
Зміст
У навчальному посібнику пояснюються основи регресійного аналізу та показано декілька різних способів виконання лінійної регресії в Excel.
Уявіть собі: вам надали цілу купу різних даних і попросили спрогнозувати показники продажів вашої компанії на наступний рік. Ви виявили десятки, можливо, навіть сотні факторів, які можуть вплинути на цифри. Але як дізнатися, які з них дійсно важливі? Запустіть регресійний аналіз в Excel. Він дасть вам відповідь на це та багато інших питань: Які факториНаскільки тісно ці фактори пов'язані між собою? І наскільки можна бути впевненим у прогнозах?
Регресійний аналіз в Excel - основи
У статистичному моделюванні, регресійний аналіз використовується для оцінки взаємозв'язку між двома або більше змінними:
Залежна змінна (він же критерій змінна) є основним фактором, який ви намагаєтеся зрозуміти і передбачити.
Незалежні змінні (він же пояснювальна змінні, або предиктори ) - це фактори, які можуть впливати на залежну змінну.
Регресійний аналіз допомагає зрозуміти, як змінюється залежна змінна при зміні однієї з незалежних змінних, і дозволяє математично визначити, яка з цих змінних дійсно має вплив.
Технічно модель регресійного аналізу базується на сума квадратів який є математичним способом знаходження дисперсії точок даних. Мета моделі - отримати найменшу можливу суму квадратів і намалювати лінію, яка найближче підходить до даних.
У статистиці розрізняють просту та множинну лінійну регресію. Проста лінійна регресія моделює зв'язок між залежною змінною та однією незалежною змінною за допомогою лінійної функції. Якщо ви використовуєте дві або більше пояснювальних змінних для прогнозування залежної змінної, ви маєте справу з множинна лінійна регресія Якщо залежна змінна моделюється як нелінійна функція, оскільки зв'язок між даними не є прямою лінією, слід використовувати нелінійна регресія Натомість у цьому посібнику ми зосередимось на простій лінійній регресії.
Для прикладу візьмемо показники продажів парасольок за останні 24 місяці і дізнаємося середньомісячну кількість опадів за цей же період. Нанесіть цю інформацію на графік, і лінія регресії продемонструє зв'язок між незалежною змінною (кількістю опадів) і залежною змінною (обсягами продажів парасольок): 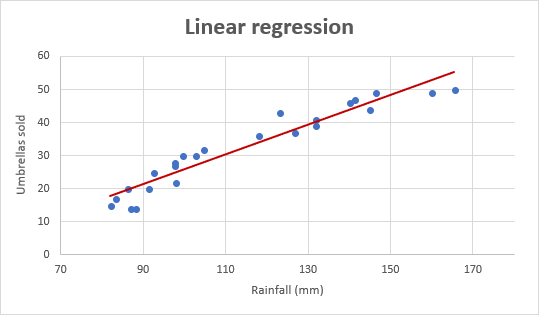
Рівняння лінійної регресії
Математично лінійна регресія визначається цим рівнянням:
y = bx + a + εДе:
- x є незалежною змінною.
- y залежна змінна.
- a це Y-перехоплення що є очікуваним середнім значенням y коли всі x На графіку регресії це точка перетину прямої з віссю Y.
- b - це нахил лінії регресії, яка є швидкістю зміни для y як x зміни.
- ε випадкова похибка, яка є різницею між фактичним значенням залежної змінної та її прогнозованим значенням.
Рівняння лінійної регресії завжди має похибку, оскільки в реальному житті предиктори ніколи не бувають ідеально точними. Однак, деякі програми, в тому числі Excel, виконують розрахунок похибки "за кадром". Отже, в Excel лінійна регресія виконується за допомогою функції найменших квадратів метод і коефіцієнти пошуку a і b що..:
y = bx + aДля нашого прикладу рівняння лінійної регресії має наступний вигляд:
Продано парасольок = b * кількість опадів + a
Існує кілька різних способів знайти a і b Існує три основні методи виконання лінійного регресійного аналізу в Excel:
- Інструмент регресії входить до складу Analysis ToolPak
- Діаграма розсіювання з лінією тренду
- Формула лінійної регресії
Нижче ви знайдете детальні інструкції щодо використання кожного з методів.
