
Indholdsfortegnelse
I denne vejledning lærer du, hvordan du bruger regulære udtryk i Excel til at finde og udtrække delstrenge, der matcher et givent mønster.
Microsoft Excel indeholder en række funktioner til at udtrække tekst fra celler. Disse funktioner kan klare de fleste udfordringer med at udtrække strenge i dine regneark. De fleste, men ikke alle. Når tekstfunktionerne snubler, kommer regulære udtryk til undsætning. Vent... Excel har ingen RegEx-funktioner! Ja, ingen indbyggede funktioner. Men der er intet, der forhindrer dig i at bruge dine egne :)
Excel VBA Regex-funktion til at udtrække strenge
Hvis du vil tilføje en brugerdefineret Regex Extract-funktion til din Excel, skal du indsætte følgende kode i VBA-editoren. For at aktivere regulære udtryk i VBA bruger vi det indbyggede Microsoft RegExp-objekt.
Public Function RegExpExtract(text As String , pattern As String , Optional instance_num As Integer = 0, Optional match_case As Boolean = True ) Dim text_matches() As String Dim matches_index As Integer On Error GoTo ErrHandl RegExpExtract = "" Set regex = CreateObject ( "VBScript.RegExp" ) regex.pattern = pattern regex.Global = True regex.MultiLine = True If True = match_case Thenregex.ignorecase = False Else regex.ignorecase = True End If Set matches = regex.Execute(text) If 0 <matches.Count Then If (0 = instance_num) Then ReDim text_matches(matches.Count - 1, 0) For matches_index = 0 To matches.Count - 1 text_matches(matches_index, 0) = matches.Item(matches_index) Next matches_index RegExpExtract = text_matches Else RegExpExtract = matches.Item(instance_num - 1) EndIf End If Exit Function ErrHandl: RegExpExtract = CVErr(xlErrValue) End FunctionHvis du har lidt erfaring med VBA, kan en trinvis brugervejledning være nyttig: Sådan indsætter du VBA-kode i Excel.
Bemærk. For at funktionen kan fungere, skal du sørge for at gemme din fil som en makroaktiveret arbejdsbog (.xlsm).
Syntaks for RegExpExtract
RegExpExtract funktionen søger i en indtastningsstreng efter værdier, der passer til et regulært udtryk, og udtrækker en eller alle overensstemmelser.
Funktionen har følgende syntaks:
RegExpExtract(text, pattern, [instance_num], [match_case])Hvor:
- Tekst (påkrævet) - den tekststreng, der skal søges i.
- Mønster (påkrævet) - det regulære udtryk, der skal matches. Når mønsteret angives direkte i en formel, skal det være omgivet af dobbelte anførselstegn.
- Instance_num (valgfrit) - et løbenummer, der angiver, hvilken instans der skal udtrækkes. Hvis udeladt, returneres alle fundne match (standard).
- Match_case (valgfrit) - angiver, om der skal matches eller ignoreres mellem store og små bogstaver i teksten. Hvis TRUE eller udeladt (standard), foretages der en case-sensitiv matchning; hvis FALSE - case-insensitiv.
Funktionen fungerer i alle versioner af Excel 365, Excel 2021, Excel 2019, Excel 2016, Excel 2013 og Excel 2010.
4 ting, du bør vide om RegExpExtract
For at bruge funktionen effektivt i Excel er der nogle få vigtige ting, som du skal være opmærksom på:
- Som standard returnerer funktionen alle fundne matches i tilstødende celler som vist i dette eksempel. Hvis du vil have en bestemt forekomst, skal du angive et tilsvarende nummer i instance_num argument.
- Som standard er funktionen skraldefølsom Hvis du vil have en matchning, der ikke tager hensyn til store og små bogstaver, skal du indstille match_case På grund af VBA-begrænsningerne virker den ikke-kriterieafhængige konstruktion (?i) ikke på grund af begrænsningerne i VBA.
