
Satura rādītājs
Šajā pamācībā uzzināsiet, kā lietot regulārās izteiksmes programmā Excel, lai atrastu un izdalītu apakšvirknes, kas atbilst dotajam paraugam.
Microsoft Excel piedāvā vairākas funkcijas teksta ieguvei no šūnām. Šīs funkcijas var tikt galā ar lielāko daļu virkņu ieguves problēmu jūsu darblapās. Lielāko daļu, bet ne visas. Kad teksta funkcijas paklūp, glābj regulārās izteiksmes. Pagaidiet... Excel nav RegEx funkciju! Tiesa, nav iebūvētu funkciju. Bet nekas neliedz jums izmantot savas :)
Excel VBA Regex funkcija virkņu izvilkšanai
Lai Excel programmā Excel pievienotu pielāgotu Regex Ekstrakta funkciju, VBA redaktorā ielīmējiet šādu kodu. Lai VBA iespējotu regulārās izteiksmes, mēs izmantojam iebūvēto Microsoft RegExp objektu.
Public Function RegExpExtract(text As String , pattern As String , Optional instance_num As Integer = 0, Optional match_case As Boolean = True ) Dim text_matches() As String Dim matches_index As Integer On Error GoTo ErrHandl RegExpExtract = "" Set regex = CreateObject ("VBScript.RegExp" ) regex.pattern = pattern regex.Global = True regex.MultiLine = True If True = match_case Thenregex.ignorrecase = False Else regex.ignorrecase = True End If Set matches = regex.Execute(text) If 0 <matches.Count Then If (0 = instance_num) Then If (0 = instance_num) Then ReDim text_matches(matches.Count - 1, 0) For matches_index = 0 To matches.Count - 1 text_matches(matches_index, 0) = matches.Item(matches_index) Next matches_index RegExpExtract = text_matches Else RegExpExtract = matches.Item(instance_num - 1) EndIf End If Exit Function ErrHandl: RegExpExtract = CVErr(xlErrValue) End FunctionJa jums ir neliela pieredze VBA izmantošanā, var noderēt lietotāja rokasgrāmata "Soli pa solim": Kā ievietot VBA kodu programmā Excel.
Piezīme. Lai funkcija darbotos, pārliecinieties, ka fails ir saglabāts kā darbgrāmata ar iespējotu makru (.xlsm).
RegExpExtract sintakse
Portāls RegExpExtract funkcija meklē ievades virknē vērtības, kas atbilst regulārajai izteiksmei, un izraksta vienu vai visas atbilstīgās vērtības.
Funkcijai ir šāda sintakse:
RegExpExtract(teksts, modelis, [instance_num], [match_case])Kur:
- Teksts (obligāts) - teksta virkne, kurā jāveic meklēšana.
- Modelis (obligāts) - regulārā izteiksme, kas jāsalīdzina. Ja to norāda tieši formulā, šablonam jābūt ieslēgtam dubultās pēdiņās.
- Instance_num (nav obligāts) - kārtas numurs, kas norāda, kuru gadījumu izvilkt. Ja netiek norādīts, tiek atgriezti visi atrastie sakritības gadījumi (noklusējuma iestatījums).
- Match_case (nav obligāts) - nosaka, vai teksta burtu un atbilžu gadījumā tiek veikta saskaņošana pēc burtu un atbilžu gadījumā - pēc burtu un atbilžu gadījumā - pēc burtu un atbilžu gadījumā - pēc burtu un atbilžu gadījumā.
Šī funkcija darbojas visās Excel 365, Excel 2021, Excel 2019, Excel 2019, Excel 2016, Excel 2013 un Excel 2010 versijās.
4 lietas, kas jāzina par RegExpExtract
Lai efektīvi izmantotu šo funkciju programmā Excel, jāņem vērā dažas svarīgas lietas:
- Pēc noklusējuma funkcija atgriež visas atrastās atbilstības blakus esošajās šūnās, kā parādīts šajā piemērā. Lai iegūtu konkrētu gadījumu, ievadiet atbilstošu skaitli vienumam instance_num arguments.