Як зробити лінійну регресію в Excel за допомогою Analysis ToolPak
У цьому прикладі показано, як запустити регресію в Excel за допомогою спеціального інструменту, що входить до складу надбудови Analysis ToolPak.
Увімкнути надбудову Analysis ToolPak
Analysis ToolPak доступний у всіх версіях Excel 365 до 2003, але за замовчуванням не ввімкнений. Отже, його потрібно ввімкнути вручну. Ось як це зробити:
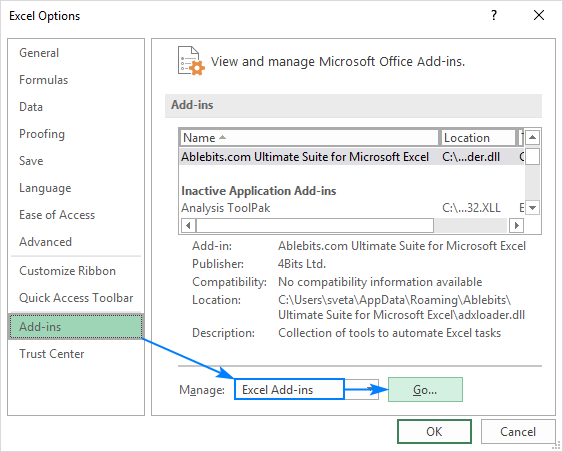
- У вашому Excel натисніть Файл > Опції .
- В рамках проекту Параметри Excel виберіть у діалоговому вікні Надбудови на лівій бічній панелі переконайтеся, що Надбудови для Excel обирається в розділі Керувати і натисніть кнопку Іди. .
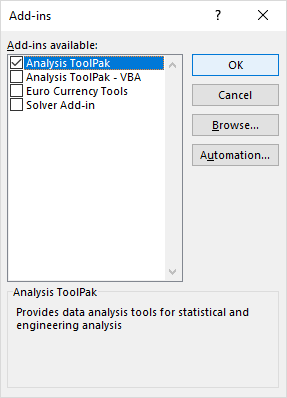
- В рамках проекту Надбудови діалогове вікно, поставте галочку Інструментарій для аналізу і натисніть ГАРАЗД. :
Це сприятиме збільшенню Аналіз даних інструментів до Дані стрічки Excel.
Запустити регресійний аналіз
У цьому прикладі ми зробимо просту лінійну регресію в Excel. У нас є список середньомісячної кількості опадів за останні 24 місяці в колонці B, яка є нашою незалежною змінною (предиктором), і кількість проданих парасольок в колонці C, яка є залежною змінною. Звичайно, є багато інших факторів, які можуть впливати на продажі, але поки що ми зосередимося тільки на цих двох змінних: 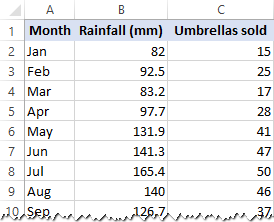
З увімкненим пакетом Analysis Toolpak, виконайте ці кроки для проведення регресійного аналізу в Excel:
- Про це йдеться на Дані у вкладці Аналіз у групі, натисніть на кнопку Аналіз даних кнопку.
- Виберіть Регресія і натисніть ГАРАЗД. .
- В рамках проекту Регресія налаштуйте наступні параметри:
- Виберіть пункт Діапазон введення Y який є вашим залежна змінна У нашому випадку це парасолькові продажі (С1:С25).
- Виберіть пункт Діапазон вхідного сигналу X тобто ваш незалежна змінна У цьому прикладі це середньомісячна кількість опадів (B1:B25).
Якщо ви будуєте модель множинної регресії, виберіть два або більше суміжних стовпчиків з різними незалежними змінними.
- Перевірте Коробка для етикеток якщо у верхній частині діапазонів X та Y є заголовки.
- Обирайте свій варіант Варіант виходу, новий аркуш у нашому випадку.
- За бажанням, виберіть опцію Залишки для отримання різниці між прогнозованим та фактичним значенням.