- Hvis en gyldigt mønster er ikke fundet , returnerer funktionen intet (tom streng).
- Hvis den mønsteret er ugyldigt , opstår der en #VALUE! fejl.
Før du begynder at bruge denne brugerdefinerede funktion i dine regneark, skal du forstå, hvad den kan, ikke? Nedenstående eksempler dækker nogle få almindelige anvendelsestilfælde og forklarer, hvorfor opførslen kan være forskellig i Dynamic Array Excel (Microsoft 365 og Excel 2021) og traditionelt Excel (2019 og ældre versioner).
Bemærk: Vores regex-eksempler er skrevet til simple datasæt. Vi kan ikke garantere, at de vil fungere fejlfrit i dine rigtige regneark. De, der har erfaring med regex, vil være enige i, at det er en uendelig vej til perfektion at skrive regulære udtryk - næsten altid er der en måde at gøre det mere elegant eller i stand til at håndtere et bredere udvalg af inputdata.
Regex til at udtrække tal fra en streng
I overensstemmelse med den grundlæggende maksime om at undervise "fra det enkle til det komplekse" starter vi med et meget enkelt tilfælde: at udtrække tal fra en streng.
Det første du skal beslutte er, hvilket nummer der skal hentes: første, sidste, specifik forekomst eller alle numre.
Udtrække første nummer
Dette er så simpelt som regex kan blive. Eftersom \d betyder ethvert tal fra 0 til 9, og + betyder en eller flere gange, har vores regulære udtryk denne form:
Mønster : \d+
Indstil instance_num til 1, og du får det ønskede resultat:
=RegExpExtract(A5, "\d+", 1)
Hvor A5 er den oprindelige streng.
For nemheds skyld kan du indtaste mønsteret i en foruddefineret celle ($A$2 ) og låse dens adresse med $-tegnet:
=RegExpExtract(A5, $A$2, 1) 
Få det sidste nummer
Hvis du vil udtrække det sidste tal i en streng, skal du bruge følgende mønster:
Mønster : (\d+)(?!.*\d)
Oversat til et menneskesprog lyder det: Find et tal, der ikke efterfølges (hvor som helst, ikke kun umiddelbart) af et andet tal. For at udtrykke dette bruger vi en negativ lookahead (?!.*\d), hvilket betyder, at der til højre for mønsteret ikke må være noget andet tal (\d), uanset hvor mange andre tegn der er før det.
=RegExpExtract(A5, "(\d+)(?!.*\d)") 
Tips:
- For at få en specifik forekomst , bruge \d+ til mønster og et passende serienummer for instance_num .
- Formlen til udtrækning alle numre behandles i det næste eksempel.
Regex til at udtrække alle kampe
Hvis vi skubber vores eksempel lidt længere frem, kan vi antage, at du vil hente alle tal fra en streng og ikke kun ét.
Som du måske husker, styres antallet af udtrækkede matches af den valgfrie instance_num Standardindstillingen er alle kampe, så du kan blot udelade denne parameter:
=RegExpExtract(A2, "\d+")
Formlen fungerer fint for en enkelt celle, men opførslen er forskellig i Dynamic Array Excel og ikke-dynamiske versioner.
Excel 365 og Excel 2021
På grund af understøttelsen af dynamiske arrays bliver en almindelig formel automatisk spredt ud i så mange celler som nødvendigt for at vise alle beregnede resultater. I Excel kaldes dette et spildt område: 
Excel 2019 og lavere
I Excel før dynamisk Excel ville ovenstående formel kun give ét match. Hvis du vil have flere matches, skal du gøre formlen til en array-formel. Vælg et område af celler, skriv formlen, og tryk på Ctrl + Shift + Enter for at fuldføre den.
En ulempe ved denne fremgangsmåde er, at der opstår en masse #N/A-fejl i "ekstra celler". Desværre kan man ikke gøre noget ved det (hverken IFERROR eller IFNA kan desværre rette det). 
