
Table of contents
在本教程中,你将学习如何在Excel中使用正则表达式来查找和提取与给定模式相匹配的子串。
Microsoft Excel提供了一些从单元格中提取文本的函数。 这些函数可以应对工作表中大多数的字符串提取挑战。 大多数,但不是全部。 当文本函数出现问题时,正则表达式就会来拯救你。 等等,Excel没有RegEx函数!确实,没有内置的函数。 但没有什么可以阻止你使用自己的函数:)
Excel VBA Regex函数提取字符串
要在你的Excel中添加一个自定义的Regex提取函数,请在VBA编辑器中粘贴以下代码。 为了在VBA中启用正则表达式,我们使用了内置的Microsoft RegExp对象。
Public Function RegExpExtract(text As String , pattern As String , Optional instance_num As Integer = 0, Optional match_case As Boolean = True ) Dim text_matches() As String Dim matches_index As Integer On Error GoTo ErrHandl RegExpExtract = "" Set regex = CreateObject ( "VBScript.RegExp" ) regex.pattern = pattern regex.Global = True regex.MultiLine = True If True = match_case Thenregex.ignorecase = False Else regex.ignorecase = True End If Set matches = regex.Execute(text) If 0 <matches.Count Then If (0 = instance_num) Then ReDim text_matches(matches.Count - 1, 0) For matches_index = 0 To matches.Count - 1 text_matches(match_index, 0) = matches.Item(match_index) Next matches_index RegExpExtract = text_matches Else RegExpExtract = matches.Item(instance_num - 1) EndIf End If 退出函数 ErrHandl: RegExpExtract = CVErr(xlErrValue) 结束函数如果你对VBA没有什么经验,一份逐步的用户指南可能会有帮助:如何在Excel中插入VBA代码。
注意:为了使该功能发挥作用,请确保将你的文件保存为 支持宏的工作簿 (.xlsm)。
正则Extract的语法
ǞǞǞ 正则Extract 函数在输入字符串中搜索与正则表达式相匹配的值,并提取一个或所有匹配的值。
该函数的语法如下。
正则Extract(text, pattern, [instance_num], [match_case])在哪里?
- 文本 (required) - 要搜索的文本字符串。
- 样式 (required) - 要匹配的正则表达式。 当直接在公式中提供时,模式应该用双引号括起来。
- Instance_num (可选) - 一个序列号,表示要提取的实例。 如果省略,则返回所有找到的匹配数据(默认)。
- Match_case (可选) - 定义是否匹配或忽略文本大小写。 如果为 "true "或省略(默认),则进行区分大小写的匹配;如果为 "false "则不区分大小写。
该功能可在所有版本的Excel 365、Excel 2021、Excel 2019、Excel 2016、Excel 2013和Excel 2010中使用。
关于RegExpExtract你应该知道的4件事
要在你的Excel中有效地使用这个函数,有几个重要的事项需要注意。
- 默认情况下,该函数返回 所有发现的匹配 要想获得一个特定的发生,可以给一个相应的数字到 实例_num 争论。
- 在默认情况下,该函数是 区分大小写 对于不区分大小写的匹配,可将 match_case 由于VBA的限制,不区分大小写的结构(?i)将无法工作。
- 如果一个 没有找到有效的模式 ,该函数不返回任何东西(空字符串)。
- 如果 模式是无效的 ,发生#VALUE!错误。
在你开始在工作表中使用这个自定义函数之前,你需要了解它的能力,对吗? 下面的例子涵盖了一些常见的使用情况,并解释了为什么在动态阵列Excel(Microsoft 365和Excel 2021)和传统Excel(2019和旧版本)中行为可能不同。
注意:外面的正则表达式例子是为简单的数据集编写的。 我们不能保证它们在你的真实工作表中能完美地工作。 那些有正则表达式经验的人都会同意,编写正则表达式是一条永无止境的完美之路--几乎总是有办法使它更优雅或能够处理更广泛的输入数据。
从字符串中提取数字的Regex
遵循 "从简单到复杂 "的基本教学原则,我们将从一个非常简单的案例开始:从字符串中提取数字。
你要决定的第一件事是检索哪个号码:第一个、最后一个、特定发生的还是所有号码。
提取第一个数字
这是最简单的正则表达式。 鉴于\d表示从0到9的任何数字,+表示一次或多次,我们的正则表达式采取这种形式。
样式 : \d+
设置 实例_num 到1,你就会得到想要的结果。
=RegExpExtract(A5, "\d+", 1)
其中A5是原始字符串。
为方便起见,你可以在一个预定义的单元格($A$2 )中输入模式,并用$符号锁定其地址。
=RegExpExtract(A5, $A$2, 1) 
获取最后一个号码
要提取一个字符串中的最后一个数字,这里要使用的模式是。
样式 : (d+)(?!.*/d)
翻译成人类的语言,它说:找到一个没有任何其他数字跟随(任何地方,不仅仅是立即)的数字。 为了表达这一点,我们使用一个负数的前瞻(?!.*\d),这意味着在图案的右边应该没有其他数字(\d),不管前面有多少其他字符。
=RegExpExtract(A5, "(\d+)(?!.*\d)" ) 
提示。
- 为了获得 具体发生情况 ,使用 \d+ 表示 模式 和一个适当的序列号,用于 实例_num .