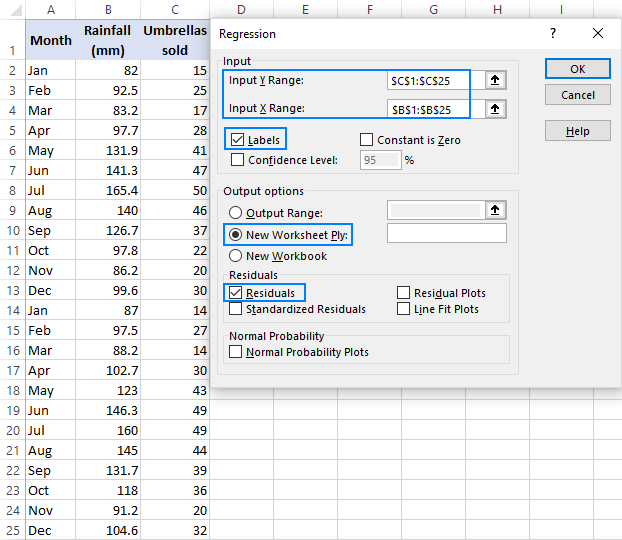
- Натисніть ГАРАЗД. та переглянути результати регресійного аналізу, створеного в Excel.
Інтерпретація результатів регресійного аналізу
Як ви щойно побачили, проводити регресію в Excel легко, оскільки всі розрахунки виконуються автоматично. Інтерпретація результатів є дещо складнішою, оскільки вам потрібно знати, що стоїть за кожним числом. Нижче ви знайдете розбивку на 4 основні частини результатів регресійного аналізу.
Результати регресійного аналізу: Підсумкові результати
Ця частина показує, наскільки добре розраховане рівняння лінійної регресії відповідає вашим вихідним даним. 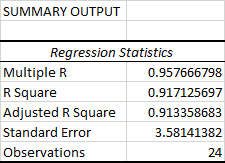
Ось що означає кожна інформація:
Кілька R Це - "С", а не "С", як раніше. Коефіцієнт кореляції коефіцієнт кореляції, який вимірює силу лінійного зв'язку між двома змінними. Коефіцієнт кореляції може мати будь-яке значення від -1 до 1, а його абсолютне значення вказує на силу зв'язку. Чим більше абсолютне значення, тим сильніший зв'язок:
- 1 - сильний позитивний зв'язок
- -1 означає сильний негативний зв'язок
- 0 - не має жодних стосунків
Квадрат R Це саме той випадок, коли Коефіцієнт детермінації який використовується як показник якості підгонки. Він показує, скільки точок потрапляє на лінію регресії. Значення R2 розраховується за загальною сумою квадратів, точніше, це сума квадратів відхилень вихідних даних від середнього значення.
У нашому прикладі R2 дорівнює 0,91 (округлено до 2 цифр), що дуже добре. Це означає, що 91% наших значень відповідають моделі регресійного аналізу. Іншими словами, 91% залежних змінних (y-значень) пояснюються незалежними змінними (x-значеннями). Як правило, R в квадраті 95% і більше вважається гарним узгодженням.
Скоригований R квадрат Це саме той випадок, коли R квадрат скориговане на кількість незалежних змінних у моделі. Ви хочете використовувати це значення замість R квадрат для множинного регресійного аналізу.
Стандартна помилка Це ще одна міра відповідності, яка показує точність вашого регресійного аналізу - чим менше число, тим більше ви можете бути впевнені у вашому рівнянні регресії. У той час як R2 представляє відсоток дисперсії залежних змінних, який пояснюється моделлю, стандартна помилка є абсолютною мірою, яка показує середню відстань, на яку потрапляють точки даних від рівняння регресії.Лінія.
Спостереження Це просто кількість спостережень у вашій моделі.
Результат регресійного аналізу: ANOVA
Друга частина результатів - дисперсійний аналіз (ANOVA): 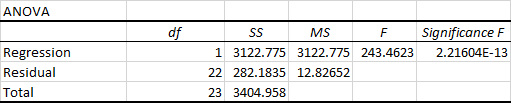
По суті, він розбиває суму квадратів на окремі компоненти, які дають інформацію про рівні варіабельності у вашій регресійній моделі:
- df кількість ступенів свободи, пов'язаних з джерелами дисперсії.
