
Obsah
V tomto učebnom texte sa naučíte používať regulárne výrazy v programe Excel na vyhľadávanie a extrahovanie podreťazcov, ktoré zodpovedajú zadanému vzoru.
Microsoft Excel poskytuje množstvo funkcií na extrakciu textu z buniek. Tieto funkcie si dokážu poradiť s väčšinou výziev na extrakciu reťazcov vo vašich pracovných hárkoch. S väčšinou, ale nie so všetkými. Keď textové funkcie zakopnú, na pomoc prídu regulárne výrazy. Počkajte... Excel nemá žiadne funkcie RegEx! Pravda, žiadne vstavané funkcie. Ale nič vám nebráni použiť vlastné :)
Funkcia Excel VBA Regex na extrahovanie reťazcov
Ak chcete do programu Excel pridať vlastnú funkciu Regex Extract, vložte do editora VBA nasledujúci kód. Aby sme umožnili regulárne výrazy vo VBA, používame vstavaný objekt Microsoft RegExp.
Public Function RegExpExtract(text As String , pattern As String , Optional instance_num As Integer = 0, Optional match_case As Boolean = True ) Dim text_matches() As String Dim matches_index As Integer On Error GoTo ErrHandl RegExpExtract = "" Set regex = CreateObject ("VBScript.RegExp" ) regex.pattern = pattern regex.Global = True regex.MultiLine = True If True = match_case Thenregex.ignorecase = False Else regex.ignorecase = True End If Set matches = regex.Execute(text) If 0 <matches.Count Then If (0 = instance_num) Then ReDim text_matches(matches.Count - 1, 0) For matches_index = 0 To matches.Count - 1 text_matches(matches_index, 0) = matches.Item(matches_index) Next matches_index RegExpExtract = text_matches Else RegExpExtract = matches.Item(instance_num - 1) EndIf End If Exit Function ErrHandl: RegExpExtract = CVErr(xlErrValue) End FunctionAk máte s VBA málo skúseností, môže vám pomôcť používateľská príručka Krok za krokom: Ako vložiť kód VBA do programu Excel.
Poznámka: Aby funkcia fungovala, nezabudnite uložiť súbor ako zošit s povolenými makrami (.xlsm).
Syntax RegExpExtract
Stránka RegExpExtract funkcia vyhľadá vo vstupnom reťazci hodnoty, ktoré zodpovedajú regulárnemu výrazu, a extrahuje jednu alebo všetky zhody.
Funkcia má nasledujúcu syntax:
RegExpExtract(text, vzor, [instance_num], [match_case])Kde:
- Text (povinné) - textový reťazec, v ktorom sa má vyhľadávať.
- Vzor (povinné) - regulárny výraz, ktorý sa má porovnať. Ak je vzor zadaný priamo vo vzorci, mal by byť uzavretý v dvojitých úvodzovkách.
- Instance_num (nepovinné) - poradové číslo, ktoré označuje, ktorá inštancia sa má extrahovať. Ak sa vynechá, vráti všetky nájdené zhody (predvolené).
- Match_case (nepovinné) - definuje, či sa má porovnať alebo ignorovať veľkosť písmen v texte. Ak je TRUE alebo je vynechaný (predvolené), porovnávajú sa veľké a malé písmená; ak je FALSE - nerozlišuje sa veľkosť písmen.
Funkcia funguje vo všetkých verziách programov Excel 365, Excel 2021, Excel 2019, Excel 2016, Excel 2013 a Excel 2010.
4 veci, ktoré by ste mali vedieť o RegExpExtract
Ak chcete túto funkciu efektívne používať v programe Excel, je potrebné dbať na niekoľko dôležitých vecí:
- V predvolenom nastavení funkcia vracia všetky nájdené zhody do susedných buniek, ako je znázornené v tomto príklade. Ak chcete získať konkrétny výskyt, zadajte zodpovedajúce číslo do instance_num argument.
- V predvolenom nastavení je funkcia rozlišovanie veľkých a malých písmen Pre porovnávanie bez rozlišovania veľkých a malých písmen nastavte match_case argument na FALSE. Z dôvodu obmedzení VBA nebude fungovať konštrukcia bez rozlišovania veľkých a malých písmen (?i).
