
Оглавление
В этом уроке вы узнаете, как использовать регулярные выражения в Excel для поиска и извлечения подстрок, соответствующих заданному шаблону.
Microsoft Excel предоставляет ряд функций для извлечения текста из ячеек. Эти функции могут справиться с большинством задач по извлечению строк в ваших рабочих листах. С большинством, но не со всеми. Когда текстовые функции спотыкаются, на помощь приходят регулярные выражения. Подождите... В Excel нет функций RegEx! Правда, нет встроенных функций. Но ничто не мешает вам использовать свои собственные :)
Функция Regex в Excel VBA для извлечения строк
Чтобы добавить пользовательскую функцию Regex Extract в Excel, вставьте следующий код в редактор VBA. Чтобы включить регулярные выражения в VBA, мы используем встроенный объект Microsoft RegExp.
Public Function RegExpExtract(text As String , pattern As String , Optional instance_num As Integer = 0, Optional match_case As Boolean = True ) Dim text_matches() As String Dim matches_index As Integer On Error GoTo ErrHandl RegExpExtract = "" Set regex = CreateObject ( "VBScript.RegExp" ) regex.pattern = pattern regex.Global = True regex.MultiLine = True If True = match_case Thenregex.ignorecase = False Else regex.ignorecase = True End If Set matches = regex.Execute(text) If 0 <matches.Count Then If (0 = instance_num) Then ReDim text_matches(matches.Count - 1, 0) For matches_index = 0 To matches.Count - 1 text_matches(matches_index, 0) = matches.Item(matches_index) Next matches_index RegExpExtract = text_matches Else RegExpExtract = matches.Item(instance_num - 1) EndIf End If Exit Function ErrHandl: RegExpExtract = CVErr(xlErrValue) End FunctionЕсли у вас небольшой опыт работы с VBA, вам может оказаться полезным пошаговое руководство пользователя: Как вставить код VBA в Excel.
Примечание. Чтобы функция работала, обязательно сохраните файл как рабочая книга с поддержкой макросов (.xlsm).
Синтаксис RegExpExtract
Сайт RegExpExtract Функция ищет во входной строке значения, соответствующие регулярному выражению, и извлекает одно или все совпадения.
Функция имеет следующий синтаксис:
RegExpExtract(text, pattern, [instance_num], [match_case])Где:
- Текст (требуется) - текстовая строка для поиска.
- Узор (требуется) - регулярное выражение для сопоставления. При вводе непосредственно в формулу шаблон должен быть заключен в двойные кавычки.
- Номер_экземпляра (необязательно) - порядковый номер, который указывает, какой экземпляр извлекать. Если не указан, возвращает все найденные совпадения (по умолчанию).
- Соответствие_случаю (необязательный) - определяет, следует ли сопоставлять или игнорировать регистр текста. Если TRUE или опущено (по умолчанию), выполняется сопоставление с учетом регистра; если FALSE - без учета регистра.
Функция работает во всех версиях Excel 365, Excel 2021, Excel 2019, Excel 2016, Excel 2013 и Excel 2010.
4 вещи, которые вы должны знать о RegExpExtract
Чтобы эффективно использовать эту функцию в Excel, необходимо обратить внимание на несколько важных моментов:
- По умолчанию функция возвращает все найденные совпадения в соседние ячейки, как показано в этом примере. Чтобы получить конкретное вхождение, введите соответствующее число в ячейку номер экземпляра аргумент.
- По умолчанию функция с учетом регистра Для поиска без учета регистра установите значение соответствие_случаю в FALSE. Из-за ограничений VBA конструкция без учета регистра (?i) не работает.
- Если не найден правильный образец функция не возвращает ничего (пустую строку).
- Если шаблон недействителен возникает ошибка #VALUE!
Прежде чем начать использовать эту пользовательскую функцию в своих рабочих листах, необходимо понять, на что она способна, верно? Приведенные ниже примеры охватывают несколько распространенных случаев использования и объясняют, почему поведение может отличаться в Dynamic Array Excel (Microsoft 365 и Excel 2021) и традиционном Excel (2019 и более старые версии).