- Pēc noklusējuma funkcija ir lielo un mazo izmēru . Lai veiktu saskaņošanu bez lielo un mazo burtu un atbilžu, iestatiet match_case argumenta FALSE. Sakarā ar VBA ierobežojumiem lielo un mazo burtu un lielo izmēru nenoteiktības konstrukcija (?i) nedarbosies.
- Ja nav atrasts derīgs modelis , funkcija neatgriež neko (tukšu virkni).
- Ja modelis ir nederīgs , rodas #VALUE! kļūda.
Pirms sākat izmantot šo pielāgoto funkciju darblapās, jums ir jāsaprot, ko tā spēj, vai ne? Tālāk sniegtajos piemēros ir aplūkoti daži bieži sastopami lietošanas gadījumi un paskaidrots, kāpēc uzvedība var atšķirties dinamiskajā masīvā Excel (Microsoft 365 un Excel 2021) un tradicionālajā Excel (2019 un vecākās versijas).
Piezīme. Out regex piemēri ir rakstīti pasaku vienkāršām datu kopām. Mēs nevaram garantēt, ka tie darbosies nevainojami jūsu reālajās darblapās. Tie, kam ir pieredze ar regex, piekritīs, ka regulāru izteicienu rakstīšana ir nebeidzams ceļš uz pilnību - gandrīz vienmēr ir veids, kā to padarīt elegantāku vai spēj apstrādāt plašāku ievades datu klāstu.
Regekss, lai no virknes izvilktu skaitli
Ievērojot pamatprincipu "no vienkāršā uz sarežģīto", mēs sāksim ar ļoti vienkāršu gadījumu: skaitļa iegūšana no virknes.
Vispirms jums jāizlemj, kuru numuru izgūt: pirmo, pēdējo, konkrētu notikumu vai visus numurus.
Izraksts pirmais numurs
Ņemot vērā, ka \d nozīmē jebkuru ciparu no 0 līdz 9 un + nozīmē vienu vai vairākas reizes, mūsu regulārā izteiksme ir šāda:
Modelis : \d+
Komplekts instance_num uz 1, un tiks iegūts vēlamais rezultāts:
=RegExpExtract(A5, "\d+", 1)
kur A5 ir sākotnējā virkne.
Ērtības labad paraugu var ievadīt iepriekš definētā šūnā ($A$2 ) un bloķēt tās adresi ar zīmi $:
=RegExpExtract(A5, $A$2, 1) 
Iegūt pēdējo numuru
Lai virknē iegūtu pēdējo skaitli, šeit ir parādīts modelis, kas jāizmanto:
Modelis : (\d+)(?!.*\d)
Tulkojot cilvēka valodā, tas nozīmē: atrodi skaitli, aiz kura neseko (nekur, ne tikai uzreiz) neviens cits skaitlis. Lai to izteiktu, mēs izmantojam negatīvu lookahead (?!.*\d), kas nozīmē, ka pa labi no šablona nedrīkst būt neviena cita cipara (\d) neatkarīgi no tā, cik daudz citu zīmju ir pirms tā.
=RegExpExtract(A5, "(\d+)(?!.*\d)") 
Padomi:
- Lai iegūtu īpašs gadījums izmantot \d+ modelis un atbilstošu sērijas numuru instance_num .
- Formula, lai iegūtu visi skaitļi ir aplūkots nākamajā piemērā.
Regekss, lai iegūtu visas sakritības
Ja mūsu piemēru pavirzīsim nedaudz tālāk, pieņemsim, ka no virknes vēlaties iegūt visus skaitļus, nevis tikai vienu.