- СС Чим менша залишкова СК у порівнянні з загальною СК, тим краще ваша модель відповідає даним.
- РС середнє квадратичне.
- F F-статистика, або F-тест для нульової гіпотези, використовується для перевірки загальної значущості моделі.
- Значущість F P-значення F.
Частина ANOVA рідко використовується для простого лінійного регресійного аналізу в Excel, але на останню складову обов'язково варто звернути увагу. Значущість F дає уявлення про те, наскільки надійними (статистично значущими) є ваші результати. Якщо значення F менше 0,05 (5%), ваша модель є нормальною. Якщо воно більше 0,05, вам, ймовірно, краще вибрати іншу незалежну змінну.
Результати регресійного аналізу: коефіцієнти
Цей розділ містить конкретну інформацію про компоненти Вашого аналізу: 
Найбільш корисним компонентом у цьому розділі є Коефіцієнти Дозволяє побудувати рівняння лінійної регресії в Excel:
y = bx + aДля нашого набору даних, де y кількість проданих парасольок та x - середньомісячна кількість опадів, наша лінійна регресійна формула виглядає наступним чином:
Y = Коефіцієнт опадів * x + Перехоплення
Задавши значення a і b, округлені до трьох знаків після коми, вона перетворюється на:
Y=0,45*x-19,074
Наприклад, при середньомісячній кількості опадів 82 мм, продаж парасольок становитиме приблизно 17,8 одиниць:
0.45*82-19.074=17.8
Аналогічним чином можна дізнатися, скільки парасольок буде продано при будь-якій іншій місячній кількості опадів (змінна x), яку ви вкажете.
Результати регресійного аналізу: залишки
Якщо порівняти розрахункову та фактичну кількість проданих парасольок, що відповідає місячній нормі опадів 82 мм, то можна побачити, що ці цифри дещо відрізняються:
- За оцінкою: 17,8 (розраховано вище)
- Фактично: 15 (рядок 2 вихідних даних)
Чому така різниця? Тому що незалежні змінні ніколи не є ідеальними предикторами залежних змінних. А залишки можуть допомогти вам зрозуміти, наскільки далекі фактичні значення від прогнозованих значень: 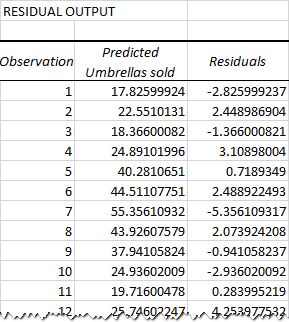
Для першої точки даних (кількість опадів 82 мм) залишок становить приблизно -2,8. Отже, додаємо це число до прогнозованого значення, і отримуємо фактичне значення: 17,8 - 2,8 = 15.
Як побудувати графік лінійної регресії в Excel
Якщо вам потрібно швидко візуалізувати залежність між двома змінними, побудуйте графік лінійної регресії. Це дуже просто! Ось як:
- Виберіть дві колонки з вашими даними, включаючи заголовки.
- Про це йдеться на Вставка у вкладці Чати у групі, натисніть на кнопку Діаграма розсіювання та виберіть піктограму Розкид мініатюра (перша):
Це призведе до вставки діаграми розсіювання на вашому робочому аркуші, яка буде схожа на цю діаграму:
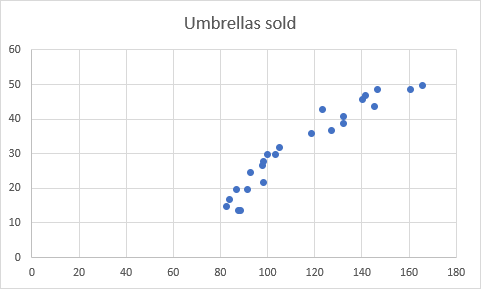
- Тепер нам потрібно побудувати лінію регресії методом найменших квадратів. Для цього клацніть правою кнопкою миші на будь-якій точці і виберіть Додати Trendline... з контекстного меню.