- 提取的公式是 所有数字 在下一个例子中讨论。
提取所有匹配的Regex
把我们的例子再推进一步,假设你想从一个字符串中获得所有的数字,而不是只有一个。
正如你可能记得的那样,提取的匹配数量是由可选的 实例_num 默认是全部匹配,所以你只需省略这个参数。
=RegExpExtract(A2, "\d+")
该公式对单个单元格来说效果很好,但在动态阵列Excel和非动态版本中的行为不同。
Excel 365和Excel 2021
由于对动态数组的支持,一个常规公式会自动溢出到显示所有计算结果所需的多个单元格中。 就Excel而言,这被称为溢出区域。 
Excel 2019及以下版本
在前动态Excel中,上述公式只返回一个匹配项。 要获得多个匹配项,你需要把它变成一个数组公式。 为此,选择一个单元格区域,输入公式,然后按Ctrl + Shift + Enter完成。
这种方法的缺点是在 "额外的单元格 "中出现了一堆#N/A错误。 遗憾的是,对此无能为力(IFERROR和IFNA都不能修复它,唉)。 
在一个单元格中提取所有匹配的内容
当处理一列数据时,上述方法显然是行不通的。 在这种情况下,理想的解决方案是在一个单元格中返回所有的匹配结果。 要做到这一点,将RegExpExtract的结果提供给TEXTJOIN函数,并用任何你喜欢的分隔符来分隔它们,例如逗号和空格。
=TEXTJOIN(", ", TRUE, RegExpExtract(A5, "\d+")) 
注意:由于TEXTJOIN函数仅在Excel for Microsoft 365、Excel 2021和Excel 2019中可用,该公式在旧版本中无法使用。
从字符串中提取文本的Regex
在Excel中,从字母数字字符串中提取文本是一项相当具有挑战性的任务。 有了regex,它变得易如反掌。 只需使用一个否定的类来匹配所有不是数字的东西。
样式 : [^\d]+
要获得单个单元格(溢出范围)中的子串,公式为:。
=RegExpExtract(A5, "[^\d]+") 
要把所有的匹配结果输出到一个单元格中,可以像这样把RegExpExtract函数嵌套在TEXTJOIN中。
=TEXTJOIN("", TRUE, RegExpExtract(A5, "[^\d]+")) 
从字符串中提取电子邮件地址的Regex
要从一个包含大量不同信息的字符串中提取出一个电子邮件地址,请编写一个复制电子邮件地址结构的正则表达式。
样式 : [\w\.\-]+@[A-Za-z0-9\.\-]+\.[A-Za-z]{2,24}
分解这个词组,我们得到的结果如下。
- [\w\.\-]+是一个用户名,可以包括1个或多个字母数字字符、下划线、点和连字符。
- @ 符号
- [A-Za-z0-9\.\-]+是一个域名,包括:大写和小写字母、数字、连字符和点(在子域的情况下)。 这里不允许使用下划线,因此使用3个不同的字符集(如A-Z a-z和0-9)而不是匹配任何字母、数字或下划线的\w。
- \[A-Za-z]{2,24}是一个顶级域名,由一个点和大、小写字母组成。 大多数顶级域名的长度为3个字母(如.com.org,.edu等),但理论上它可以包含2到24个字母(最长的注册顶级域名)。
假设字符串在A5中,模式在A2中,提取电子邮件地址的公式是。
