
Obsah
V tomto kurzu se naučíte používat regulární výrazy v aplikaci Excel k vyhledání a extrakci podřetězců odpovídajících zadanému vzoru.
Microsoft Excel nabízí řadu funkcí pro extrakci textu z buněk. Tyto funkce si poradí s většinou problémů s extrakcí řetězců v pracovních listech. S většinou, ale ne se všemi. Když textové funkce klopýtnou, přijdou na pomoc regulární výrazy. Počkat... Excel nemá žádné funkce RegEx! Pravda, žádné vestavěné funkce. Ale nic vám nebrání použít vlastní :).
Funkce Regex aplikace Excel VBA pro extrakci řetězců
Chcete-li do aplikace Excel přidat vlastní funkci Regex Extract, vložte do editoru VBA následující kód. Abychom mohli ve VBA používat regulární výrazy, používáme vestavěný objekt Microsoft RegExp.
Public Function RegExpExtract(text As String , pattern As String , Optional instance_num As Integer = 0, Optional match_case As Boolean = True ) Dim text_matches() As String Dim matches_index As Integer On Error GoTo ErrHandl RegExpExtract = "" Set regex = CreateObject ("VBScript.RegExp" ) regex.pattern = pattern regex.Global = True regex.MultiLine = True If True = match_case Thenregex.ignorecase = False Else regex.ignorecase = True End If Set matches = regex.Execute(text) If 0 <matches.Count Then If (0 = instance_num) Then ReDim text_matches(matches.Count - 1, 0) For matches_index = 0 To matches.Count - 1 text_matches(matches_index, 0) = matches.Item(matches_index) Next matches_index RegExpExtract = text_matches Else RegExpExtract = matches.Item(instance_num - 1) EndIf End If Exit Function ErrHandl: RegExpExtract = CVErr(xlErrValue) End FunctionPokud máte s VBA jen malé zkušenosti, může vám pomoci uživatelská příručka Krok za krokem: Jak vložit kód VBA do aplikace Excel.
Poznámka: Aby funkce fungovala, nezapomeňte soubor uložit jako sešit s povolenými makry (.xlsm).
Syntaxe RegExpExtract
Na stránkách RegExpExtract hledá ve vstupním řetězci hodnoty, které odpovídají regulárnímu výrazu, a extrahuje jednu nebo všechny shody.
Funkce má následující syntaxi:
RegExpExtract(text, pattern, [instance_num], [match_case])Kde:
- Text (povinné) - textový řetězec, ve kterém se má vyhledávat.
- Vzor (povinné) - regulární výraz, který má být porovnán. Pokud je vzor zadán přímo ve vzorci, měl by být uzavřen do dvojitých uvozovek.
- Instance_num (nepovinné) - pořadové číslo, které určuje, která instance se má extrahovat. Pokud je vynecháno, vrátí se všechny nalezené shody (výchozí).
- Match_case (nepovinné) - určuje, zda se mají porovnávat nebo ignorovat velká a malá písmena textu. Je-li TRUE nebo vynecháno (výchozí), porovnávají se velká a malá písmena; je-li FALSE, porovnávají se malá a velká písmena.
Funkce funguje ve všech verzích aplikací Excel 365, Excel 2021, Excel 2019, Excel 2016, Excel 2013 a Excel 2010.
4 věci, které byste měli vědět o RegExpExtract
Abyste mohli funkci v Excelu efektivně používat, je třeba dbát na několik důležitých věcí:
- Ve výchozím nastavení funkce vrací všechny nalezené shody do sousedních buněk, jak je znázorněno v tomto příkladu. Chcete-li získat konkrétní výskyt, zadejte odpovídající číslo do příkazu instance_num argument.
- Ve výchozím nastavení je funkce rozlišování velkých a malých písmen . Pro porovnávání bez rozlišení velkých a malých písmen nastavte parametr match_case argumentu na FALSE. Vzhledem k omezením VBA nebude fungovat konstrukce nerozlišující velká a malá písmena (?i).