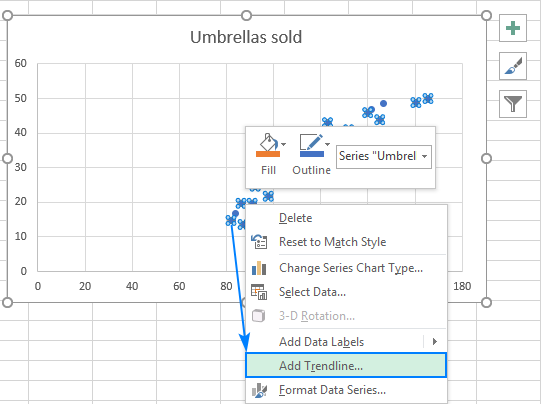
- На правій панелі виберіть пункт Лінійний форма лінії тренду та, за бажанням, галочка Відобразити рівняння на графіку щоб отримати формулу регресії:
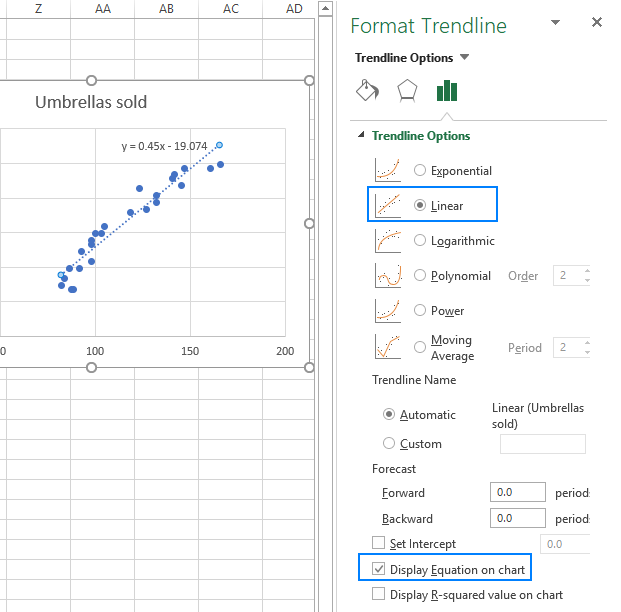
Як можна помітити, рівняння регресії, яке створив для нас Excel, збігається з формулою лінійної регресії, яку ми побудували на основі вихідних даних Коефіцієнти.
- Перейдіть на сторінку Заповнити & рядок і налаштуйте лінію на свій смак. Наприклад, ви можете вибрати інший колір лінії та використовувати суцільну лінію замість пунктирної (виберіть Суцільна лінія у вкладці Тип тире коробка):
На цьому етапі ваш графік вже виглядає як пристойний графік регресії: 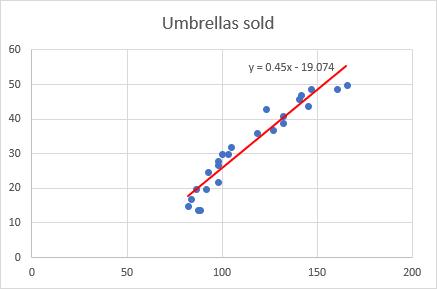
Проте, можливо, ви захочете зробити ще кілька поліпшень:
- Перетягніть рівняння туди, куди вважаєте за потрібне.
- Додати назви осей ( Елементи діаграми кнопку>; Назви осей ).
- Якщо ваші точки даних починаються посередині горизонтальної та/або вертикальної осі, як у цьому прикладі, можливо, ви захочете позбутися надмірного білого простору. Наступна порада пояснює, як це зробити: Масштабуйте осі діаграми, щоб зменшити білий простір.
А ось так виглядає наш покращений графік регресії:
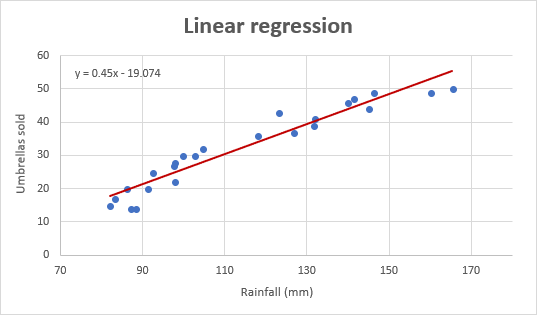
На графіку регресії незалежна змінна завжди повинна знаходитися на осі Х, а залежна - на осі Y. Якщо графік побудований у зворотному порядку, поміняйте місцями стовпчики на робочому аркуші, а потім намалюйте графік заново. Якщо вам не дозволено переставляти вихідні дані, то ви можете поміняти місцями осі Х і Y безпосередньо на графіку.
