
Kazalo
V tem vodniku se boste naučili, kako v Excelu uporabiti regularne izraze za iskanje in izločanje podrejencev, ki ustrezajo danemu vzorcu.
Microsoft Excel ponuja številne funkcije za izpis besedila iz celic. Te funkcije se lahko spopadejo z večino izzivov izpisovanja nizov v vaših delovnih listih. Z večino, vendar ne z vsemi. Ko se funkcije za besedilo spotaknejo, pridejo na pomoč regularni izrazi. Počakajte... Excel nima funkcij RegEx! Res je, nima vgrajenih funkcij. Toda nič vam ne preprečuje, da bi uporabili svoje lastne funkcije :)
Funkcija Excel VBA Regex za ekstrakcijo nizov
Če želite v Excel dodati funkcijo Regex Extract po meri, v urejevalnik VBA prilepite naslednjo kodo. Za omogočanje regularnih izrazov v VBA uporabljamo vgrajeni Microsoftov objekt RegExp.
Public Function RegExpExtract(text As String , pattern As String , Optional instance_num As Integer = 0, Optional match_case As Boolean = True ) Dim text_matches() As String Dim matches_index As Integer On Error GoTo ErrHandl RegExpExtract = "" Set regex = CreateObject ("VBScript.RegExp" ) regex.pattern = pattern regex.Global = True regex.MultiLine = True If True = match_case Thenregex.ignorecase = False Else regex.ignorecase = True End If Set matches = regex.Execute(text) If 0 <matches.Count Then If (0 = instance_num) Then ReDim text_matches(matches.Count - 1, 0) For matches_index = 0 To matches.Count - 1 text_matches(matches_index, 0) = matches.Item(matches_index) Next matches_index RegExpExtract = text_matches Else RegExpExtract = matches.Item(instance_num - 1) EndIf End If Exit Function ErrHandl: RegExpExtract = CVErr(xlErrValue) End FunctionČe imate malo izkušenj z VBA, vam bo v pomoč uporabniški priročnik, ki opisuje korak za korakom: Kako vstaviti kodo VBA v Excel.
Opomba: Da bo funkcija delovala, morate datoteko shraniti kot Delovni zvezek z omogočenimi makri (.xlsm).
Sintaksa RegExpExtract
Spletna stran RegExpExtract funkcija v vhodnem nizu poišče vrednosti, ki ustrezajo regularnemu izrazu, in izloči eno ali vsa ujemanja.
Funkcija ima naslednjo sintakso:
RegExpExtract(besedilo, vzorec, [številka primera], [match_case])Kje:
- Besedilo (obvezno) - besedilni niz za iskanje.
- Vzorec (obvezno) - regularni izraz za ujemanje. Če je vzorec naveden neposredno v formuli, mora biti zaprt v dvojne narekovaje.
- Instance_num (neobvezno) - zaporedna številka, ki označuje, kateri primerek je treba izpisati. Če je izpuščen, se vrnejo vsa najdena ujemanja (privzeto).
- Match_case (neobvezno) - določa, ali se velikost črk v besedilu ujema ali ne. Če je nastavitev TRUE ali je izpuščena (privzeto), se izvede ujemanje z upoštevanjem velikosti črk; če je nastavitev FALSE, se izvede ujemanje brez upoštevanja velikosti črk.
Funkcija deluje v vseh različicah programov Excel 365, Excel 2021, Excel 2019, Excel 2016, Excel 2013 in Excel 2010.
4 stvari, ki jih morate vedeti o RegExpExtract
Za učinkovito uporabo funkcije v Excelu morate upoštevati nekaj pomembnih stvari:
- Privzeto funkcija vrne vse najdene zadetke v sosednje celice, kot je prikazano v tem primeru. Če želite dobiti določen pojav, vnesite ustrezno številko v instance_num argument.
- Privzeto je funkcija , ki upošteva velike in male črke. . Za ujemanje brez upoštevanja velikih in malih črk nastavite match_case na FALSE. Zaradi omejitev VBA konstrukcija, ki ne razlikuje velikih in malih črk (?i), ne bo delovala.