Примечание. Приведенные примеры regex написаны для простых наборов данных. Мы не можем гарантировать, что они будут безупречно работать в ваших реальных рабочих листах. Те, кто имеет опыт работы с regex, согласятся, что написание регулярных выражений - это бесконечный путь к совершенству - почти всегда есть способ сделать его более элегантным или способным обрабатывать более широкий диапазон входных данных.
Regex для извлечения числа из строки
Следуя основной максиме обучения "от простого к сложному", мы начнем с очень простого случая: извлечения числа из строки.
Прежде всего, необходимо решить, какой номер извлекать: первый, последний, конкретное вхождение или все номера.
Извлечение первого числа
Учитывая, что \d означает любую цифру от 0 до 9, а + означает один или несколько раз, наше регулярное выражение имеет следующий вид:
Узор : \d+
Установите номер экземпляра к 1, и вы получите желаемый результат:
=RegExpExtract(A5, "\d+", 1)
Где A5 - исходная струна.
Для удобства можно ввести шаблон в заранее определенную ячейку ($A$2 ) и зафиксировать ее адрес знаком $:
=RegExpExtract(A5, $A$2, 1) 
Получить последний номер
Чтобы извлечь последнее число в строке, используйте следующий шаблон:
Узор : (\d+)(?!.*\d)
В переводе на человеческий язык это звучит так: найдите число, за которым (нигде, а не только сразу) не следует никакое другое число. Чтобы выразить это, мы используем отрицательное наклонение (?!.*\d), что означает, что справа от образца не должно быть никакой другой цифры (\d), независимо от того, сколько других символов находится перед ней.
=RegExpExtract(A5, "(\d+)(?!.*\d)") 
Советы:
- Чтобы получить конкретное происшествие используйте \d+ для шаблон и соответствующий серийный номер для номер экземпляра .
- Формула для извлечения все номера рассматривается в следующем примере.
Regex для извлечения всех совпадений
Если продвинуть наш пример немного дальше, предположим, что вы хотите получить все числа из строки, а не только одно.
Как вы помните, количество извлеченных совпадений контролируется дополнительным параметром номер экземпляра по умолчанию - все совпадения, поэтому этот параметр можно просто опустить:
=RegExpExtract(A2, "\d+")
Формула прекрасно работает для одной ячейки, но поведение отличается в динамическом массиве Excel и нединамических версиях.
Excel 365 и Excel 2021
Благодаря поддержке динамических массивов обычная формула автоматически распространяется на столько ячеек, сколько необходимо для отображения всех вычисленных результатов. В терминах Excel это называется разлинованным диапазоном: 
Excel 2019 и ниже
В додинамическом Excel приведенная выше формула возвращала только одно совпадение. Чтобы получить несколько совпадений, нужно сделать формулу массивом. Для этого выделите диапазон ячеек, введите формулу и нажмите Ctrl + Shift + Enter, чтобы завершить ее.
Недостатком такого подхода является появление в "лишних ячейках" кучи ошибок #N/A. К сожалению, с этим ничего нельзя поделать (ни IFERROR, ни IFNA не могут это исправить, увы). 
Извлечение всех совпадений в одну ячейку
При обработке столбца данных описанный выше подход, очевидно, не сработает. В этом случае идеальным решением было бы возвращение всех совпадений в одной ячейке. Чтобы сделать это, передайте результаты RegExpExtract в функцию TEXTJOIN и разделите их любым разделителем, который вам нравится, например, запятой и пробелом:
=TEXTJOIN(", ", TRUE, RegExpExtract(A5, "\d+")) 
Примечание. Поскольку функция TEXTJOIN доступна только в Excel для Microsoft 365, Excel 2021 и Excel 2019, формула не будет работать в более старых версиях.
Regex для извлечения текста из строки
Извлечение текста из буквенно-цифровой строки - довольно сложная задача в Excel. С помощью regex это становится просто как пирог. Просто используйте отрицание класса для соответствия всему, что не является цифрой.
Узор : [^\d]+
Чтобы получить подстроки в отдельных ячейках (диапазон разлива), используется следующая формула:
=RegExpExtract(A5, "[^\d]+") 
Чтобы вывести все совпадения в одну ячейку, вложите функцию RegExpExtract в TEXTJOIN следующим образом:
=TEXTJOIN("", TRUE, RegExpExtract(A5, "[^\d]+")) 
Regex для извлечения адреса электронной почты из строки
Чтобы извлечь адрес электронной почты из строки, содержащей множество различной информации, напишите регулярное выражение, повторяющее структуру адреса электронной почты.
