
Innehållsförteckning
I den här handledningen lär du dig hur du använder reguljära uttryck i Excel för att hitta och extrahera delsträngar som matchar ett givet mönster.
Microsoft Excel tillhandahåller ett antal funktioner för att extrahera text från celler. Dessa funktioner kan hantera de flesta utmaningar med att extrahera strängar i dina kalkylblad. De flesta, men inte alla. När textfunktionerna inte fungerar kommer reguljära uttryck till undsättning. Vänta... Excel har inga RegEx-funktioner! Det stämmer, inga inbyggda funktioner. Men det finns inget som hindrar dig från att använda dina egna :)
Excel VBA Regex-funktion för att extrahera strängar
Om du vill lägga till en egen Regex Extract-funktion i Excel klistrar du in följande kod i VBA-redigeraren. För att aktivera reguljära uttryck i VBA använder vi det inbyggda Microsoft RegExp-objektet.
Public Function RegExpExtract(text As String , pattern As String , Optional instance_num As Integer = 0, Optional match_case As Boolean = True ) Dim text_matches() As String Dim matches_index As Integer On Error GoTo ErrHandl RegExpExtract = "" Set regex = CreateObject ( "VBScript.RegExp" ) regex.pattern = pattern regex.Global = True regex.MultiLine = True If True = match_case Thenregex.ignorecase = False Else regex.ignorecase = True End If Set matches = regex.Execute(text) If 0 <matches.Count Then If (0 = instance_num) Then ReDim text_matches(matches.Count - 1, 0) For matches_index = 0 To matches.Count - 1 text_matches(matches_index, 0) = matches.Item(matches_index) Next matches_index RegExpExtract = text_matches Else RegExpExtract = matches.Item(instance_num - 1) EndIf End If Exit Function ErrHandl: RegExpExtract = CVErr(xlErrValue) End FunctionOm du har lite erfarenhet av VBA kan en steg-för-steg-användarhandledning vara till hjälp: How to insert VBA code in Excel (hur man infogar VBA-kod i Excel).
Observera: För att funktionen ska fungera måste du spara filen som en arbetsbok med makroaktiverad arbetsbok (.xlsm).
Syntax för RegExpExtract
RegExpExtract funktionen söker i en inmatningssträng efter värden som matchar ett reguljärt uttryck och extraherar en eller alla matchningar.
Funktionen har följande syntax:
RegExpExtract(text, mönster, [instance_num], [match_case])Var:
- Text (obligatoriskt) - den textsträng som ska sökas i.
- Mönster (obligatoriskt) - det reguljära uttrycket som ska matchas. När mönstret anges direkt i en formel ska det omges av dubbla citattecken.
- Instance_num (valfritt) - ett serienummer som anger vilken instans som ska extraheras. Om det inte anges, returneras alla hittade träffar (standard).
- Match_case (valfritt) - definierar om text ska matcha eller ignorera skiftläget. Om TRUE eller utelämnas (standard), görs en skiftlägeskänslig matchning; om FALSE - skiftlägesokänslig.
Funktionen fungerar i alla versioner av Excel 365, Excel 2021, Excel 2019, Excel 2016, Excel 2013 och Excel 2010.
4 saker du bör veta om RegExpExtract
För att använda funktionen effektivt i Excel finns det några viktiga saker att tänka på:
- Som standard returnerar funktionen alla hittade träffar i angränsande celler som i det här exemplet. Om du vill få fram en specifik förekomst anger du ett motsvarande nummer till instance_num argument.
- Som standard är funktionen Skiftlägeskänslig Om du vill ha en matchning som inte tar hänsyn till stor- och små bokstäver, anger du match_case argumentet till FALSE. På grund av VBA-begränsningarna fungerar inte konstruktionen (?i) som inte tar hänsyn till storleken på storleken på skiftläget.
- Om en giltigt mönster har inte hittats återger funktionen ingenting (tom sträng).
- Om den Mönstret är ogiltigt. , uppstår ett #VALUE! fel.
Innan du börjar använda den här anpassade funktionen i dina kalkylblad måste du förstå vad den kan göra, eller hur? Nedanstående exempel täcker några vanliga användningsfall och förklarar varför beteendet kan skilja sig åt i Dynamic Array Excel (Microsoft 365 och Excel 2021) och traditionell Excel (2019 och äldre versioner).