- Če je veljavni vzorec ni najden , funkcija ne vrne ničesar (prazen niz).
- Če je vzorec je neveljaven. , se pojavi napaka #VALUE!.
Preden začnete uporabljati to funkcijo po meri v delovnih listih, morate razumeti, kaj zmore, kajne? Spodnji primeri zajemajo nekaj pogostih primerov uporabe in pojasnjujejo, zakaj se lahko obnašanje razlikuje v programu Excel z dinamičnim poljem (Microsoft 365 in Excel 2021) in tradicionalnem Excelu (2019 in starejše različice).
Opomba: Izhodiščni primeri regularnih izrazov so napisani za pravljično preproste podatkovne nize. Ne moremo zagotoviti, da bodo brezhibno delovali v vaših resničnih delovnih listih. Tisti, ki imajo izkušnje z regexi, se strinjajo, da je pisanje regularnih izrazov neskončna pot do popolnosti - skoraj vedno obstaja način, kako jih narediti elegantnejše ali sposobne obdelati širši razpon vhodnih podatkov.
Regex za izpis števila iz niza
V skladu z osnovnim načelom poučevanja "od preprostega k zapletenemu" bomo začeli z zelo preprostim primerom: pridobivanjem števila iz niza.
Najprej se morate odločiti, katero številko želite priklicati: prvo, zadnjo, določen pojav ali vse številke.
Izvleček prve številke
Glede na to, da \d pomeni katero koli številko od 0 do 9, + pa pomeni en ali večkrat, je naš regularni izraz v tej obliki:
Vzorec : \d+
Nastavite instance_num na 1 in dobili boste želeni rezultat:
=RegExpExtract(A5, "\d+", 1)
Pri čemer je A5 izvirni niz.
Zaradi priročnosti lahko vzorec vnesete v vnaprej določeno celico ($A$2 ) in njen naslov zaklenete z znakom $:
=RegExpExtract(A5, $A$2, 1) 
Pridobite zadnjo številko
Če želite izpisati zadnjo številko v nizu, uporabite naslednji vzorec:
Vzorec : (\d+)(?!.*\d)
Prevedeno v človeški jezik se glasi: poišči število, ki mu ne sledi (kjerkoli, ne le takoj) nobeno drugo število. Da bi to izrazili, uporabljamo negativni lookahead (?!.*\d), kar pomeni, da desno od vzorca ne sme biti nobene druge številke (\d) ne glede na to, koliko drugih znakov je pred njo.
=RegExpExtract(A5, "(\d+)(?!.*\d)") 
Nasveti:
- Če želite pridobiti poseben pojav , uporabite \d+ za vzorec in ustrezno serijsko številko za instance_num .
- Formula za pridobivanje vse številke je obravnavan v naslednjem primeru.
Regex za izločanje vseh zadetkov
Če naš primer še malo razširimo, predpostavimo, da želite iz niza dobiti vse številke in ne samo ene.
Kot se morda spomnite, je število izluščenih zadetkov nadzorovano z izbirnim ukazom instance_num Privzeto so vsa ujemanja, zato ta parameter preprosto izpustite:
=RegExpExtract(A2, "\d+")
Formula odlično deluje za eno celico, vendar se obnašanje razlikuje v dinamičnem polju programa Excel in nedinamičnih različicah.
Excel 365 in Excel 2021
Zaradi podpore dinamičnim nizom se običajna formula samodejno razlije v toliko celic, kolikor je potrebno za prikaz vseh izračunanih rezultatov. V Excelu se to imenuje razlito območje: 
Excel 2019 in nižje
V preddinamičnem Excelu bi zgornja formula vrnila samo eno ujemanje. Če želite dobiti več ujemanj, morate formulo spremeniti v polje. V ta namen izberite območje celic, vnesite formulo in pritisnite Ctrl + Shift + Enter, da jo dokončate.