- Ak a nebol nájdený platný vzor , funkcia nevráti nič (prázdny reťazec).
- Ak sa vzor je neplatný , nastane chyba #VALUE!.
Skôr ako začnete používať túto vlastnú funkciu vo svojich pracovných hárkoch, musíte pochopiť, čo dokáže, však? Nižšie uvedené príklady zahŕňajú niekoľko bežných prípadov použitia a vysvetľujú, prečo sa správanie môže líšiť v programe Excel s dynamickým poľom (Microsoft 365 a Excel 2021) a v tradičnom programe Excel (2019 a staršie verzie).
Poznámka: Uvedené príklady regexov sú napísané pre rozprávkovo jednoduché súbory údajov. Nemôžeme zaručiť, že budú bezchybne fungovať vo vašich skutočných pracovných listoch. Tí, ktorí majú skúsenosti s regexmi, budú súhlasiť, že písanie regulárnych výrazov je nekonečná cesta k dokonalosti - takmer vždy existuje spôsob, ako ich urobiť elegantnejšími alebo schopnými spracovať širší rozsah vstupných údajov.
Regex na extrakciu čísla z reťazca
V súlade so základným princípom výučby "od jednoduchého k zložitému" začneme veľmi jednoduchým prípadom: extrakciou čísla z reťazca.
Najskôr sa musíte rozhodnúť, ktoré číslo chcete načítať: prvé, posledné, konkrétny výskyt alebo všetky čísla.
Výpis prvého čísla
Vzhľadom na to, že \d znamená ľubovoľnú číslicu od 0 do 9 a + znamená jeden alebo viac krát, náš regulárny výraz má tento tvar:
Vzor : \d+
Nastavenie instance_num na 1 a dosiahnete požadovaný výsledok:
=RegExpExtract(A5, "\d+", 1)
Kde A5 je pôvodný reťazec.
Pre väčšie pohodlie môžete vzor zadať do preddefinovanej bunky ($A$2 ) a jej adresu uzamknúť znakom $:
=RegExpExtract(A5, $A$2, 1) 
Získajte posledné číslo
Ak chcete získať posledné číslo v reťazci, použite tento vzor:
Vzor : (\d+)(?!.*\d)
Preložené do ľudského jazyka to znamená: nájdi číslo, za ktorým (nikde, nielen bezprostredne) nenasleduje žiadna iná číslica. Na vyjadrenie tejto požiadavky používame záporný lookahead (?!.*\d), čo znamená, že napravo od vzoru by sa nemala nachádzať žiadna iná číslica (\d) bez ohľadu na to, koľko ďalších znakov je pred ňou.
=RegExpExtract(A5, "(\d+)(?!.*\d)") 
Tipy:
- Ak chcete získať špecifický výskyt , použite \d+ pre vzor a príslušné sériové číslo pre instance_num .
- Vzorec na extrakciu všetky čísla je opísaný v ďalšom príklade.
Regex na extrakciu všetkých zhody
Ak náš príklad posunieme trochu ďalej, predpokladajme, že chcete z reťazca získať všetky čísla, nielen jedno.
Ako si možno pamätáte, počet extrahovaných zhody je riadený voliteľným instance_num Predvolené nastavenie je všetky zhody, takže tento parameter jednoducho vynechajte:
=RegExpExtract(A2, "\d+")
Vzorec funguje krásne pre jednu bunku, ale správanie v dynamickom poli Excelu a v nedynamických verziách sa líši.
Excel 365 a Excel 2021
Vďaka podpore dynamických polí sa bežný vzorec automaticky rozleje do toľkých buniek, koľko je potrebné na zobrazenie všetkých vypočítaných výsledkov. V podmienkach programu Excel sa to nazýva rozleje rozsah: 
Excel 2019 a nižšie
V preddynamickom programe Excel by uvedený vzorec vrátil len jednu zhodu. Ak chcete získať viacero zhod, musíte z neho vytvoriť vzorec poľa. Na tento účel vyberte rozsah buniek, zadajte vzorec a stlačte klávesovú skratku Ctrl + Shift + Enter, aby ste ho dokončili.