Udtrække alle kampe i en celle
Når du behandler en kolonne af data, vil ovenstående fremgangsmåde naturligvis ikke fungere. I dette tilfælde ville den ideelle løsning være at returnere alle resultater i en enkelt celle. For at få det gjort, skal du sende resultaterne af RegExpExtract til TEXTJOIN-funktionen og adskille dem med en vilkårlig afgrænser, f.eks. et komma og et mellemrum:
=TEXTJOIN(", ", ", TRUE, RegExpExtract(A5, "\d+"))) 
Bemærk: Da TEXTJOIN-funktionen kun er tilgængelig i Excel til Microsoft 365, Excel 2021 og Excel 2019, virker formlen ikke i ældre versioner.
Regex til at udtrække tekst fra en streng
At udtrække tekst fra en alfanumerisk streng er en ret udfordrende opgave i Excel. Med regex bliver det så let som ingenting. Brug blot en negeret klasse til at matche alt, der ikke er et ciffer.
Mønster : [^\d]+
For at få delstrenge i individuelle celler (spildområde) er formlen:
=RegExpExtract(A5, "[^\d]+") 
Hvis du vil have alle match i én celle, skal du integrere funktionen RegExpExtract i TEXTJOIN på følgende måde:
=TEXTJOIN("", TRUE, RegExpExtract(A5, "[^\d]+"))) 
Regex til at udtrække e-mail-adresse fra streng
Hvis du vil trække en e-mail-adresse ud af en streng, der indeholder mange forskellige oplysninger, skal du skrive et regulært udtryk, der kopierer e-mail-adressestrukturen.
Mønster : [\w\.\-]+@[A-Za-z0-9\.\-]+\.[A-Za-z]{2,24}
Hvis vi nedbryder denne regex, får vi følgende:
- [\w\.\-]+ er et brugernavn, der kan indeholde 1 eller flere alfanumeriske tegn, understregninger, prikker og bindestreger.
- @ symbol
- [A-Za-z0-9\.\-]+ er et domænenavn bestående af: store og små bogstaver, tal, bindestreger og prikker (i tilfælde af subdomæner). Understregninger er ikke tilladt her, og derfor anvendes 3 forskellige tegnsæt (f.eks. A-Z a-z og 0-9) i stedet for \w, der matcher ethvert bogstav, tal eller understregning.
- \.[A-Za-z]{2,24} er et topdomæne. Det består af et punkt efterfulgt af store og små bogstaver. De fleste topdomæner er på 3 bogstaver (f.eks. .com .org, .edu osv.), men i teorien kan det indeholde fra 2 til 24 bogstaver (det længste registrerede topdomæne).
Hvis vi antager, at strengen er i A5 og mønsteret i A2, er formlen til at udtrække en e-mail-adresse følgende:
=RegExpExtract(A5, $A$2) 
Regex til at udtrække domæne fra e-mail
Når det drejer sig om at udtrække e-mail-domænet, er den første tanke, der falder dig ind, at bruge en opfangningsgruppe til at finde tekst, der følger umiddelbart efter @-tegnet.
Mønster : @([A-Za-z0-9\.\-]+\.[A-Za-z]{2,24})
Send den til vores RegExp-funktion:
=RegExpExtract(A5, "@([A-Za-z0-9\.\-]+\.[A-Za-z]{2,24})")
Og du får dette resultat: 
Med klassiske regulære udtryk er alt uden for en fangstgruppe ikke med i udtrækket. Ingen ved, hvorfor VBA RegEx fungerer anderledes og også fanger "@". For at slippe af med det kan du fjerne det første tegn fra resultatet ved at erstatte det med en tom streng.