Slabost tega pristopa je, da se v "dodatnih celicah" pojavlja veliko napak #N/A. Na žalost ni mogoče storiti ničesar (niti IFERROR niti IFNA tega ne moreta popraviti). 
Izvleček vseh zadetkov v eni celici
Pri obdelavi stolpca podatkov zgornji pristop očitno ne bo deloval. V tem primeru bi bila idealna rešitev vračanje vseh zadetkov v eni celici. Če želite to narediti, rezultate funkcije RegExpExtract podajte funkciji TEXTJOIN in jih ločite s poljubnim ločilom, na primer z vejico in presledkom:
=TEXTJOIN(", ", TRUE, RegExpExtract(A5, "\d+")) 
Opomba: Ker je funkcija TEXTJOIN na voljo samo v Excelu za Microsoft 365, Excel 2021 in Excel 2019, formula ne bo delovala v starejših različicah.
Regex za pridobivanje besedila iz niza
Izločanje besedila iz alfanumeričnega niza je v Excelu precej zahtevno opravilo. Z regexom je to preprosto kot torta. Uporabite le razred z zanikanjem, da se ujemate z vsem, kar ni številka.
Vzorec : [^\d]+
Če želite dobiti podredja v posameznih celicah (razpon razlitja), je formula naslednja:
=RegExpExtract(A5, "[^\d]+") 
Če želite izpisati vsa ujemanja v eno celico, vnesite funkcijo RegExpExtract v TEXTJOIN na naslednji način:
=TEXTJOIN("", TRUE, RegExpExtract(A5, "[^\d]+")) 
Regex za pridobivanje e-poštnega naslova iz niza
Če želite iz niza, ki vsebuje veliko različnih informacij, izluščiti e-poštni naslov, napišite regularni izraz, ki posnema strukturo e-poštnega naslova.
Vzorec : [\w\.\-]+@[A-Za-z0-9\.\-]+\.[A-Za-z]{2,24}
Če razčlenimo ta regex, dobimo naslednji rezultat:
- [\w\.\-]+ je uporabniško ime, ki lahko vsebuje 1 ali več alfanumeričnih znakov, podčrtancev, pik in pomišljajev.
- @ simbol
- [A-Za-z0-9\.\-]+ je ime domene, sestavljeno iz: velikih in malih črk, številk, pomišljajev in pik (v primeru poddomen). Podčrtaje tu niso dovoljene, zato se namesto \w, ki ustreza kateri koli črki, številki ali podčrtaji, uporabljajo 3 različni nabori znakov (na primer A-Z a-z in 0-9).
- \.[A-Za-z]{2,24} je domena najvišje ravni. Sestavljena je iz pike, ki ji sledijo velike in male črke. Večina domen najvišje ravni je dolga 3 črke (npr. .com .org, .edu itd.), teoretično pa lahko vsebuje od 2 do 24 črk (najdaljša registrirana TLD).
Ob predpostavki, da je niz v A5, vzorec pa v A2, je formula za izpis e-poštnega naslova naslednja:
=RegExpExtract(A5, $A$2) 
Regex za pridobivanje domene iz e-pošte
Pri pridobivanju e-poštne domene najprej pomislite, da je treba uporabiti skupino za zajemanje za iskanje besedila, ki sledi znaku @.
Vzorec : @([A-Za-z0-9\.\-]+\.[A-Za-z]{2,24})
Posredujte ga naši funkciji RegExp:
=RegExpExtract(A5, "@([A-Za-z0-9\.\-]+\.[A-Za-z]{2,24})")
In dobili boste ta rezultat: 
Pri klasičnih regularnih izrazih vse, kar je zunaj skupine za zajemanje, ni vključeno v izločanje. Nihče ne ve, zakaj VBA RegEx deluje drugače in zajame tudi znak "@". Če se ga želite znebiti, lahko prvi znak odstranite iz rezultata tako, da ga nadomestite s praznim nizom.