- Pokud a nebyl nalezen platný vzor , funkce nevrátí nic (prázdný řetězec).
- Pokud vzor je neplatný , dojde k chybě #VALUE!.
Než začnete tuto vlastní funkci používat ve svých pracovních listech, musíte pochopit, co umí, že? Níže uvedené příklady zahrnují několik běžných případů použití a vysvětlují, proč se chování může lišit v aplikaci Excel s dynamickým polem (Microsoft 365 a Excel 2021) a v tradičním Excelu (2019 a starší verze).
Poznámka: Výstupní příklady regexů jsou napsány pro pohádkově jednoduché datové sady. Nemůžeme zaručit, že budou bezchybně fungovat i ve vašich skutečných tabulkách. Ti, kteří mají s regexy zkušenosti, se shodnou, že psaní regulárních výrazů je nekonečná cesta k dokonalosti - téměř vždy existuje způsob, jak je udělat elegantnější nebo jak je schopné zpracovat širší rozsah vstupních dat.
Regex pro extrakci čísla z řetězce
V souladu se základní zásadou výuky "od jednoduchého ke složitému" začneme velmi jednoduchým případem: extrakcí čísla z řetězce.
Nejprve se musíte rozhodnout, které číslo chcete načíst: první, poslední, konkrétní výskyt nebo všechna čísla.
Výpis prvního čísla
Vzhledem k tomu, že \d znamená jakoukoli číslici od 0 do 9 a + znamená jeden nebo vícekrát, má náš regulární výraz tento tvar:
Vzor : \d+
Sada instance_num na 1 a dosáhnete požadovaného výsledku:
=RegExpExtract(A5, "\d+", 1)
Kde A5 je původní řetězec.
Pro větší pohodlí můžete zadat vzor do předem definované buňky ($A$2 ) a uzamknout její adresu pomocí znaku $:
=RegExpExtract(A5, $A$2, 1) 
Získat poslední číslo
Chcete-li získat poslední číslo v řetězci, použijte tento vzor:
Vzor : (\d+)(?!.*\d)
Přeloženo do lidské řeči říká: najděte číslo, za kterým nenásleduje (nikde, nejen bezprostředně) žádná jiná číslice. Pro vyjádření tohoto požadavku používáme záporný lookahead (?!.*\d), což znamená, že napravo od vzoru by neměla být žádná další číslice (\d) bez ohledu na to, kolik dalších znaků je před ní.
=RegExpExtract(A5, "(\d+)(?!.*\d)") 
Tipy:
- Chcete-li získat konkrétní výskyt , použijte \d+ pro vzor a příslušné sériové číslo pro instance_num .
- Vzorec pro extrakci všechna čísla je popsán v dalším příkladu.
Regex pro extrakci všech shod
Pokud náš příklad posuneme o něco dále, předpokládejme, že chceme z řetězce získat všechna čísla, nikoli pouze jedno.
Jak si možná vzpomínáte, počet extrahovaných shod je řízen nepovinným parametrem instance_num Výchozí hodnota je všechny shody, takže tento parametr jednoduše vynecháte:
=RegExpExtract(A2, "\d+")
Vzorec funguje krásně pro jednu buňku, ale chování v dynamickém poli Excelu a v nedynamických verzích se liší.
Excel 365 a Excel 2021
Díky podpoře dynamických polí se běžný vzorec automaticky rozlévá do tolika buněk, kolik je potřeba k zobrazení všech vypočtených výsledků. Z hlediska aplikace Excel se tomu říká rozlitý rozsah: 
Excel 2019 a nižší
V předdynamickém Excelu by výše uvedený vzorec vrátil pouze jednu shodu. Chcete-li získat více shod, musíte z něj vytvořit vzorec pole. Za tímto účelem vyberte rozsah buněk, zadejte vzorec a dokončete jej stisknutím kláves Ctrl + Shift + Enter.
