
Оглавление
В учебном пособии объясняются основы регрессионного анализа и показано несколько различных способов выполнения линейной регрессии в Excel.
Представьте себе следующее: вам предоставили множество различных данных и попросили спрогнозировать показатели продаж вашей компании в следующем году. Вы обнаружили десятки, возможно, даже сотни факторов, которые могут повлиять на показатели. Но как узнать, какие из них действительно важны? Запустите регрессионный анализ в Excel. Он даст вам ответ на этот и многие другие вопросы: какие факторыНасколько тесно эти факторы связаны друг с другом? И насколько вы можете быть уверены в прогнозах?
Регрессионный анализ в Excel - основы
В статистическом моделировании, регрессионный анализ используется для оценки взаимосвязей между двумя или более переменными:
Зависимая переменная (aka критерий переменная) - это основной фактор, который вы пытаетесь понять и предсказать.
Независимые переменные (aka пояснительная переменные, или предикторы ) - это факторы, которые могут повлиять на зависимую переменную.
Регрессионный анализ помогает понять, как изменяется зависимая переменная при изменении одной из независимых переменных, и позволяет математически определить, какая из этих переменных действительно оказывает влияние.
Технически, модель регрессионного анализа основана на сумма квадратов Цель модели - получить наименьшую возможную сумму квадратов и провести линию, наиболее близко подходящую к данным.
В статистике различают простую и множественную линейную регрессию. Простая линейная регрессия моделирует связь между зависимой переменной и одной независимой переменной с помощью линейной функции. Если вы используете две или более объясняющих переменных для прогнозирования зависимой переменной, вы имеете дело с множественная линейная регрессия Если зависимая переменная моделируется как нелинейная функция, потому что зависимости данных не следуют прямой линии, используйте нелинейная регрессия вместо этого. Основное внимание в этом учебнике будет уделено простой линейной регрессии.
В качестве примера возьмем данные о продажах зонтов за последние 24 месяца и выясним среднемесячное количество осадков за тот же период. Нанесите эту информацию на график, и линия регрессии продемонстрирует связь между независимой переменной (количество осадков) и зависимой переменной (продажи зонтов): 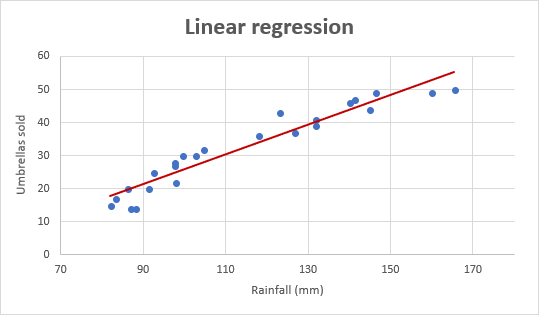
Уравнение линейной регрессии
Математически линейная регрессия определяется этим уравнением:
Где:
- x является независимой переменной.
- y является зависимой переменной.
- a это Y-интерцепт что является ожидаемым средним значением y когда все x переменные равны 0. На графике регрессии это точка, где линия пересекает ось Y.
- b - это наклон линии регрессии, которая является скоростью изменения для y в качестве x изменения.
- ε случайный член ошибки, который представляет собой разницу между фактическим значением зависимой переменной и ее прогнозируемым значением.
Уравнение линейной регрессии всегда содержит член ошибки, поскольку в реальной жизни предсказатели никогда не бывают идеально точными. Однако некоторые программы, включая Excel, выполняют расчет члена ошибки за кадром. Так, в Excel вы выполняете линейную регрессию с помощью функции наименьшие квадраты метод и искать коэффициенты a и b такой, что:
y = bx + aДля нашего примера уравнение линейной регрессии имеет следующий вид:
Проданные зонтики = b * количество осадков + a
Существует несколько различных способов найти a и b Три основных метода проведения линейного регрессионного анализа в Excel:
- Инструмент регрессии, включенный в пакет Analysis ToolPak
- Диаграмма разброса с линией тренда
- Формула линейной регрессии
Ниже приведены подробные инструкции по использованию каждого метода.
