
विषयसूची
TOROW फ़ंक्शन की सहायता से सेल की एक श्रेणी को एक पंक्ति में बदलने का एक त्वरित तरीका।
Microsoft Excel 365 ने कई नए फ़ंक्शन पेश किए हैं सरणियों के साथ विभिन्न जोड़तोड़ करने के लिए। टोरो के साथ, आप कुछ ही समय में रेंज-टू-रो ट्रांसफॉर्मेशन कर सकते हैं। यहां उन कार्यों की एक सूची दी गई है जो यह नया फ़ंक्शन पूरा कर सकता है:
एक्सेल टोरो फ़ंक्शन
एक्सेल में टोरो फ़ंक्शन का उपयोग किसी सरणी या सेल की श्रेणी को में बदलने के लिए किया जाता है एक पंक्ति।
फ़ंक्शन में कुल तीन तर्क होते हैं, जिनमें से केवल पहले वाले की आवश्यकता होती है।
TOROW(array, [ignore], [scan_by_column])कहा पे:
ऐरे (आवश्यक) - एक पंक्ति में बदलने के लिए एक सरणी या श्रेणी।
अनदेखा करें (वैकल्पिक) - यह निर्धारित करता है कि रिक्त स्थान को अनदेखा करना है या/और त्रुटियां। इनमें से कोई एक मान ले सकते हैं:
- 0 या छोड़ा गया (डिफ़ॉल्ट) - सभी मान रखें
- 1 - रिक्त स्थान को अनदेखा करें
- 2 - त्रुटियों को अनदेखा करें
- 3 - रिक्त स्थान और त्रुटियों को अनदेखा करें
Scan_by_column (वैकल्पिक) - सरणी को स्कैन करने का तरीका परिभाषित करता है:
- गलत या छोड़ा गया (डिफ़ॉल्ट) - पंक्ति द्वारा क्षैतिज रूप से सरणी को स्कैन करें।
- TRUE - कॉलम द्वारा लंबवत रूप से सरणी को स्कैन करें। एक एकल कॉलम में, TOCOL फ़ंक्शन का उपयोग करें।
- रिवर्स पंक्ति-से-सरणी परिवर्तन को पूर्वनिर्मित करने के लिए, या तो WRAPCOLS फ़ंक्शन का उपयोग कॉलम में रैप करने के लिए या रैप करने के लिए WRAPROWS फ़ंक्शन का उपयोग करेंसरणी को पंक्तियों में।
- पंक्तियों को स्तंभों में बदलने के लिए, TRANSPOSE फ़ंक्शन का उपयोग करें।
टोरो उपलब्धता
टोरो एक नया फ़ंक्शन है, जो केवल एक्सेल में समर्थित है माइक्रोसॉफ्ट 365 (विंडोज और मैक के लिए) और वेब के लिए एक्सेल। अपने मूल रूप में। इसके लिए, आपको केवल पहले तर्क ( सरणी ) को परिभाषित करने की आवश्यकता है। सूत्र है:
=TOROW(A3:C6)
आप सूत्र को केवल एक सेल (हमारे मामले में A10) में दर्ज करते हैं, और यह स्वचालित रूप से सभी परिणामों को धारण करने के लिए आवश्यक कई सेल में फैल जाता है। एक्सेल के शब्दों में, एक पतली नीली सीमा से घिरी आउटपुट रेंज को स्पिल रेंज कहा जाता है। 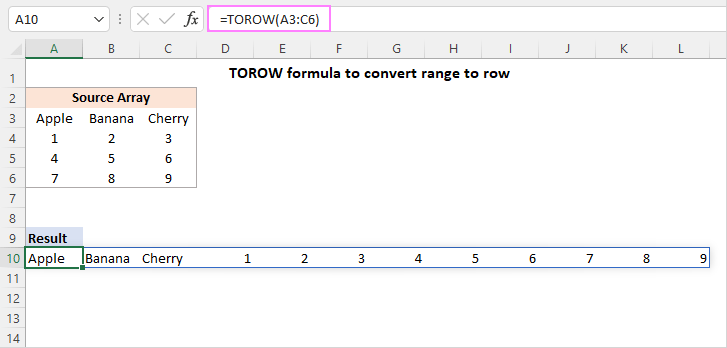
यह सूत्र कैसे काम करता है:
सबसे पहले, सेल की आपूर्ति की गई रेंज को द्वि-आयामी सरणी में रूपांतरित किया जाता है। कृपया कॉमा-सीमांकित कॉलम और अर्धविराम से अलग की गई पंक्तियों पर ध्यान दें:
{"Apple","Banana","Cherry";1,2,3;4,5,6;7,8,9}
