
Obsah
Výukový program vysvětluje základy regresní analýzy a ukazuje několik různých způsobů, jak v aplikaci Excel provádět lineární regresi.
Představte si následující situaci: máte k dispozici celou řadu různých údajů a máte předpovědět, jaké budou tržby vaší společnosti v příštím roce. Objevili jste desítky, možná dokonce stovky faktorů, které mohou mít na čísla vliv. Jak ale zjistíte, které z nich jsou skutečně důležité? Spusťte regresní analýzu v programu Excel. Ta vám dá odpověď na tuto a mnoho dalších otázek: Které faktoryNa čem záleží a které lze ignorovat? Jak úzce spolu tyto faktory souvisejí? A jak jistí si můžete být předpovědí?
Regresní analýza v aplikaci Excel - základy
Ve statistickém modelování, regresní analýza se používá k odhadu vztahů mezi dvěma nebo více proměnnými:
Závislá proměnná (aka kritérium proměnná) je hlavním faktorem, který se snažíte pochopit a předpovědět.
Nezávislé proměnné (aka vysvětlení proměnné nebo prediktory ) jsou faktory, které mohou ovlivnit závislou proměnnou.
Regresní analýza pomáhá pochopit, jak se mění závislá proměnná při změně jedné z nezávislých proměnných, a umožňuje matematicky určit, která z těchto proměnných má skutečný vliv.
Z technického hlediska je model regresní analýzy založen na tom, že součet čtverců , což je matematický způsob, jak zjistit rozptyl datových bodů. Cílem modelu je získat co nejmenší součet čtverců a nakreslit přímku, která se nejvíce blíží datům.
Ve statistice se rozlišuje jednoduchá a vícenásobná lineární regrese. Jednoduchá lineární regrese modeluje vztah mezi závislou proměnnou a jednou nezávislou proměnnou pomocí lineární funkce. Pokud k předpovědi závislé proměnné použijete dvě nebo více vysvětlujících proměnných, máte co do činění s tzv. vícenásobná lineární regrese Pokud je závislá proměnná modelována jako nelineární funkce, protože vztahy mezi daty nesledují přímku, použijte příkaz nelineární regrese Místo toho se v tomto tutoriálu zaměříme na jednoduchou lineární regresi.
Jako příklad uveďme údaje o prodeji deštníků za posledních 24 měsíců a zjistěme průměrný měsíční úhrn srážek za stejné období. Tyto informace zakreslete do grafu a regresní přímka ukáže vztah mezi nezávislou proměnnou (úhrn srážek) a závislou proměnnou (prodej deštníků): 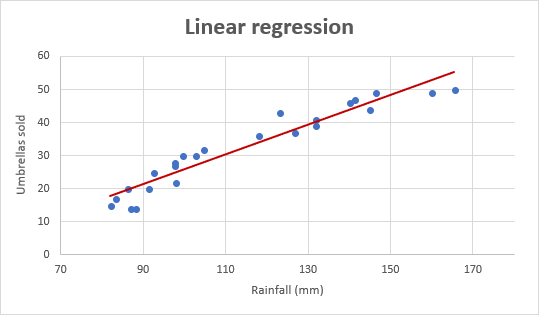
Lineární regresní rovnice
Matematicky je lineární regrese definována touto rovnicí:
y = bx + a + εKde:
- x je nezávislá proměnná.
- y je závislá proměnná.
- a je Y-intercept , což je očekávaná střední hodnota y když všechny x proměnné jsou rovny 0. V regresním grafu je to bod, kde přímka protíná osu Y.
- b je svah regresní přímky, což je míra změny pro y jako x změny.
- ε je náhodný chybový člen, který představuje rozdíl mezi skutečnou hodnotou závislé proměnné a její předpovídanou hodnotou.
Rovnice lineární regrese vždy obsahuje chybový člen, protože v reálném životě nejsou prediktory nikdy dokonale přesné. Některé programy, včetně Excelu, však provádějí výpočet chybového členu v pozadí. V Excelu tedy provádíte lineární regresi pomocí příkazu nejmenší čtverce metoda a hledání koeficientů a a b tak, že:
y = bx + aPro náš příklad má rovnice lineární regrese následující tvar:
Prodané deštníky = b * srážky + a
Existuje několik různých způsobů, jak najít a a b Tři hlavní metody provádění lineární regresní analýzy v aplikaci Excel jsou následující:
- Regresní nástroj obsažený v balíku Analysis ToolPak
- Graf rozptylu s trendovou čarou
- Lineární regresní vzorec
Níže najdete podrobné pokyny k použití jednotlivých metod.
