
Съдържание
В този урок ще научите как да използвате регулярни изрази в Excel, за да намирате и извличате поднизове, които отговарят на даден шаблон.
Microsoft Excel предоставя редица функции за извличане на текст от клетките. Тези функции могат да се справят с повечето предизвикателства, свързани с извличането на низове във вашите работни листове. Повечето, но не всички. Когато функциите за текст се препънат, на помощ идват регулярните изрази. Чакайте... Excel няма RegEx функции! Вярно, няма вградени функции. Но нищо не ви пречи да използвате свои собствени :)
Функция Excel VBA Regex за извличане на низове
За да добавите потребителска функция Regex Extract в Excel, поставете следния код в редактора VBA. За да активираме регулярните изрази във VBA, използваме вградения обект Microsoft RegExp.
Public Function RegExpExtract(text As String , pattern As String , Optional instance_num As Integer = 0, Optional match_case As Boolean = True ) Dim text_matches() As String Dim matches_index As Integer On Error GoTo ErrHandl RegExpExtract = "" Set regex = CreateObject ("VBScript.RegExp" ) regex.pattern = pattern regex.Global = True regex.MultiLine = True If True = match_case Thenregex.ignorecase = False Else regex.ignorecase = True End If Set matches = regex.Execute(text) If 0 <matches.Count Then If (0 = instance_num) Then ReDim text_matches(matches.Count - 1, 0) For matches_index = 0 To matches.Count - 1 text_matches(matches_index, 0) = matches.Item(matches_index) Next matches_index RegExpExtract = text_matches Else RegExpExtract = matches.Item(instance_num - 1) EndIf End If Exit Function ErrHandl: RegExpExtract = CVErr(xlErrValue) End FunctionАко нямате голям опит с VBA, може да ви бъде от полза ръководството за потребителя "стъпка по стъпка": Как да вмъкнете код VBA в Excel.
Забележка: За да работи функцията, не забравяйте да запишете файла си като работна книга с активирани макроси (.xlsm).
Синтаксис на RegExpExtract
Сайтът RegExpExtract Функцията търси във входния низ стойности, които съответстват на регулярен израз, и извлича едно или всички съвпадения.
Функцията има следния синтаксис:
RegExpExtract(текст, шаблон, [instance_num], [match_case])Къде:
- Текст (задължително) - текстовият низ, в който ще се търси.
- Модел (задължително) - регулярен израз за съответствие. Когато се въвежда директно във формула, шаблонът трябва да бъде заграден в двойни кавички.
- Instance_num (незадължително) - сериен номер, който указва коя инстанция да се извлече. Ако не се посочи, се връщат всички намерени съвпадения (по подразбиране).
- Match_case (незадължително) - определя дали да се съпоставят или игнорират регистрите на текста. Ако е TRUE или е пропуснато (по подразбиране), се извършва съпоставяне с отчитане на регистрите; ако е FALSE - без отчитане на регистрите.
Функцията работи във всички версии на Excel 365, Excel 2021, Excel 2019, Excel 2016, Excel 2013 и Excel 2010.
4 неща, които трябва да знаете за RegExpExtract
За да използвате ефективно функцията в Excel, трябва да обърнете внимание на няколко важни неща:
- По подразбиране функцията връща всички намерени съвпадения в съседни клетки, както е показано в този пример. За да получите конкретна поява, въведете съответния номер в instance_num аргумент.
- По подразбиране функцията е отчитане на малки и големи букви За съвпадение без значение на големината на буквите задайте match_case поради ограниченията на VBA, конструкцията с нечувствителност на малките и големите букви (?i) няма да работи.
- Ако a не е намерен валиден модел , функцията не връща нищо (празен низ).
- Ако моделът е невалиден , се появява грешка #VALUE!.
Преди да започнете да използвате тази потребителска функция в работните си листове, трябва да разберете на какво е способна тя, нали? Примерите по-долу обхващат няколко често срещани случая на употреба и обясняват защо поведението може да се различава в Dynamic Array Excel (Microsoft 365 и Excel 2021) и традиционния Excel (2019 и по-стари версии).