फिर, TOROW फ़ंक्शन सरणी को बाएं से दाएं पढ़ता है और इसे एक-आयामी क्षैतिज सरणी में परिवर्तित करता है:
{"Apple","Banana","Cherry",1,2,3,4,5,6,7,8,9}
नतीजा सेल ए10 में जाता है, जहां से यह दाईं ओर के पड़ोसी सेल में जाता है।> डिफ़ॉल्ट रूप से, टो फ़ंक्शन खाली सेल और सहित, स्रोत सरणी से सभी मान रखता हैत्रुटियां। आउटपुट में, रिक्त कक्षों के स्थान पर शून्य मान दिखाई देते हैं, जो काफी भ्रमित करने वाला हो सकता है। 3>
=TOROW(A3:C5, 1)
त्रुटियों को अनदेखा करने के लिए, अनदेखा तर्क को 2 पर सेट करें:
=TOROW(A3:C5, 2)
छोड़ने के लिए दोनों, रिक्त और त्रुटियाँ , उपेक्षा तर्क के लिए 3 का उपयोग करें:
=TOROW(A3:C5, 3)
नीचे दी गई छवि कार्रवाई में सभी तीन परिदृश्य दिखाती है: <18
सरणी को क्षैतिज या लंबवत रूप से पढ़ें
डिफ़ॉल्ट व्यवहार के साथ, टो फ़ंक्शन सरणी को बाएं से दाएं क्षैतिज रूप से संसाधित करता है। ऊपर से नीचे तक कॉलम द्वारा मानों को स्कैन करने के लिए, आप तीसरे तर्क ( scan_by_column ) को TRUE या 1 पर सेट करते हैं।
उदाहरण के लिए, पंक्ति द्वारा स्रोत श्रेणी को पढ़ने के लिए, सूत्र में E3 है:
=TOROW(A3:C5)
स्तंभ द्वारा श्रेणी को स्कैन करने के लिए, E8 में सूत्र है:
=TOROW(A3:C5, ,TRUE)
दोनों मामलों में, परिणामी सरणियाँ हैं एक ही आकार, लेकिन मान एक अलग क्रम में व्यवस्थित होते हैं। 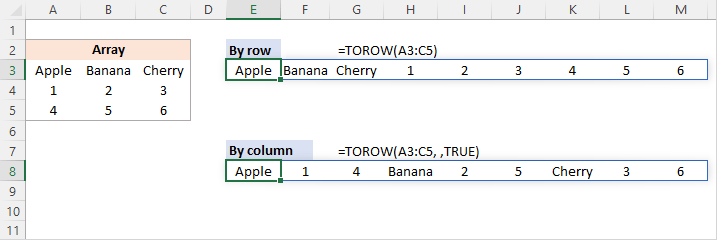
कई श्रेणियों को एक पंक्ति में मर्ज करें
कई गैर-सन्निकट श्रेणियों को एक पंक्ति में संयोजित करने के लिए, आप पहले उन्हें क्रमशः HSTACK या VSTACK की सहायता से क्षैतिज या लंबवत रूप से एकल सरणी में स्टैक करते हैं , और फिर संयुक्त सरणी को एक पंक्ति में बदलने के लिए TOROW फ़ंक्शन का उपयोग करें।
आपके व्यावसायिक तर्क के आधार पर, निम्न में से कोई एक सूत्र कार्य करेगा।
सरणी को क्षैतिज रूप से ढेर करें और इसके द्वारा रूपांतरित करें पंक्ति
पहले के साथA3:C4 में श्रेणी और A8:C9 में दूसरी श्रेणी, नीचे दिया गया सूत्र दो श्रेणियों को क्षैतिज रूप से एक सरणी में ढेर कर देगा, और फिर इसे बाएं से दाएं मानों को पढ़ने वाली पंक्ति में बदल देगा। परिणाम नीचे दी गई छवि में E3 में है।
=TOROW(HSTACK(A3:C4, A8:C9))
सरणियों को क्षैतिज रूप से ढेर करें और स्तंभ द्वारा परिवर्तित करें
स्टैक्ड सरणी को ऊपर से नीचे तक लंबवत पढ़ने के लिए, आप TOROW के तीसरे तर्क को TRUE पर सेट करते हैं जैसा कि नीचे दी गई छवि में E5 में दिखाया गया है:
=TOROW(HSTACK(A3:C4, A8:C9), ,TRUE)
सरणी को लंबवत रूप से ढेर करें और पंक्ति द्वारा परिवर्तित करें