=RegExpExtract(A5, $A$2) 
从电子邮件中提取域名的Regex
当谈到提取电子邮件域名时,人们首先想到的是使用一个捕捉组来寻找紧随@字符的文本。
样式 : @([A-Za-z0-9\.\-]+\.[A-Za-z]{2,24})
将其送入我们的正则函数。
=RegExpExtract(A5, "@([A-Za-z0-9\.\-]+\.[A-Za-z]{2,24})")
然后你会得到这个结果。 
在经典的正则表达式中,捕获组以外的任何东西都不包括在提取范围内。 没有人知道为什么VBA RegEx的工作方式不同,也会捕获"@"。 为了摆脱它,你可以从结果中删除第一个字符,用一个空字符串替换它。
=REPLACE(RegExpExtract(A5, "@([a-z\d][a-z\d\-\.]*.[a-z]{2,})", 1, FALSE), 1, 1, "") 
用正则表达式提取电话号码
电话号码有许多不同的写法,这就是为什么几乎不可能想出一个在所有情况下都有效的解决方案。 尽管如此,你可以写下你的数据集中使用的所有格式,并尝试与之匹配。
在这个例子中,我们将创建一个将提取任何这些格式的电话号码的词条。
(123) 345-6789 (123) 345 6789 (123)3456789 123-345-6789 See_also: Excel MATCH函数与公式实例 | 123.345.6789 123 345 6789 1233456789 |
样式 : \(?\d{3}[-\.\)]*\d{3}[-.]?\d{4}\b
- 第一部分 \(?\d{3} 匹配零或一个开口括号,后面是三个数字d{3}。
- [-\. \)]*部分是指方括号内出现0次或更多次的任何字符:连字符、句号、空格或闭合括号。
- 接下来,我们又有三个数字d{3},后面是任何连字符、句号或空格[-/...]? 出现0次或1次。
- 在这之后,有一组四位数 (d{4}。
- 最后,有一个词的边界(b)定义,我们正在寻找的电话号码不能是一个更大的数字的一部分。
完整的公式是这样形成的。
=RegExpExtract(A5, "\(?\d{3}[-\. \)]*\d{3}[-\. ] ?\d{4}\b") 
请注意,上述的正则表达式可能会返回一些错误的结果,如123)456 7899或(123 456 7899。 下面的版本修复了这些问题。 然而,这种语法只在VBA正则函数中起作用,在经典正则表达式中不起作用。
样式 : (\(\d{3}\)
从字符串中提取日期的Regex
一个用于提取日期的正则表达式取决于日期在字符串中出现的格式。 例如。
要提取1/1/21或01/01/2021这样的日期,词组是:\d{1,2}\/\d{1,2}/(\d{4})
它搜索的是一组1或2个数字d{1,2},后面是斜线,后面是另一组1或2个数字,后面是斜线,后面是一组4或2个数字(\d{4})。第一个条件在交替OR结构中被匹配,其余条件不被检查。
要检索1-1-21或01-1-2021这样的日期,模式是:\d{1,2}-[A-Za-z]{3}-\d{2,4}。
它搜索一组1或2个数字,后面是连字符,后面是3个大写或小写字母,后面是连字符,后面是一组4或2个数字。
将这两种模式结合在一起后,我们得到了以下的词条。
样式 : \b\d{1,2}[\/-](\d{1,2})
在哪里?