Забележка. Изнесените примери за регулярни изрази са написани за приказно прости набори от данни. Не можем да гарантираме, че те ще работят безупречно във вашите реални работни листове. Тези, които имат опит с регулярни изрази, ще се съгласят, че писането на регулярни изрази е безкраен път към съвършенството - почти винаги има начин да се направи по-елегантен или способен да обработва по-широк набор от входни данни.
Regex за извличане на число от низ
Следвайки основната максима на обучението "от простото към сложното", ще започнем с един много прост случай: извличане на число от низ.
Първото нещо, което трябва да решите, е кой номер да извлечете: първия, последния, определен случай или всички номера.
Извлечете първото число
Като се има предвид, че \d означава всяка цифра от 0 до 9, а + означава един или повече пъти, нашият регулярен израз е в този вид:
Модел : \d+
Задайте instance_num на 1 и ще получите желания резултат:
=RegExpExtract(A5, "\d+", 1)
Където A5 е оригиналният низ.
За удобство можете да въведете шаблона в предварително определена клетка ($A$2 ) и да заключите адреса ѝ със знака $:
=RegExpExtract(A5, $A$2, 1) 
Получаване на последния номер
За извличане на последното число в низ ето какъв модел трябва да използвате:
Модел : (\d+)(?!.*\d)
Преведено на човешки език, то гласи: намерете число, което не е последвано (никъде, не само непосредствено) от друго число. За да изразим това, използваме отрицателна стъпка (?!.*\d), което означава, че вдясно от образеца не трябва да има друга цифра (\d), независимо колко други знака има преди нея.
=RegExpExtract(A5, "(\d+)(?!.*\d)") 
Съвети:
- За да получите специфична поява , използвайте \d+ за модел и подходящ сериен номер за instance_num .
- Формулата за извличане всички числа се разглежда в следващия пример.
Регекс за извличане на всички съвпадения
Ако задълбочим примера, ще предположим, че искате да получите всички числа от даден низ, а не само едно.
Както може би си спомняте, броят на извлечените съвпадения се контролира от опцията instance_num по подразбиране са всички съвпадения, така че просто пропускате този параметър:
=RegExpExtract(A2, "\d+")
Формулата работи чудесно за една клетка, но поведението се различава в Dynamic Array Excel и нединамичните версии.
Excel 365 и Excel 2021
Благодарение на поддръжката на динамични масиви обикновена формула автоматично се разлива в толкова клетки, колкото е необходимо, за да се покажат всички изчислени резултати. В Excel това се нарича разлят диапазон: 
Excel 2019 и по-ниски версии
В преддинамичния Excel горната формула би върнала само едно съвпадение. За да получите множество съвпадения, трябва да я превърнете във формула за масив. За целта изберете диапазон от клетки, въведете формулата и натиснете Ctrl + Shift + Enter, за да я завършите.
Недостатък на този подход е появата на множество грешки #N/A в "допълнителни клетки". За съжаление, нищо не може да се направи по въпроса (нито IFERROR, нито IFNA могат да го поправят, уви). 
Извличане на всички съвпадения в една клетка
Когато обработвате колона от данни, горният подход очевидно няма да работи. В този случай идеалното решение би било връщането на всички съвпадения в една клетка. За да го направите, подайте резултатите от RegExpExtract на функцията TEXTJOIN и ги разделете с какъвто искате разделител, например запетая и интервал:
=TEXTJOIN(", ", TRUE, RegExpExtract(A5, "\d+")) 
Забележка: Тъй като функцията TEXTJOIN е налична само в Excel за Microsoft 365, Excel 2021 и Excel 2019, формулата няма да работи в по-стари версии.
Regex за извличане на текст от низ
Извличането на текст от буквено-цифров низ е доста трудна задача в Excel. С помощта на regex това става лесно като пай. Просто използвайте отрицателен клас, за да съответства на всичко, което не е цифра.
Модел : [^\d]+
За получаване на поднизове в отделни клетки (диапазон на разливане) формулата е:
=RegExpExtract(A5, "[^\d]+") 
За да изведете всички съвпадения в една клетка, вмъкнете функцията RegExpExtract в TEXTJOIN по следния начин:
=TEXTJOIN("", TRUE, RegExpExtract(A5, "[^\d]+")) 
Regex за извличане на имейл адрес от низ
За да извлечете имейл адрес от низ, съдържащ много различна информация, напишете регулярен израз, който възпроизвежда структурата на имейл адреса.