Nevýhodou tohoto přístupu je spousta chyb #N/A, které se objevují v "buňkách navíc". Bohužel s tím nelze nic dělat (IFERROR ani IFNA to bohužel neopraví). 
Výpis všech shod v jedné buňce
Při zpracování sloupce dat výše uvedený přístup samozřejmě nebude fungovat. V takovém případě by bylo ideálním řešením vrátit všechny shody v jedné buňce. Chcete-li to provést, naservírujte výsledky funkce RegExpExtract funkci TEXTJOIN a oddělte je libovolným oddělovačem, například čárkou a mezerou:
=TEXTJOIN(", ", TRUE, RegExpExtract(A5, "\d+")) 
Poznámka: Protože funkce TEXTJOIN je k dispozici pouze v aplikaci Excel pro Microsoft 365, Excel 2021 a Excel 2019, vzorec nebude fungovat ve starších verzích.
Regex pro extrakci textu z řetězce
Extrahovat text z alfanumerického řetězce je v Excelu poměrně náročný úkol. S regexem je to snadné jako facka. Stačí použít třídu negace, která odpovídá všemu, co není číslice.
Vzor : [^\d]+
Chcete-li získat podřetězce v jednotlivých buňkách (rozsah rozlití), vzorec je:
=RegExpExtract(A5, "[^\d]+") 
Chcete-li vypsat všechny shody do jedné buňky, vnořte funkci RegExpExtract do TEXTJOIN takto:
=TEXTJOIN("", TRUE, RegExpExtract(A5, "[^\d]+")) 
Regex pro extrakci e-mailové adresy z řetězce
Chcete-li z řetězce obsahujícího mnoho různých informací vytáhnout e-mailovou adresu, napište regulární výraz, který kopíruje strukturu e-mailové adresy.
Vzor : [\w\.\-]+@[A-Za-z0-9\.\-]+\.[A-Za-z]{2,24}
Rozložením tohoto regexu získáme následující výsledky:
- [\w\.\-]+ je uživatelské jméno, které může obsahovat 1 nebo více alfanumerických znaků, podtržítek, teček a pomlček.
- @ symbol
- [A-Za-z0-9\.\-]+ je název domény složený z velkých a malých písmen, číslic, pomlček a teček (v případě subdomén). Podtržítka zde nejsou povolena, proto se místo \w, které odpovídá jakémukoli písmenu, číslici nebo podtržítku, používají 3 různé znakové sady (například A-Z a-z a 0-9).
- \.[A-Za-z]{2,24} je doména nejvyšší úrovně. Skládá se z tečky následované velkými a malými písmeny. Většina domén nejvyšší úrovně má 3 písmena (např. .com .org, .edu atd.), ale teoreticky může obsahovat 2 až 24 písmen (nejdelší registrovaná TLD).
Za předpokladu, že řetězec je v poli A5 a vzor v poli A2, vzorec pro získání e-mailové adresy je:
=RegExpExtract(A5, $A$2) 
Regex pro extrakci domény z e-mailu
Pokud jde o extrakci e-mailové domény, první, co vás napadne, je použití zachytávací skupiny k vyhledání textu, který následuje bezprostředně za znakem @.
Vzor : @([A-Za-z0-9\.\-]+\.[A-Za-z]{2,24})
Podejte ji naší funkci RegExp:
=RegExpExtract(A5, "@([A-Za-z0-9\.\-]+\.[A-Za-z]{2,24})")
A získáte tento výsledek: 
U klasických regulárních výrazů není do extrakce zahrnuto nic mimo zachycující skupinu. Nikdo neví, proč RegEx VBA funguje jinak a zachycuje i znak "@". Chcete-li se ho zbavit, můžete první znak z výsledku odstranit tak, že ho nahradíte prázdným řetězcem.