Nevýhodou tohto prístupu je množstvo chýb #N/A, ktoré sa objavujú v "bunkách navyše". Žiaľ, nedá sa s tým nič robiť (IFERROR ani IFNA to bohužiaľ nedokážu opraviť). 
Výpis všetkých zhody v jednej bunke
Pri spracovaní stĺpca údajov uvedený prístup samozrejme nebude fungovať. V tomto prípade by bolo ideálnym riešením vrátenie všetkých zhody v jednej bunke. Ak to chcete urobiť, naservírujte výsledky funkcie RegExpExtract funkcii TEXTJOIN a oddeľte ich ľubovoľným oddeľovačom, napríklad čiarkou a medzerou:
=TEXTJOIN(", ", TRUE, RegExpExtract(A5, "\d+")) 
Poznámka: Keďže funkcia TEXTJOIN je k dispozícii len v aplikácii Excel pre Microsoft 365, Excel 2021 a Excel 2019, vzorec nebude fungovať v starších verziách.
Regex na extrahovanie textu z reťazca
Extrahovanie textu z alfanumerického reťazca je v programe Excel pomerne náročná úloha. Pomocou regexu je to jednoduché ako facka. Stačí použiť negovanú triedu na porovnanie všetkého, čo nie je číslica.
Vzor : [^\d]+
Ak chcete získať podreťazce v jednotlivých bunkách (rozsah rozliatia), vzorec je:
=RegExpExtract(A5, "[^\d]+") 
Ak chcete vypísať všetky zhody do jednej bunky, vnorte funkciu RegExpExtract do TEXTJOIN takto:
=TEXTJOIN("", TRUE, RegExpExtract(A5, "[^\d]+")) 
Regex na extrahovanie e-mailovej adresy z reťazca
Ak chcete vytiahnuť e-mailovú adresu z reťazca, ktorý obsahuje veľa rôznych informácií, napíšte regulárny výraz, ktorý kopíruje štruktúru e-mailovej adresy.
Vzor : [\w\.\-]+@[A-Za-z0-9\.\-]+\.[A-Za-z]{2,24}
Ak tento regex rozoberieme, dostaneme nasledovné:
- [\w\.\-]+ je používateľské meno, ktoré môže obsahovať 1 alebo viac alfanumerických znakov, podčiarkovníkov, bodiek a pomlčiek.
- @ symbol
- [A-Za-z0-9\.\-]+ je názov domény pozostávajúci z: veľkých a malých písmen, číslic, pomlčiek a bodiek (v prípade subdomén). Podčiarkovníky tu nie sú povolené, preto sa namiesto \w, ktoré zodpovedá akémukoľvek písmenu, číslici alebo podčiarkovníku, používajú 3 rôzne znakové sady (napríklad A-Z a-z a 0-9).
- \.[A-Za-z]{2,24} je doména najvyššej úrovne. Skladá sa z bodky, za ktorou nasledujú veľké a malé písmená. Väčšina domén najvyššej úrovne má 3 písmená (napr. .com .org, .edu atď.), ale teoreticky môže obsahovať 2 až 24 písmen (najdlhšia registrovaná TLD).
Za predpokladu, že reťazec je v poli A5 a vzor v poli A2, vzorec na získanie e-mailovej adresy je:
=RegExpExtract(A5, $A$2) 
Regex na extrahovanie domény z e-mailu
Pri extrahovaní e-mailovej domény vám ako prvé napadne použitie skupiny na zachytenie textu, ktorý nasleduje bezprostredne po znaku @.
Vzor : @([A-Za-z0-9\.\-]+\.[A-Za-z]{2,24})
Podajte ho našej funkcii RegExp:
=RegExpExtract(A5, "@([A-Za-z0-9\.\-]+\.[A-Za-z]{2,24})")
A dostanete tento výsledok: 
Pri klasických regulárnych výrazoch sa do extrakcie nezahŕňa nič, čo je mimo zachytávacej skupiny. Nikto nevie, prečo VBA RegEx funguje inak a zachytáva aj znak "@". Ak sa ho chcete zbaviť, môžete z výsledku odstrániť prvý znak tak, že ho nahradíte prázdnym reťazcom.