Kā jūs, iespējams, atceraties, iegūto atbilstību skaits tiek kontrolēts ar neobligāto parametru instance_num Noklusējuma iestatījums ir visas atbilstības, tāpēc šo parametru var vienkārši izlaist:
=RegExpExtract(A2, "\d+")
Formula darbojas lieliski vienai šūnai, taču dinamiskā masīva Excel un nedinamiskās versijās uzvedība atšķiras.
Excel 365 un Excel 2021
Pateicoties dinamisko masīvu atbalstam, regulārā formula automātiski izplūst tik daudzās šūnās, cik nepieciešams, lai parādītu visus aprēķinātos rezultātus. Excel terminoloģijā to sauc par izplūdušo diapazonu: 
Excel 2019 un zemāka
Pirms dinamiskā Excel programmā iepriekšminētā formula atgrieztu tikai vienu atbilstību. Lai iegūtu vairākas atbilstības, tā ir jāpadara par masīva formulu. Lai to izdarītu, atlasiet šūnu diapazonu, ievadiet formulu un nospiediet Ctrl + Shift + Enter, lai to pabeigtu.
Šīs pieejas trūkums ir tas, ka "papildu šūnās" parādās vairākas #N/A kļūdas. Diemžēl ar to neko nevar izdarīt (diemžēl ne IFERROR, ne IFNA to nevar novērst). 
Izvilkt visus vienādojumus vienā šūnā
Apstrādājot datu sleju, iepriekšminētā pieeja acīmredzot nedarbosies. Šajā gadījumā ideāls risinājums būtu atgriezt visas atbilstības vienā šūnā. Lai to izdarītu, iesniedziet RegExpExtract rezultātus funkcijai TEXTJOIN un atdaliet tos ar jebkuru norobežotāju, piemēram, komatu un atstarpi:
=TEXTJOIN(", ", TRUE, RegExpExtract(A5, "\d+")) 
Piezīme. Tā kā funkcija TEXTJOIN ir pieejama tikai Excel programmā Microsoft 365, Excel 2021 un Excel 2019, formula nedarbosies vecākās versijās.
Regekss teksta iegūšanai no virknes
Teksta iegūšana no burtciparu virknes ir diezgan sarežģīts uzdevums programmā Excel. Izmantojot regex, tas ir tikpat vienkārši kā pīrāgs. Vienkārši izmantojiet noliegto klasi, lai saskaņotu visu, kas nav cipars.
Modelis : [^\d]+
Lai iegūtu apakšvirsrakstus atsevišķās šūnās (noplūdes diapazons), formula ir šāda:
=RegExpExtract(A5, "[^\d]+") 
Lai visas sakritības izvadītu vienā šūnā, funkciju RegExpExtract ievietojiet TEXTJOIN šādā veidā:
=TEXTJOIN("", TRUE, RegExpExtract(A5, "[^\d]+")) 
Regekss, lai iegūtu e-pasta adresi no virknes
Lai no virknes, kas satur daudz dažādas informācijas, iegūtu e-pasta adresi, uzrakstiet regulāru izteiksmi, kas atveido e-pasta adreses struktūru.
Modelis : [\w\.\-]+@[A-Za-z0-9\.\-]+\.[A-Za-z]{2,24}
Ja sadalām šo regekss formulējumu, redzam, ko mēs iegūstam:
- [\w\.\-]+ ir lietotājvārds, kas var ietvert 1 vai vairākas burtu un ciparu zīmes, pasvītrojumus, punktus un defisi.
- @ simbols
- [A-Za-z0-9\.\-]+ ir domēna vārds, kas sastāv no lielajiem un mazajiem burtiem, cipariem, defisēm un punktiem (apakšdomēnu gadījumā). Šeit nav atļauti zemsvītras burti, tāpēc \w vietā tiek izmantotas 3 dažādas rakstzīmju kopas (piemēram, A-Z a-z un 0-9), kas atbilst jebkuram burtam, ciparam vai zemsvītrai.