=REPLACE(RegExpExtract(A5, "@([a-z\d][a-z\d\-\.]*\.[a-z]{2,})", 1, FALSE), 1, 1, "") 
Regulární výraz pro extrakci telefonních čísel
Telefonní čísla lze zapsat mnoha různými způsoby, a proto je téměř nemožné přijít s řešením fungujícím za všech okolností. Přesto si můžete zapsat všechny formáty používané v souboru dat a pokusit se je porovnat.
V tomto příkladu vytvoříme regex, který bude extrahovat telefonní čísla v některém z těchto formátů:
(123) 345-6789 (123) 345 6789 (123)3456789 123-345-6789 | 123.345.6789 123 345 6789 1233456789 |
Vzor : \(?\d{3}[-\. \)]*\d{3}[-\. ]?\d{4}\b
- První část \(?\d{3} odpovídá nule nebo jedné otevírací závorce následované třemi číslicemi d{3}.
- Část [-\. \)]* znamená jakýkoli znak v hranatých závorkách, který se vyskytuje 0 nebo vícekrát: pomlčka, tečka, mezera nebo uzavírací závorka.
- Dále máme opět tři číslice d{3} následované libovolnou pomlčkou, tečkou nebo mezerou [-\. ]?, které se vyskytují 0krát nebo 1krát.
- Poté následuje skupina čtyř číslic \d{4}.
- Nakonec je zde slovní hranice \b, která definuje, že hledané telefonní číslo nemůže být součástí většího čísla.
Kompletní vzorec má tento tvar:
=RegExpExtract(A5, "\(?\d{3}[-\. \)]*\d{3}[-\. ]?\d{4}\b") 
Upozorňujeme, že výše uvedený regex může vrátit několik falešně pozitivních výsledků, jako například 123) 456 7899 nebo (123 456 7899. Níže uvedená verze tyto problémy odstraňuje. Tato syntaxe však funguje pouze ve funkcích VBA RegExp, nikoli v klasických regulárních výrazech.
Vzor : (\(\d{3}\)
Regex pro extrakci data z řetězce
Regulární výraz pro extrakci data závisí na formátu, ve kterém se datum v řetězci vyskytuje. Například:
Chcete-li extrahovat data jako 1/1/21 nebo 01/01/2021, regex je: \d{1,2}\/\d{1,2}\/(\d{4}).
Vyhledá skupinu 1 nebo 2 číslic d{1,2} následovanou lomítkem, následovanou další skupinou 1 nebo 2 číslic, následovanou lomítkem, následovanou skupinou 4 nebo 2 číslic (\d{4}).první podmínka je v konstrukci alternace NEBO je splněna, ostatní podmínky se nekontrolují.
Chcete-li získat data, jako je 1.1.21 nebo 1.1.2021, vzor je: \d{1,2}-[A-Za-z]{3}-\d{2,4}.
Vyhledává skupinu 1 nebo 2 číslic, za nimiž následuje pomlčka, skupina 3 velkých nebo malých písmen, za nimiž následuje pomlčka a skupina 4 nebo 2 číslic.
Po spojení obou vzorů dohromady získáme následující regex:
Vzor : \b\d{1,2}[\/-](\d{1,2})
Kde:
- První část je 1 nebo 2 číslice: \d{1,2}
- Druhá část je buď 1 nebo 2 číslice nebo 3 písmena: (\d{1,2})
- Třetí část je skupina 4 nebo 2 číslic: (\d{4})
- Oddělovač je buď lomítko vpřed, nebo pomlčka: [\/-]
- Hranice slova \b je umístěna na obou stranách, aby bylo jasné, že datum je samostatné slovo, a ne součást většího řetězce.