=REPLACE(RegExpExtract(A5, "@([a-z\d][a-z\d\-\.]*\.[a-z]{2,})", 1, FALSE), 1, 1, "") 
Regulárny výraz na extrahovanie telefónnych čísel
Telefónne čísla sa môžu zapisovať mnohými rôznymi spôsobmi, preto je takmer nemožné navrhnúť riešenie fungujúce za všetkých okolností. Napriek tomu si môžete zapísať všetky formáty používané vo vašom súbore údajov a pokúsiť sa ich porovnať.
V tomto príklade vytvoríme regex, ktorý bude extrahovať telefónne čísla v ktoromkoľvek z týchto formátov:
(123) 345-6789 (123) 345 6789 (123)3456789 123-345-6789 | 123.345.6789 123 345 6789 1233456789 |
Vzor : \(?\d{3}[-\. \)]*\d{3}[-\. ]?\d{4}\b
- Prvá časť \(?\d{3} zodpovedá nule alebo jednej otváracej zátvorke, za ktorou nasledujú tri číslice d{3}.
- Časť [-\. \)]* znamená akýkoľvek znak v hranatých zátvorkách, ktorý sa vyskytuje 0 alebo viackrát: pomlčka, bodka, medzera alebo uzatváracia zátvorka.
- Ďalej máme opäť tri číslice d{3}, za ktorými nasleduje akákoľvek pomlčka, bodka alebo medzera [-\. ]?, ktoré sa vyskytujú 0 alebo 1-krát.
- Potom nasleduje skupina štyroch číslic \d{4}.
- Nakoniec je tu slovná hranica \b, ktorá definuje, že hľadané telefónne číslo nemôže byť súčasťou väčšieho čísla.
Kompletný vzorec má tento tvar:
=RegExpExtract(A5, "\(?\d{3}[-\. \)]*\d{3}[-\. ]?\d{4}\b") 
Upozorňujeme, že vyššie uvedený regex môže vrátiť niekoľko falošne pozitívnych výsledkov, napríklad 123) 456 7899 alebo (123 456 7899. Nižšie uvedená verzia tieto problémy odstraňuje. Táto syntax však funguje len vo funkciách VBA RegExp, nie v klasických regulárnych výrazoch.
Vzor : (\(\d{3}\)
Regex na extrahovanie dátumu z reťazca
Regulárny výraz na extrakciu dátumu závisí od formátu, v ktorom sa dátum vyskytuje v reťazci. Napríklad:
Ak chcete extrahovať dátumy ako 1/1/21 alebo 01/01/2021, regex je: \d{1,2}\/\d{1,2}\/(\d{4}
Hľadá skupinu 1 alebo 2 číslic d{1,2}, za ktorou nasleduje lomka, za ktorou nasleduje ďalšia skupina 1 alebo 2 číslic, za ktorou nasleduje lomka, za ktorou nasleduje skupina 4 alebo 2 číslic (\d{4}).prvá podmienka je v konštrukcii alternácie OR, ostatné podmienky sa nekontrolujú.
Ak chcete získať dátumy ako 1.1.21 alebo 1.1.2021, vzor je: \d{1,2}-[A-Za-z]{3}-\d{2,4}
Vyhľadáva skupinu 1 alebo 2 číslic, za ktorou nasleduje pomlčka, za ktorou nasleduje skupina 3 veľkých alebo malých písmen, za ktorou nasleduje pomlčka a za ktorou nasleduje skupina 4 alebo 2 číslic.
Po skombinovaní týchto dvoch vzorov dostaneme nasledujúci regex:
Vzor : \b\d{1,2}[\/-](\d{1,2}
Kde:
- Prvá časť je 1 alebo 2 číslice: \d{1,2}
- Druhá časť je buď 1 alebo 2 číslice alebo 3 písmená: (\d{1,2}
- Tretia časť je skupina 4 alebo 2 číslic: (\d{4})
- Oddeľovač je buď lomka alebo spojovník: [\/-]
- Hranica slova \b je umiestnená na oboch stranách, aby bolo jasné, že dátum je samostatné slovo a nie súčasť väčšieho reťazca.