Узор : [\w\.\-]+@[A-Za-z0-9\.\-]+\.[A-Za-z]{2,24}
Разбирая этот regex, вот что мы получаем:
- [\w\.\-]+ - это имя пользователя, которое может включать 1 или более буквенно-цифровых символов, подчеркивание, точки и дефисы.
- @ символ
- [A-Za-z0-9\.\-]+ - это доменное имя, состоящее из: заглавных и строчных букв, цифр, дефисов и точек (в случае поддоменов). Подчеркивания здесь не допускаются, поэтому вместо \w используются 3 различных набора символов (например, A-Z a-z и 0-9), которые соответствуют любой букве, цифре или подчеркиванию.
- \.[A-Za-z]{2,24} - это домен верхнего уровня. Состоит из точки, за которой следуют заглавные и строчные буквы. Большинство доменов верхнего уровня состоят из 3 букв (например, .com .org, .edu и т.д.), но теоретически он может содержать от 2 до 24 букв (самый длинный зарегистрированный TLD).
Если предположить, что строка находится в A5, а шаблон - в A2, то формула для извлечения адреса электронной почты будет следующей:
=RegExpExtract(A5, $A$2) 
Regex для извлечения домена из электронной почты
Когда речь заходит об извлечении домена электронной почты, первая мысль, которая приходит на ум, - это использование группы захвата для поиска текста, который следует сразу за символом @.
Узор : @([A-Za-z0-9\.\-]+\.[A-Za-z]{2,24})
Передайте его в нашу функцию RegExp:
=RegExpExtract(A5, "@([A-Za-z0-9\.\-]+\.[A-Za-z]{2,24})")
И вы получите такой результат: 
В классических регулярных выражениях все, что находится вне группы захвата, не включается в извлечение. Никто не знает, почему VBA RegEx работает иначе и захватывает "@". Чтобы избавиться от него, вы можете удалить первый символ из результата, заменив его пустой строкой.
=REPLACE(RegExpExtract(A5, "@([a-z\d][a-z\d\-\.]*\.[a-z]{2,})", 1, FALSE), 1, 1, "") 
Регулярное выражение для извлечения телефонных номеров
Телефонные номера могут быть записаны множеством различных способов, поэтому практически невозможно придумать решение, работающее при любых обстоятельствах. Тем не менее, вы можете записать все форматы, используемые в вашем наборе данных, и попытаться сопоставить их.
Для этого примера мы создадим regex, который будет извлекать телефонные номера в любом из этих форматов:
(123) 345-6789 (123) 345 6789 (123)3456789 123-345-6789 | 123.345.6789 123 345 6789 1233456789 |
Узор : \(?\d{3}[-\. \)]*\d{3}[-\. ]\d{4}\b
- Первая часть \(?\d{3} соответствует нулю или одной открывающей скобке, за которой следуют три цифры d{3}.
- Часть [-\. \)]* означает любой символ в квадратных скобках, встречающийся 0 или более раз: дефис, точка, пробел или закрывающая скобка.
- Далее у нас снова три цифры d{3}, за которыми следует любой дефис, точка или пробел [-\. ]? появляющиеся 0 или 1 раз.
- После этого идет группа из четырех цифр \d{4}.
- Наконец, есть слово граница \b, определяющее, что искомый номер телефона не может быть частью большего номера.
Полная формула имеет такую форму:
=RegExpExtract(A5, "\(?\d{3}[-\. \)]*\d{3}[-\. ]?\d{4}\b") 
Пожалуйста, имейте в виду, что вышеприведенное выражение может возвращать несколько ложноположительных результатов, таких как 123) 456 7899 или (123 456 7899. Приведенная ниже версия исправляет эти проблемы. Однако этот синтаксис работает только в функциях VBA RegExp, а не в классических регулярных выражениях.