Jak vidíte na obrázku níže, úspěšně vytáhne data a vynechá podřetězce, jako je 11/22/333. Stále však vrací falešně pozitivní výsledky. V našem případě podřetězec 11-ABC-2222 v A9 technicky odpovídá formátu data. dd-mmm-rrrr a proto je extrahován. 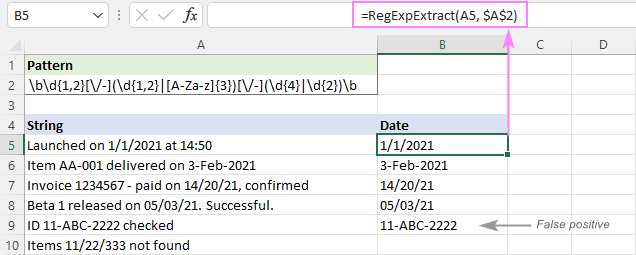
Chcete-li eliminovat falešně pozitivní výsledky, můžete část [A-Za-z]{3} nahradit úplným seznamem třípísmenných zkratek měsíců:
Vzor : \b\d{1,2}[\/-](\d{1,2})
Abychom ignorovali velikost písmen, nastavíme poslední argument naší vlastní funkce na hodnotu FALSE:
=RegExpExtract(A5, $A$2, 1, FALSE)
A tentokrát jsme dosáhli perfektního výsledku: 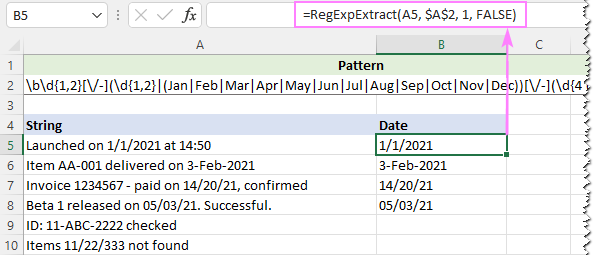
Regex pro extrakci času z řetězce
Chcete-li získat čas v hh:mm nebo hh:mm:ss bude fungovat následující výraz.
Vzor : \b(0?[0-9]
Při rozkladu tohoto regexu vidíte 2 části oddělené znakem
Vyjádření 1 : \b(0?[0-9]
Vyhledá časy s AM/PM.
Hodina může být libovolné číslo od 0 do 12. Abychom ho získali, použijeme konstrukci OR ([0-9]
- [0-9] odpovídá libovolnému číslu od 0 do 9
- 1[0-2] odpovídá libovolnému číslu od 10 do 12
Minutka [0-5]\d je libovolné číslo od 00 do 59.
Druhý (:[0-5]\d)? je také libovolné číslo od 00 do 59. Kvantifikátor ? znamená nula nebo jeden výskyt, protože sekundy mohou, ale nemusí být zahrnuty do hodnoty času.
Vyjádření 2 : \b([0-9]
Výpis časů bez AM/PM.
Na stránkách hodina část může být libovolné číslo od 0 do 32. Pro jeho získání se použije jiná konstrukce OR ([0-9]
- [0-9] odpovídá libovolnému číslu od 0 do 9
- [0-1]\d odpovídá libovolnému číslu od 00 do 19
- 2[0-3] odpovídá libovolnému číslu od 20 do 23
Na stránkách minuta a druhý části jsou stejné jako ve výrazu 1 výše.
Záporný lookahead (?!:) se přidává k řetězcům vynechání, jako je 20:30:80.
Protože PM/AM mohou být velká nebo malá písmena, nerozlišujeme velká a malá písmena:
=RegExpExtract(A5, $A$2, 1, FALSE) 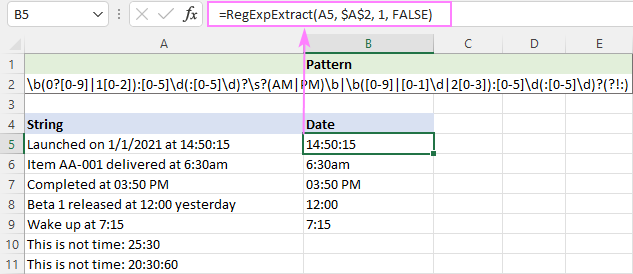
Doufám, že vám výše uvedené příklady poskytly několik nápadů, jak regulární výrazy v tabulkách Excelu používat. Bohužel ne všechny funkce klasických regulárních výrazů jsou ve VBA podporovány. Pokud váš úkol nelze pomocí VBA RegExp splnit, doporučuji vám přečíst si další část, která pojednává o mnohem výkonnějších funkcích .NET Regex.