- \.[A-Za-z]{2,24} ir augstākā līmeņa domēns. Sastāv no punkta, kam seko lielie un mazie burti. Lielākā daļa augstākā līmeņa domēnu ir trīsburtu garumā (piemēram, .com .org, .edu u. c.), bet teorētiski tas var saturēt no 2 līdz 24 burtiem (garākais reģistrētais TLD).
Pieņemot, ka virkne atrodas A5 un modelis A2, formula e-pasta adreses iegūšanai ir šāda:
=RegExpExtract(A5, $A$2) 
Regekss, lai iegūtu domēnu no e-pasta
Kad runa ir par e-pasta domēna ieguvi, pirmā doma, kas nāk prātā, ir izmantot uztveršanas grupu, lai atrastu tekstu, kas seko uzreiz pēc @ rakstzīmes.
Modelis : @([A-Za-z0-9\.\-]+\.[A-Za-z]{2,24})
Iesniedziet to mūsu funkcijai RegExp:
=RegExpExtract(A5, "@([A-Za-z0-9\.\-]+\.[A-Za-z]{2,24})")
Un iegūsiet šādu rezultātu: 
Izmantojot klasiskās regulārās izteiksmes, ekstrakcijā netiek iekļauts nekas, kas atrodas ārpus fiksēšanas grupas. Nevienam nav zināms, kāpēc VBA RegEx darbojas citādi un fiksē arī "@". Lai no tā atbrīvotos, varat no rezultāta izņemt pirmo rakstzīmi, aizstājot to ar tukšu virkni.
=REPLACE(RegExpExtract(A5, "@([a-z\d][a-z\d\-\.]*\.[a-z]{2,})", 1, FALSE), 1, 1, 1, "") 
Regulārā izteiksme tālruņa numuru izvilkšanai
Tālruņu numurus var pierakstīt dažādos veidos, tāpēc ir gandrīz neiespējami rast risinājumu, kas darbotos visos apstākļos. Tomēr varat pierakstīt visus datu kopā izmantotos formātus un mēģināt tos saskaņot.
Šajā piemērā izveidosim regeksi, kas izvilks tālruņa numurus jebkurā no šiem formātiem:
(123) 345-6789 (123) 345 6789 (123)3456789 123-345-6789 | 123.345.6789 123 345 6789 1233456789 |
Modelis : \(?\d{3}[-\. \)]*\d{3}[-\. ]?\d{4}\b
- Pirmā daļa \(?\d{3} atbilst nullei vai vienam atverošajam iekavam, kam seko trīs cipari d{3}.
- [-\. \)]* daļa nozīmē jebkuru kvadrātiekavās iekavās ievietotu rakstzīmi, kas parādās 0 vai vairāk reižu: defisi, punktu, atstarpi vai noslēdzošos iekavus.
- Tālāk atkal ir trīs cipari d{3}, kam seko jebkurš defise, punkts vai atstarpe [-\. ]?, kas parādās 0 vai 1 reizi.
- Pēc tam ir četru ciparu grupa \d{4}.
- Visbeidzot, ir vārda robeža \b, kas nosaka, ka meklētais tālruņa numurs nevar būt daļa no lielāka numura.
Pilna formula ir šāda:
=RegExpExtract(A5, "\(?\d{3}[-\. \)]*\d{3}[-\. ]?\d{4}\b") 
Lūdzu, ņemiet vērā, ka iepriekš minētā regekss var dot dažus viltus pozitīvus rezultātus, piemēram, 123) 456 7899 vai (123 456 7899. Tālāk sniegtajā versijā šīs problēmas ir novērstas. Tomēr šī sintakse darbojas tikai VBA RegExp funkcijās, nevis klasiskajās regulārajās izteiksmēs.