=REPLACE(RegExpExtract(A5, "@([a-z\d][a-z\d\d\-\.]*\..[a-z]{2,})", 1, FALSE), 1, 1, 1, "") 
Almindeligt udtryk til at udtrække telefonnumre
Telefonnumre kan skrives på mange forskellige måder, og derfor er det næsten umuligt at finde en løsning, der fungerer under alle omstændigheder. Du kan dog skrive alle de formater, der anvendes i dit datasæt, ned og forsøge at matche dem.
I dette eksempel vil vi oprette en regex, der vil udtrække telefonnumre i et af disse formater:
(123) 345-6789 (123) 345 6789 (123)3456789 123-345-6789 | 123.345.6789 123 345 6789 1233456789 |
Mønster : \(?\d{3}[-\. \)]*\d{3}[-\. ]?\d{4}\b
- Den første del \(?\d{3} svarer til nul eller én åbningsparentes efterfulgt af tre cifre d{3}.
- Ved [-\.. \)]* forstås ethvert tegn i firkantede parenteser, der forekommer 0 eller flere gange: bindestreg, punktum, mellemrum eller lukkende parentes.
- Dernæst har vi igen tre cifre d{3} efterfulgt af en bindestreg, et punktum eller et mellemrum [-\. ]? som forekommer 0 eller 1 gang.
- Derefter er der en gruppe på fire cifre \d{4}.
- Endelig er der en ordgrænse \b som definerer, at et telefonnummer, vi leder efter, ikke kan være en del af et større nummer.
Den fuldstændige formel ser således ud:
=RegExpExtract(A5, "\(?\d{3}[-\. \)]*\d{3}[-\. ]?\d{4}\b") 
Vær opmærksom på, at ovenstående regex kan give nogle få falske positive resultater som f.eks. 123) 456 7899 eller (123 456 7899. Den nedenstående version løser disse problemer. Denne syntaks fungerer dog kun i VBA RegExp-funktioner, ikke i klassiske regulære udtryk.
Mønster : (\(\d{3}\)
Regex til at udtrække dato fra streng
Et regulært udtryk til at udtrække en dato afhænger af det format, som datoen vises i en streng. F.eks:
For at udtrække datoer som 1/1/21 eller 01/01/2021 er regex'en: \d{1,2}\/\d{1,2}\/(\d{4}
Der søges efter en gruppe på 1 eller 2 cifre d{1,2} efterfulgt af en skråstreg, efterfulgt af en anden gruppe på 1 eller 2 cifre, efterfulgt af en skråstreg, efterfulgt af en gruppe på 4 eller 2 cifre (\d{4}den første betingelse er i alternationen OR-konstruktionen er matchet, kontrolleres de resterende betingelser ikke.
For at hente datoer som 1-Jan-21 eller 01-Jan-2021 er mønsteret: \d{1,2}-[A-Za-z]{3}-\d{2,4}
Der søges efter en gruppe på 1 eller 2 cifre efterfulgt af en bindestreg, efterfulgt af en gruppe på 3 store eller små bogstaver efterfulgt af en bindestreg og efterfulgt af en gruppe på 4 eller 2 cifre.
Når vi kombinerer de to mønstre, får vi følgende regex:
Mønster : \b\d{1,2}[\/-](\d{1,2}
Hvor:
- Den første del består af 1 eller 2 cifre: \d{1,2}
- Den anden del er enten 1 eller 2 cifre eller 3 bogstaver: (\d{1,2}
- Den tredje del er en gruppe på 4 eller 2 cifre: (\d{4}
- Afgrænseren er enten en skråstreg eller en bindestreg: [\/-]
- En ordgrænse \b er placeret på begge sider for at gøre det klart, at en dato er et separat ord og ikke en del af en større streng.