=REPLACE(RegExpExtract(A5, "@([a-z\d][a-z\d\-\.]*\.[a-z]{2,})", 1, FALSE), 1, 1, 1, "") 
Regularni izraz za pridobivanje telefonskih številk
Telefonske številke se lahko zapišejo na veliko različnih načinov, zato je skoraj nemogoče najti rešitev, ki bi delovala v vseh okoliščinah. Kljub temu lahko zapišete vse oblike, ki se uporabljajo v vašem naboru podatkov, in jih poskušate uskladiti.
V tem primeru bomo ustvarili regex, ki bo izpisal telefonske številke v kateri koli od teh oblik:
(123) 345-6789 (123) 345 6789 (123)3456789 123-345-6789 | 123.345.6789 123 345 6789 1233456789 |
Vzorec : \(?\d{3}[-\. \)]*\d{3}[-\. ]?\d{4}\b
- Prvi del \(?\d{3} se ujema z nič ali enim odprtim oklepajem, ki mu sledijo tri številke d{3}.
- Del [-\. \)]* pomeni kateri koli znak v oglatem oklepaju, ki se pojavi 0-krat ali večkrat: pomišljaj, pika, presledek ali zaključni oklepaj.
- Nato imamo spet tri številke d{3}, ki jim sledi katerikoli pomišljaj, pika ali presledek [-\. ]?, ki se pojavi 0- ali 1-krat.
- Nato sledi skupina štirih številk \d{4}.
- Nazadnje je tu še beseda meja \b, ki določa, da iskana telefonska številka ne more biti del večje številke.
Celotna formula je takšna:
=RegExpExtract(A5, "\(?\d{3}[-\. \)]*\d{3}[-\. ]?\d{4}\b") 
Upoštevajte, da lahko zgornji regex vrne nekaj lažno pozitivnih rezultatov, na primer 123) 456 7899 ali (123 456 7899. Spodnja različica te težave odpravlja. Vendar ta sintaksa deluje le v funkcijah VBA RegExp in ne v klasičnih regularnih izrazih.
Vzorec : (\(\d{3}\)
Regex za izpis datuma iz niza
Regularni izraz za ekstrakcijo datuma je odvisen od oblike, v kateri se datum pojavi v nizu:
Za izpis datumov, kot sta 1/1/21 ali 01/01/2021, je regex naslednji: \d{1,2}\/\d{1,2}\/(\d{4}
Išče skupino 1 ali 2 številk d{1,2}, ki ji sledi poševnica, nato drugo skupino 1 ali 2 številk, ki ji sledi poševnica, nato skupino 4 ali 2 številk (\d{4}prvi pogoj je v konstrukciji alternacije ALI se ujema, preostali pogoji se ne preverjajo.
Če želite pridobiti datume, kot sta 1-Jan-21 ali 01-Jan-2021, je vzorec naslednji: \d{1,2}-[A-Za-z]{3}-\d{2,4}
Išče skupino 1 ali 2 številk, ki ji sledi pomišljaj, nato skupino 3 velikih ali malih črk, ki ji sledi pomišljaj, nato pa skupino 4 ali 2 številk.
Po združitvi obeh vzorcev dobimo naslednji regex:
Vzorec : \b\d{1,2}[\/-](\d{1,2}
Kje:
- Prvi del je 1 ali 2 števki: \d{1,2}
- Drugi del je 1 ali 2 števki ali 3 črke: (\d{1,2})
- Tretji del je skupina 4 ali 2 številk: (\d{4})
- Razmejitev je poševnica naprej ali pomišljaj: [\/-]
- Besedna meja \b je na obeh straneh, da je jasno razvidno, da je datum ločena beseda in ne del večjega niza.