प्रत्येक को जोड़ने के लिए पिछली सरणी के निचले भाग में बाद की सरणी और संयुक्त सरणी को क्षैतिज रूप से पढ़ें, E12 में सूत्र है:> प्रत्येक बाद की सरणी को पिछले एक के नीचे जोड़ने के लिए और संयुक्त सरणी को लंबवत रूप से स्कैन करने के लिए, सूत्र है:
=TOROW(VSTACK(A3:C4, A8:C9), ,TRUE)
तर्क को बेहतर ढंग से समझने के लिए, मूल्यों के विभिन्न क्रम का निरीक्षण करें परिणामी सरणियाँ: 
एक पंक्ति में एक सीमा से अद्वितीय मान निकालें
Microsoft Excel 2016 से शुरू होकर, हमारे पास एक अद्भुत कार्य है, जिसका नाम UNIQUE है, जो आसानी से एक एकल स्तंभ से अद्वितीय मान प्राप्त कर सकता है या पंक्ति। हालाँकि, यह बहु-स्तंभ सरणियों को संभाल नहीं सकता है। इस सीमा को पार करने के लिए, UNIQUE और TOOW फ़ंक्शंस का एक साथ उपयोग करें।
उदाहरण के लिए, श्रेणी A2:C7 से सभी अलग-अलग (अलग) मानों को निकालने और परिणामों को एक पंक्ति में रखने के लिए,सूत्र है:
=UNIQUE(TOROW(A2:C7), TRUE)
जैसा कि TOROW एक आयामी क्षैतिज सरणी लौटाता है, हम प्रत्येक कॉलम की तुलना करने के लिए UNIQUE के दूसरे ( by_col ) तर्क को TRUE पर सेट करते हैं अन्य।
यदि आप चाहते हैं कि परिणाम वर्णानुक्रम में व्यवस्थित हों, तो उपरोक्त सूत्र को SORT फ़ंक्शन में लपेटें:
=SORT(UNIQUE(TOROW(A2:C7), TRUE), , ,TRUE )
UNIQUE की तरह, by_col SORT का तर्क भी TRUE पर सेट है। 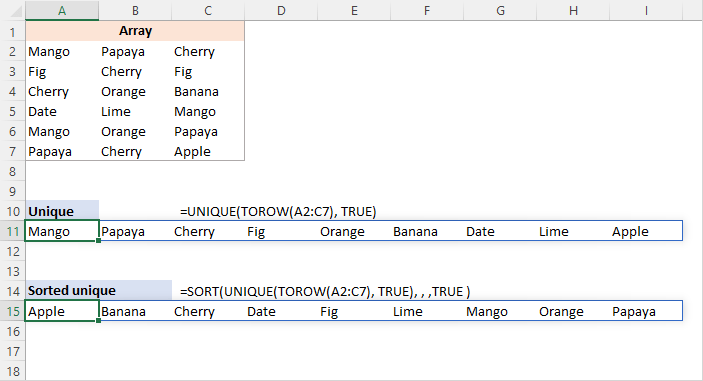
एक्सेल 365 - 2010 के लिए टोरो विकल्प
एक्सेल के उन संस्करणों में जहां टोरो फंक्शन उपलब्ध नहीं है, आप कुछ विभिन्न फंक्शनों के संयोजन का उपयोग करके एक रेंज को सिंगल रो में बदल सकते हैं जो पुराने संस्करण। ये समाधान अधिक जटिल हैं, लेकिन वे काम करते हैं।
क्षैतिज रूप से सीमा को स्कैन करने के लिए, सामान्य सूत्र है:
INDEX( श्रेणी , QUOTIENT(COLUMN (A1)-1, COLUMNS( श्रेणी ))+1, MOD(COLUMN(A1)-1, COLUMNS( श्रेणी ))+1)श्रेणी को लंबवत रूप से स्कैन करने के लिए, सामान्य सूत्र है :
INDEX( श्रेणी , MOD(COLUMN(A1)-1, COLUMNS( श्रेणी ))+1, QUOTIENT(COLUMN (A1)-1, COLUMNS(<15)>रेंज ))+1)A3:C5 में हमारे नमूना डेटासेट के लिए, सूत्र इस आकार को लेते हैं:
पंक्ति द्वारा श्रेणी को स्कैन करने के लिए:
=INDEX($A$3:$C$5, QUOTIENT(COLUMN(A1)-1, COLUMNS($A$3:$C$5))+1, MOD(COLUMN(A1)-1, COLUMNS($A$3:$C$5))+1)
यह सूत्र TOROW फ़ंक्शन का एक विकल्प है जिसमें तीसरा तर्क FALSE पर सेट है या छोड़ दिया गया है:
=TOROW(A3:C5)
द्वारा श्रेणी को स्कैन करने के लिए column:
=INDEX($A$3:$C$5, MOD(COLUMN(A1)-1, COLUMNS($A$3:$C$5))+1, QUOTIENT(COLUMN(A1)-1, COLUMNS($A$3:$C$5))+1)