- 第一部分是1或2位数:\d{1,2}。
- 第二部分是1或2位数字或3个字母:(\d{1,2})。
- 第三部分是一组4位或2位的数字:(\d{4})。
- 分隔符是正斜线或连字符:[\/-]
- 一个词的边界(b)被放在两边,以明确日期是一个独立的词,而不是一个更大的字符串的一部分。
正如你在下面的图片中所看到的,它成功地拉出了日期,并留下了诸如11/22/333这样的子串。 然而,它仍然返回错误的肯定结果。 在我们的案例中,A9中的子串11-ABC-2222在技术上是符合日期格式的 dd-mmm-yyy 并因此被提取出来。 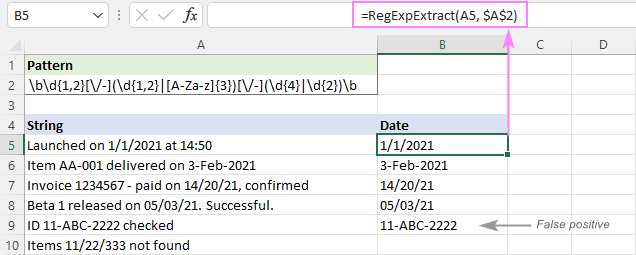
为了消除误报,你可以将[A-Za-z]{3}部分替换为3个字母的月份缩写的完整列表。
样式 : \b\d{1,2}[\/-](\d{1,2})
为了忽略字母大小写,我们将自定义函数的最后一个参数设置为FALSE。
=RegExpExtract(A5, $A$2, 1, FALSE)
而这一次,我们得到了一个完美的结果。 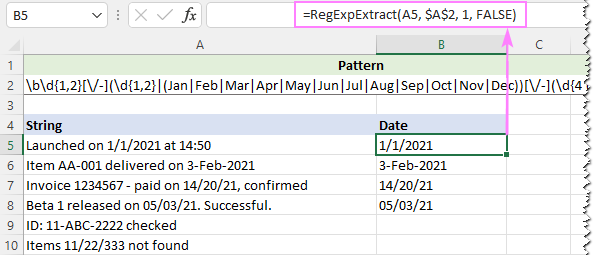
从字符串中提取时间的Regex
为了获得时间,在 hh:mm 或 hh:mm:ss 格式,下面的表达式会很有效。
样式 : \b(0?[0-9]
分解这个词组,你可以看到两个部分,分别由
表达方式1 : \b(0?[0-9]
检索带有AM/PM的时间。
一小时 可以是0到12之间的任何数字。 为了得到它,我们使用OR结构([0-9] )。
- [0-9] 匹配从0到9的任何数字
- 1[0-2] 匹配10至12的任何数字
分钟 [0-5]d是00到59之间的任何数字。
第二次 (:[0-5]\d)? 也是00到59之间的任何数字。 ? 量词表示零或一个出现,因为秒可能包括在时间值中,也可能不包括。
表达方式2 : \b([0-9]
提取不含AM/PM的时间。
ǞǞǞ 小时 部分可以是0到32之间的任何数字。 为了得到它,需要一个不同的OR结构([0-9] )。
- [0-9] 匹配从0到9的任何数字
- [0-1]/d 匹配从00到19的任何数字
- 2[0-3] 匹配20到23之间的任何数字
ǞǞǞ 分 和 第二 部分与上述表达式1相同。
负数的lookahead(?!:)被添加到跳过字符串中,如20:30:80。
由于PM/AM可以是大写或小写,我们使这个函数不区分大小写。
=RegExpExtract(A5, $A$2, 1, FALSE) 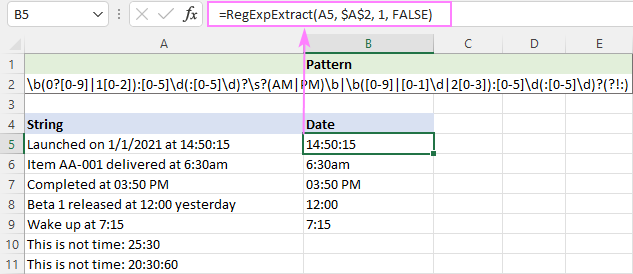
希望上面的例子能给你一些如何在你的Excel工作表中使用正则表达式的想法。 不幸的是,并不是所有经典正则表达式的功能都能在VBA中得到支持。 如果你的任务不能用VBA RegExp完成,我鼓励你阅读下一部分,它讨论了很多更强大的.NET Regex函数。
自定义基于.NET的Regex函数来提取Excel中的文本
与任何Excel用户都可以编写的VBA正则函数不同,.NET RegEx是开发者的领域。 微软.NET框架支持与Perl 5兼容的全功能正则表达式语法。 本文不会教你如何编写这种函数(我不是程序员,对如何编写没有丝毫概念 :)
由标准的.NET RegEx引擎处理的四个强大的函数已经由我们的开发人员编写并包含在Ultimate Suite中。 下面,我们将演示一些专门为提取Excel中的文本而设计的函数的实际用途。
提示:关于.NET Regex语法的信息,请参考.NET正则表达式语言。
如何在Excel中使用正则表达式提取毒刺
假设你安装了最新版本的Ultimate Suite,使用正则表达式提取文本可以归结为以下两个步骤。
- 关于 阿博比特数据 选项卡,在 文本 组,点击 Regex工具 .

- 关于 Regex工具 窗格,选择源数据,输入你的Regex模式,并选择 萃取物 要想得到一个自定义函数的结果,而不是一个值,选择 作为一个公式插入 完成后,点击 萃取物 按钮。

结果将出现在你的原始数据右边的一个新栏目中。 
AblebitsRegexExtract的语法
我们的自定义函数有以下语法。
AblebitsRegexExtract( reference, regular_expression)在哪里?