Kot lahko vidite na spodnji sliki, uspešno izloči datume in izpusti podrejene nize, kot je 11/22/333. Vendar še vedno vrne lažno pozitivne rezultate. V našem primeru se podrejeni niz 11-ABC-2222 v A9 tehnično ujema z obliko datuma dd-mmm-yyyy in se zato izloči. 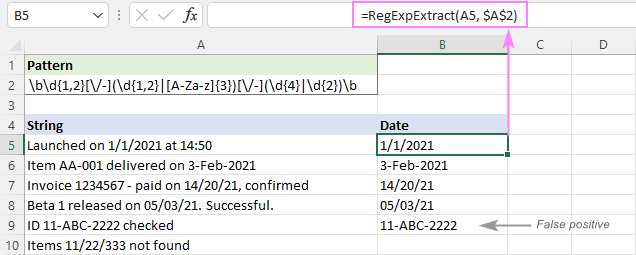
Za odpravo lažnih pozitivnih rezultatov lahko del [A-Za-z]{3} nadomestite s popolnim seznamom tričrkovnih kratic mesecev:
Vzorec : \b\d{1,2}[\/-](\d{1,2}
Če želimo zanemariti velikost črk, nastavimo zadnji argument naše funkcije po meri na FALSE:
=RegExpExtract(A5, $A$2, 1, FALSE)
Tokrat smo dobili odličen rezultat: 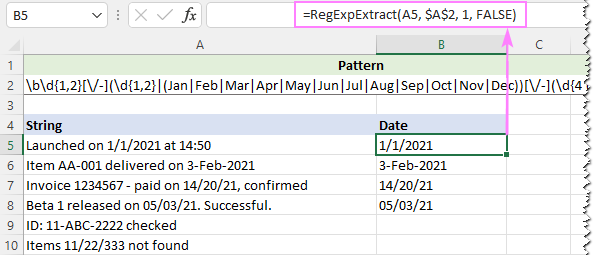
Regex za pridobivanje časa iz niza
Če želite pridobiti čas v hh:mm ali hh:mm:ss se bo obnesel naslednji izraz.
Vzorec : \b(0?[0-9]
Če razčlenite ta regex, lahko vidite 2 dela, ki sta ločena z
Izraz 1 : \b(0?[0-9]
Prikliče čase z AM/PM.
Ura je lahko katero koli število od 0 do 12. Da bi ga dobili, uporabimo konstrukcijo OR ([0-9]
- [0-9] ustreza katerikoli številki od 0 do 9
- 1[0-2] ustreza katerikoli številki od 10 do 12
Minuta [0-5]\d je katero koli število od 00 do 59.
Drugi (:[0-5]\d)?? je tudi katero koli število od 00 do 59. Kvantifikator ? pomeni nič ali eno pojavitev, saj so sekunde lahko vključene v vrednost časa ali ne.
Izraz 2 : \b([0-9]
Izvleče čase brez AM/PM.
Spletna stran ura del je lahko katero koli število od 0 do 32. Da bi ga dobili, je treba uporabiti drugačno konstrukcijo OR ([0-9]
- [0-9] ustreza katerikoli številki od 0 do 9
- [0-1]\d ustreza katerikoli številki od 00 do 19
- 2[0-3] ustreza katerikoli številki od 20 do 23
Spletna stran minuta in . drugi deli so enaki kot v izrazu 1 zgoraj.
Negativni lookahead (?!:) se doda nizom za preskok, kot so 20:30:80.
Ker so lahko PM/AM velike ali male črke, funkcija ne upošteva velikih in malih črk:
=RegExpExtract(A5, $A$2, 1, FALSE) 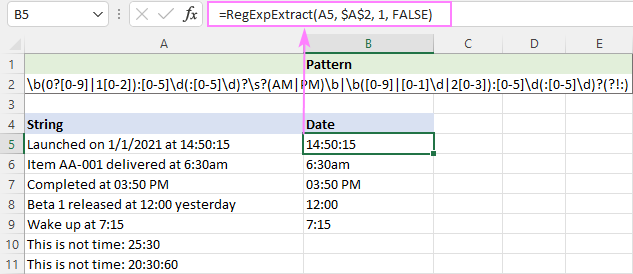
Upam, da ste z zgornjimi primeri dobili nekaj idej, kako uporabiti regularne izraze v delovnih listih programa Excel. Žal v programu VBA niso podprte vse funkcije klasičnih regularnih izrazov. Če vaše naloge ni mogoče opraviti z VBA RegExp, vam priporočam, da preberete naslednji del, v katerem so opisane veliko zmogljivejše funkcije .NET Regex.