यह सूत्र तीसरे तर्क के साथ TOROW फ़ंक्शन के समतुल्य हैTRUE:
=TOROW(A3:C5, ,TRUE)
कृपया ध्यान दें कि डायनामिक ऐरे TOROW फ़ंक्शन के विपरीत, इन पारंपरिक फ़ार्मुलों को प्रत्येक सेल में दर्ज किया जाना चाहिए जहाँ आप परिणाम दिखाना चाहते हैं। हमारे मामले में, पहला सूत्र (पंक्ति द्वारा) E3 में जाता है और M3 के माध्यम से कॉपी किया जाता है। दूसरा फॉर्मूला (कॉलम द्वारा) E8 में आता है और M8 के माध्यम से खींचा जाता है। एक नामांकित श्रेणी भी काम करेगी।
यदि आपने सूत्रों को आवश्यकता से अधिक कक्षों में कॉपी किया है, तो एक #REF! त्रुटि "अतिरिक्त" कोशिकाओं में दिखाई देगी। इसे ठीक करने के लिए, अपने सूत्र को IFERROR फ़ंक्शन में इस प्रकार लपेटें:
=IFERROR(INDEX($A$3:$C$5, QUOTIENT(COLUMN(A1)-1, COLUMNS($A$3:$C$5))+1, MOD(COLUMN(A1)-1, COLUMNS($A$3:$C$5))+1), "") 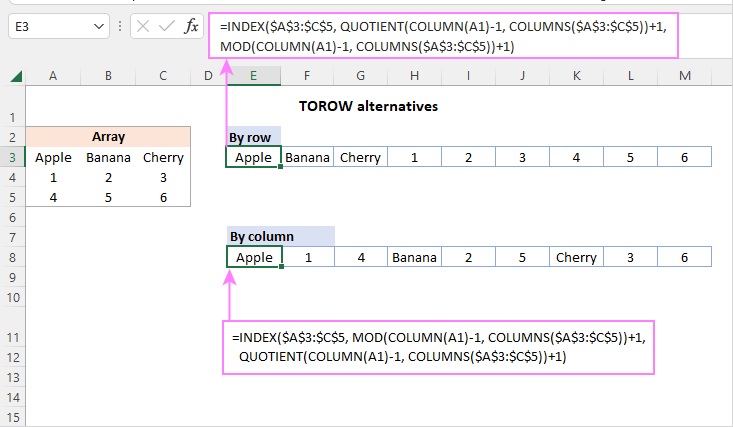
ये सूत्र कैसे काम करते हैं
नीचे एक विस्तृत ब्रेक-डाउन है पंक्ति द्वारा मानों को व्यवस्थित करने वाले पहले सूत्र का:
=INDEX($A$3:$C$5, QUOTIENT(COLUMN(A1)-1, COLUMNS($A$3:$C$5))+1, MOD(COLUMN(A1)-1, COLUMNS($A$3:$C$5))+1)
सूत्र के केंद्र में, हम सेल में इसकी सापेक्ष स्थिति के आधार पर सेल का मान प्राप्त करने के लिए INDEX फ़ंक्शन का उपयोग करते हैं रेंज।
पंक्ति संख्या की गणना इस सूत्र द्वारा की जाती है:
QUOTIENT(COLUMN(A1)-1, COLUMNS($A$3:$C$5))+1
आइडिया 1,1 जैसे दोहराए जाने वाले संख्या अनुक्रम का उत्पादन करना है ,1,2,2,2,3,3,3, … जहां प्रत्येक संख्या उतनी बार दोहराई जाती है जितनी बार स्रोत श्रेणी में कॉलम होते हैं। और यहां बताया गया है कि हम यह कैसे करते हैं:
QUOTIENT किसी भाग का पूर्णांक भाग लौटाता है।
अंश के लिए, हम COLUMN(A1)-1 का उपयोग करते हैं, जो एक सीरियल लौटाता है पहली सेल में 0 से संख्या जहां फॉर्मूला दर्ज किया गया है n (श्रेणी में मानों की कुल संख्यामाइनस 1) अंतिम सेल में जहां सूत्र दर्ज किया गया था। इस उदाहरण में, हमारे पास E2 में 0 और M3 में 8 है।
हर के लिए, हम COLUMNS($A$3:$C$5)) का उपयोग करते हैं। यह आपकी श्रेणी (हमारे मामले में 3) में कॉलम की संख्या के बराबर एक स्थिर संख्या देता है। 1 जोड़ें, इसलिए पंक्ति संख्या 1 है।
अगली 3 कोशिकाओं (H3:J3) के लिए, QUOTIENT 1 लौटाता है, और +1 पंक्ति संख्या 2 देता है। और इसी तरह आगे।
स्तंभ संख्या की गणना करने के लिए, आप एमओडी फ़ंक्शन का उपयोग करके एक उपयुक्त संख्या अनुक्रम बनाते हैं:
MOD(COLUMN(A1)-1, COLUMNS($A$3:$C$5))+1
चूंकि हमारी सीमा में 3 स्तंभ हैं, क्रम ऐसा दिखना चाहिए : 1,2,3,1,2,3,...