Jak provádět lineární regresi v aplikaci Excel pomocí nástroje Analysis ToolPak
Tento příklad ukazuje, jak spustit regresi v aplikaci Excel pomocí speciálního nástroje, který je součástí doplňku Analysis ToolPak.
Povolení doplňku Analysis ToolPak
Nástroj Analysis ToolPak je k dispozici ve všech verzích aplikace Excel 365 až 2003, ale ve výchozím nastavení není povolen. Musíte jej tedy zapnout ručně. Zde je návod, jak na to:
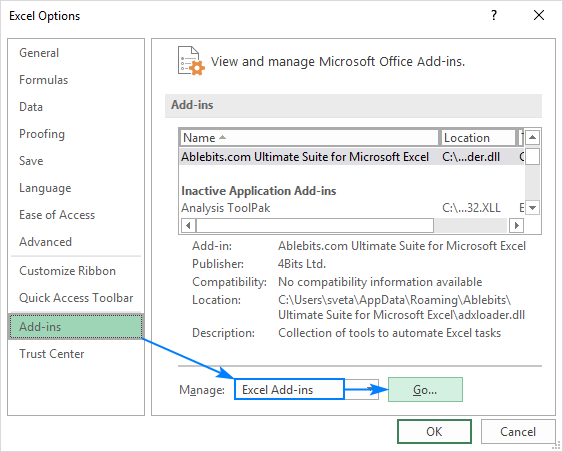
- V aplikaci Excel klikněte na Soubor > Možnosti .
- V Možnosti aplikace Excel dialogového okna vyberte možnost Doplňky na levém postranním panelu, ujistěte se, že Doplňky aplikace Excel je vybrána v okně Správa a klikněte na tlačítko Přejít na .
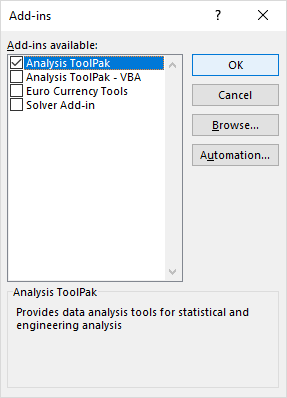
- V Doplňky dialogové okno, zaškrtněte políčko Analytický balíček nástrojů a klikněte na tlačítko OK :
Tím se přidá Analýza dat nástroje do Data na kartě Pás karet aplikace Excel.
Proveďte regresní analýzu
V tomto příkladu provedeme v Excelu jednoduchou lineární regresi. Máme k dispozici seznam průměrných měsíčních srážek za posledních 24 měsíců ve sloupci B, což je naše nezávislá proměnná (prediktor), a počet prodaných deštníků ve sloupci C, což je závislá proměnná. Samozřejmě existuje mnoho dalších faktorů, které mohou ovlivnit prodej, ale prozatím se zaměříme pouze na tyto dvě proměnné: 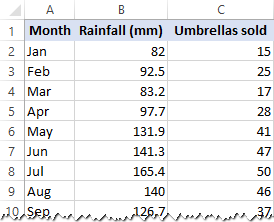
Po přidání nástroje Analysis Toolpak proveďte následující kroky k provedení regresní analýzy v aplikaci Excel:
- Na Data na kartě Analýza klikněte na skupinu Analýza dat tlačítko.
- Vyberte Regrese a klikněte na OK .
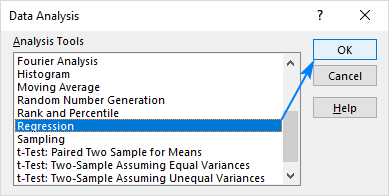
- V Regrese dialogového okna nakonfigurujte následující nastavení:
- Vyberte Vstupní rozsah Y , což je vaše závislá proměnná V našem případě je to prodej deštníků (C1:C25).
- Vyberte Rozsah vstupu X , tj. vaše nezávislá proměnná V tomto příkladu se jedná o průměrné měsíční srážky (B1:B25).