Som du kan se på billedet nedenfor, er det lykkedes at trække datoer ud og udelade delstrenge som 11/22/333. Der returneres dog stadig falske positive resultater. I vores tilfælde passer delstrengen 11-ABC-2222 i A9 teknisk set til datoformatet dd-mmm-yyyy og er derfor udtaget. 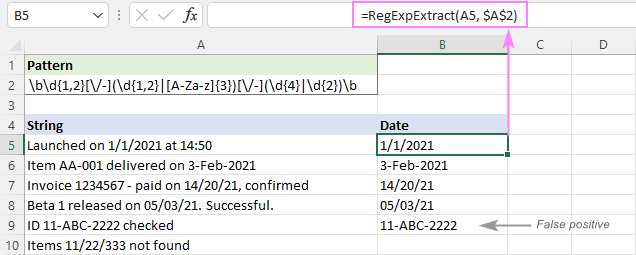
For at eliminere falske positive resultater kan du erstatte [A-Za-z]{3}-delen med en komplet liste over månedens forkortelser på 3 bogstaver:
Mønster : \b\d{1,2}[\/-](\d{1,2}
For at ignorere bogstaver, sætter vi det sidste argument i vores brugerdefinerede funktion til FALSE:
=RegExpExtract(A5, $A$2, 1, FALSE)
Og denne gang får vi et perfekt resultat: 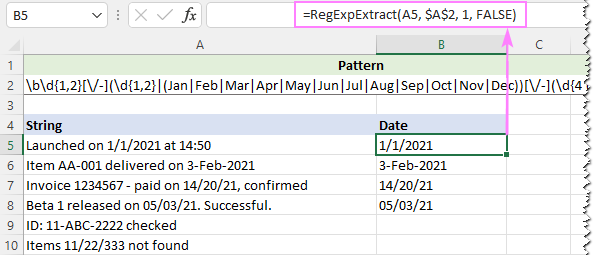
Regex til at udtrække tid fra streng
For at få tid i den hh:mm eller hh:mm:ss format, vil følgende udtryk fungere fint.
Mønster : \b(0?[0-9]
Ved at opdele denne regex kan du se 2 dele adskilt af
Udtryk 1 : \b(0?[0-9]
Henter tider med AM/PM.
Timer kan være et hvilket som helst tal fra 0 til 12. For at få det bruger vi OR-konstruktionen ([0-9]
- [0-9] passer til ethvert tal fra 0 til 9
- 1[0-2] passer til ethvert tal fra 10 til 12
Minut [0-5]\d er et vilkårligt tal fra 00 til 59.
Anden (:[0-5]\d)? er også et tal fra 00 til 59. Kvantifikatoren ? betyder nul eller én forekomst, da sekunder kan være inkluderet eller ikke kan være inkluderet i tidsværdien.
Udtryk 2 : \b([0-9]
Udvinder tider uden AM/PM.
time kan være et tal fra 0 til 32. For at få det, skal der anvendes en anden OR-konstruktion ([0-9]
- [0-9] passer til ethvert tal fra 0 til 9
- [0-1]\d passer til ethvert tal fra 00 til 19
- 2[0-3] passer til et vilkårligt tal fra 20 til 23
minut og anden dele er de samme som i udtryk 1 ovenfor.
Den negative lookahead (?!:) tilføjes til at springe strenge som f.eks. 20:30:80 over.
Da PM/AM kan være både store og små bogstaver, er funktionen ikke afgørende for store og små bogstaver:
=RegExpExtract(A5, $A$2, 1, FALSE) 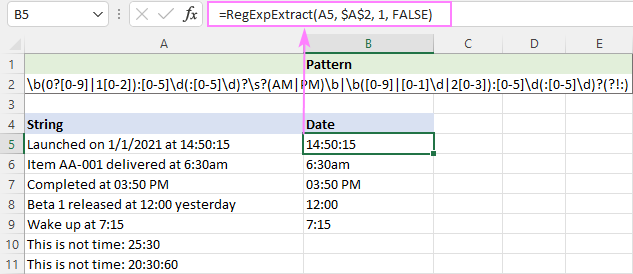
Forhåbentlig har ovenstående eksempler givet dig nogle ideer til, hvordan du kan bruge regulære udtryk i dine Excel-regneark. Desværre understøttes ikke alle funktioner i klassiske regulære udtryk i VBA. Hvis din opgave ikke kan løses med VBA RegExp, opfordrer jeg dig til at læse den næste del, som omhandler en masse mere kraftfulde .NET Regex-funktioner.