Модел : [\w\.\-]+@[A-Za-z0-9\.\-]+\.[A-Za-z]{2,24}
Разбиваме този регекс и получаваме следното:
- [\w\.\-]+ е потребителско име, което може да включва 1 или повече буквено-цифрови знаци, подчертавания, точки и тирета.
- @ символ
- [A-Za-z0-9\.\-]+ е име на домейн, състоящо се от: главни и малки букви, цифри, тирета и точки (в случай на поддомейни). Подточките не са разрешени тук, затова вместо \w, което съвпада с всяка буква, цифра или подточка, се използват 3 различни набора от символи (като A-Z a-z и 0-9).
- \.[A-Za-z]{2,24} е домейн от най-високо ниво. Състои се от точка, последвана от главни и малки букви. Повечето домейни от най-високо ниво са с дължина 3 букви (например .com .org, .edu и др.), но на теория може да съдържа от 2 до 24 букви (най-дългият регистриран TLD).
Ако приемем, че низът е в A5, а шаблонът - в A2, формулата за извличане на имейл адрес е:
=RegExpExtract(A5, $A$2) 
Regex за извличане на домейн от имейл
Когато става въпрос за извличане на имейл домейн, първата мисъл, която ви идва наум, е да използвате група за улавяне, за да намерите текста, който следва непосредствено след символа @.
Модел : @([A-Za-z0-9\.\-]+\.[A-Za-z]{2,24})
Подайте го на нашата функция RegExp:
=RegExpExtract(A5, "@([A-Za-z0-9\.\-]+\.[A-Za-z]{2,24})")
И ще получите този резултат: 
При класическите регулярни изрази всичко извън групата за улавяне не се включва в извличането. Никой не знае защо VBA RegEx работи по различен начин и улавя и "@". За да се отървете от него, можете да премахнете първия символ от резултата, като го замените с празен низ.
=REPLACE(RegExpExtract(A5, "@([a-z\d][a-z\d\-\.]*\.[a-z]{2,})", 1, FALSE), 1, 1, "") 
Редовен израз за извличане на телефонни номера
Телефонните номера могат да се записват по много различни начини, поради което е почти невъзможно да се предложи решение, което да работи при всички обстоятелства. Въпреки това можете да запишете всички формати, използвани в набора от данни, и да се опитате да ги съпоставите.
За този пример ще създадем регекс, който ще извлече телефонни номера във всеки от тези формати:
(123) 345-6789 (123) 345 6789 (123)3456789 Вижте също: Как да премахнете дубликатите в Excel 123-345-6789 | 123.345.6789 123 345 6789 1233456789 |
Модел : \(?\d{3}[-\. \)]*\d{3}[-\. ]?\d{4}\b
- Първата част \(?\d{3} съвпада с нула или една отваряща скоба, последвана от три цифри d{3}.
- Частта [-\. \)]* означава всеки символ в квадратни скоби, който се появява 0 или повече пъти: дефис, точка, интервал или затварящи скоби.
- След това отново имаме три цифри d{3}, последвани от тире, точка или интервал [-\. ]?, които се появяват 0 или 1 път.
- След това има група от четири цифри \d{4}.
- И накрая, има дума граница \b, която определя, че търсеният телефонен номер не може да бъде част от по-голям номер.
Пълната формула има следния вид:
=RegExpExtract(A5, "\(?\d{3}[-\. \)]*\d{3}[-\. ]?\d{4}\b") 
Моля, имайте предвид, че горният regex може да върне няколко фалшиво положителни резултата, като например 123) 456 7899 или (123 456 7899. Версията по-долу отстранява тези проблеми. Този синтаксис обаче работи само във функциите VBA RegExp, а не в класическите регулярни изрази.