Vlastní funkce Regex založená na technologii .NET pro extrakci textu v aplikaci Excel
Na rozdíl od funkcí VBA RegExp, které může napsat každý uživatel Excelu, jsou funkce .NET RegEx doménou vývojářů. Microsoft .NET Framework podporuje plnohodnotnou syntaxi regulárních výrazů kompatibilní s Perlem 5. Tento článek vás nenaučí, jak takové funkce psát (nejsem programátor a nemám nejmenší tušení, jak na to :).
Čtyři výkonné funkce zpracovávané standardním enginem .NET RegEx již napsali naši vývojáři a jsou součástí sady Ultimate Suite. Níže si ukážeme několik praktických použití funkce speciálně navržené pro extrakci textu v aplikaci Excel.
Tip. Informace o syntaxi jazyka .NET Regex naleznete v části Jazyk regulárních výrazů .NET.
Jak extrahovat žihadla v aplikaci Excel pomocí regulárních výrazů
Za předpokladu, že máte nainstalovanou nejnovější verzi sady Ultimate Suite, se extrakce textu pomocí regulárních výrazů omezuje na tyto dva kroky:
- Na Data Ablebits na kartě Text klikněte na tlačítko Nástroje Regex .

- Na Nástroje Regex vyberte zdrojová data, zadejte vzor Regex a vyberte možnost Výpis Chcete-li získat výsledek jako vlastní funkci, nikoli jako hodnotu, vyberte možnost Vložit jako vzorec Zaškrtněte políčko . Po dokončení klikněte na Výpis tlačítko.

Výsledky se zobrazí v novém sloupci napravo od původních dat: 
Syntaxe AblebitsRegexExtract
Naše vlastní funkce má následující syntaxi:
AblebitsRegexExtract(reference, regular_expression)Kde:
- Odkaz (povinné) - odkaz na buňku obsahující zdrojový řetězec.
- Regular_expression (povinné) - regexový vzor, který se má porovnat.
Důležitá poznámka! Funkce funguje pouze v počítačích s nainstalovanou sadou Ultimate Suite for Excel.
Poznámky k použití
Abyste se mohli učit plynuleji a aby se vám lépe pracovalo, věnujte prosím pozornost těmto bodům:
- K vytvoření vzorce můžete použít náš Nástroje Regex nebo aplikace Excel Vložit funkci nebo zadejte celý název funkce do buňky. Jakmile je vzorec vložen, můžete jej spravovat (upravovat, kopírovat nebo přesouvat) jako každý jiný vzorec.
- Vzor, který zadáte na Nástroje Regex panelu přejde na 2. argument. Regulární výraz je také možné ponechat v samostatné buňce. V tomto případě stačí použít odkaz na buňku pro 2. argument.
- Funkce extrahuje první nalezená shoda .
- Ve výchozím nastavení je funkce rozlišování velkých a malých písmen . Pro porovnávání bez rozlišení velkých a malých písmen použijte vzor (?i).
- Pokud není nalezena shoda, je vrácena chyba #N/A.
Regex pro extrakci řetězce mezi dvěma znaky
Chcete-li získat text mezi dvěma znaky, můžete použít buď zachycující skupinu, nebo hledání.
Řekněme, že chcete extrahovat text mezi závorkami. Nejjednodušší způsob je zachycení skupiny.
Vzor 1 : \[(.*?)\]
Při pozitivním pohledu dozadu a dopředu bude výsledek naprosto stejný.