Funkcija Regex po meri na osnovi tehnologije .NET za izpis besedila v Excelu
Za razliko od funkcij VBA RegExp, ki jih lahko napiše vsak uporabnik programa Excel, so funkcije .NET RegEx domena razvijalcev. Microsoftovo ogrodje .NET podpira polno funkcionalno sintakso regularnih izrazov, združljivo s Perlom 5. Ta članek vas ne bo naučil, kako napisati takšne funkcije (nisem programer in nimam niti najmanjšega pojma, kako to storiti :)
Štiri zmogljive funkcije, ki jih obdeluje standardni pogon .NET RegEx, so že napisali naši razvijalci in so vključene v paket Ultimate Suite. V nadaljevanju bomo prikazali nekaj praktičnih uporab funkcije, ki je posebej zasnovana za pridobivanje besedila v programu Excel.
Nasvet. Za informacije o sintaksi .NET Regex si oglejte poglavje .NET Regular Expression Language.
Kako v Excelu izluščiti žige z uporabo regularnih izrazov
Če imate nameščeno najnovejšo različico paketa Ultimate Suite, je ekstrakcija besedila z uporabo regularnih izrazov omejena na naslednja dva koraka:
- Na Podatkovni zapisi o napravah Ablebits v zavihku Besedilo skupino, kliknite Orodja Regex .

- Na Orodja Regex izberite izvorne podatke, vnesite vzorec Regex in izberite Izvleček Če želite dobiti rezultat kot funkcijo po meri in ne kot vrednost, izberite možnost Vstavite kot formulo Ko končate, kliknite potrditveno polje Izvleček gumb.

Rezultati bodo prikazani v novem stolpcu na desni strani prvotnih podatkov: 
Sintaksa AblebitsRegexExtract
Naša funkcija po meri ima naslednjo sintakso:
AblebitsRegexExtract(reference, regular_expression)Kje:
- Referenca (obvezno) - sklic na celico, ki vsebuje izvorni niz.
- Regular_expression (obvezno) - vzorec regex za ujemanje.
Pomembna opomba! Funkcija deluje samo v računalnikih z nameščenim paketom Ultimate Suite for Excel.
Opombe o uporabi
Da bo vaše učenje potekalo lažje in izkušnja prijetnejša, bodite pozorni na naslednje točke:
- Če želite ustvariti formulo, lahko uporabite našo Orodja Regex ali Excelovo Funkcija vstavljanja Ko je formula vstavljena, jo lahko upravljate (urejate, kopirate ali premikate) kot katero koli drugo formulo.
- Vzorec, ki ga vnesete v Orodja Regex V tem primeru uporabite samo sklic na celico za 2. argument. Prav tako je mogoče ohraniti regularni izraz v ločeni celici. V tem primeru uporabite samo sklic na celico za 2. argument.
- Funkcija pridobi prvo najdeno ujemanje .
- Privzeto je funkcija , ki upošteva velike in male črke. . Za ujemanje brez upoštevanja velikosti črk uporabite vzorec (?i).
- Če ujemanje ni najdeno, se vrne napaka #N/A.
Regex za izvleček niza med dvema znakoma
Če želite pridobiti besedilo med dvema znakoma, lahko uporabite skupino za zajemanje ali obhode.
Recimo, da želite izločiti besedilo med oklepaji. Najlažji način je skupina za zajemanje.
Vzorec 1 : \[(.*?)\]
S pozitivnim pogledom nazaj in naprej bo rezultat popolnoma enak.