Модел : (\(\d{3}\)
Regex за извличане на дата от низ
Регулярният израз за извличане на дата зависи от формата, в който датата се появява в даден низ. Например:
За да извлечете дати като 1/1/21 или 01/01/2021, регексът е: \d{1,2}\/\d{1,2}\/(\d{4}
Търси се група от 1 или 2 цифри d{1,2}, последвана от наклонена черта, последвана от друга група от 1 или 2 цифри, последвана от наклонена черта, последвана от група от 4 или 2 цифри (\d{4}).първото условие е в редуващата се конструкция ИЛИ е съчетано, останалите условия не се проверяват.
За извличане на дати като 1 януари 21 г. или 01 януари 2021 г. моделът е: \d{1,2}-[A-Za-z]{3}-\d{2,4}
Търси се група от 1 или 2 цифри, последвана от тире, последвана от група от 3 главни или малки букви, последвана от тире, последвана от група от 4 или 2 цифри.
След комбиниране на двата шаблона получаваме следния регекс:
Модел : \b\d{1,2}[\/-](\d{1,2}
Къде:
- Първата част е от 1 или 2 цифри: \d{1,2}
- Втората част е 1 или 2 цифри, или 3 букви: (\d{1,2})
- Третата част е група от 4 или 2 цифри: (\d{4})
- Разделител е или наклонена черта, или тире: [\/-]
- От двете страни е поставена граница на думата \b, за да е ясно, че датата е отделна дума, а не част от по-голям низ.
Както можете да видите на изображението по-долу, тя успешно извлича дати и пропуска поднизове като 11/22/333. Въпреки това тя все още връща фалшиво положителни резултати. В нашия случай поднизът 11-ABC-2222 в A9 технически отговаря на формата на датата dd-mmm-yyyy и следователно се извлича. 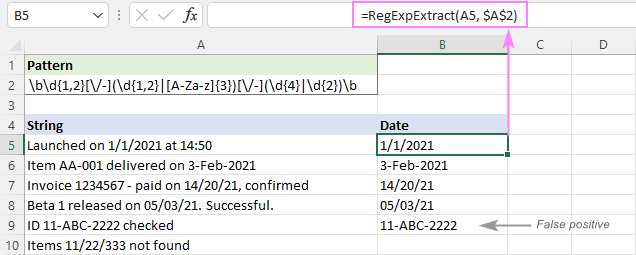
За да елиминирате фалшивите положителни резултати, можете да замените частта [A-Za-z]{3} с пълен списък от трибуквени съкращения на месеци:
Модел : \b\d{1,2}[\/-](\d{1,2}
За да пренебрегнем регистъра на буквите, задаваме последния аргумент на нашата потребителска функция на FALSE:
=RegExpExtract(A5, $A$2, 1, FALSE)
И този път получаваме перфектен резултат: 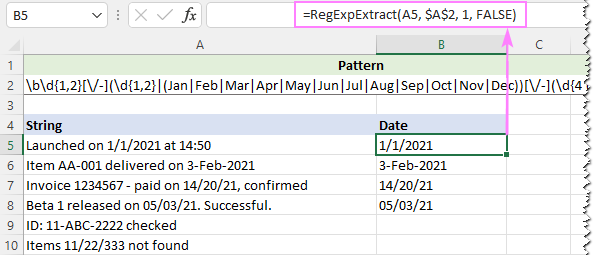
Regex за извличане на време от низ
За да получите време в hh:mm или hh:mm:ss Следващият израз ще работи добре.
Модел : \b(0?[0-9]
При разбиването на този регекс можете да видите 2 части, разделени от
Изразяване 1 : \b(0?[0-9]
Извлича времена с AM/PM.
Час може да бъде всяко число от 0 до 12. За да го получим, използваме конструкцията OR ([0-9]
- [0-9] съвпада с всяко число от 0 до 9
- 1[0-2] съвпада с всяко число от 10 до 12
Минута [0-5]\d е всяко число от 00 до 59.
Втори (:[0-5]\d)? е също така всяко число от 00 до 59. Квантификаторът ? означава нула или еднократна поява, тъй като секундите могат да бъдат или да не бъдат включени в стойността на времето.
Изразяване 2 : \b([0-9]
Извличане на времена без AM/PM.