Узор : (\(\d{3}\)
Regex для извлечения даты из строки
Регулярное выражение для извлечения даты зависит от формата, в котором дата появляется в строке. Например:
Чтобы извлечь такие даты, как 1/1/21 или 01/01/2021, используется следующий регекс: \d{1,2}\/\d{1,2}\/(\d{4}
Он ищет группу из 1 или 2 цифр d{1,2}, за которой следует косая черта, за которой следует другая группа из 1 или 2 цифр, за которой следует косая черта, за которой следует группа из 4 или 2 цифр (\d{4}первое условие в конструкции чередования ИЛИ совпадает, остальные условия не проверяются.
Чтобы получить даты, например, 1-январь-21 или 01-январь-2021, шаблон выглядит так: \d{1,2}-[A-Za-z]{3}-\d{2,4}
Он ищет группу из 1 или 2 цифр, за которой следует дефис, за которой следует группа из 3 заглавных или строчных букв, за которой следует дефис, за которой следует группа из 4 или 2 цифр.
После объединения двух шаблонов вместе мы получаем следующий регекс:
Узор : \b\d{1,2}[\/-](\d{1,2}
Где:
- Первая часть - 1 или 2 цифры: \d{1,2}
- Вторая часть - это 1 или 2 цифры или 3 буквы: (\d{1,2}
- Третья часть - это группа из 4 или 2 цифр: (\d{4}
- Разделителем является либо прямая косая черта, либо дефис: [\/-]
- Граница слов \b размещается с обеих сторон, чтобы было понятно, что дата - это отдельное слово, а не часть большой строки.
Как вы можете видеть на изображении ниже, он успешно извлекает даты и удаляет подстроки, такие как 11/22/333. Однако он все равно возвращает ложные положительные результаты. В нашем случае подстрока 11-ABC-2222 в A9 технически соответствует формату даты dd-mmm-yyy и поэтому извлекается. 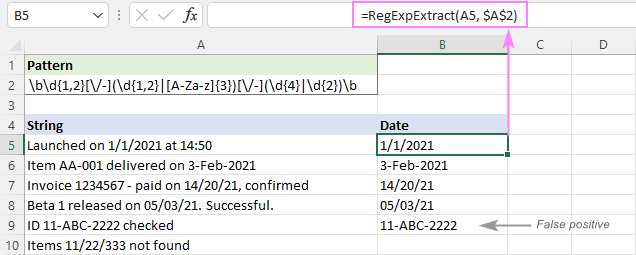
Чтобы исключить ложные срабатывания, можно заменить часть [A-Za-z]{3} полным списком трехбуквенных сокращений месяца:
Узор : \b\d{1,2}[\/-](\d{1,2}
Чтобы игнорировать регистр букв, мы устанавливаем последний аргумент нашей пользовательской функции в FALSE:
=RegExpExtract(A5, $A$2, 1, FALSE)
И на этот раз мы получаем прекрасный результат: 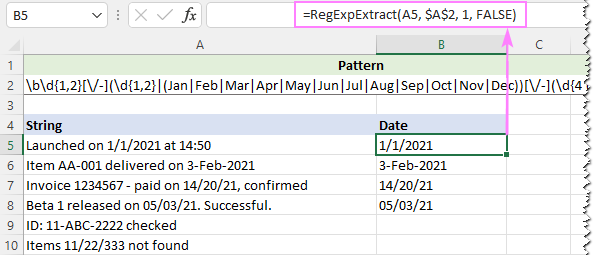
Regex для извлечения времени из строки
Чтобы получить время в чч:мм или чч:мм:сс формат, следующее выражение будет работать отлично.
Узор : \b(0?[0-9]
Разбирая этот regex, вы можете увидеть 2 части, разделенные
Выражение 1 : \b(0?[0-9]
Извлекает время с указанием AM/PM.
Час может быть любое число от 0 до 12. Чтобы получить его, мы используем конструкцию OR ([0-9]
- [0-9] соответствует любому числу от 0 до 9
- 1[0-2] соответствует любому числу от 10 до 12
Минута [0-5]\d - любое число от 00 до 59.
Второй (:[0-5]\d)? также любое число от 00 до 59. Квантификатор ? означает ноль или один случай, поскольку секунды могут быть включены или не включены в значение времени.