Pokud sestavujete vícenásobný regresní model, vyberte dva nebo více sousedních sloupců s různými nezávislými proměnnými.
- Zkontrolujte Krabice na štítky pokud jsou v horní části rozsahů X a Y hlavičky.
- Vyberte si preferovaný Možnost výstupu, nový pracovní list v našem případě.
- Volitelně vyberte Zbytky zaškrtávacího políčka, abyste získali rozdíl mezi předpokládanými a skutečnými hodnotami.
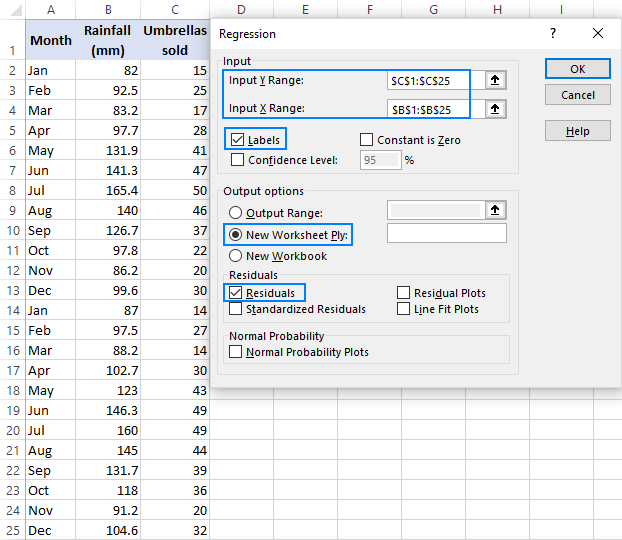
- Klikněte na OK a sledujte výstup regresní analýzy vytvořený programem Excel.
Interpretace výstupu regresní analýzy
Jak jste právě viděli, spuštění regrese v aplikaci Excel je snadné, protože všechny výpočty jsou provedeny automaticky. Interpretace výsledků je trochu složitější, protože musíte vědět, co se za jednotlivými čísly skrývá. Níže najdete rozpis 4 hlavních částí výstupu regresní analýzy.
Výstup regresní analýzy: Souhrnný výstup
V této části se dozvíte, jak dobře vypočtená rovnice lineární regrese odpovídá zdrojovým datům. 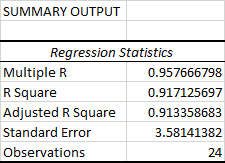
Zde se dozvíte, co jednotlivé informace znamenají:
Více R . Je to C orrelační koeficient který měří sílu lineárního vztahu mezi dvěma proměnnými. Korelační koeficient může nabývat libovolné hodnoty v rozmezí -1 až 1 a jeho absolutní hodnota udává sílu vztahu. Čím větší je absolutní hodnota, tím silnější je vztah:
- 1 znamená silný pozitivní vztah
- -1 znamená silný negativní vztah
- 0 znamená žádný vztah
R Square . Je to Koeficient determinace , který se používá jako ukazatel dobré shody. Ukazuje, kolik bodů připadá na regresní přímku. Hodnota R2 se vypočítá z celkového součtu čtverců, přesněji řečeno je to součet čtvercových odchylek původních dat od průměru.
V našem příkladu je R2 0,91 (zaokrouhleno na 2 číslice), což je pohádkově dobré. Znamená to, že 91 % našich hodnot odpovídá modelu regresní analýzy. Jinými slovy, 91 % závislých proměnných (hodnot y) je vysvětleno nezávislými proměnnými (hodnotami x). Obecně se za dobrou shodu považuje hodnota R Squared 95 % nebo vyšší.
Upravené R Square . Je to R čtverec upravená podle počtu nezávislých proměnných v modelu. Tuto hodnotu budete chtít použít místo hodnoty R čtverec pro vícenásobnou regresní analýzu.
Standardní chyba Jedná se o další míru dobré shody, která ukazuje přesnost vaší regresní analýzy - čím menší číslo, tím jistější si můžete být svou regresní rovnicí. Zatímco R2 představuje procento rozptylu závislých proměnných, které je vysvětleno modelem, standardní chyba je absolutní míra, která ukazuje průměrnou vzdálenost, v jaké se datové body nacházejí od regresní rovnice.linka.
Pozorování Je to jednoduše počet pozorování ve vašem modelu.