Vzorec 2 : (?<=\[)(.*?)(?=\])
Bodite pozorni, da naša skupina za zajemanje (.*?) izvede leno iskanje za besedilo med dvema oklepajema - od prvega [ do prvega ]. Zajemalna skupina brez vprašalnega znaka (.*) bi naredila požrešno iskanje in zajamete vse od prvega do zadnjega posnetka.
Z vzorcem v A2 je formula naslednja:
=AblebitsRegexExtract(A5, $A$2) 
Kako dobiti vse tekme
Kot smo že omenili, lahko funkcija AblebitsRegexExtract izlušči le eno ujemanje. Če želite pridobiti vsa ujemanja, lahko uporabite funkcijo VBA, o kateri smo govorili prej. Vendar pa obstaja en zadržek - VBA RegExp ne podpira zajemanja skupin, zato bo zgornji vzorec vrnil tudi "mejne" znake, v našem primeru oklepaje.
=TEXTJOIN(" ", TRUE, RegExpExtract(A5, $A$2)) 
Če se želite znebiti oklepajev, jih zamenjajte s praznimi nizi ("") s to formulo:
=SUBSTITUTE(SUBSTITUTE(TEXTJOIN(", ", TRUE, RegExpExtract(A5, $A$2)), "]", ""),"[","")
Za boljšo berljivost uporabljamo vejico kot ločilo. 
Regex za izpis besedila med dvema nizoma
Pristop, ki smo ga uporabili za pridobivanje besedila med dvema znakoma, bo deloval tudi za pridobivanje besedila med dvema nizoma.
Če želite na primer pridobiti vse med "test 1" in "test 2", uporabite naslednji regularni izraz.
Vzorec : test 1(.*?)test 2
Celotna formula je:
=AblebitsRegexExtract(A5, "test 1(.*?)test 2") 
Regex za pridobivanje domene iz naslova URL
Tudi z uporabo regularnih izrazov izločanje domenskih imen iz naslovov URL ni trivialna naloga. Ključni element, ki opravi trik, so skupine, ki ne zajemajo domen. Glede na končni cilj izberite enega od spodnjih regeksov.
Če želite pridobiti celotno ime domene vključno s poddomenami
Vzorec : (?:https?\:
Če želite pridobiti druga raven domena brez poddomen
Vzorec : (?:https?\:
Oglejmo si, kako ti regularni izrazi delujejo na primeru "//www.mobile.ablebits.com" kot vzorčnega naslova URL:
- (?:https?\:
- \/\\/ - dve sprednji poševnici (pred njima je povratna poševnica, da se izognemo posebnemu pomenu sprednje poševnice in jo razlagamo dobesedno).
- (?:[A-Za-z\d\-\.]{2,255}\.)? - skupina, ki ne zajema, za identifikacijo domen tretje, četrte itd. ravni, če obstajajo ( mobilni v našem vzorcu URL). V prvem vzorcu je umeščen v večjo skupino za zajemanje, da se v ekstrakcijo vključijo vse take poddomene. Poddomena je lahko dolga od 2 do 255 znakov, zato je kvantifikator {2,255}.
- ([A-Za-z\d\-]{1,63}\.[A-Za-z]{2,24}) - zajemalna skupina za izpis domene druge ravni ( ablebits ) in domeno najvišje ravni ( com ). največja dolžina domene druge ravni je 63 znakov. najdaljša trenutno obstoječa domena najvišje ravni vsebuje 24 znakov.
Glede na to, kateri regularni izraz je vnesen v A2, bo spodnja formula dala različne rezultate:
=AblebitsRegexExtract(A5, $A$2)
Regex za izpis celotno ime domene z vsemi poddomenami: 
Regex za izločanje druga raven domena brez poddomen: 
To je način izločanja delov besedila v Excelu z uporabo regularnih izrazov. Zahvaljujem se vam za branje in se veselim, da se naslednji teden vidimo na našem blogu!
Razpoložljivi prenosi
Excel Regex Izvleček primerov (.xlsm datoteka)
Poskusna različica paketa Ultimate Suite (.exe datoteka)