Brugerdefineret .NET-baseret Regex-funktion til at udtrække tekst i Excel
I modsætning til VBA RegExp-funktioner, der kan skrives af enhver Excel-bruger, er .NET RegEx udviklerens område. Microsoft .NET Framework understøtter en fuldt udbygget syntaks for regulære udtryk, der er kompatibel med Perl 5. Denne artikel vil ikke lære dig at skrive sådanne funktioner (jeg er ikke programmør og har ikke den mindste idé om, hvordan man gør det :)
Fire kraftfulde funktioner, der behandles af standard .NET RegEx-motoren, er allerede skrevet af vores udviklere og er inkluderet i Ultimate Suite. Nedenfor demonstrerer vi nogle praktiske anvendelser af funktionen, der er specielt designet til at udtrække tekst i Excel.
Tip. Du kan finde oplysninger om .NET Regex-syntaksen i .NET Regular Expression Language.
Sådan udtrækkes sting i Excel ved hjælp af regulære udtryk
Hvis du har den nyeste version af Ultimate Suite installeret, kan du udtrække tekst ved hjælp af regulære udtryk ved hjælp af disse to trin:
- På den Ablebits Data under fanen, i fanen Tekst gruppe, klik på Regex-værktøjer .

- På den Regex-værktøjer ruden, vælg kildedata, indtast dit Regex-mønster, og vælg den Uddrag Hvis du vil have resultatet som en brugerdefineret funktion og ikke som en værdi, skal du vælge indstillingen Indsæt som en formel afkrydsningsfeltet. Når du er færdig, skal du klikke på Uddrag knap.

Resultaterne vises i en ny kolonne til højre for dine oprindelige data: 
Syntaks for AblebitsRegexExtract
Vores brugerdefinerede funktion har følgende syntaks:
AblebitsRegexExtract(reference, regular_expression)Hvor:
- Henvisning (påkrævet) - en henvisning til den celle, der indeholder kildestrengen.
- Almindeligt_udtryk (påkrævet) - det regex-mønster, der skal matches.
Vigtig bemærkning! Funktionen fungerer kun på maskiner, hvor Ultimate Suite for Excel er installeret.
Brugsanvisninger
For at gøre din indlæringskurve lettere og din oplevelse mere behagelig, skal du være opmærksom på disse punkter:
- For at oprette en formel kan du bruge vores Regex-værktøjer , eller Excel's Indsæt funktion eller skriv det fulde funktionsnavn i en celle. Når formlen er indsat, kan du administrere den (redigere, kopiere eller flytte) som en hvilken som helst anden formel.
- Det mønster, du indtaster på Regex-værktøjer ruden går til det andet argument. Det er også muligt at holde et regulært udtryk i en separat celle. I dette tilfælde skal du blot bruge en cellehenvisning til det andet argument.
- Funktionen udtrækker den første fundne match .
- Som standard er funktionen skraldefølsom Hvis du ønsker at skelne mellem store og små bogstaver, skal du bruge mønsteret (?i).
- Hvis der ikke findes et match, returneres en #N/A-fejl.
Regex til at udtrække streng mellem to tegn
Hvis du vil have tekst mellem to tegn, kan du bruge enten en opfangningsgruppe eller opslagsveje.
Lad os sige, at du ønsker at udtrække tekst mellem parenteser. En opsamlingsgruppe er den nemmeste måde.
Mønster 1 : \[(.*?)\]
Med et positivt lookbehind og lookahead bliver resultatet nøjagtig det samme.
