
INHOUDSOPGAWE
Die tutoriaal verduidelik die basiese beginsels van regressie-analise en wys 'n paar verskillende maniere om lineêre regressie in Excel te doen.
Stel jou dit voor: jy word voorsien van 'n hele klomp verskillende data en word gevra om volgende jaar se verkoopsgetalle vir jou maatskappy te voorspel. Jy het tientalle, miskien selfs honderde, faktore ontdek wat moontlik die getalle kan beïnvloed. Maar hoe weet jy watter een regtig belangrik is? Voer regressie-analise in Excel uit. Dit sal jou 'n antwoord op hierdie en vele meer vrae gee: Watter faktore maak saak en watter kan geïgnoreer word? Hoe nou is hierdie faktore verwant aan mekaar? En hoe seker kan jy wees oor die voorspellings?
Regressie-analise in Excel - die basiese beginsels
In statistiese modellering word regressie-analise gebruik om skat die verwantskappe tussen twee of meer veranderlikes:
Afhanklike veranderlike (aka kriterium veranderlike) is die hooffaktor wat jy probeer verstaan en voorspel.
Onafhanklike veranderlikes (ook bekend as verklarende veranderlikes, of voorspellers ) is die faktore wat die afhanklike veranderlike kan beïnvloed.
Regressie-analise help jou verstaan hoe die afhanklike veranderlike verander wanneer een van die onafhanklike veranderlikes varieer en laat toe om wiskundig te bepaal watter van daardie veranderlikes werklik 'n impak het.
Tegies gesproke is 'n regressie-analise-model gebaseer op die som van 
Op hierdie stadium lyk jou grafiek reeds soos 'n ordentlike regressiegrafiek: 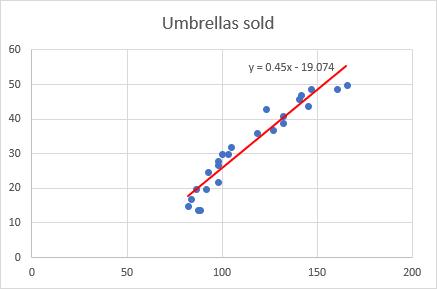
Tog wil jy dalk nog 'n paar verbeterings aanbring:
- Sleep die vergelyking waar jy ook al goeddink.
- Voeg assetitels by ( Kaartelemente -knoppie > Astitels ).
- As jou datapunte begin in die middel van die horisontale en/of vertikale as soos in hierdie voorbeeld, jy wil dalk van die oormatige wit spasie ontslae raak. Die volgende wenk verduidelik hoe om dit te doen: Skaal die grafiek-asse om wit spasie te verminder.
En dit is hoe ons verbeterde regressiegrafiek lyk:
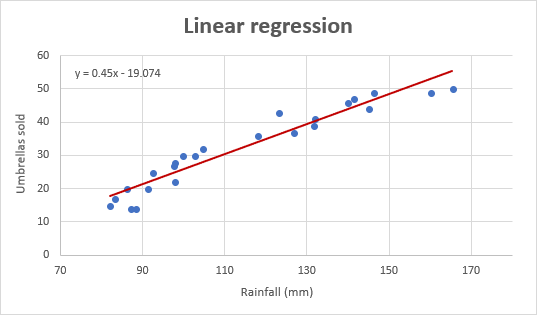
Belangrike nota! In die regressiegrafiek moet die onafhanklike veranderlike altyd op die X-as wees en die afhanklike veranderlike op die Y-as. As jou grafiek in die omgekeerde volgorde geplot is, ruil die kolomme in jou werkblad om en teken dan die grafiek opnuut. As jy nie toegelaat word om die brondata te herrangskik nie, kan jy die X- en Y-asse direk in 'n grafiek verander.
Hoe om regressie in Excel te doen deur formules te gebruik
Microsoft Excel het 'n paar statistiese funksies wat jou kan help om lineêre regressie-analise te doen, soos LINEST, SLOPE, INTERCEPT en CORREL.
Die LINEST-funksie gebruik die kleinste-kwadrate-regressiemetode om 'n reguit te bereken lyn wat die verband tussen jou veranderlikes die beste verduidelik en 'n skikking gee wat daardie lyn beskryf. Jy kan die gedetailleerde verduideliking van vinddie funksie se sintaksis in hierdie handleiding. Kom ons maak vir eers 'n formule vir ons voorbeelddatastel:
=LINEST(C2:C25, B2:B25)
Omdat die LINEST-funksie 'n reeks waardes terugstuur, moet jy dit as 'n skikkingsformule invoer. Kies twee aangrensende selle in dieselfde ry, E2:F2 in ons geval, tik die formule in en druk Ctrl + Shift + Enter om dit te voltooi.