Выражение 2 : \b([0-9]
Извлекает время без AM/PM.
Сайт час часть может быть любым числом от 0 до 32. Для ее получения используется другая конструкция OR ([0-9]
- [0-9] соответствует любому числу от 0 до 9
- [0-1]\d соответствует любому числу от 00 до 19
- 2[0-3] соответствует любому числу от 20 до 23
Сайт минута и второй части такие же, как в выражении 1 выше.
Отрицательное опережение (?!:) добавляется к строкам пропуска, таким как 20:30:80.
Поскольку PM/AM могут быть как прописными, так и строчными, мы делаем функцию нечувствительной к регистру:
=RegExpExtract(A5, $A$2, 1, FALSE) 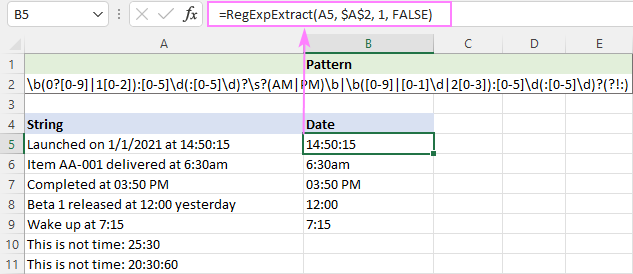
Надеюсь, приведенные выше примеры дали вам несколько идей по использованию регулярных выражений в ваших листах Excel. К сожалению, не все возможности классических регулярных выражений поддерживаются в VBA. Если ваша задача не может быть решена с помощью VBA RegExp, я советую вам прочитать следующую часть, в которой рассматриваются более мощные функции .NET Regex.
Пользовательская функция Regex на основе .NET для извлечения текста в Excel
В отличие от функций VBA RegExp, которые может написать любой пользователь Excel, .NET RegEx - это сфера разработчиков. Microsoft .NET Framework поддерживает полнофункциональный синтаксис регулярных выражений, совместимый с Perl 5. Эта статья не научит вас писать такие функции (я не программист и не имею ни малейшего представления о том, как это сделать :)).
Четыре мощные функции, обрабатываемые стандартным механизмом .NET RegEx, уже написаны нашими разработчиками и включены в Ultimate Suite. Ниже мы продемонстрируем несколько практических применений функции, специально разработанной для извлечения текста в Excel.
Совет. Информацию о синтаксисе .NET Regex см. в разделе Язык регулярных выражений .NET.
Как извлечь жала в Excel с помощью регулярных выражений
Если у вас установлена последняя версия Ultimate Suite, извлечение текста с помощью регулярных выражений сводится к следующим двум шагам:
- На Ablebits Data во вкладке Текст группу, нажмите Инструменты регекса .

- На Инструменты регекса на панели выберите исходные данные, введите шаблон Regex и выберите опцию Выписка Чтобы получить результат в виде пользовательской функции, а не значения, выберите опцию Вставка в виде формулы установите флажок. После этого нажмите кнопку Выписка кнопка.

Результаты появятся в новой колонке справа от исходных данных: 
Синтаксис AblebitsRegexExtract
Наша пользовательская функция имеет следующий синтаксис:
AblebitsRegexExtract(reference, regular_expression)Где:
- Ссылка (требуется) - ссылка на ячейку, содержащую исходную строку.
- Регулярное_выражение (требуется) - шаблон regex для сравнения.
Важное замечание! Функция работает только на машинах с установленным Ultimate Suite for Excel.
Примечания по использованию
Чтобы сделать процесс обучения более плавным, а опыт - более приятным, обратите внимание на следующие моменты:
- Чтобы создать формулу, вы можете использовать нашу Инструменты регекса , или Excel Функция вставки или введите полное имя функции в ячейке. После вставки формулы вы можете управлять ею (редактировать, копировать или перемещать), как и любой другой формулой.
- Шаблон, который вы вводите на Инструменты регекса панели переходит ко второму аргументу. Можно также хранить регулярное выражение в отдельной ячейке. В этом случае просто используйте ссылку на ячейку для второго аргумента.
- Функция извлекает первое найденное совпадение .
- По умолчанию функция с учетом регистра Для сопоставления без учета регистра используйте шаблон (?i).