Mønster 2 : (?<=\[)(.*?)(?=\])
Vær opmærksom på, at vores opsamlingsgruppe (.*?) udfører en doven søgning for tekst mellem to parenteser - fra den første [ til den første ]. En fangstgruppe uden et spørgsmålstegn (.*) vil gøre en grådig søgning og fanger alt fra den første [ til den sidste ].
Med mønsteret i A2 lyder formlen som følger:
=AblebitsRegexExtract(A5, $A$2) 
Sådan får du alle kampe
Som allerede nævnt kan AblebitsRegexExtract-funktionen kun udtrække ét match. For at få alle matches kan du bruge VBA-funktionen, som vi har diskuteret tidligere. Der er dog et forbehold - VBA RegExp understøtter ikke indfangning af grupper, så ovenstående mønster vil også returnere "grænsekarakterer", i vores tilfælde parenteser.
=TEXTJOIN(" ", TRUE, RegExpExtract(A5, $A$2)) 
Hvis du vil slippe af med parenteserne, skal du SUBSTITUERE dem med tomme strenge ("") ved hjælp af denne formel:
=SUBSTITUTE(SUBSTITUTE(TEXTJOIN(", ", ", TRUE, RegExpExtract(A5, $A$2)), "]", ""),"[",""")
Af hensyn til læsbarheden bruger vi et komma som afgrænser. 
Regex til at udtrække tekst mellem to strenge
Den fremgangsmåde, vi har udviklet til at udtrække tekst mellem to tegn, vil også fungere til at udtrække tekst mellem to strenge.
Hvis du f.eks. vil have alt mellem "test 1" og "test 2", skal du bruge følgende regulære udtryk.
Mønster : test 1(.*?)test 2
Den fuldstændige formel er:
=AblebitsRegexExtract(A5, "test 1(.*?)test 2") 
Regex til at udtrække domæne fra URL
Selv med regulære udtryk er det ikke en triviel opgave at udtrække domænenavne fra URL'er. Det vigtigste element, der gør tricket, er ikke-fangende grupper. Afhængigt af dit endelige mål skal du vælge en af nedenstående regexer.
For at få en fuldstændigt domænenavn herunder underdomæner
Mønster : (?:https?\:
For at få en andet niveau domæne uden underdomæner
Mønster : (?:https?\:
Lad os nu se, hvordan disse regulære udtryk virker på et eksempel med "//www.mobile.ablebits.com" som en prøve-URL:
- (?:https?\:
- \/\// - to skråstreger fremad (hver af dem er indskudt af en bagudstreger for at undgå den særlige betydning af skråstregen fremad og fortolke den bogstaveligt).
- (?:[A-Za-z\d\d\-\.]{2,255}\..)?? - ikke-fangende gruppe til at identificere domæner på tredje niveau, fjerde niveau osv. mobil I det første mønster placeres det inden for en større fangstgruppe for at få alle sådanne underdomæner med i udtrækket. Et underdomæne kan være mellem 2 og 255 tegn langt, deraf kvantifikatoren {2,255}.
- ([A-Za-z\d\-]{1,63}\.[A-Za-z]{2,24}) - fanggruppe til udtrækning af domæne på andet niveau ( ablebits ) og top-level domænet ( com ). Den maksimale længde af et domæne på andet niveau er 63 tegn. Det længste topdomæne, der findes i øjeblikket, indeholder 24 tegn.
Afhængigt af hvilket regulært udtryk der er indtastet i A2, vil nedenstående formel give forskellige resultater:
=AblebitsRegexExtract(A5, $A$2)
Regex til at udtrække fuldstændigt domænenavn med alle underdomæner: 
Regex til at udtrække en andet niveau domæne uden underdomæner: 
Sådan uddrager du dele af tekst i Excel ved hjælp af regulære udtryk. Tak for din læsning, og jeg glæder mig til at se dig på vores blog i næste uge!
Tilgængelige downloads
Eksempler på Excel Regex-udtræk (.xlsm-fil)
Prøveversion af Ultimate Suite (.exe-fil)