Сайтът час частта може да бъде всяко число от 0 до 32. За да я получите, трябва да използвате различна конструкция OR ([0-9]
- [0-9] съвпада с всяко число от 0 до 9
- [0-1]\d съвпада с всяко число от 00 до 19
- 2[0-3] съвпада с всяко число от 20 до 23
Сайтът минута и втори частите са същите като в израз 1 по-горе.
Отрицателният знак за изчакване (?!:) се добавя към низове за пропускане, като например 20:30:80.
Тъй като PM/AM могат да бъдат както главни, така и малки букви, функцията не се различава по размер:
=RegExpExtract(A5, $A$2, 1, FALSE) 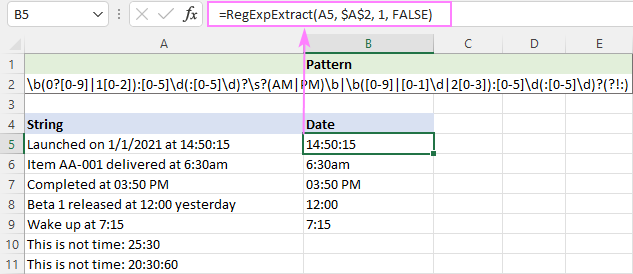
Надявам се, че горните примери са ви дали някои идеи за използване на регулярни изрази в работните листове на Excel. За съжаление не всички функции на класическите регулярни изрази се поддържат във VBA. Ако задачата ви не може да бъде изпълнена с VBA RegExp, ви препоръчвам да прочетете следващата част, в която се разглеждат много по-мощни .NET Regex функции.
Потребителска функция Regex, базирана на .NET, за извличане на текст в Excel
За разлика от VBA RegExp функциите, които могат да бъдат написани от всеки потребител на Excel, .NET RegEx е сфера на разработчиците. Microsoft .NET Framework поддържа пълноценен синтаксис на регулярни изрази, съвместим с Perl 5. Тази статия няма да ви научи как да пишете такива функции (аз не съм програмист и нямам ни най-малка представа как да го направя :)
Четири мощни функции, обработвани от стандартния двигател на .NET RegEx, вече са написани от нашите разработчици и са включени в Ultimate Suite. По-долу ще демонстрираме някои практически приложения на функцията, специално разработена за извличане на текст в Excel.
Съвет. За информация относно синтаксиса на .NET Regex, моля, вижте .NET Regular Expression Language.
Как да извличате жалони в Excel с помощта на регулярни изрази
Ако приемем, че имате инсталирана най-новата версия на Ultimate Suite, извличането на текст с помощта на регулярни изрази се свежда до тези две стъпки:
- На Данни от Ablebits в раздела Текст група, щракнете върху Инструменти за регексиране .

- На Инструменти за регексиране изберете изходните данни, въведете своя Regex шаблон и изберете Извлечение За да получите резултата като потребителска функция, а не като стойност, изберете опцията Вмъкване като формула Когато приключите, щракнете върху Извлечение бутон.

Резултатите ще се появят в нова колона вдясно от първоначалните данни: 
Синтаксис на AblebitsRegexExtract
Нашата потребителска функция има следния синтаксис:
AblebitsRegexExtract(референция, regular_expression)Къде:
- Справка (задължително) - препратка към клетката, която съдържа изходния низ.
- Regular_expression (задължително) - regex шаблонът за съответствие.
Важна забележка! Функцията работи само на машини с инсталиран Ultimate Suite for Excel.
Бележки за употреба
За да направите обучението си по-плавно и опита си по-приятен, моля, обърнете внимание на тези точки:
- За да създадете формула, можете да използвате нашата Инструменти за регекс , или на Excel Функция за вмъкване След като формулата е вмъкната, можете да я управлявате (да я редактирате, копирате или премествате) като всяка друга собствена формула.
- Моделът, който сте въвели в Инструменти за регексиране е възможно също така да запазите регулярен израз в отделна клетка. В този случай просто използвайте препратка към клетка за втория аргумент.
- Функцията извлича първо намерено съвпадение .
- По подразбиране функцията е отчитане на малки и големи букви . За съвпадение без значение на големи и малки букви използвайте шаблона (?i).
