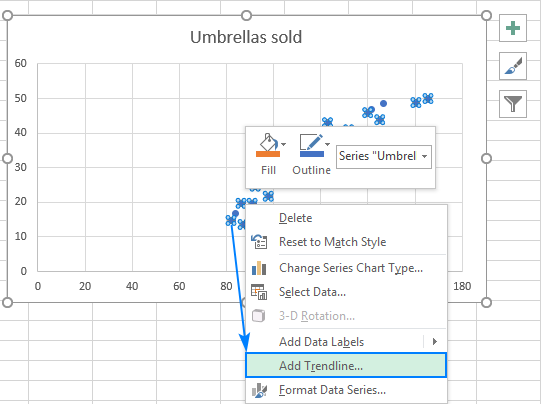
- I den højre rude skal du vælge den Lineær trendlinjeform og eventuelt kontrollere Visning af ligning på diagrammet for at få din regressionsformel:
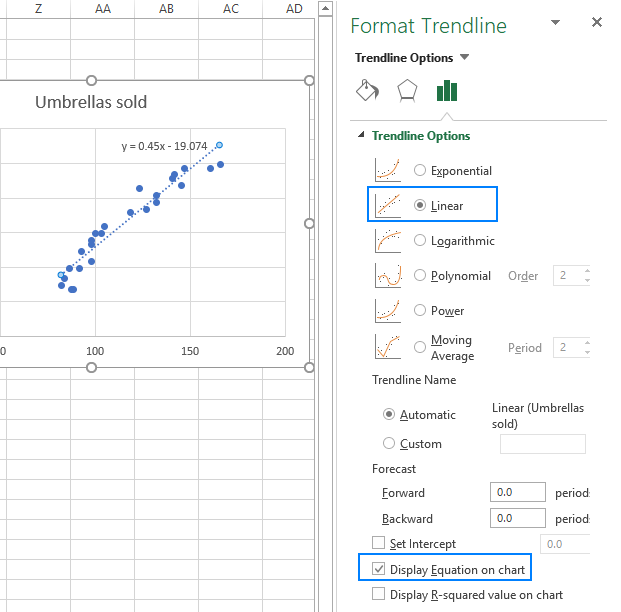
Som du måske vil bemærke, er den regressionsligning, som Excel har oprettet for os, den samme som den lineære regressionsformel, vi har oprettet på grundlag af koefficienterne.
- Skift til den Fyld & linje og tilpasse linjen efter dine ønsker. Du kan f.eks. vælge en anden farve på linjen og bruge en gennemgående linje i stedet for en stiplet linje (vælg Gennemgående linje i fanebladet Type af instrumentbræt boks):
På dette tidspunkt ligner dit diagram allerede en fornuftig regressionsgraf: 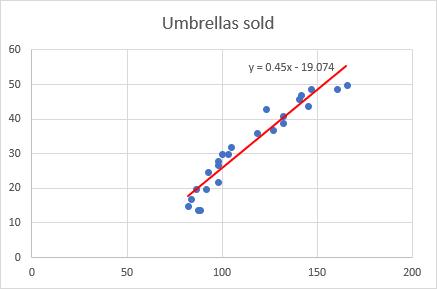
Alligevel bør du måske foretage et par forbedringer mere:
- Træk ligningen, hvor du ønsker det.
- Tilføj titler på akser ( Diagramelementer knap> Axis Titler ).
- Hvis dine datapunkter starter midt på den vandrette og/eller lodrette akse som i dette eksempel, kan det være nødvendigt at fjerne det for store hvide rum. Følgende tip forklarer, hvordan du gør dette: Skaler diagramakserne for at reducere det hvide rum.