Observera: Exemplen på reguljära uttryck är skrivna för enkla datamängder. Vi kan inte garantera att de kommer att fungera felfritt i dina riktiga arbetsblad. De som har erfarenhet av reguljära uttryck håller med om att det är en oändlig väg mot perfektion att skriva reguljära uttryck - det finns nästan alltid ett sätt att göra det elegantare eller att hantera ett bredare utbud av indata.
Regex för att extrahera nummer från sträng
Enligt den grundläggande principen om att lära ut "från enkelt till komplext" börjar vi med ett mycket enkelt fall: att extrahera ett nummer från en sträng.
Det första du måste bestämma är vilket nummer du vill hämta: första, sista, en viss förekomst eller alla nummer.
Extrahera det första numret
Det här är så enkelt som ett regex kan bli. Eftersom \d betyder en siffra från 0 till 9 och + betyder en eller flera gånger, får vårt reguljära uttryck följande form:
Mönster : \d+
Ställ in instance_num till 1 så får du det önskade resultatet:
=RegExpExtract(A5, "\d+", 1)
Där A5 är den ursprungliga strängen.
För att underlätta kan du ange mönstret i en fördefinierad cell ($A$2 ) och låsa dess adress med $-tecknet:
=RegExpExtract(A5, $A$2, 1) 
Hämta det sista numret
Om du vill extrahera det sista numret i en sträng kan du använda följande mönster:
Mönster : (\d+)(?!.*\d)
Översatt till ett mänskligt språk säger det: hitta ett tal som inte följs (var som helst, inte bara omedelbart) av något annat tal. För att uttrycka detta använder vi en negativ lookahead (?!.*\d), vilket innebär att det till höger om mönstret inte ska finnas någon annan siffra (\d), oavsett hur många andra tecken som finns före den.
=RegExpExtract(A5, "(\d+)(?!.*\d)") 
Tips:
- För att få en Särskild förekomst. , använda \d+ för mönster och ett lämpligt serienummer för instance_num .
- Formeln för att extrahera alla nummer diskuteras i nästa exempel.
Regex för att extrahera alla träffar
Om du vill ta vårt exempel lite längre, antar vi att du vill hämta alla siffror från en sträng, inte bara en.
Som du kanske minns styrs antalet utdragna träffar av den valfria instance_num Standardvärdet är alla träffar, så du kan helt enkelt utelämna denna parameter:
=RegExpExtract(A2, "\d+")
Formeln fungerar utmärkt för en enskild cell, men beteendet skiljer sig åt mellan Excel med dynamisk matris och icke-dynamiska versioner.
Excel 365 och Excel 2021
Tack vare stöd för dynamiska matriser sprider sig en vanlig formel automatiskt till så många celler som behövs för att visa alla beräknade resultat. I Excel kallas detta för ett spilled range: 
Excel 2019 och lägre
I det fördynamiska Excel skulle formeln ovan bara ge en träff. Om du vill få flera träffar måste du göra formeln till en matrisformel. Markera ett antal celler, skriv formeln och tryck på Ctrl + Shift + Enter för att slutföra den.
En nackdel med detta tillvägagångssätt är att en massa #N/A-fel dyker upp i "extra celler". Tyvärr går det inte att göra något åt det (varken IFERROR eller IFNA kan tyvärr rätta till det). 
Extrahera alla matchningar i en cell
När du bearbetar en kolumn med data fungerar ovanstående tillvägagångssätt uppenbarligen inte. I det här fallet skulle en idealisk lösning vara att returnera alla träffar i en enda cell. För att göra det, servera resultaten av RegExpExtract till TEXTJOIN-funktionen och separera dem med valfri avgränsare, till exempel ett kommatecken och ett mellanslag:
=TEXTJOIN(", ", ", TRUE, RegExpExtract(A5, "\d+")) 
Eftersom TEXTJOIN-funktionen endast är tillgänglig i Excel för Microsoft 365, Excel 2021 och Excel 2019 fungerar formeln inte i äldre versioner.
Regex för att extrahera text från en sträng
Att extrahera text från en alfanumerisk sträng är en ganska svår uppgift i Excel. Med regex blir det lätt som en plätt. Använd bara en negerad klass för att matcha allt som inte är en siffra.