- 参考资料 (required) - 对包含源字符串的单元格的引用。
- 正则表达式 (required) - 匹配的反义词模式。
重要提示!该功能只在安装了Ultimate Suite for Excel的机器上运行。
使用说明
为了使你的学习曲线更顺畅,使你的体验更愉快,请注意以下几点。
- 要创建一个公式,你可以使用我们的 Regex工具 ,或Excel的 插入功能 一旦公式被插入,你可以像管理任何本地公式一样管理它(编辑、复制或移动)。
- 你所输入的图案在 Regex工具 也可以将正则表达式保存在单独的单元格中。 在这种情况下,只需为第2个参数使用一个单元格引用。
- 该函数提取了 第一个发现的匹配 .
- 在默认情况下,该函数是 区分大小写 对于不区分大小写的匹配,使用(?i)模式。
- 如果没有找到匹配,将返回#N/A错误。
Regex提取两个字符之间的字符串
为了获得两个字符之间的文本,你可以使用捕捉组或查找法。
比方说,你想提取括号之间的文本。 捕捉组是最简单的方法。
模式1 : \[(.*?)\]
有了积极的后看和前看,结果将是完全一样的。
模式2 : (?<==[)(.*?)(?==])
请注意,我们的捕获组(.*?)执行的是 懒惰的搜索 一个没有问号(.*)的抓取组将做一个 贪婪的搜索 并捕捉到从第一个[ 到最后一个] 的一切。
在A2的模式下,公式如下。
=AblebitsRegexExtract(A5, $A$2) 
如何获得所有的比赛
如前所述,AblebitsRegexExtract函数只能提取一个匹配项。 要获得所有的匹配项,你可以使用我们前面讨论过的VBA函数。 然而,有一个注意事项--VBA RegExp不支持捕获组,所以上述模式也会返回 "边界 "字符,在我们的例子中就是括号。
=TEXTJOIN(" ", TRUE, RegExpExtract(A5, $A$2)) 
要去掉括号,用这个公式把它们换成空字符串("")。
=SUBSTITUTE(SUBSTITUTE(TEXTJOIN(", ", TRUE, RegExpExtract(A5, $A$2)), "]", ""), "[", ")
为了提高可读性,我们使用了逗号作为分隔符。 
Regex提取两个字符串之间的文本
我们为提取两个字符之间的文本而研究出来的方法,也适用于提取两个字符串之间的文本。
例如,要获得 "test 1 "和 "test 2 "之间的所有内容,使用以下正则表达式。
样式 : 测试1(.*?)测试2
完整的公式是:。
=AblebitsRegexExtract(A5, "test 1(.*?)test 2") 
从URL中提取域名的Regex
即使使用正则表达式,从URL中提取域名也不是一件轻而易举的事情。 做到这一点的关键因素是不抓取组。 根据你的最终目标,选择下面的一个正则表达式。
为了获得 全域名 包括子域
样式 : (?:https?\:
为了获得 二级 没有子域的域名
样式 : (?:https?\:
现在,让我们看看这些正则表达式在以"//www.mobile.ablebits.com "为例的URL上如何工作。
- (?:https?\:
- \/\/ - 两个正斜线(每个正斜线前都有一个反斜线,以摆脱正斜线的特殊含义,按字面意思解释)。
- (?:[A-Za-z\d\-\.]{2,255}?--非捕获组,用于识别第三级、第四级等域,如果有( 手机 在第一个模式中,它被放置在一个更大的捕获组中,以使所有这些子域被包括在提取中。 一个子域的长度可以是2到255个字符,因此有{2,255}的量词。
- ([A-Za-z\d-]{1,63}\.[A-Za-z]{2,24})--提取二级域的捕获组( 能手 )和顶级域名( com 二级域名的最大长度为63个字符。 目前存在的最长的顶级域名包含24个字符。
根据A2中输入的正则表达式,下面的公式将产生不同的结果。
=AblebitsRegexExtract(A5, $A$2)
Regex来提取 全域名 与所有子域。 
Regex来提取一个 二级 领域 没有子域。 
这就是如何在Excel中使用正则表达式提取部分文本的方法。 感谢你的阅读,并期待着下周在我们的博客上见到你!
可用的下载
Excel Regex Extract示例(.xlsm文件)。
终极套装试用版(.exe文件)。