Ako vidíte na obrázku nižšie, úspešne vytiahne dátumy a vynechá podreťazce, ako napríklad 11/22/333. Stále však vracia falošne pozitívne výsledky. V našom prípade podreťazec 11-ABC-2222 v A9 technicky zodpovedá formátu dátumu dd-mmm-rrrr a preto sa extrahuje. 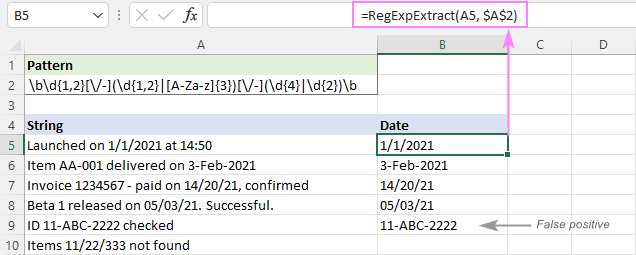
Ak chcete eliminovať falošné pozitívne výsledky, môžete časť [A-Za-z]{3} nahradiť úplným zoznamom trojpísmenových skratiek mesiacov:
Vzor : \b\d{1,2}[\/-](\d{1,2}
Ak chceme ignorovať veľkosť písmen, nastavíme posledný argument našej vlastnej funkcie na hodnotu FALSE:
=RegExpExtract(A5, $A$2, 1, FALSE)
Tentoraz sme dosiahli perfektný výsledok: 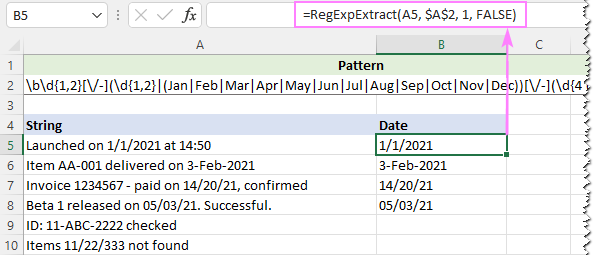
Regex na extrakciu času z reťazca
Ak chcete získať čas v hh:mm alebo hh:mm:ss bude fungovať nasledujúci výraz.
Vzor : \b(0?[0-9]
Ak tento regex rozdelíte, uvidíte 2 časti oddelené
Vyjadrenie 1 : \b(0?[0-9]
Vyhľadá časy s AM/PM.
Hodina môže byť ľubovoľné číslo od 0 do 12. Na jeho získanie použijeme konštrukciu OR ([0-9]
- [0-9] zodpovedá akémukoľvek číslu od 0 do 9
- 1[0-2] zodpovedá akémukoľvek číslu od 10 do 12
Minúta [0-5]\d je akékoľvek číslo od 00 do 59.
Druhý (:[0-5]\d)? je tiež ľubovoľné číslo od 00 do 59. Kvantifikátor ? znamená nula alebo jeden výskyt, pretože sekundy môžu, ale nemusia byť zahrnuté do hodnoty času.
Vyjadrenie 2 : \b([0-9]
Výpisy časov bez AM/PM.
Stránka hodina časť môže byť ľubovoľné číslo od 0 do 32. Na jej získanie sa použije iná konštrukcia OR ([0-9]
- [0-9] zodpovedá ľubovoľnému číslu od 0 do 9
- [0-1]\d zodpovedá akémukoľvek číslu od 00 do 19
- 2[0-3] zodpovedá ľubovoľnému číslu od 20 do 23
Stránka minúta a druhý časti sú rovnaké ako vo výraze 1 vyššie.
Záporný lookahead (?!:) sa pridáva k reťazcom s preskočením, ako napríklad 20:30:80.
Keďže PM/AM môžu byť veľké alebo malé písmená, nerozlišujeme veľkosť písmen:
=RegExpExtract(A5, $A$2, 1, FALSE) 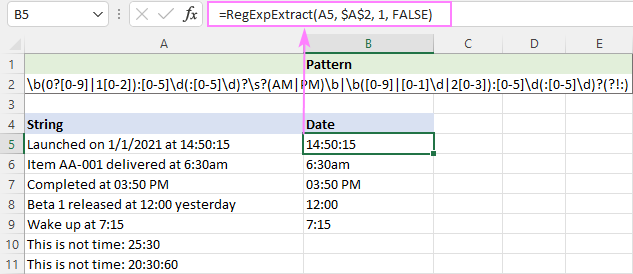
Dúfam, že vám vyššie uvedené príklady poskytli niekoľko nápadov, ako používať regulárne výrazy v pracovných listoch Excelu. Bohužiaľ, nie všetky funkcie klasických regulárnych výrazov sú podporované vo VBA. Ak sa vaša úloha nedá splniť pomocou VBA RegExp, odporúčam vám prečítať si ďalšiu časť, ktorá pojednáva o oveľa výkonnejších funkciách .NET Regex.