Mönster : [^\d]+
För att få fram delsträngar i enskilda celler (spillområde) är formeln följande:
=RegExpExtract(A5, "[^\d]+") 
För att skriva ut alla matchningar i en cell, bädda in funktionen RegExpExtract i TEXTJOIN på följande sätt:
=TEXTJOIN("", TRUE, RegExpExtract(A5, "[^\d]+")) 
Regex för att extrahera e-postadress från sträng
Om du vill ta fram en e-postadress från en sträng som innehåller mycket olika information skriver du ett reguljärt uttryck som replikerar strukturen för e-postadressen.
Mönster : [\w\.\-]+@[A-Za-z0-9\.\-]+\.[A-Za-z]{2,24}
Om vi bryter ner detta regex får vi följande resultat:
- [\w\.\-]+ är ett användarnamn som kan innehålla 1 eller flera alfanumeriska tecken, understrykningar, punkter och bindestreck.
- @-symbol
- [A-Za-z0-9\.\-]+ är ett domännamn som består av stora och små bokstäver, siffror, bindestreck och punkter (om det finns underdomäner). Understrykningar är inte tillåtna här, därför används tre olika teckenuppsättningar (t.ex. A-Z a-z och 0-9) i stället för \w som matchar alla bokstäver, siffror och understrykningar.
- \..[A-Za-z]{2,24} är en toppdomän som består av en punkt följt av stora och små bokstäver. De flesta toppdomäner är tre bokstäver långa (t.ex. .com .org, .edu osv.), men i teorin kan de innehålla mellan 2 och 24 bokstäver (den längsta registrerade toppdomänen).
Om strängen finns i A5 och mönstret i A2 är formeln för att extrahera en e-postadress följande:
=RegExpExtract(A5, $A$2) 
Regex för att extrahera domän från e-post
När det gäller att extrahera e-postdomäner är den första tanken att använda en fångavgränsningsgrupp för att hitta text som följer omedelbart efter @-tecknet.
Mönster : @([A-Za-z0-9\.\-]+\.[A-Za-z]{2,24})
Skicka den till vår RegExp-funktion:
=RegExpExtract(A5, "@([A-Za-z0-9\.\-]+\.[A-Za-z]{2,24})")
Du får det här resultatet: 
Med klassiska reguljära uttryck tas inte allt som ligger utanför en grupp som fångas upp med i utdraget. Ingen vet varför VBA RegEx fungerar annorlunda och även fångar upp "@". För att bli av med det kan du ta bort det första tecknet från resultatet genom att ersätta det med en tom sträng.
=REPLACE(RegExpExtract(A5, "@([a-z\d][a-z\d\-\.]*\..[a-z]{2,})", 1, FALSE), 1, 1, 1, "") 
Regulärt uttryck för att extrahera telefonnummer
Telefonnummer kan skrivas på många olika sätt, och därför är det nästan omöjligt att hitta en lösning som fungerar under alla omständigheter. Du kan dock skriva ner alla format som används i ditt dataset och försöka matcha dem.
I det här exemplet ska vi skapa ett regex som extraherar telefonnummer i något av dessa format:
(123) 345-6789 (123) 345 6789 (123)3456789 123-345-6789 | 123.345.6789 123 345 6789 1233456789 |
Mönster : \(?\d{3}[-\. \)]*\d{3}[-\. ]?\d{4}\b
- Den första delen \(?\d{3} matchar noll eller en öppnande parentes följt av tre siffror d{3}.
- Delen [-\. \)]* avser varje tecken inom hakparentes som förekommer 0 eller fler gånger: bindestreck, punkt, mellanslag eller avslutande parentes.
- Därefter har vi återigen tre siffror d{3} följt av ett bindestreck, punkt eller mellanslag [-\. ]? som förekommer 0 eller 1 gång.
- Därefter finns det en grupp med fyra siffror \d{4}.
- Slutligen finns det en ordgräns \b som definierar att ett telefonnummer vi söker inte kan vara en del av ett större nummer.
Den fullständiga formeln har följande form:
=RegExpExtract(A5, "\(?\d{3}[-\. \)]*\d{3}[-\. ]?\d{4}\b") 
Observera att ovanstående regex kan ge några falska positiva resultat, t.ex. 123) 456 7899 eller (123 456 7899. Nedanstående version löser dessa problem. Den här syntaxen fungerar dock endast i VBA RegExp-funktioner, inte i klassiska reguljära uttryck.