MOD फ़ंक्शन विभाजन के बाद शेषफल लौटाता है।
E3 में, MOD(COLUMN(A1)-1, COLUMNS($) A$3:$C$5))+
बन जाता है
MOD(1-1, 3)+1)
और 1 लौटाता है।
में F3, MOD(COLUMN(B1)-1, COLUMNS($A$3:$C$5))+
बन जाता है
MOD(2-1, 3)+1)
और रिटर्न 2.
एक बार पंक्ति और कॉलम संख्या स्थापित हो जाने के बाद, INDEX उस पंक्ति और कॉलम के चौराहे पर आसानी से मान प्राप्त करता है।
E3 में, INDEX($A$3) :$C$5, 1, 1) पहली पंक्ति और पहले कॉलम से मान लौटाता है संदर्भित श्रेणी का, यानी सेल ए3 से।
और इसी तरह आगे।
दूसरा सूत्र जो कॉलम द्वारा श्रेणी को स्कैन करता है, एक में काम करता हैसमान रास्ता। अंतर यह है कि हम पंक्ति संख्या की गणना करने के लिए एमओडी का उपयोग करते हैं और कॉलम संख्या का पता लगाने के लिए QUOTIENT। इन कारणों में से एक होने की सबसे अधिक संभावना है:
#NAME? त्रुटि
अधिकांश एक्सेल फ़ंक्शंस के साथ, एक #NAME? त्रुटि एक स्पष्ट संकेत है कि फ़ंक्शन का नाम गलत वर्तनी है। टोरो के साथ, इसका अर्थ यह भी हो सकता है कि फ़ंक्शन आपके एक्सेल में उपलब्ध नहीं है। यदि आपका एक्सेल संस्करण 365 के अलावा अन्य में है, तो टोरो विकल्प का उपयोग करने का प्रयास करें। अक्सर ऐसा तब होता है जब आप छोटी श्रेणी के बजाय पूरे कॉलम और/या पंक्तियों को संदर्भित करते हैं।
#SPILL त्रुटि
ज्यादातर मामलों में, #SPILL त्रुटि बताती है कि पंक्ति जहां आपने सूत्र में प्रवेश किया है, उसमें परिणामों को फैलाने के लिए पर्याप्त रिक्त कक्ष नहीं हैं। यदि आस-पास के सेल नेत्रहीन रूप से खाली हैं, तो सुनिश्चित करें कि उनमें कोई रिक्त स्थान या अन्य गैर-मुद्रण वर्ण नहीं हैं। अधिक जानकारी के लिए देखें कि एक्सेल में #SPILL त्रुटि का क्या मतलब है।
इसी तरह आप एक्सेल में टोरो फ़ंक्शन का उपयोग 2-आयामी सरणी या श्रेणी को एक पंक्ति में बदलने के लिए करते हैं। मैं आपको पढ़ने के लिए धन्यवाद देता हूं और अगले सप्ताह आपको हमारे ब्लॉग पर देखने की आशा करता हूं!
डाउनलोड के लिए अभ्यास कार्यपुस्तिका
एक्सेल टोरो फ़ंक्शन - सूत्र उदाहरण (.xlsx फ़ाइल)