Die formule gee die b -koëffisiënt ( E1) en die a konstante (F1) vir die reeds bekende lineêre regressievergelyking:
y = bx + a 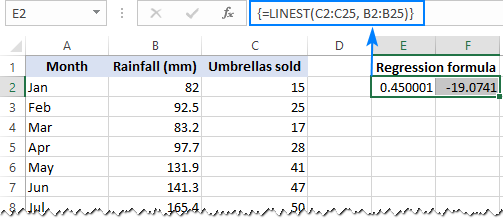
As jy vermy om skikkingsformules in jou werkblaaie te gebruik, kan jy
Kry die Y-afsnit (a):
=INTERCEPT(C2:C25, B2:B25)
Kry die helling (b):
=SLOPE(C2:C25, B2:B25)
Boonop kan jy die korrelasiekoëffisiënt ( Multiple R in die regressie-analise opsommingsuitset) vind wat aandui hoe Die twee veranderlikes is sterk verwant aan mekaar:
=CORREL(B2:B25,C2:C25)
Die volgende skermkiekie wys al hierdie Excel-regressieformules in aksie: 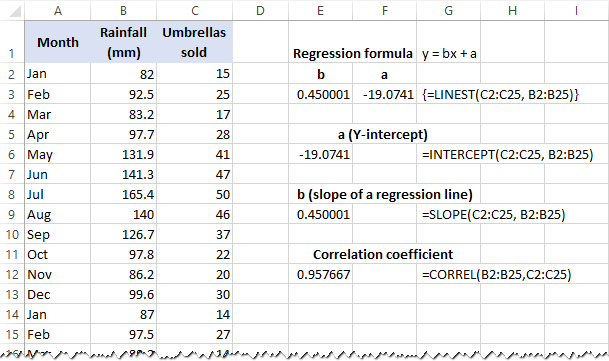
Wenk. As jy bykomende statistieke vir jou regressie-analise wil kry, gebruik die LINEST-funksie met die s tats -parameter op WAAR gestel soos in hierdie voorbeeld getoon.
Dit is hoe jy lineêre regressie doen in Excel. Dit gesê, hou asseblief in gedagte dat Microsoft Excel nie 'n statistiese program is nie. As jy regressie-analise op professionele vlak moet uitvoer, wil jy dalk geteikende gebruiksagteware soos XLSTAT, RegressIt, ens.
Om ons lineêre regressieformules en ander tegnieke wat in hierdie tutoriaal bespreek word van nader te bekyk, is jy welkom om ons voorbeeldwerkboek hieronder af te laai. Dankie dat jy gelees het!
Oefenwerkboek
Regressie-analise in Excel - voorbeelde (.xlsx-lêer)
vierkante, wat 'n wiskundige manier is om die verspreiding van datapunte te vind. Die doel van 'n model is om die kleinste moontlike som van vierkante te kry en 'n lyn te trek wat die naaste aan die data kom.In statistiek onderskei hulle tussen 'n eenvoudige en meervoudige lineêre regressie. Eenvoudige lineêre regressie modelleer die verwantskap tussen 'n afhanklike veranderlike en een onafhanklike veranderlike deur 'n lineêre funksie te gebruik. As jy twee of meer verduidelikende veranderlikes gebruik om die afhanklike veranderlike te voorspel, hanteer jy meervoudige lineêre regressie . As die afhanklike veranderlike as 'n nie-lineêre funksie gemodelleer word omdat die dataverwantskappe nie 'n reguit lyn volg nie, gebruik eerder nie-lineêre regressie . Die fokus van hierdie tutoriaal sal op 'n eenvoudige lineêre regressie wees.
Kom ons neem as voorbeeld verkoopsgetalle vir sambrele vir die afgelope 24 maande en vind die gemiddelde maandelikse reënval vir dieselfde tydperk uit. Stip hierdie inligting op 'n grafiek, en die regressielyn sal die verband tussen die onafhanklike veranderlike (reënval) en afhanklike veranderlike (sambreelverkope) demonstreer: 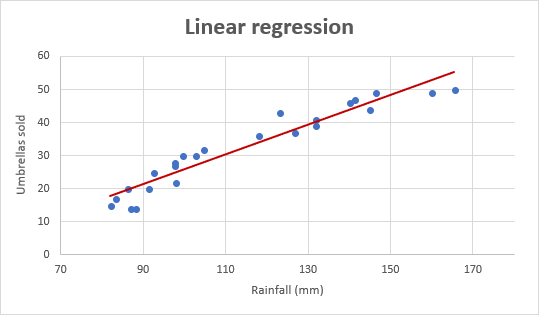
Lineêre regressievergelyking
Wiskundig, 'n lineêre regressie word deur hierdie vergelyking gedefinieer:
y = bx + a + εWaar:
- x 'n onafhanklike veranderlike is.