Modelis : (\(\d{3}\)
Regekss, lai izvilktu datumu no virknes
Regulārā izteiksme datuma iegūšanai ir atkarīga no formāta, kādā datums parādās rindā, piemēram:
Lai iegūtu tādus datumus kā 1/1/21 vai 01/01/2021, regekss ir šāds: \d{1,2}\/\d{1,2}\/(\d{4}
Tiek meklēta 1 vai 2 ciparu grupa d{1,2}, kam seko slīpsvītra, kam seko cita 1 vai 2 ciparu grupa, kam seko slīpsvītra, kam seko 4 vai 2 ciparu grupa (\d{4}).pirmais nosacījums ir pārmaiņus vai ir atbilstīgs, pārējie nosacījumi netiek pārbaudīti.
Lai iegūtu datumus, piemēram, 1-jan-21 vai 01-jan-2021, modelis ir šāds: \d{1,2}-[A-Za-z]{3}-\d{2,4}.
Tā meklē 1 vai 2 ciparu grupu, kam seko defise, kam seko 3 lielo vai mazo burtu grupa, kam seko defise, kam seko 4 vai 2 ciparu grupa.
Apvienojot abus šablonus kopā, iegūstam šādu regekss:
Modelis : \b\d{1,2}[\/-](\d{1,2}
Kur:
- Pirmā daļa ir 1 vai 2 cipari: \d{1,2}
- Otrā daļa ir 1 vai 2 cipari vai 3 burti: (\d{1,2})
- Trešā daļa ir 4 vai 2 ciparu grupa: (\d{4})
- Atdalītājs ir vai nu slīpsvītra uz priekšu, vai defise: [\/-]
- Vārda robeža \b ir novietota abās pusēs, lai skaidri parādītu, ka datums ir atsevišķs vārds, nevis daļa no lielākas virknes.
Kā redzams attēlā zemāk, tas veiksmīgi izvelk datumus un neiekļauj tādas apakšvirknes kā 11/22/333. Tomēr tas joprojām atgriež viltus pozitīvus rezultātus. Mūsu gadījumā A9 apakšvirkne 11-ABC-2222 tehniski atbilst datuma formātam. dd-mmm-ggggggg un tāpēc tiek ekstrahēts. 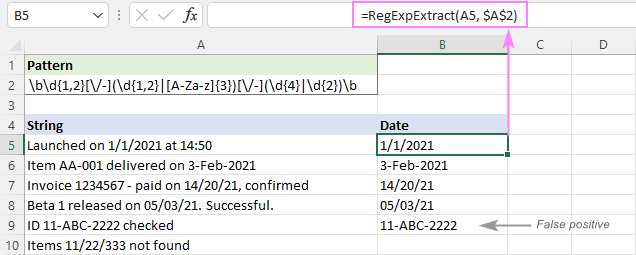
Lai novērstu viltus pozitīvos rezultātus, daļu [A-Za-z]{3} var aizstāt ar pilnu trīsburtu mēnešu saīsinājumu sarakstu:
Modelis : \b\d{1,2}[\/-](\d{1,2}
Lai ignorētu burtu burtu lielumu, mūsu pielāgotās funkcijas pēdējam argumentam tiek iestatīta vērtība FALSE:
=RegExpExtract(A5, $A$2, 1, FALSE)
Un šoreiz mēs iegūstam perfektu rezultātu: 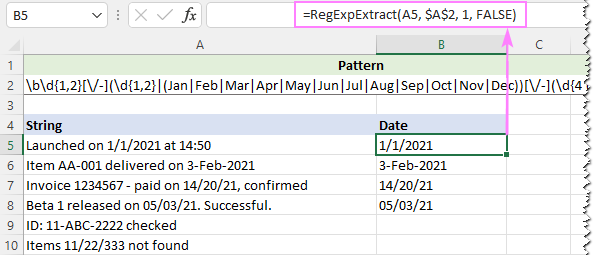
Regekss, lai iegūtu laiku no virknes
Lai iegūtu laiku hh:mm vai hh:mm:ss formātā, tiks izmantota šāda izteiksme.