Og sådan ser vores forbedrede regressionsgraf ud:
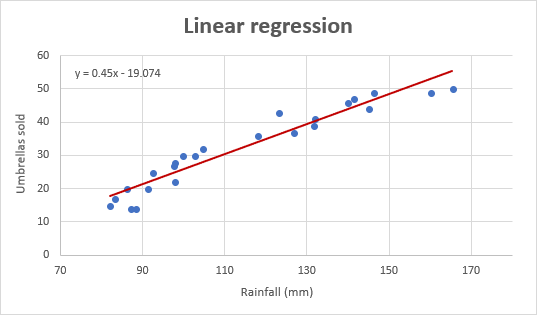
Vigtig bemærkning! I regressionsgrafen skal den uafhængige variabel altid være på X-aksen og den afhængige variabel på Y-aksen. Hvis din graf er tegnet i omvendt rækkefølge, skal du bytte kolonnerne i dit regneark og derefter tegne grafen på ny. Hvis du ikke må omarrangere kildedataene, kan du bytte om på X- og Y-aksen direkte i et diagram.
Sådan laver du regression i Excel ved hjælp af formler
Microsoft Excel har et par statistiske funktioner, der kan hjælpe dig med at lave lineær regressionsanalyse, f.eks. LINEST, SLOPE, INTERCEPT og CORREL.
LINEST-funktionen bruger regressionsmetoden med mindste kvadraters regression til at beregne en lige linje, der bedst forklarer forholdet mellem dine variabler, og returnerer et array, der beskriver denne linje. Du kan finde en detaljeret forklaring af funktionens syntaks i denne vejledning. Lad os nu bare lave en formel for vores eksempeldatasæt:
=LINEST(C2:C25, B2:B25)
Da LINEST-funktionen returnerer et array af værdier, skal du indtaste den som en arrayformel. Vælg to tilstødende celler i samme række, E2:F2 i vores tilfælde, skriv formlen, og tryk på Ctrl + Shift + Enter for at fuldføre den.
Formlen returnerer den b koefficient (E1) og den a konstant (F1) for den allerede velkendte lineære regressionsligning:
y = bx + a 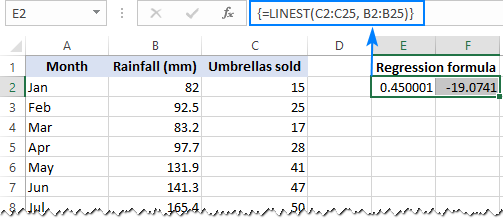
Hvis du undgår at bruge arrayformler i dine regneark, kan du beregne a og b individuelt med almindelige formler:
Få Y-interceptet (a):
=INTERCEPT(C2:C25, B2:B25)
Beregn hældningen (b):
=HÆLDNING(C2:C25, B2:B25)
Derudover kan du finde den korrelationskoefficient ( Flere R i regressionsanalysens resumé), der angiver, hvor stærkt de to variabler er relateret til hinanden:
=CORREL(B2:B25,C2:C25)
Følgende skærmbillede viser alle disse regressionsformler i Excel i aktion: 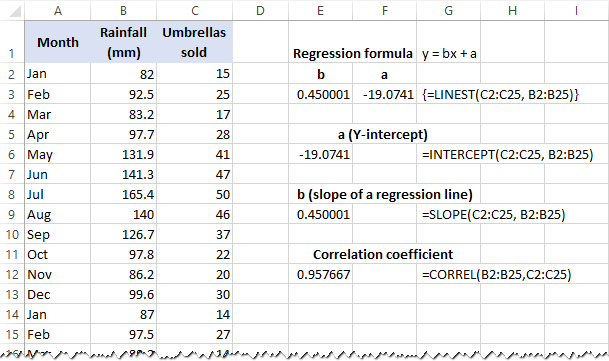
Tip. Hvis du gerne vil have yderligere statistik til din regressionsanalyse, kan du bruge LINEST-funktionen med s tatoveringer parameteren sat til TRUE som vist i dette eksempel.
Sådan laver du lineær regression i Excel. Når det er sagt, skal du huske på, at Microsoft Excel ikke er et statistisk program. Hvis du skal udføre regressionsanalyse på professionelt niveau, skal du måske bruge målrettet software som XLSTAT, RegressIt osv.
Hvis du vil se nærmere på vores formler til lineær regression og andre teknikker, der er beskrevet i denne vejledning, er du velkommen til at downloade vores prøvearbejdsbog nedenfor. Tak for læsningen!
Arbejdsbog til øvelser
Regressionsanalyse i Excel - eksempler (.xlsx-fil)