- y is 'n afhanklike veranderlike.
- a is die Y-afsnit , wat die verwagte gemiddelde waarde van y wanneer alle x veranderlikes gelyk is aan 0. Op 'n regressiegrafiek is dit die punt waar die lyn die Y-as kruis.
- b is die helling van 'n regressielyn, wat die tempo van verandering vir y is soos x verander.
- ε is die ewekansige fout term, wat die verskil is tussen die werklike waarde van 'n afhanklike veranderlike en sy voorspelde waarde.
Die lineêre regressievergelyking het altyd 'n foutterm omdat voorspellers in die werklike lewe nooit perfek presies is nie. Sommige programme, insluitend Excel, doen egter die fouttermberekening agter die skerms. Dus, in Excel, doen jy lineêre regressie deur die kleinste vierkante -metode te gebruik en soek koëffisiënte a en b sodat:
y = bx + aVir ons voorbeeld neem die lineêre regressievergelyking die volgende vorm aan:
Umbrellas sold = b * rainfall + a
Daar bestaan 'n handvol verskillende maniere om a en b
- Regressie-instrument ingesluit by Analysis ToolPak
- Verspreidingsgrafiek met 'n tendenslyn
- Lineêre regressieformule
Hieronder vind jy die gedetailleerde instruksies oor die gebruik van elke metode.
Hoe om lineêre regressie in Excel te doen met Analysis ToolPak
Hierdie voorbeeld wys hoe om regressie in Excel uit te voer deur 'n spesiale hulpmiddel te gebruik wat by die Analysis ToolPak-byvoeging ingesluit is.
Aktiveer die Analysis ToolPak-byvoeging-in
Analysis ToolPak is beskikbaar in alle weergawes van Excel 365 tot 2003, maar is nie by verstek geaktiveer nie. So, jy moet dit handmatig aanskakel. Hier is hoe:
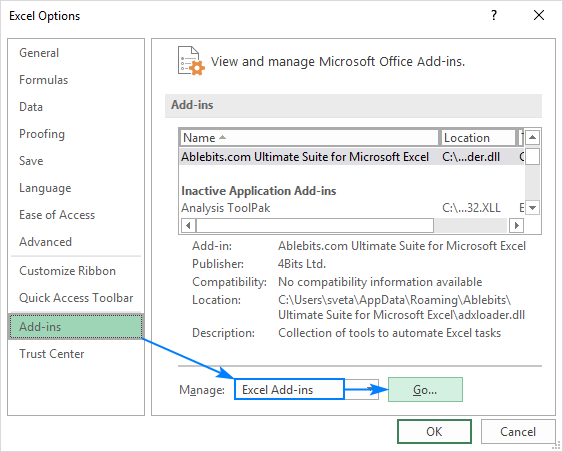
- Klik in jou Excel Lêer > Opsies .
- In die Excel-opsies dialoogkassie, kies Byvoegings op die linkerkantbalk, maak seker dat Excel-byvoegings gekies is in die boks Bestuur en klik Gaan .
- In die Byvoegings dialoogkassie, merk Analise Toolpak af en klik OK :
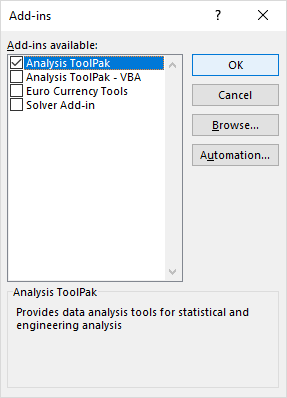
Dit sal die Data-analise -nutsgoed by die Data -oortjie van jou Excel-lint voeg.