Как выполнить линейную регрессию в Excel с помощью Analysis ToolPak
В этом примере показано, как запустить регрессию в Excel с помощью специального инструмента, входящего в состав надстройки Analysis ToolPak.
Включите надстройку Analysis ToolPak
Analysis ToolPak доступен во всех версиях Excel 365 до 2003, но по умолчанию он не включен. Поэтому его нужно включить вручную. Вот как это сделать:
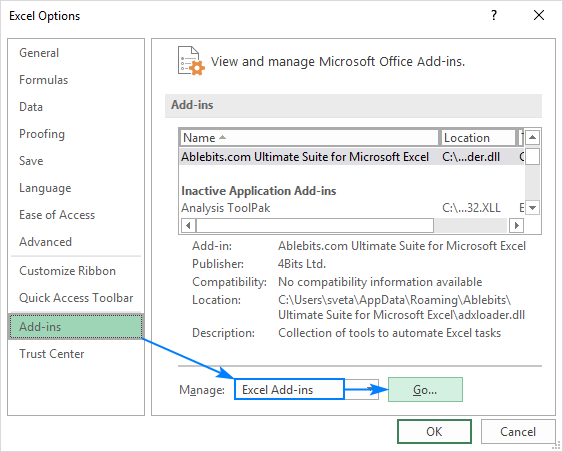
- В Excel нажмите кнопку Файл > Опции .
- В Параметры Excel в диалоговом окне выберите Дополнения на левой боковой панели, убедитесь, что Надстройки Excel выбран в Управляйте и нажмите кнопку Перейти .
- В Дополнения диалогового окна, поставьте галочку Пакет инструментов для анализа , и нажмите OK :
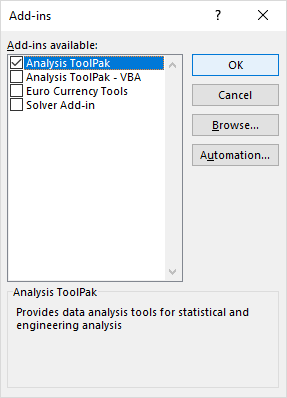
Это добавит Анализ данных инструменты для Данные на вкладке ленты Excel.
Провести регрессионный анализ
В этом примере мы собираемся провести простую линейную регрессию в Excel. У нас есть список среднемесячных осадков за последние 24 месяца в столбце B, который является нашей независимой переменной (предиктором), и количество проданных зонтов в столбце C, который является зависимой переменной. Конечно, существует множество других факторов, которые могут повлиять на продажи, но пока мы сосредоточимся только на этих двух переменных: 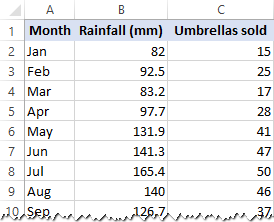
При включенном Analysis Toolpak, выполните следующие шаги для проведения регрессионного анализа в Excel:
- На Данные во вкладке Анализ группу, нажмите кнопку Анализ данных кнопка.
- Выберите Регрессия и нажмите OK .
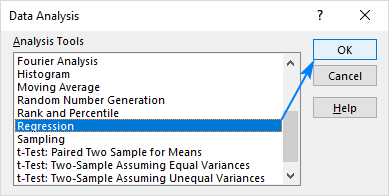
- В Регрессия диалоговое окно, настройте следующие параметры:
- Выберите Входной диапазон Y , который является вашим зависимая переменная В нашем случае это продажа зонтиков (C1:C25).
- Выберите Вход X Диапазон , т.е. ваш независимая переменная В данном примере это среднемесячное количество осадков (B1:B25).
Если вы строите модель множественной регрессии, выберите два или более соседних столбца с разными независимыми переменными.