- Ако не бъде намерено съвпадение, се връща грешка #N/A.
Regex за извличане на низ между два символа
За да получите текст между два символа, можете да използвате група за улавяне или обходни пътища.
Да речем, че искате да извлечете текст между скоби. Най-лесният начин е да използвате група за улавяне.
Модел 1 : \[(.*?)\]
При положителен поглед назад и напред резултатът ще бъде абсолютно същият.
Модел 2 : (?<=\[)(.*?)(?=\])
Моля, обърнете внимание, че нашата група за улавяне (.*?) извършва мързеливо търсене за текст между две скоби - от първата [ до първата ]. Група за улавяне без въпросителен знак (.*) ще направи алчно търсене и да заснемете всичко - от първия до последния [ ].
С модела в A2 формулата е следната:
=AblebitsRegexExtract(A5, $A$2) 
Как да получите всички мачове
Както вече споменахме, функцията AblebitsRegexExtract може да извлече само едно съвпадение. За да получите всички съвпадения, можете да използвате функцията VBA, която обсъдихме по-рано. Има обаче една уговорка - VBA RegExp не поддържа улавяне на групи, така че горният шаблон ще върне и "граничните" символи, в нашия случай скоби.
=TEXTJOIN(" ", TRUE, RegExpExtract(A5, $A$2)) 
За да се отървете от скобите, заместете ги с празни низове (""), като използвате тази формула:
=SUBSTITUTE(SUBSTITUTE(TEXTJOIN(", ", TRUE, RegExpExtract(A5, $A$2)), "]", ""),"[","")
За по-добра четливост използваме запетая за разделител. 
Regex за извличане на текст между два низа
Подходът, който разработихме за извличане на текст между два символа, ще работи и за извличане на текст между два низа.
Например, за да получите всичко между "test 1" и "test 2", използвайте следния регулярен израз.
Модел : тест 1(.*?)тест 2
Пълната формула е:
=AblebitsRegexExtract(A5, "test 1(.*?)test 2") 
Регекс за извличане на домейн от URL
Дори и с помощта на регулярни изрази извличането на имена на домейни от URL адреси не е тривиална задача. Ключовият елемент, който върши работа, са групите, които не се улавят. В зависимост от крайната ви цел изберете един от посочените по-долу регекси.
За да получите пълно име на домейна включително поддомейни
Модел : (?:https?\:
За да получите второ ниво домейн без поддомейни
Модел : (?:https?\:
Сега нека видим как работят тези регулярни изрази за пример с "//www.mobile.ablebits.com" като примерен URL адрес:
- (?:https?\:
- \/\/ - две наклонени чертички напред (всяка от тях се предшества от обратна наклонена черта, за да се избегне специалното значение на наклонената чертачка напред и да се интерпретира буквално).
- (?:[A-Za-z\d\-\.]{2,255}\.)? - група за идентифициране на домейни от трето, четвърто и т.н. ниво, ако има такива ( мобилен В първия модел той се поставя в по-голяма група за улавяне, за да се включат всички такива поддомейни в извличането. Поддомейнът може да бъде дълъг от 2 до 255 символа, откъдето идва и квантификаторът {2,255}.
- ([A-Za-z\d\-]{1,63}\.[A-Za-z]{2,24}) - улавяща група за извличане на домейна от второ ниво ( ablebits ) и домейна от първо ниво ( com ). максималната дължина на домейн от второ ниво е 63 символа. най-дългият съществуващ в момента домейн от първо ниво съдържа 24 символа.
В зависимост от това кой регулярен израз е въведен в A2, формулата по-долу ще даде различни резултати:
=AblebitsRegexExtract(A5, $A$2)
Regex за извличане на пълно име на домейна с всички поддомейни: 
Regex за извличане на второ ниво домейн без поддомейни: 
Това е начинът за извличане на части от текст в Excel с помощта на регулярни изрази. Благодаря ви, че прочетохте, и с нетърпение очаквам да ви видя в нашия блог следващата седмица!
Налични изтегляния
Примери за извличане на регекс от Excel (.xlsm файл)
Пробна версия на Ultimate Suite (.exe файл)