Laat regressie-analise uit
In hierdie voorbeeld gaan ons 'n eenvoudige lineêre regressie in Excel doen. Wat ons het, is 'n lys van gemiddelde maandelikse reënval vir die afgelope 24 maande in kolom B, wat ons onafhanklike veranderlike (voorspeller) is, en die aantal sambrele wat in kolom C verkoop word, wat die afhanklike veranderlike is. Natuurlik is daar baie ander faktore wat verkope kan beïnvloed, maar vir nou fokus ons net op hierdie twee veranderlikes: 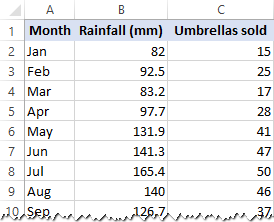
Met Analysis Toolpak bygevoeg geaktiveer, voer hierdie stappe uit om regressie-analise in Excel uit te voer:
- Op die Data -oortjie, in die Analise -groep, klik die Data-analise -knoppie.
- Kies Regressie en klik OK .
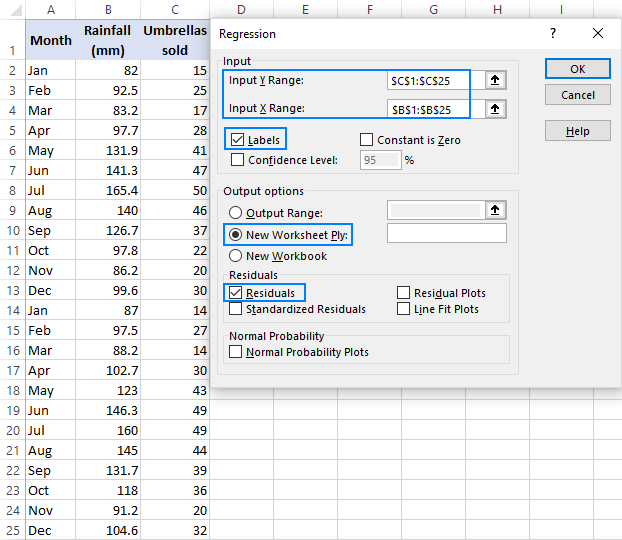
- In die Regressie dialoogkassie, stel die volgende instellings op:
- Kies die InvoerY Range , wat jou afhanklike veranderlike is. In ons geval is dit sambreelverkope (C1:C25).
- Kies die Invoer X-reeks , dit wil sê jou onafhanklike veranderlike . In hierdie voorbeeld is dit die gemiddelde maandelikse reënval (B1:B25).
As jy 'n meervoudige regressiemodel bou, kies twee of meer aangrensende kolomme met verskillende onafhanklike veranderlikes.
- Kyk die Etikette-blokkie as daar opskrifte bo-aan jou X- en Y-reekse is.
- Kies jou voorkeur Afvoer opsie, 'n nuwe werkblad in ons geval.
- Opsioneel, kies die Residuele -merkblokkie om die verskil tussen die voorspelde en werklike waardes te kry.
- Klik OK en let op die regressie-analise-uitset wat deur Excel geskep is.
Interpreteer regressie-analise-uitset
Soos jy sopas gesien het, is die uitvoer van regressie in Excel maklik omdat alle berekeninge outomaties vooraf gevorm word. Die interpretasie van die resultate is 'n bietjie moeiliker, want jy moet weet wat agter elke nommer is. Hieronder sal jy 'n uiteensetting van 4 hoofdele van die regressie-analise-uitset vind.
Regressie-analise-uitset: Opsommingsuitset
Hierdie deel vertel jou hoe goed die berekende lineêre regressievergelyking by jou brondata pas. 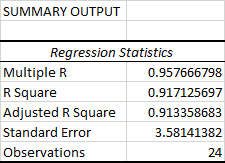
Hier is wat elke stukkie inligting beteken:
Veelvuldige R . Dit is die C relasiekoëffisiënt wat die sterkte van meet'n lineêre verband tussen twee veranderlikes. Die korrelasiekoëffisiënt kan enige waarde tussen -1 en 1 wees, en die absolute waarde daarvan dui die verhoudingsterkte aan. Hoe groter die absolute waarde, hoe sterker is die verhouding:
- 1 beteken 'n sterk positiewe verhouding
- -1 beteken 'n sterk negatiewe verhouding
- 0 beteken geen verwantskap by almal
R Vierkant . Dit is die Bepalingskoëffisiënt , wat gebruik word as 'n aanduiding van die goedheid van passing. Dit wys hoeveel punte op die regressielyn val. Die R2-waarde word bereken uit die totale som van vierkante, meer presies, dit is die som van die kwadraatafwykings van die oorspronklike data vanaf die gemiddelde.