Modelis : \b(0?[0-9]
Ja sadalām šo regekss formulējumu, redzam 2 daļas, kas atdalītas ar
Izteiksme 1 : \b(0?[0-9]
Atgūst laikus ar AM/PM.
Stunda var būt jebkurš skaitlis no 0 līdz 12. Lai to iegūtu, mēs izmantojam OR konstrukciju ([0-9]
- [0-9] atbilst jebkuram skaitlim no 0 līdz 9.
- 1[0-2] atbilst jebkuram skaitlim no 10 līdz 12.
Minūtes [0-5]\d ir jebkurš skaitlis no 00 līdz 59.
Otrais (:[0-5]\d)? ir arī jebkurš skaitlis no 00 līdz 59. Kvantifikators ? nozīmē nulli vai vienu gadījumu, jo sekundes var būt vai nebūt iekļautas laika vērtībā.
Izteiksme 2 : \b([0-9]
Izraksta laikus bez AM/PM.
Portāls stundu daļa var būt jebkurš skaitlis no 0 līdz 32. Lai to iegūtu, izmanto citu OR konstrukciju ([0-9]
- [0-9] atbilst jebkuram skaitlim no 0 līdz 9.
- [0-1]\d atbilst jebkuram skaitlim no 00 līdz 19
- 2[0-3] atbilst jebkuram skaitlim no 20 līdz 23.
Portāls minūte un otrais daļas ir tādas pašas kā 1. izteiksmē.
Negatīvais priekšvēstnesis (?!:) tiek pievienots izlaišanas virknēm, piemēram, 20:30:80.
Tā kā PM/AM var rakstīt gan ar lielajiem, gan ar mazajiem burtiem, mēs šajā funkcijā lielo un mazo burtu nesaredzam:
=RegExpExtract(A5, $A$2, 1, FALSE) 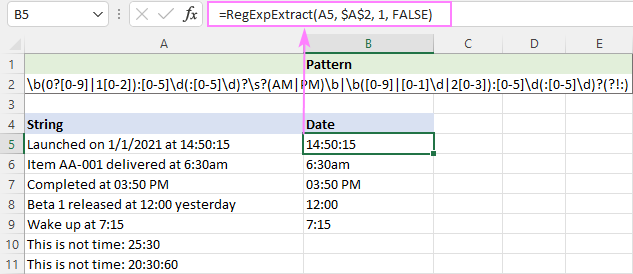
Cerams, ka iepriekš minētie piemēri sniedza jums dažas idejas par to, kā Excel darblapās izmantot regulārās izteiksmes. Diemžēl ne visas klasisko regulāro izteiksmes veidu funkcijas tiek atbalstītas VBA. Ja jūsu uzdevumu nevar izpildīt ar VBA RegExp, iesaku izlasīt nākamo daļu, kurā aplūkotas daudz jaudīgākas .NET Regex funkcijas.
Pielāgota .NET bāzēta Regex funkcija teksta izvilkšanai programmā Excel
Atšķirībā no VBA RegExp funkcijām, kuras var uzrakstīt jebkurš Excel lietotājs, .NET RegEx ir izstrādātāju darbības joma. Microsoft .NET Framework atbalsta pilnvērtīgu regulārās izteiksmes sintaksi, kas ir saderīga ar Perl 5. Šajā rakstā jūs nemācīsim, kā rakstīt šādas funkcijas (es neesmu programmētājs un man nav ne mazākās nojausmas, kā to darīt :).
Četras jaudīgas funkcijas, ko apstrādā standarta .NET RegEx dzinējs, jau ir uzrakstījuši mūsu izstrādātāji un ir iekļautas Ultimate Suite komplektā. Tālāk mēs demonstrēsim dažas praktiskas funkcijas, kas īpaši izstrādātas teksta ieguvei programmā Excel.