Vlastná funkcia Regex založená na technológii .NET na extrahovanie textu v programe Excel
Na rozdiel od funkcií VBA RegExp, ktoré môže napísať každý používateľ Excelu, funkcie .NET RegEx sú doménou vývojárov. Microsoft .NET Framework podporuje plnohodnotnú syntax regulárnych výrazov kompatibilnú s Perlom 5. Tento článok vás nenaučí písať takéto funkcie (nie som programátor a nemám ani najmenšiu predstavu o tom, ako to urobiť :)
Štyri výkonné funkcie spracované štandardným mechanizmom .NET RegEx už napísali naši vývojári a sú súčasťou balíka Ultimate Suite. Nižšie si ukážeme niekoľko praktických použití funkcie špeciálne navrhnutej na extrahovanie textu v programe Excel.
Tip. Informácie o syntaxi jazyka .NET Regex nájdete v časti Jazyk regulárnych výrazov .NET.
Ako extrahovať žihadlá v programe Excel pomocou regulárnych výrazov
Za predpokladu, že máte nainštalovanú najnovšiu verziu balíka Ultimate Suite, sa extrahovanie textu pomocou regulárnych výrazov obmedzuje na tieto dva kroky:
- Na Údaje Ablebits na karte Text kliknite na položku Nástroje Regex .

- Na Nástroje Regex vyberte zdrojové údaje, zadajte vzor Regex a vyberte Výpis Ak chcete získať výsledok ako vlastnú funkciu, nie ako hodnotu, vyberte možnosť Vložiť ako vzorec Začiarknite políčko. Po dokončení kliknite na Výpis tlačidlo.

Výsledky sa zobrazia v novom stĺpci napravo od pôvodných údajov: 
Syntax AblebitsRegexExtract
Naša vlastná funkcia má nasledujúcu syntax:
AblebitsRegexExtract(reference, regular_expression)Kde:
- Odkaz (povinné) - odkaz na bunku obsahujúcu zdrojový reťazec.
- Regular_expression (povinné) - regexový vzor, ktorý sa má porovnať.
Dôležitá poznámka! Funkcia funguje len na počítačoch s nainštalovaným balíkom Ultimate Suite for Excel.
Poznámky k používaniu
Aby bolo vaše učenie plynulejšie a zážitok príjemnejší, venujte pozornosť týmto bodom:
- Ak chcete vytvoriť vzorec, môžete použiť náš Nástroje Regex , alebo Excel Vložiť funkciu Po vložení vzorca ho môžete spravovať (upravovať, kopírovať alebo presúvať) ako akýkoľvek iný vzorec.
- Vzor, ktorý zadáte do Nástroje Regex paneli prejde na 2. argument. Regulárny výraz je možné uchovávať aj v samostatnej bunke. V tomto prípade stačí použiť odkaz na bunku pre 2. argument.
- Funkcia extrahuje prvá nájdená zhoda .
- V predvolenom nastavení je funkcia rozlišovanie veľkých a malých písmen Pre porovnávanie bez rozlišovania veľkých a malých písmen použite vzor (?i).
- Ak sa nenájde zhoda, vráti sa chyba #N/A.
Regex na extrakciu reťazca medzi dvoma znakmi
Ak chcete získať text medzi dvoma znakmi, môžete použiť buď zachytávaciu skupinu, alebo hľadanie.
Povedzme, že chcete extrahovať text medzi zátvorkami. Najjednoduchším spôsobom je zachytenie skupiny.
Vzor 1 : \[(.*?)\]
Pri pozitívnom pohľade dozadu a dopredu bude výsledok presne rovnaký.