- Проверьте Коробка с этикетками если есть заголовки в верхней части диапазонов X и Y.
- Выберите предпочтительный Возможность вывода, в нашем случае - новый рабочий лист.
- По желанию выберите Остатки флажок, чтобы получить разницу между прогнозируемым и фактическим значениями.
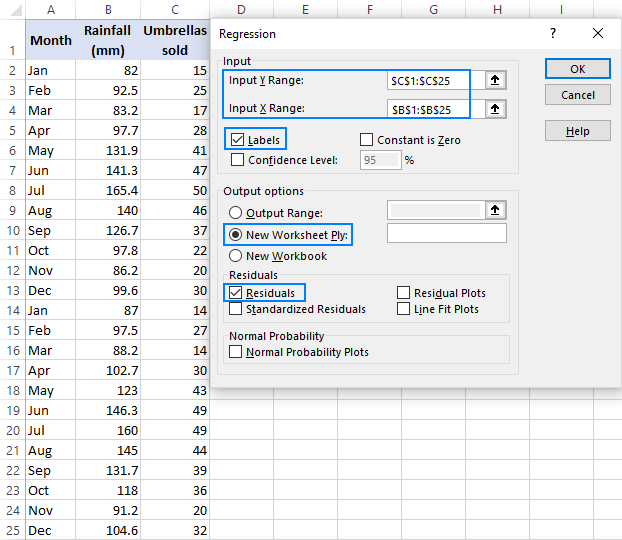
- Нажмите OK и проследите за выводом регрессионного анализа, созданного Excel.
Интерпретировать результаты регрессионного анализа
Как вы только что убедились, запустить регрессию в Excel очень просто, поскольку все вычисления выполняются автоматически. Интерпретация результатов немного сложнее, поскольку вам нужно знать, что стоит за каждым числом. Ниже вы найдете разбивку 4 основных частей результатов регрессионного анализа.
Выходные данные регрессионного анализа: Сводный выход
Эта часть говорит о том, насколько хорошо рассчитанное уравнение линейной регрессии соответствует вашим исходным данным. 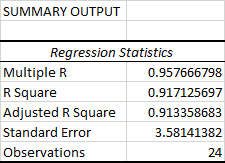
Вот что означает каждая часть информации:
Множественные R Это С Коэффициент корреляции Коэффициент корреляции может иметь любое значение от -1 до 1, а его абсолютное значение указывает на силу связи. Чем больше абсолютное значение, тем сильнее связь:
- 1 означает сильную положительную связь
- -1 означает сильную отрицательную связь
- 0 означает полное отсутствие отношений
R-квадрат . Это Коэффициент детерминации R2 рассчитывается из общей суммы квадратов, точнее, это сумма квадратов отклонений исходных данных от среднего значения.
В нашем примере R2 равен 0,91 (округлим до двузначного числа), что является хорошим показателем. Это означает, что 91% наших значений соответствуют модели регрессионного анализа. Другими словами, 91% зависимых переменных (значения y) объясняются независимыми переменными (значениями x). Обычно хорошим показателем считается R Squared, равный 95% или более.
Скорректированный квадрат R . Это Площадь с поправкой на количество независимых переменных в модели. Вы захотите использовать это значение вместо Площадь для множественного регрессионного анализа.
Стандартная ошибка Это еще одна мера хорошего соответствия, которая показывает точность регрессионного анализа - чем меньше число, тем больше уверенности в уравнении регрессии. В то время как R2 представляет собой процент дисперсии зависимых переменных, которая объясняется моделью, стандартная ошибка - это абсолютная мера, которая показывает среднее расстояние, на котором точки данных отклоняются от регрессии.линия.
Наблюдения Это просто количество наблюдений в вашей модели.