Mönster : (\(\d{3}\)
Regex för att extrahera datum från sträng
Ett reguljärt uttryck för att extrahera ett datum beror på i vilket format datumet visas i en sträng. Till exempel:
För att extrahera datum som 1/1/21 eller 01/01/2021 är regexet: \d{1,2}\/\d{1,2}\/(\d{4}
Den söker efter en grupp av 1 eller 2 siffror d{1,2} följt av ett snedstreck, följt av en annan grupp av 1 eller 2 siffror, följt av ett snedstreck, följt av en grupp av 4 eller 2 siffror (\d{4}Det första villkoret är i alternationen ELLER-konstruktionen är matchad, de återstående villkoren kontrolleras inte.
För att hämta datum som 1-Jan-21 eller 01-Jan-2021 är mönstret: \d{1,2}-[A-Za-z]{3}-\d{2,4}
Den söker efter en grupp med 1 eller 2 siffror, följt av ett bindestreck, följt av en grupp med 3 versaler eller gemener, följt av ett bindestreck, följt av en grupp med 4 eller 2 siffror.
Efter att ha kombinerat de två mönstren får vi följande regex:
Mönster : \b\d{1,2}[\/-](\d{1,2}
Var:
- Den första delen är 1 eller 2 siffror: \d{1,2}
- Den andra delen är antingen 1 eller 2 siffror eller 3 bokstäver: (\d{1,2}
- Den tredje delen är en grupp av 4 eller 2 siffror: (\d{4}
- Avgränsare är antingen ett snedstreck eller ett bindestreck: [\/-]
- En ordgräns \b placeras på båda sidor för att tydliggöra att ett datum är ett separat ord och inte en del av en större sträng.
Som du kan se i bilden nedan tar den fram datum och lämnar bort delsträngar som 11/22/333. Den returnerar dock fortfarande falska positiva resultat. I vårt fall stämmer delsträngen 11-ABC-2222 i A9 tekniskt sett överens med datumformatet. dd-mmm-yyyy och därför utvinns. 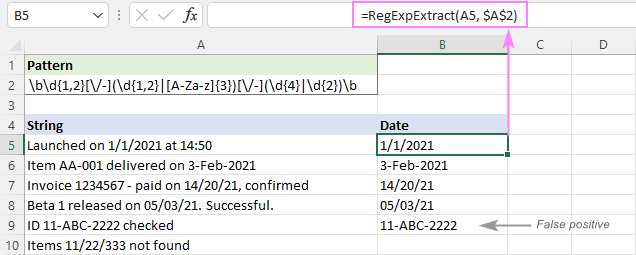
För att eliminera falska positiva resultat kan du ersätta delen [A-Za-z]{3} med en fullständig lista över månadsförkortningar på tre bokstäver:
Mönster : \b\d{1,2}[\/-](\d{1,2}
För att ignorera bokstavsbokstäverna ställer vi in det sista argumentet i vår anpassade funktion till FALSE:
=RegExpExtract(A5, $A$2, 1, FALSE)
Och den här gången får vi ett perfekt resultat: 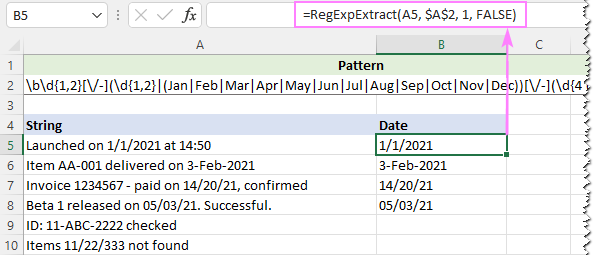
Regex för att extrahera tid från sträng
För att få tid i hh:mm eller . hh:mm:ss formatet fungerar följande uttryck utmärkt.
Mönster : \b(0?[0-9]
Om du bryter ner detta regex kan du se 2 delar som är separerade av
Uttryck 1 : \b(0?[0-9]
Hämtar tider med AM/PM.
Timme kan vara ett valfritt tal mellan 0 och 12. För att få fram det använder vi OR-konstruktionen ([0-9]
- [0-9] matchar alla siffror från 0 till 9.
- 1[0-2] matchar alla siffror från 10 till 12.
Protokoll [0-5]\d är ett valfritt nummer mellan 00 och 59.
Andra (:[0-5]\d)? är också ett tal mellan 00 och 59. Kvantifieringen ? betyder noll eller en förekomst eftersom sekunder kan ingå eller inte ingå i tidsvärdet.