Vzor 2 : (?<=\[)(.*?)(?=\])
Upozorňujeme, že naša skupina pre zachytávanie (.*?) vykonáva lenivé vyhľadávanie pre text medzi dvoma zátvorkami - od prvej [ po prvú ]. Zachytenie skupiny bez otáznika (.*) by urobilo chamtivé vyhľadávanie a zachytiť všetko od prvého [ po posledný ].
Vzorec v A2 je nasledovný:
=AblebitsRegexExtract(A5, $A$2) 
Ako získať všetky zápasy
Ako už bolo spomenuté, funkcia AblebitsRegexExtract dokáže extrahovať iba jednu zhodu. Ak chcete získať všetky zhody, môžete použiť funkciu VBA, o ktorej sme hovorili skôr. Je tu však jedna výhrada - VBA RegExp nepodporuje zachytávanie skupín, takže uvedený vzor vráti aj "hraničné" znaky, v našom prípade zátvorky.
=TEXTJOIN(" ", TRUE, RegExpExtract(A5, $A$2)) 
Ak sa chcete zbaviť zátvoriek, nahraďte ich prázdnymi reťazcami ("") pomocou tohto vzorca:
=SUBSTITUTE(SUBSTITUTE(TEXTJOIN(", ", TRUE, RegExpExtract(A5, $A$2)), "]", ""),"[","")
Pre lepšiu čitateľnosť používame na oddeľovanie čiarku. 
Regex na extrakciu textu medzi dvoma reťazcami
Prístup, ktorý sme vypracovali na vytiahnutie textu medzi dvoma znakmi, bude fungovať aj na vytiahnutie textu medzi dvoma reťazcami.
Ak chcete napríklad získať všetko medzi "test 1" a "test 2", použite nasledujúci regulárny výraz.
Vzor : test 1(.*?)test 2
Úplný vzorec je:
=AblebitsRegexExtract(A5, "test 1(.*?)test 2") 
Regex na extrahovanie domény z adresy URL
Extrahovanie názvov domén z adries URL nie je triviálna úloha ani pomocou regulárnych výrazov. Kľúčovým prvkom, ktorý tento trik dokáže, sú skupiny, ktoré sa nezachytávajú. V závislosti od vášho konečného cieľa si vyberte jeden z nižšie uvedených regexov.
Ak chcete získať celý názov domény vrátane subdomén
Vzor : (?:https?\:
Ak chcete získať druhá úroveň doména bez subdomén
Vzor : (?:https?\:
Teraz sa pozrime, ako tieto regulárne výrazy fungujú na príklade "//www.mobile.ablebits.com" ako vzorovej adresy URL:
- (?:https?\:
- \/\/ - dve lomítka vpred (pred každým z nich je spätné lomítko, aby sa uniklo špeciálnemu významu lomítka vpred a interpretovalo sa doslovne).
- (?:[A-Za-z\d\-\]{2,255}\.)? - nezachytávajúca skupina na identifikáciu domén tretej, štvrtej atď. úrovne, ak existujú ( mobilný v našej vzorovej adrese URL). V prvom vzore je umiestnený do väčšej zachytávacej skupiny, aby sa do extrakcie zahrnuli všetky takéto subdomény. Subdoména môže mať dĺžku od 2 do 255 znakov, preto je tu kvantifikátor {2,255}.
- ([A-Za-z\d\-]{1,63}\.[A-Za-z]{2,24}) - zachytávajúca skupina na extrakciu domény druhej úrovne ( ablebits ) a doména najvyššej úrovne ( com Maximálna dĺžka domény druhej úrovne je 63 znakov. Najdlhšia v súčasnosti existujúca doména najvyššej úrovne obsahuje 24 znakov.
V závislosti od toho, ktorý regulárny výraz je zadaný v A2, bude nasledujúci vzorec poskytovať rôzne výsledky:
=AblebitsRegexExtract(A5, $A$2)
Regex na extrakciu celý názov domény so všetkými subdoménami: 
Regex na extrakciu druhá úroveň doména bez subdomén: 
To je spôsob, ako extrahovať časti textu v programe Excel pomocou regulárnych výrazov. Ďakujem vám za prečítanie a teším sa na vás na našom blogu budúci týždeň!
Dostupné súbory na stiahnutie
Príklady extrakcie regexu Excel (.xlsm súbor)
Skúšobná verzia balíka Ultimate Suite (.exe súbor)