Výstup regresní analýzy: ANOVA
Druhou částí výstupu je analýza rozptylu (ANOVA): 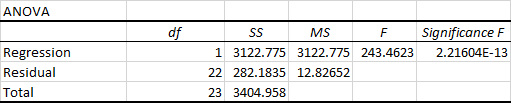
V podstatě rozdělí součet čtverců na jednotlivé složky, které poskytují informace o úrovni variability v rámci regresního modelu:
- df je počet stupňů volnosti spojených se zdroji rozptylu.
- SS Čím menší je zbytkové SS ve srovnání s celkovým SS, tím lépe váš model odpovídá datům.
- MS je střední kvadratická hodnota.
- F je statistika F neboli F-test pro nulovou hypotézu. Používá se k testování celkové významnosti modelu.
- Významnost F je P-hodnota F.
Část ANOVA se u jednoduché lineární regresní analýzy v Excelu používá jen zřídka, ale rozhodně byste se měli pozorně podívat na poslední složku. Významnost F hodnota poskytuje představu o tom, jak spolehlivé (statisticky významné) jsou vaše výsledky. Pokud je Significance F menší než 0,05 (5 %), je váš model v pořádku. Pokud je větší než 0,05, pravděpodobně bude lepší zvolit jinou nezávislou proměnnou.
Výstup regresní analýzy: koeficienty
Tato část obsahuje konkrétní informace o složkách vaší analýzy: 
Nejužitečnější složkou v této části je Koeficienty Umožňuje sestavit rovnici lineární regrese v aplikaci Excel:
y = bx + aPro náš soubor dat, kde y je počet prodaných deštníků a x je průměrný měsíční úhrn srážek, je náš lineární regresní vzorec následující:
Y = Koeficient srážek * x + Intercept
Po doplnění hodnot a a b zaokrouhlených na tři desetinná místa vznikne:
Y=0,45*x-19,074
Například při průměrném měsíčním úhrnu srážek 82 mm by prodej deštníků činil přibližně 17,8:
0.45*82-19.074=17.8
Podobným způsobem můžete zjistit, kolik deštníků se prodá při jakémkoli jiném zadaném měsíčním úhrnu srážek (proměnná x).
Výstup regresní analýzy: rezidua
Porovnáte-li odhadovaný a skutečný počet prodaných deštníků odpovídající měsíčnímu úhrnu srážek 82 mm, zjistíte, že se tato čísla mírně liší:
- Odhad: 17,8 (vypočteno výše)
- Skutečnost: 15 (řádek 2 zdrojových údajů)
Proč je v tom rozdíl? Protože nezávislé proměnné nikdy nejsou dokonalými prediktory závislých proměnných. A rezidua vám pomohou pochopit, jak daleko jsou skutečné hodnoty od hodnot předpovídaných: 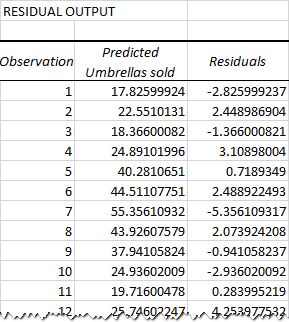
Pro první datový bod (srážky 82 mm) je reziduální hodnota přibližně -2,8. Toto číslo tedy přičteme k předpovězené hodnotě a získáme skutečnou hodnotu: 17,8 - 2,8 = 15.
Jak vytvořit lineární regresní graf v aplikaci Excel
Pokud potřebujete rychle zobrazit vztah mezi dvěma proměnnými, nakreslete lineární regresní graf. To je velmi snadné! Zde je návod:
- Vyberte dva sloupce s daty včetně záhlaví.
- Na Vložka na kartě Chaty klikněte na skupinu Graf rozptylu a vyberte ikonu Rozptyl miniatura (první):
Tím se do pracovního listu vloží graf rozptylu, který se bude podobat tomuto grafu:
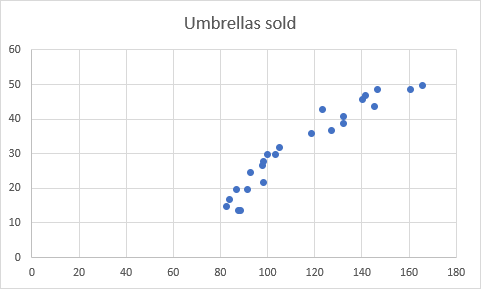
- Nyní musíme nakreslit regresní přímku nejmenších čtverců. To provedeme tak, že klikneme pravým tlačítkem myši na libovolný bod a vybereme možnost Přidat Trendline... z kontextové nabídky.