Vzor 2 : (?<=\[)(.*?)(?=\])
Věnujte prosím pozornost tomu, že naše zachycující skupina (.*?) provádí líné vyhledávání pro text mezi dvěma závorkami - od prvního [ do prvního ]. Zachycení skupiny bez otazníku (.*) by provedlo chamtivé vyhledávání a zachytit vše od prvního [ až po poslední ].
Se vzorem v A2 je vzorec následující:
=AblebitsRegexExtract(A5, $A$2) 
Jak získat všechny zápasy
Jak již bylo zmíněno, funkce AblebitsRegexExtract dokáže extrahovat pouze jednu shodu. Chcete-li získat všechny shody, můžete použít funkci VBA, o které jsme hovořili dříve. Je zde však jedno upozornění - VBA RegExp nepodporuje zachycení skupin, takže výše uvedený vzor vrátí i "hraniční" znaky, v našem případě závorky.
=TEXTJOIN(" ", TRUE, RegExpExtract(A5, $A$2)) 
Chcete-li se zbavit závorek, PŘEDLOŽTE je prázdnými řetězci ("") podle tohoto vzorce:
=SUBSTITUTE(SUBSTITUTE(TEXTJOIN(", ", TRUE, RegExpExtract(A5, $A$2)), "]", ""),"[","")
Pro lepší čitelnost používáme jako oddělovač čárku. 
Regex pro extrakci textu mezi dvěma řetězci
Přístup, který jsme vypracovali pro extrakci textu mezi dvěma znaky, bude fungovat i pro extrakci textu mezi dvěma řetězci.
Chcete-li například získat vše mezi "test 1" a "test 2", použijte následující regulární výraz.
Vzor : test 1(.*?)test 2
Úplný vzorec je:
=AblebitsRegexExtract(A5, "test 1(.*?)test 2") 
Regex pro extrakci domény z adresy URL
Extrahovat názvy domén z adres URL není triviální úkol ani s regulárními výrazy. Klíčovým prvkem, který tento trik provádí, jsou skupiny bez zachycení. V závislosti na vašem konečném cíli si vyberte jeden z níže uvedených regexů.
Chcete-li získat celé jméno domény včetně subdomén
Vzor : (?:https?\:
Chcete-li získat druhá úroveň doména bez subdomén
Vzor : (?:https?\:
Nyní se podívejme, jak tyto regulární výrazy fungují na příkladu adresy URL "//www.mobile.ablebits.com":
- (?:https?\:
- \/\/ - dvě lomítka vpřed (před každým z nich je zpětné lomítko, aby se zabránilo zvláštnímu významu lomítka vpřed a interpretovalo se doslovně).
- (?:[A-Za-z\d\-\.]{2,255}\.)? - nezachycující skupina pro identifikaci domén třetí, čtvrté atd. úrovně, pokud existují ( mobilní v naší ukázkové adrese URL). V prvním vzoru je umístěn do větší zachycující skupiny, aby byly do extrakce zahrnuty všechny takové subdomény. Subdoména může mít délku 2 až 255 znaků, proto kvantifikátor {2,255}.
- ([A-Za-z\d\-]{1,63}\.[A-Za-z]{2,24}) - zachycující skupina pro extrakci domény druhé úrovně ( ablebits ) a domény nejvyšší úrovně ( com Maximální délka domény druhé úrovně je 63 znaků. Nejdelší v současnosti existující doména nejvyšší úrovně obsahuje 24 znaků.
V závislosti na tom, jaký regulární výraz je zadán v poli A2, bude níže uvedený vzorec poskytovat různé výsledky:
=AblebitsRegexExtract(A5, $A$2)
Regex pro extrakci celé jméno domény se všemi subdoménami: 
Regex pro extrakci druhá úroveň doména bez subdomén: 
To je návod, jak extrahovat části textu v Excelu pomocí regulárních výrazů. Děkuji vám za přečtení a těším se na vás na našem blogu příští týden!
Dostupné soubory ke stažení
Příklady extrakce regexů v aplikaci Excel (.xlsm soubor)
Zkušební verze sady Ultimate Suite (.exe soubor)