Padoms. Informāciju par .NET Regex sintaksi skatiet sadaļā .NET regulārās izteiksmes valoda.
Kā izvilkt dzeltenumus programmā Excel, izmantojot regulārās izteiksmes
Pieņemot, ka ir instalēta jaunākā Ultimate Suite versija, teksta ekstrahēšana, izmantojot regulārās izteiksmes, sastāv no šiem diviem soļiem:
- Par Ablebits dati cilnē Teksts grupu, noklikšķiniet uz Regekses rīki .

- Par Regekses rīki panelī atlasiet avota datus, ievadiet Regex modeli un izvēlieties Izraksts Lai iegūtu rezultātu kā pielāgotu funkciju, nevis vērtību, atlasiet opciju Ievietot kā formulu izvēles rūtiņu. Kad tas ir izdarīts, noklikšķiniet uz Izraksts pogu.

Rezultāti tiks parādīti jaunā slejā pa labi no sākotnējiem datiem: 
AblebitsRegexExtract sintakse
Mūsu pielāgotajai funkcijai ir šāda sintakse:
AblebitsRegexExtract(atsauce, regular_expression)Kur:
- Atsauce (obligāts) - atsauce uz šūnu, kurā atrodas avota virkne.
- Regular_expression (obligāts) - regekssaraksts, kam jāatbilst.
Svarīga piezīme! Šī funkcija darbojas tikai tajos datoros, kuros ir instalēts Ultimate Suite for Excel.
Lietošanas piezīmes
Lai mācīšanās process noritētu raitāk un pieredze būtu patīkamāka, pievērsiet uzmanību šiem punktiem:
- Lai izveidotu formulu, varat izmantot mūsu Regekses rīki vai Excel Ievietot funkciju Kad formula ir ievietota, varat to pārvaldīt (rediģēt, kopēt vai pārvietot) tāpat kā jebkuru citu formulu.
- Modelis, ko ievadāt Regekses rīki panelī tiek ievadīts 2. arguments. Regulāro izteiksmi ir iespējams saglabāt arī atsevišķā šūnā. Šajā gadījumā 2. argumentam vienkārši izmantojiet šūnas atsauci.
- Funkcija izraksta pirmais atrastais sakritības variants .
- Pēc noklusējuma funkcija ir lielo un mazo izmēru Lai veiktu saskaņošanu bez lielo un mazo burtu un atbilstu lielajiem burtiem, izmantojiet modeli (?i).
- Ja atbilstība nav atrasta, tiek atgriezta #N/A kļūda.
Regekss, lai iegūtu virkni starp divām rakstzīmēm
Lai iegūtu tekstu starp divām rakstzīmēm, varat izmantot vai nu uztveršanas grupu, vai arī apvedceļus.
Pieņemsim, ka vēlaties iegūt tekstu starp iekavām. Visvienkāršākais veids ir iegūt grupu.
1 modelis : \[(.*?)\]
Ar pozitīvu skatījumu uz priekšu un uz aizmuguri rezultāts būs tieši tāds pats.
2 modelis : (?<=\[)(.*?)(?=\])
Lūdzu, pievērsiet uzmanību tam, ka mūsu uztveršanas grupa (.*?) veic slinka meklēšana teksta starp diviem iekaviem - no pirmā [ līdz pirmajam ]. Ierobežojuma grupa bez jautājuma zīmes (.*) veidotu alkatīga meklēšana un fiksēt visu, sākot no pirmā [ līdz pēdējam ].
Izmantojot A2 modeli, formula ir šāda:
=AblebitsRegexExtract(A5, $A$2) 
Kā iegūt visas spēles
Kā jau minēts, ar funkciju AblebitsRegexExtract var iegūt tikai vienu sakritību. Lai iegūtu visas sakritības, varat izmantot VBA funkciju, par kuru runājām iepriekš. Tomēr ir viens brīdinājums - VBA RegExp neatbalsta grupu fiksēšanu, tāpēc iepriekš minētais modelis atgriezīs arī "robežzīmes", mūsu gadījumā - iekavās.