Uttryck 2 : \b([0-9]
Extraherar tider utan AM/PM.
timme delen kan vara ett valfritt tal mellan 0 och 32. För att få fram den, måste man använda en annan OR-konstruktion ([0-9]
- [0-9] matchar alla siffror från 0 till 9.
- [0-1]\d matchar alla nummer från 00 till 19.
- 2[0-3] matchar alla nummer mellan 20 och 23.
minut och andra är samma som i uttryck 1 ovan.
Negativ lookahead (?!:) läggs till för att hoppa över strängar som 20:30:80.
Eftersom PM/AM kan vara antingen stora eller små bokstäver är funktionen okänslig för stor- och små bokstäver:
=RegExpExtract(A5, $A$2, 1, FALSE) 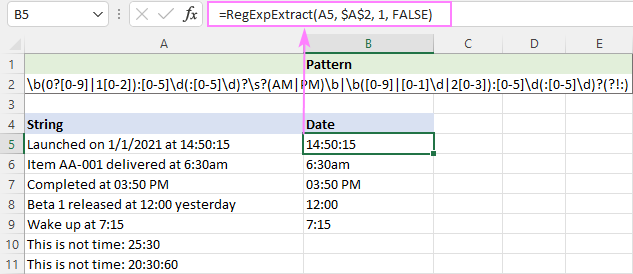
Förhoppningsvis gav ovanstående exempel dig några idéer om hur du kan använda reguljära uttryck i dina Excel-arbetsblad. Tyvärr stöds inte alla funktioner i klassiska reguljära uttryck i VBA. Om din uppgift inte kan utföras med VBA RegExp, uppmanar jag dig att läsa nästa del där vi diskuterar mycket mer kraftfulla .NET Regex-funktioner.
Anpassad .NET-baserad Regex-funktion för att extrahera text i Excel
Till skillnad från VBA RegExp-funktioner som kan skrivas av vilken Excel-användare som helst, är .NET RegEx utvecklarens område. Microsoft .NET Framework har stöd för fullfjädrad syntax för reguljära uttryck som är kompatibel med Perl 5. Den här artikeln kommer inte att lära dig hur du skriver sådana funktioner (jag är ingen programmerare och har inte den minsta aning om hur man gör det :)
Fyra kraftfulla funktioner som bearbetas av standard .NET RegEx-motorn har redan skrivits av våra utvecklare och ingår i Ultimate Suite. Nedan visar vi några praktiska användningsområden för den funktion som är speciellt utformad för att extrahera text i Excel.
Tips: Information om .NET Regex-syntaxen finns i .NET Regular Expression Language.
Hur man extraherar stickor i Excel med hjälp av reguljära uttryck
Om du har installerat den senaste versionen av Ultimate Suite kan du extrahera text med hjälp av reguljära uttryck i två steg:
- På den Uppgifter om Ablebits på fliken Text grupp, klicka på Regex-verktyg .

- På den Regex-verktyg Välj källdata, skriv in ditt Regex-mönster och välj den Utdrag Om du vill få resultatet som en anpassad funktion, inte som ett värde, väljer du alternativet Infoga som en formel När du är klar klickar du på kryssrutan Utdrag knapp.

Resultaten visas i en ny kolumn till höger om de ursprungliga uppgifterna: 
Syntax för AblebitsRegexExtract
Vår anpassade funktion har följande syntax:
AblebitsRegexExtract(referens, regular_expression)Var:
- Referens (obligatoriskt) - en referens till cellen som innehåller källsträngen.
- Regulärt_uttryck (obligatoriskt) - det regexmönster som ska matchas.
Viktigt att notera: Funktionen fungerar endast på maskiner med Ultimate Suite for Excel installerad.
Användningsanvisningar
För att göra din inlärningskurva smidigare och din upplevelse roligare bör du vara uppmärksam på dessa punkter:
- För att skapa en formel kan du använda vår Regex-verktyg , eller Excels Infoga funktion eller skriv in hela funktionsnamnet i en cell. När formeln väl är infogad kan du hantera den (redigera, kopiera eller flytta) som vilken annan formel som helst.
- Mönstret som du anger på Regex-verktyg går till det andra argumentet. Det är också möjligt att ha ett reguljärt uttryck i en separat cell. I det här fallet använder du bara en cellreferens för det andra argumentet.
- Funktionen hämtar den första funna matchning .
- Som standard är funktionen Skiftlägeskänslig Använd (?i) för att matcha mellan olika bokstäver.