In ons voorbeeld is R2 0,91 (afgerond tot 2 syfers) , wat redelik goed is. Dit beteken dat 91% van ons waardes by die regressie-analisemodel pas. Met ander woorde, 91% van die afhanklike veranderlikes (y-waardes) word deur die onafhanklike veranderlikes (x-waardes) verklaar. Oor die algemeen word R Squared van 95% of meer as 'n goeie passing beskou.
Aangepaste R Square . Dit is die R vierkant aangepas vir die aantal onafhanklike veranderlikes in die model. Jy sal hierdie waarde wil gebruik in plaas van R vierkant vir meervoudige regressie-analise.
Standaardfout . Dit is nog 'n goeie maatstaf wat die akkuraatheid van jou regressie-analise toon - hoe kleiner die getal, hoe sekerder kan jy wees oorjou regressievergelyking. Terwyl R2 die persentasie van die afhanklike veranderlikes variansie verteenwoordig wat deur die model verduidelik word, is Standaardfout 'n absolute maatstaf wat die gemiddelde afstand toon wat die datapunte van die regressielyn val.
Waarnemings . Dit is bloot die aantal waarnemings in jou model.
Regressie-analise-uitset: ANOVA
Die tweede deel van die uitset is Variansie-analise (ANOVA): 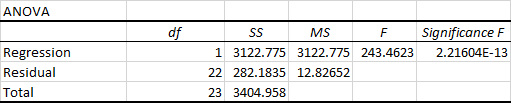
Basies, dit verdeel die som van vierkante in individuele komponente wat inligting gee oor die vlakke van veranderlikheid binne jou regressiemodel:
- df is die getal van die vryheidsgrade wat met die bronne geassosieer word van variansie.
- SS is die som van vierkante. Hoe kleiner die Residuele SS in vergelyking met die Total SS, hoe beter pas jou model by die data.
- MS is die gemiddelde vierkant.
- F is die F-statistiek, of F-toets vir die nulhipotese. Dit word gebruik om die algehele betekenisvolheid van die model te toets.
- Betekenis F is die P-waarde van F.
Die ANOVA-deel word selde gebruik vir 'n eenvoudige lineêre regressie-analise in Excel, maar jy moet beslis die laaste komponent fyn kyk. Die Betekenis F waarde gee 'n idee van hoe betroubaar (statisties betekenisvol) jou resultate is. As Betekenis F minder as 0.05 (5%) is, is jou model OK. As dit groter as 0,05 is, sal jywaarskynlik beter 'n ander onafhanklike veranderlike kies.
Regressie-analise-uitset: koëffisiënte
Hierdie afdeling verskaf spesifieke inligting oor die komponente van jou analise: 
Die nuttigste komponent in hierdie afdeling is Koëffisiënte . Dit stel jou in staat om 'n lineêre regressievergelyking in Excel te bou:
y = bx + aVir ons datastel, waar y die aantal sambrele verkoop is en x 'n gemiddelde maandelikse reënval is, ons lineêre regressieformule lyk soos volg:
Y = Rainfall Coefficient * x + Intercept
Toegerus met a- en b-waardes afgerond tot drie desimale plekke, verander dit in:
Y=0.45*x-19.074
Byvoorbeeld, met die gemiddelde maandelikse reënval gelykstaande aan 82 mm, sal die sambreelverkope ongeveer 17,8 wees:
0.45*82-19.074=17.8
Op 'n soortgelyke manier kan jy uitvind hoeveel sambrele gaan wees verkoop met enige ander maandelikse reënval (x veranderlike) wat jy spesifiseer.
Regressie-analise-uitset: residue
As jy die beraamde en werklike aantal verkoopte sambrele vergelyk wat ooreenstem met die maandelikse reënval van 82 mm, jy sal sien dat hierdie getalle effens verskil:
- Geskatte: 17.8 (hierbo bereken)
- Werklik: 15 (ry 2 van die brondata)
Hoekom is die verskil? Omdat onafhanklike veranderlikes nooit perfekte voorspellers van die afhanklike veranderlikes is nie. En die residuele kan jou help om te verstaan hoe ver die werklike waardes van die voorspelde waardes af is: 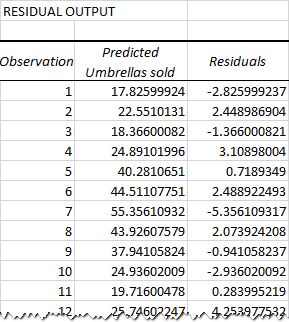
Virdie eerste datapunt (reënval van 82 mm), die oorblywende is ongeveer -2,8. Dus, ons voeg hierdie getal by die voorspelde waarde, en kry die werklike waarde: 17.8 - 2.8 = 15.