Выход регрессионного анализа: ANOVA
Вторая часть вывода - дисперсионный анализ (ANOVA): 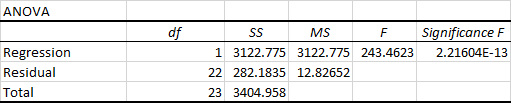
По сути, он разделяет сумму квадратов на отдельные компоненты, которые дают информацию об уровнях изменчивости в вашей регрессионной модели:
- df число степеней свободы, связанных с источниками дисперсии.
- SS Чем меньше остаточный SS по сравнению с общим SS, тем лучше ваша модель соответствует данным.
- MS средний квадрат.
- F F-статистика, или F-тест для нулевой гипотезы. Используется для проверки общей значимости модели.
- Значимость F P-значение F.
Часть ANOVA редко используется для простого линейного регрессионного анализа в Excel, но вы обязательно должны внимательно изучить последний компонент. The Значимость F дает представление о том, насколько надежны (статистически значимы) ваши результаты. Если значение Significance F меньше 0,05 (5%), ваша модель в порядке. Если оно больше 0,05, вам, вероятно, лучше выбрать другую независимую переменную.
Результаты регрессионного анализа: коэффициенты
В этом разделе представлена конкретная информация о компонентах вашего анализа: 
Наиболее полезным компонентом в этом разделе является Коэффициенты Она позволяет построить уравнение линейной регрессии в Excel:
y = bx + aДля нашего набора данных, где y это количество проданных зонтиков, а x - среднемесячное количество осадков, наша формула линейной регрессии выглядит следующим образом:
Y = Коэффициент осадков * x + Перехват
При использовании значений a и b, округленных до трех знаков после запятой, получается:
Y=0.45*x-19.074
Например, при среднемесячном количестве осадков, равном 82 мм, объем продаж зонтов составит приблизительно 17,8:
0.45*82-19.074=17.8
Аналогичным образом можно узнать, сколько зонтиков будет продано при любом другом заданном вами месячном количестве осадков (переменная x).
Выходные данные регрессионного анализа: остатки
Если сравнить расчетное и фактическое количество проданных зонтов, соответствующее месячному количеству осадков в 82 мм, то можно увидеть, что эти цифры немного отличаются:
- Предполагаемый: 17,8 (рассчитано выше)
- Фактически: 15 (строка 2 исходных данных)
Почему разница? Потому что независимые переменные никогда не являются идеальными предсказателями зависимых переменных. А остатки могут помочь вам понять, насколько далеки фактические значения от предсказанных: 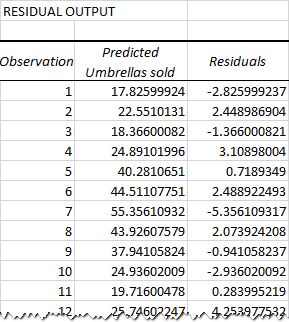
Для первой точки данных (количество осадков 82 мм) остаток составляет примерно -2,8. Прибавляем это число к предсказанному значению и получаем фактическое значение: 17,8 - 2,8 = 15.
Как построить график линейной регрессии в Excel
Если вам нужно быстро визуализировать связь между двумя переменными, постройте график линейной регрессии. Это очень просто! Вот как:
- Выберите два столбца с данными, включая заголовки.
- На Вставка во вкладке Чаты группу, нажмите кнопку Диаграмма рассеяния значок и выберите Разброс миниатюра (первая):
Это позволит вставить в рабочий лист диаграмму рассеяния, которая будет похожа на эту:
- Теперь нам нужно построить линию регрессии наименьших квадратов. Чтобы сделать это, щелкните правой кнопкой мыши на любой точке и выберите Добавить линию тренда... из контекстного меню.