Як зробити регресію в Excel за допомогою формул
Microsoft Excel має декілька статистичних функцій, які можуть допомогти вам у проведенні лінійного регресійного аналізу, таких як ЛИНЕЙН, СЛОЙ, ІНТЕРЦЕПТ та КОРЕЛЯЦІЯ.
Функція LINEST використовує метод найменших квадратів для обчислення прямої лінії, яка найкраще пояснює зв'язок між вашими змінними, і повертає масив, що описує цю лінію. Детальне пояснення синтаксису функції можна знайти в цьому підручнику. А поки що давайте просто складемо формулу для нашого прикладу набору даних:
=LINEST(C2:C25, B2:B25)
Оскільки функція ЛИНЕЙНСТ повертає масив значень, то вводити її потрібно як формулу масиву. Виділіть дві сусідні комірки в одному рядку, в нашому випадку E2:F2, введіть формулу і натисніть Ctrl + Shift + Enter, щоб завершити її введення.
Формула повертає значення b коефіцієнт (Е1) та a константа (F1) для вже знайомого рівняння лінійної регресії:
y = bx + a 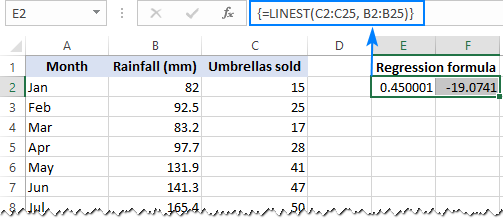
Якщо не використовувати формули масивів у робочих аркушах, то можна обчислити a і b індивідуально зі звичайними формулами:
Отримайте Y-перехоплення (a):
=INTERCEPT(C2:C25, B2:B25)
Отримайте нахил (b):
=SLOPE(C2:C25, B2:B25)
Крім того, ви можете ознайомитися з коефіцієнт кореляції ( Кілька R у підсумковому виводі регресійного аналізу), який показує, наскільки сильно дві змінні пов'язані між собою:
=CORREL(B2:B25,C2:C25)
На наступному скріншоті показані всі ці формули регресії в Excel в дії: 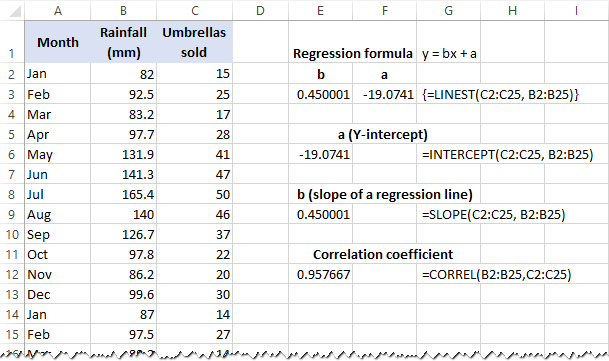
Порада: якщо ви хочете отримати додаткову статистику для регресійного аналізу, скористайтеся функцією ЛИНЕЙН з параметром s татуювання встановлюється в значення TRUE, як показано в цьому прикладі.
Ось так виконується лінійна регресія в Excel. При цьому слід пам'ятати, що Microsoft Excel не є статистичною програмою. Якщо вам потрібно виконати регресійний аналіз на професійному рівні, ви можете скористатися спеціалізованим програмним забезпеченням, таким як XLSTAT, RegressIt тощо.
Для більш детального ознайомлення з формулами лінійної регресії та іншими методами, що розглядаються в цьому посібнику, ви можете завантажити наш зразок робочого зошита нижче. Дякуємо за прочитання!
Практичний посібник
Регресійний аналіз в Excel - приклади (файл .xlsx)