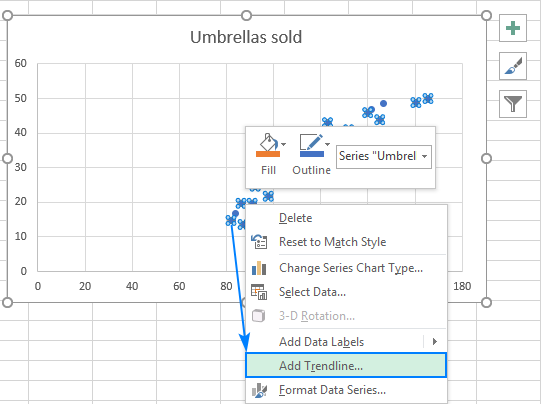
- V pravém podokně vyberte Lineární tvar trendové čáry a volitelně zkontrolovat Zobrazení rovnice na grafu a získáte regresní vzorec:
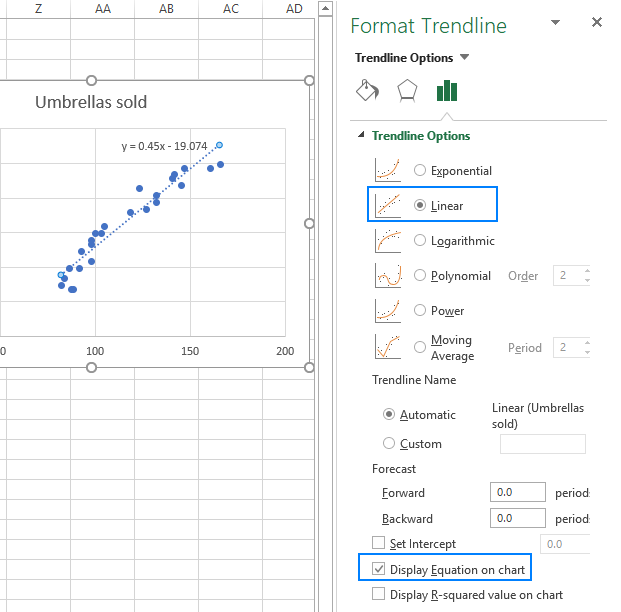
Jak si můžete všimnout, regresní rovnice, kterou pro nás Excel vytvořil, je stejná jako vzorec lineární regrese, který jsme sestavili na základě výstupu Koeficienty.
- Přepněte na Výplň & řádek a upravte čáru podle svých představ. Můžete například zvolit jinou barvu čáry a použít plnou čáru místo přerušované (vyberte možnost Plná čára v okně . Typ pomlčky box):
V tuto chvíli už váš graf vypadá jako slušný regresní graf: 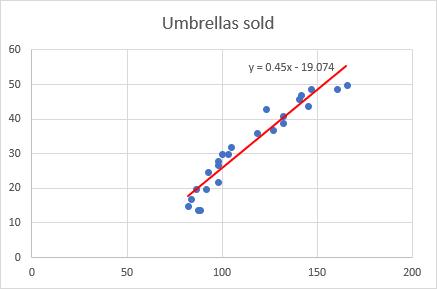
Přesto byste možná chtěli provést několik dalších vylepšení:
- Přetáhněte rovnici, kam uznáte za vhodné.
- Přidání názvů os ( Prvky grafu tlačítko> Tituly osy ).
- Pokud vaše datové body začínají uprostřed vodorovné a/nebo svislé osy jako v tomto příkladu, možná se budete chtít zbavit nadměrného bílého místa. Následující tip vysvětluje, jak to udělat: Zmenšete měřítko os grafu, abyste zmenšili bílé místo.