- Om ingen matchning hittas returneras ett #N/A-fel.
Regex för att extrahera strängar mellan två tecken
Om du vill få fram text mellan två tecken kan du använda antingen en fångavsnittsgrupp eller en omväg.
Låt oss säga att du vill extrahera text mellan parenteser. Det enklaste sättet är att använda en fångavsnittsgrupp.
Mönster 1 : \[(.*?)\]
Med en positiv blick bakåt och framåt blir resultatet exakt detsamma.
Mönster 2 : (?<=\[)(.*?)(?=\])
Var uppmärksam på att vår fångstgrupp (.*?) utför en lat sökning för text mellan två parenteser - från den första [ till den första ]. En fånggrupp utan frågetecken (.*) skulle göra en girig sökning och fånga allt från den första [ till den sista ].
Med mönstret i A2 kan formeln användas på följande sätt:
=AblebitsRegexExtract(A5, $A$2) 
Hur du får alla matcher
Som redan nämnts kan AblebitsRegexExtract-funktionen bara ta fram en träff. För att få fram alla träffar kan du använda VBA-funktionen som vi har diskuterat tidigare. Det finns dock en invändning - VBA RegExp har inte stöd för att fånga upp grupper, så ovanstående mönster kommer att ge tillbaka även "gränstecken", i vårt fall parenteser.
=TEXTJOIN(" ", TRUE, RegExpExtract(A5, $A$2)) 
Om du vill bli av med parenteserna kan du ersätta dem med tomma strängar ("") med hjälp av denna formel:
=SUBSTITUTE(SUBSTITUTE(TEXTJOIN(", ", ", TRUE, RegExpExtract(A5, $A$2)), "]", ""), "[","")
För bättre läsbarhet använder vi ett kommatecken som avgränsare. 
Regex för att extrahera text mellan två strängar
Det tillvägagångssätt som vi har utarbetat för att ta fram text mellan två tecken fungerar också för att ta fram text mellan två strängar.
Om du till exempel vill få fram allt mellan "test 1" och "test 2" använder du följande reguljära uttryck.
Mönster : test 1(.*?)test 2
Den fullständiga formeln är:
=AblebitsRegexExtract(A5, "test 1(.*?)test 2") 
Regex för att extrahera domän från URL
Även med reguljära uttryck är det inte helt enkelt att extrahera domännamn från webbadresser. Det viktigaste elementet som gör susen är att inte fånga grupper. Beroende på ditt slutmål kan du välja en av nedanstående regexer.
För att få en fullständigt domännamn inklusive underdomäner
Mönster : (?:https?\:
För att få en andra nivån domän utan underdomäner
Mönster : (?:https?\:
Nu ska vi se hur dessa reguljära uttryck fungerar på ett exempel med "//www.mobile.ablebits.com" som exempel-URL:
- (?:https?\:
- \/\// - två snedstreck (varje snedstreck föregås av ett backslash för att undvika den särskilda betydelsen av snedstrecket och tolka det bokstavligt).
- (?:[A-Za-z\d\d\-\.]{2,255}\..)?? - icke-fångstgivande grupp för att identifiera domäner på tredje och fjärde nivå etc., om sådana finns ( mobil I det första mönstret placeras den i en större grupp för att få med alla sådana underdomäner i utvinningen. En underdomän kan vara mellan 2 och 255 tecken lång, därav kvantifieringen {2,255}.
- ([A-Za-z\d\-]{1,63}\.[A-Za-z]{2,24}) - fångavsnitt för att extrahera domänen på andra nivån ( kapablabitar ) och toppdomänen ( com ). Den maximala längden på en toppdomän är 63 tecken. Den längsta toppdomänen som för närvarande existerar innehåller 24 tecken.
Beroende på vilket reguljärt uttryck som anges i A2 kommer formeln nedan att ge olika resultat:
=AblebitsRegexExtract(A5, $A$2)
Regex för att extrahera fullständigt domännamn med alla underdomäner: 
Regex för att extrahera en andra nivån domän utan underdomäner: 
Så här gör du för att extrahera delar av text i Excel med hjälp av reguljära uttryck. Tack för att du läste och jag ser fram emot att se dig på vår blogg nästa vecka!
Tillgängliga nedladdningar
Excel Regex Extract-exempel (.xlsm-fil)
Ultimate Suite testversion (.exe-fil)