Hoe om 'n lineêre regressiegrafiek in Excel te maak
As jy vinnig moet visualiseer die verwantskap tussen die twee veranderlikes, teken 'n lineêre regressiegrafiek. Dis baie maklik! Dit is hoe:
- Kies die twee kolomme met jou data, insluitend opskrifte.
- Op die Invoeging -oortjie, in die Klets -groep , klik die Verspreidingsgrafiek -ikoon, en kies die Verspreidingsgrafiek -kleinkiekie (die eerste een):
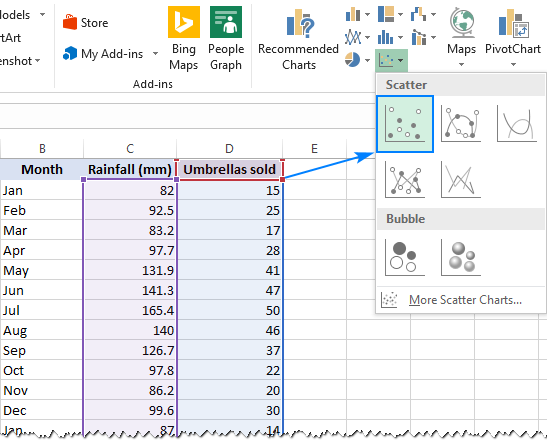
Dit sal 'n verstrooiingsgrafiek in jou werkblad invoeg, wat soos hierdie sal lyk een:
- Nou moet ons die kleinste kwadrate-regressielyn trek. Om dit te laat doen, regskliek op enige punt en kies Voeg neiginglyn by... uit die kontekskieslys.
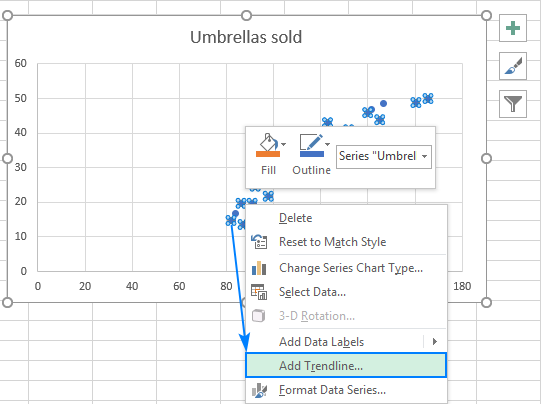
- Op die regterpaneel, kies die Lineêre tendenslynvorm en, opsioneel, merk Vertoon vergelyking op grafiek om jou regressieformule te kry:
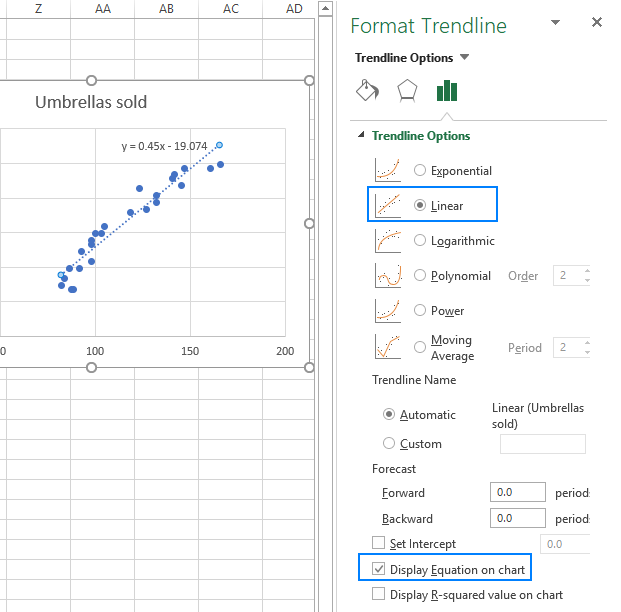
Soos jy dalk opmerk, is die regressievergelyking wat Excel vir ons geskep het dieselfde as die lineêre regressieformule wat ons gebou het op grond van die Koëffisiënte-uitset.
- Skakel oor na die Vul & Line -oortjie en pasmaak die lyn na jou smaak. Byvoorbeeld, jy kan 'n ander lynkleur kies en 'n soliede lyn gebruik in plaas van 'n stippellyn (kies Soliede lyn in die Dash type boks):