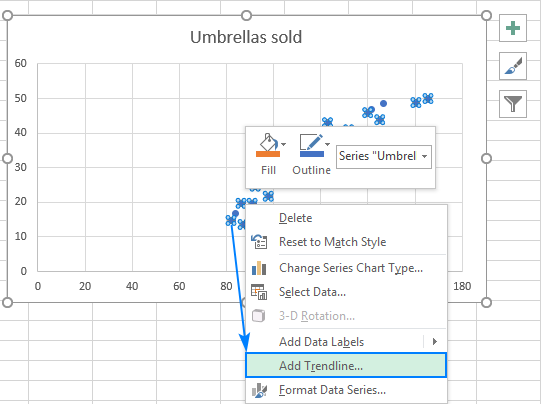
- На правой панели выберите Линейный форму линии тренда и, по желанию, проверить Отображение уравнения на графике чтобы получить формулу регрессии:
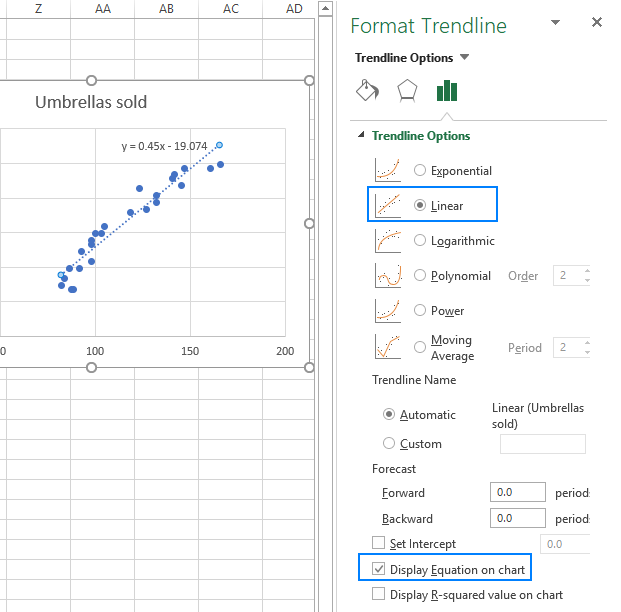
Как вы можете заметить, уравнение регрессии, которое Excel создал для нас, совпадает с формулой линейной регрессии, которую мы построили на основе вывода Coefficients.
- Переключитесь на Заполнение & линия и настройте линию по своему вкусу. Например, вы можете выбрать другой цвет линии и использовать сплошную линию вместо пунктирной (выберите Сплошная линия в меню Тип тире коробка):
На данном этапе ваш график уже выглядит как приличный график регрессии: 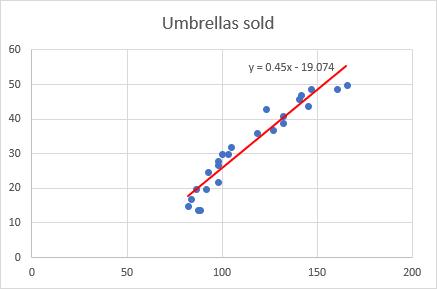
Тем не менее, вы можете захотеть сделать еще несколько улучшений:
- Перетащите уравнение туда, куда считаете нужным.
- Добавьте заголовки осей ( Элементы диаграммы кнопка> Осевые титулы ).
- Если точки данных начинаются в середине горизонтальной и/или вертикальной оси, как в данном примере, возможно, вам захочется избавиться от лишнего белого пространства. Следующий совет объясняет, как это сделать: масштабируйте оси графика, чтобы уменьшить белое пространство.
А вот так выглядит наш улучшенный график регрессии:
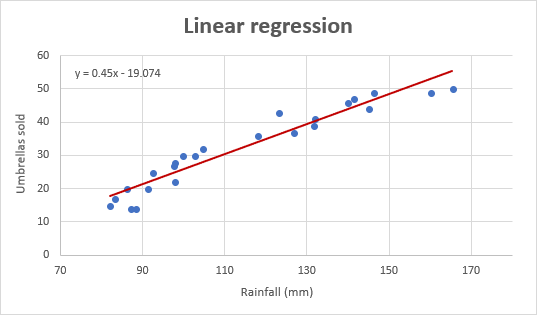
Важное замечание! На графике регрессии независимая переменная всегда должна находиться на оси X, а зависимая - на оси Y. Если ваш график построен в обратном порядке, поменяйте местами столбцы в рабочем листе, а затем постройте график заново. Если вам не разрешено переставлять исходные данные, то вы можете поменять местами оси X и Y непосредственно на графике.