A takto vypadá náš vylepšený regresní graf:
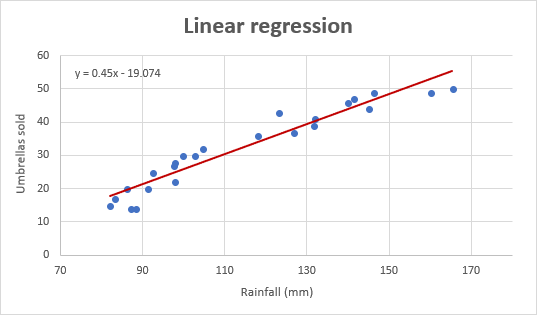
Důležité upozornění! V regresním grafu by měla být nezávislá proměnná vždy na ose X a závislá proměnná na ose Y. Pokud je graf vykreslen v opačném pořadí, prohoďte sloupce v pracovním listu a poté graf nakreslete znovu. Pokud nemáte možnost změnit pořadí zdrojových dat, můžete osy X a Y prohodit přímo v grafu.
Jak provádět regresi v aplikaci Excel pomocí vzorců
Aplikace Microsoft Excel má několik statistických funkcí, které vám pomohou provést lineární regresní analýzu, například LINEST, SLOPE, INTERCEPT a CORREL.
Funkce LINEST používá metodu regrese nejmenších čtverců k výpočtu přímky, která nejlépe vysvětluje vztah mezi vašimi proměnnými, a vrací pole popisující tuto přímku. Podrobné vysvětlení syntaxe funkce najdete v tomto tutoriálu. Prozatím pouze vytvoříme vzorec pro naši ukázkovou datovou sadu:
=LINEST(C2:C25, B2:B25)
Protože funkce LINEST vrací pole hodnot, musíte ji zadat jako vzorec pole. Vyberte dvě sousední buňky ve stejném řádku, v našem případě E2:F2, zadejte vzorec a dokončete jej stisknutím kláves Ctrl + Shift + Enter.
Vzorec vrací b koeficient (E1) a a konstanta (F1) pro již známou lineární regresní rovnici:
y = bx + a 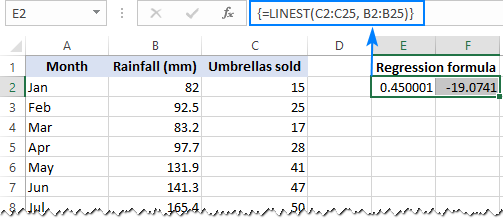
Pokud se v pracovních listech vyhnete používání vzorců pole, můžete vypočítat a a b jednotlivě s pravidelnými vzorci:
Získejte průsečík Y (a):
=INTERCEPT(C2:C25, B2:B25)
Získejte sklon (b):
=SLOPE(C2:C25, B2:B25)
Kromě toho můžete najít korelační koeficient ( Více R v souhrnném výstupu regresní analýzy), který udává, jak silně spolu obě proměnné souvisejí:
=CORREL(B2:B25,C2:C25)
Následující snímek obrazovky ukazuje všechny tyto regresní vzorce aplikace Excel v akci: 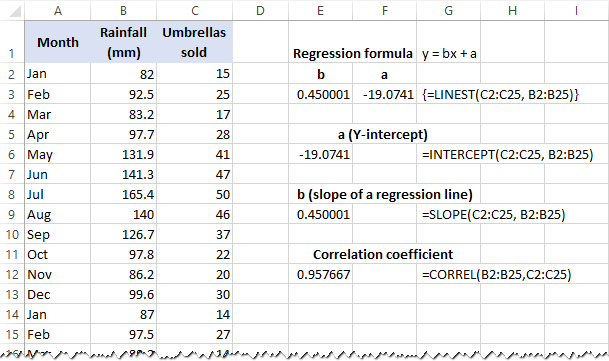
Tip: Pokud chcete získat další statistiky pro regresní analýzu, použijte funkci LINEST s příznakem s tetování nastaven na hodnotu TRUE, jak je uvedeno v tomto příkladu.
Takto se provádí lineární regrese v aplikaci Excel. Přesto mějte na paměti, že aplikace Microsoft Excel není statistický program. Pokud potřebujete provádět regresní analýzu na profesionální úrovni, můžete použít cílený software, jako je XLSTAT, RegressIt atd.
Chcete-li se blíže seznámit s našimi vzorci pro lineární regresi a dalšími technikami probíranými v tomto kurzu, můžete si stáhnout náš ukázkový sešit níže. Děkujeme za přečtení!
Cvičebnice
Regresní analýza v Excelu - příklady (.xlsx soubor)