=TEXTJOIN(" ", TRUE, RegExpExtract(A5, $A$2)) 
Lai atbrīvotos no iekavām, aizstāt tās ar tukšām virknēm (""), izmantojot šo formulu:
=SUBSTITUTE(SUBSTITUTE(TEXTJOIN(", ", ", TRUE, RegExpExtract(A5, $A$2)), "]", ""),"[","")
Labākai lasāmībai mēs izmantojam komatu kā norobežotāju. 
Regex, lai iegūtu tekstu starp divām virknēm
Pieeja, ko esam izstrādājuši teksta izvilkšanai starp divām rakstzīmēm, darbojas arī teksta izvilkšanai starp divām virknēm.
Piemēram, lai iegūtu visu, kas atrodas starp "test 1" un "test 2", izmantojiet šādu regulāro izteiksmi.
Modelis : tests 1(.*?)tests 2
Pilna formula ir šāda:
=AblebitsRegexExtract(A5, "tests 1(.*?)tests 2") 
Regekss domēna izvilkšanai no URL
Pat izmantojot regulārās izteiksmes, domēna vārdu iegūšana no URL nav triviāls uzdevums. Galvenais elements, kas veic šo triku, ir neķeršanas grupas. Atkarībā no jūsu galīgā mērķa izvēlieties kādu no turpmāk minētajām regeksēm.
Lai iegūtu pilns domēna nosaukums ieskaitot apakšdomēnus
Modelis : (?:https?\:
Lai iegūtu otrā līmeņa domēns bez apakšdomēniem
Modelis : (?:https?\:
Tagad aplūkosim, kā šīs regulārās izteiksmes darbojas, izmantojot piemēru "//www.mobile.ablebits.com" kā parauga URL:
- (?:https?\:
- \/\/ - divas slīpsvītras uz priekšu (pirms katras no tām ir backslash, lai izvairītos no slīpsvītras uz priekšu īpašās nozīmes un interpretētu to burtiski).
- (?:[A-Za-z\d\-\-\]{2,255}\.)? - nefiksēšanas grupa, lai identificētu trešā līmeņa, ceturtā līmeņa utt. domēnus, ja tādi ir ( mobilais Mūsu parauga URL). Pirmajā rakstzīmē tas tiek ievietots lielākā ieguves grupā, lai ieguvē iekļautu visas šādas apakšdomēnas. Apakšdomēna garums var būt no 2 līdz 255 rakstzīmēm, tāpēc ir izmantots kvantifikators {2,255}.
- ([A-Za-z\d\-]{1,63}\.[A-Za-z]{2,24}) - pārtveršanas grupa, lai iegūtu otrā līmeņa domēnu ( ablebits ) un augstākā līmeņa domēna ( com ). Otrā līmeņa domēna maksimālais garums ir 63 rakstzīmes. Pašlaik garākais pastāvošais augstākā līmeņa domēns satur 24 rakstzīmes.
Atkarībā no tā, kāda regulārā izteiksme ir ievadīta A2, tālāk sniegtā formula dos dažādus rezultātus:
=AblebitsRegexExtract(A5, $A$2)
Regex, lai iegūtu pilns domēna nosaukums ar visām apakšdomēnām: 
Regex, lai iegūtu otrā līmeņa domēns bez apakšdomēniem: 
Lūk, kā izvilkt teksta daļas programmā Excel, izmantojot regulārās izteiksmes. Paldies, ka izlasījāt, un ar nepacietību gaidīsim jūs mūsu blogā nākamnedēļ!
Pieejamās lejupielādes
Excel Regex Ekstrakcijas piemēri (.xlsm fails)
Ultimate Suite izmēģinājuma versija (.exe fails)