- Если совпадение не найдено, возвращается ошибка #N/A.
Regex для извлечения строки между двумя символами
Чтобы получить текст между двумя символами, можно использовать либо группу захвата, либо обходные пути.
Допустим, вам нужно извлечь текст между скобками. Группа захвата - самый простой способ.
Образец 1 : \[(.*?)\]
При позитивном взгляде назад и вперед результат будет точно таким же.
Узор 2 : (?<=\[)(.*?)(?=\])
Пожалуйста, обратите внимание, что наша группа захвата (.*?) выполняет ленивый поиск для текста между двумя скобками - от первой [ до первой ]. Группа захвата без вопросительного знака (.*) будет выполнять функцию жадный поиск и запечатлеть все от первого [ до последнего].
С шаблоном в A2 формула выглядит следующим образом:
=AblebitsRegexExtract(A5, $A$2) 
Как получить все спички
Как уже упоминалось, функция AblebitsRegexExtract может извлечь только одно совпадение. Чтобы получить все совпадения, вы можете использовать функцию VBA, о которой мы говорили ранее. Однако есть одна оговорка - VBA RegExp не поддерживает захват групп, поэтому приведенный выше шаблон вернет и "граничные" символы, в нашем случае скобки.
=TEXTJOIN(" ", TRUE, RegExpExtract(A5, $A$2)) 
Чтобы избавиться от скобок, замените их пустыми строками (""), используя эту формулу:
=SUBSTITUTE(SUBSTITUTE(TEXTJOIN(", ", TRUE, RegExpExtract(A5, $A$2)), "]", ""),"[",""))
Для лучшей читабельности мы используем запятую в качестве разделителя. 
Regex для извлечения текста между двумя строками
Подход, который мы использовали для извлечения текста между двумя символами, будет работать и для извлечения текста между двумя строками.
Например, чтобы получить все, что находится между "test 1" и "test 2", используйте следующее регулярное выражение.
Узор : тест 1(.*?)тест 2
Полная формула такова:
=AblebitsRegexExtract(A5, "test 1(.*?)test 2") 
Regex для извлечения домена из URL
Даже при использовании регулярных выражений извлечение доменных имен из URL не является тривиальной задачей. Ключевым элементом, который делает этот трюк, являются группы без захвата. В зависимости от вашей конечной цели выберите один из приведенных ниже регексов.
Чтобы получить полное доменное имя включая субдомены
Узор : (?:https?\:
Чтобы получить второго уровня домен без поддоменов
Узор : (?:https?\:
Теперь давайте посмотрим, как эти регулярные выражения работают на примере "//www.mobile.ablebits.com" в качестве образца URL:
- (?:https?\:
- \/\/ - две прямые косые черты (перед каждой из них ставится обратная косая черта, чтобы избежать специального значения прямой косой черты и интерпретировать ее буквально).
- (?:[A-Za-z\d\-\.]{2,255}\.)? - не захватывающая группа для идентификации доменов третьего, четвертого и т.д. уровня, если таковые имеются ( мобильный в нашем примере URL). В первом шаблоне он помещается в большую группу захвата, чтобы все такие поддомены были включены в извлечение. Поддомен может иметь длину от 2 до 255 символов, отсюда квантификатор {2,255}.
- ([A-Za-z\d\-]{1,63}\.[A-Za-z]{2,24}) - группа захвата для извлечения домена второго уровня ( ablebits ) и домен верхнего уровня ( com ). Максимальная длина домена второго уровня составляет 63 символа. Самый длинный домен верхнего уровня, существующий в настоящее время, содержит 24 символа.
В зависимости от того, какое регулярное выражение введено в A2, приведенная ниже формула будет давать разные результаты:
=AblebitsRegexExtract(A5, $A$2)
Regex для извлечения полное доменное имя со всеми поддоменами: 
Regex для извлечения второго уровня домен без субдоменов: 
Вот как извлекать части текста в Excel с помощью регулярных выражений. Я благодарю вас за прочтение и жду вас на нашем блоге на следующей неделе!
Доступные загрузки
Примеры Excel Regex Extract (файл.xlsm)
Ultimate Suite пробная версия (файл .exe)