Как сделать регрессию в Excel с помощью формул
В Microsoft Excel есть несколько статистических функций, которые могут помочь вам провести линейный регрессионный анализ, например, LINEST, SLOPE, INTERCEPT и CORREL.
Функция LINEST использует метод регрессии наименьших квадратов для вычисления прямой линии, которая наилучшим образом объясняет связь между вашими переменными, и возвращает массив, описывающий эту линию. Подробное объяснение синтаксиса функции вы можете найти в этом учебнике. Пока давайте просто составим формулу для нашего набора данных:
=LINEST(C2:C25, B2:B25)
Поскольку функция LINEST возвращает массив значений, вы должны ввести ее как формулу массива. Выделите две соседние ячейки в одной строке, E2:F2 в нашем случае, введите формулу и нажмите Ctrl + Shift + Enter, чтобы завершить ее.
Формула возвращает b коэффициент (E1) и a константа (F1) для уже знакомого уравнения линейной регрессии:
y = bx + a 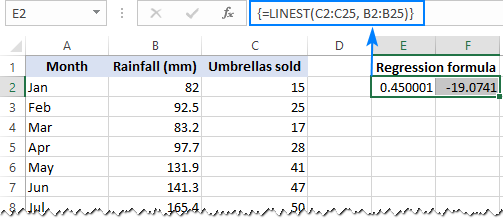
Если вы избегаете использования формул массивов в своих рабочих листах, вы можете вычислить a и b индивидуально с помощью обычных формул:
Получите Y-интерцепт (a):
=INTERCEPT(C2:C25, B2:B25)
Получите наклон (b):
=SLOPE(C2:C25, B2:B25)
Кроме того, вы можете найти коэффициент корреляции ( Множественные R в итоговом выводе регрессионного анализа), который показывает, насколько сильно две переменные связаны друг с другом:
=CORREL(B2:B25,C2:C25)
На следующем снимке экрана показаны все эти формулы регрессии Excel в действии: 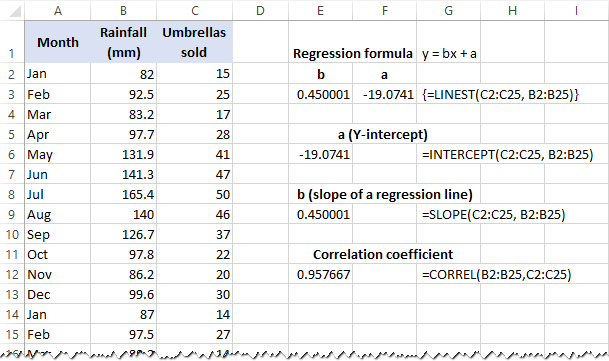
Совет. Если вы хотите получить дополнительную статистику для регрессионного анализа, используйте функцию LINEST с параметром s татуировки параметр установлен в TRUE, как показано в этом примере.
Вот как выполняется линейная регрессия в Excel. При этом следует помнить, что Microsoft Excel не является статистической программой. Если вам необходимо выполнить регрессионный анализ на профессиональном уровне, вам может понадобиться целевое программное обеспечение, такое как XLSTAT, RegressIt и т.д.
Чтобы более подробно ознакомиться с формулами линейной регрессии и другими методами, рассмотренными в этом учебнике, вы можете скачать наш образец рабочей тетради ниже. Спасибо за чтение!
Практическая тетрадь
Регрессионный анализ в Excel - примеры (файл.xlsx)
